Лента новостей
|
03.04.2020 [13:37], Геннадий Детинич
Консорциумы CXL и Gen-Z объединяют усилия: протоколы станут совместимыми, а возможности расширятсяКонсорциумы CXL и Gen-Z сообщили, что их руководящие органы подписали договор о взаимопонимании. Пописанный меморандум раскрывает планы сотрудничества между двумя организациями, обещая совместимые протоколы и расширенные возможности каждого из представленных интерфейсов. Первые версии спецификаций Gen-Z и CXL (Compute Express Link) вышли, соответственно, в феврале 2018 года и в марте 2019 года. Каждый из этих интерфейсов призван обойти ограничения по пропускной способности, накладываемые на многоядерные и многоузловые конфигурации процессоров и ускорителей. Как один, так и другой интерфейс отвечают за согласованность кешей множества подключённых решений и обеспечивают минимальные задержки при доступе к вычислительным ресурсам и хранилищам данных на основе ОЗУ или долговременных накопителей. В то же время интерфейс CXL специализируется на согласованной работе внутри шасси, а интерфейс Gen-Z позволяет согласовывать работу на уровне блоков, стоек и массивов. В целом, участники консорциума Gen-Z поддержали идею Compute Express Link и признали её как дополняющую для развития интерфейса Gen-Z. В течение прошлого года в консорциум CXL, за организацией которого стоит компания Intel, вошли много компаний, включая AMD и ARM. Дело оставалось за малым ― объединить усилия и добиться совместимости протоколов и архитектур. Сегодня такой день настал. Консорциумы CXL и Gen-Z договорились организовать совместные смешанные рабочие группы для разработки «мостов» между протоколами обеих спецификаций и сделать всё необходимое, чтобы расширить возможности каждого из стандартов за счёт возможностей другого.
15.03.2020 [00:40], Андрей Крупин
Видео: как устроен дата-центр «Росэнергоатома» вблизи Калининской АЭСРоссийский энергетический концерн «Росэнергоатом» (входит состав госкорпорации «Росатом») разместил на своей странице в социальной сети «ВКонтакте» ролик, рассказывающий об особенностях работы центра обработки данных «Калининский», расположенного вблизи Калининской АЭС в Тверской области. Территориальная приближённость ЦОД «Калининский» к атомной электростанции обусловлена необходимостью обеспечения объекта надёжным источником электроснабжения.  Вычислительный комплекс «Калининский» был введён в эксплуатацию весной 2018 года и является первым дата-центром проекта «Менделеев» концерна «Росэнергоатом» по созданию сети центров обработки данных на площадках атомной отрасли РФ и за рубежом, соединённых высокоскоростными каналами связи в единую территориально распределённую катастрофоустойчивую информационную инфраструктуру. Дата-центр «Калининский» включает три здания с машинными залами общей площадью 38000 кв. метров и 4800 серверными стойками с проектной мощностью потребления электроэнергии от 6 кВт в расчёте на одну стойку. Подведённая мощность дата-центра составляет 48 МВт. Рядом с ЦОД развёрнута инфраструктурная площадка для размещения сторонними компаниями модульных и контейнерных центров обработки данных мощностью 32 МВт (проектом предполагается размещение до 30 модульных и контейнерных ЦОД по одному мегаватту каждый). Таким образом «Калининский» является одним из самых крупных дата-центров в России и позволяет разместить в машинных залах до 10 тысяч стоек с оборудованием суммарной мощностью до 80 МВт. В ближайших планах «Росэнергоатома» — строительство ЦОД в Сосновом Бору (Ленинградская область) и Иннополисе (Республика Татарстан).
24.02.2020 [17:00], Константин Ходаковский
Intel представила семейство процессоров Intel Xeon Cascade Lake RefreshВместе с серией продуктов для инфраструктуры сетей 5G, включающей систему на кристалле Atom P5900 для базовых станций, структурированную платформу ASIC Diamond Mesa для ускорения сетей 5G, серию сетевых контроллеров Ethernet 700 и программное решение OpenNESS для лёгкого развёртывания облачных периферийных микросервисов, корпорация Intel расширила и серию серверных процессоров Intel Xeon Scalable 2-го поколения.  Intel Xeon Scalable 2-го поколения являются основой платформенной инфраструктуры в центрах обработки данных. На сегодняшний день чипов Xeon Scalable продано в общей сложности более 30 миллионов. Появление этих процессоров позволило трансформировать ядро сети: сегодня на их долю приходится 50 % всех виртуализированных окружений по всему миру, а к 2023 году это число дополнительно увеличится.  Как мы уже сообщали, новая серия серверных процессоров Intel включает 18 моделей с более высокими частотами (до 4 ГГц в режиме Turbo Boost), увеличенным количеством ядер и объёмом кеша в различной комбинации этих параметров. Но главное изменение — это существенно сниженная стоимость. Например, Xeon Gold 6238R предложит 28 ядер и базовую частоту 2,2/4 ГГц, тогда как его предшественник в лице Xeon Gold 6238 использует 22 ядра с частотой 2,1/3,7 ГГц при одинаковой стоимости.  Флагманом семейства станет Xeon Gold 6258R с 28 ядрами, поддержкой Hyper-Threading, базовой частотой 2,7 ГГц и уровнем TDP не более 205 Вт. В обозначении моделей новых процессоров, как правило, присутствует литера «R», то есть Refresh. Серия оптимизированных ЦП для высочайшей производительности отдельных ядер теперь представляет собой такой перечень. Все процессоры поддерживают Intel Optane DC Persistent Memory (жирным помечены новые модели):
Серия ЦП, оптимизированных для производительности на Ватт, представляет собой такой перечень. Все процессоры Platinum и Gold поддерживают Intel Optane DC Persistent Memory, а остальные — нет (жирным помечены новые модели):
Также компания представила новый чип в семействе энергоэффективных, рассчитанных на долгий цикл процессоров, — Silver 4210T (10 ядер, 2,3/3,2 ГГц, 13,75 Мбайт, 95 Вт, $554). Как и старая 8-ядерная модель Silver 4209T, новая тоже не поддерживает Intel Optane DC Persistent Memory. И наконец для односокетных серверов, где принципиальную роль играет стоимость, представлена 16-ядерная модель Gold 6208U (2,9/3,9 ГГц, 22 Мбайт, 150 Вт, $989, поддержка Intel Optane DC Persistent Memory). Запуск новых моделей призван сделать предложения Intel более конкурентоспособными по сравнению с 7-нм чипами AMD EPYC Rome — неслучайно затронуты были наиболее ходовые процессоры. Самое производительное (и дорогое) семейство Xeon Platinum 9000 с количеством ядер от 32 до 56 обновлено не было. Повышение показателя цены/производительности — главный повод к запуску Cascade Lake R (снижение наблюдается кратное). В новой серии процессоры разделены между семействами Bronze, Silver и Gold. Неслучайно процессоров Platinum в ней нет: старшие модели, в том числе и 28-ядерный флагман, вошли в семейство Gold. Поэтому Intel законно поставила на «новинки» более низкие ценники. Ранее компания уже серьёзно пересмотрела свои серверные предложения. Она, по сути, отказалась от процессоров серии M, которые, в отличие от стандартных решений, ограниченных объёмом ОЗУ в 1,5 Тбайт, позволяют работать в системах с 2 Тбайт памяти. Клиентам, нуждающимся в таком объёме ОЗУ, теперь предлагается использовать процессоры класса выше — L, поддерживающие уже 4,5 Тбайт. Для этого компания уравняла цены моделей L с M. Впрочем, не все OEM-производители спешат обесценить свои запасы и задерживают снижение цен.  Помимо процессоров Intel также представила 17 обновлённых решений Select Solutions, в которых реализована поддержка этих новых продуктов для ускорения наиболее важных рабочих нагрузок у заказчиков. Ведущие отраслевые производители уже начинают поставки новых платформ на базе Intel Xeon 2-го поколения Refresh.
