Материалы по тегу: tpu
|
04.08.2024 [15:25], Сергей Карасёв
В Google Cloud появился выделенный ИИ-кластер для стартапов Y CombinatorОблачная платформа Google Cloud, по сообщению TechCrunch, развернула выделенный субсидируемый кластер для ИИ-стартапов, которые поддерживаются венчурным фондом Y Combinator. Предполагается, что данная инициатива поможет Google привлечь в своё облако перспективные компании, которым в будущем могут понадобиться значительные вычислительные ресурсы. Отмечается, что для ИИ-стартапов на ранней стадии одной из самых распространённых проблем является ограниченная доступность вычислительных мощностей. Крупные предприятия обладают достаточными финансами для заключения многолетних соглашений с поставщиками облачных услуг на доступ к НРС/ИИ-сервисам. Однако у небольших фирм с этим возникают сложности. Ожидается, что Google Cloud поможет в решении данной проблемы. Google предоставит выделенный кластер с приоритетным доступом для стартапов Y Combinator. Платформа базируется на ускорителях NVIDIA и тензорных процессорах (TPU) самой Google. Каждый участник программы получит кредиты на сумму $350 тыс. для использования облачных сервисов Google в течение двух лет. Кроме того, Google предоставит стартапам кредиты в размере $12 тыс. на расширенную поддержку и бесплатную годовую подписку Google Workspace Business Plus. Молодые компании также смогут консультироваться с экспертами Google в области ИИ. 
Источник изображения: Google Оказав поддержку ИИ-стартапам, Google в дальнейшем сможет рассчитывать на заключение с ними долгосрочных контрактов на обслуживание. Говорится, что за последние 18 лет примерно 5 % стартапов Y Combinator стали единорогами с оценкой $1 млрд и более. Такие компании могут принести облачной платформе Google значительную выручку в случае заключения соглашения о сотрудничестве. С другой стороны, фонд Y Combinator сможет привлечь больше перспективных ИИ-проектов, предлагая вычислительные ресурсы Google вместе со своей поддержкой. Аналогичные программы есть и у других игроков. Так, венчурный инвестор Andreessen Horowitz (a16z) тоже запасается ИИ-ускорителями, чтобы стать более привлекательным для ИИ-стартапов. AWS предлагает ИИ-стартапам доступ к облаку и сервисам, а Alibaba Cloud готова предоставить ресурсы в обмен на долю в стартапе. Сама Google на днях наняла основателей стартапа Character.AI и лицензировал его модели. Стартапу, по-видимому, не хватило средств на ИИ-ускорители для дальнейшего развития.
23.06.2024 [22:50], Владимир Мироненко
Облачный союз: Apple использует ИИ-инфраструктуру Google Cloud для Apple IntelligenceИИ-инфраструктура Apple Private Cloud Compute использует не только базовую ИИ-модель собственной разработки и серверы Apple для инференса, работающие на собственных чипах Apple, но и облако Google Cloud Compute, обратил внимание ресурс HPCWire. Сведения об ML-платформе Apple AXLearn указывают на гибридный подход к работе с ИИ, при котором Apple объединяет свои собственные серверы с возможностями Google Cloud, сообщил HPCwire, отметив, что новая инфраструктура является для Apple большим шагом вперёд. Например, Google и Microsoft, активно работают над развёртыванием ИИ ещё с конца 2022 года. Выпуск собственных систем знаменует возвращение Apple в сектор серверного оборудования после того, как в 2011 году она прекратила выпуск Xserve. 
Источник изображения: Apple Apple сообщила в своём блоге, что AXLearn использует фреймворк Google JAX и компилятор XLA и позволяет обучать модели с высокой эффективностью и масштабируемостью на различном оборудовании и облачных платформах, включая фирменные ИИ-ускорители Google TPU, а также облачные и локальные ускорители на базе GPU (конкретные модели не уточняются). У Apple есть две новые собственные ИИ-модели, одна из которых имеет 3 млрд параметров и используется для ИИ приложений на устройствах, а также более крупная LLM для запуска на серверах. Модели, разработанные с помощью фреймворка TensorFlow, созданного Google, были обучены на TPU Google. При этом AXLearn включает оркестратор, который пока работает только с Google Cloud. Впрочем, Apple оговаривается, что «теоретически его можно расширить для работы на платформах других облачных провайдеров». Инференс же выполняется исключительно на собственных серверах компании, причём для обработки запроса пользователя каждый раз создаётся новый временный инстанс, который безвозвратно удаляется вместе с данными после завершения задачи, а для передачи информации используется сквозное шифрование. Apple в рамках объявленного на WWDC 2024 сотрудничества c OpenAI интегрирует чат-бот ChatGPT в голосового помощника Siri, а также в другие инструменты iOS и остальных платформ. Поскольку существуют риски утечки данных на сторонней платформе, устройства Apple будут направлять запрос на разрешение пользователя отправлять данные в ChatGPT.
