Материалы по тегу: интерконнект
|
17.11.2023 [21:46], Алексей Степин
PCI-SIG выпустила предварительные спецификации PCIe 7.0 и анонсировала кабели CopprLinkОрганизация PCI Special Interest Group (PCI-SIG) рассказала о последних планах по развитию интерфейса PCI Express. В числе прочего были опубликованы сведения о новом стандарте кабелей и разъёмов CopprLink для подключений PCIe 5.0/6.0. Основанная в 1992 году организация PCI-SIG опубликовала первые спецификации PCI Express в 2003 году, а сегодня без этого интерфейса невозможно представить себе ни одну мало-мальски мощную вычислительную систему. В PCI-SIG на данный момент входит свыше 950 участников. Планы по развитию PCI Express, простирающиеся до 2028 года, показывают, что разработка новых, более производительных версий шины идёт темпами, позволяющими удовлетворить требования к скорости IO-подсистем, удваивающиеся примерно каждые 3 года. В версии PCIe 7.0 планируется довести этот показатель для x16-подключений до 512 Гбайт/с. Предварительная версия стандарта (релиз 0.3) была сформирована совсем недавно. 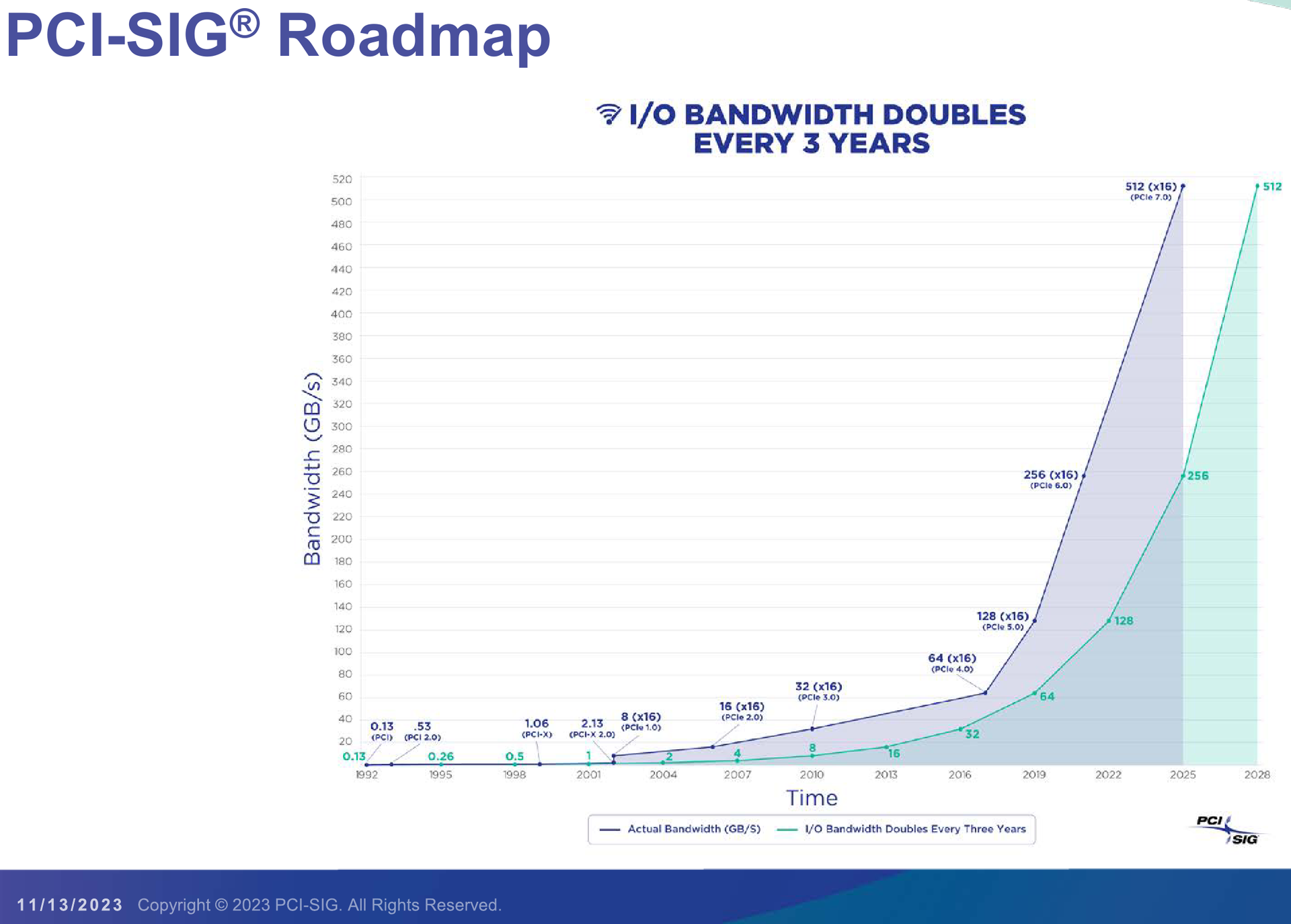
Источник изображений здесь и далее: PCI-SIG На данный момент релиз спецификаций PCI Express 7.0 ожидается в 2025 году, а массовое появление новых продуктов на их основе запланировано на 2028 год. Впрочем, первые продукты наверняка появятся чуть раньше. Во II квартале 2024 года ожидается появление первых решений с PCIe 6.0, а массовый характер программа тестирования таких устройств на соответствие стандарту примет лишь в 2025.  В августе этого года была сформирована новая рабочая группа PCI-SIG Optical Workgroup, ответственная за разработку оптического интерконнекта на базе PCI Express и взаимодействие с производителями в этой области. Задача заключается в адаптации стека технологий PCIe к оптической среде передачи данных с минимальными изменениями. Новые кабели позволят организовать соединения между стойками в пределах ЦОД в случаях, когда требуется минимальная латентность.  Однако полная замена медных кабелей не планируется — оптика дополнит медь там, где нужна большая длина соединения. Поэтому PCI-SIG ведёт разработку нового стандарта электрических кабелей под общим названием CopprLink, который должен будет заменить существующие кабели OCuLink. Возможностей последних для организации внутрисистемного интерконнекта в современных условиях уже не всегда достаточно.  Новые серверы и СХД требуют более высокой пропускной способности и гибкости топологии, что учитывается при разработке CopprLink. Эти кабели позволят как обеспечивать высокоскоростные подключения в пределах самих систем, так и соединять между собой шасси в пределах стойки. Разрабатываются и варианты для межстоечного соединения.  Вопреки непроверенным слухам, CopprLink не поддерживает передачу сколько-нибудь мощного питания и не является заменой стандарту 12VHPWR. В настоящее время спецификации CopprLink, обеспечивающего работу на скоростях PCIe 5.0/6.0, уже достигли версии 0.9. Полноценный анонс технологии должен состояться в начале 2024 года. 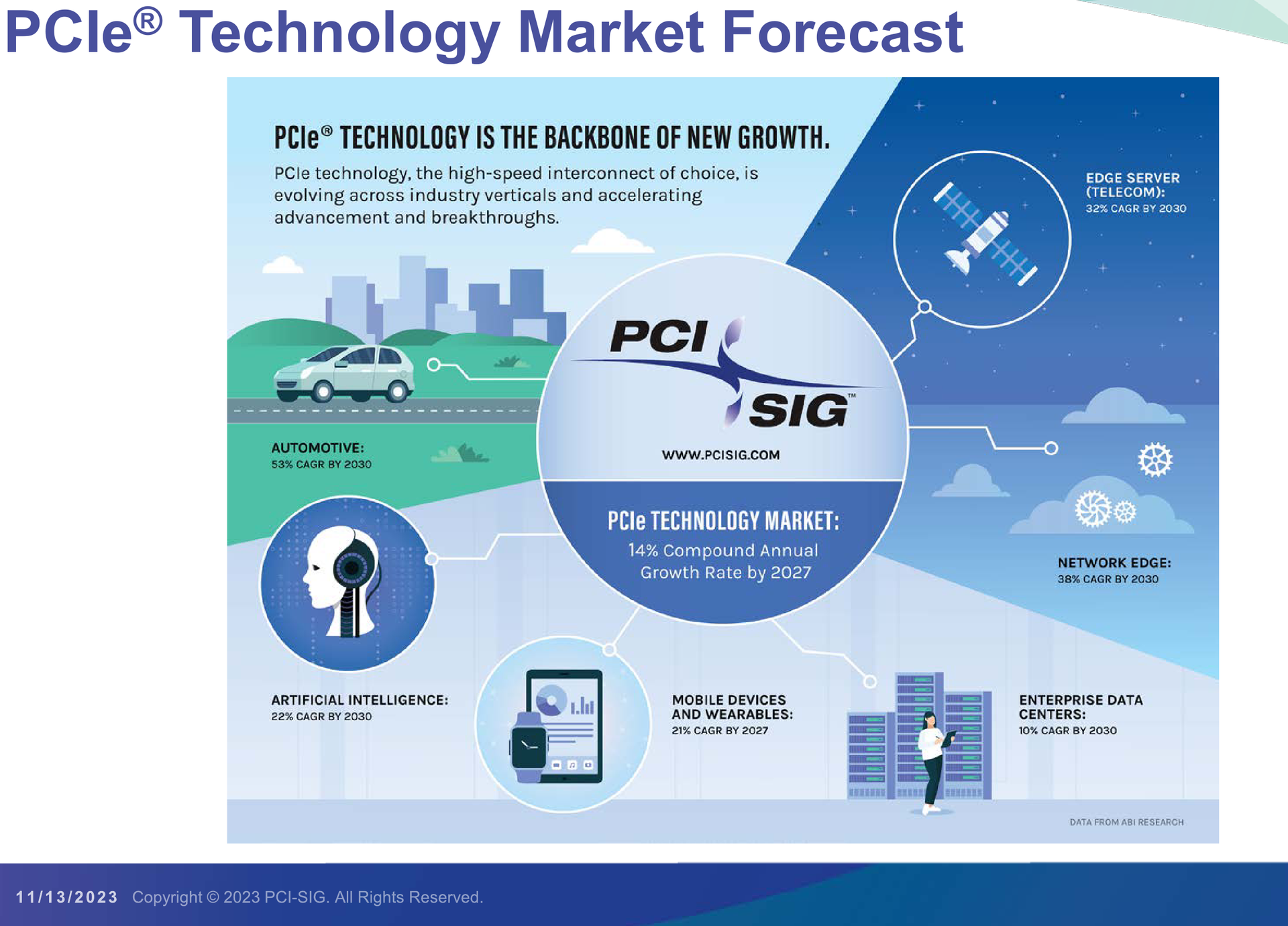 Технология PCI Express востребована во многих сегментах, от традиционных серверов и ПК до крупных ЦОД, телеком-платформ, ИИ-кластеров, умного транспорта и даже в мобильных и носимых устройствах. Ожидается, что в период до 2027 показатель CAGR для рынка PCIe-решений составит 14 %, а к концу периода он достинет объёма $10 млрд. Быстрее всего развитие будет идти в секторе автомобильных решений (CAGR 53 % до 2030 года), периферийных сетевых (38 %) и телекоммуникационных (32 %) платформ.
17.11.2023 [13:35], Сергей Карасёв
Cornelis Networks присоединилась к консорциуму Ultra EthernetКомпания Cornelis Networks, поставщик HPC-интерконнекта на базе технологий Omni-Path, объявила о вступлении в организацию Ultra Ethernet Consortium. Специалисты Cornelis помогут в разработке интерконнекта нового поколения с высокой пропускной способностью. Цель консорциума Ultra Ethernet, сформированного в июле нынешнего года, заключается в создании основанной на Ethernet открытой высокопроизводительной архитектуры с полным коммуникационным стеком, отвечающей задачам современных рабочих нагрузок ИИ и НРС. Cornelis Networks отмечает, что требования к производительности и масштабируемости приложений ИИ обнажают ограничения традиционных коммуникационных решений на основе Ethernet. А поэтому необходима разработка альтернативных систем, способных удовлетворить потребность в высокоскоростных соединениях для обмена огромными массивами данных. Cornelis Networks привнесёт в консорциум свой опыт в области высокопроизводительных сетей, а также базу актуальных и уникальных технологий. 
Источник изображения: Cornelis Networks Ожидается, что благодаря сотрудничеству коллективный опыт участников Ultra Ethernet Consortium позволит установить новые стандарты совместимости и производительности, что в конечном итоге приведет к появлению революционных коммуникационных платформ. На сегодняшний день в состав консорциума входят AMD, Arista, Broadcom, Cisco, Eviden, HPE, Intel, Meta✴, Microsoft, Oracle и другие крупные компании.