19.02.2020 [17:16], Алексей Степин
Calxeda: взлёт и падение первого разработчика серверных процессоров ARMАрхитектура ARM активно прокладывает себе путь в серверные системы и даже в суперкомпьютеры. Но судьба первой компании, рискнувшей сделать ставку на ARM, вовсе не так радужна. В 2011 году компания Calxeda опубликовала сведения о 32-бит серверном процессоре на базе ARM Cortex-A9. В 2020 году можно считать, последний гвоздь в крышку гроба этих CPU забит — в ядре Linux поддержка платформ Calxeda будет в ближайшее время прекращена. Но мы считаем, что те, кто первыми бросил вызов могуществу x86, заслуживают памяти.  Ещё первая разработка Calxeda, четырёхъядерный процессор ARM Cortex-A9, о котором мы писали в 2011 году, позволял создавать серверы формата 2U со 120 процессорами (480 ядер совокупно). Компания называла свою затею «первопроходческой инициативой» и планировала развернуть вокруг своих разработок целую экосистему — и спрос на такие решения был. 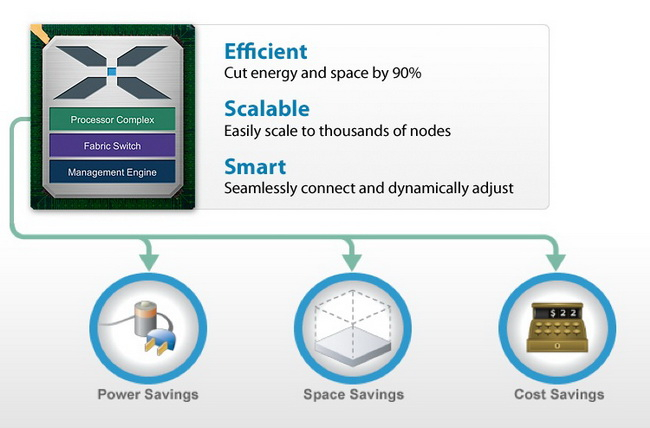
Преимущества платформы Calxeda по мнению компании: экономичность, компактность, низкая стоимость Проект поддержал солидный список из венчурных фондов и производителей полупроводников: ARM, Advanced Technology Investment Company, Battery Ventures, Flybridge Capital Partners и Highland Capital Partners, а первым ключевым партнёром для Calxeda стала Canonical — разработчик операционной системы Ubuntu. 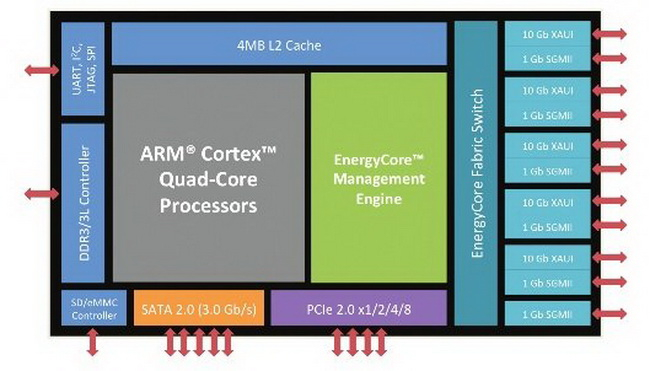
Архитектура первого серверного процессора Calxeda EnergyCore ECX-1000 К концу 2011 года проект оформился окончательно. CPU получил название EnergyCore, стали известны тактовые частоты (1,1 ‒ 1,4 ГГц) и другие подробности: наличие 4 Мбайт кеша L3, интегрированного коммутатора с производительностью 80 Гбит/с, отдельного ядра для управления энергопотребления. Энергопотребление одного узла на базе EnergyCore, в состав которого, помимо процессора, входило 4 Гбайт памяти и SSD-накопитель, могло составлять всего 5 ватт. Неудивительно, что разработкой заинтересовалась Hewlett-Packard, объявившая о намерении использовать EnergyCore в своих новых серверах. Говорилось о 4U-шасси, содержащих 288 чипов Calxeda EnergyCore. 
Эталонный дизайн вычислительного узла с четырьмя Calxeda EnergyCore К сожалению, в 2012 году было объявлено о том, что OEM-серверы на базе чипов Calxeda появятся только ближе к концу года. Но HP уже располагает такими системами под названием Redstone; они используются для разработки энергоэффективной серверной архитектуры в проекте Moonshot. 
Мини-кластер HP Redstone Осенью того же года Calxeda объявляет о выпуске новой платформы Midway. В ней используется более совершенная архитектура ARM Cortex-A15 с поддержкой аппаратных средств виртуализации. Опубликованы планы на 2014 год, в них фигурирует поддержка 64-битной архитектуры ARM v8. Наконец, на конференции Strata + HadoopWorld в Нью-Йорке компания Penguin Computing демонстрирует успешную работу Hadoop на платформе UDX1, построенной с использованием Calxeda EnergyCore. 
