Материалы по тегу: интерконнект
|
15.11.2024 [10:31], Сергей Карасёв
Eviden представила интерконнект BullSequana eXascale третьего поколения для ИИ-системКомпания Eviden (дочерняя структура Atos) анонсировала BullSequana eXascale Interconnect (BXI v3) — интерконнект третьего поколения, специально разработанный для рабочих нагрузок ИИ и HPC. Технология станет доступа на рынке во II половине 2025 года. Отмечается, что существующие высокоскоростные сетевые решения недостаточно эффективны, поскольку не устраняют критическое узкое место, известное как «сетевая стена». По заявлениям Eviden, зачастую при крупномасштабном обучении ИИ компании наращивают количество ускорителей, однако на самом деле ограничивающим фактором является интерконнект. Хотя поставщики сетевых решений продолжают удваивать пропускную способность каждые несколько лет, этого недостаточно для решения проблемы. В результате, до 70 % времени GPU простаивают, ожидая получения данных из-за задержек, утверждает Eviden. Технология BXI v3 призвана устранить этот недостаток. 
Источник изображений: Eviden Новый интерконнект использует стандарт Ethernet в качестве базового протокола связи. При этом реализованы функции, которые обычно характерны для масштабируемых сетей высокого класса, таких как Infiniband. Отмечается, что BXI v3 обеспечивает низкие задержки (менее 200 нс от порта к порту), высокую пропускную способность, упорядоченную (in order) доставку пакетов, расширенное управление перегрузками и масштабируемость. Технология BXI v3 ляжет в основу интеллектуального сетевого адаптера (Smart NIC) нового поколения, который поможет снизить влияние задержек сети на GPU и CPU. При использовании такого решения ускоритель ИИ выгружает данные на сетевой адаптер и сразу же переходит к другим задачам, что устраняет неэффективность, связанную с простоями. Подчёркивается, что протокол BXI v3 интегрируется непосредственно в Smart NIC, благодаря чему оборудование работает сразу после установки, а в приложения не требуется вносить какие-либо изменения.  Кроме того, новая технология предоставляет ряд дополнительных функций, ориентированных на повышение производительности путём оптимизации системных операций и обработки данных. В частности, BXI v3 обеспечивает прозрачную трансляцию виртуальных адресов в физические, что позволяет приложениям напрямую отправлять запросы в SmartNIC с использованием виртуальных адресов без необходимости системных вызовов. Такой подход повышает эффективность, обеспечивая бесперебойное управление памятью при сохранении высокой производительности. Технология BXI v3 также позволяет регистрировать до 32 млн приёмных буферов, которые SmartNIC выбирает с помощью ключей сопоставления на основе атрибутов сообщения. Благодаря этому уменьшается нагрузка на CPU, что повышает общую эффективность системы. Кроме того, сетевой адаптер способен выполнять математические атомарные операции, что дополнительно высвобождает ресурсы CPU. Впрочем, деталей пока мало, зато говорится об участии в консорциуме Ultra Ethernet (UEC) и партнёрстве с AMD.
05.11.2024 [11:17], Сергей Карасёв
Создан консорциум UALink по разработке альтернативы NVIDIA NVLinkВ мае нынешнего года был сформирован альянс Ultra Accelerator Link (UALink) по разработке технологии, призванной составить конкуренцию NVIDIA NVLink. А теперь участники отрасли объявили о создании соответствующего консорциума — UALink Consortium. Новую структуру возглавляют представители AMD, AWS, Astera Labs, Cisco, Google, HPE, Intel, Meta✴ и Microsoft. В состав консорциума также входят Cadence, Lenovo, H3C, Centec, Anapass и пр. Кроме того, к участию приглашаются другие заинтересованные стороны. Фактически участники заняты созданием более открытой альтернативы NVLink. 
Источник изображения: UALink «Стандарт UALink определяет высокоскоростную связь с низкими задержками для масштабируемых систем ИИ в дата-центрах. Заинтересованные компании могут присоединиться к консорциуму и поддержать нашу миссию: создание открытого и высокопроизводительного интерконнекта для рабочих нагрузок ИИ», — сказал Вилли Нельсон (Willie Nelson), президент UALink. Отмечается, что компании, входящие в совет консорциума, охватывают широкий спектр отраслей — от поставщиков облачных услуг и OEM-производителей до разработчиков ПО и полупроводниковых компонентов. В I квартале 2025 года планируется представить общедоступную спецификацию UALink 1.0, которая предусматривает пропускную способность до 200 Гбит/с на соединение. В пределах одного домена при этом могут быть объединены до 1024 ускорителей ИИ. Выпуск спецификации UALink 1.0 станет важной вехой, поскольку она определит открытый отраслевой стандарт, позволяющий ускорителям и коммутаторам ИИ взаимодействовать более эффективно. Это откроет новые возможности в плане развития и внедрения крупных ИИ-моделей.
20.10.2024 [11:06], Сергей Карасёв
Стартап Xscape Photonics получил $44 млн на создание фотонных решений для ИИ-дата-центровСтартап Xscape Photonics, создающий решения на основе кремниевой фотоники, вышел из скрытного режима, объявив о проведении раунда финансирования Series A на сумму в $44 млн. Таким образом, как отмечается, общий объём привлечённых компанией средств на сегодняшний день достиг $57 млн. Xscape Photonics была основана в 2022 году. В число её учредителей входят доктора наук и специалисты с опытом работы в области полупроводников в различных компаниях, таких как Broadcom, Cerebras, InPhi, Intel, Juniper, Lumentum, Marvell и Neophotonics. Среди основателей — доктора Вивек Рагхунатхан (Vivek Raghunathan) и Йоши Окавачи (Yoshi Okawachi), а также профессоры Александр Гаэта (Alexander Gaeta), Михал Липсон (Michal Lipson) и Керен Бергман (Keren Bergman). 
Источник изображения: Xscape Photonics Xscape Photonics ставит своей целью решение проблемы ширины полосы пропускания, которая является узким местом платформ для рабочих нагрузок ИИ. Стартап разрабатывает фотонные чипы для организации высокоскоростных соединений в дата-центрах. «Исторически проблемы производительности и масштабируемости при обучении больших языковых моделей решались путём создания более крупных ЦОД. Такой подход является неэффективным и порождает множество дополнительных сложностей, связанных с потреблением энергии и стоимостью. Мы стремимся помочь клиентам полностью переосмыслить то, как они решают эти проблемы», — говорит Рагхунатхан, занимающий пост генерального директора Xscape Photonics. Компания создаёт многоволновую фотонную платформу ChromX, которая позволяет повысить пропускную способность в системах на основе GPU-ускорителей при одновременном снижении энергопотребления. В результате, улучшается общая производительность при выполнении задач инференса. Раунд финансирования Series A проведён под руководством IAG Capital Partners с участием Altair, Cisco Investments, Fathom Fund, Kyra Ventures, LifeX Ventures, NVIDIA и OUP. Деньги будут направлены на ускорение разработки платформы ChromX.