22.05.2024 [21:45], Руслан Авдеев
Google обогнала AMD на рынке процессоров для ЦОД и вот-вот догонит Intel
cpu
google
google cloud platform
hardware
techinsights
tpu
анализ рынка
гиперскейлер
ии
облако
ускоритель
цод
В прошлом месяце компания Google анонсировала долгожданный серверный CPU на архитектуре Arm. Впрочем, как сообщает The Register, она уже оказалась третьей на рынке процессоров для ЦОД (сюда входят не только CPU, но и GPU, TPU и иные ускорители). Согласно отчёту TechInsights, компания теперь уступает только NVIDIA и Intel и давно обогнала AMD. 
Источник изображения: Google Как и другие крупные облачные операторы, IT-гигант выпускает собственные чипы TPU, шестое поколение которых было представлено на прошлой неделе. Хотя на сторону их не продают, компания заказывает огромные партии TPU для оснащения собственных ЦОД — только в прошлом году речь шла о 2 млн штук. Ключевым партнёром Google в создании кастомного «кремния» является Broadcom. Поставки TPU нарастают с каждым поколением, следуя за ростом самой компании. После премьеры TPU v4 в 2021 году в связи с развитием больших языковых моделей (LLM) объём полупроводникового бизнеса Google значительно вырос. TPU применяются компанией для внутренних задач, а ускорители NVIDIA — для облака. В TechInsights считают, что на сегодняшний день у Google имеется крупнейшая в отрасли база установленных ИИ-ускорителей и самая масштабная ИИ-инфраструктура. 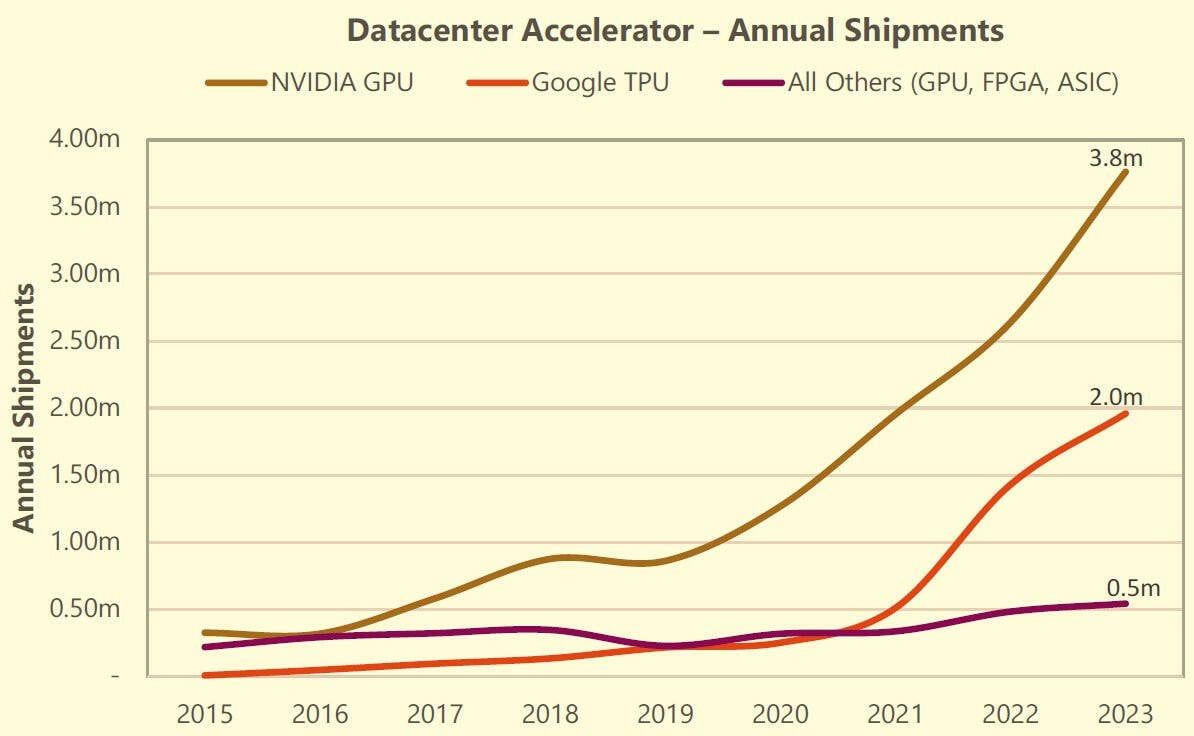
Источник изображения: TechInsights В прошлом году на серверным рынке произошла «масштабная коррекция запасов» — гиперскейлеры увеличили срок службы оборудования, отложив замену серверов общего назначения и повысив капитальные затраты на ИИ-серверы и ускорители NVIDIA. Аналитики Omdia говорят о таких тенденциях на рынке что в прошлом, что в начале этого года. В TechInsights считают, что по итогам I квартала 2024 года Google сможет догнать или даже перегнать Intel по доле на этом рынке. Конечно, Google — не единственная облачная компания, разрабатывающая собственные чипы. Microsoft работает над серверным CPU Azure Cobalt и ИИ-ускорителями