Лента новостей
|
19.11.2019 [00:29], Андрей Созинов
Ноябрьский TOP500: больше китайских систем и меньше американских, и первая система на AMD EPYC RomeУже традиционно в рамках конференции SC была опубликована свежая версия TOP500, рейтинга пятисот самых производительных суперкомпьютеров в мире.  В новой версии списка стало больше систем из Китая, и в то же время сократилось количество систем, расположенных в США. Значительно увеличилась общая производительность всех систем, однако десятка лидеров рейтинга изменений не претерпела. 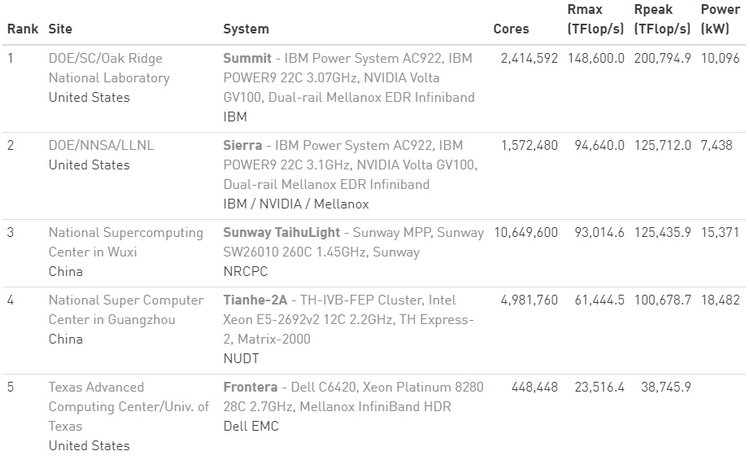 За последние шесть месяцев число китайских суперкомпьютеров в рейтинге TOP500 увеличилась с 219 до 228, и в итоге их доля составила 45,6 %. В то же время количество американских суперкомпьютеров достигло минимума в 117 систем, что составляет 23,4 %. Однако общая производительность систем из США выше — 37,1 % от общей, в то время как доля Китая здесь составляет 32,2 %. Суммарная производительность всех пятисот самых мощных суперкомпьютеров в мире составляет 1,65 Экзафлопс. Российских машин в рейтинге три. На 29 месте TOP500 теперь находится суперкомпьютер Кристофари, принадлежащий Сбербанку. 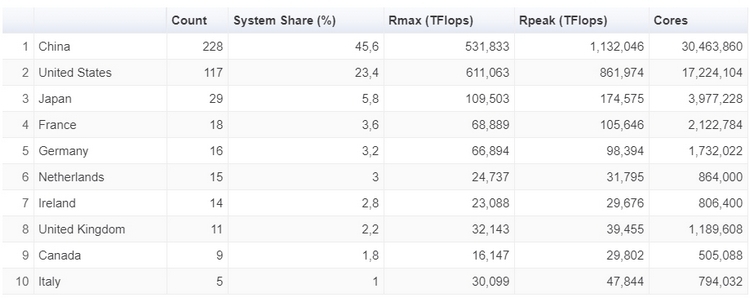 Количество систем, использующих ускорители вычислений и сопроцессоры также возросло, со 134 до 145. Большинство из них использует продукты на базе NVIDIA Volta, a также Pascal и Kepler. Что касается центральных процессоров, то здесь безоговорочным лидером остаётся Intel — 94,8 % систем из TOP500 построены на её чипах.  И здесь же хотелось бы отметить, что в свежем рейтинге TOP500 появилась первая система на процессорах AMD EPYC Rome. Это французский суперкомпьютер Joliot-Curie, построенный на платформе AtoS BullSequana XH2000, которая включает 64-ядерные процессоры AMD EPYC 7H12. Данный суперкомпьютер обладает производительностью 9,4 Пфлопс, он разместился на 59 строке рейтинга TOP500. Значительно увеличилась и минимальная производительность систем рейтинга TOP500. Теперь пятисотая система в рейтинге обладает производительностью в 1,142 Петафлопс. Полгода назад эта система располагалась на 399 месте. А чтобы претендовать на сотое место в рейтинге, системе теперь необходимо обладать производительностью более чем в 2,57 Пфлопс. 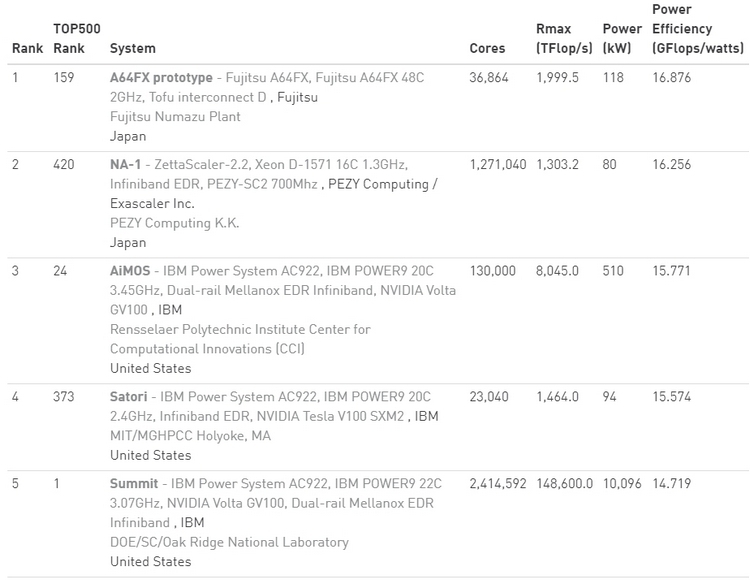 Рейтинг наиболее энергоэффективных систем — Green500 — возглавила японская система от Fujitsu. Это прототип суперкомпьютера на базе процессоров A64FX, который обеспечивает производительность в 16,9 Гфлопс на 1 ватт энергии. В общем рейтинге TOP500 данная система занимает 159 строку с общей производительностью в 2 Пфлопс. Интересно, что система обладает всего лишь 36 864 ядрами и не использует ускорители, что делает её результаты ещё более впечатляющими. Кстати, среднее количество ядер на систему из списка TOP500 также увеличилось — с 118 213 до 126 308.
