Материалы по тегу: суперкомпьютер
|
25.11.2024 [13:10], Руслан Авдеев
Эффективность новинок NVIDIA в рейтинге суперкомпьютеров Green500 оказалась под вопросом из-за чипов AMD и… самой NVIDIAХотя ускорители NVIDIA считаются одними из самых энергоёмких в своём классе, суперкомпьютеры на основе чипов компании по-прежнему доминируют в мировом рейтинге энергоэффективности соответствующих машин — Green500. Тем не менее компания столкнулась с сильной конкуренцией со стороны AMD и не всегда готова состязаться даже с собственной продукцией, сообщает The Register. На первый взгляд, лидерство проектов на базе NVIDIA неоспоримо. Восемь из десяти суперкомпьютеров, входящих в «Топ-10» энергоэффективных машин, построены на чипах NVIDIA, из них пять — на 1000-ваттных гибридных ускорителях GH200. В новейшем рейтинге Green500 на их основе построены первая и вторая из наиболее энергоэффективных систем — JEDI (EuroHPC) и ROMEO-2025 (Romeo HPC Center). В бенчмарке High-Performance Linpack они продемонстрировали производительность 72,7 Гфлопс/Вт и 70,9 Гфлопс/Вт соответственно (FP64). Системы почти идентичны и построены на платформе BullSequana XH3000 компании Eviden (Atos). На решение GH200 также приходятся четвёртая, шестая и седьмая позиции рейтинга: Isambard-AI Phase 1 (68,8 Гфлопс/Вт), Jupiter Exascale Transition Instrument (67,9 Гфлопс/Вт) и Helios (66,9 Гфлопс/Вт). Системы с проверенными NVIDIA H100 занимают пятое, восьмое и девятое места — это Capella, Henri и HoreKa-Teal. 
Источник изображения: Jakub Żerdzicki/unsplash.com Тем не менее есть сомнения в том, что продукты NVIDIA и дальше будут безраздельно господствовать в рейтинге Green500. Уже на подходе решения Grace-Blackwell в виде GB200 (2,7 кВт) и GB200 NVL4 (5,4 кВт). Новые продукты далеко не всегда обеспечивают максимальную производительность на ватт энергии. При переходе от A100 (2020 год) к H100 (2022 год) FP64-производительность взлетела приблизительно в 3,5 раза, но в сравнении с 1,2-кВт платформой Blackwell даже 700-Вт H100 в режиме матричных FP64-вычислений фактически быстрее. Для FP64 улучшилась только работа с векторными операциями, где новинки оказались на 32 % производительнее. Другими словами, хотя сегодня NVIDIA может похвастаться высоким положением в рейтинге Green500, решение на ускорителях MI300A компании AMD уже заняло третье место (Adastra 2). MI300A анонсировали чуть менее года назад, решение получило 24-ядерный CPU и шесть чиплетов CDNA-3 в едином APU-модуле, оснащённым до 128 Гбайт памяти HBM3, а также настраиваемый уровень TDP 550–760 Вт. Более того, такая система в 1,8 раза производительнее NVIDIA H100 (по крайней мере, на бумаге). Суперкомпьютер Adastra 2 на базе HPE Cray EX255a обеспечивает производительность 69 Гфлопс/Вт. Десятое место также занимает машина на MI300A — RZAdams Ливерморской национальной лаборатории (62,8 Гфлопс/Вт). Таким образом, все системы, входящие в первую десятку рейтинга Green500, уже значительно превышают целевой показатель энергоэффективности в 50 Гфлопс/Вт, необходимый для достижений 1 Эфлопс (FP64) при энергопотреблении до 20 МВт. Проблема в том, что малые системы значительно эффективнее: JEDI потребляет всего 67 кВт, а самая производительная машина на базе GH200 в рейтинге TOP500 — швейцарская Alps — обеспечивает 434 Пфлопс (FP64), потребляя 7,1 МВт — это лишь 14-я из наиболее энергоэффективных машин (61 Гфлопс/Вт). Та же проблема и с Adastra 2: компьютер потребляет даже меньше JEDI — 37 кВт. Если бы удалось сохранять уровень 69 Гфлопс/Вт в больших масштабах, потребовалось бы всего 25,2 МВт для достижения 1,742 Эфлопс, как у El Capitan. Но последнему требуется около 29,6 МВт для достижения таких рекордных показателей.
