Материалы по тегу: gpu
|
16.10.2025 [16:44], Сергей Карасёв
Pegatron представила ИИ-сервер AS501-4A1-16I1 с СЖО и 16 ускорителями AMD Instinct MI355XPegatron анонсировала высокопроизводительный сервер AS501-4A1-16I1 с СЖО для задач НРС, а также ресурсоёмких приложений ИИ, включая инференс и обучение больших языковых моделей. Устройство выполнено в форм-факторе 5OU на аппаратной платформе AMD. До восьми серверов AS501-4A1-16I1 могут быть установлены в стойку RA5100-128I1. Это позволяет сформировать ИИ-систему высокой плотности, насчитывающую до 32 процессоров EPYC 9005 и до 128 ускорителей Instinct MI355X. Конструкция системы включает два CPU-узла и два лотка GPU. Каждая из CPU-секций допускает установку двух процессоров AMD EPYC 9005 Turin с показателем TDP до 500 Вт и 24 модулей оперативной памяти DDR5-6400 RDIMM. Таким образом, в общей сложности могут быть задействованы четыре чипа EPYC и 48 модулей ОЗУ. В свою очередь, каждый из GPU-лотков оснащается восемью ускорителями AMD Instinct MI355X, которые несут на борту 288 Гбайт памяти HBM3E с пропускной способностью до 8 Тбайт/с. В общей сложности реализованы 12 слотов PCIe 5.0 x16 FHHL, в которые установлены десять однопортовых сетевых адаптеров 400GbE и два двухпортовых адаптера 10GbE 
Источник изображения: Pegatron В оснащение входят контроллер Aspeed AST2600, два сетевых порта 1GbE (RJ45), выделенный сетевой порт управления (RJ45), последовательный порт (разъём Micro-USB), интерфейсы USB 2.0 Type-C и Mini-DP. В дополнение к СЖО имеются десять вентиляторов охлаждения. Применяется шина питания ORv3 на 48 В DC.
15.10.2025 [09:13], Сергей Карасёв