Maia 100. AWS и вовсе годами использует собственные Arm-процессоры Graviton и ИИ-ускорители серий Trainium и Inferentia. В прошлогоднем докладе Bernstein Research сообщалось, что архитектуру Arm используют уже около 10 % серверов по всему миру, а более 50 % из них внедряется AWS. Softbank в начале 2023 года говорила о том, что Arm захватила 5 % облачного рынка. 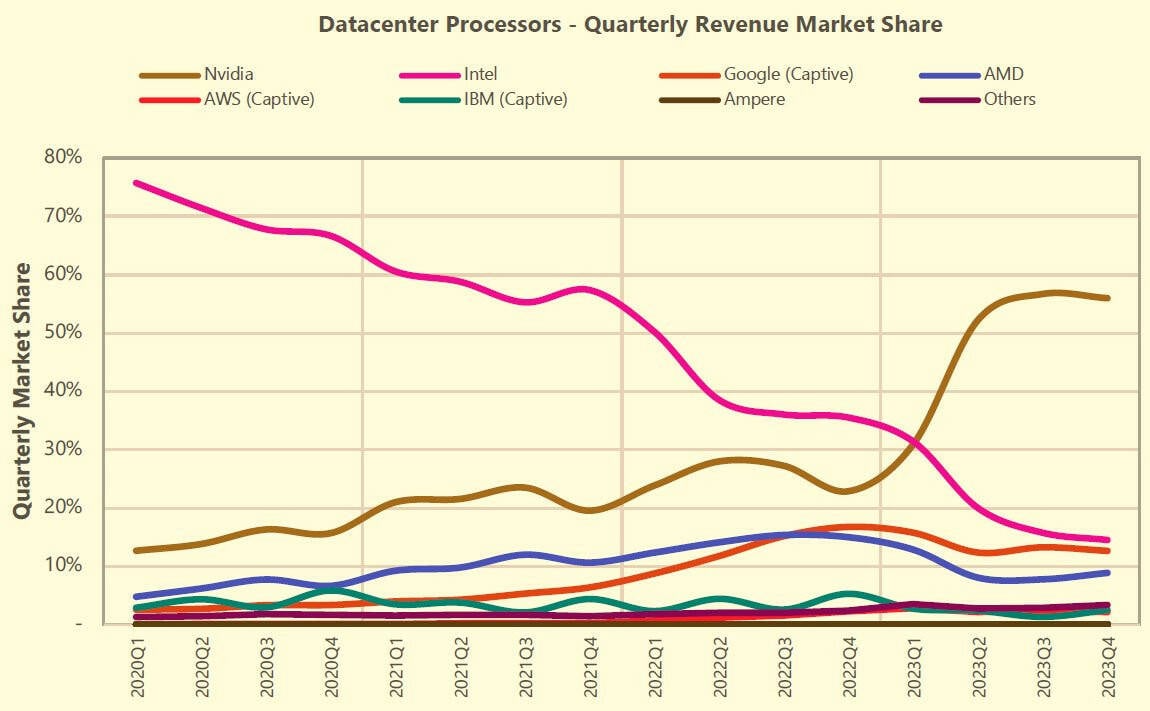
Источник изображения: TechInsights Впрочем, с появлением процессоров TPU V5e и TPU V5p решения Google будут использоваться всё шире из-за «взрывного роста» больших языковых моделей вроде Gemini. В 2024 году у Google появится Arm-процессор Axion. И его внедрение, по мнению TechInsights, будет происходить намного быстрее, чем Graviton, поскольку у Google уже имеется программная инфраструктура для такого чипа. Всё это необходимо компании, чтобы идти в ногу с AWS, Microsoft и, в меньшей степени, Alibaba. При этом в докладе упоминается, что рынок полупроводников для ЦОД быстро меняется — раньше на нём доминировала Intel с архитектурой x86. Теперь его структура определяется потребностями ИИ-систем.
16.05.2024 [23:30], Алексей Степин
Шестое поколение ускорителей Google TPU v6 готово к обучению ИИ-моделей следующего поколенияGoogle успешно занимается разработкой ИИ-ускорителей порядка 10 лет. В прошлом году компания заявила, что четвёртое поколение TPU в связке с фирменными оптическими коммутаторами превосходит кластеры на базе NVIDIA A100 с интерконнектом InfiniBand, а к концу того же года было представлено уже пятое поколение, причём в двух вариантах: энергоэффективные TPU v5e для малых и средних ИИ-моделей и высокопроизводительные TPU v5p для больших моделей. Сбавлять темпа компания явно не собирается — не прошло и полугода, как было анонсировано последнее, шестое поколение TPU, получившее, наконец, собственное имя — Trillium. Клиентам Gooogle Cloud новинка станет доступна до конца этого года, в том числе в составе AI Hypercomputer. Сведений об архитектуре и особенностях Trillium пока не очень много, но согласно заявлениям разработчиков, он в 4,7 раза быстрее TPU v5e. 