04.11.2019 [21:00], Алексей Степин
IBM продвигает открытый стандарт оперативной DDIMM-памяти OMI для серверовПрактически у всех современных процессоров контроллер памяти давно и прочно является частью самого ЦП, будь то монолитный кристалл или чиплетная сборка. Но не всегда подобная монолитность является плюсом — к примеру, она усложняет задачу увеличения количества каналов доступа к памяти. Таких каналов уже 8 и существуют проекты процессоров с 10 каналами памяти. Но это усложняет как сами ЦП, так и системные платы, ведь только на подсистему памяти, без учёта интерфейса PCI Express, может уйти 300 и более контактов, которые ещё требуется корректно развести и подключить. 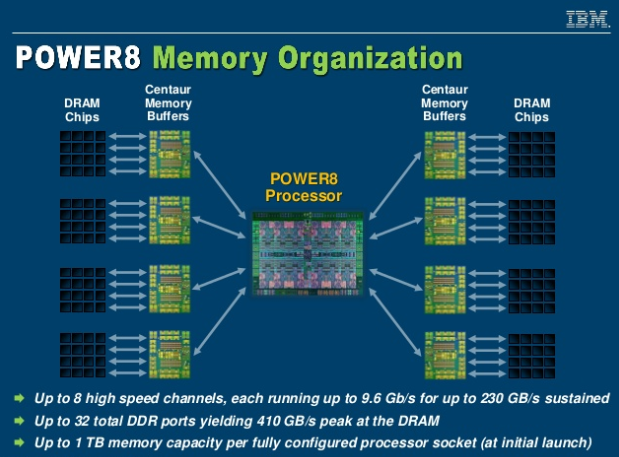
Организация подсистемы памяти у POWER8 У IBM есть ответ, и заключается он в переносе части функций контроллера памяти на сторону модулей DIMM. Сам интерфейс между ЦП и модулями памяти становится последовательным и предельно унифицированным. Похожая схема использовалась в стандарте FB-DIMM, аналогичную компоновку применила и сама IBM в процессорах POWER8 и POWER9 в варианте Scale-Up. 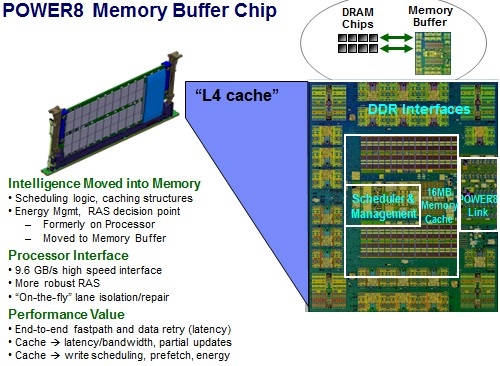
Роль и возможности буфера Centaur у POWER8 Контроллер памяти у этих процессоров упрощён, в нём отсутствует контроллер физического уровня (PHY). Его задачи возложены на чип-буфер Centaur, который посредством одноимённого последовательного интерфейса и связывается с процессором на скорости 28,8 Гбайт/с. Контроллеров интерфейса Centaur в процессорах IBM целых восемь, что дает ПСП в районе 230 Гбайт/с. За счёт выноса ряда функций в чипы-буфера удалось сократить площадь кристалла, и без того немалую (свыше 700 мм2), но за это пришлось заплатить увеличением задержек в среднем на 10 нс. Частично это сглажено за счёт наличия в составе Centaur кеша L4. 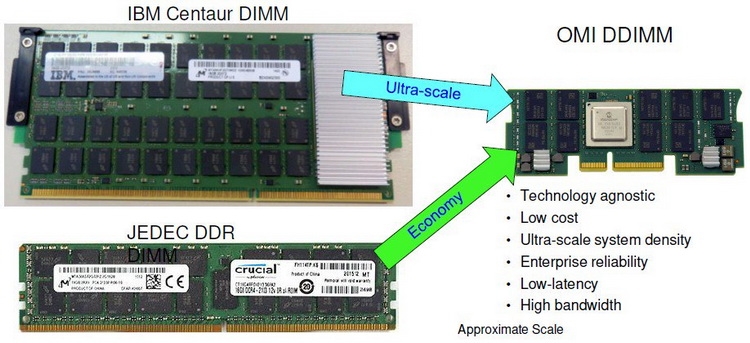
Сравнительные размеры модулей Centaur, RDIMM и OMI DDIMM Стандарт не является открытым, но IBM предлагает ему на смену полностью открытый вариант под названием Open Memory Interface (OMI). В его основу положена семантика и протоколы, описанные в стандарте OpenCAPI 3.1, а физический уровень представлен шиной BlueLink (25 Гбит/с на линию), которая уже используется для реализации NVLink и OpenCAPI. Реализация OMI проще Centaur, что позволяет сделать чип-буфер более компактным и выделяющим меньше тепла. Но все преимущества сохраняются: так, число контактов процессора, отвечающих за интерфейс памяти, можно снизить с примерно 300 до 75, поскольку посылаются только простые команды загрузки и сохранения данных. Вся реализация физического интерфейса осуществляется силами чипа-компаньона OMI, и в нём же может находиться дополнительный кеш. 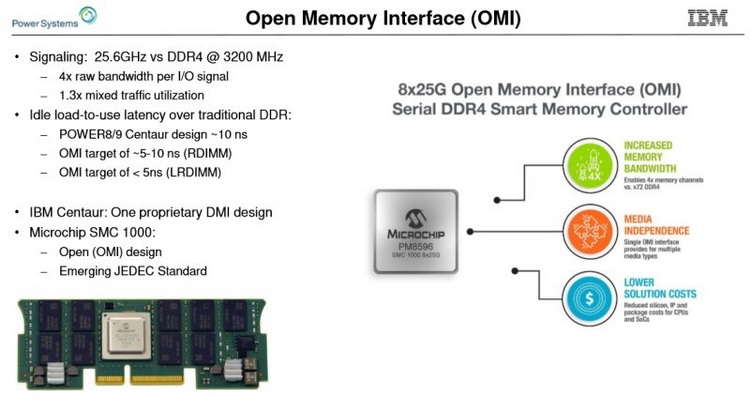
Модули OMI DDIMM станут стандартом JEDEC Помимо экономии контактов есть и ещё одна выгода: можно реализовать любой тип памяти, будь то DDR, GDDR и даже NVDIMM — вся PHY-часть придётся на различные варианты чипов OMI, но со стороны стандартного разъёма любой модуль OMI будет выглядеть одинаково. Сейчас взят прицел на реализацию модулей с памятью DDR5. При использовании существующих чипов DDR4 система с интерфейсом OMI может достичь совокупной ПСП порядка 650 Гбайт/с. Дополнительные задержки составят 5 ‒ 10 нс для RDIMM и лишь 4 нс для LRDIMM. Из всех соперников технологии на такое способны только сборки HBM, которые в силу своей природы имеют ограниченную ёмкость, дороги в реализации и не могут быть вынесены с общей с ЦП подложки. 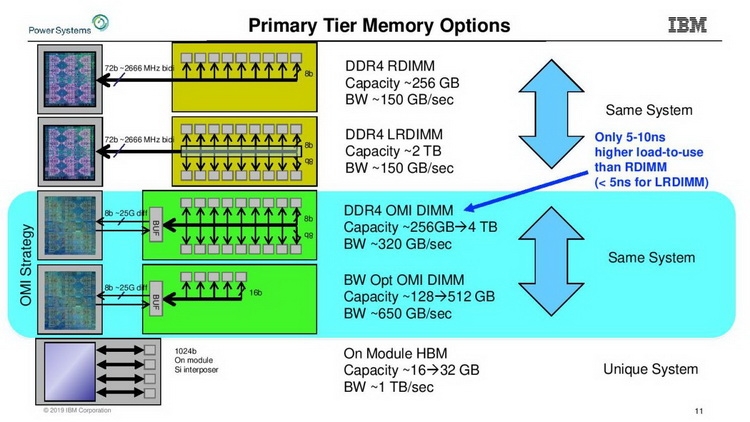
Новый стандарт упростит процессоры и позволит увеличить ёмкость подсистемы памяти Чипы-буферы OMI можно разместить как на модуле памяти, так и на системной плате. Разумеется, для стандартизации выбран первый вариант. В нём предусмотрено 84 контакта на модуль, сами же модули получили название Dual-Inline Memory Module (DDIMM). DDIMM вышли существенно компактнее своих традиционных собратьев: ширина модуля сократилась со 133 до 85 мм. Реализация буфера OMI ↔ DDR4 уже существует в кремнии: компания Microsemi продемонстрировала чип SMC 1000 (PM8596), поддерживающего 8 линий OMI со скоростью 25 Гбит/с каждая. Допустима также работа в режиме 4 × 1 с вдвое меньшей общей пропускной способностью. 