15.11.2023 [20:25], Алексей Степин
Cornelis Networks анонсировала семейство продуктов CN5000 для экосистемы Omni-Path 400GКак известно, уроненное Intel знамя Omni-Path подхватила компания Cornelis Networks, которая достаточно успешно и уверенно продолжает совершенствовать эту систему интерконнекта. Буквально на днях состоялся официальный анонс CN5000 — серии решений для экосистемы Omni-Path второго поколения, способных работать на скорости 400 Гбит/с. 
Источник изображений здесь и далее: Cornelis Networks О планах Cornelis Networks относительно CN5000 и следующих за ним поколений Omni-Path уже рассказывалось ранее. Во втором поколении разработчики отказались от Performance Scale Messaging и целиком перешли на открытый стек OFI (libfabric). По всей видимости, дела у Cornelis идут хорошо, поскольку анонс состоялся уже сейчас, хотя ранее выход CN5000 был запланирован на 2024 год. Никаких данных о сроках начала массовых поставок и ценах компания-разработчик пока не приводит, но потенциальным заказчикам уже предлагает связаться с отделом продаж.  Компания назвала главные достоинства новой технологии. Среди них высокая инфраструктурная эффективность, отличное соотношение цены и качеству, высокая защищённость соединений, реализация QoS, а также лучшая в своём классе латентность (менее 1 мкс), что особенно важно для рынков ИИ и HPC.  В основе инфраструктуры Omni-Path CN5000 лежат три ключевых продукта: хост-адаптеры PCIe 5.0, непосредственно устанавливаемые в узлы, 48-портовые 1U-коммутаторы и 576-портовые 17U-директоры. Для всех трёх доступно как воздушное, так и жидкостное охлаждение. Фабрика на базе CN5000 может содержать до 330 тыс. узлов, чего достаточно для построения крупномасштабных HPC-систем.
24.10.2023 [12:35], Сергей Карасёв
Консорциум PCI-SIG открыл тестовые лаборатории для технологии PCI ExpressКонсорциум PCI-SIG объявил об открытии авторизованных испытательных лабораторий (ATL) для тестирования технологий PCI Express (PCIe). Участники PCI-SIG смогут получить статус лаборатории, пройдя специальный квалификационный процесс. Прохождение тестирования на базе ATL позволит заинтересованным сторонам претендовать на включение в список интеграторов PCI-SIG Integrators List. Лаборатории обязаны обеспечивать возможность проведения необходимых тестовых измерений в соответствии с требованиями PCI-SIG. 