Источник: The Verge Ранее аналитик Патрик Мурхед (Patrick Moorhead) опубликовал любопытное фото, на котором глава подразделения кастомных чипов Broadcom держит в руках некий XPU, разработанный для «крупной ИИ-компании». Не исключено, что сделан он именно для Google. На снимке видна чиплетная сборка из двух крупных кристаллов в окружении 12 стеков HBM-памяти. Любопытно и то, что TPU v6 нарекли точно так же, как и проект Arm шестилетней давности по созданию нового поколения ИИ-ускорителей. Пропускная способность 32 Гбайт набортной HBM-памяти составляет 1,6 Тбайт/с. Межчиповый интерконнект ICI имеет пропускную способность до 3,2 Тбит/с, хотя в TPU v5p скорости ICI уже 4,8 Тбит/с. По словам Google, новый чип получился на 67% энергоэффективнее TPU v5e. Складывается ощущение, что компания сознательно избегает сравнения с TPU v5p. Но это объяснимо, поскольку заявленный почти пятикратный прирост производительности в сравнении с TPU v5e даёт примерно 926 Тфлопс в режиме BF16 и 1847 Топс в INT8, что практически вдвое выше показателей TPU v5p. 
Кластер Google на базе TPU v5e. Источник: Google При этом компания не бравирует высокими цифрами в INT4/FP4, как это делает NVIDIA в случае с Blackwell. Согласно опубликованным данным, прирост производительности достигнут за счёт расширения блоков перемножения матриц (MXU) и прироста тактовой частоты. В новом TPU также использовано новое, третье поколение блоков SparseCore, предназначенных для ускорения работы с ИИ-модели, часто использующихся в системах ранжирования и рекомендаций. Масштабируется Trillium практически так же, как TPU v5e — в составе одного блока («пода») могут работать до 256 чипов. Эти «поды» формируют кластер с технологией Multislice, позволяющий задействовать в одной задаче до 4096 чипов. В таких кластерах на помощь приходят DPU Titanium, берущие на себя обслуживание IO-операций, сети, виртуализации, безопасности и доверенных вычислений. Размеры кластера могут достигать сотен «подов». 
Кластер Google на базе TPU v5p. Источник: Google Google полагает, что TPU v6 готовы к приходу ИИ-моделей нового поколения и имеет для этого все основания: ориентировочно каждый Trillium с его 32 Гбайт быстрой памяти может оперировать примерно 30 млрд параметров, а речь, напомним, в перспективе идёт о десятках тысяч таких чипов в одном кластере. В качестве интерконнекта в таких системах используется платформа Google Jupiter с оптической коммутацией, совокупная пропускная способность которой уже сейчас превышает 6 Пбайт/с.
25.01.2024 [18:03], Руслан Авдеев
Singular Computing отозвала многомиллиардный иск к Google, обвинявшейся в краже технологий ИИ-чиповКомпания Singular Computing отозвала иск к Google на сумму в несколько миллиардов долларов — техногиганта обвиняли в нарушении патентных прав, связанных с чипами для ИИ-вычислений. Как сообщает The Register, в Google согласились на компенсацию, а сам иск уже отозван. В Google выразили удовлетворение тем, что пятилетнее разбирательство завершилось. В материалах суда, касающихся мирового соглашения, информация о сумме отсутствует, но в предшествовавших судебному разбирательству документах упоминалось требование Singular выплатить $1,6–5,2 млрд в качестве компенсации ущерба за использование патентованных технологий без лицензий при разработке и тензорных процессоров (TPU) второй и третьей версий. 
Источник изображения: Google Cloud Singular ещё в 2010–2014 гг. предлагала техногиганту патентованные технологии и прототипы своих процессоров с раскрытием соответствующей информации. Впоследствии Singular обвинила Google в краже разработок и их использовании для создания тензорных ускорителей. Хотя Google отрицала любые контакты с Singular, в ходе разбирательства выяснилось, что во внутренней переписке Джефф Дин (Jeff Dean), главный учёный Google, упоминал разработки Singular как «очень хорошо подходящие» для задач техногиганта. В то же время Google неоднократно заявляла, что с разработками Singular её TPU никак не связаны, а исследования велись совершенно независимо многие годы. Тем не менее, компания, похоже, решила отделаться малой кровью — сейчас основу её ИИ-инфраструктуры составляет уже пятое поколение TPU, так что проблемы с патентами способны вылиться в ещё больший ущерб, чем скромная компенсация. Даже если разработка действительно велась независимо, наличие чужого патента всё равно накладывает обязательства по лицензированию.