DDIMM: меньше ширина, проще разъём Со стороны чипов памяти SMC 1000 имеет стандартный 72-битный интерфейс с ECC и поддержкой различных комбинаций DRAM и NAND-устройств. Тактовая частота DRAM — до 3,2 ГГц, высота модуля зависит от количества и типов устанавливаемых чипов. В случае одиночной высоты модули могут иметь ёмкость до 128 Гбайт, двойная высота позволит создать DDIMM объёмом свыше 256 Гбайт. Сам чип SMC 1000 невелик, всего 17 × 17 мм, а невысокое тепловыделение гарантирует отсутствие проблем с перегревом, свойственных FB-DIMM. 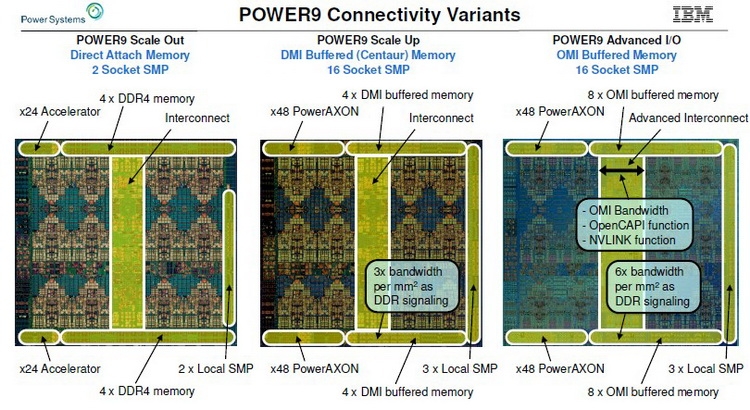
Процессоры IBM POWER9 AIO дополнили существующую серию Первыми процессорами с поддержкой OMI стали новые POWER9 версии Advanced I/O (AIO), дополнившие семейства Scale Up (SC) и Scale Out (SO). В них реализовано 16 каналов OMI по 8 линий каждый (до 650 Гбайт/с суммарно), а также новые версии интерфейсов NVLink (возможно, 3.0) и OpenCAPI 4.0. Количество линий PCI Express 4.0 по-прежнему составляет 48. Шина IBM BlueLink была переименована в PowerAXON. За счёт её использования в системах на базе процессоров POWER возможна реализация 16-сокетных систем без применения дополнительной логики. Максимальное количество ядер у POWER9 AIO равно 24, с учётом SMT4 это даёт 96 исполняемых потоков. Имеется также кеш L3 типа eDRAM объёмом 120 Мбайт. Техпроцесс остался прежним, это 14-нм FinFET. 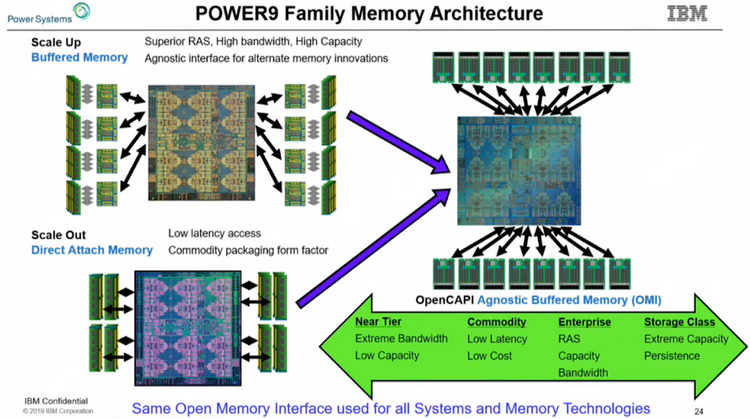
Архитектура подсистем памяти у семейства IBM POWER9 Поставки POWER9 AIO начнутся в этом году, цены неизвестны, но с учётом 8 миллиардов транзисторов и кристалла площадью 728 мм2 они не могут быть низкими. Однако без OMI эти процессоры были бы ещё более дорогими. В комплект поставки входит и чип-буфер OMI, правда, не самая быстрая версия с пропускной способностью на уровне 410 Гбайт/с. Задел для модернизации есть, и для расширения ПСП достаточно будет заменить модули DDIMM на более быстрые варианты. 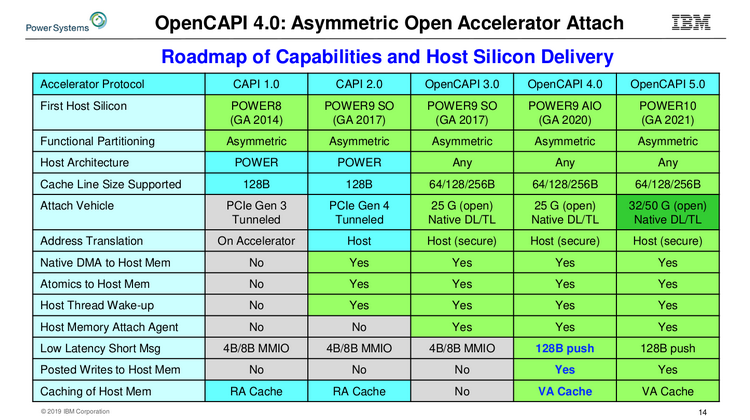
Сравнительная таблица существующих и будущих версий OpenCAPI Следующее поколение процессоров IBM, POWER10, появится только в 2021 году. К этому времени ожидается принятие стандарта OMI на рынке высокопроизводительных многопроцессорных систем. Попутно IBM готовит новые версии OpenCAPI, не привязанные к архитектуре POWER, а значит, путь к OMI будет открыт и другим вендорам.
30.10.2019 [20:13], Алексей Степин
Новая СХД Cray ClusterStor E1000: до 1,6 Тбайт/с и 50 млн IOPSКомпания Cray, известная своими суперкомпьютерами, представила новую платформу хранения данных, ClusterStor E1000. Она предназначена для самых мощных конвергентных вычислительных систем экзафлопсного класса и спроектирована в расчёте на постоянно растущие объёмы данных и требования к скоростным показателям. Новая платформа дополняет экосистему Cray Shasta и, как заявляют представители компании, по некоторым показателям не имеет равных в мире. 