Типичный дизайн сервера на базе процессоров Calxeda. Производитель Boston, модель Viridis 2013 год. Intel не собирается уступать и в противовес Calxeda и AMD, работающими над созданием экономичных ARM-процессоров, выпускает первую систему на чипе на базе архитектуры Broadwell. К сожалению, это последний год деятельности Calxeda. Исчерпав резервы денежных средств, пионер на рынке ARM-серверов объявляет о прекращении своей работы. По мнению экспертов, причин краха две — компания слишком рано начала наступление на серверный рынок, ещё не готовый к пришествию ARM, а также сделала ставку на 32-битные процессоры в то время, как серверный рынок уже успел привыкнуть к 64-битным чипам, хотя бы потому, что они поддерживают большие объемы оперативной памяти. Кроме того, даже сама ARM относительно недавно, наконец, ввела спецификации ServerReady для упрощения внедрения в серверный сегмент. Крах Calxeda также негативно сказался на общее отношение к серверным ARM в индустрии, которая сама по себе всегда была консервативна. В частности, в разговоре на SC19 представитель одного из ведущих производителей серверов отметил, что неуспех первых ARM-платформ и фактически впустую потраченные средства надолго отпугнули корпорацию даже от экспериментов в этой области. 
Последние из могикан: вскоре для них не останется работы Уже выпущенные серверы с процессорами Calxeda ещё работают. Но дни их уже сочтены: на рынке серверных процессоров с архитектурой ARM появляются другие игроки, изначально сделавшие ставку на мощные 64-битные варианты. К 2020 году встретить сервер Calxeda в работе удаётся очень редко — и разработчики ядра Linux объявляют о том, что вскоре откажутся от поддержки инфраструктуры Calxeda. Будет также убрана поддержка KVM-виртуализации для всех 32-битных процессоров ARM. Это не первая история неуспеха ARM в серверном сегмента. Два крупнейших производителя SoC, Broadcom и Qualcomm, в итоге отказались от затеи. Наработки первой после долгих скитаний воплотились в ThunderX, а процессоры Centriq второй так толком и не увидели свет. Собственные CPU Marvell не снискали большой популярности, так что компания в итоге купила ThunderX. ThunderX 2 вместе с Fujitsu A64FX пока остаются единственными крупными игроками на этом рынке, если не считать ряда внутренних разработок вроде AWS Graviton, которые не предназначены для свободной продажи. Конкуренцию им в ближайшее время должны составить Ampere eMAG и Huawei KunPeng.
04.02.2020 [22:15], Алексей Степин
Спасибо AMD: для VMWare теперь потребуется оплачивать ядра, а не сокетыКрупнейший разработчик ПО для виртуализации, компания VMWare, приняла решение об изменении модели лицензирования своего программного обеспечения. Если ранее оплата рассчитывалась исходя из количества физических процессоров в системе, то теперь она будет взыматься с учётом количества ядер и даже однопроцессорные системы могут потребовать дополнительной лицензии. Причины довольно очевидны — если раньше на рынке доминировали серверные процессоры с количеством ядер не выше 24 ‒ 28, а 32-ядерные AMD EPYC появились сравнительно недавно, то теперь в арсенале той же AMD есть EPYC второго поколения с 48 и 64 ядрами, да и Intel Xeon 9200 (48 и 56 ядер) не стоит сбрасывать со счетов. При прежней модели лицензирования плата взималась за количество физических процессоров в системе. 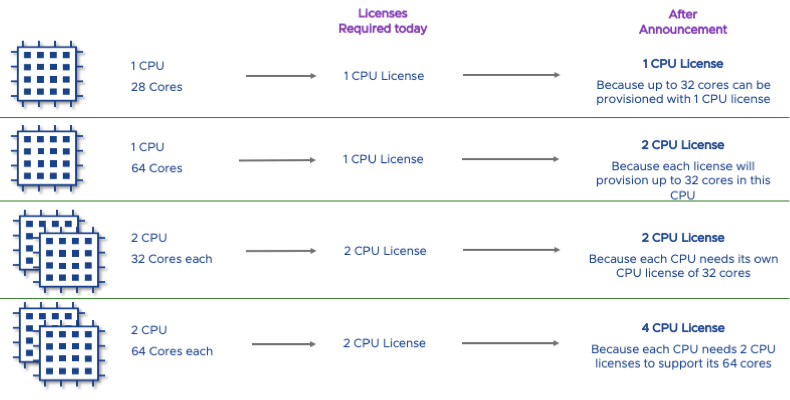
Особенно серьёзно потребуется потратиться владельцам систем с двумя 64-ядерными чипами (Источник: VMware) Разумеется, с появлением новых CPU клиенты VMWare стали активно пользоваться «лазейкой» в системе и применять «однопроцессорную» лицензию для 48- и 64-ядерных односокетных машин. Однако в свете того, что индустрия программного обеспечения активно переходит к лицензированию «по количеству ядер», VMWare также решила изменить принципы ценообразования. 
Такое лезвие на базе двух Xeon 9200 тоже потребует четыре лицензии VMWare Теперь однопроцессорные системы на базе процессоров с количеством ядер более 32 потребуют приобретения дополнительной лицензии, как если бы речь шла о системах с двумя физическими ЦП. Владельцы приобретённых до 30 апреля 2020 года лицензий смогут получить вторую лицензию бесплатно, но при условии, что они заключили с VMWare контракт на поддержку и обслуживание. Тем не менее, смена модели лицензирования уже вызвала недовольство тех, кто уже воспользовался или только планировал воспользоваться преимуществами новых процессоров AMD и Intel.