Источник изображения: PCI-SIG Первой авторизованной площадкой ATL стала Granite River Labs (GRL). Компания начала деятельность в 2010 году: она предоставляет услуги по тестированию, чтобы помочь разработчикам оборудования во внедрении технологий высокоскоростного подключения. GRL сотрудничает с более чем 500 компаниями-производителями полупроводников и различных систем, предоставляя комплексные инженерные услуги и решения для испытаний в своих центрах исследований и разработок по всему миру. Появление авторизованных тестовых лабораторий предоставляет разработчикам дополнительную возможность принять участие в программе соответствия PCI-SIG. При этом компании смогут выводить продукты с поддержкой PCIe на коммерческий рынок в соответствии со своим собственным графиком.
10.10.2023 [22:33], Алексей Степин
Опубликованы первичные спецификациии InfiniBand XDR: 200 Гбит/с на линию, 800 — на портАссоциация IBTA (InfiniBand Trade Association), ответственная за развитие данного стандарта, опубликовала новые спецификации, утверждающие характеристики стандарта InfiniBand XDR. Хотя Ethernet активно вытесняет другие сетевые стандарты благодаря быстрому росту скоростей и активному освоению всё новых технологий вроде RDMA, InfiniBand (IB) зачастую продолжает оставаться предпочтительным выбором для HPC-систем благодаря низкому уровню задержек, особенно критичному в случае крупномасштабной сети. Согласно данным Naddod, задержи у InfiniBand составляют не более 150–200 нс, в то время как для Ethernet этот показатель обычно составляет 500 нс и более. Проблему с отставанием в пропускной способности должны решить новые спецификации, опубликованные IBTA в виде томов Volume 1 Release 1.7 (ядро архитектуры InfiniBand) и Volume 2 release 1.5 (аспекты физической реализации). Наиболее важным в новых спецификациях является первичное введение и описание стандарта XDR, предусматривающего скорость передачи данных 200 Гбит/с на каждую линию. Это автоматически даёт 800 Гбит/с на стандартный IB-порт из четырёх линий, а для связи между коммутаторами может быть использован канал на восемь линий, что даёт 1600 Гбит/с. 
Текущие планы IBTA по развитиию InfiniBand. Источник: InfiniBand Trade Association Также тома содержат финальные спецификации физического уровня для InfiniBand NDR (100 Гбит/с на линию, 400 Гбит/с на порт). В данный момент полные тексты спецификаций доступны только для зарегистрированных пользователей на сайте IBTA. С кратким обзором Volume 1 Release 1.7 можно ознакомиться здесь. Помимо этого, в обновлениях описывается улучшенная поддержка крупных многопортовых коммутаторов (radix switches), а также механизмы, улучшающие обработку сетевых заторов (congestion control). Как отмечает IBTA, InfiniBand XDR должен стать новым золотым стандартом в среде ИИ и HPC благодаря оптимальному сочетанию высокой пропускной способности с низким уровнем задержек и энергоэффективностью. Дальнейшие планы IBTA включают освоение ещё более скоростных стандартов GDR и LDR к 2026 и 2030 гг. соответственно.
07.09.2023 [21:25], Алексей Степин