Возможные конфигурации базовой стойки ClusterStor E1000 Cray ClusterStor E1000 конфигурируется под конкретную задачу заказчика. СХД может быть гибридной, полностью твердотельной или оснащаться только традиционными жёсткими дисками. В случае варианта all-flash максимальная производительность может достигать 1,6 Тбайт/с и 50 миллионов IOPS на стойку.  В случае HDD скоростные показатели несколько скромнее — пиковая скорость составляет 120 Гбайт/с, зато ёмкость одной стойки может достигать 10 Пбайт. Cray пока не планирует отказа от традиционных HDD, как обеспечивающих меньшую удельную стоимость хранения данных. 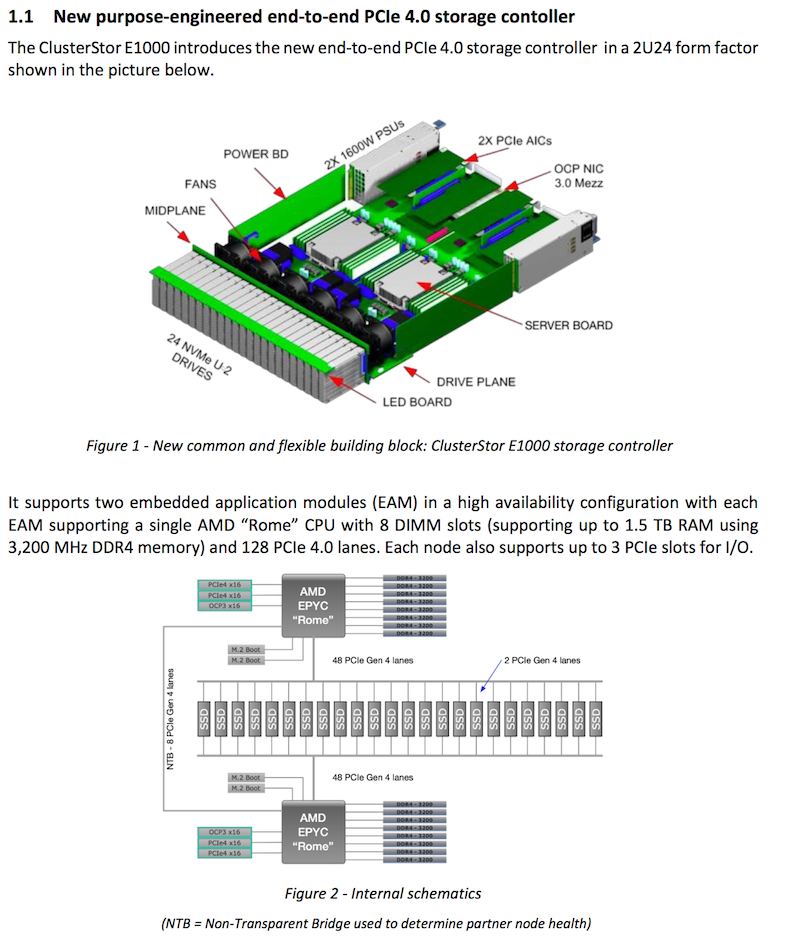
Контроллеры ClusterStor E1000 используют процессоры AMD Rome В базовой конфигурации новинка состоит из двух модулей формата 2U: модуля управления (System Management) и модуля метаданных (Metadata Unit), дополнительные модули устанавливаются в соответствии с задачами заказчика. Модуль управления оснащается одной коммуникационной платой HDR/Slingshot (200 Гбит/с) и двумя хост-адаптерами SAS с интерфейсом PCIe 4.0 (16 линий SAS 12 Гбит/с). Также доступна поддержка 100GbE и InfiniBand EDR/HDR. В системе используются процессоры AMD EPYC Rome, которые наверняка были выбраны из-за большого числа линий PCIe 4.0 (до 128 на сокет/систему), необходимых для подключения и быстрых накопителей, и внешних сетевых интерфейсов. 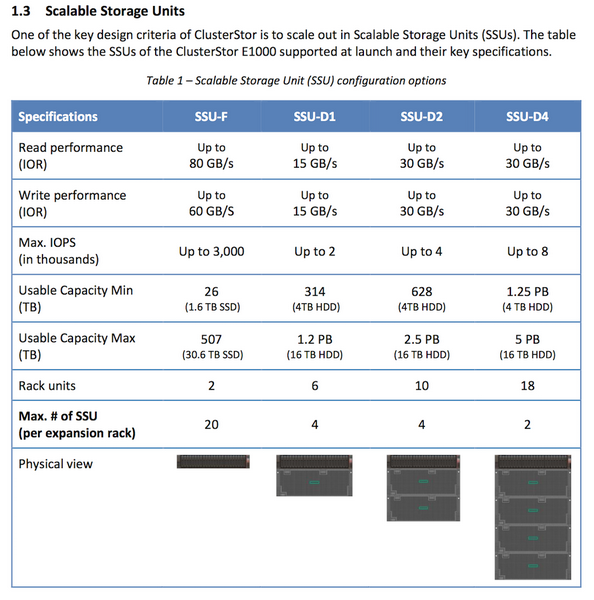
Доступные конфигурации модулей хранения данных Модули хранения данных (Storage Units) могут иметь габариты от 2U до 18U и максимальную ёмкость от 507 Тбайт до 5 Пбайт. Один модуль с SSD обеспечивает производительность до 3 миллионов IOPS, у HDD-версий показатели скромнее: от 2 до 8 тысяч IOPS. Система работает под управлением ClusterStor Data Services и использует файловую систему Lustre с открытым исходным кодом. Стоимость базовой конфигурации ClusterStor E1000 оценивается в $200 тысяч, в эту цену входит и трёхлетняя поддержка. Первые поставки Cray наметила уже на декабрь этого года, полномасштабная доступность новых систем будет достигнута во втором квартале 2020 года.
18.10.2019 [20:36], Алексей Степин
ARMv8 на китайский лад — представлена Micro-ATX плата с 3-ГГц Phytium FT2000/4Китайская компания-разработчик Phytium, известная созданием CPU для суперкомпьютеров Tiahne-1A и Tiahne-2, занимавших первую строку в рейтинге TOP500, уже несколько лет работает над новым поколением 64-ядерных ARMv8-процессоров FeiTeng FT-2000 для будущего Tiahne-3. В сентябре компания анонсировала упрощённый вариант CPU всего с четырьмя ядрами — Phytium FT2000/4. А на днях в сети была замечена первая системная плата формата Micro-ATX на базе этой SoC. 
Так выглядит системная плата на базе данного ЦП Phytium FT2000/4 производится с использованием 16-нм техпроцесса TSMC, диапазон его тактовых частот лежит в пределах 2,6-3,0 ГГц. Имеется 4 Мбайт кеша L2 (по 2 Мбайт на пару ядер) и 4 Мбайт общего кеша L3. Теплопакет невелик и не превышает 10 Вт. Процессор размером 35 × 35 мм имеет упаковку FCBGA 1144. 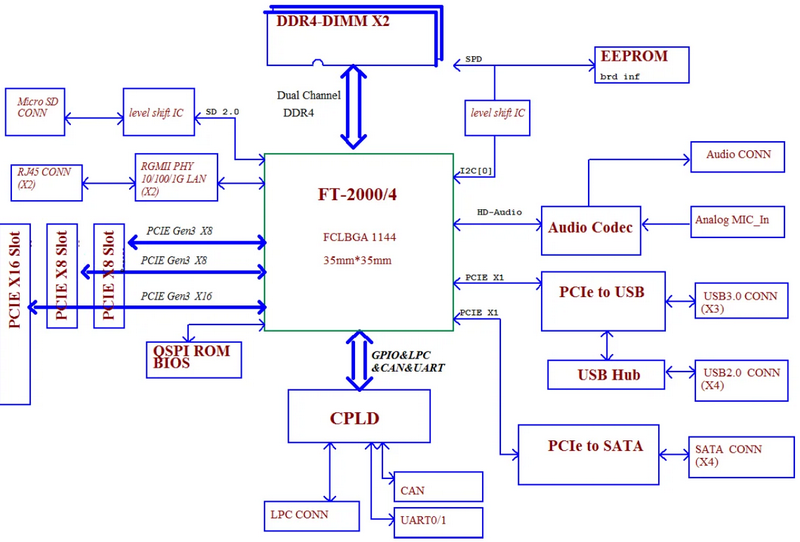
Возможности процессора FT2000/4 SoC предлагает 34 линии PCI-Express 3.0: две x1 и две x16, которые можно разделить, получив четыре x8. Линни x1 отведены под контроллеры USB 3.0 (3 скоростных порта и 4 версии 2.0) и Serial ATA (4 порта). Также есть встроенные интерфейсы HD Audio и 1GbE. Кроме того, имеется отдельный блок аппаратного ускорения шифрования, поддерживающий китайские стандарты SM2/SM3/SM4. Память работает в двухканальном режиме, но слотов DDR4 DIMM всего два, что может ограничить её объём. Встроенного графического адаптера нет, однако есть поддержка некоторых чипов AMD Radeon и GPU китайского производителя Jingjia. На уровне ПО заявлена совместимость с Linux-дистрибутивом Kylin OS. Phytium позиционирует FT2000/4 как основу для создания промышленных компьютеров, встраиваемых решений, тонких клиентов и терминалов (в том числе ноутбуков и моноблоков). А новая материнская плата пригодится для разработчиков. Как упомянутых выше решений, так и приложений для будущего суперкомпьютера.