02.12.2019 [14:58], Алексей Степин
NEC обновила серию ускорителей SX-Aurora и опубликовала планы относительно HPCКомпания NEC не спешит отказываться от своего уникального пути на рынке супервычислений и продолжает развивать серию векторных процессоров SX-Aurora. На конференции SC19 компания представила ряд новых решений, сочетающих в себе SX-Aurora и новейшие процессоры AMD «Rome» Intel Xeon 9200. 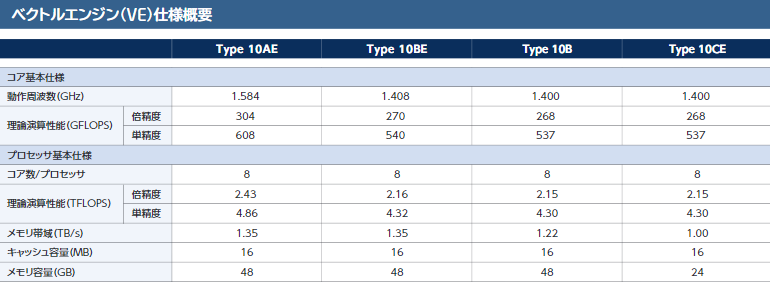
Типы ускорителей SX-Aurora Как и два года назад, основой платформы NEC является плата расширения «Type 10»; впрочем, в настоящее время производитель заменяет его на усовершенствованный «Type 10E» с более быстрыми сборками HBM2 на борту. За счёт этого ПСП удалось поднять на 10%, и даже в самом доступном варианте «Type 10CE» данный параметр теперь составляет 1 Тбайт/с против ранних 750 Гбайт/с. 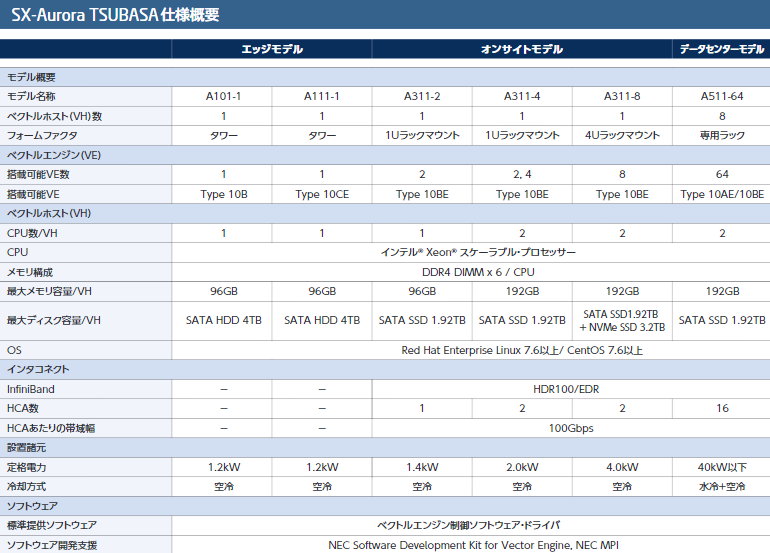
Системы NEC на базе SX-Aurora Массовый выпуск плат NEC «Type 10E» намечен на январь 2020 года. Всего в семействе будет четыре модели, отличающиеся тактовыми частотами, объёмом HBM2 и системой охлаждения. Последняя будет представлена в воздушном активном и пассивном вариантах, также будет выпускаться и вариант с жидкостным охлаждением. 
Сервер NEC A412-8 сочетает в себе SX-Aurora и AMD Rome Компания не собирается останавливаться на достигнутом и чип текущего поколения VE10 будет заменён на VE20 уже в середине или конце 2020 года. Он получит ещё более быструю память, больше векторных ядер (возможно 10 против 8 сегодняшних) и неизвестные пока новые функции. Следующее за ним поколение, VE30, должно появиться в 2022 году. Об этом поколении данных пока нет — известно лишь, что эти процессоры будут иметь новую архитектуру. 
25.11.2019 [16:29], Андрей Созинов
SC19: TMGcore OTTO — автономный роботизированный микро-ЦОД с иммерсионной СЖОКомпания TMGcore представила в рамках прошедшей конференции SC19 свою весьма необычную систему OTTO. Новинка является модульной платформой для создания автономных ЦОД, которая характеризуется высокой плотностью размещения аппаратного обеспечения, использует двухфазную иммерсионную систему жидкостного охлаждения, а также обладает роботизированной системой замены серверов. 
Версия OTTO на 600 кВт Первое, что отмечает производитель в системе OTTO — это высокая плотность размещения аппаратного обеспечения. Система состоит из довольно компактных серверов, которые размещены в резервуаре с охлаждающей жидкость. Собственно, использование двухфазной иммерсионной системы жидкостного охлаждения и позволяет размещать «железо» с максимальной плотностью. 
Версия OTTO на 60 кВт Всего OTTO будет доступна в трёх вариантах, рассчитанных на 60, 120 и 600 кВт. Системы состоят из одного или нескольких резервуаров для размещения серверов. Один такой резервуар имеет 12 слотов высотой 1U, в десяти из которых располагаются сервера, а ещё в двух — блоки питания. Также каждый резервуар снабжён шиной питания с рабочей мощностью 60 кВт. Отметим, что площадь, занимаемая самой большой 600-кВт системой OTTO составляет всего 14,9 м2. В состав системы OTTO могут входить как эталонные серверы HydroBlades от самой TMGcore, так и решения от других производителей, прошедшие сертификацию «OTTO Ready». В последнем случае серверы должны использовать корпуса и компоновку, которые позволяют использовать их в иммерсионной системе охлаждения. Например, таким сервером является Dell EMC PowerEdge C4140.  В рамках конференции SC19 был продемонстрирован и фирменный сервер OTTOblade G1611. При высоте всего 1U он включает два процессора Intel Xeon Scalable, до 16 графических процессоров NVIDIA V100, до 1,5 Тбайт оперативной памяти и два 10- или 100-гигабитных интерфейса Ethernet либо одиночный InfiniBand 100G. Такой сервер обладает производительность в 2000 Тфлопс при вычислениях на тензорных ядрах.  Мощность описанной абзацем выше машины составляет 6 кВт, то есть в системе OTTO может работать от 10 до 100 таких машин. И охладить столь компактную и мощную систему способна только двухфазная погружная система жидкостного охлаждения. Он состоит из резервуара, заполненного охлаждающей жидкостью от 3M и Solvay, и теплообменника для конденсации испарившейся жидкости.  Для замены неисправных серверов система OTTO оснащена роботизированной рукой, которая способна производить замены в полностью автоматическом режиме. В корпусе OTTO имеется специальный отсек с резервными серверами, а также отсек для неисправных систем. Такой подход позволяет производить замену серверов без остановки всей системы, и позволяет избежать контакта человека с СЖО во время работы.  Изначально TMGcore специализировалась на системах для майнинга с иммерсионным охлаждением, а после перенесла свои разработки на обычные системы. Поэтому, в частности, описанный выше OTTOblade G1611 с натяжкой можно отнести к HPC-решениям, так как у него довольно слабый интерконнект, не слишком хорошо подходящий для решения классических задач. Впрочем, если рассматривать OTTO как именно автономный или пограничный (edge) микро-ЦОД, то решение имеет право на жизнь.