02.07.2024 [23:55], Алексей Степин
15 тыс. ускорителей на один ЦОД: Alibaba Cloud рассказала о сетевой фабрике, используемой для обучения ИИAlibaba Cloud раскрыла ряд сведений технического характера, касающихся сетевой инфраструктуры и устройства своих дата-центров, занятых обработкой ИИ-нагрузок, в частности, обслуживанием LLM. Один из ведущих инженеров компании, Эньнань Чжай (Ennan Zhai), опубликовал доклад «Alibaba HPN: A Data Center Network for Large Language Model Training», который будет представлен на конференции SIGCOMM в августе этого года. В качестве основы для сетевой фабрики Alibaba Cloud выбрала Ethernet, а не, например, InfiniBand. Новая платформа используется при обучении масштабных LLM уже в течение восьми месяцев. Выбор обусловлен открытостью и универсальностью стека технологий Ethernet, что позволяет не привязываться к конкретному вендору. Кроме того, меньше шансы пострадать от очередных санкций США. Отмечается, что традиционный облачный трафик состоит из множества относительно небыстрых потоков (к примеру, менее 10 Гбит/с), тогда как трафик при обучении LLM включает относительно немного потоков, имеющих периодический характер со всплесками скорости до очень высоких значений (400 Гбит/с). При такой картине требуются новые подходы к управлению трафиком, поскольку традиционные алгоритмы балансировки склонны к перегрузке отдельных участков сети. 
Источник здесь и далее: Alibaba Cloud Разработанная Alibaba Cloud альтернатива носит название High Performance Network (HPN). Она учитывает многие аспекты работы именно с LLM. Например, при обучении важна синхронизация работы многих ускорителей, что делает сетевую инфраструктуру уязвимой даже к единичным точкам отказа, особенно на уровне внутристоечных коммутаторов. Alibaba Cloud использует для решения этой проблемы парные коммутаторы, но не в стековой конфигурации, рекомендуемой производителями. 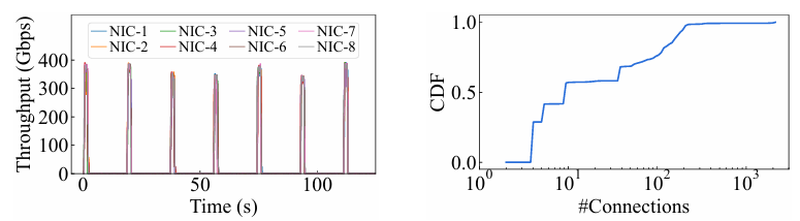
Характер трафика при обучении LLM Каждый хост содержит восемь ИИ-ускорителей и девять сетевых адаптеров. Каждый из NIC имеет по паре портов 200GbE. Девятый адаптер нужен для служебной сети. Между собой внутри хоста ускорители общаются посредством NVLink на скорости 400–900 Гбайт/с, а для общения с внешним миром каждому из них полагается свой 400GbE-канал с поддержкой RDMA. При этом порты сетевых адаптеров подключены к разным коммутаторам из «стоечной пары», что серьёзно уменьшает вероятность отказа. 