13.01.2024 [21:37], Сергей Карасёв
Началось рассмотрение иска на $1,67 млрд о нарушении патентов в ИИ-ускорителях Google TPUВ США, по сообщению The Register, начался суд по иску компании Singular Computing в отношении Google: IT-корпорация обвиняется в незаконном использовании запатентованных разработок в своих ИИ-ускорителях TPU (Tensor Processing Unit). В случае победы Singular может получить компенсацию от $1,67 млрд до $5,19 млрд. Singular была основана в 2005 году доктором Джозефом Бейтсом (Joseph Bates). Согласно его профилю на LinkedIn, более 30 лет Бейтс занимал исследовательские и преподавательские должности в университетах Корнелла (Cornell University), Карнеги-Меллона (Carnegie Mellon University) и Джона Хопкинса (Johns Hopkins University), а также в Массачусетском технологическом институте (MIT) в США. Созданная Бейтсом компания Singular, как говорится на её сайте, «разрабатывает и лицензирует аппаратные и программные технологии для высокопроизводительных и энергоэффективных вычислений». Иск против Google был подан в 2019 году в федеральный суд Массачусетса. Утверждается, что в период с 2010-го по 2014 год Бейтс трижды делился с Google своими технологиями, обсуждая, в частности, как решать проблемы, связанные с ИИ-нагрузками. При этом якобы было заключено соглашение о неразглашении конфиденциальной информации. Кроме того, как утверждается, Бейтс заранее предупредил Google, что рассматриваемые технологии защищены патентами. 
Источник изображения: Google В иске говорится, что Google незаконно использовала разработки Бейтса в ИИ-ускорителях TPU v2 и v3. Singular утверждает, что Google намеренно внедрила архитектуру Бейтса в свои чипы без разрешения или приобретенияя лицензии и тем самым сознательно нарушила патенты. Речь идёт о разработках, связанных с архитектурой, предназначенной для выполнения большого количества вычислений низкой точности в каждом цикле. Истцы утверждают, что данная технология хорошо подходит для использования в сфере ИИ. Соответствующие патентные заявки были оформлены и опубликованы в 2009–2010 гг. В деле упоминается внутреннее электронное письмо, в котором главный научный сотрудник Google якобы написал, что идеи Бейтса могут «очень хорошо подойти» для того, что разрабатывает Google. Кроме того, истцы упоминают письмо от другого неназванного работника Google, в котором говорится, что сотрудники компании «подкуплены идеями Джозефа». Google отвергает обвинения в нарушении прав. Корпорация заявляет, что патентные претензии Singular «сомнительны» и «в настоящее время находятся на апелляции».