Intel представила GPU-ускоритель Crescent Island для ИИ-инференсаКорпорация Intel, как и ожидалось, представила на мероприятии OCP Global Summit в Сан-Хосе (Калифорния, США) графический процессор нового поколения для дата-центров. Изделие с кодовым названием Crescent Island специально оптимизировано для задач ИИ-инференса. В основу GPU положена архитектура Xe3P. Она представляет собой усовершенствованную версию Xe3, которая используется в процессорах Core Ultra 300 семейства Panther Lake для ноутбуков и компактных настольных ПК. Говорится об улучшенном показателе производительности в расчёте на 1 Вт затрачиваемой энергии. Ускоритель на базе Crescent Island получит 160 Гбайт памяти LPDDR5X. Как отмечает ресурс Tom's Hardware, максимальный объём чипов LPDDR5X составляет 8 Гбайт. При этом используются два 16-бит канала памяти, что в сумме даёт 32 бита. Таким образом, для обеспечения 160 Гбайт памяти требуются 20 чипов LPDDR5X. Это означает, что ускоритель получит либо один массивный GPU с 640-бит интерфейсом памяти для подключения всех 20 чипов LPDDR5X, либо два менее крупных процессора с 320-бит интерфейсом, каждый из которых будет обслуживать 10 чипов LPDDR5X. 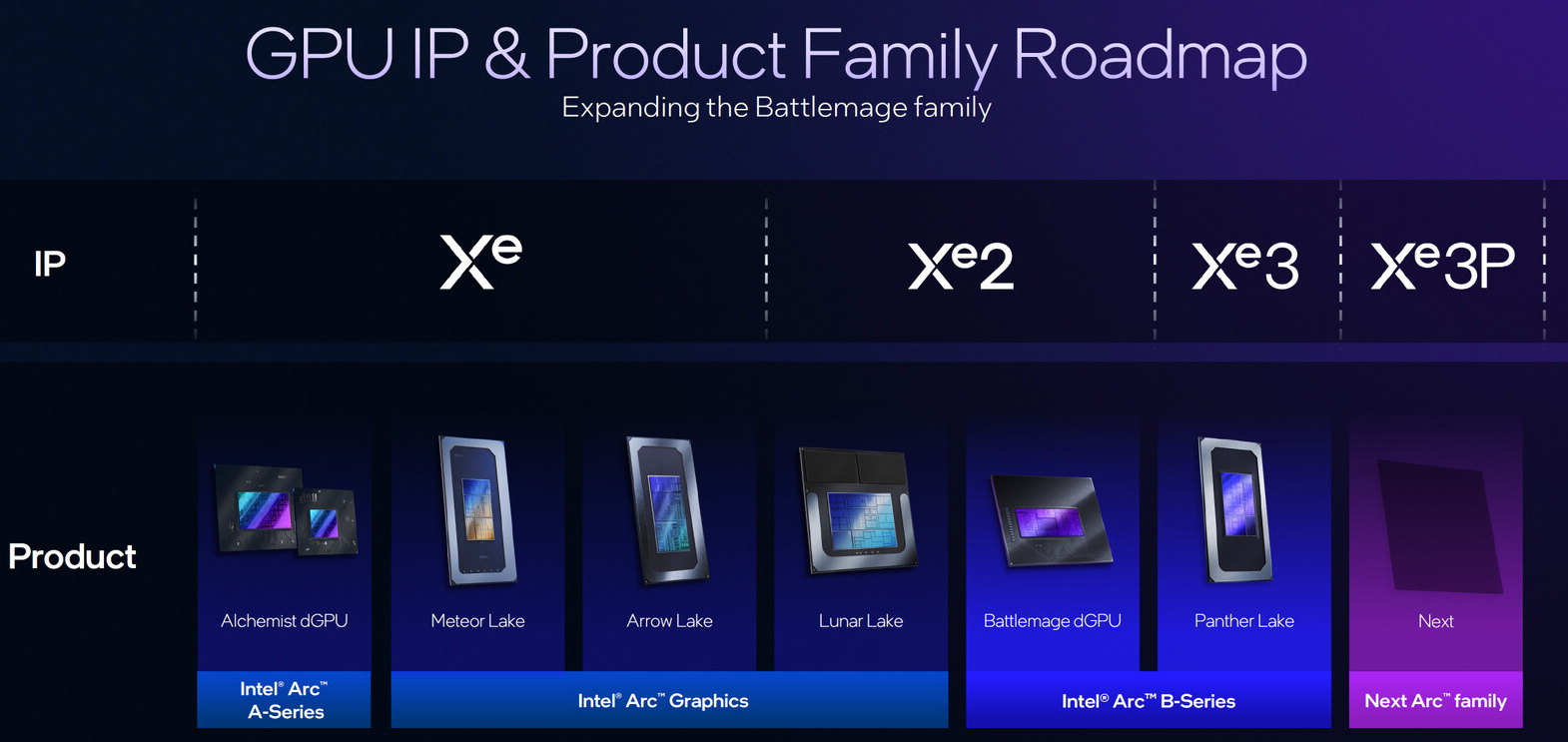
Источник изображения: Intel Прочие технические детали не раскрываются. При этом Intel отмечает, что изделие Crescent Island предназначено для использования в серверах с воздушным охлаждением. GPU поддерживает работу с широким спектром типов данных, благодаря чему может применяться в составе облачных платформ «токен как услуга» (tokens-as-a-service). Пробные поставки новинки планируется начать во II половине 2026 года, тогда как широкая доступность ожидается не ранее 2027-го. Решениям на основе Crescent Island предстоит конкурировать с ИИ-ускорителями AMD и NVIDIA следующего поколения, такими как Rubin CPX.