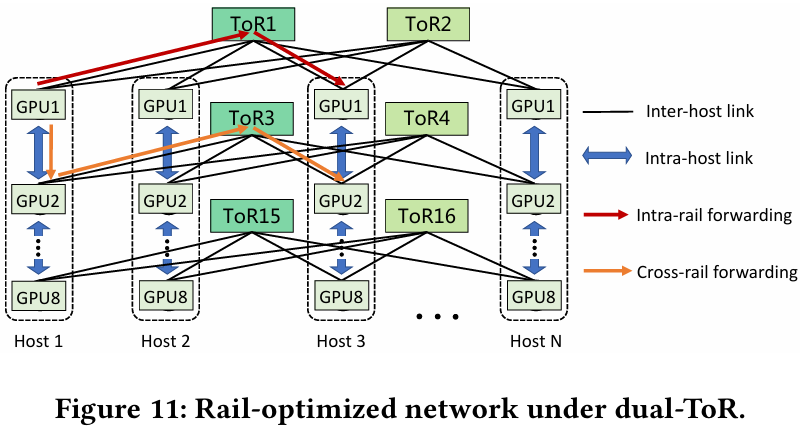 В докладе говорится, что Alibaba Cloud использует современные одночиповые коммутаторы с пропускной способностью 51,2 Тбит/с. Этим условиям отвечают либо устройства на базе Broadcom Tomahawk 5 (март 2023 года), либо Cisco Silicon One G200 (июнь того же года). Судя по использованию выражения «начало 2023 года», речь идёт именно об ASIC Broadcom. 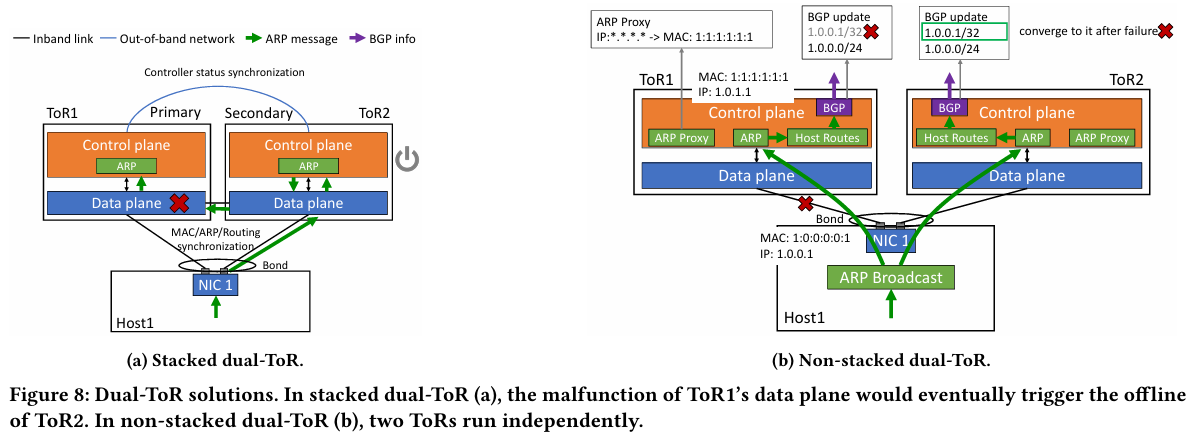 Своё предпочтение именно одночиповых коммутаторов компания объясняет просто: хотя многочиповые решения с большей пропускной способностью существуют, в долгосрочной перспективе они менее надёжны и стабильны в работе. Статистика показывает, что аппаратные проблемы у подобных коммутаторов возникают в 3,77 раза чаще, нежели у одночиповых. 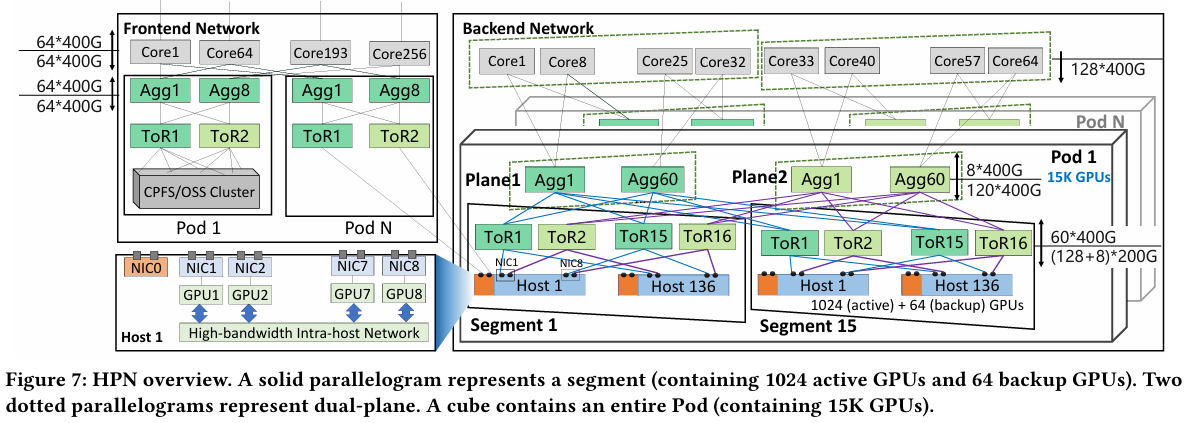 Одночиповые решения класса 51,2 Тбит/с выделяют много тепла, но ни один поставщик оборудования не смог предложить Alibaba Cloud готовые решения, способные удерживать температуру ASIC в пределах 105 °C. Выше этого порога срабатывает автоматическая защита. Поэтому для охлаждения коммутаторов Alibaba Cloud создала собственное решение на базе испарительных камер. 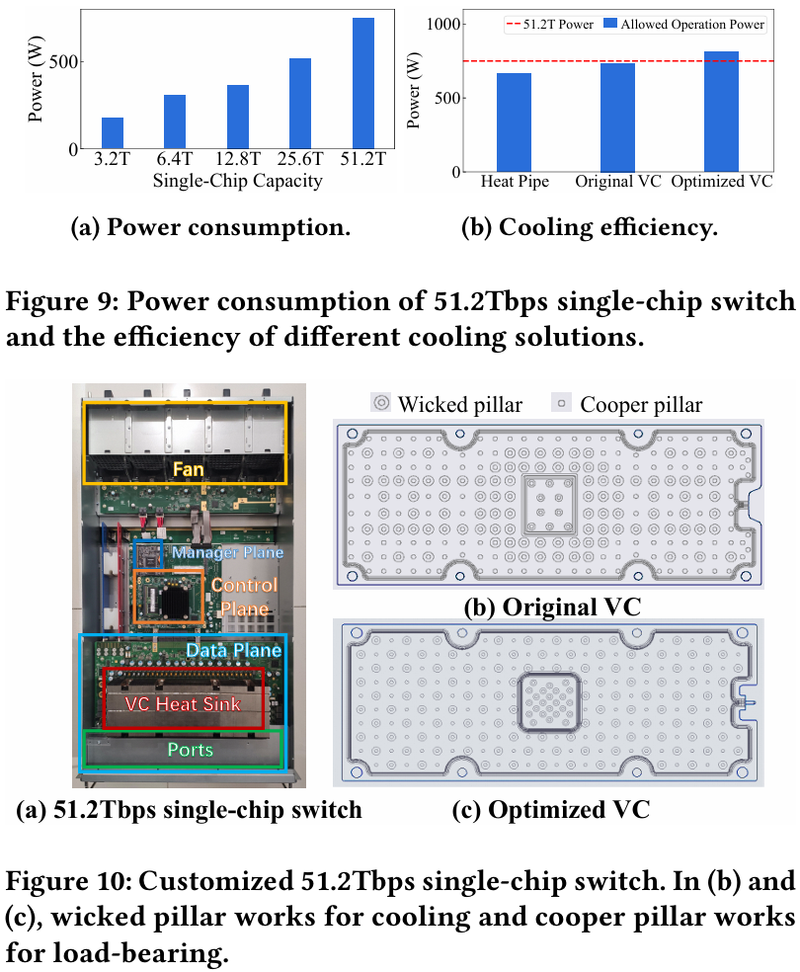 Сетевая фабрика позволяет создавать кластеры, каждый из которых содержит 15360 ускорителей и располагается в отдельном здании ЦОД. Такое высокоплотное размещение позволяет использовать оптические кабели длиной менее 100 м и более дешёвые многомодовые трансиверы, которые дешевле одномодовых примерно на 70 %. Ёмкость такого дата-центра составляет около 18 МВт. 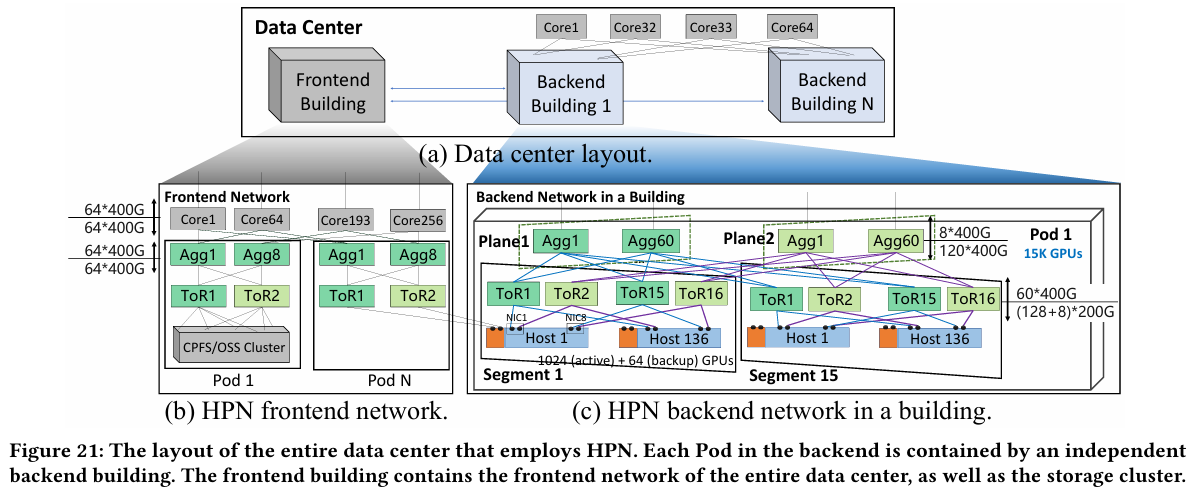 Но есть у HPN и недостаток: использование топологии с двумя внутристоечными коммутаторами и другие особенности архитектуры усложняют кабельную подсистему, поэтому инженеры поначалу столкнулись с ростом ошибок при подключении сетевых интерфейсов. В настоящее время активно используются тесты, позволяющие проверить каждое подключение на соответствие идентификаторов портов и коммутаторов рабочим схемам. Отмечается, что параметры Ethernet-коммутаторов удваиваются каждые два года, поэтому компания уже разрабатывает сетевую архитектуру следующего поколения, рассчитанную на применение будущих ASIC 102,4 Тбит/с. По словам Alibaba Cloud, обучение LLM с сотнями миллиардов параметров потребует огромного распределённого кластера, количество ускорителей в котором исчисляется миллионами. И ему требуется соответствующая сетевая инфраструктура.