07.12.2023 [21:04], Сергей Карасёв
Google представила Cloud TPU v5p — свой самый мощный ИИ-ускорительКомпания Google анонсировала свой самый высокопроизводительный ускоритель для задач ИИ — Cloud TPU v5p. По сравнению с изделием предыдущего поколения TPU v4 обеспечивается приблизительно 1,7-кратный пророст быстродействия на операциях BF16. Впрочем, для Google важнее то, что она наряду с AWS является одной из немногих, кто при разработке ИИ не зависит от дефицитных ускорителей NVIDIA. К этому же стремится сейчас и Microsoft. Решение Cloud TPU v5p оснащено 95 Гбайт памяти HBM с пропускной способностью 2765 Гбайт/с. Для сравнения: конфигурация TPU v4 включает 32 Гбайт памяти HBM с пропускной способностью 1228 Гбайт/с. 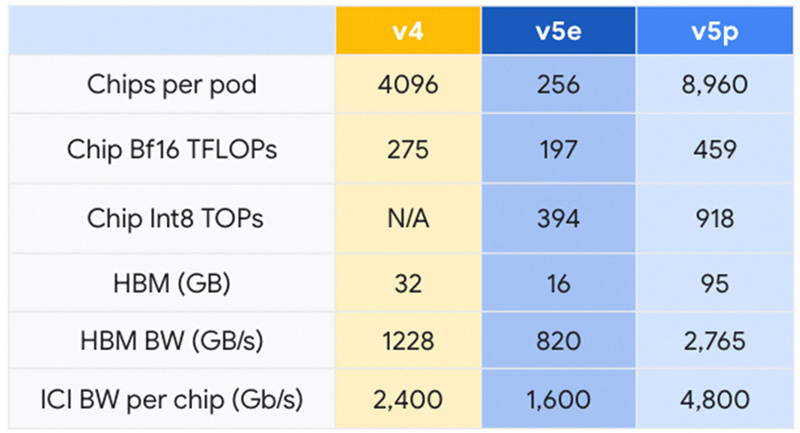
Источник изображений: Google Кластер на базе Cloud TPU v5p может содержать до 8960 чипов, объединённых высокоскоростным интерконнектом со скоростью передачи данных до 4800 Гбит/с на чип. В случае TPU v4 эти значения составляют соответственно 4096 чипов и 2400 Гбит/с. Что касается производительности, то у Cloud TPU v5p она достигает 459 Тфлопс (BF16) против 275 Тфлопс у TPU v4. На операциях INT8 новинка демонстрирует результат до 918 TOPS. 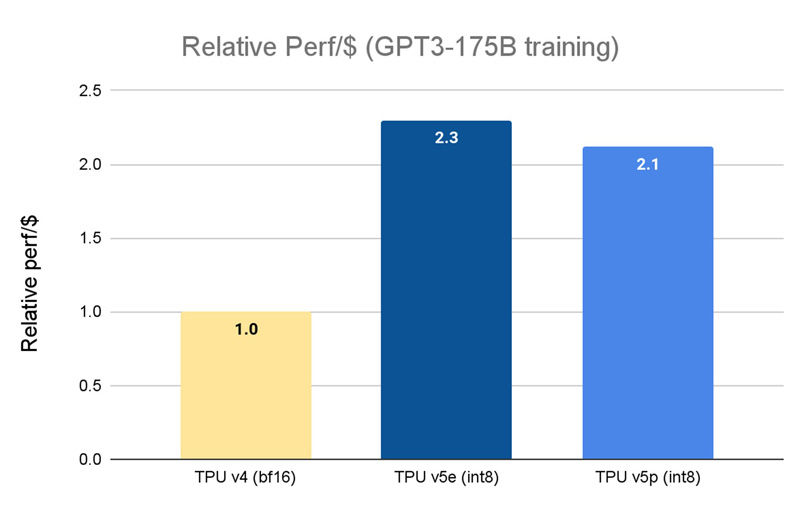 В августе нынешнего года Google представила ИИ-ускоритель TPU v5e, созданный для обеспечения наилучшего соотношения стоимости и эффективности. Это изделие с 16 Гбайт памяти HBM (820 Гбит/с) показывает быстродействие 197 Тфлопс и 394 TOPS на операциях BF16 и INT8 соответственно. При этом решение обеспечивает относительную производительность на доллар на уровне $1,2 в пересчёте на чип в час. У TPU v4 значение равно $3,22, а у новейшего Cloud TPU v5p — $4,2 (во всех случаях оценка выполнена на модели GPT-3 со 175 млрд параметров). 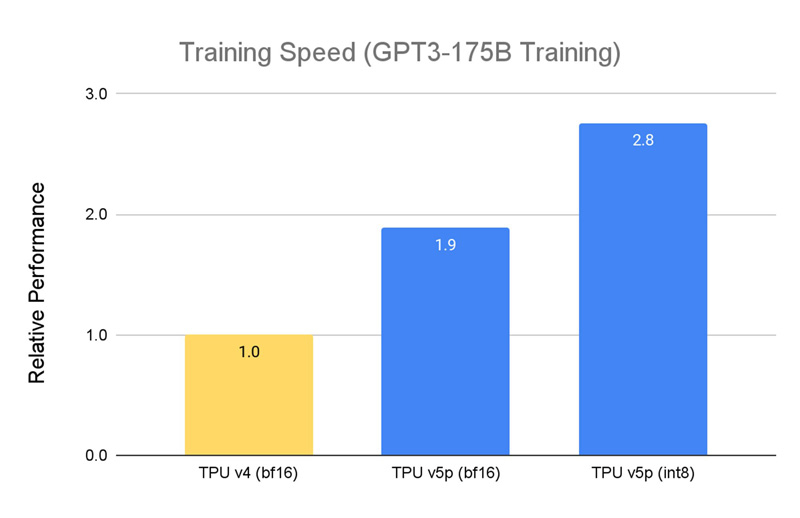 По заявлениям Google, чип Cloud TPU v5p может обучать большие языковые модели в 2,8 раза быстрее по сравнению с TPU v4. Более того, благодаря SparseCores второго поколения скорость обучения моделей embedding-dense увеличивается приблизительно в 1,9 раза. На базе TPU и GPU компания предоставляет готовый программно-аппаратный стек AI Hypercomputer для комплексной работы с ИИ. Система объединяет различные аппаратные ресурсы, включая различные типы хранилищ и оптический интерконнект Jupiter, сервисы GCE и GKE, популярные фреймворки AX, TensorFlow и PyTorch, что позволяет быстро и эффективно заниматься обучением современных моделей, а также организовать инференс.
