Материалы по тегу: компьютер
|
15.04.2021 [01:31], Владимир Мироненко
TSMC остановит выпуск Arm-процессоров Phytium — судьба китайского экзафлопсного суперкомпьютера Tianhe-3 под вопросомТайваньская компания Taiwan Semiconductor Manufacturing Company (TSMC) приостановила поставку чипов по новым заказам китайской компании Phytium, которая на прошлой неделе была добавлена властями США в «чёрный» список Министерства торговли. Внесение компаний в этот перечень означает запрет для американских компаний на работу с ними и предоставление продуктов или услуг без получения соответствующих лицензий. Иностранные компании, такие как TSMC, теоретически могут продолжать работать с компаниями из «чёрного списка», но США могут оказывать на них давление через их американских поставщиков. Например, когда США занесли Huawei в «чёрный» список, TSMC была вынуждена отказаться от сотрудничества с ней, поскольку многие ключевые технологии, лежащие в основе её производственных процессов, были разработаны американскими фирмами. Пока неясно, оказывалось ли сейчас подобное давление на TSMC, и были ли ею прекращены поставки остальным шести суперкомпьютерным китайским фирмам из «чёрного» списка. Как сообщает South China Morning Post, TSMC выполнит заказы, размещённые Phytium до внесения в «чёрный список», но больше поставлять ей чипы не будет. 
Прототип Tianhe-3. Фото: Xinhua Предполагается, что Phytium стоит за развёртыванием систем высокопроизводительных вычислений для китайского военно-промышленного комплекса, использующего её разработки при создании гиперзвуковых ракет. Компания сотрудничает с Оборонным научно-техническим университетом Народно-освободительной армии Китая (NUDT), который ранее создал суперкомпьютеры Tianhe-1 и Tianhe-2, в своё время занимавшие первые строчки рейтинга TOP500. Tianhe-3, один из трёх проектов китайских суперкомпьютеров экзафлопсного класса, должен был быть закончен в прошлом году, однако осенью было объявлено, что из-за пандемии коронавируса сроки сдвигаются. Летом 2020 года в распоряжении исследователей уже был прототип новой машины, имевший теоретическую производительность 3,146 Пфлопс. Он включал 512 плат с тремя процессорами Phytium MT2000+ и 128 плат с четырьмя Phytium FT2000+. Точные параметры этих 7-нм Arm-чипов не приводятся, но в одной из свежих научных публикаций упоминается, что на каждый 64-ядерный FT2000+ в прототипе Tianhe-3 приходилось 64 Гбайт RAM. А каждый MT2000+ можно поделить на четыре NUMA-узла с 32 ядрами и 16 Гбайт RAM, то есть, судя по описанию, это 128-ядерный чип, о котором ранее ничего не было известно. Теперь же судьба этих CPU и суперкомпьютера Tianhe-3 и вовсе под вопросом.