27.06.2024 [23:57], Алексей Степин
Intel представила фотонный интерконнект OCI: по 2 Тбит/с в обе стороны на расстоянии 100 мIntel ведет исследования в области интегрированной фотоники уже много лет, поскольку успех в этой сфере критически важен для HPC-систем нового поколения. Два года назад компания сообщила о создании технологии, использующей существующие техпроцессы обработки 300-мм кремниевых пластин для формирования массива лазеров вкупе с модуляторами. А сейчас можно говорить о достижении новой важной вехи в этой области. На OFC 2024 Intel продемонстрировала опытный образец CPU, оснащённый 64-канальным фотонным интерконнектом OCI (Optical Compute Interconnect). Каждый канал позволяет передавать данные на скорости 32 Гбит/с на расстоянии до 100 м, что позволит решить проблему масштабирования HPC-систем и ИИ-комплексов: пропускной способности 2 Тбит/с (256 Гбайт/с) в каждом направлении хватит на многое. А в перспективе скорость будет доведена до 32 Тбит/с. 
Источник изображений: Intel В настоящее время в системах подобного класса для высокоскоростного соединения узлов используются либо решения с внешними оптическими трансиверами, что серьёзно увеличивает стоимость и энергопотреблению в целом, либо классическую «медь», серьёзно ограниченную по максимальной длине кабеля. OCI позволяет избежать обеих проблем.  Чиплет использует DWDM (восемь длин волн на волокно) и при этом экономичен: энергозатраты на передачу информации составляют всего 5 пДж/бит против 15 пДж/бит у решений с внешними оптическими трансиверами. Ранее заявленную цифру 3 пДж/бит пришлось немного увеличить, что связано с интеграцией интерфейса PCIe.  Внешне продемонстрированный образец чипа напоминает выпускавшиеся когда процессоры Xeon с поддержкой Omni-Path, но вместо электрического разъёма у него теперь оптический соединитель на восемь пар волокон. С помощью простого пассивного переходника к нему в демонстрационной системе Inel был подключен типовой оптоволоконный кабель.  Поскольку речь идёт о чиплете, теоретически ничто не мешает разместить модуль OCI в составе GPU/NPU, FPGA, DPU/IPU и вообще любой модульной SoC. При этом чиплет совместим с PCIe 5.0, так что проблем с интеграцией быть не должно, хотя это и не самый оптимальный вариант. А на уровне упаковки поддерживается и UCIe. 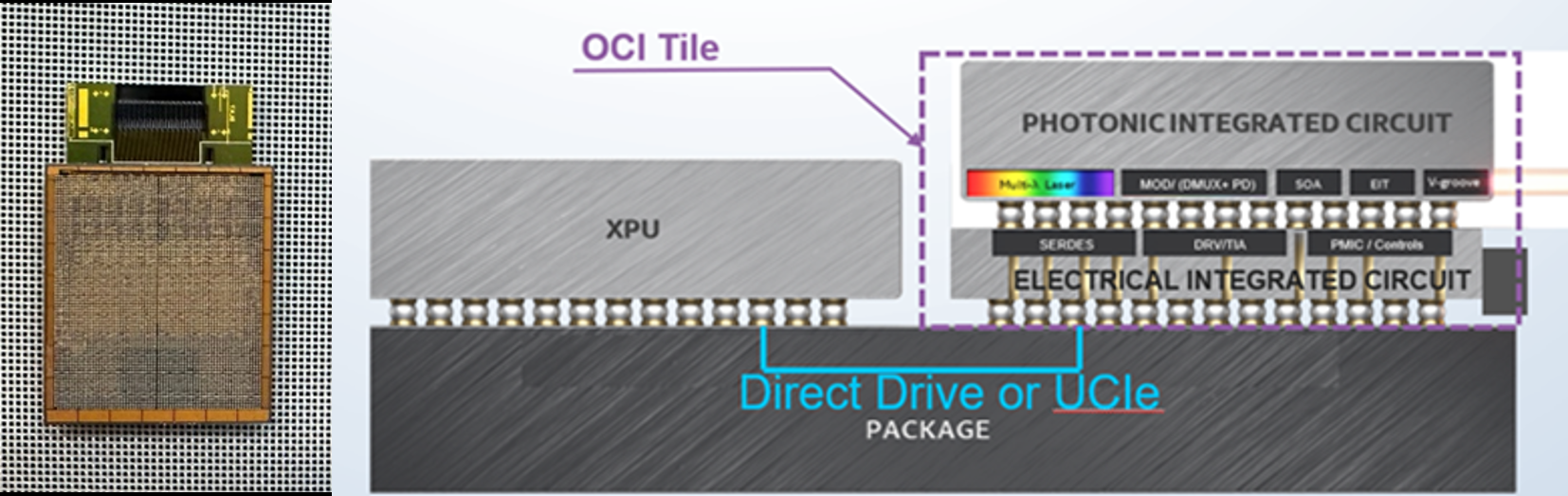 Вкупе с предельной дистанцией до 100 м новый чиплет существенно упростит системы интерконнекта: за редкими исключениями, вроде NVIDIA NVLink или Intel Gaudi 3 с его массивом Ethernet-контроллеров, связь организуется посредством PCIe-адаптера InfiniBand, либо Ethernet, в которые устанавливаются оптические трансиверы. Впрочем, и у PCI Express вскоре появится поддержка оптических подключений, что будет на руку Ultra Accelerator Link (UALink).  В следующем поколении пропускная способность каждой линии OCI возрастёт с 32 до 64 Гбит/с, после чего Intel планирует довести число одновременно используемых длин волн до 16. Затем, в промежутке между 2030 и 2035 годами планируется достигнуть 128 Гбит/с на линию, уже с 16 длинами волн и 16 парами волокон. Но без конкуренции здесь не обойдётся. NVLink, который уже сейчас существенно быстрее (1,8 Тбайт/с в нынешнем поколении), вскоре тоже обзаведётся оптической версией. Похожие решения развивают Celestial AI, MediaTek и Ranovus, Lightmatter и Ayar Labs.