21.11.2019 [13:11], Алексей Степин
SC19: СЖО Chilldyne Cool-Flo для ЦОД исключает протечкиВыгоды от использования жидкостного охлаждения очевидны. Оно открывает путь к более плотному размещению вычислительных узлов, и сама эффективность охлаждения существенно выше. Но существуют у таких систем и серьезные недостатки. Главной опасностью систем СЖО является возможность протечки теплоносителя. Такой сценарий может вывести из строя весьма дорогостоящее оборудование. Компания Chilldyne утверждает, что данную проблему ей удалось решить, и демонстрирует на SC19 систему охлаждения Cool-Flo с «отрицательным давлением». 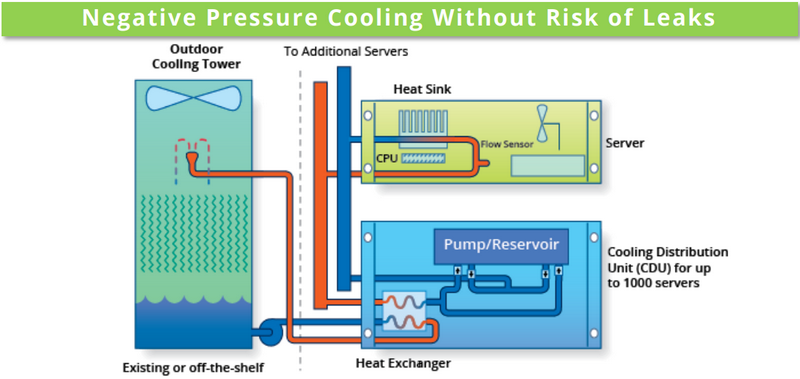
Принципиальная схема Chilldyne Cool-Flo. Обратите внимание на направление движения жидкости Главный принцип можно сравнить с вентилятором, работающим не на обдув, а на откачку воздуха из корпуса системы. Если в классическом контуре СЖО насосы нагнетают холодную жидкость в водоблоки, то насосы Cool-Flo, напротив, откачивают горячую. Если герметичность контура будет нарушена, то произойдёт не классический «залив» системной платы, а наоборот, вся жидкость будет выкачана, и вслед за ней в систему попадет воздух. 
Модуль распределения теплоносителя (CDU) Cool-Flo В таком сценарии возможен простой, но не повреждение драгоценного оборудования, поскольку контакт с жидкостью практически исключён. К тому же, сама вероятность разгерметизации серьёзно уменьшена из-за «отрицательного давления», снижающего механическую нагрузку на элементы контура. Давление в нем составляет менее 1 атмосферы, что исключает выдавливание жидкости наружу. 
Двухпроцессорное лезвие Xeon Scalable с водоблоками Cool-Flo Из прочих преимуществ системы Cool-Flo можно назвать низкую стоимость развёртывания и совместимость с существующей инфраструктурой воздушного охлаждения. Серьёзные монтажные работы с привлечением сторонних специалистов требуются только для установки CDU (системы распределения теплоносителя) и внешней башни-градирни, а монтаж стоек и серверов может осуществляться техническим персоналом ЦОД. 
Комплект водоблоков Cool-Flo для процессоров Intel в исполнении LGA2011-3. Справа ‒ разъём No-Drip Технически же в качестве водоблоков Cool-Flo может использовать модернизированные радиаторы воздушного охлаждения ЦП либо версии с теплоотводной пластиной; последний вариант идеально подходит для плотного размещения ускорителей на базе GPU и других чипов с высоким уровнем тепловыделения. В первом случае вентиляторы серверов могут работать на пониженной скорости, создавая дополнительный обдув элементов системы. 
Графический ускоритель с дополнительной пластиной охлаждения. Ни одной протечки на более чем 6 тысяч плат На выставке SC19 Chilldyne продемонстрировала как OEM-комплекты для процессоров Xeon, так и варианты для ускорителей AMD Radeon и NVIDIA Tesla. Переделка сервера, по сути, заключается в установке водоблоков и специальной заглушки с фирменным разъёмом No-Drip, напоминающим двухконтактную силовую розетку и допускающим «горячее» подключение или отключение сервера от главного контура системы. 
Стойка с ускорителями, оснащённая системой Cool-Flo Система распределения теплоносителя Cool-Flo CDU300 выполнена в виде стандартного шкафа, имеющего на передней панели экран с сенсорным управлением. Она рассчитана на температуру жидкости в районе 15‒30 градусов и при разнице температур 15 градусов способна отвести 300 киловатт тепла. Производительность водяных насосов составляет 300 литров в минуту при давлении в главном контуре менее 0,5 атмосфер. 
Комплект Cool-Flo для Radeon Fury X. Охлаждается не только GPU, но и силовая часть Предусмотрена полная система мониторинга (включая контроль качества теплоносителя) и удалённого управления, один шкаф может обслуживать до шести контуров охлаждения. Имеется возможность резервирования: резервный модуль CDU находится в активном режиме, но потребляет минимум энергии, а при необходимости мгновенно включается в работу. Компания-разработчик считает, что при использовании Cool-Flo в ЦОД можно избавиться от так называемых «горячих рядов», снизить затраты на вентиляцию и кондиционирование воздуха практически до нуля и на 75% снизить мощность, потребляемую вентиляторами серверов. Chilldyne оценивает стоимость 1 мегаватта охлаждения в $580 тысяч, в то время как классическая воздушная реализация может обойтись более чем в $1,2 миллиона. За четыре года эксплуатации ЦОД, оснащённого системой Cool-Flo экономия может составить почти $100 тысяч, и это не считая вышеупомянутых сниженных затрат на оснащение. С учётом пониженного риска повреждения оборудования в результате возможных протечек выигрыш может быть даже более серьёзным.