22.06.2020 [18:20], Игорь Осколков
ARM-суперкомпьютер Fugaku поднялся на вершину рейтингов TOP500, HPCG и HPL-AIКонечно же, речь идёт о японском суперкомпьютере Fugaku на базе ARM-процессоров A64FX, который досрочно начал трудиться весной этого года. Эта машина стала самым мощным суперкомпьютером в мире сразу в трёх рейтингах: классическом TOP500, современном HPCG и специализированном HPL-AI.  Суперкомпьютер состоит из 158976 узлов, которые имеют почти 7,3 млн процессорных ядер, обеспечивающих реальную производительность на уровне 415,5 Пфлопс, то есть Fugaku почти в два с половиной раза быстрее лидера предыдущего рейтинга, машины Summit. Правда, оказалось, что с точки зрения энергоэффективности новая ARM-система мало чем отличается от связки обычного процессора и GPU, которой пользуется большая часть суперкомпьютеров. Так что на первое место в Green500 она не попала. 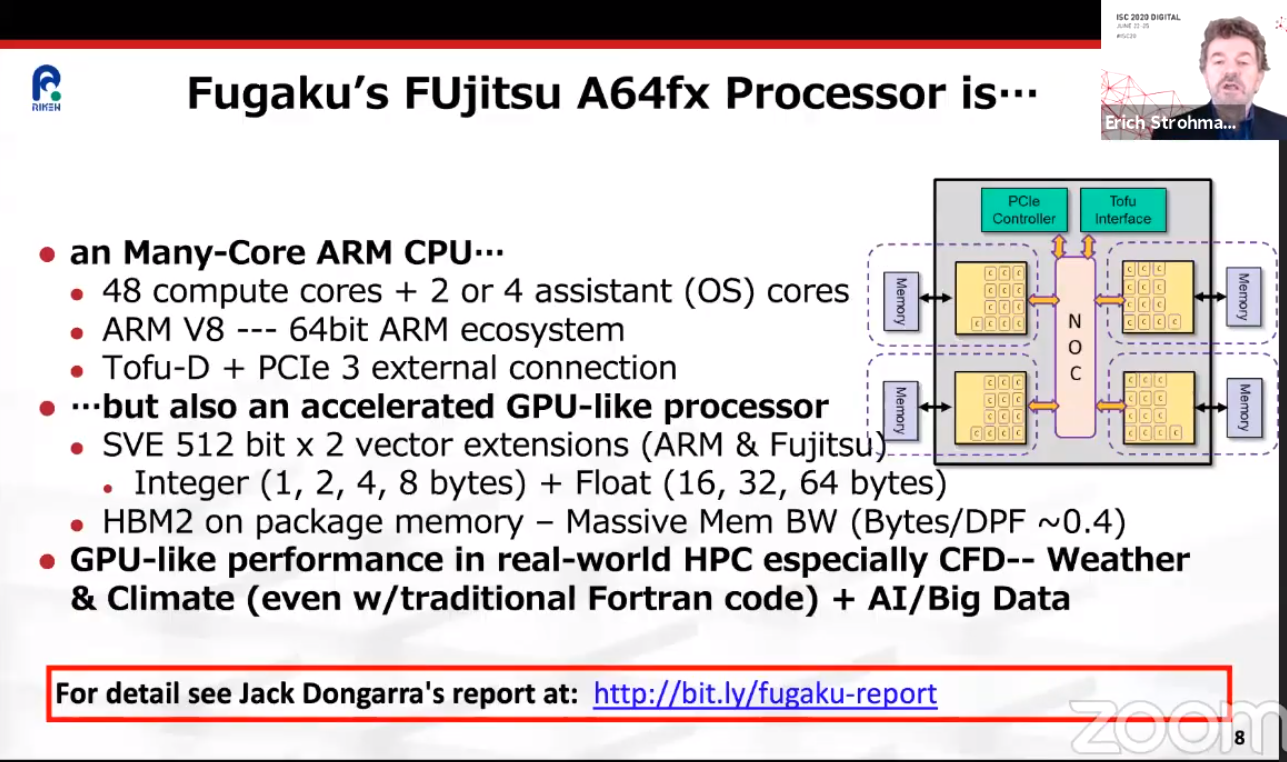  Однако на стороне Fugaku универсальность — понижение точности вычислений вдвое приводит к удвоение производительности. Так что машина имеет впечатляющую теоретическую пиковую скорость вычислений 4,3 Эопс на INT8 и не менее впечатляющие 537 Пфлопс на FP64. Это помогло занять её первое место в бенчмарке HPL-AI, которые использует вычисления разной точности. А общая архитектура процессора, включающего набортную память HBM2, и системы, использующей интерконнект Tofu, способствовали лидерству в бенчмарке HPCG, который оценивает эффективность машины в целом. 
09.06.2020 [19:49], Юрий Поздеев
Суперкомпьютер Neocortex: 800 тыс. ядер Cerebras для ИИПиттсбургский суперкомпьютерный центр (PSC) получит $5 млн от Национального научного фонда на создание суперкомпьютера нового типа Neocortex, который объединяет ИИ-серверы Cerebras CS-1 и HPE SuperDome Flex в единую систему с общей памятью. Планируется, что решение будет введено в эксплуатацию до конца 2020 года.  Каждый сервер Cerebras CS-1 имеет процессор Cerebras Wafer Scale Engine (WSE), который содержит 400 000 ядер, оптимизированных для работы с ИИ (46 225 мм2, 1,2 трлн транзисторов). В паре с ними работает HPE SuperDome Flex, который используется для предварительной обработки информации и постобработки после Cerebras. SuperDome Flex представлен в максимальной комплектации, то есть с 32 процессорами Intel Xeon, 24 Тбайт оперативной памяти, 205 Тбайт флеш-памяти и 24 интерфейсными картами.  Каждый сервер Cerebras CS-1 подключается к SuperDome Flex через 12 каналов со скоростью 100 Гбит/с каждый. Процессор WSE способен обрабатывать 9 Пбайт данных в секунду, что, по подсчетам Nystrom, эквивалентно примерно миллиону фильмов в HD-качестве. Характеристики решения действительно впечатляют! 