Cerebras готова к построению масштабных ИИ-кластеров CS-2 с 163 млн ядерНа прошедшей недавно конференции Hot Chips 2023 компания Cerebras, создатель самого большого в мире ИИ-процессора WSE-2, рассказала о своём видении будущего ИИ-систем. По мнению Cerebras, сфокусировать внимание стоит не столько на наращивании сложности отдельных чипов, сколько на решениях проблем, связанных с масштабированием кластеров. Свою презентацию Cerebras начала с любопытных фактов: за прошедшие пять лет сложность ИИ-моделей возросла в 40 тыс. раз. И этот темп явно опережает темпы развития чипов-ускорителей. Хотя налицо прогресс и в техпроцессах (5x), и в архитектуре (14x), и во внедрении более эффективных для ИИ форматов данных, но наибольший прирост производительности обеспечивает именно возможность эффективного масштабирования. 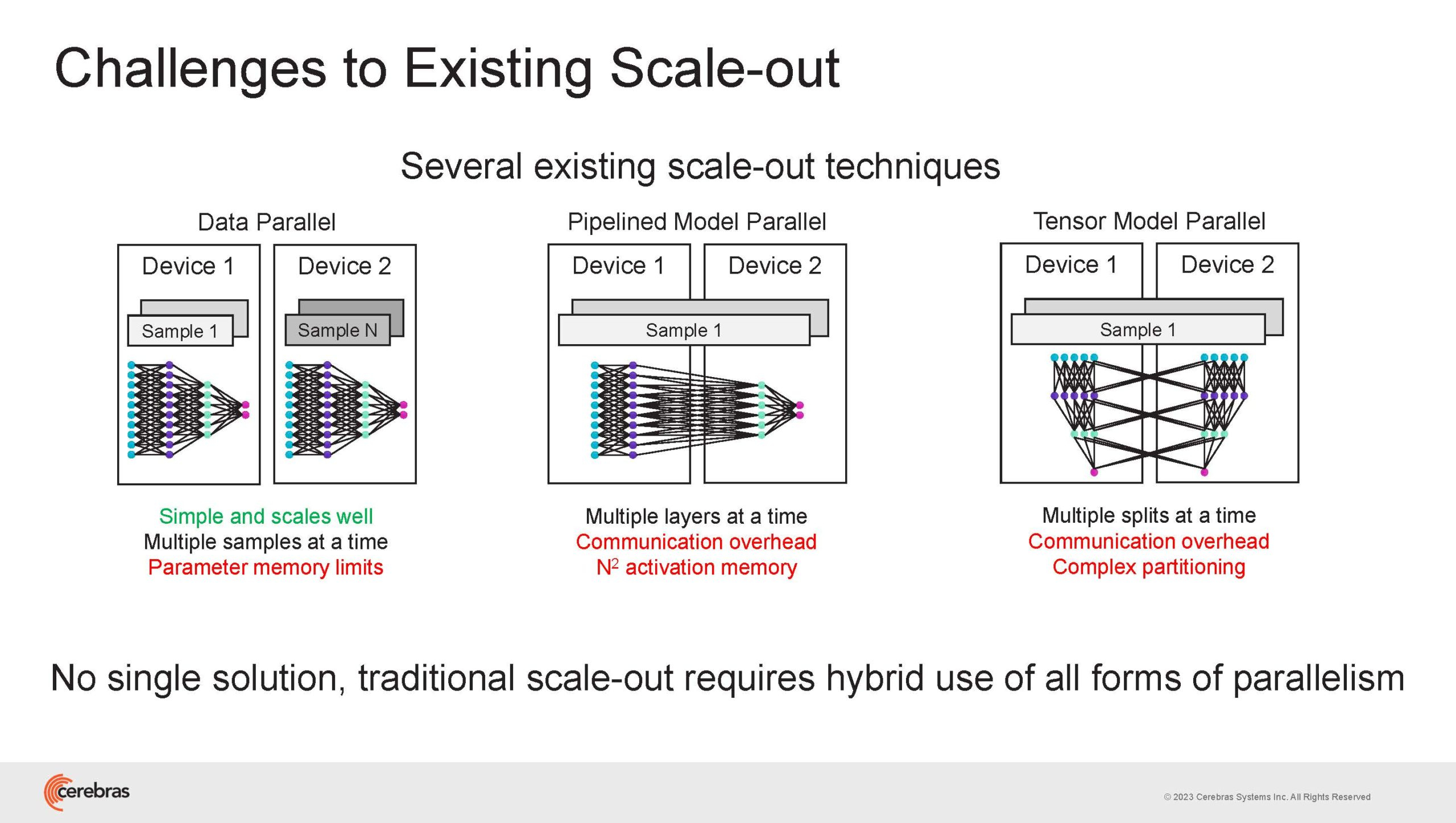
Источник изображений здесь и далее: Cerebras (via ServeTheHome) Однако и этого недостаточно — 600-кратный прирост от кластеризации явно теряется на фоне 40-тыс. усложнения самих нейросетей. А дальнейший рост масштабов ИИ-комплексов в их классическом виде, состоящих из множества «малых» ускорителей, неизбежно приводит к проблемам с организацией памяти, интерконнекта и вычислительных мощностей. 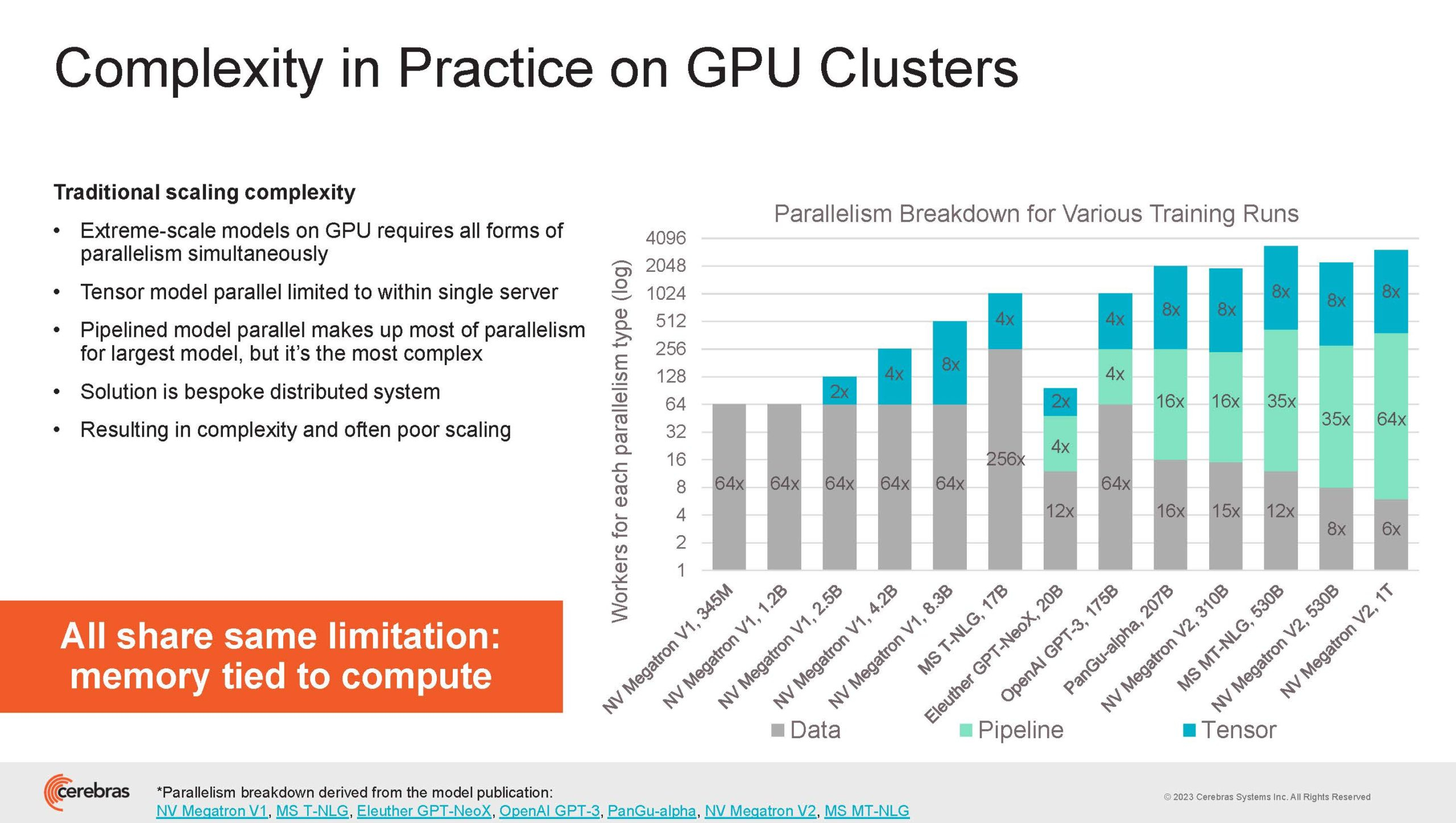 В итоге решение любой задачи в таких системах часто упирается в необходимость тончайшей, но при этом далеко не всегда эффективной оптимизации разделения ресурсов. При этом разные методы масштабирования имеют свои проблемы — узким местом могут оказаться и память, и интерконнект, и конкретный подход к организации кластера. 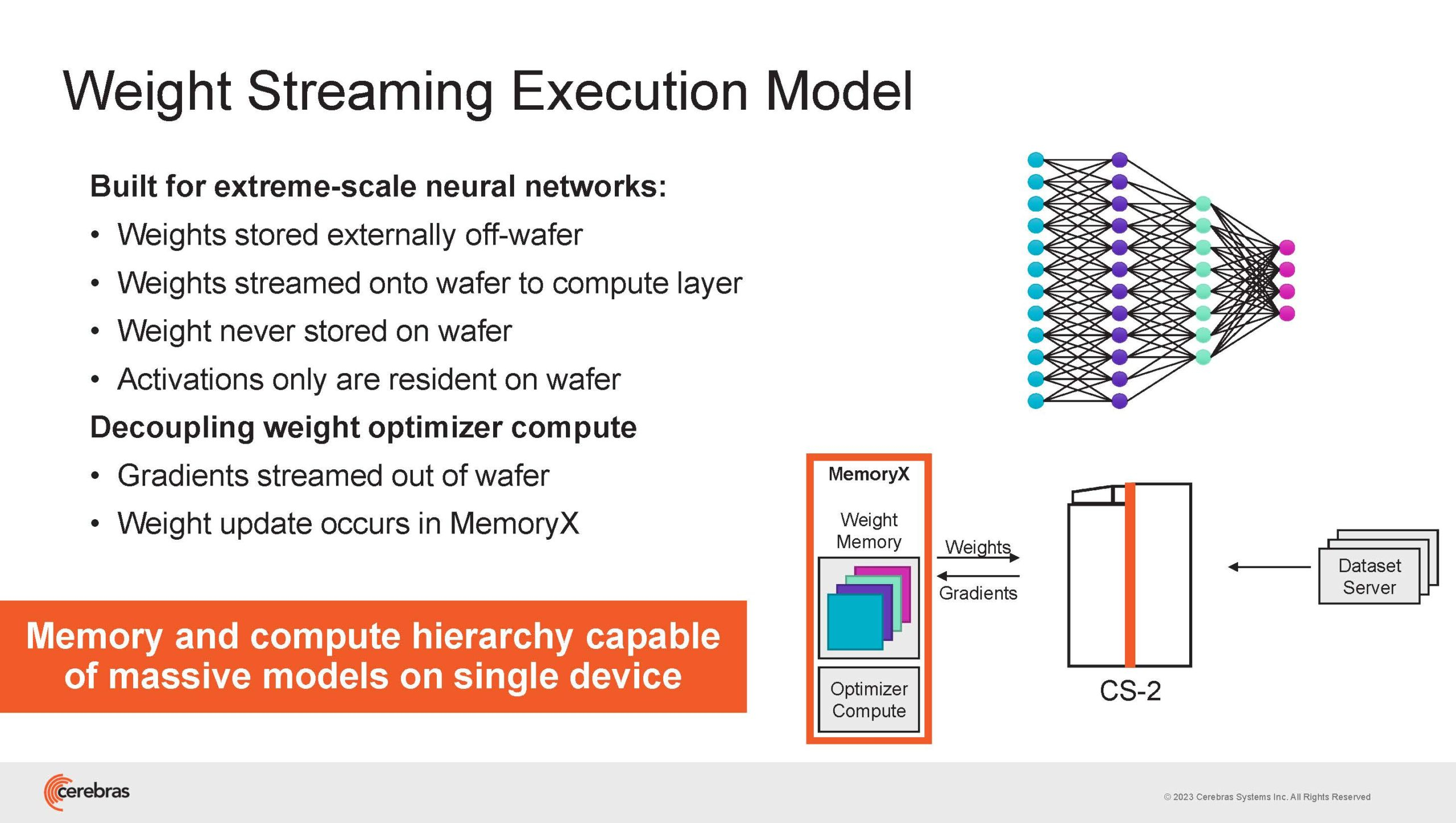 Cerebras же предлагает совершенно иной подход. Выход компания видит в создании огромных чипов-кластеров, таких, как 7-нм Cerebras WSE-2. Этот чип на сегодня можно назвать самым большим в индустрии: его площадь составляет более 45 тыс. мм2, при этом он содержит 2,6 трлн транзисторов и имеет 850 тыс. ядер, дополненных 40 Гбайт сверхбыстрой памяти. Что интереснее, кластер на базе CS-2 представляется с точки зрения исполняемой модели, как единая система. 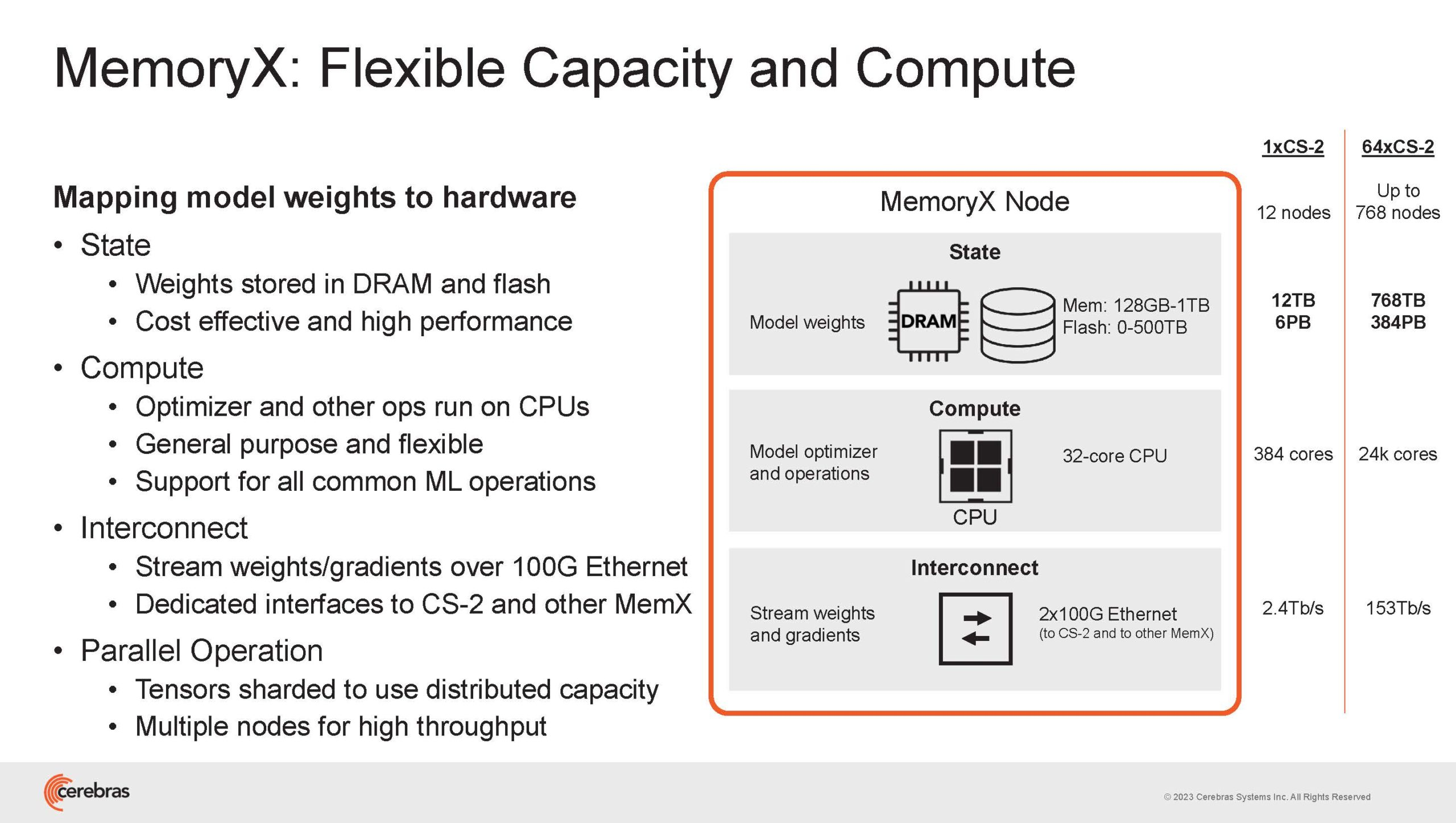 Сама по себе сложность WSE-2 и платформы CS-2 на его основе такова, что позволяет запускать модели практически любых размеров, благо весовые коэффициенты чип в себе не хранит, а подгружает извне с помощью подсистемы MemoryX. При этом сама по себе платформа CS-2 допускает и дальнейшее масштабирование: с помощью интерконнекта SwarmX в единый кластер можно объединить до 192 таких машин, что в теории позволит поднять производительность до 8+ Эфлопс. 