10.11.2023 [16:11], Сергей Карасёв
ИИ-стартап Anthropic задействует чипы Google TPU v5e для обучения моделейСтартап Anthropic, специализирующийся на технологиях генеративного ИИ, по информации Datacenter Dynamics, намерен использовать ускорители Google TPU для обучения своих систем, включая большую языковую модель Claude. Многие компании вынуждены искать альтернативы дефицитным чипам NVIDIA, хотя это и требует дополнительных затрат для адаптации ПО. Речь идёт о чипах Google TPU v5e, которые были анонсированы в августе нынешнего года. Это специализированные решения, предназначенные для обучения нейросетей или инференс-систем среднего и большого классов. Ускоритель содержит четыре блока матричных вычислений, по одному блоку для скалярных и векторных расчётов, а также HBM2-память. 
Источник изображения: pixabay.com Google и Anthropic уже связывают партнёрские отношения. В частности, в конце 2022-го Google приобрела в этом ИИ-стартапе долю в размере 10 % за $300 млн. В октябре 2023-го стало известно, что Google предоставит Anthropic дополнительно $500 млн, а позднее — ещё $1,5 млрд. Google уже добавила в своё облако ИИ-модели Anthropic, а стартап, в свою очередь, развернул один из самых крупных кластеров Google Kubernetes Engine (GKE) для ИИ. Между тем интерес к Anthropic проявляют и другие компании. Так, в августе нынешнего года SK Telecom вложила $100 млн в этот ИИ-стартап. А в сентябре Amazon объявила о намерении инвестировать в Anthropic до $4 млрд. По условиям соглашения, Anthropic будет использовать облачные ресурсы AWS; кроме того, стороны займутся разработкой чипов Trainium и Inferentia нового поколения.
07.04.2023 [20:36], Сергей Карасёв
Google заявила, что её ИИ-кластеры на базе TPU v4 и оптических коммутаторов эффективнее кластеров на базе NVIDIA A100 и InfiniBandКомпания Google обнародовала новую информацию о своей облачной суперкомпьютерной платформе Cloud TPU v4, предназначенной для решения задач ИИ и машинного обучения с высокой эффективностью. Система может использоваться в том числе для работы с крупномасштабными языковыми моделями (LLM). Один кластер Cloud TPU Pod содержит 4096 чипов TPUv4, соединённых между собой через оптические коммутаторы (OCS). По словам Google, решение OCS быстрее, дешевле и потребляют меньше энергии по сравнению с InfiniBand. Google также утверждает, что в составе её платформы на OCS приходится менее 5 % от общей стоимости. Причём данная технология даёт возможность динамически менять топологию для улучшения масштабируемости, доступности, безопасности и производительности. Отмечается, что платформа Cloud TPU v4 в 1,2–1,7 раза производительнее и расходует в 1,3–1,9 раза меньше энергии, чем платформы на базе NVIDIA A100 в системах аналогичного размера. Правда, пока компания не сравнивала TPU v4 с более новыми ускорителями NVIDIA H100 из-за их ограниченной доступности и 4-нм архитектуры (по сравнению с 7-нм у TPU v4). 