Neocortex назван в честь области мозга, отвечающей за функции высокого порядка, включая когнитивные способности, сновидения и формирование речи Архитектура решения строилась таким образом, чтобы не пришлось разбивать вычислительные блоки на множество узлов — это позволило снизить задержки в обработке информации и ускорить обучение моделей ИИ. Cerebras CS-1 разрабатывался специально для ИИ, поэтому он имеет преимущества перед серверами с графическими ускорителями, которые хорошо справляются с матричными операциями, но имеют многие конструктивные ограничения.  По заявлениям Neocortex, сервер CS-1 будет на несколько порядков мощнее системы PSC Bridges-AI. Один сервер Neocortex CS-1 будет эквивалентен примерно 800-1500 серверов с традиционной архитектурой с использованием графических ускорителей. Задачи, в которых Neocortex покажет себя максимально эффективно относятся к классу нейронных сетей DCIGN (deep convolutional inverse graphics networks) и RNN (recurrent neural networks). Если говорить простыми словами, то это более точное прогнозирование погоды, анализ геномов, поиск новых материалов и разработка новых лекарств. 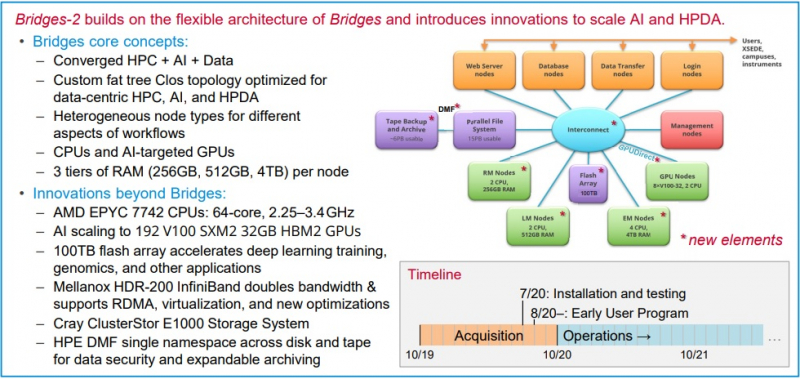 PSC, помимо Neocortex, запускает еще и новое поколение системы Bridges-2, которое будет развернуто осенью 2020 года. Таким образом, до конца этого года будут введены в эксплуатацию два мощных суперкомпьютера для ИИ. Neocortex и Bridges-2 будут поддерживать самые популярные фреймворки машинного обучения, что позволит создать гибкую и мощную экосистему для ИИ, анализа данных, моделирования и симуляции. До 90% машинного времени Neocortex будет выделяться через XSEDE (Extreme Science and Engineering Discovery Environment), финансируемую NSF организацию, которая координирует совместное использование передовых цифровых услуг, включая суперкомпьютеры и ресурсы для визуализации и анализа данных, с исследователями на национальном уровне.
19.11.2019 [00:29], Андрей Созинов
Ноябрьский TOP500: больше китайских систем и меньше американских, и первая система на AMD EPYC RomeУже традиционно в рамках конференции SC была опубликована свежая версия TOP500, рейтинга пятисот самых производительных суперкомпьютеров в мире.  В новой версии списка стало больше систем из Китая, и в то же время сократилось количество систем, расположенных в США. Значительно увеличилась общая производительность всех систем, однако десятка лидеров рейтинга изменений не претерпела. 