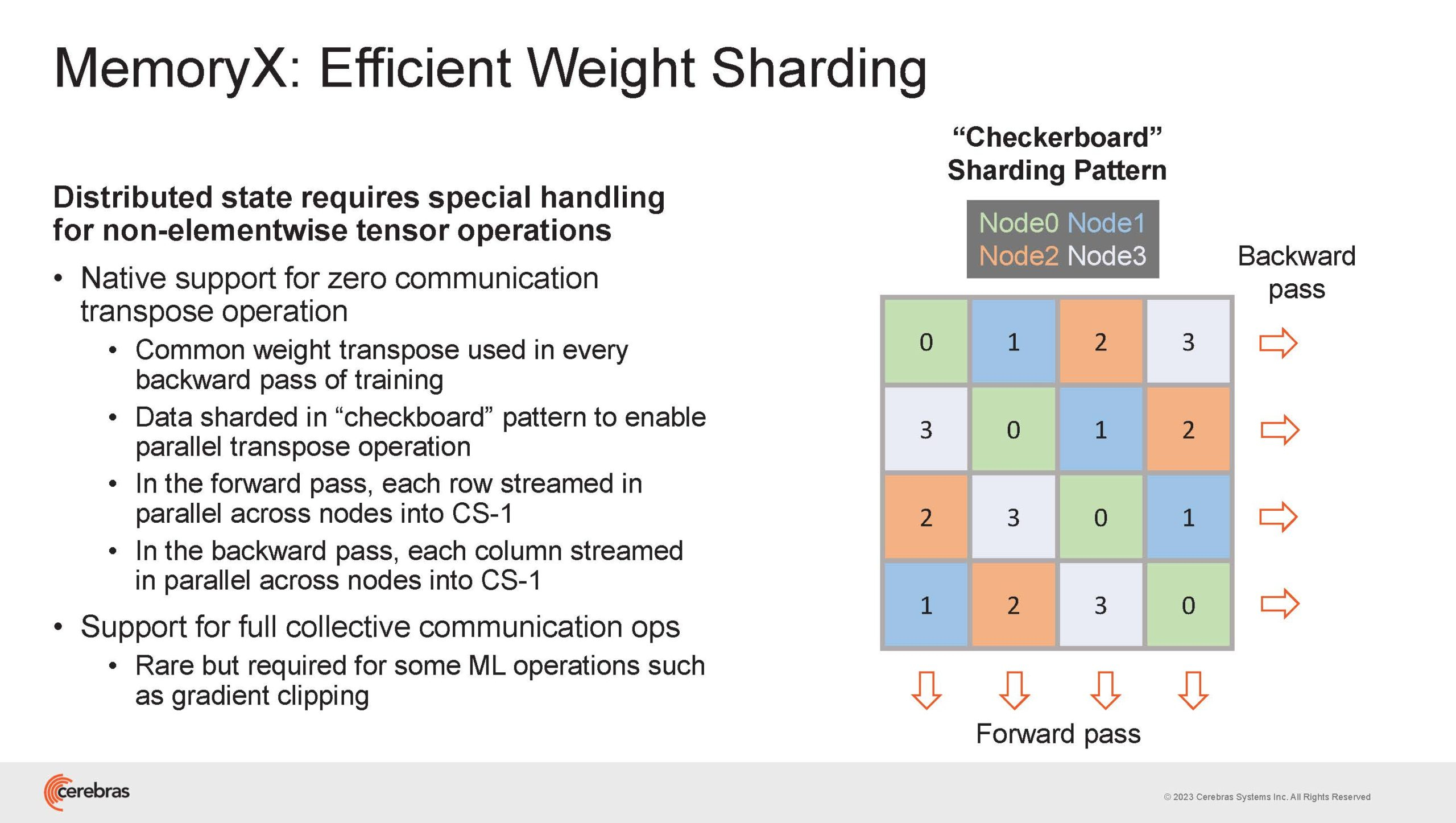 Подсистема MemoryX включает в себя 12 узлов, за оптимизацию модели в ней отвечают 32-ядерные процессоры, а веса хранятся как в DRAM, так и во флеш-памяти — объёмы этих подсистем составляют 12 Тбайт и 6 Пбайт соответственно. Каждый узел имеет по 2 порта 100GbE — один для закачки данных в CS-2, второй для общения с другими MemoryX в кластере. Оптимизация данных производится на процессорах MemoryX, «мегачипы» CS-2 для этого не используются. 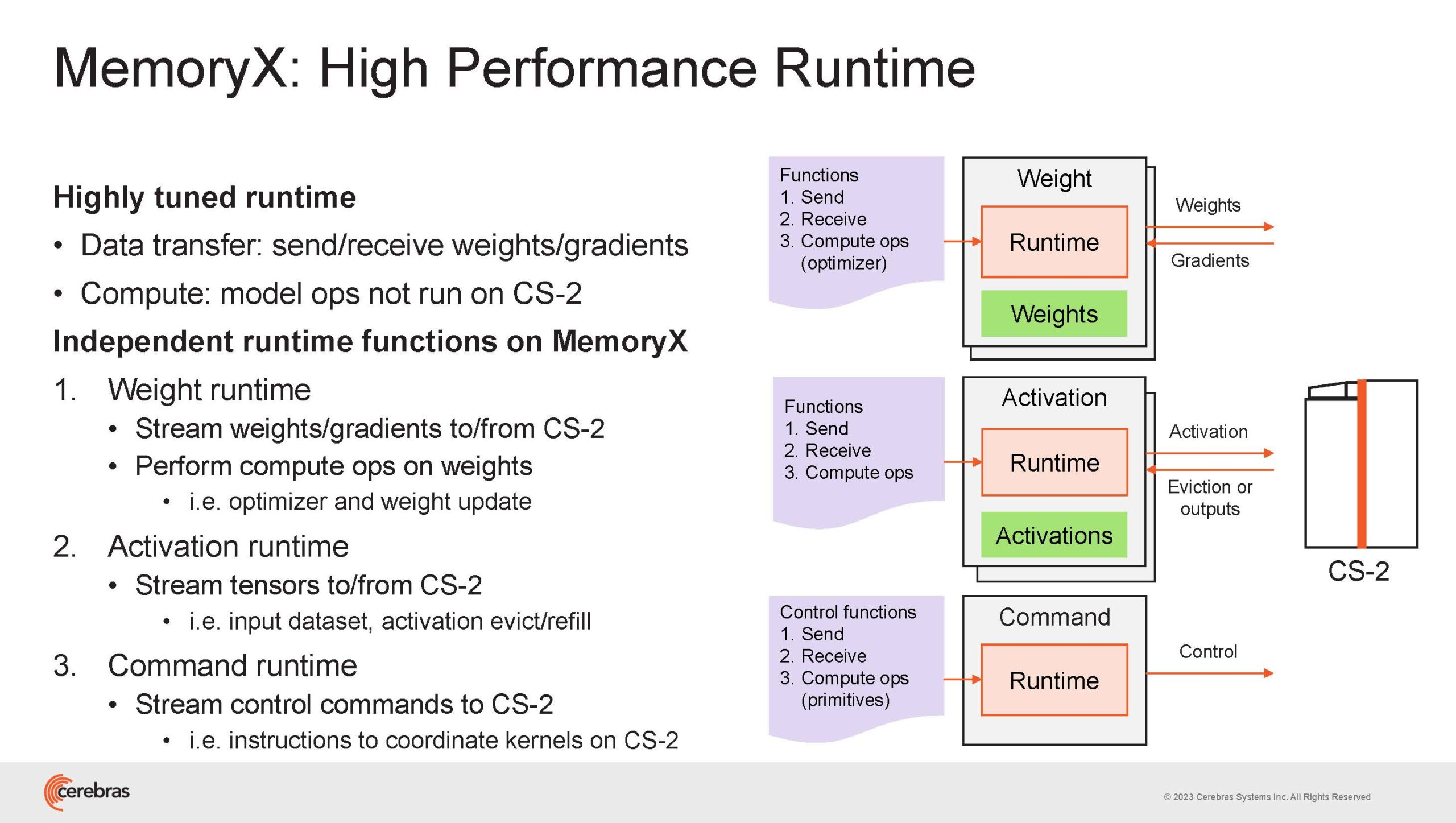 Подсистема интерконнекта SwarmX базируется на 100GbE с поддержкой RoCE DRMA, но имеет ряд особенностей: на каждые четыре системы CS-2 приходтся 12 узлов SwarmX c производительностью интерконнекта 7,2 Тбит/с. Трансляция и редуцирование данных осуществляются с коэффициентом 1:4, причём и здесь используются силы собственных 32-ядерных процессоров, а не ресурсы CS-2. Топологически SwarmX имеет двухслойную конфигурацию spine-leaf и обеспечивает соединение типа all-to-all, при этом каждая CS-2 имеет свой канал с пропускной способностью 1,2 Тбит/с. 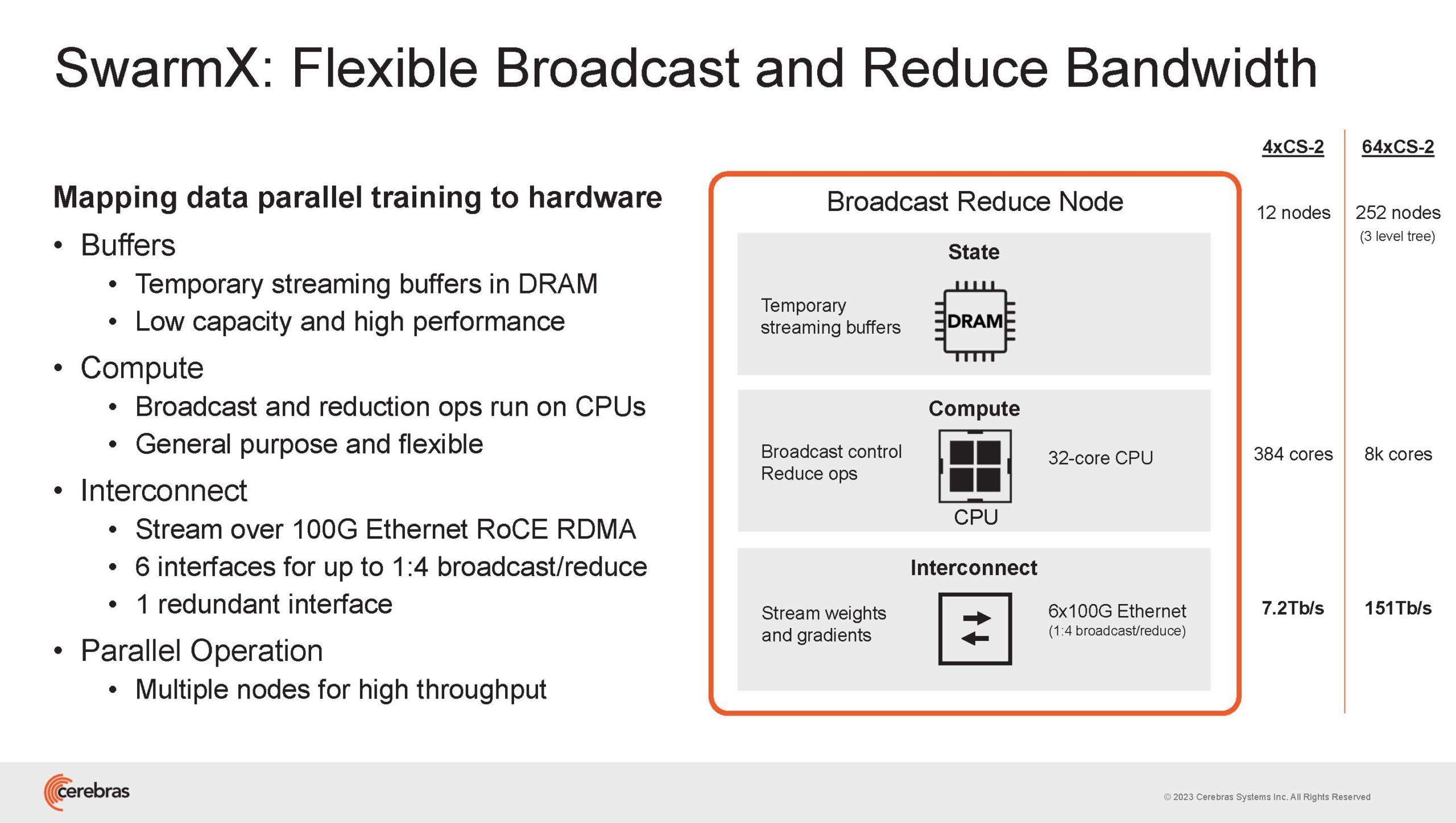 Сочетание MemoryX и SwarmX позволяет делать кластеры на базе CS-2 крайне гибкими: размер модели ограничивается лишь ёмкостью узлов MemoryX, а степень параллелизма — их количеством. При этом интерконнект обладает достаточной степенью избыточности, чтобы говорить об отсутствии единых точек отказа. 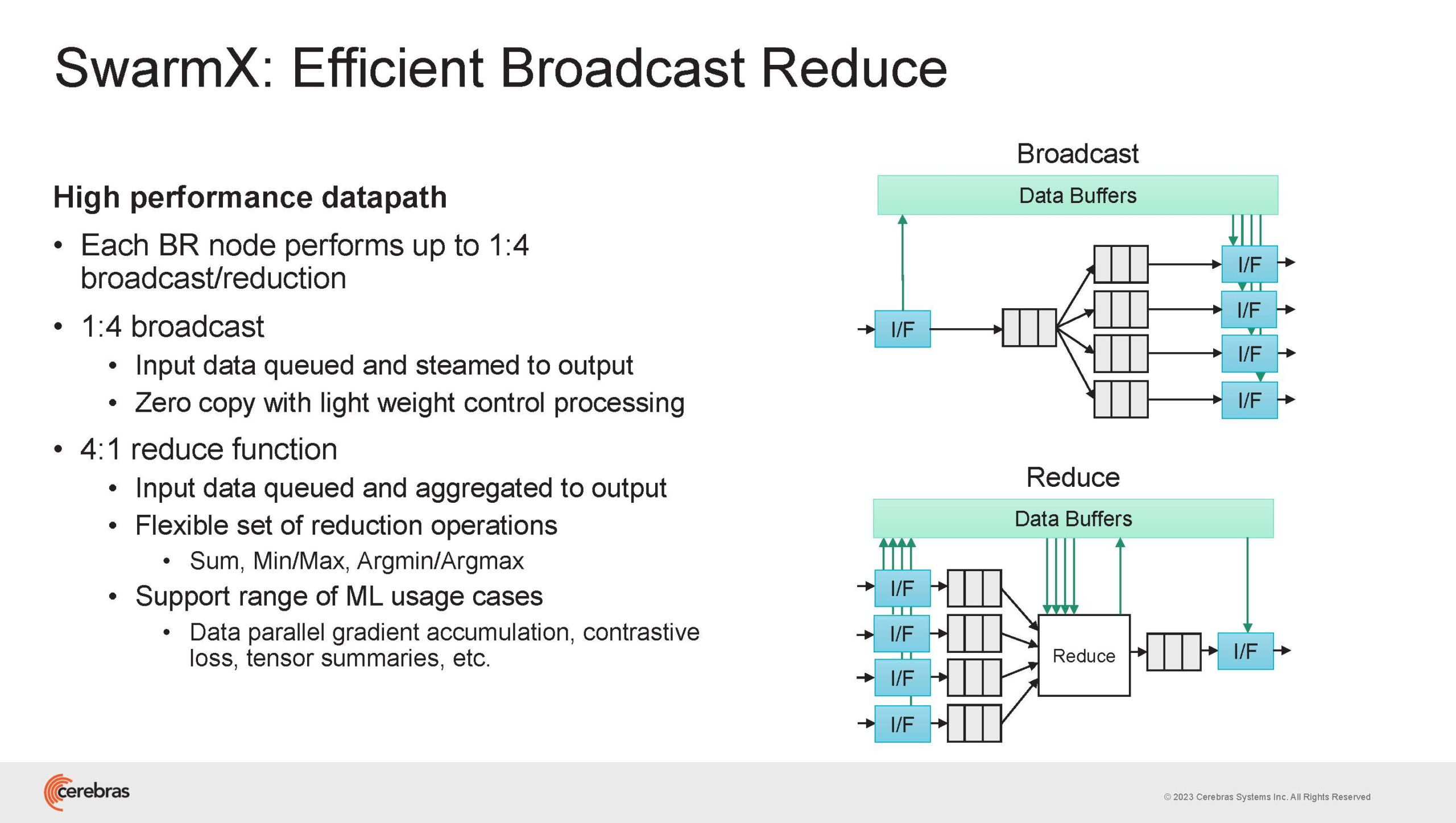 Таким образом, Cerebras имеет на руках всё необходимое для запуска самых сложных моделей искусственного интеллекта. Уже сравнительно немолодой кластер Andromeda, включающий всего 16 платформ CS-2, способен «натаскивать» за считанные недели нейросети размерностью до 13 млрд параметров. При этом масштабирование по размеру модели не требует серьёзного вмешательства в программный код, в отличие от классического подхода для ускорителей NVIDIA. Фактически для сетей и с 1, и со 100 млрд параметров используется один и тот же код. 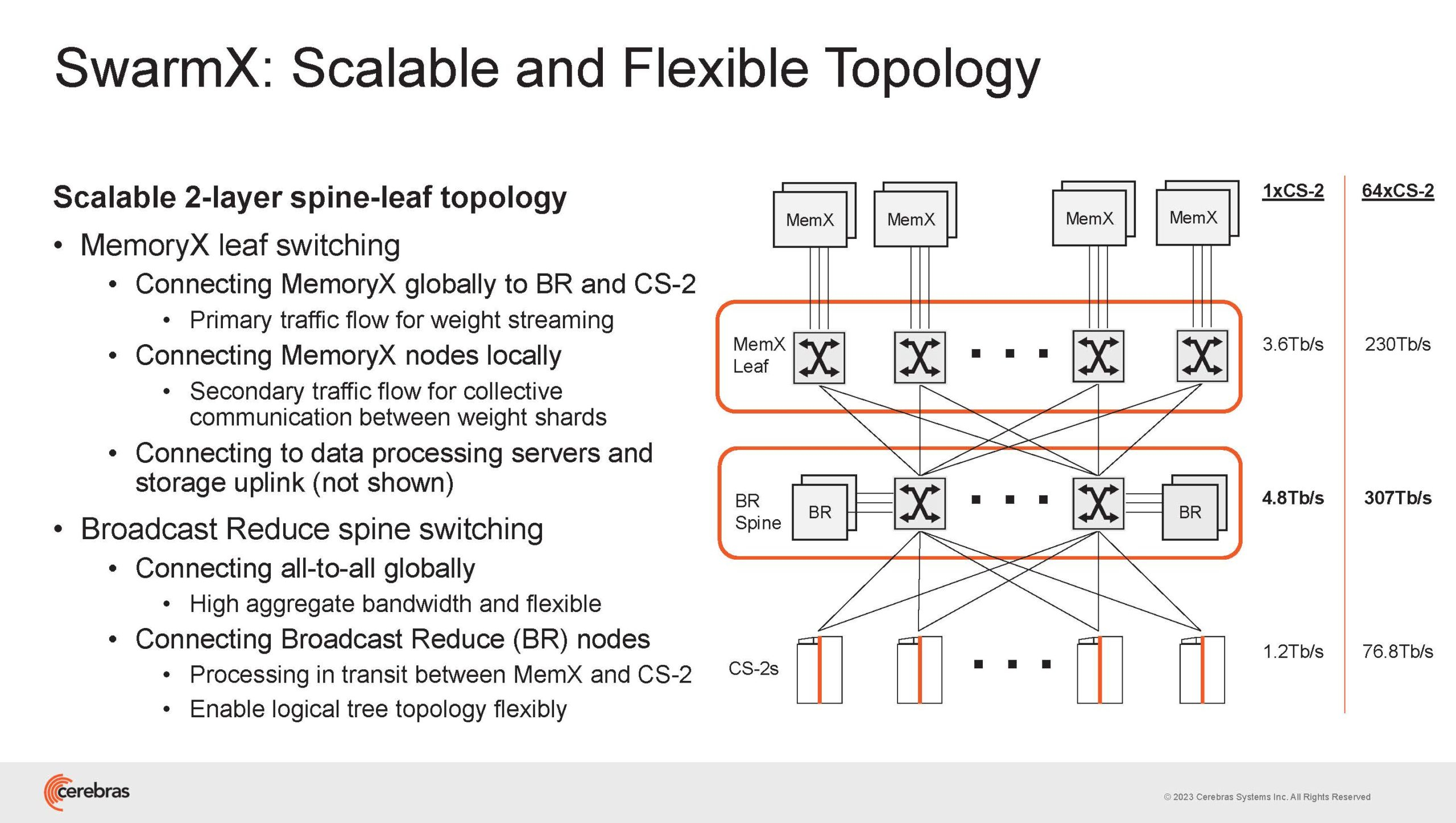 Более мощный 64-узловой комплекс Condor Galaxy 1 (CG-1), располагающий 54 млн ИИ-ядер и развивающий до 4 Эфлопс уже доказал, что подход к масштабированию, продвигаемый Cerebras, оправдывает себя. Он успешно обучил первую публичную модель с 3 млрд параметров, причём по возможностям она приближается к моделям с 7 млрд параметров. И это не предел: напомним, в текущем воплощении сочетание подсистем MemoryX и интерконнекта SwarmX допускает объединение в единый кластер до 192 узлов CS-2. 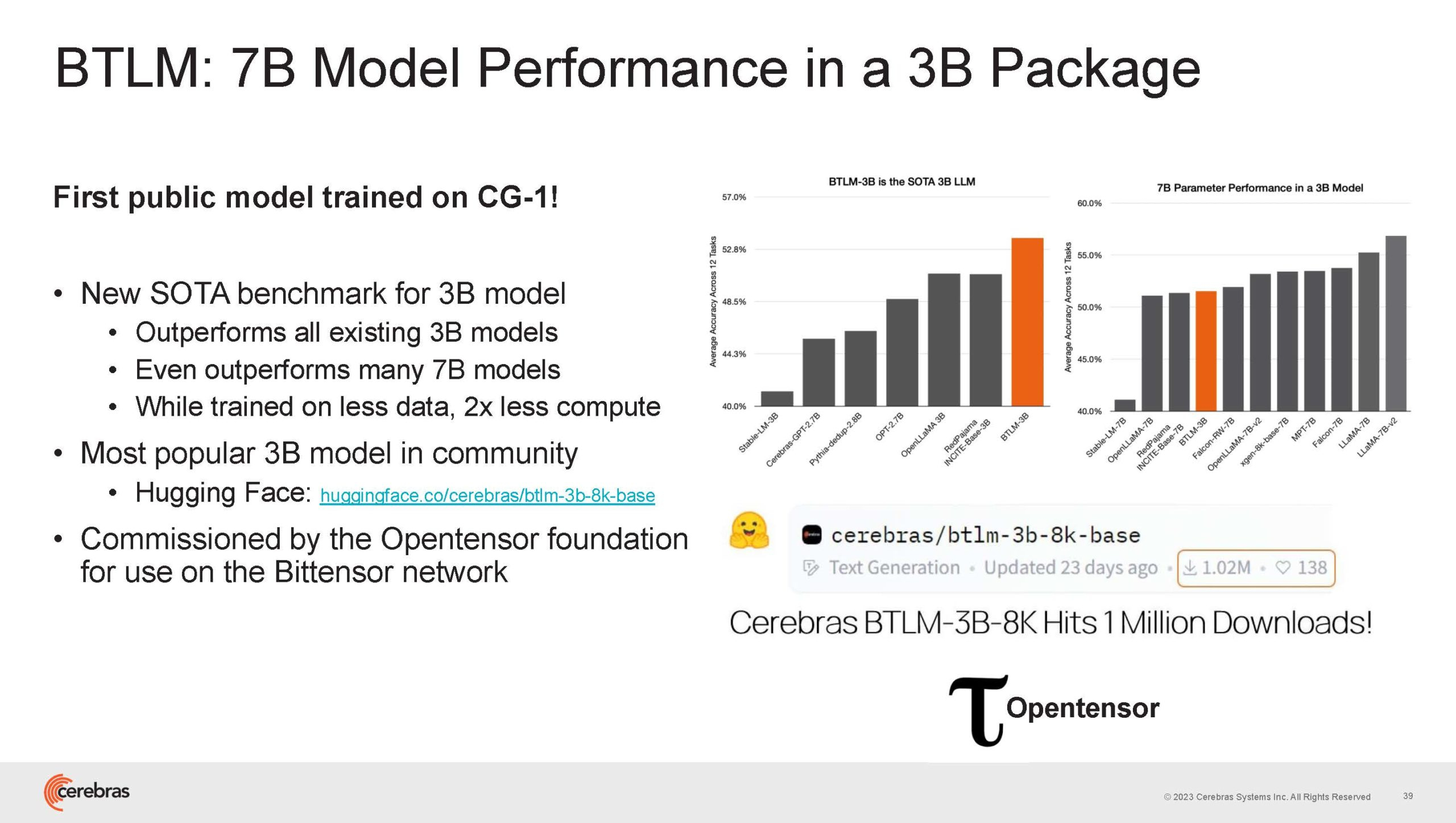 Компания считает, что она полностью готова к наплыву ещё более сложных нейросетей, а предлагаемая ей архитектура в явном виде лишена многих узких мест, свойственных традиционным GPU-архитектурам. Насколько успешным окажется такой подход в более отдалённой перспективе, покажет время.