18.06.2024 [22:45], Алексей Степин
Обещанного три года ждут: разработка и внедрение новых стандартов PCI Express не ускорятся, но PCI-SIG не видит в этом проблемыНа недавно прошедшей конференции PCI-SIG Developers Conference 2024 вице-президент группы, Ричард Соломон (Richard Solomon) рассказал о разработке новых версий стандарта PCI Express. Создание новых стандартов вышло на устоявшийся трехлётний цикл, но в данном случае имплементация и выход на массовый рынок не равны собственно разработке очередной версии PCIe. Приблизительно за три года PCI-SIG успевает разработать, внести корректировки, согласовать все нюансы со всеми участниками консорциума и опубликовать спецификации нового стандарта. Но после этого необходимо получить первые образцы «кремния» с его поддержкой и провести все необходимые квалификационные процедуры. Одна только фаза «тестирования на соответствие» (FYI, First Year Inventory Compliance Program) занимает полгода. 
Источник здесь и далее: PCI-SIG Главной причиной достаточно длительного цикла, отметил вице-президент PCI-SIG, является время от окончания работы над спецификациями до получения готовых ASIC, без которых невозможно начать полномасштабное тестирование. Таким образом, формально появившийся в начале 2022 года стандарт PCIe 6.0 лишь в июне 2024 года добрался до фазы FYI. При этом первый дизайн (только на бумаге, конечно) IP-блоков для PCIe 6.0 появился ещё даже до финализации стандарта.  Более того, спецификации PCIe 6.0 в скором времени снова будут обновлены для поддержки нового стандарта оптических соединений, которые, впрочем, не заменят, а дополнят традиционные медные соединения. Финализация правок ожидается в декабре текущего года. Кроме того, появится поддержка и новых кабелей CopprLink. Так что на выход PCIe 6.0 на рынок стоит рассчитывать где-то в начале 2025 года.  Конечно, хотелось бы привести цикл разработки PCI Express в соответствии с циклами других производителей, включая разработчиков Ethernet, Infiniband и CXL, но состав PCI-SIG, насчитывающий уже почти тысячу компаний-участников, продолжает расти, что, конечно, не способствует быстрому согласованию спецификаций и получению всех нужных образцов технологии. Более того, все устройства любого стандарта PCIe обязаны быть совместимы со старыми версиями, вплоть до 1.0.  И весь этот процесс необходимо поддерживать и далее: на середину или конец 2025 года запланирован выпуск финальных спецификаций PCI Express 7.0. Так что FIY-фазы стоит ожидать не ранее 2028 года. При этом проверка устройств нового стандарта на взаимную совместимость, в том числе чисто электрическую, становится всё сложнее с учётом заявленных частот и скоростей и оттого всё более необходимой.  Но даже с трёхлетним циклом разработки, говорит PCI-SIG, пока удаётся опережать требования индустрии. Пропускная способность I/O-систем тоже удваивается примерно каждые три года, но к этому моменту у разработчиков PCIe уже готов и протестирован новый стандарт, покрывающий все разумные потребности и массово реализуемый за разумные деньги.  И сравнивать PCIe, например, с NVLink с этой точки зрения может быть не совсем корректно, поскольку целью PCI-SIG не является достижение предельно высокой производительности любой ценой. Вместо этого группа обеспечивает развитие разумной, совместимой экосистемы решений с наилучшим соотношением цены и возможностей. Это не означает, что в абсолютных значениях решения на базе новых стандартов будут дешевле, но, как отметил вице-президент, экосистема PCIe позволяет разработчикам выбрать приемлемое для каждого случая сочетание характеристик. В настоящее время спецификация PCIe 7.0 версии 0.5 стала доступна участникам PCI-SIG. Новый стандарт доводит скорость передачи данных до 128 ГТ/с на линию при повышении энергоэффективности. Напомним, начиная с PCIe 6.0 доступен режим кодирования Flit, позволяющий избежать накладных расходов при передаче данных, и сделан переход к модуляции PAM4. Оптический вариант PCIe 7.0 тоже появится, но всё ещё будет опциональным. По словам Соломона, разговоры о вынужденном переходе на «оптику» ведутся более десяти лет, но по факту возможностей «меди» всё ещё хватает и будет хватать.
10.06.2024 [13:06], Сергей Карасёв
Разработчик СХД Qumulo присоединился к консорциуму Ultra EthernetКомпания Qumulo сообщила о вступлении в консорциум Ultra Ethernet Consortium (UEC), который был сформирован в июле 2023 года. Кроме того, Qumulo объявила о сотрудничестве с Intel и Arista Networks для продвижения передовых IT-инфраструктур, использующих современные сетевые технологии, а также средства хранения и управления данными. Группа Ultra Ethernet занимается разработкой открытой высокопроизводительной сетевой архитектуры с полным коммуникационным стеком, отвечающей задачам современных рабочих нагрузок ИИ и НРС. Основателями UEC стали AMD, Arista, Broadcom, Cisco, Eviden (Atos), HPE, Intel, Meta✴ и Microsoft. Впоследствии к группе присоединились многие другие компании, включая Nokia, Lenovo, Baidu, Dell, Huawei, IBM, Supermicro, Tencent и пр. В состав Ultra Ethernet Consortium также вошла Cornelis Networks, поставщик HPC-интерконнекта Omni-Path. А вот NVIDIA в UEC не входит. 
Источник изображения: Qumulo Qumulo, как отмечается, стала первым разработчиком хранилищ, присоединившимся к консорциуму Ultra Ethernet. Технический директор отмечает, что новые решения, разрабатывающиеся в рамках консорциума, в перспективе будут определять способы передачи данных по сетям, улучшая взаимодействие вычислительных систем и хранилищ информации. При этом станет возможным упрощение архитектуры при одновременном повышении производительности и надёжности. На сегодняшний день Qumulo развернула более 1 Эбайт хранилищ среди сотен клиентов, используя системы на базе Arista Extensible Operating System (EOS). Вице-президент по развитию бизнеса и стратегическим альянсам Arista Networks говорит о том, что участие Qumulo в Ultra Ethernet Consortium будет способствовать ускорению внедрения новых технологий. Ожидается, что результаты работы группы помогут в развёртывании высокопроизводительных и масштабируемых сетей для современных приложений, связанных в том числе с ИИ.