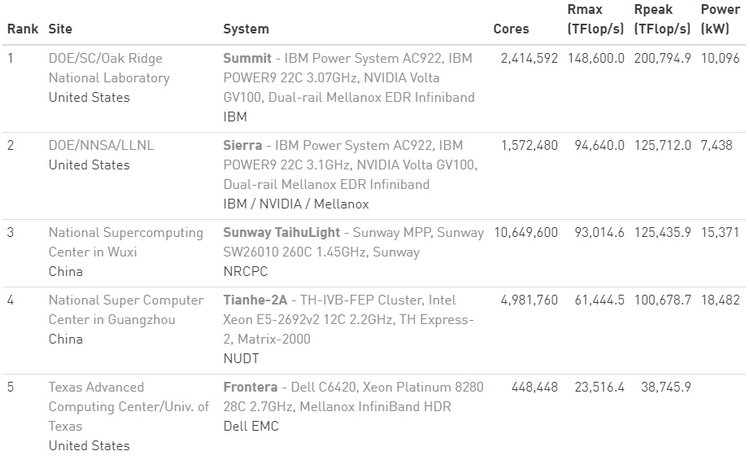 За последние шесть месяцев число китайских суперкомпьютеров в рейтинге TOP500 увеличилась с 219 до 228, и в итоге их доля составила 45,6 %. В то же время количество американских суперкомпьютеров достигло минимума в 117 систем, что составляет 23,4 %. Однако общая производительность систем из США выше — 37,1 % от общей, в то время как доля Китая здесь составляет 32,2 %. Суммарная производительность всех пятисот самых мощных суперкомпьютеров в мире составляет 1,65 Экзафлопс. Российских машин в рейтинге три. На 29 месте TOP500 теперь находится суперкомпьютер Кристофари, принадлежащий Сбербанку. 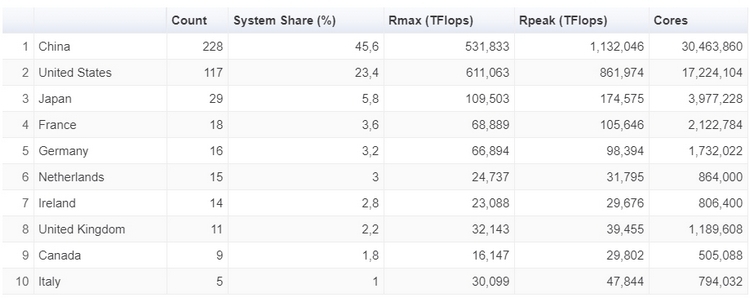 Количество систем, использующих ускорители вычислений и сопроцессоры также возросло, со 134 до 145. Большинство из них использует продукты на базе NVIDIA Volta, a также Pascal и Kepler. Что касается центральных процессоров, то здесь безоговорочным лидером остаётся Intel — 94,8 % систем из TOP500 построены на её чипах.  И здесь же хотелось бы отметить, что в свежем рейтинге TOP500 появилась первая система на процессорах AMD EPYC Rome. Это французский суперкомпьютер Joliot-Curie, построенный на платформе AtoS BullSequana XH2000, которая включает 64-ядерные процессоры AMD EPYC 7H12. Данный суперкомпьютер обладает производительностью 9,4 Пфлопс, он разместился на 59 строке рейтинга TOP500. Значительно увеличилась и минимальная производительность систем рейтинга TOP500. Теперь пятисотая система в рейтинге обладает производительностью в 1,142 Петафлопс. Полгода назад эта система располагалась на 399 месте. А чтобы претендовать на сотое место в рейтинге, системе теперь необходимо обладать производительностью более чем в 2,57 Пфлопс. 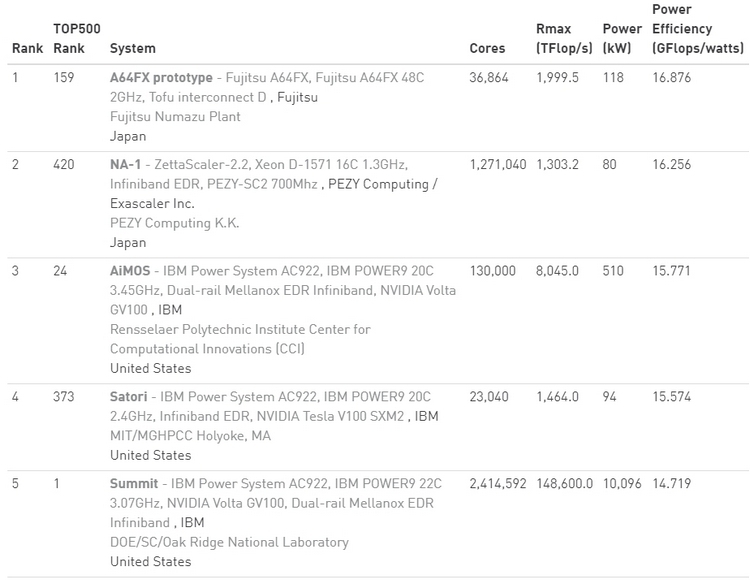 Рейтинг наиболее энергоэффективных систем — Green500 — возглавила японская система от Fujitsu. Это прототип суперкомпьютера на базе процессоров A64FX, который обеспечивает производительность в 16,9 Гфлопс на 1 ватт энергии. В общем рейтинге TOP500 данная система занимает 159 строку с общей производительностью в 2 Пфлопс. Интересно, что система обладает всего лишь 36 864 ядрами и не использует ускорители, что делает её результаты ещё более впечатляющими. Кстати, среднее количество ядер на систему из списка TOP500 также увеличилось — с 118 213 до 126 308.