01.09.2023 [16:26], Алексей Степин
Cornelis Networks ускорит Omni-Path Express до 1,6 Тбит/сИнтерконнекту Omni-Path прочили в своё время светлое будущее, но в 2019 году компания Intel отказалась от своего детища и свернула поставки OPA-решений. Однако эстафету подхватила Cornelis Networks, так что технология не умерла — совсем недавно The Next Platform были опубликованы планы по дальнейшему развитию Omni-Path. В 2012 году Intel выкупила наработки по TruScale InfiniBand у QLogic, позднее дополнив их приобретением у Cray интерконнектов Gemini XT и Aries XC. Задачей было создание единого интерконнекта, могущего заменить PCIe, FC и Ethernet, а в основу была положена технология Performance Scale Messaging (PSM). PSM считалась более эффективной и пригодной в сравнении с verbs InfiniBand, однако самой технологии более 20 лет. В итоге Cornelis Networks отказалась от PSM и теперь развивает новый программный стек на базе libfabric. 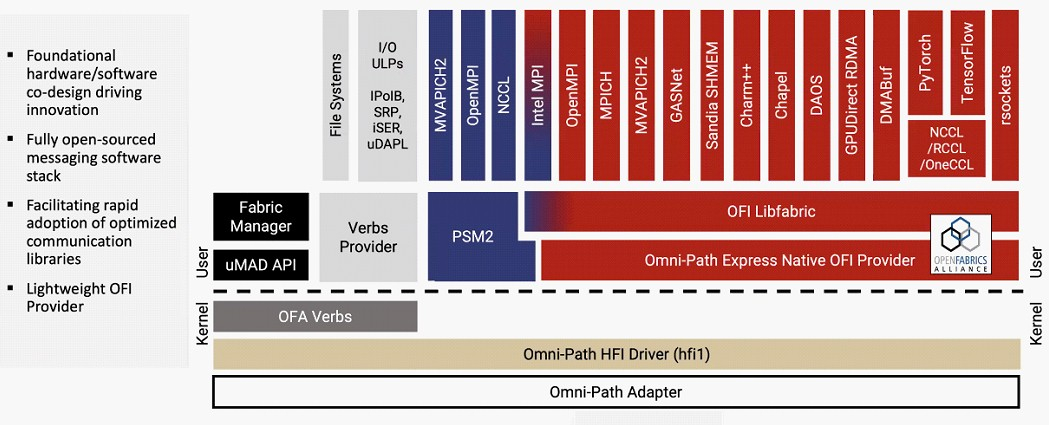
Источник изображений здесь и далее: Cornelis Networks (viaThe Next Platform) Уже первое поколение Omni-Path Express (OPX), работающее со скоростью 100 Гбит/с могло работать под управлением нового стека бок о бок с PSM2, а для актуальных 400G-продуктов Omni-Path Express CN5000 вариант OFI станет единственным. Скорее всего, в этом поколении будет также убрано всё, что работает на основе кода OFA Verbs. Останутся только части, выделенные на слайде выше красным. Как отмечает Cornelis Networks, главным отличием OPX от InfiniBand станет использование стека на базе полностью открытого кода с апстримом драйвера OFI в ядро Linux. 
Планы Cornelis Networks по развитию Omni-Path Планы компании простираются достаточно далеко: на 2024 год запланировано пятое поколение Omni-Path, включающее в себя не только адаптеры, но и необходимую инфраструктуру — 48-портовые коммутаторы и 576-портовые директоры. Предел масштабирования возрастёт практически на порядок, с 36,8 тыс. подключений для Omni-Path 100 до 330 тыс. Латентность при этом составит менее 1 мкс при потоке до 1,2 млрд сообщений в секунду. Появится поддержка топологий Dragonfly и Megafly, оптимизированных для применения в крупных HPC-системах, и динамическая адаптивная маршрутизация на базе данных телеметрии. 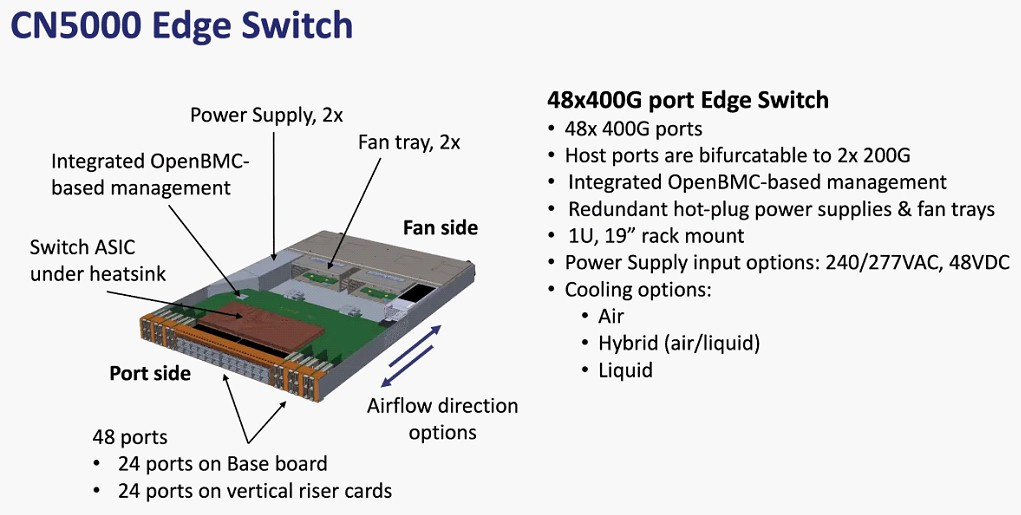 Характеристики и внутреннее устройство коммутаторов пятого поколения CN5000 компания публикует уже сейчас. Обычный периферийный коммутатор займёт высоту 1U, но при этом будет поддерживать как воздушное, так и жидкостное охлаждение, а модульный коммутатор класса director будет занимать 17U и получит внутренний интерконнект с топологией 2-tier Fat Tree. В нём будет предусмотрена горячая замена модулей и опция жидкостного охлаждения.  Базовый адаптер CN5000 выглядит как обычная плата расширения с интерфейсом PCIe 5.0 x16. Будут доступны варианты с одним и двумя портами 400G. Что интересно, опция жидкостного охлаждения предусмотрена и здесь. В 2026 году должно появиться шестое поколение решений Omni-Path CN6000 со скоростью 800 Гбит/с, включающее в себя не только базовые адаптеры и коммутаторы, но и первый в мире DPU для OPA, построенный на базе архитектуры RISC-V и поддерживающий CXL. Благодаря DPU будут реализованы более продвинутые опции разгрузки хост-системы и ускорения конкретных приложений. 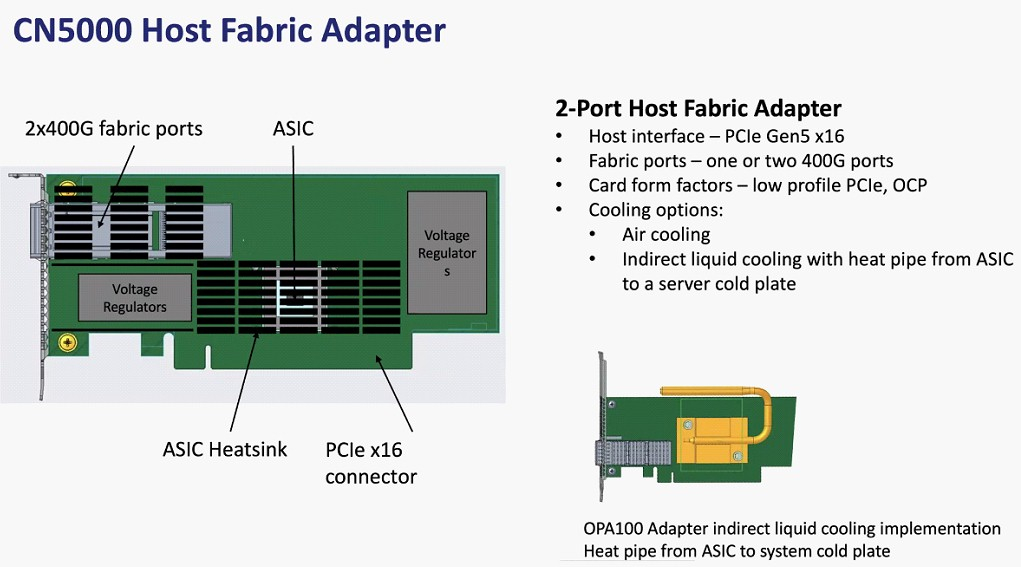 Наконец, в 2028 году в седьмом поколении CN7000 скоростной потолок поднимется с 800 до 1600 Гбит/с. Будет внедрена перспективная для крупномасштабных сетей поддержка топологии HyperX. Также ожидается появление чиплетов с интерфейсом UCIe и интегрированной фотоникой, что позволит интегрировать Omni-Path в решения сторонних производителей. Одной из главных целей Cornelis Networks, напомним, заявлено создание системы интерконнекта для суперкомпьютеров нового поколения экзафлопного класса. Разработка финансируется в рамках инициативы Exascale Computing Initiative (ECI). А первым суперкомпьютером, использующим Omni-Path пятого поколения (400G), станет техасский Stampede3.