Изображение: Google Благодаря ключевым инновациям в области интерконнекта и специализированных ускорителей (DSA, Domain Specific Accelerator) платформа Google Cloud TPU v4 обеспечивает почти 10-кратный прирост в масштабировании производительности по сравнению с TPU v3. Это также позволяет повысить энергоэффективность примерно в 2–3 раза по сравнению с современными DSA ML и сократить углеродный след примерно в 20 раз по сравнению с обычными дата-центрами.
23.09.2022 [19:58], Алексей Степин
Google заявила, что использует процессоры SiFive Intelligence X280 на RISC-V вместе со своим TPUАрхитектура RISC-V продолжает понемногу набирать популярность и завоевывать внимание ведущих игроков на рынке информационных технологий. На мероприятии AI Hardware Summit в совместном выступлении ведущего архитектора SiFive и архитектора Google TPU было отмечено, что Google уже использует процессоры с ядрами Intelligence X280. Эти ядра — один из вариантов воплощения архитектуры RISC-V, из продвигаемых SiFive. Анонс Intelligence X280 состоялся ещё в апреле 2021 года, когда SiFive выпустила апдейт 21G1, основной упор в котором был сделан на максимизацию характеристик уже существующих ядер RISC-V в области операций с плавающей запятой. 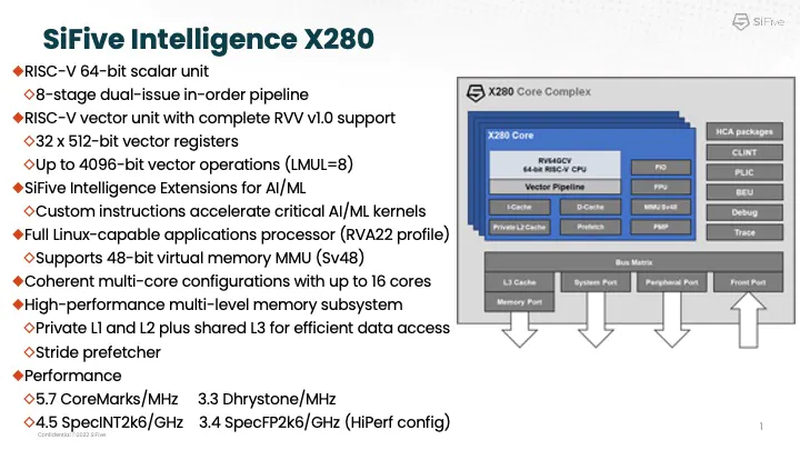
Процессорное ядро Intelligence X280 и его возможности. Источник: SiFive Как следует из названия, данный вариант процессора оптимизирован под задачи машинного интеллекта: ядра RISC-V в нём дополнены векторными конвейерами RISC-V Vector (RVV) с производительностью 4,5 Тфлопс BF16 и 9,2 Топс INT8 на ядро. Одной из самых интересных технологий в Intelligence X280 является интерфейс Vector Coprocessor Interface eXtension (VCIX). 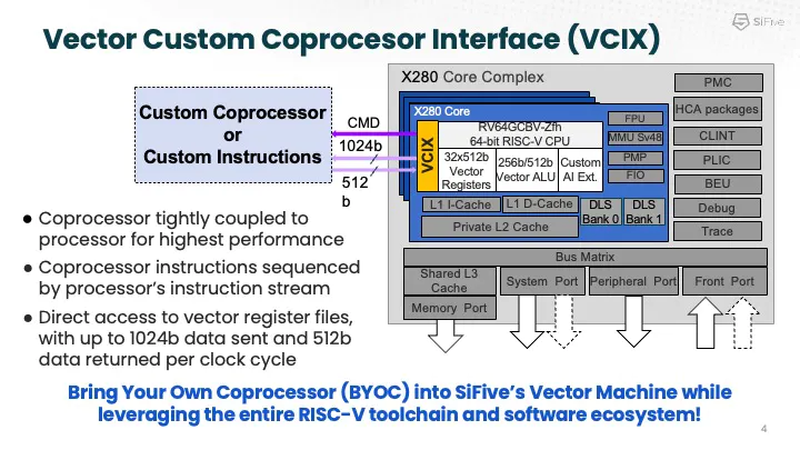
Устройство VCIX. Источник: SiFive Он позволяет подключать внешние ускорители векторных операций напрямую к регистровому файлу X280, минуя основную шину и кеши. Такой подход минимизирует накладные расходы и не требует использования специальных средств при программировании системы, поскольку связка из X280 и подключённого по VCIX ускорителя работает полностью прозрачно в рамках стандартных средств разработки SiFive. 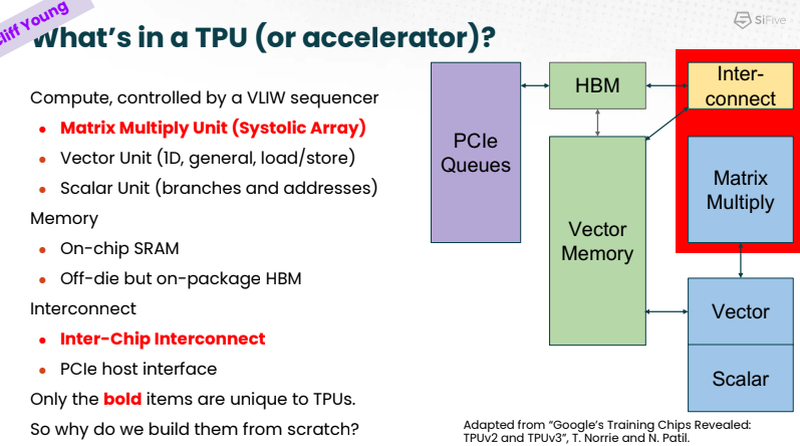
Сильные стороны Google TPU. Источник: SiFive На саммите в Санта-Кларе разработчики SiFive и Google TPU рассказали, что процессоры Intelligence X280 используются в качестве хост-процессоров к ускорителям систолической векторной математики Google MXU; правда, о масштабах внедрения RISC-V в Google сведений приведено не было. 
Разделение труда Intelligence X280 и Google TPU. Источник: SiFive Ранее уже появлялась информация, что Google активно тестирует ASIC сторонних разработчиков в связке со своим TPU, в частности, чипы Broadcom, дабы разгрузить его от второстепенных задач и сделать упор на сильных сторонах — матричной математике и быстром интерконнекте. Похоже, SiFive Intelligence X280 решает задачу интеграции подобного рода задач более изящно: как отметил в выступлении Клифф Янг (Cliff Young), архитектор Google TPU, с помощью VCIX можно построить машину, позволяющую усидеть на двух стульях (build a machine that lets you have your cake and eat it too). |
|