10.10.2025 [10:11], Сергей Карасёв
Intel готовит новый GPU-ускоритель, оптимизированный для инференсаКорпорация Intel в ходе мероприятия Intel Tech Tour Arizona сообщила о подготовке новых ИИ-ускорителей на базе GPU. Речь идёт об изделиях, специально оптимизированных для задач инференса. Кроме того, компания поделилась планами по развитию ИИ-продуктов в целом. Ранее предполагалось, что в 2025 году Intel выведет на рынок ускорители Falcon Shores. Изначально планировалось, что это будут гибридные решения, содержащие блоки CPU и GPU. Однако впоследствии Intel сделала выбор в пользу конфигурации исключительно на основе GPU. А затем корпорация и вовсе заявила, что на коммерческом рынке изделия Falcon Shores не появятся. Вместо этого Intel решила сфокусировать внимание на выпуске ускорителей Jaguar Shores. Войдёт ли готовящийся к выпуску GPU для инференса в семейство Jaguar Shores, пока не ясно. Подробности о новинке Intel обещает раскрыть в ходе предстоящего мероприятия 2025 OCP Global Summit, которое пройдёт с 13 по 16 октября в Сан-Хосе (Калифорния, США). На сегодняшний день известно, что устройство получит улучшенную память с высокой пропускной способностью. Изделие будет ориентировано на корпоративный сектор. 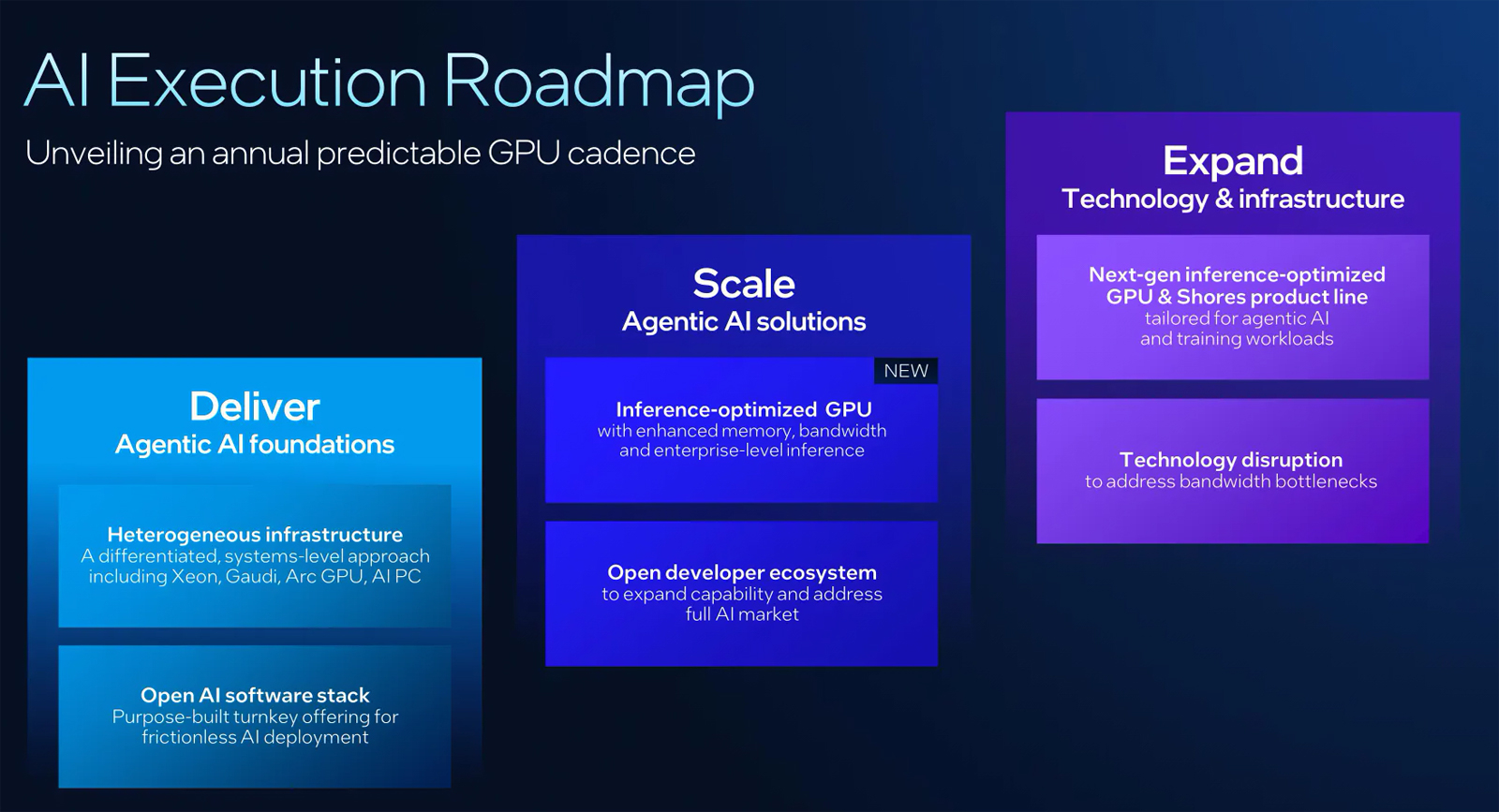
Источник изображения: Intel «Мы активно работаем над оптимизированным для инференса GPU, о котором подробнее расскажем на конференции OCP», — сообщил технический директор Intel Сачин Катти (Sachin Katti). Кроме того, Intel объявила о намерении перейти на ежегодный график выпуска ИИ-продуктов следующего поколения. Предполагается, что это поможет укрепить позиции на глобальном рынке ИИ, на котором корпорация уступила позиции NVIDIA. При этом Intel подчёркивает, что на ближайшую перспективу Jaguar Shores является основным приоритетом в области развития высокопроизводительных решений для ИИ-инфраструктуры.