30.05.2024 [23:56], Игорь Осколков
NVLink для экономных — AMD, Intel и другие IT-гиганты объединились для создания UALink и противостояния NVIDIAЛетом прошлого года AMD, Arista, Broadcom, Cisco, Eviden/Atos, HPE, Intel, Meta✴ и Microsoft сформировали консорциум Ultra Ethernet (UEC), призванный составить конкуренцию технологии InfiniBand, которая фактически единолично контролируется NVIDIA после покупки Mellanox, и стандартизировать Ethernet-решения для современных ИИ- и HPC-платформ. А теперь AMD, Broadcom, Cisco, Google, HPE, Intel, Meta✴ и Microsoft сформировали альянс Ultra Accelerator Link (UALink), который должен составить конкуренцию NVLink. К UEC за год присоединились ещё полсотни компаний, кроме, конечно, NVIDIA, которая, впрочем, про Ethernet тоже не забывает, хотя периодически получает критику со стороны Broadcom. Единственной альтернативой в деле построения фабрик для более-менее крупных кластеров остаётся Omni-Path Express, развиваемый Cornelis Networks, которая тоже присоединилась к UEC, но доля этой технологии на фоне Ethernet и InfiniBand мизерная. Кроме того, ни одна из этих технологий не может предложить то, что может NVIDIA NVLink — возможность напрямую объединить сотни ускорителей (точнее, их память) сверхбыстрым соединением с низким уровнем задержки. 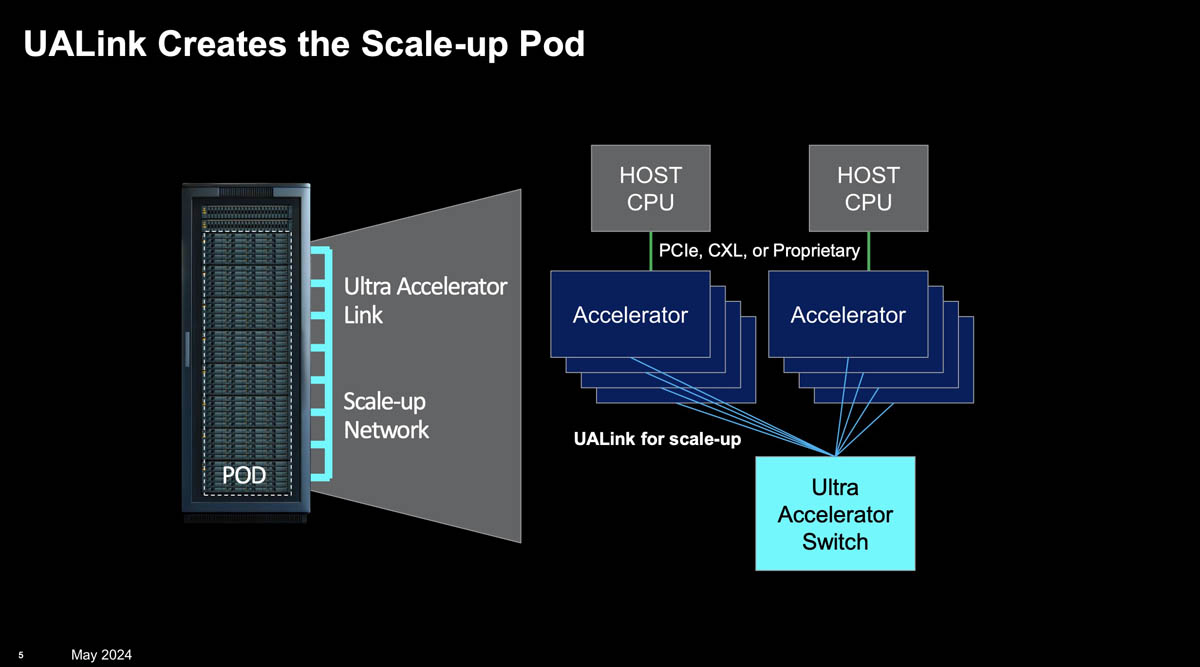
Источник изображений: UALink via ServeTheHome NVLink 4 достиг скорости 900 Гбайт/с на ускоритель и впервые вышел за пределы узла, позволив объединить в домен до 256 ускорителей, что NVIDIA и предложила в рамках DGX SuperPod H100. NVLink 5 удвоил пропускную способность до 1,8 Тбайт/с и теоретически позволит объединить до 576 ускорителей в одном домене. Именно NVLink позволил создать высокоплотные суперускорители GH200 NVL32 и GB200 NVL72. И именно их NVIDIA считает минимальной эффективной единицей кластеров ближайшего будущего, предлагая крупным заказчикам на меньшее даже не размениваться.  Intel в семействе Gaudi использует Ethernet (1,2 Тбайт/с на ускоритель) как для вертикального, так и для горизонтального масштабирования. AMD же полагается на Infinity Fabric (896 Гбайт/с на ускоритель) на базе PCIe и xGMI, которые до недавнего времени за пределы узла не выходили. Однако в конце 2023 года было объявлено, что в 2025 году AMD и Broadcom выпустят коммутатор на базе PCIe 7.0 (стандарт планируют только-только утвердить в этом же году), который будет поддерживать технологию, которая теперь называется AFL (Accelerated Fabric Link) — это и будет выходом Infinity Fabric за пределы узла.  И именно совместными наработками AMD и Broadcom поделятся в рамках UALink. Первую версию нового интерконнекта альянс обещает представить уже в III квартале 2024 года, а в IV квартале — версию 1.1. При этом пока прямо не говорится, будет ли основным транспортом PCIe или Ethernet, и какой протокол будет использоваться для работы с памятью. Но уже обещано, что UALink 1.0 позволит объединить до 1024 ускорителей в одном домене с возможностью прямых load/store-запросов к их памяти. Для дальнейшего масштабирования кластеров по-прежнему предлагается использовать Ultra Ethernet.  При этом UALink, строго говоря, не обещает возможности беспрепятственного общения ускорителей разных вендоров, зато позволяет упростить инфраструктуру и сделать её дешевле благодаря открытости и конкуренции. Хотя было бы приятно увидеть UALink в качестве аппаратной основы и для стандарта UXL, который намерен побороться с NVIDIA CUDA. Что касается CXL, то этот стандарт, тоже использующий PCIe в качестве транспорта, вероятно, останется «привязанным» к CPU и внутриузловым коммуникациям, хотя возможности его гораздо шире.