22.04.2023 [00:15], Алексей Степин
Ловкость роборук: TopoOpt от Meta✴ и MIT поможет ускорить и удешевить обучение ИИТехнологии искусственного интеллекта (ИИ) сегодня бурно развиваются и требуют всё более серьёзных вычислительных мощностей. Но наряду с наращиванием этих мощностей растут требования и к сетевой подсистеме, поэтому крупные компании и исследовательские организации ищут всё новые способы оптимизации инфраструктуры. Компания Meta✴ в сотрудничестве с Массачусетским технологическим институтом (MIT) и рядом прочих исследовательских организаций опубликовала данные любопытного эксперимента, в котором ИИ-кластер мог менять топологию своего интерконнекта с помощью механической «роборуки». Система получила название TopoOpt, поскольку вычислительные узлы в ней использовали полностью оптическую сеть с оптической же патч-панелью. Эта сеть объединяла 12 вычислительных узлов ASUS ESC4000A-E10, каждый из которых был оснащён ускорителем NVIDIA A100, сетевыми адаптерами HPE и Mellanox ConnectX-5 (100 Гбит/с) с оптическими трансиверами. 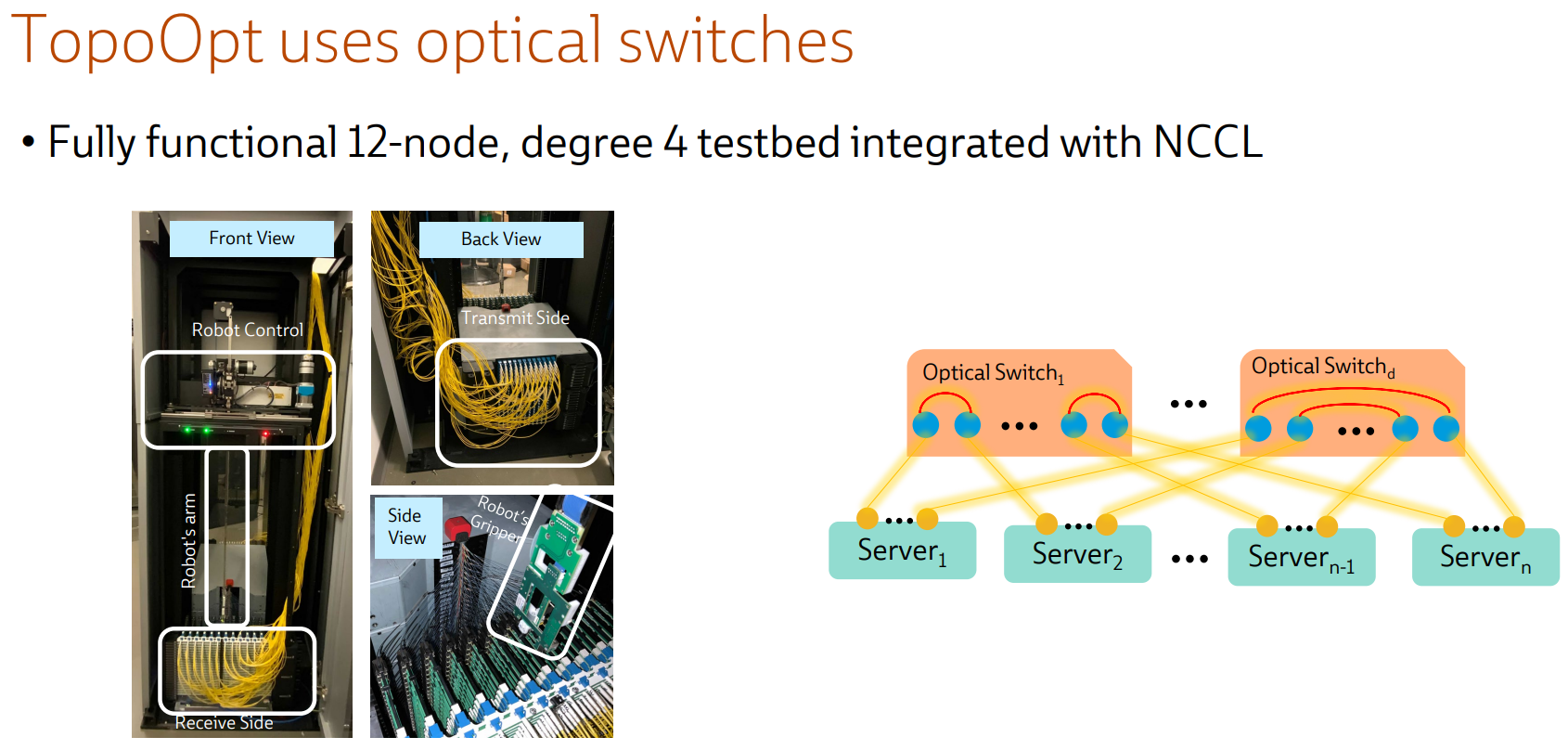
Источник здесь и далее: USENIX Наиболее интересное устройство в эксперименте — оптическая патч-панель Telescent, оснащённая механическим манипулятором, способным производить перекоммутацию на лету. Эта «роборука» работала под управлением специализированного ПО, целью которого ставилось нахождение оптимальной сетевой топологии и сегментации сети применительно к различным задачам машинного обучения. 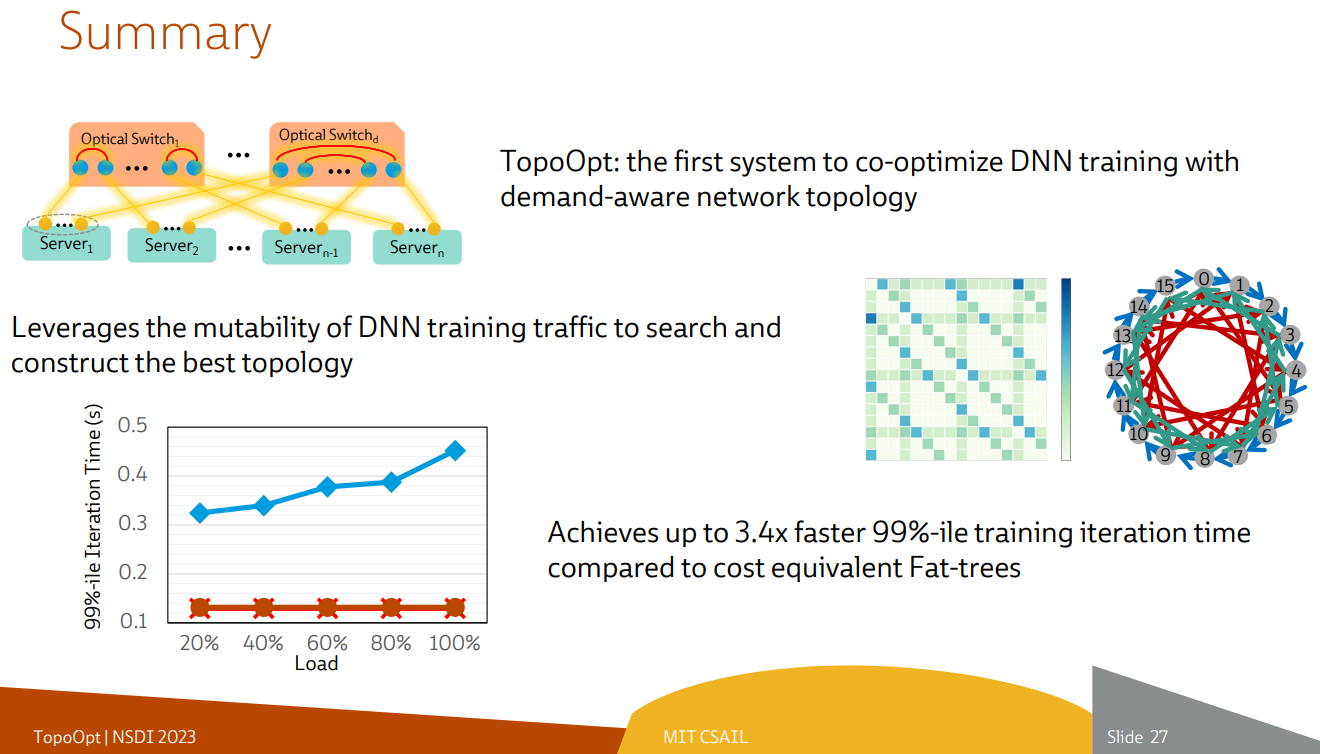
Система с перекоммутируемой оптической сетью не требует энергоёмких высокоскоростных коммутаторов и обеспечивает ряд других преимуществ Такая роботизированная патч-панель не столь расторопна, как оптические коммутаторы Google с микрозеркальной механикой, но стоит впятеро дешевле и имеет больше портов. Опубликованные экспериментальные данные уверенно свидетельствуют о том, что топология «толстого дерева» (fat tree), использующая несколько слоёв коммутаторов, не оптимальна и даже избыточна для ряда нейросетевых задач. К тому же перекоммутируемая оптическая сеть без традиционных высокоскоростных коммутаторов требует меньше оборудования, а значит, может быть не только быстрее сети fat tree в ряде ИИ-задач, но и существенно дешевле в развёртывании и поддержании в рабочем состоянии — как минимум за счёт отсутствия затрат на питание множества коммутаторов.
07.04.2023 [20:36], Сергей Карасёв
Google заявила, что её ИИ-кластеры на базе TPU v4 и оптических коммутаторов эффективнее кластеров на базе NVIDIA A100 и InfiniBandКомпания Google обнародовала новую информацию о своей облачной суперкомпьютерной платформе Cloud TPU v4, предназначенной для решения задач ИИ и машинного обучения с высокой эффективностью. Система может использоваться в том числе для работы с крупномасштабными языковыми моделями (LLM). Один кластер Cloud TPU Pod содержит 4096 чипов TPUv4, соединённых между собой через оптические коммутаторы (OCS). По словам Google, решение OCS быстрее, дешевле и потребляют меньше энергии по сравнению с InfiniBand. Google также утверждает, что в составе её платформы на OCS приходится менее 5 % от общей стоимости. Причём данная технология даёт возможность динамически менять топологию для улучшения масштабируемости, доступности, безопасности и производительности. Отмечается, что платформа Cloud TPU v4 в 1,2–1,7 раза производительнее и расходует в 1,3–1,9 раза меньше энергии, чем платформы на базе NVIDIA A100 в системах аналогичного размера. Правда, пока компания не сравнивала TPU v4 с более новыми ускорителями NVIDIA H100 из-за их ограниченной доступности и 4-нм архитектуры (по сравнению с 7-нм у TPU v4). 