07.10.2025 [15:52], Сергей Карасёв
Китайские компании укрепляют позиции на местном рынке ИИ-ускорителей — часть основана выходцами из AMD и NVIDIAРазработчики из Китая, как сообщает TrendForce, добились существенных успехов в создании ускорителей. Речь идёт о решениях на основе ASIC и GPU, призванных составить конкуренцию картам NVIDIA, поставки которых в КНР ограничены в связи с американскими санкциями. Разработкой ИИ-ускорителей в КНР, помимо Huawei HiSilicon с её решениями Ascend, занимаются несколько других крупных игроков, быстро укрепляющих позиции. В их число входят Moore Threads, MetaX и Cambricon. Генеральный директор NVIDIA Дженсен Хуанг (Jensen Huang) недавно отметил значительные достижения Китая в плане разработки и производства микросхем, заявив, что страна отстаёт от США на «наносекунды». По его словам, доля NVIDIA на китайском рынке ИИ-ускорителей за последние годы сократилась с 95 % до 50 %. Хуан отмечает, что более половины мировых ИИ-исследователей сосредоточены в Китае, что говорит о большом потенциале страны в соответствующей области. Moore Threads заявляет, что является единственной в Китае компанией, которая в настоящее время серийно производит полнофункциональные GPU. Эта фирма уже представила четыре продуктовых семейства, включая Sudi (2021 год), Chunxiao (2022), Quyuan (2023) и Pinghu (2024). Решения первых двух серий применяются в настольных системах и рабочих станциях, двух других — в составе ИИ-платформ. Отмечается, что основатель и генеральный директор Moore Threads Джеймс Чжан Цзяньчжун (James Zhang Jianzhong) в течение 14 лет работал в NVIDIA, в частности, занимал должность вице-президента и генерального менеджера этой компании по операциям в Китае. 
Источник изображения: Moore Threads В MetaX трудятся выходцы из AMD. Так, основатель MetaX Чэнь Вэйлян (Chen Weiliang) с 2007 года работал в качестве старшего директора в шанхайском представительстве AMD, откуда ушел в 2020-м. Технические директора MetaX Пэн Ли (Peng Li) и Ян Цзянь (Yang Jian) также имеют опыт работы в AMD. Компания MetaX предлагает ускорители для обучения ИИ-моделей и инференса, а также GPU-серверы. В 2024 году на эти продукты пришлось соответственно 68,99 % и 28,29 % от общей выручки компании. Однако, ни MetaX, ни Moore Threads пока не вышли на уровень прибыльности. В свою очередь, фирма Cambricon, основанная в 2016 году братьями Чэнь Юньцзи (Chen Yunji) и Чэнь Тяньши (Chen Tianshi), в I половине 2025 года показала чистую прибыль в размере примерно ¥1 млрд ($140 млн) против ¥530 млн убытков годом ранее. В сентябре Cambricon получила одобрение со стороны регулирующих органов КНР на размещение акций на сумму ¥3,99 млрд (около $559,6 млн). Компания прогнозирует, что её выручка в текущем году увеличится на 317–483 % и составит от ¥5 до ¥7 млрд. Компания проектирует свой флагманский ИИ-ускоритель Siyuan 690, который, как ожидается, по производительности будет сопоставим с NVIDIA H100.