27.09.2019 [09:36], Владимир Мироненко
LEGO для ускорителей: Inspur представила референсную OCP-систему для модулей OAMКомпания Inspur анонсировала 26 сентября на саммите OCP Regional Summit в Амстердаме новую референсую платформу с UBB-платой (Universal Baseboard) для ускорителей в форм-факторе Open Accelerator Module (OAM). OAM был представлен Facebook✴ в марте этого года. Он очень похож на слегка увеличенный (102 × 165 мм) модуль NVIDIA SXM2: «плиточка» с группами контактов на дне и радиатором на верхней крышке. 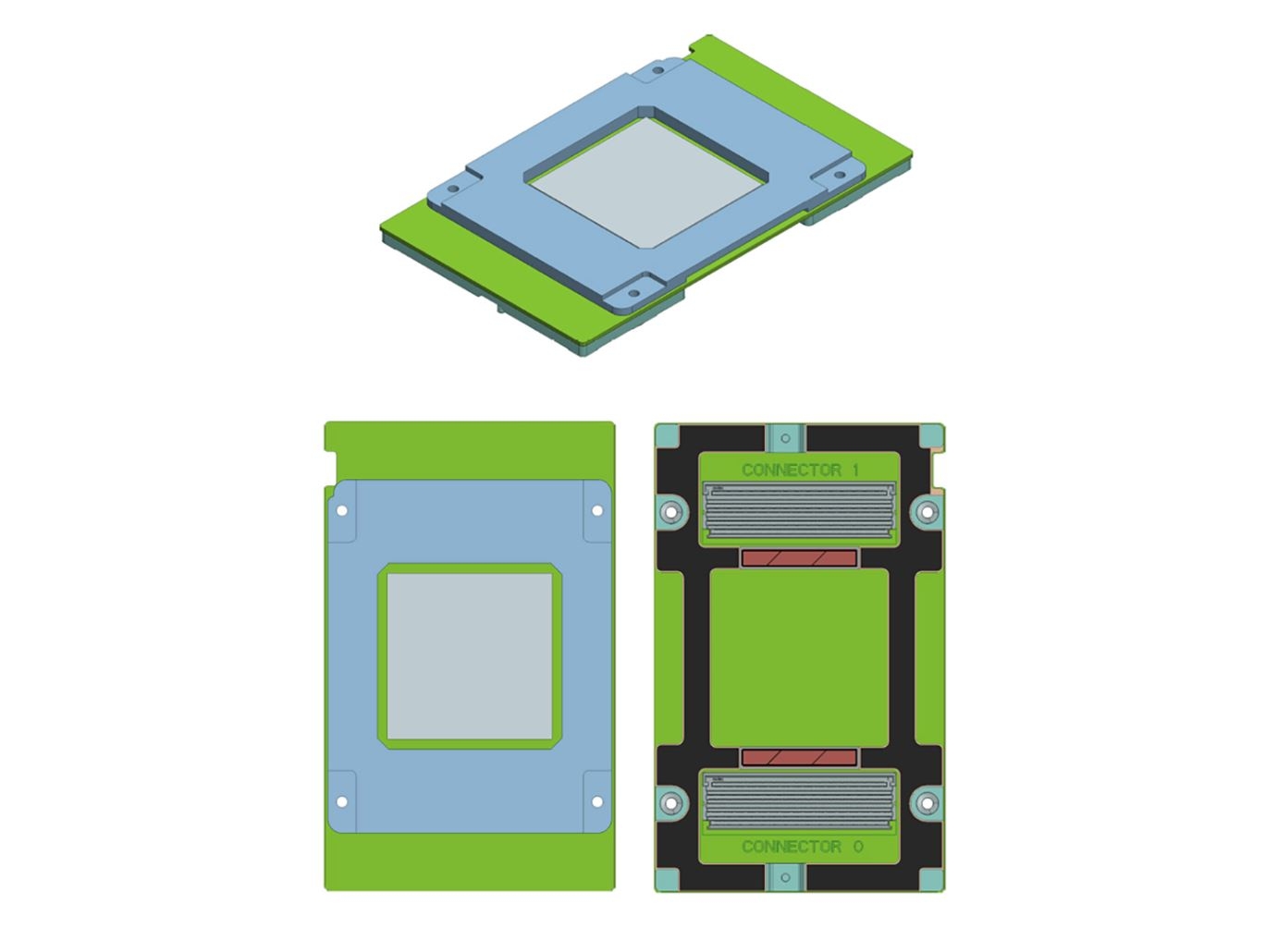 Ключевые спецификации модуля OAM:
 OAM, в отличие от классических карт PCI-E, позволяет повысить плотнсть размещения ускорителей в системе без ущерба их охлаждению, а также увеличить скорость обмена данными между модулями, благодаря легко настраиваемой топологии соединений между ними. В числе поддержавших проект OCP Accelerator Module такие компании, как Intel, AMD, NVIDIA, Google,Microsoft, Baidu и Huawei. 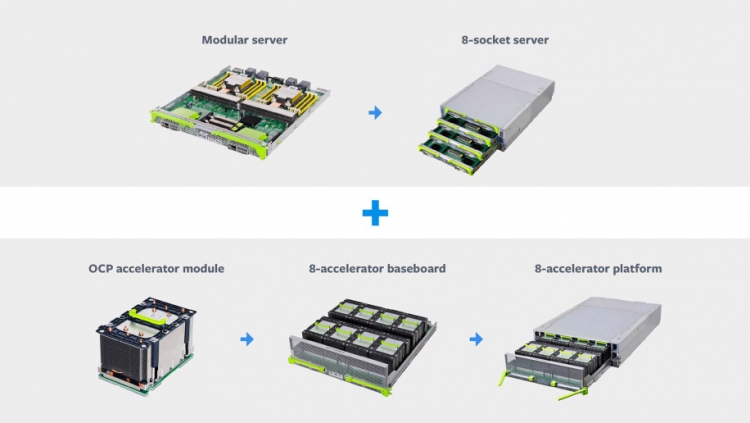 Inspur приступил к разработке референс-системы для ускорителей OAM в связи растущими требованиями, предъявляемыми к приложениям ИИ и необходимостью обеспечения взаимодействия между несколькими модулями на основе ASIC или GPU. Данная платформа представляет собой 21" шасси стандарта Open Rack V2 с BBU для восьми модулей OAM. Плата BBU снабжена восемью коннекторами QSFP-DD для прямого подключения к другим BBU. Система Inspur OAM позволяет создавать кластеры из 16, 32, 64 и 128 модулей OAM и имеет гибкую архитектуру для поддержки инфраструктур с несколькими хостами. По требованию заказчика Inspur также может поставлять 19-дюймовые системы OAM. Одной из первых преимущества новинки для задач, связанных с ИИ и машинным обучением, оценила китайская Baidu, продемонстрировавшая собственное серверное решение X-Man 4.0 на базе платформы Inspur и восьми ускорителей. 