01.05.2024 [17:00], Сергей Карасёв
Внутри и снаружи: PCI-SIG обнародовала спецификации кабелей CopprLink для PCIe 5.0/6.0Организация PCI Special Interest Group (PCI-SIG) обнародовала спецификации электрических кабелей и разъёмов CopprLink для внешних и внутренних подключений PCIe 5.0/6.0. Новые соединения на основе меди позволят заменить существующие кабели OCuLink в тех случаях, когда требуется более высокая пропускная способность. Стандарт CopprLink был анонсирован в конце 2023 года. Кабели данного типа обеспечат высокоскоростные подключения в пределах отдельных систем, а также между различными узлами в составе стойки. Кроме того, как отмечалось ранее, разрабатываются варианты для межстоечного соединения. Спецификация CopprLink для внутренних подключений:

Источник изображений: PCI-SIG Спецификация CopprLink для внешних подключений:
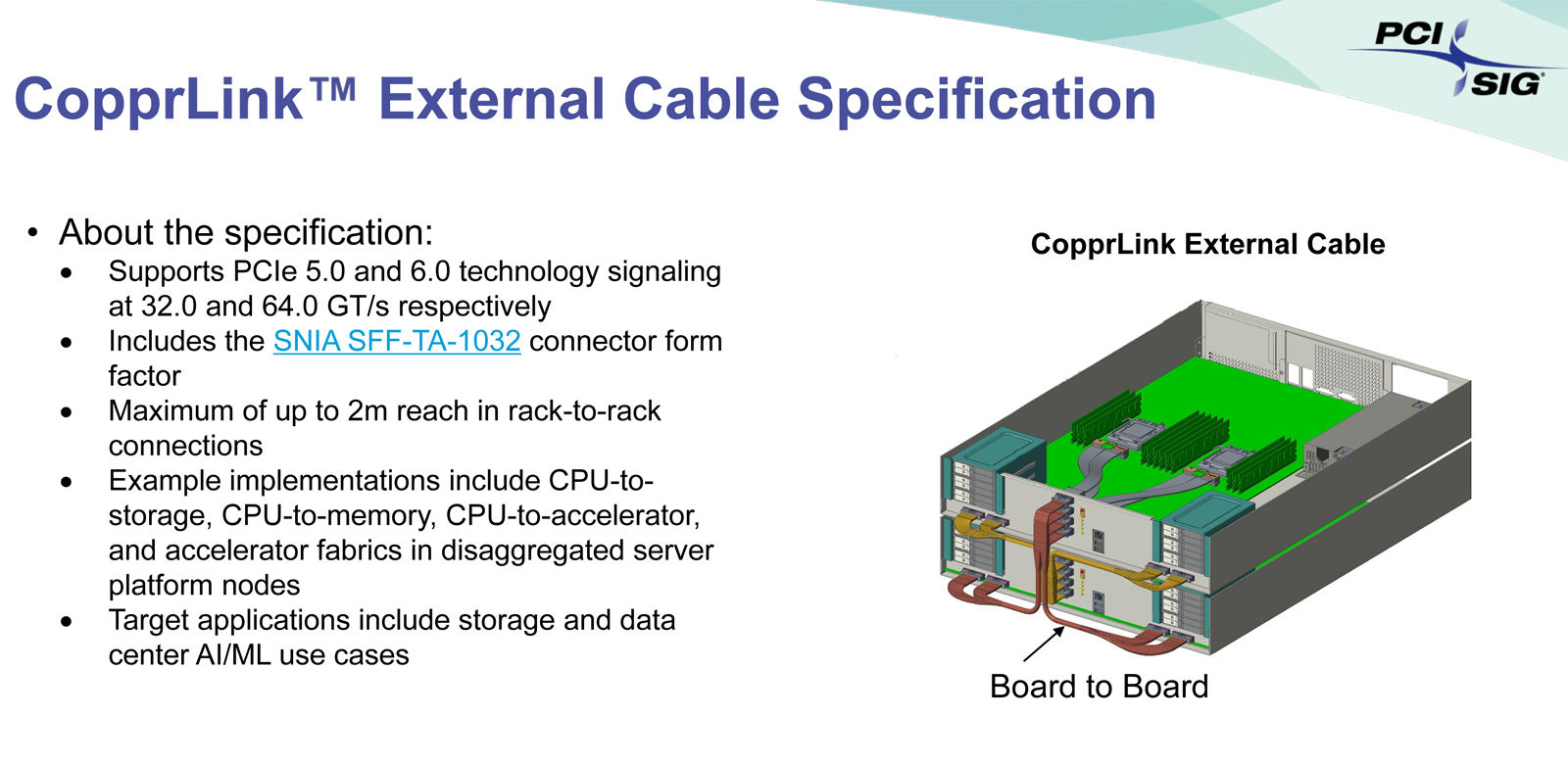 Отмечается, что в дальнейшем кабели CopprLink будут развиваться с учётом возможностей интерфейса PCIe следующих поколений. Технология CopprLink, как ожидается, будет востребована в сферах, где необходимы небольшие задержки, включая дата-центры, производительные СХД, сети и пр. В будущем ожидается появление оптических кабелей PCIe. 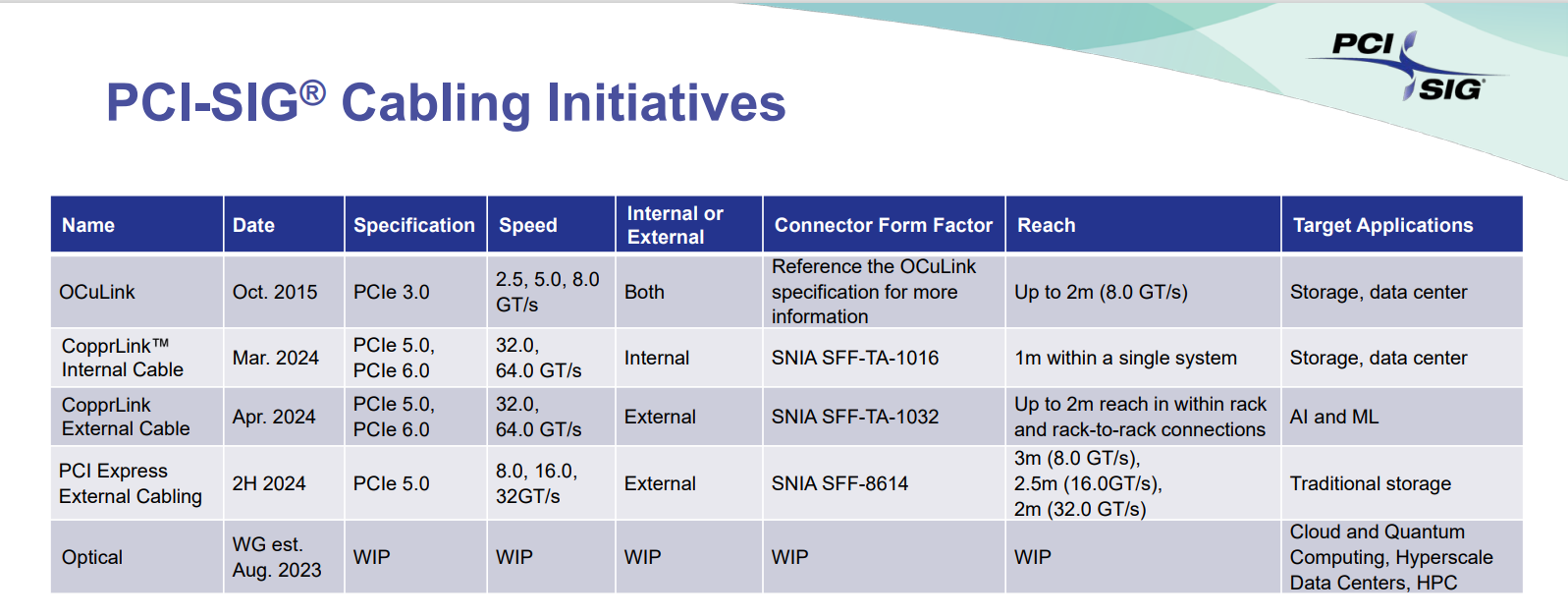
11.04.2024 [22:27], Алексей Степин
ИИ-ускорители NVIDIA являются самими дорогими в мире контроллерами памяти — Celestial AI предлагает связать оптикой HBM, DDR5 и процессорыВ 2024 году нельзя пожаловаться на отсутствие подходящего интерконнекта, если целью является «сшивка» в единую систему сотен, тысяч или даже десятков тысяч ускорителей. Есть NVIDIA NVLink и InfiniBand. Google использует оптические коммутаторы OCS, AMD вскоре выведет Infinity Fabric на межузловой уровень, да и старый добрый Ethernet отнюдь не собирается сдавать позиций и обретает новую жизнь в виде Ultra Ethernet. Проблема не в наличии и выборе подходящего интерконнекта, а в резкой потере пропускной способности за пределами упаковки чипа (т.н. Memory Wall). Да, память HBM быстра, но намертво привязана к вычислительным ресурсам, а в итоге, как отметил глава Celestial AI в комментарии изданию The Next Platform, индустрия ИИ использует ускорители NVIDIA в качестве самых дорогих в мире контроллеров памяти. Celestial AI ещё в прошлом году объявила, что ставит своей целью создание универсального «умного» интерконнекта на основе фотоники, который смог бы использоваться во всех нишах, требующих активного обмена большими потоками данных, от межкристалльной (chip-to-chip) до межузловой (node-to-node). Недавно она получила дополнительный пакет инвестиций объёмом $175 млн. 