02.10.2025 [10:56], Сергей Карасёв
РСК представила внешний JBOG-массив RSC ScaleStream-CГруппа компаний РСК представила на международной конференции «Суперкомпьютерные дни в России», прошедшей в МГУ имени Ломоносова, внешний массив PCIe-коммутации RSC ScaleStream-C (JBOG). Это решение предназначено для установки ускорителей GPU/TPU с целью повышения производительности серверов при работе с различными ресурсоёмкими приложениями, включая задачи ИИ и НРС. Решение RSC ScaleStream-C выполнено в форм-факторе 3U. Допускается установка до десяти карт с интерфейсом PCIe x16 (до 600 Вт), связанных интерконнектом NVLink. При использовании ускорителей на базе GPU применяется гибридное охлаждение, при работе с TPU — воздушное. Питание обеспечивают четыре блока мощностью 2200 Вт каждый. Массив может монтироваться в стандартную 19″ серверную стойку. Задействованы средства управления и мониторинга на базе Redfish, RESTful API, GUI разработки РСК. К системе RSC ScaleStream-C могут быть подсоединены до четырёх серверов посредством внешних кабелей на базе стандарта PCIe 4.0 x16. Ресурсы GPU/TPU могут динамически перераспределяться между подключенными серверами, что, как утверждается, обеспечивает уникальные возможности по созданию оптимальных конфигураций под конкретную нагрузку. Благодаря этому достигается наиболее эффективное использование вычислительных мощностей ИИ-ускорителей, используемых в составе массива. РСК заявляет, что утилизация GPU в некоторых случаях повышается на десятки процентов по сравнению с применением ускорителей в составе традиционных серверных платформах. 
Источник изображения: РСК В целом, RSC ScaleStream-C обеспечивает производительность до 300 ТФлопс (FP64) на массив в случае применения десяти ускорителей NVIDIA H200. При установке карт LinQ HPQ, разработанных российской компании «ХайТэк», быстродействие достигает 960 TOPS на операциях INT8. Среди ключевых сфер применения новинки названы: машинное обучение и ИИ (инференс и работа с большими языковыми моделями), НРС-нагрузки (научные исследования и моделирование), анализ больших данных, виртуализация, криптография и блокчейн (майнинг криптовалют и задачи распределенных реестров).
22.09.2025 [16:44], Сергей Карасёв
OpenYard представила российский GPU-сервер HN203I на базе Intel Xeon 6Российский разработчик и производитель серверного оборудования OpenYard сообщил о создании флагманской системы HN203I на аппаратной платформе Intel Xeon 6. Сервер выполнен в формате 2OU в соответствии со стандартом Open Rack v3.0 (опционально Open Rack v2.2). «HN203I — это технологический скачок для российской серверной индустрии. Мы создаём флагманскую платформу, которая сочетает в себе максимальную производительность, энергоэффективность и простоту эксплуатации», — говорит компания. Возможна установка двух процессоров Intel Xeon 6700E (Sierra Forest-SP) или Xeon 6500P/6700P (Granite Rapids-SP) с показателем TDP до 350 Вт. Доступны 32 слота для модулей оперативной памяти DDR5 с поддержкой изделий RDIMM ёмкостью до 128 Гбайт и 3DS RDIMM ёмкостью до 256 Гбайт. Таким образом, максимальный объём ОЗУ составляет 8 Тбайт. В оснащение входят восемь слотов PCIe 5.0 x16 MCIO и три слота PCIe 5.0 x4 MCIO, разъём OCP 3.0 (PCIe 5.0 x16), два коннектора M.2 M-Key (PCIe 5.0 x2 и PCIe 5.0 x4), а также разъём M.2 Key E (PCIe 5.0 x1). Допускается монтаж десяти SFF-накопителей (NVMe) с возможностью горячей замены и четырёх LFF-устройств с интерфейсом SATA/SAS. Кроме того, могут быть установлены до четырёх PCIe-ускорителей NVIDIA H100/L40/L40S/L4. 
Источник изображения: OpenYard Модель HN203I располагает контролером ASPEED AST2600, двумя сетевыми портами управления RJ45 (по одному спереди и сзади), двумя портами USB 3.0 Type-A, интерфейсом mini-DP. Применено воздушное охлаждение, а диапазон рабочих температур простирается от +10 до +40 °C. Максимальная мощность блоков питания — 5500 Вт. Габариты составляют 537 × 801,6 × 93 мм. Управление осуществляется через BIOS OpenYard и систему OYBMC. Сервер подходит для ИИ-нагрузок, облачных сервисов, телеком-задач и гиперскейл-инфраструктуры.