19.11.2019 [00:29], Андрей Созинов
Ноябрьский TOP500: больше китайских систем и меньше американских, и первая система на AMD EPYC RomeУже традиционно в рамках конференции SC была опубликована свежая версия TOP500, рейтинга пятисот самых производительных суперкомпьютеров в мире.  В новой версии списка стало больше систем из Китая, и в то же время сократилось количество систем, расположенных в США. Значительно увеличилась общая производительность всех систем, однако десятка лидеров рейтинга изменений не претерпела. 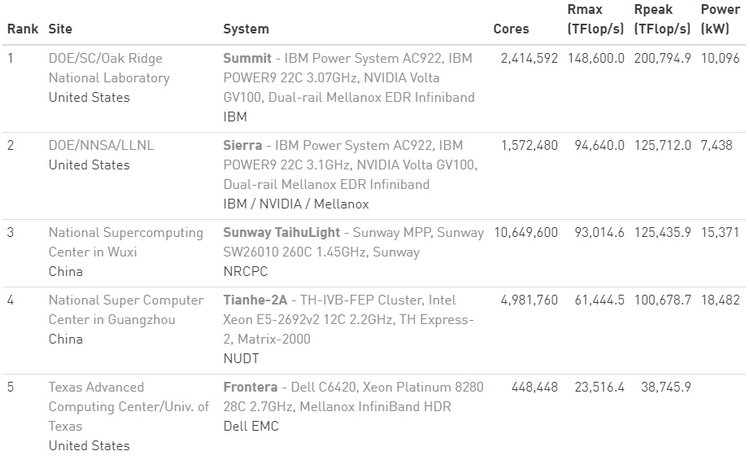 За последние шесть месяцев число китайских суперкомпьютеров в рейтинге TOP500 увеличилась с 219 до 228, и в итоге их доля составила 45,6 %. В то же время количество американских суперкомпьютеров достигло минимума в 117 систем, что составляет 23,4 %. Однако общая производительность систем из США выше — 37,1 % от общей, в то время как доля Китая здесь составляет 32,2 %. Суммарная производительность всех пятисот самых мощных суперкомпьютеров в мире составляет 1,65 Экзафлопс. Российских машин в рейтинге три. На 29 месте TOP500 теперь находится суперкомпьютер Кристофари, принадлежащий Сбербанку. 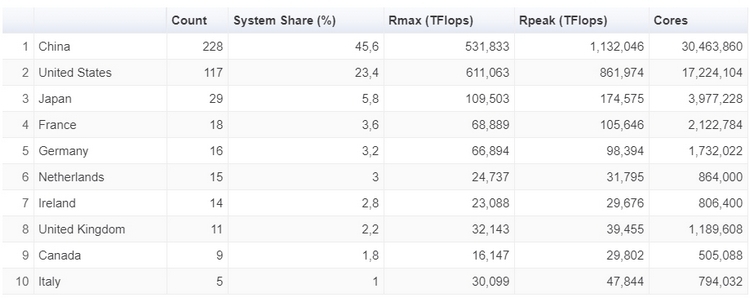 Количество систем, использующих ускорители вычислений и сопроцессоры также возросло, со 134 до 145. Большинство из них использует продукты на базе NVIDIA Volta, a также Pascal и Kepler. Что касается центральных процессоров, то здесь безоговорочным лидером остаётся Intel — 94,8 % систем из TOP500 построены на её чипах.  И здесь же хотелось бы отметить, что в свежем рейтинге TOP500 появилась первая система на процессорах AMD EPYC Rome. Это французский суперкомпьютер Joliot-Curie, построенный на платформе AtoS BullSequana XH2000, которая включает 64-ядерные процессоры AMD EPYC 7H12. Данный суперкомпьютер обладает производительностью 9,4 Пфлопс, он разместился на 59 строке рейтинга TOP500. Значительно увеличилась и минимальная производительность систем рейтинга TOP500. Теперь пятисотая система в рейтинге обладает производительностью в 1,142 Петафлопс. Полгода назад эта система располагалась на 399 месте. А чтобы претендовать на сотое место в рейтинге, системе теперь необходимо обладать производительностью более чем в 2,57 Пфлопс. 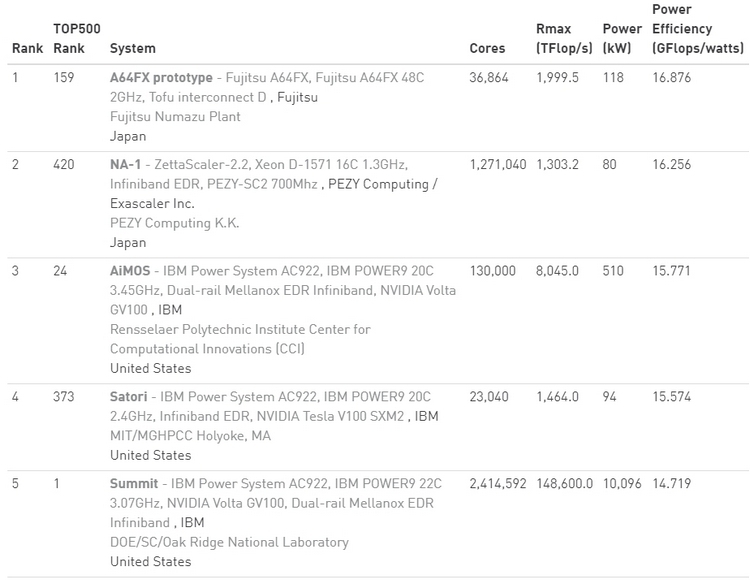 Рейтинг наиболее энергоэффективных систем — Green500 — возглавила японская система от Fujitsu. Это прототип суперкомпьютера на базе процессоров A64FX, который обеспечивает производительность в 16,9 Гфлопс на 1 ватт энергии. В общем рейтинге TOP500 данная система занимает 159 строку с общей производительностью в 2 Пфлопс. Интересно, что система обладает всего лишь 36 864 ядрами и не использует ускорители, что делает её результаты ещё более впечатляющими. Кстати, среднее количество ядер на систему из списка TOP500 также увеличилось — с 118 213 до 126 308.