19.09.2019 [21:46], Андрей Созинов
Atos BullSequana XH2000 на процессорах EPYC 7H12 установила ряд мировых рекордовНовая версия суперкомпьютерного узла BullSequana XH2000 компании Atos, построенная на новейших 64-ядерных процессорах AMD EPYC 7H12, смогла установить сразу несколько абсолютных мировых рекордов производительности.  Новинка была протестирована самой Atos в пакете бенчмарков SPECrate 2017, который как раз и предназначен для оценки производительности мощных вычислительных систем. По результатам тестов, новинка претендует на звание рекордсмена среди всех двухпроцессорных систем в четырёх бенчмарках пакета: 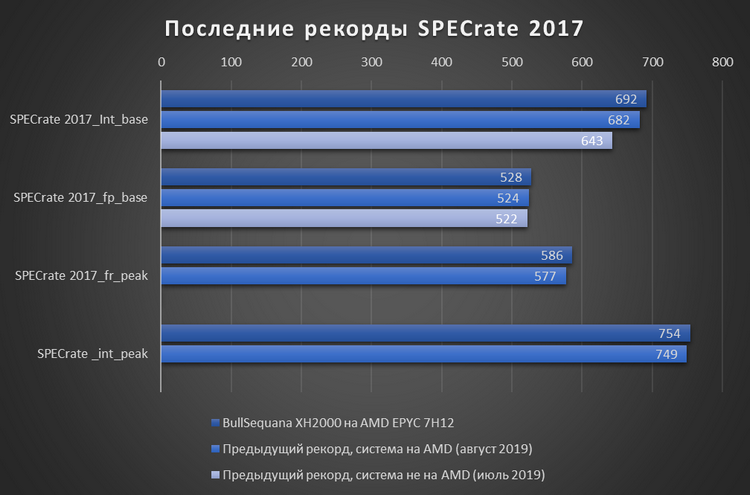 На данный момент представленные Atos результаты тестов проходят проверку комитетом SPEC. Кроме того, Atos заявляет, что система BullSequana XH2000 на базе EPYC 7H12 установила рекорд в бенчмарке HPL Linpack для систем на процессорах AMD. Новинка показала результат в 4,296 Тфлопс, что на 11 % больше результата системы с процессорами AMD EPYC 7742. 
Atos оставляет системы AMD для ряда европейских суперкомпьютеров Прирост производительности обусловлен тем, что средняя рабочая частота процессора EPYC 7H12 выше по сравнению с моделью EPYC 7742. А чтобы справиться с тепловыделением, увеличившимся вместе с частотой, компания Atos использует в BullSequana XH2000 систему жидкостного охлаждения.
02.08.2019 [14:32], Геннадий Детинич
Intel хоронит шину Omni-PathДовольно неожиданно компания Intel отказалась от развития интерконнекта Omni-Path, которую она продвигала в серверных и HPC-платформах сначала для соединения узлов, в том числе для гиперконвергентных систем. Первое поколение шины Omni-Path с пропускной способностью до 100 Гбит/с на порт появилось несколько лет назад. Но ожидаемого второго поколения решений с пропускной способностью до 200 Гбит/с уже не будет. 
Ускорители Intel Xeon Phi с интегрированными контроллером и шиной Omni-Path Информацию о прекращении разработки и выпуска продукции Intel OmniPath Architecture 200 (OPA200) компания подтвердила, например, нашим коллегам с сайта HPCwire. Компания продолжит поддержку и поставку решений с шиной OPA100, но поставок продуктов с архитектурой OPA200 на рынок больше не будет. В принципе, сравнительно слабая поддержка шины Intel OmniPath со стороны клиентов рынка высокопроизводительных систем намекала на нечто подобное. Большей популярностью у строителей суперсистем и не только продолжает пользоваться InfiniBand и её новое HDR-воплощение с той же пропускной способностью до 200 Гбит/с. В свете ликвидации OPA200 становится понятно, почему Intel схватилась с NVIDIA за право поглощения компании Mellanox. Но не вышло: приз ушёл к NVIDIA. «Вообще, половина инсталляций в TOP500 использует Ethernet, но в основном 10/25/40 Гбит/с, и лишь совсем чуть-чуть может похвастаться 100 Гбит/с. InfiniBand установлен почти в 130 машинах, а Omni-Path есть чуть больше чем в 40. Остальное — проприетарные разработки». Что остаётся Intel? У лидера рынка микропроцессоров есть I/O-активы. Компания около 8 лет активно выстраивает направление для развития коммуникаций в ЦОД. За это время она поглотила разработчика коммутационных ASIC компанию Fulcrum Microsystems, подразделение по разработке адаптеров и коммутаторов InfiniBand компании QLogic и коммуникационное подразделение компании Cray. Относительно свежей покупкой Intel стала компания Barefoot Networks, разработчик решений для Ethernet-коммутаторов. Похоже, Intel решила вернуться к классике: InfiniBand (что менее вероятно) и Ethernet (что более вероятно), а о проприетарных шинах в виде той же Omni-Path решила забыть. В конце концов, Ethernet-подразделение компании славится своими продуктами. Новое поколения Intel Ethernet 800 Series способно заменить OPA100.