22.09.2019 [21:27], Андрей Созинов
3 ядра, 2 гига: Aspeed выпустила BMC AST2600Компания Aspeed официально представила новый BMC под названием AST2600, который придёт на смену актуальному контроллеру AST2500. Новинка найдёт применение в серверах следующего поколения, которые появятся в 2020 году.  Предварительные данные о харакеристиках новинки, про которые мы уже писали, подтвердились. В основе 28-нм SoC Aspeed AST2600 лежат три ядра с архитектурой ARM: два основных Cortex A7 и одно вспомогательное Cortex M3. Контроллер позволяет использовать до 2 Гбайт RAM DDR4. 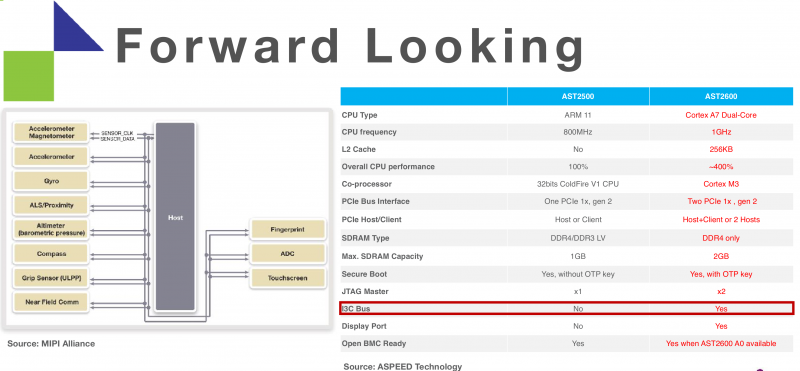 BMC поддерживает технологии TrustZone и Secure Boot, которые призваны повысить безопасность. Также он обладает поддержкой до четырёх гигабитных сетевых интерфейсов. Обычно, правда, используется не более одного интерфейса, который нужен для подключения к BMC. Однако дополнительные сетевые порты можно использовать, например, для мониторинга и других задач. 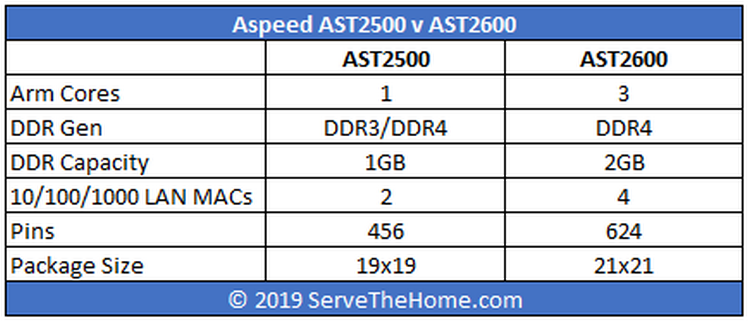 Дополнительные возможности отразились на числе контактов — их теперь 624, что на 37 % больше по сравнению с предшественником — и, что важнее, на площади чипа, которая увеличилась до 441 мм 2. Соответственно, на материнской плате придётся отводить под BMC больше места.
19.09.2019 [21:46], Андрей Созинов
Atos BullSequana XH2000 на процессорах EPYC 7H12 установила ряд мировых рекордовНовая версия суперкомпьютерного узла BullSequana XH2000 компании Atos, построенная на новейших 64-ядерных процессорах AMD EPYC 7H12, смогла установить сразу несколько абсолютных мировых рекордов производительности.  Новинка была протестирована самой Atos в пакете бенчмарков SPECrate 2017, который как раз и предназначен для оценки производительности мощных вычислительных систем. По результатам тестов, новинка претендует на звание рекордсмена среди всех двухпроцессорных систем в четырёх бенчмарках пакета: 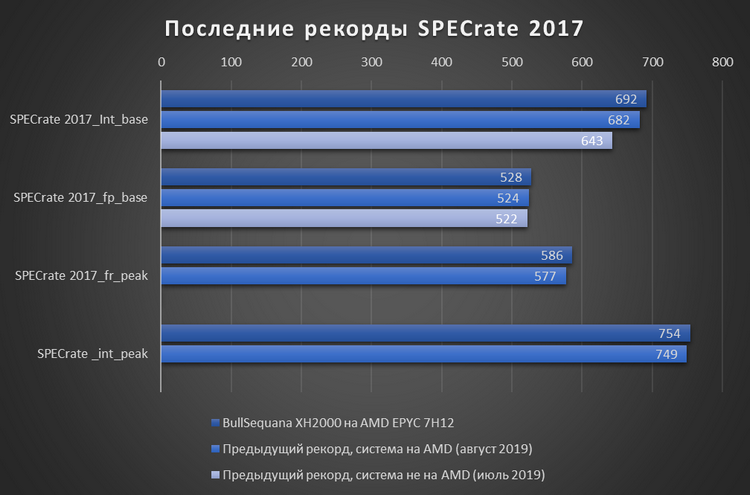 На данный момент представленные Atos результаты тестов проходят проверку комитетом SPEC. Кроме того, Atos заявляет, что система BullSequana XH2000 на базе EPYC 7H12 установила рекорд в бенчмарке HPL Linpack для систем на процессорах AMD. Новинка показала результат в 4,296 Тфлопс, что на 11 % больше результата системы с процессорами AMD EPYC 7742. 
Atos оставляет системы AMD для ряда европейских суперкомпьютеров Прирост производительности обусловлен тем, что средняя рабочая частота процессора EPYC 7H12 выше по сравнению с моделью EPYC 7742. А чтобы справиться с тепловыделением, увеличившимся вместе с частотой, компания Atos использует в BullSequana XH2000 систему жидкостного охлаждения.
18.09.2019 [19:50], Андрей Созинов
AMD представила EPYC 7H12: самый быстрый процессор семейства RomeСегодня в Риме компания AMD провела европейскую презентацию процессоров EPYC Rome (символично, не правда ли?), на которой неожиданно представила совершенно новый процессор — EPYC 7H12. Новинка отличается не только своим нестандартным названием, но и характеристиками, которые делают её самым мощным серверным процессором AMD на текущий момент. Процессор EPYC 7H12 обладает 64 ядрами, как и другие старшие модели семейства EPYC Rome. Базовая частота новинки составляет 2,6 ГГц, а максимальная Turbo-частота достигает 3,3 ГГц. Для сравнения — возглавлявший до этого семейство Rome процессор EPYC 7742 обладает значительно более низкой базовой частотой в 2,25 ГГц, а вот в режиме Turbo может разгоняться чуть выше — до 3,4 ГГц. Средняя же рабочая частота новинки будет выше. 
Источник изображения: AMD Базовая частота напрямую влияет на уровень TDP процессора. Поэтому показатель TDP EPYC 7H12 увеличился до 280 Вт, тогда как у EPYC 7742 он составлял 225 Вт. Из-за возросшего TDP новый процессор рекомендуется использовать в серверах с системами жидкостного охлаждения. Один из партнёров AMD, компания Atos, уже показала узел Bullsequana XH2000 с восемью процессорами EPYC 7H12 и полностью жидкостным охлаждением, высота которого составит лишь 1U. 
Источник изображения: Atos Кроме как частотами и уровнем TDP, процессоры EPYC 7H12 и EPYC 7742 ничем не отличаются друг от друга. Оба имеют 64 ядра Zen 2, 128 вычислительных потоков, 256 Мбайт кеш-памяти третьего уровня, 128 линий PCIe 4.0 и контроллер памяти с восемью каналами и поддержкой DDR4-3200. 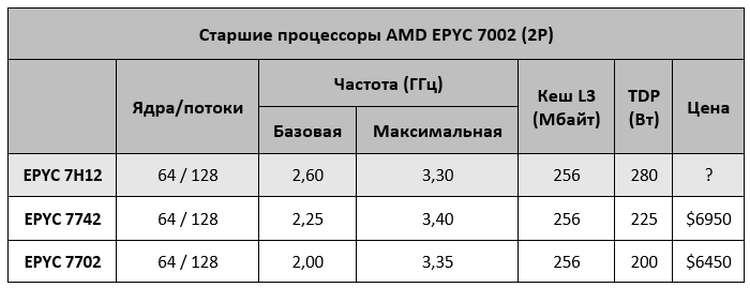 Процессор EPYC 7H12 ориентирован на использование в составе высокопроизводительных вычислительных систем и центрах обработки данных. Согласно синтетическому тесту Linpack, новый процессор обеспечивает прирост производительности до 11 % по сравнению с EPYC 7742, который мы протестировали в августе. Цена новинки пока не названа. Не исключено, что она будет заметно выше, чем у 7742. Всё-таки, это особый сегмент рынка, где даже за незначительный прирост производительности готовы платить. Аналогичную политику проводит и Intel. В семействе Xeon на базе Broadwell были модели с индексом A, которые отличались чуть более высокими частотами. А летом Intel представила процессор Xeon Platinum 8284, который в сравнении с базовой моделью 8280 также имеет повышенную частоту и возросший в полтора раза ценник.