22.09.2025 [13:02], Сергей Карасёв
ASRock представила видеокарты Intel Arc Pro B60 для рабочих станций с ИИКомпания ASRock анонсировала видеокарты Intel Arc Pro B60 Passive 24GB и Intel Arc Pro B60 Creator 24GB для профессиональных рабочих станций, ориентированных на задачи ИИ, большие языковые модели (LLM), дизайн, 3D-моделирование и пр. Новинки выполнены на архитектуре Intel Xe2-HPG и оснащены 24 Гбайт памяти GDDR6 со 192-битной шиной (19 Гбит/с). Модель Intel Arc Pro B60 Passive 24GB, наделённая пассивным охлаждением, имеет однослотовое исполнение. Карта будет доступна исключительно бизнес-заказчикам. В свою очередь, Intel Arc Pro B60 Creator 24GB получила активный кулер (с бесшумным режимом 0dB Silent Cooling) и двухслотовое исполнение. Обе новинки могут использоваться в конфигурациях с несколькими GPU в Linux-средах, что делает их подходящими для серверных развёртываний в рамках масштабных ИИ-платформ. 
Источник изображений: ASRock Видеокарты располагают 20 ядрами Xe2-HPG и 160 матричными движками (XMX). Частота ядра составляет 2400 МГц. Задействован интерфейс PCIe 5.0. Дополнительное питание подаётся через 8-контактный коннектор. Говорится о поддержке Microsoft DirectX 12 Ultimate. Доступны четыре интерфейса DisplayPort 2.1 — основной с поддержкой UHBR13.5 и три дополнительных с поддержкой UHBR10. Видеокарта Intel Arc Pro B60 Passive 24GB имеет размеры 190 × 112 × 19 мм и весит 566 г. Габариты Intel Arc Pro B60 Creator 24GB составляют 271 × 112 × 39 мм, масса — 1118 г.  Некоторые ретейлеры уже начали приём предварительных заказов на эти решения. Так, на сайте американского магазина Central Computers версия Intel Arc Pro B60 Creator 24GB предлагается по ориентировочной цене $600.
16.08.2025 [15:16], Сергей Карасёв
Inspur представила суперускоритель Metabrain SD200 для ИИ-моделей с триллионами параметровКитайская компания Inspur создала суперускоритель Metabrain SD200 для наиболее ресурсоёмких задач ИИ. Система, как утверждается, может работать с моделями, насчитывающими более 1 трлн параметров. Платформа Metabrain SD200 объединяет 64 карты в единый суперузел с унифицированной памятью. В основу положены открытая архитектура 3D Mesh и проприетарные коммутаторы Open Fabric Switch. Иными словами, ускорители на базе GPU, распределённые по разным серверам, объединяются посредством высокоскоростного интерконнекта в единый домен. Суперускоритель предоставляет доступ к 4 Тбайт VRAM и 64 Тбайт основной RAM. Благодаря этому возможен одновременный запуск четырёх китайских ИИ-моделей с открытым исходным кодом, включая DeepSeek R1 и Kimi K2. Кроме того, поддерживается совместная работа нескольких ИИ-агентов в режиме реального времени. 
Источник изображения: Inspur Для Metabrain SD200 заявлена низкая задержка при передаче данных, которая исчисляется «сотнями наносекунд». В распространённых сценариях инференса, предполагающих обработку небольших пакетов данных, по величине задержки система превосходит распространённые отраслевые решения. В составе новой платформы задействованы средства оптимизации. В частности, инструмент Smart Fabric Manager автоматически формирует оптимальные маршруты данных на основе характеристик нагрузки. Metabrain SD200 совместим с распространёнными фреймворками, такими как PyTorch, vllm и SGLang: благодаря этому возможен быстрый перенос существующих моделей и ИИ-агентов без необходимости переписывать программный код с нуля. Таким образом, значительно снижается стоимость миграции. В целом, реализованная технология удалённого vGPU позволяет ускорителям, распределённым по разным серверам, взаимодействовать столь же эффективно, как если бы они находились на одном хосте. При этом достигается восьмикратное расширение адресного пространства, что обеспечивает полную загрузку ресурсов и эффективную работу даже при использовании ИИ-моделей с триллионами параметров.