22.08.2018 [13:00], Геннадий Детинич
Раскрыты спецификации ARM-процессоров Fujitsu A64FX для суперкомпьютера Post-KПримерно через три года начнётся коммерческая эксплуатация суперкомпьютера Post-K, который компании Fujitsu и RIKEN разрабатывают на смену предыдущей совместной системы суперкомпьютера K (начал работать в 2011 году). Новая система Post-K обещает 100-кратно поднять производительность на уровне приложений. И сделано это будет благодаря переходу Fujitsu на ARM-совместимые ядра и новую архитектуру с масштабируемыми векторными инструкциями (Scalable Vector Extensions).  На прошедшей на днях конференции Hot Chips 30 (2018) компания Fujitsu впервые обнародовала спецификации новых процессоров, которые получили обозначение A64FX. Ни «A», ни «64», ни «FX» не имеют отношение к компании AMD, хотя в названии новых суперпроцессоров Fujitsu что-то немного согревает душу. Это процессоры с поддержкой 64-разрядных команд ARM и векторных инструкций длиной до 512 бит. Каждый процессор Fujitsu A64FX будет нести 48 вычислительных ядер и 4 вспомогательных ядра, разделённые на четыре блока, соединённых внутренней кольцевой шиной. Для связи с другими процессорами Fujitsu использует две линии внешнего интерфейса Tofu с пропускной способностью 28 Гбит/с. Строение процессора и внешний скоростной интерфейс обещают значительное наращивание параллелизма в вычислениях. 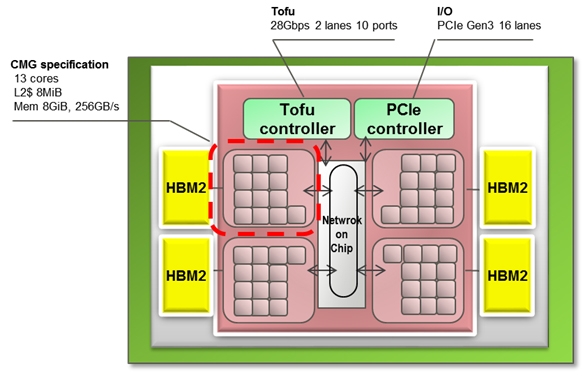
Fujitsu Каждый из 13-ядерных блоков поддержан кеш-памятью L2 объёмом 8 Мбайт. Кроме этого каждый из блоков напрямую обращается к модулю стековой памяти HBM2 объёмом 8 Гбайт. Суммарный объём памяти HBM2 у каждого процессора насчитывает 32 Гбайт, а общая скорость доступа достигает 1024 Гбайт/с. Поскольку память HBM2 можно рассматривать в качестве кеш-памяти третьего уровня, все или большинство операций выполняются в процессоре, что обещает отличный прирост производительности.  Процессор Fujitsu A64FX выпускается с использованием 7-нм техпроцесса, очевидно, что на линиях компании TSMC. Он насчитывает 8,7 млрд транзисторов. Пиковая производительность процессора для операций с двойной точностью достигает 2,7 терафлопс. Процессор без потерь на переход может вычислять операции с одинарной точностью и половинной, соответственно, в два и четыре раза быстрее. Также, за что надо благодарить тему машинного обучения, процессор A64FX оптимизирован для обработки 16- и 8-битных целочисленных значений. 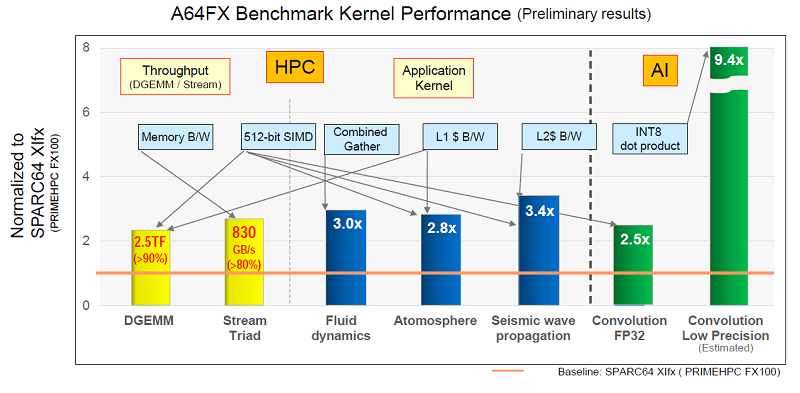
29.07.2018 [13:00], Геннадий Детинич
Американские ВВС получили самый большой в мире нейроморфный суперкомпьютерЗвучит громко, но это именно так. Лаборатория Air Force Research Laboratory (AFRL) в городе Ром, штат Нью-Йорк, получила в своё распоряжение самый большой в мире компьютер по числу задействованных в системе нейроморфных процессоров IBM TrueNorth. Система представлена полочными компьютерами высотой 4U (7 дюймов) для стандартной серверной стойки. Каждый компьютер располагает 64 процессорами IBM TrueNorth. В пересчёте на человеческие в буквальном смысле единицы измерения мозга — это 64 млн нейронов и 16 млрд синапсов. Всего в стойке может разместиться 512 млн цифровых нейронов. Примерно столько нейронов в коре головного мозга собаки. 