27.08.2019 [11:00], Геннадий Детинич
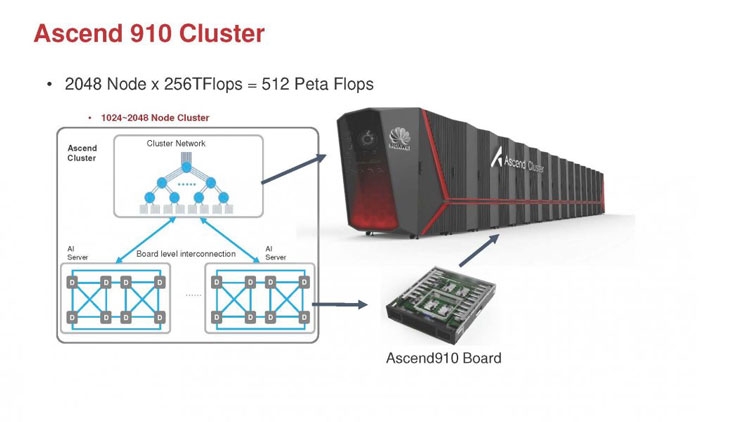
Huawei Ascend 910: китайская альтернатива ИИ-платформам NVIDIAГлубокое машинное обучение ― это сравнительно новая область приложения для вычислительных архитектур. Как всё новое, ML заставляет искать альтернативные пути решения задач. В этом поиске китайские разработчики оказались на равных и даже в привилегированных условиях, что привело к появлению в Китае мощнейших ИИ-платформ. Как всем уже известно, на конференции Hot Chips 31 компания Huawei представила самый мощный в мире ИИ-процессор Ascend 910. Процессоры для ИИ каждый разрабатывает во что горазд, но все разработчики сравнивают свои творения с ИИ-процессорами компании NVIDIA (а NVIDIA с процессорами Intel Xeon). Такова участь пионера. NVIDIA одной из первых широко начала продвигать свои модифицированные графические архитектуры в качестве ускорителей для решения задач с машинным обучением.  Гибкость GPU звездой взошла над косностью x86-совместимой архитектуры, но во время появления новых подходов и методов тренировки машинного обучения, где пока много открытых дорожек, она рискует стать одной из немногих. Компания Huawei со своими платформами вполне способна стать лучшей альтернативой решениям NVIDIA. Как минимум, это произойдёт в Китае, где Huawei готовится выпускать и надеется найти сбыт для миллионов процессоров для машинного обучения. 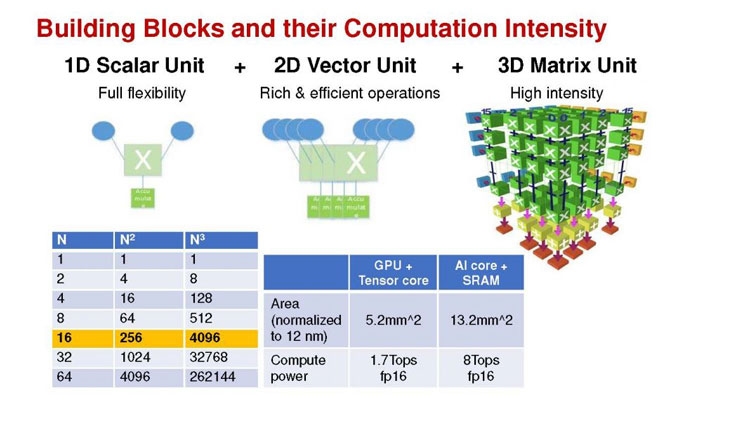 Мы уже публиковали анонс наиболее мощного ускорителя для ML чипа Huawei Ascend 910. Сейчас посмотрим на это решение чуть пристальнее. Итак, Ascend 910 выпускается компанией TSMC с использованием второго поколения 7-нм техпроцесса (7+ EUV). Это техпроцесс характеризуется использованием сканеров EUV для изготовления нескольких слоёв чипа. На конференции Huawei сравнивала Ascend 910 с ИИ-решением NVIDIA на архитектуре Volta, выпущенном TSMC с использованием 12-нм FinFET техпроцесса. Выше на картинке приводятся данные для Ascend 910 и Volta, с нормализацией к 12-нм техпроцессу. Площадь решения Huawei на кристалле в 2,5 раза больше, чем у NVIDIA, но при этом производительность Ascend 910 оказывается в 4,7 раза выше, чем у архитектуры Volta. 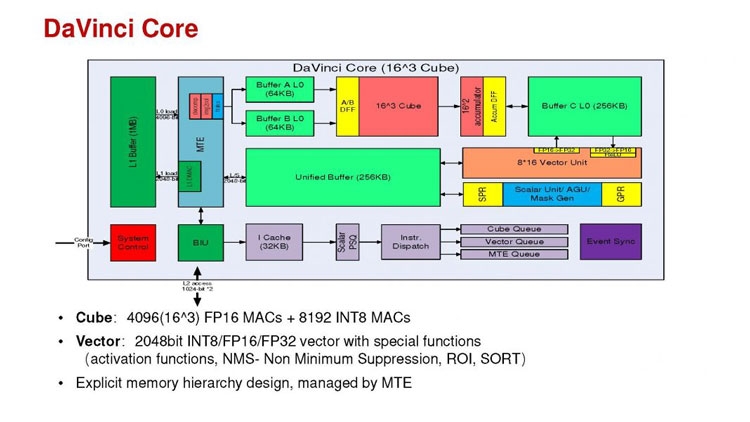 Также на схеме видно, что Huawei заявляет о крайне высокой масштабируемости архитектуры. Ядра DaVinci, лежащие в основе Ascend 910, могут выпускаться в конфигурации для оперирования скалярными величинами (16), векторными (16 × 16) и матричными (16 × 16 × 16). Это означает, что архитектура и ядра DaVinci появятся во всём спектре устройств от IoT и носимой электроники до суперкомпьютеров (от платформ с принятием решений до машинного обучения). Чип Ascend 910 несёт матричные ядра, как предназначенный для наиболее интенсивной работы. 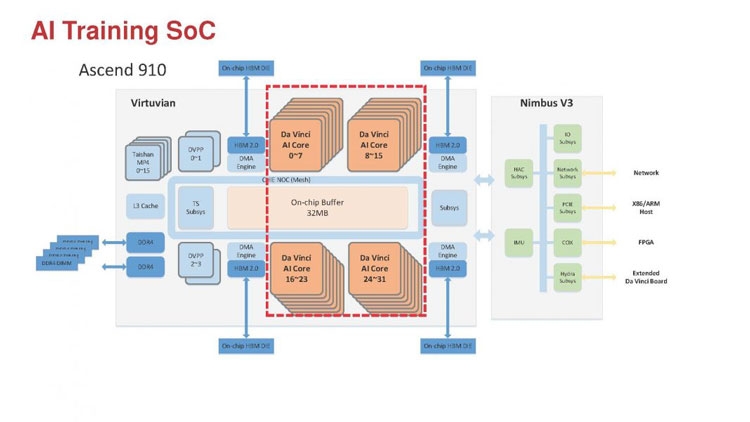 Ядро DaVinci в максимальной конфигурации (для Ascend 910) содержит 4096 блоков Cube для вычислений с половинной точностью (FP16). Также в ядро входят специализированные блоки для обработки скалярных (INT8) и векторных величин. Пиковая производительность Ascend с 32 ядрами DaVinci достигает 256 терафлопс для FP16 и 512 терафлопс для целочисленных значений. Всё это при потреблении до 350 Вт. Альтернатива от NVIDIA на тензорных ядрах способна максимум на 125 терафлопс для FP16. Для решения задач ML чип Huawei оказывается в два раза производительнее. 