16.08.2025 [14:45], Сергей Карасёв
Dell представила ИИ-серверы PowerEdge R7725 и R770 на базе NVIDIA RTX Pro 6000 Blackwell Server EditionКомпания Dell анонсировала серверы PowerEdge R7725 и PowerEdge R770 в форм-факторе 2U, построенные на аппаратной платформе AMD и Intel соответственно. Новинки оснащаются ускорителями NVIDIA RTX Pro 6000 Blackwell Server Edition. 
Источник изображений: Dell Модель PowerEdge R7725 может нести на борту два процессора AMD EPYC 9005 (Turin), а также до 6 Тбайт оперативной памяти DDR5-6400 в виде 24 модулей. Доступны до восьми слотов PCIe 5.0 x8 или x16. При этом возможна установка двух GPU-ускорителей. Сервер предлагает различные варианты исполнения подсистемы хранения данных с фронтальным доступом: 12 × LFF SAS/SATA, 8/16/24 × SFF SAS/SATA, 16 × SFF SAS/SATA + 8 × U.2/NVMe или 8/16/32/40 × EDSFF E3.S. Имеется выделенный сетевой порт управления 1GbE, а дополнительно предлагается установка адаптеров с поддержкой 1GbE, 10GbE, 25GbE, 100GbE и 400GbE.  В свою очередь, вариант PowerEdge R770 комплектуется двумя чипами Intel Xeon 6 Granite Rapids с производительными Р-ядрами или Xeon 6 Sierra Forest с энергоэффективными Е-ядрами. Реализованы 32 слота для модулей оперативной памяти DDR5-6400 суммарным объёмом до 8 Тбайт. Предлагается широкий набор опций в плане установки накопителей в лицевой и тыльной частях корпуса, включая 24 × SFF SAS/SATA и 40 × EDSFF E3.S. Система может быть укомплектована четырьмя картами OCP NIC 3.0 (вплоть до 400GbE). Есть слоты PCIe 5.0 x8 и x16.  Серверы поддерживают воздушное и прямое жидкостное охлаждение (DLC). Мощность блоков питания с сертификатом 80 Plus Titanium достигает 3200 Вт. Заявлена совместимость с Canonical Ubuntu Server LTS, Windows Server (Hyper-V), Red Hat Enterprise Linux, SUSE Linux Enterprise Server и VMware ESXi.
14.08.2025 [09:21], Сергей Карасёв
Gigabyte представила MGX-сервер с восемью ускорителями NVIDIA RTX Pro 6000Компания Gigabyte расширила ассортимент серверов для ИИ-задач, анонсировав модель XL44-SX2-AAS1 в форм-факторе 4U с модульной архитектурой NVIDIA MGX. Новинка предназначена для формирования ИИ-фабрик, работы с большими языковыми моделями (LLM) корпоративного уровня, научной визуализации, создания цифрового контента и других ресурсоёмких нагрузок. Сервер допускает установку двух процессоров Intel Xeon 6700/6500 и 32 модулей оперативной памяти DDR5 RDIMM/MRDIMM. В оснащение входят до восьми ускорителей NVIDIA RTX Pro 6000 Blackwell Server Edition, которые ориентированы на требовательные приложения ИИ. Эти карты несут на борту 96 Гбайт памяти GDDR7 (ECC) с пропускной способностью до 1,6 Тбайт/с. Во фронтальной части располагаются отсеки для восьми накопителей SFF с интерфейсом PCIe 5.0 (NVMe). Есть восемь разъёмов PCIe 5.0 x16 для двухслотовых карт FHFL, а также коннектор PCIe 5.0 x16 для однослотового DPU NVIDIA BlueField-3. В конструкции задействованы коммутационная плата NVIDIA MGX PCIe 6.0 на базе ASIC ConnectX-8 и контроллер Intel X710-AT2, на базе которого реализованы два сетевых порта 10GbE. 
Источник изображения: Gigabyte За питание отвечают четыре блока с сертификатом 80 PLUS Titanium мощностью 3200 Вт каждый с резервированием по схеме 3+1, благодаря чему обеспечиваются стабильность и надёжность во время непрерывной круглосуточной эксплуатации. На лицевую панель выведены гнёзда RJ45 для сетевых кабелей и порты USB Type-A. Прочие технические характеристики сервера Gigabyte XL44-SX2-AAS1 пока не раскрываются. |
|