AFRL Система под именем «Blue Raven» на базе IBM TrueNorth для Лаборатории ВВС США представлена пока 64-процессорным решением с общим потреблением 40 Вт. Это, кстати, в 4 раза больше ожидаемого. Аналогичный 16-процессорный компьютер, переданный в 2016 году Ливерморской национальной лаборатории им. Лоуренса, потреблял всего 2,5 Вт или 156 мВт на один процессор. Возможно таким образом была повышена производительность системы, которая при потреблении 70 мВт способна работать с производительностью 46 млрд синаптических операций в секунду. 
IBM По оценкам IBM, работа процессоров TrueNorth с необозначенным датасетом на CIFAR-100 по распознаванию наборов изображений характеризуется производительностью свыше 1500 кадров в секунду с потреблением 200 мВт или свыше 7000 кадров в секунду на ватт. Ускоритель NVIDIA Tesla P4 (Pascal GP104), например, обрабатывает датасет Resnet-50 с производительностью 27 кадров в секунду на ватт. 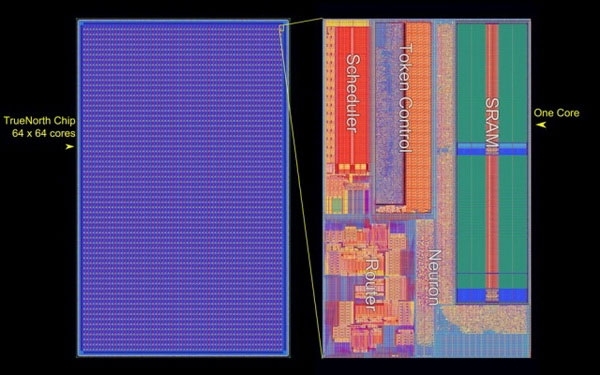
Структура процессора IBM TrueNorth Вообще, в Лаборатории AFRL, похоже, работают увлечённые люди. Новым проектом «Blue Raven» руководит тот же человек (Mark Barnell), который несколько лет назад отметился запуском суперкомпьютера Condor Cluster на базе сотен игровых консолей Sony PlayStation 3. Какими расчётами в AFRL будет заниматься суперкомпьютер с «мозгами» не уточняется. Пока учёные будут изучать круг задач, решаемый подобными системами. Ожидается, что принятая на «вооружение» научным отделом ВВС США вычислительная система обеспечит дальнейшее приоритетное развитие технологий в этой стране.
30.09.2017 [00:15], Алексей Степин
Терафлопс в космосе: на МКС тестируется компьютер HPE SpaceborneБытует мнение, что в космической отрасли используется всё самое лучшее, включая компьютерные компоненты. Это не совсем так: вы не встретите в космических аппаратах 18-ядерных Xeon и ускорителей Tesla. Во-первых, энергетические резервы за пределами Земли строго ограничены, и даже на МКС никто не будет тратить несколько киловатт на питание «космического суперкомпьютера». Во-вторых, практически вся электроника, работающая за пределами атмосферы, выпускается в специальном радиационно-стойком исполнении. Чаще всего за счёт техпроцессов «кремний на диэлектрике» (SOI) и «сапфировая подложка» (SOS), используется также биполярная логика вместо менее стойкой к внешним излучениям CMOS. 