04.11.2019 [21:00], Алексей Степин
IBM продвигает открытый стандарт оперативной DDIMM-памяти OMI для серверовПрактически у всех современных процессоров контроллер памяти давно и прочно является частью самого ЦП, будь то монолитный кристалл или чиплетная сборка. Но не всегда подобная монолитность является плюсом — к примеру, она усложняет задачу увеличения количества каналов доступа к памяти. Таких каналов уже 8 и существуют проекты процессоров с 10 каналами памяти. Но это усложняет как сами ЦП, так и системные платы, ведь только на подсистему памяти, без учёта интерфейса PCI Express, может уйти 300 и более контактов, которые ещё требуется корректно развести и подключить. 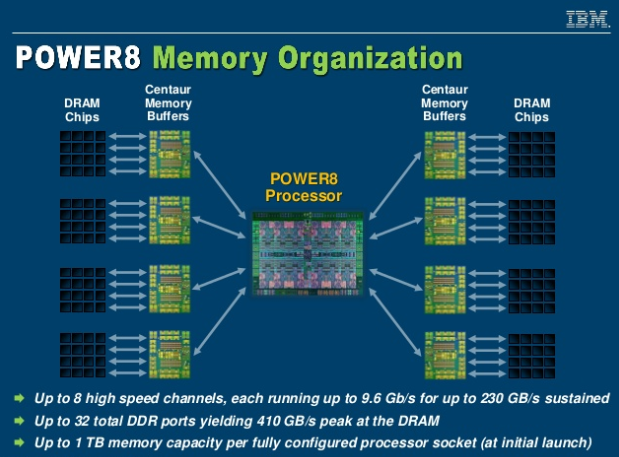
Организация подсистемы памяти у POWER8 У IBM есть ответ, и заключается он в переносе части функций контроллера памяти на сторону модулей DIMM. Сам интерфейс между ЦП и модулями памяти становится последовательным и предельно унифицированным. Похожая схема использовалась в стандарте FB-DIMM, аналогичную компоновку применила и сама IBM в процессорах POWER8 и POWER9 в варианте Scale-Up. 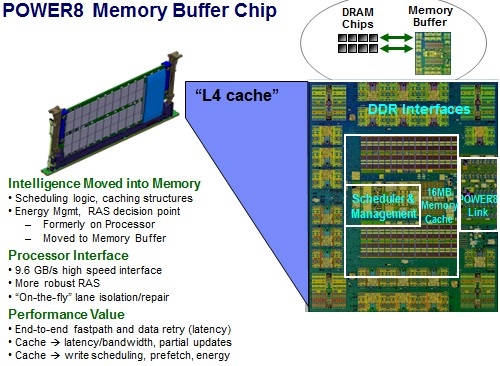
Роль и возможности буфера Centaur у POWER8 Контроллер памяти у этих процессоров упрощён, в нём отсутствует контроллер физического уровня (PHY). Его задачи возложены на чип-буфер Centaur, который посредством одноимённого последовательного интерфейса и связывается с процессором на скорости 28,8 Гбайт/с. Контроллеров интерфейса Centaur в процессорах IBM целых восемь, что дает ПСП в районе 230 Гбайт/с. За счёт выноса ряда функций в чипы-буфера удалось сократить площадь кристалла, и без того немалую (свыше 700 мм2), но за это пришлось заплатить увеличением задержек в среднем на 10 нс. Частично это сглажено за счёт наличия в составе Centaur кеша L4. 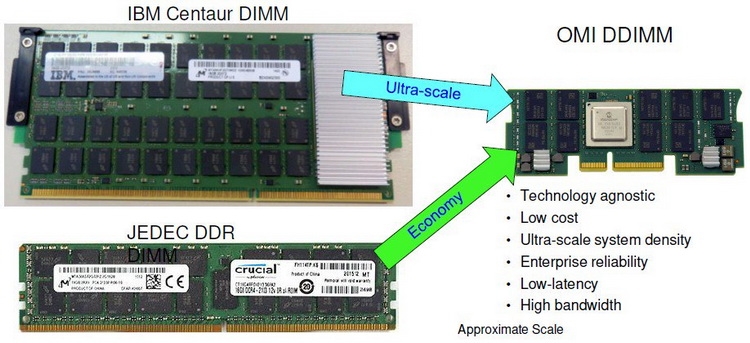
Сравнительные размеры модулей Centaur, RDIMM и OMI DDIMM Стандарт не является открытым, но IBM предлагает ему на смену полностью открытый вариант под названием Open Memory Interface (OMI). В его основу положена семантика и протоколы, описанные в стандарте OpenCAPI 3.1, а физический уровень представлен шиной BlueLink (25 Гбит/с на линию), которая уже используется для реализации NVLink и OpenCAPI. Реализация OMI проще Centaur, что позволяет сделать чип-буфер более компактным и выделяющим меньше тепла. Но все преимущества сохраняются: так, число контактов процессора, отвечающих за интерфейс памяти, можно снизить с примерно 300 до 75, поскольку посылаются только простые команды загрузки и сохранения данных. Вся реализация физического интерфейса осуществляется силами чипа-компаньона OMI, и в нём же может находиться дополнительный кеш. 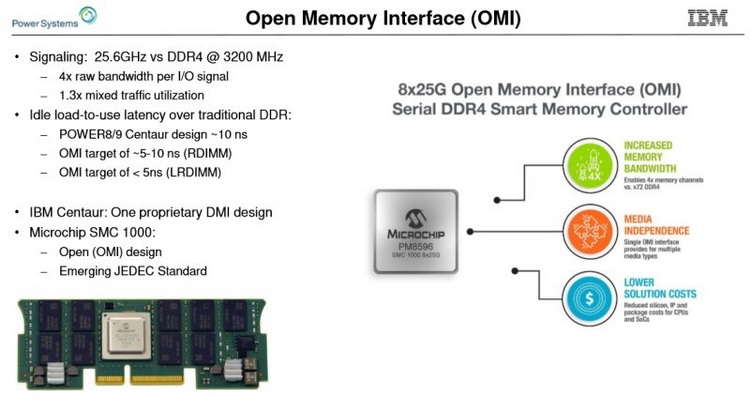
Модули OMI DDIMM станут стандартом JEDEC Помимо экономии контактов есть и ещё одна выгода: можно реализовать любой тип памяти, будь то DDR, GDDR и даже NVDIMM — вся PHY-часть придётся на различные варианты чипов OMI, но со стороны стандартного разъёма любой модуль OMI будет выглядеть одинаково. Сейчас взят прицел на реализацию модулей с памятью DDR5. При использовании существующих чипов DDR4 система с интерфейсом OMI может достичь совокупной ПСП порядка 650 Гбайт/с. Дополнительные задержки составят 5 ‒ 10 нс для RDIMM и лишь 4 нс для LRDIMM. Из всех соперников технологии на такое способны только сборки HBM, которые в силу своей природы имеют ограниченную ёмкость, дороги в реализации и не могут быть вынесены с общей с ЦП подложки. 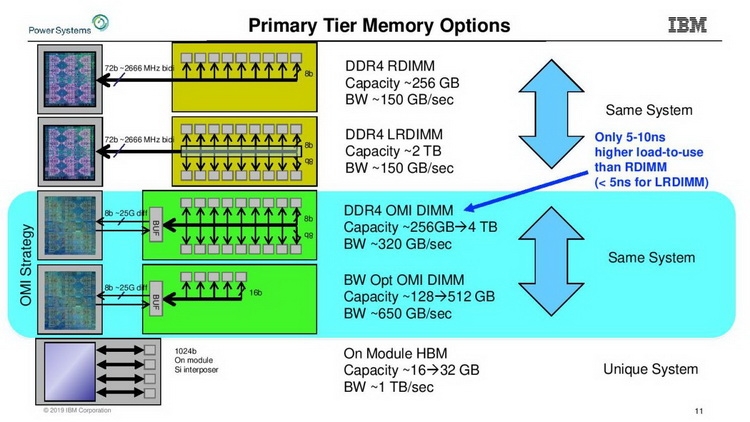
Новый стандарт упростит процессоры и позволит увеличить ёмкость подсистемы памяти Чипы-буферы OMI можно разместить как на модуле памяти, так и на системной плате. Разумеется, для стандартизации выбран первый вариант. В нём предусмотрено 84 контакта на модуль, сами же модули получили название Dual-Inline Memory Module (DDIMM). DDIMM вышли существенно компактнее своих традиционных собратьев: ширина модуля сократилась со 133 до 85 мм. Реализация буфера OMI ↔ DDR4 уже существует в кремнии: компания Microsemi продемонстрировала чип SMC 1000 (PM8596), поддерживающего 8 линий OMI со скоростью 25 Гбит/с каждая. Допустима также работа в режиме 4 × 1 с вдвое меньшей общей пропускной способностью. 