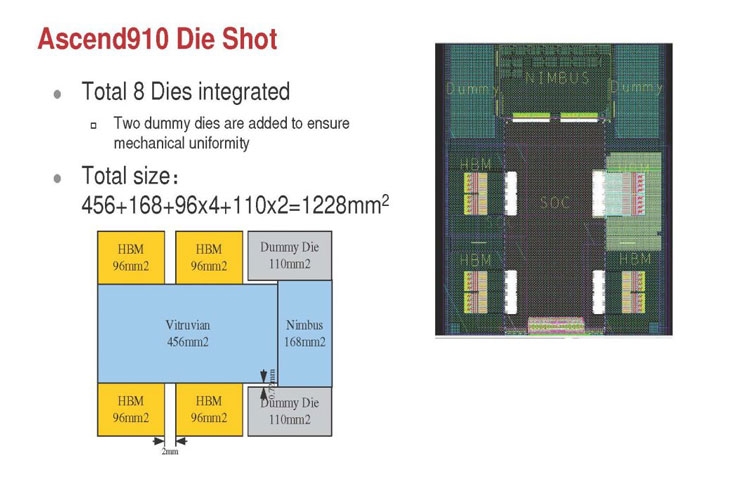 Помимо ядер DaVinci на кристалле Ascend 910 находятся несколько других блоков, включая контроллер памяти HBM2, 128-канальный движок для декодирования видеопотоков. Мощный чип для операций ввода/вывода Nimbus V3 выполнен на отдельном кристалле на той же подложке. Рядом с ним для механической прочности всей конструкции пришлось расположить два кристалла-заглушки, каждый из которых имеет площадь 110 мм2. С учётом болванок и четырёх чипов HBM2 площадь всех кристаллов достигает 1228 мм2. 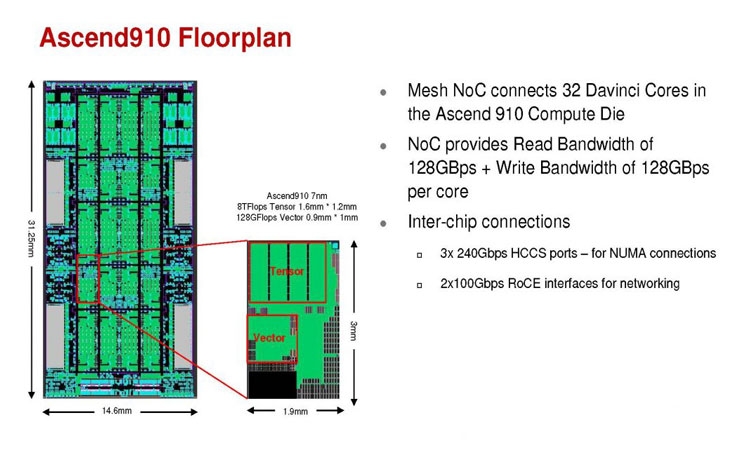 Для связи ядер и памяти на кристалле создана ячеистая сеть в конфигурации 6 строк на 4 колонки со скоростью доступа 128 Гбайт/с на каждое ядро для одновременных операций записи и чтения. Для соединения с соседними чипами предусмотрена шина со скоростью 720 Гбит/с и два линка RoCE со скоростью 100 Гбит/с. К кеш-памяти L2 ядра могут обращаться с производительностью до 4 Тбайт/с. Скорость доступа к памяти HBM2 достигает 1,2 Тбайт/с.  В каждый полочный корпус входят по 8 процессоров Ascend 910 и блок с двумя процессорами Intel Xeon Scalable. Спецификации полки ниже на картинке. Решения собираются в кластер из 2048 узлов суммарной производительностью 512 петафлопс для операций FP16. Кластеры NVIDIA DGX Superpod обещают производительность до 9,4 петафлопс для сборки из 96 узлов. В сравнении с предложением Huawei это выглядит бледно, но создаёт стимул рваться вперёд. 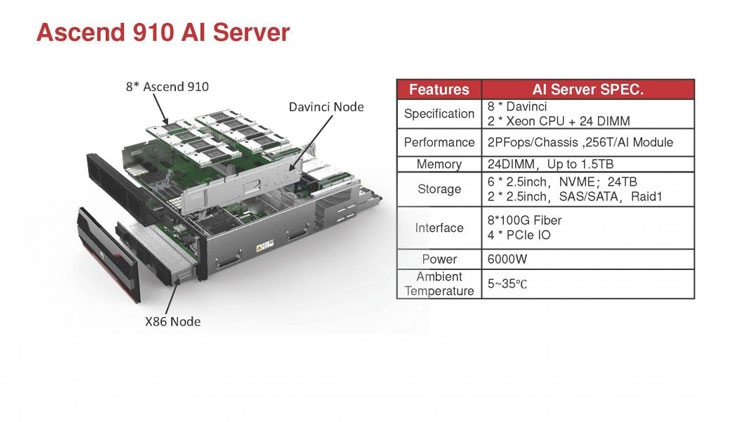
24.08.2019 [06:14], Андрей Галадей
IBM передала наработки по архитектуре Power сообществуКорпорация IBM сообщила, что переводит архитектуру набора команд (ISA) Power в разряд открытых решений. То есть, за неё не нужно будет платить, как это было в последние 6 лет. Отмечается, что с 2013 года действовал консорциум OpenPOWER, который лицензировал связанную с Power интеллектуальную собственность. Но теперь все наработки и патенты будут переданы сообществу безвозмездно. Сама же организация OpenPOWER Foundation будет переподчинена Linux Foundation, что позволит создать площадку для развития архитектуры без привязки к чипмейкеру или иной компании. Как отмечается, OpenPOWER Foundation включает в себя более 350 компаний, а сообществу передали свыше 3 млн строк кода системных прошивок, спецификаций и схем. Всё это позволит создавать Power-совместимые чипы всем желающим. 
pixabay.com Помимо собственно процессоров, компания передала сообществу и смежные технологии для разработки расширений на основе интерфейсов OpenCAPI (Open Coherent Accelerator Processor Interface) и OMI (Open Memory Interface). Первая технология должна устранить «узкие места» во взаимодействии CPU, GPU, ASIC, а также других чипов и контроллеров. Вторая же должна ускорить оперативную память. Это позволит создавать на базе архитектуры Power специализированные чипы для искусственного интеллекта. Важно отметить, что процессоры Power позволяют создавать современные серверы и суперкомпьютеры. К примеру, суперкомпьютеры Summit и Sierra работают как раз на таких чипах. А это, на минуточку, первый и второй номера в мировом рейтинге таких систем. Напомним, на процессорах с архитектурой Power (хотя и специализированных) работали в том числе и консоли Sony PlayStation 3, Xbox 360, а также старые ПК и ноутбуки Apple. |
|