Источник изображений здесь и далее: Celestial AI Технология, названная Photonic Fabric, если верить заявлениям Celestial AI, способна в 25 раз увеличить пропускную способность и объёмы доступной памяти при на порядок меньшем энергопотреблении в сравнении с существующими системами соединений. Развивается она в трёх направлениях: чиплеты, интерпозеры и оптический аналог технологии Intel EMIB под названием OMIB. Наиболее простым способом интеграции своей технологии Celestial AI справедливо считает чиплеты. В настоящее время разработанный компанией модуль обеспечивает пропускную способность за пределами чипа на уровне 14,4 Тбит/с (1,8 Тбайт/с), а по размерам он немного уступает стандартной сборке HBM. Но это лишь первое поколение: во втором поколении Photonic Fabric 56-Гбит/с SerDes-блоки SerDes будут заменены на блоки класса 112 Гбит/с (PAM4). 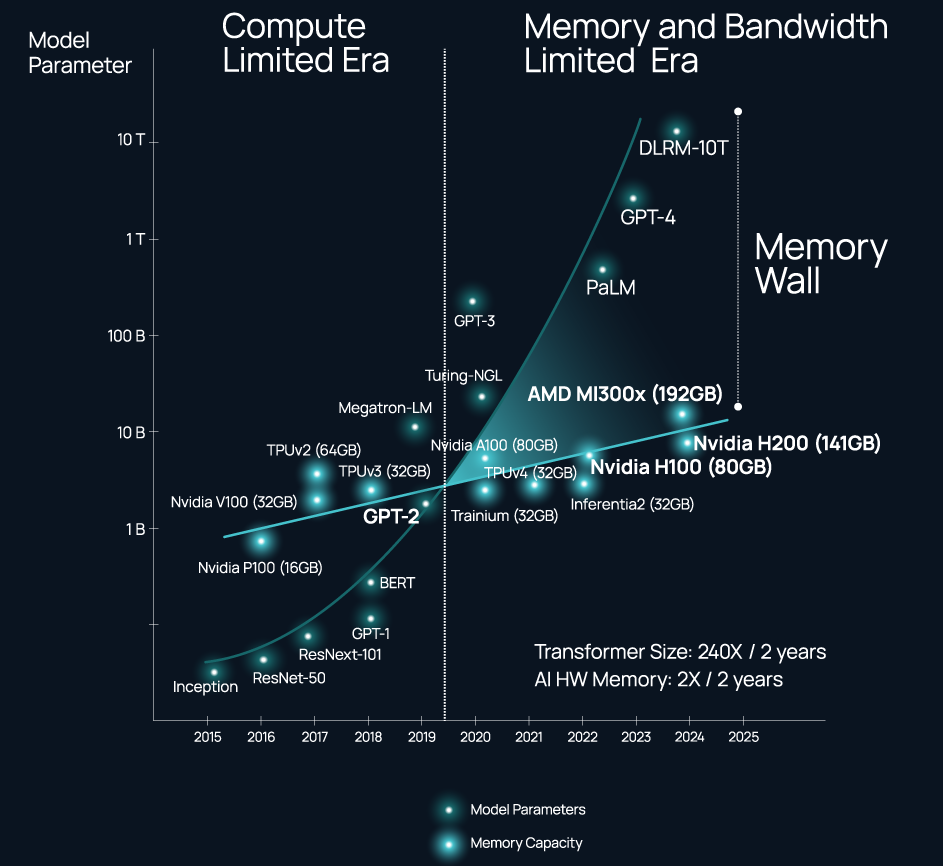
Пресловутая «Стена Памяти» Поскольку речь идёт о системах с дезагрегацией ресурсов, проблему быстрого доступа к большому объёму памяти Celestial AI предлагает решить следующим образом: новый чиплет, содержащий помимо интерконнекта две сборки HBM общим объёмом 72 Гбайт, получит также поддержку четырёх DDR5 DIMM суммарным объёмом до 2 Тбайт. С использованием 5-нм техпроцесса такой чиплет сможет легко превратить HBM в быстрый сквозной кеш (write through) для DDR5. Фактически речь идёт об относительно простом и сравнительно доступном способе превратить любой процессор с чиплетной компоновкой в дезагрегированный аналог Intel Xeon Max или NVIDIA Grace Hopper. При этом латентность при удалённом обращении к памяти не превысит 120 нс, а энергозатраты в данном случае составят на порядок меньшую величину, нежели в случае с NVLink — всего 6,2 пДж/бит против 62,5 пДж/бит у NVIDIA. 
Новый чиплет Celestial породнит HBM с DDR5 теснее, нежели это сделала NVIDIA Таким образом, с использованием новых чиплетных контроллеров памяти становятся реальными системы, где все чипы, от CPU до сетевых процессоров и ускорителей, будут объединены единым фотонным интерконнектом и при этом будут иметь общий пул памяти DDR5 большого объёма с эффективным HBM-кешированием. По словам Celestial AI, она уже сотрудничает с некоторыми гиперскейлерами и с одним «крупным производителем процессоров». По словам руководителя Celestial AI, образцы чиплетов с поддержкой Photonic Fabric появятся во II половине 2025 года, а массовое внедрение начнется уже в 2027 году. Однако это может оказаться гонкой на выживание: Ayar Labs, другой разработчик фотоники, получившая поддержку со стороны Intel, уже показала прототип процессора с интегрированным фотонным интерконнектом. А Lightmatter ещё в декабре получила финансирование в объёме $155 млн на разработку фотонного интерпозера Passage и якобы уже сотрудничает с клиентами, заинтересованными в создании суперкомпьютера с 300 тыс. узлов. Нельзя сбрасывать со счетов и Eliyan, предлагающую вообще отказаться от технологии интерпозеров и заменить её на контроллеры физического уровня NuLink. |
|
{kind=link}