Мини-кластер в космическом исполнении. Охлаждение жидкостное Мощными в космосе считаются такие решения, как BAE Systems серии RAD, особенно новая RAD5500 (от 1 до 4 ядер, 45-нм SOI, PowerPC, 64 бита). Четырёхъядерный вариант RAD5545 развивает производительность более 3,7 гигафлопс при потреблении около 20 ватт. Иными словами, вычислительные мощности в космосе тоже растут, но совсем иными темпами, нежели на Земле. Тому подтверждением служит недавно вступивший в строй на борту Международной космической станции компьютер HPE Spaceborne. Если на Земле мощность суперкомпьютеров измеряется десятками и сотнями петафлопс, то Spaceborne куда скромнее — судя по проведённым тестам, его вычислительная мощность достигает 1 терафлопса. Достигнута она путём сочетания современных процессоров Intel с ускорителями NVIDIA Tesla P100 (NVLink-версия). 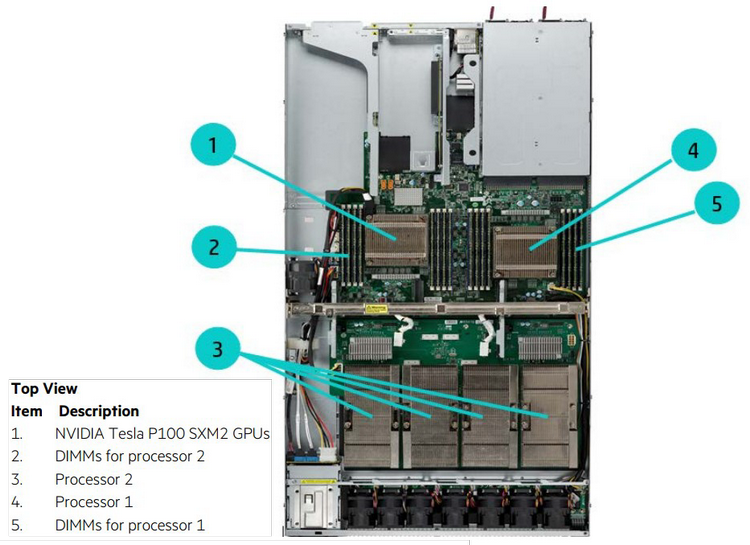
Конфигурация каждого из узлов Spaceborne Для космических систем это большое достижение, и не стоит иронизировать над этим показателем производительности. Интересно, что сама по себе система Spaceborne, доставленная на борт станции миссией SpaceX CRS-12, является своего рода экспериментом на тему «как чувствуют себя в космосе обычные компьютерные комплектующие». Это связка из двух серверов HPE Apollo 40 на базе Intel Xeon, объединённая сетью со скоростью 56 Гбит/с. 14 сентября на систему было подано питание (48 и 110 вольт), а недавно проведены первые тесты High Performance LINPACK. 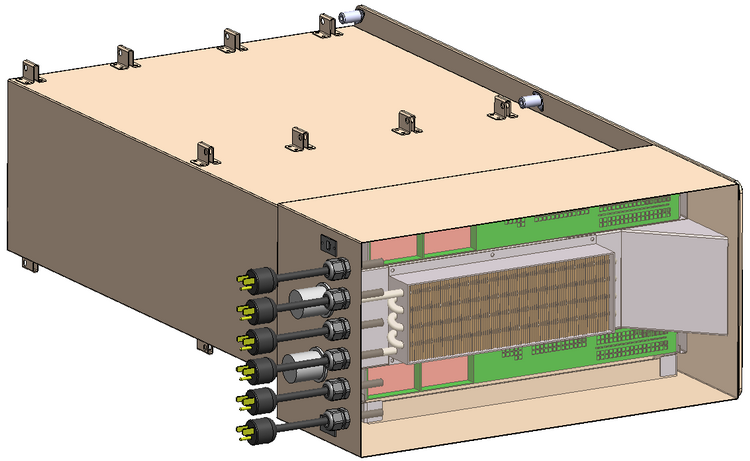
Системы охлаждения и электропитания Spaceborne Пока Spaceborne не будет использоваться для анализа научных данных или управления какими-либо системами станции. Его миссия — продемонстрировать то, насколько живучи обычные серверы в космосе. Результаты постоянных тестов будут сравниваться с аналогичной системой, оставшейся на Земле. Тем не менее, достижение первого терафлопса в космосе является своеобразным мировым рекордом. Это маленький шаг для супервычислений, но большой для всей космической индустрии, поскольку за Spaceborne явно последуют его более совершенные и мощные потомки. |
|