Изображение: Google Благодаря ключевым инновациям в области интерконнекта и специализированных ускорителей (DSA, Domain Specific Accelerator) платформа Google Cloud TPU v4 обеспечивает почти 10-кратный прирост в масштабировании производительности по сравнению с TPU v3. Это также позволяет повысить энергоэффективность примерно в 2–3 раза по сравнению с современными DSA ML и сократить углеродный след примерно в 20 раз по сравнению с обычными дата-центрами.
06.09.2022 [22:47], Алексей Степин
Кремниевая фотоника Lightmatter Passage объединит чиплеты на скорости 96 Тбайт/сНа конференции Hot Chips 34 компания Lightmatter, занимающаяся созданием фотонного ИИ-процессора, рассказала о своей новой разработке, Lightmatter Passage, открывающей для чиплетов эру фотоники. Как известно, переход на чиплеты позволил разработчикам сложных чипов сравнительно малой кровью обойти ограничения, накладываемые технологиями на создание монолитных кристаллов большой площади. Однако современный высокоскоростной межчиплетный интерконнект всё равно весьма сложен и потребляет сравнительно много энергии. И по мере роста количества чиплетов на общей подложке проблема будет лишь обостряться. 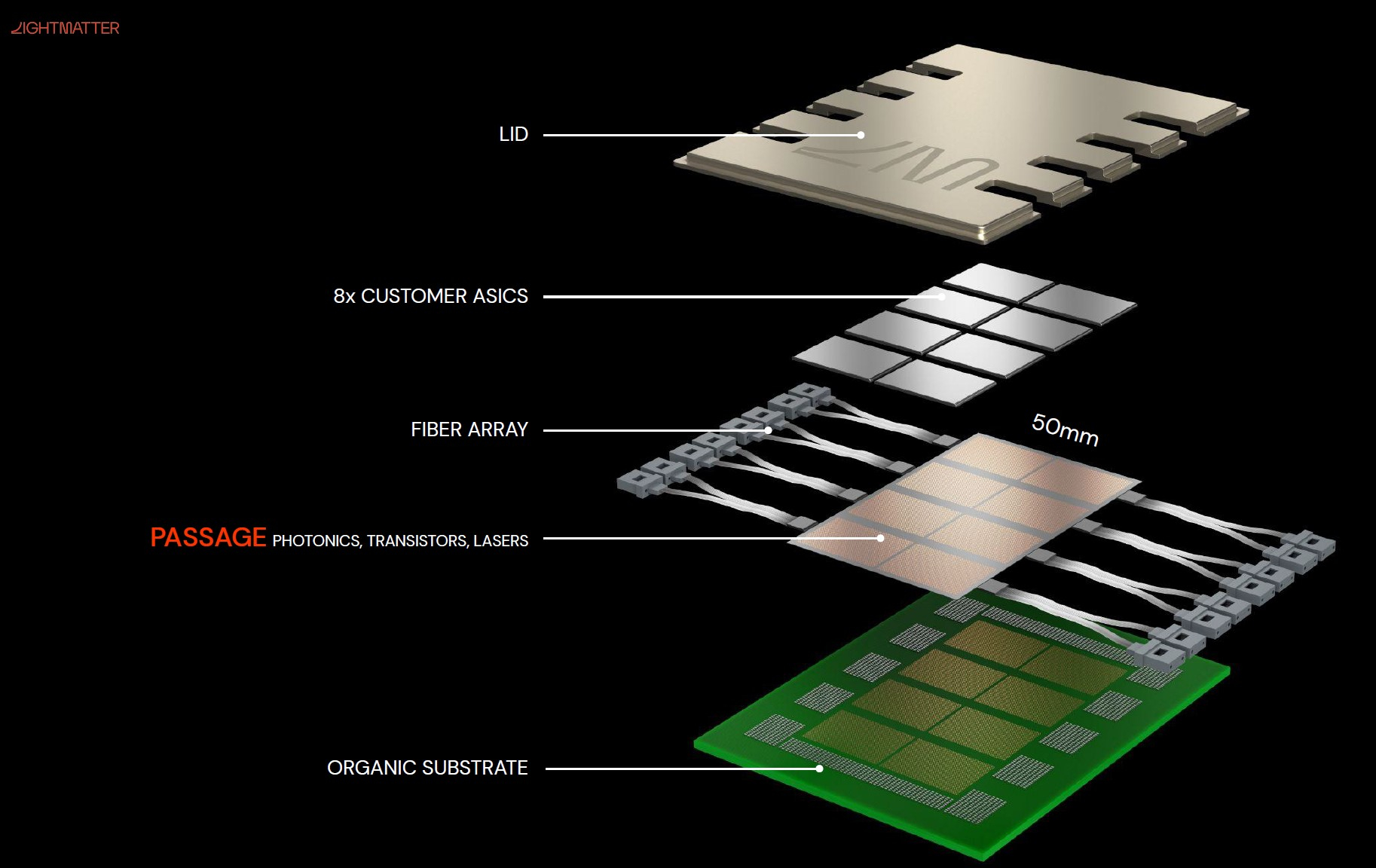
Изображения: Lightmatter (via ServeTheHome) Но технология Lightmatter Passage, призванная заменить электрический интерконнект оптическим, позволит эту проблему обойти. По сути, Passage — универсальная кремниевая прослойка, содержащая в своём составе лазеры, оптические модуляторы, фотодетекторы, волноводы, а также классические транзисторы для сопутствующей логики. Поверх этой прослойки Lightmatter и предлагает размещать чиплеты любой архитектуры. 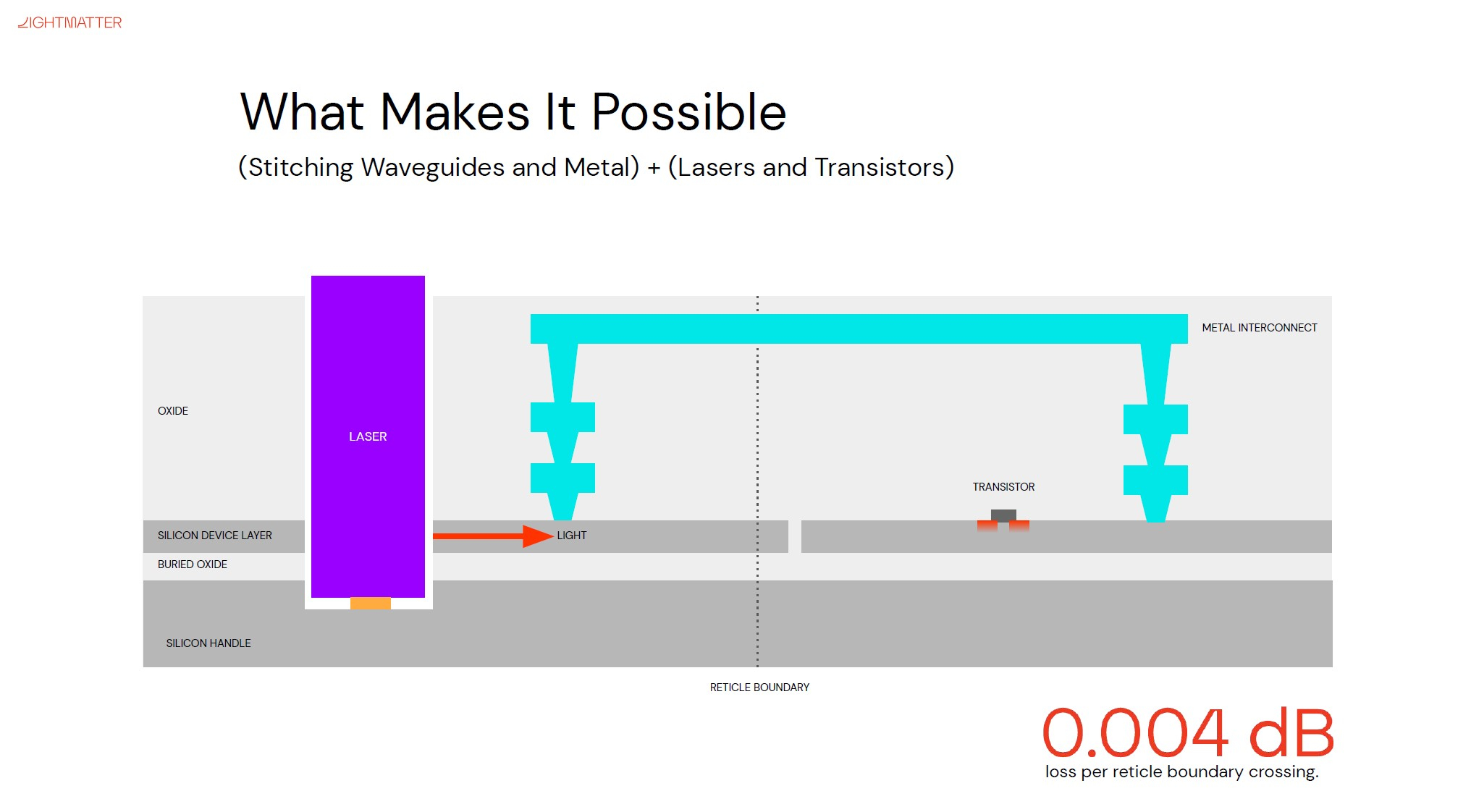 Электрическая часть Passage имеет изменяемую конфигурацию и в текущей реализации поддерживает установку до 48 чиплетов (в виде матрицы 6×8). Производится такая прослойка из 300-мм кремниевой пластины SOI, верхний и нижний слои Passage имеют классические контакты для чиплетов и установки на PCB соответственно. При этом максимальная подводимая электрическая мощность может достигать 700 Вт. Вся же коммуникация чиплетов между собой происходит внутри и является оптической. 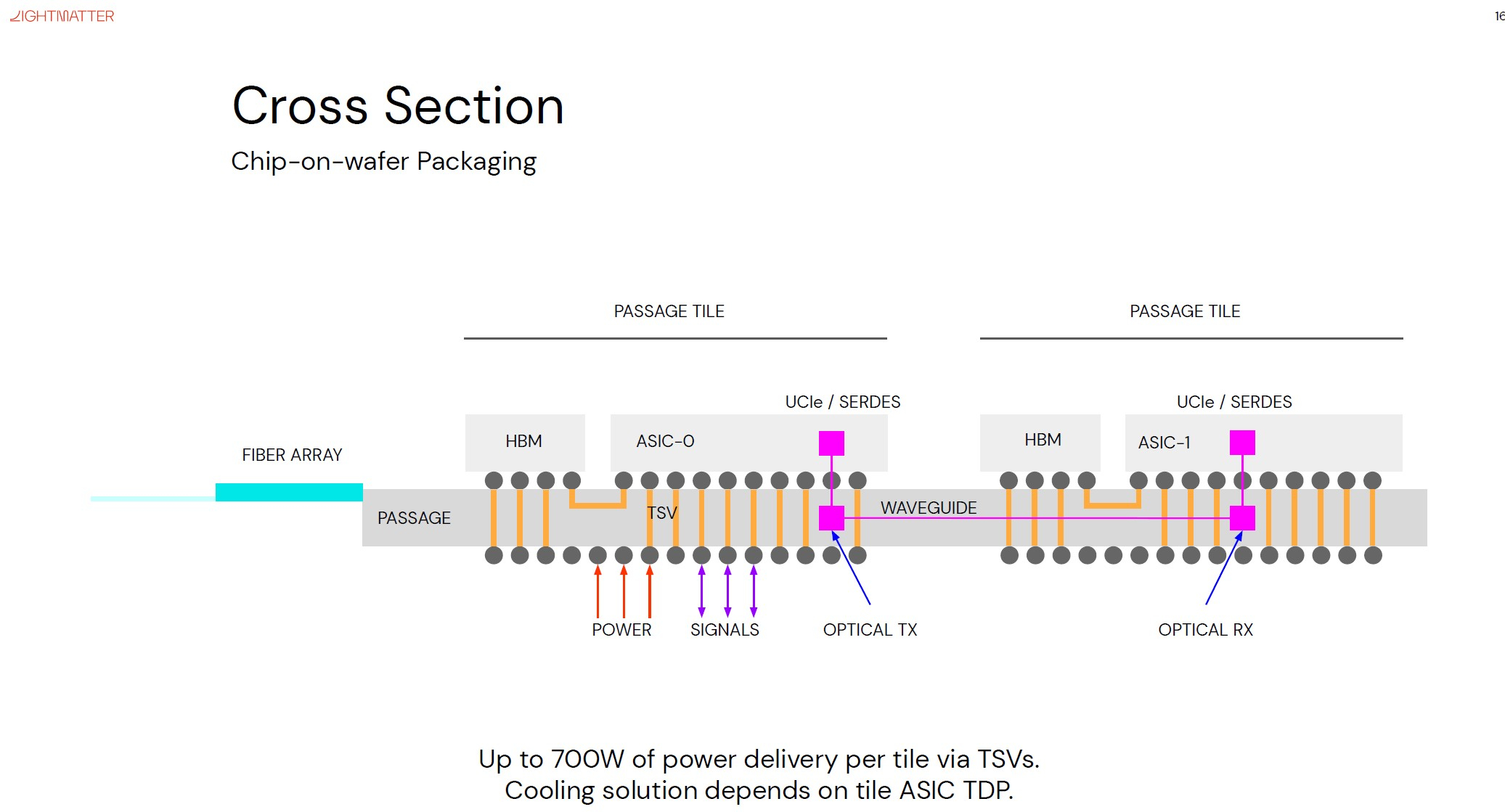 Матрица фотонных волноводов, плотность которой в 40 раз выше, чем у традиционных оптоволоконные технологий, обеспечивает латентность одного перехода на уровне менее 2 нс. Как заявляют разработчики, расстояние между чиплетами при этом роли не играет — для любого сочетания пары точек «входа» и «выхода» сигнала значение задержки одинаково. Высокая плотность волноводов позволяет «накормить» каждый чиплет потоком данных до 96 Тбайт/с, а внешние каналы Passage позволяют связать чипы с другими компонентами системы на скоростях до 16 Тбайт/с. 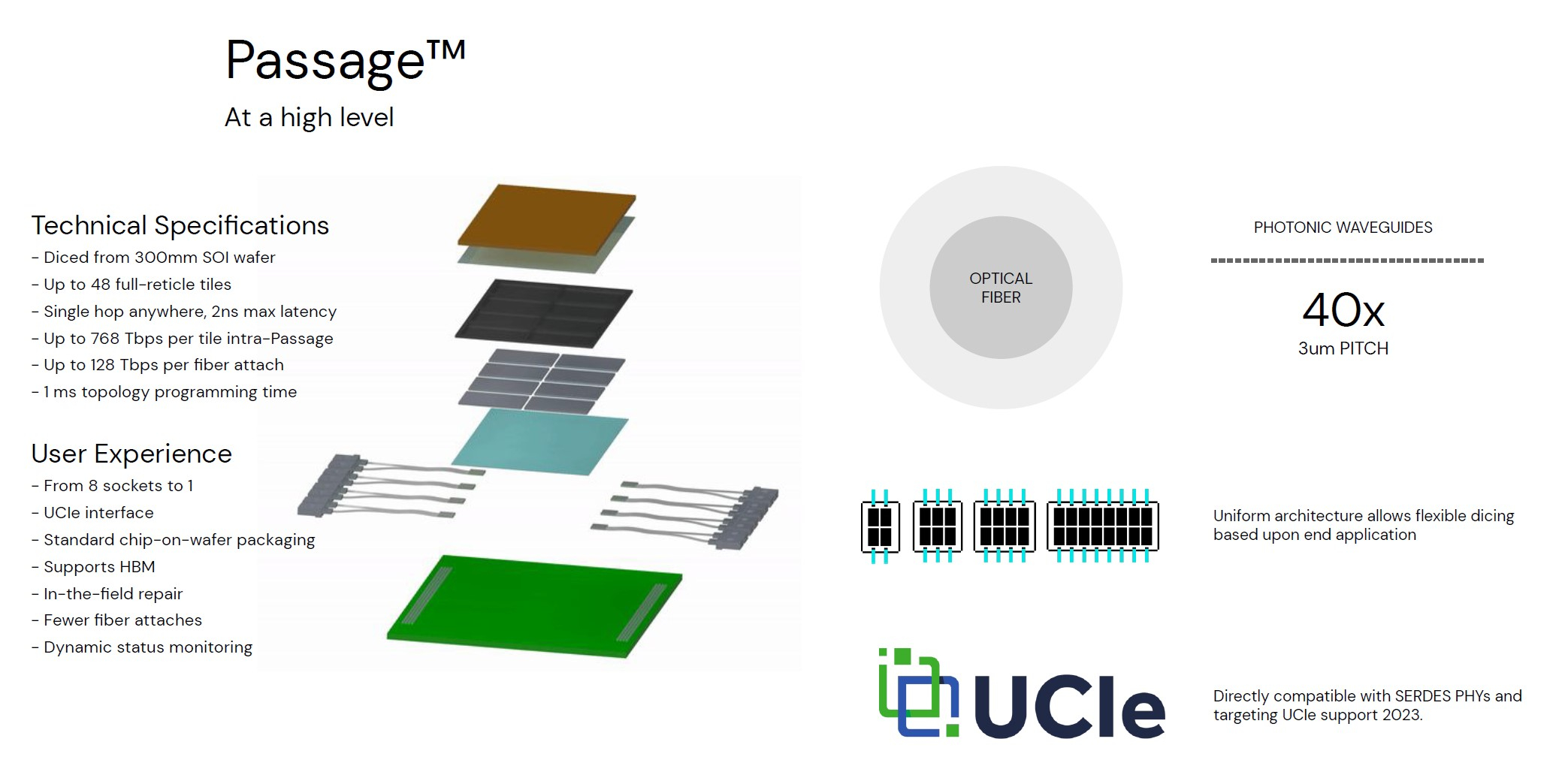 Основой данной технологии является фирменная разработка компании, позволяющая точно «сшивать» в пределах нескольких слоев SOI-кремния электрические соединения с многочисленными волноводами. Уже существующая в кремнии тестовая реализация Passage потребляет 21 Вт, позволяет устанавливать до 48 чиплетов площадью по 800 мм2, обеспечивает каждое посадочное место 32 каналами с пропускной способностью 1024 Тбит/с, причём топологию интерконнекта можно динамически менять.  Тестовая подложка Passage, полученная из 300-мм пластины, содержит 288 лазеров мощностью 50 мВт каждый. Всего в состав системы входит 150 тыс. компонентов, и это заявка на абсолютный рекорд для фотонных чипов. Кроме того, новая технология совместима со стандартом UCIe — говорится о скорости 32 Гбит/с на линию. Впрочем, в случае простого SerDes-соединения, как считают создатели, этот показатель можно поднять до 112 Гбит/с. |
|