DDIMM: меньше ширина, проще разъём Со стороны чипов памяти SMC 1000 имеет стандартный 72-битный интерфейс с ECC и поддержкой различных комбинаций DRAM и NAND-устройств. Тактовая частота DRAM — до 3,2 ГГц, высота модуля зависит от количества и типов устанавливаемых чипов. В случае одиночной высоты модули могут иметь ёмкость до 128 Гбайт, двойная высота позволит создать DDIMM объёмом свыше 256 Гбайт. Сам чип SMC 1000 невелик, всего 17 × 17 мм, а невысокое тепловыделение гарантирует отсутствие проблем с перегревом, свойственных FB-DIMM. 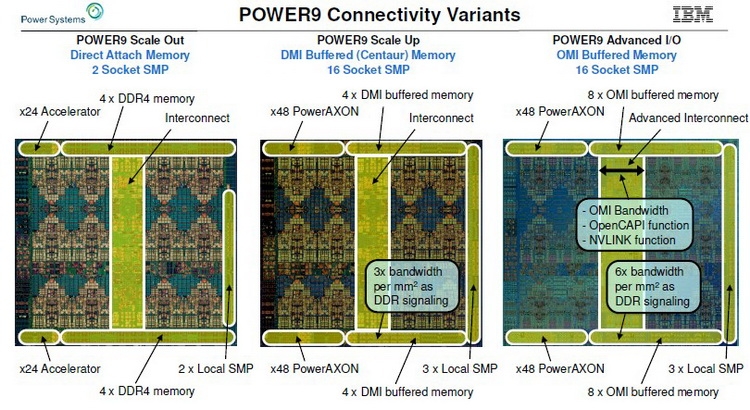
Процессоры IBM POWER9 AIO дополнили существующую серию Первыми процессорами с поддержкой OMI стали новые POWER9 версии Advanced I/O (AIO), дополнившие семейства Scale Up (SC) и Scale Out (SO). В них реализовано 16 каналов OMI по 8 линий каждый (до 650 Гбайт/с суммарно), а также новые версии интерфейсов NVLink (возможно, 3.0) и OpenCAPI 4.0. Количество линий PCI Express 4.0 по-прежнему составляет 48. Шина IBM BlueLink была переименована в PowerAXON. За счёт её использования в системах на базе процессоров POWER возможна реализация 16-сокетных систем без применения дополнительной логики. Максимальное количество ядер у POWER9 AIO равно 24, с учётом SMT4 это даёт 96 исполняемых потоков. Имеется также кеш L3 типа eDRAM объёмом 120 Мбайт. Техпроцесс остался прежним, это 14-нм FinFET. 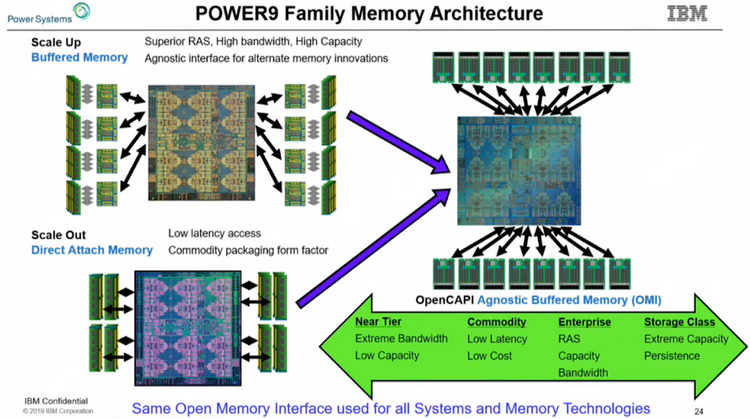
Архитектура подсистем памяти у семейства IBM POWER9 Поставки POWER9 AIO начнутся в этом году, цены неизвестны, но с учётом 8 миллиардов транзисторов и кристалла площадью 728 мм2 они не могут быть низкими. Однако без OMI эти процессоры были бы ещё более дорогими. В комплект поставки входит и чип-буфер OMI, правда, не самая быстрая версия с пропускной способностью на уровне 410 Гбайт/с. Задел для модернизации есть, и для расширения ПСП достаточно будет заменить модули DDIMM на более быстрые варианты. 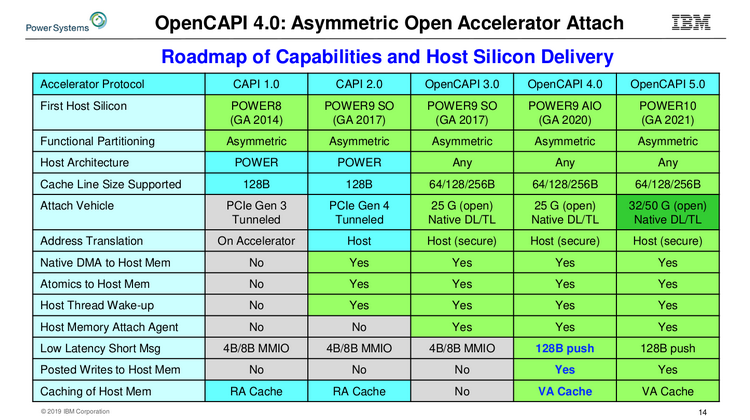
Сравнительная таблица существующих и будущих версий OpenCAPI Следующее поколение процессоров IBM, POWER10, появится только в 2021 году. К этому времени ожидается принятие стандарта OMI на рынке высокопроизводительных многопроцессорных систем. Попутно IBM готовит новые версии OpenCAPI, не привязанные к архитектуре POWER, а значит, путь к OMI будет открыт и другим вендорам. |
|