25.11.2024 [11:40], Владимир Мироненко
Hyperion Research: рынок HPC куда больше, чем считается, и растёт он куда быстрееАналитики The Next Platform считают, что обучение и инференс ИИ в ЦОД также относятся к высокопроизводительным вычислениям (HPC), хотя в некоторых случаях могут значительно отличаться от их традиционного определения. HPC используют небольшой набор данных, расширяя его до огромных симуляций, таких как прогнозы погоды или климата, в то время как ИИ анализирует массу данных о мире и преобразует их в модель, в которую можно добавлять новые данные для ответа на вопросы, сообщается на ресурсе The Next Platform. HPC и ИИ имеют разные потребности в вычислительных ресурсах, памяти и пропускной способности на разных этапах обработки приложений. Но в конечном итоге как при HPC, так и при обучении ИИ компании стремятся объединить множество узлов в единую систему для выполнения больших объёмов работы, которые невозможно выполнить иначе. 
Источник изображений: Hyperion Research Для получения «реальных» данных о рынке HPC необходимо добавить к расходам на традиционные платформы ModSim (моделирование и симуляция) средства, потраченные на применение технологий генеративного ИИ, традиционное обучение и инференс ИИ в ЦОД. Исходя из этого, Hyperion Research значительно пересмотрела оценку рынка, учтя продажи серверов ИИ, которые ранее не включались в расчёты, в том числе решения компаний NVIDIA, Supermicro и других.  В обновлённом прогнозе рынка HPC, представленном Hyperion Research в минувший вторник, расходы на серверы значительно выросли благодаря добавлению «нетрадиционных поставщиков». В 2021 году было продано серверов в объединённом секторе HPC/ИИ на $1,34 млрд, в 2022 году расходы на их покупку составили $3,44 млрд, а в 2023 году, благодаря буму на генеративный ИИ, они подскочили до $5,78 млрд. Hyperion Research ожидает, что эти производители заработают на серверах $7,46 млрд в 2024 году, и их доходы почти удвоятся к 2028 году, достигнув $14,97 млрд.  Историческая часть рынка серверов HPC/ИИ (согласно прежней методике), показанная синим цветом на диаграмме, как ожидается, составит $17,93 млрд в этом году и вырастет до $26,81 млрд к 2028 году. Объединённый рынок HPC/ИИ с учётом нового подхода составит в этом году $25,39 млрд и будет расти ежегодно на 15 %, достигнув $41,78 млрд к 2028 году.  Как отметили в Hyperion Research, теперь не все расходы на вычисления HPC и ИИ осуществляются локально (on-premise). Большая часть ИТ-бюджета на рабочие нагрузки HPC и ИИ переносится в облако.  Hyperion подсчитала, что приложения HPC и ИИ, работающие в облаке, в совокупности «потребили» $7,18 млрд виртуальных серверных мощностей в 2023 году и что эти цифры вырастут на 21,2 % до $8,71 млрд в 2024 году. К 2028 году расходы на вычислительные мощности HPC и ИИ в облаке составят $15,11 млрд, а совокупные годовые темпы роста с 2023 по 2028 год составят 16,1 %.  Помимо затрат на вычисления, бюджет HPC и ИИ включает расходы на хранение, ПО и сервисы. Hyperion ожидает, что в 2024 году общие расходы на HPC и ИИ вырастут на 22,4 %, с $42,4 млрд до $51,9 млрд. При совокупном годовом темпе роста в 15 % в период с 2023 по 2028 год все затраты на HPC и ИИ составят к 2028 году $85,5 млрд, что в два раза превышает показатель нынешнего года.  Согласно данным Hyperion, в 2021 году в Китае было установлено две экзафлопсные системы стоимостью $350 млн каждая. Также по одной системе с такой же стоимостью было установлено в 2023 году и нынешнем году. Hyperion ожидает, что в 2025 году Китай установит ещё одну или две экзафлопсные системы с оценочной стоимостью $300 млн за штуку и ещё две с такой же стоимостью в 2026 году. Общая стоимость девяти экзафлопсных систем составит около $2,95 млрд — примерно столько стартап xAI, курируемый Илоном Маском (Elon Musk), израсходовал на создание кластера Colossus из 100 000 ускорителей NVIDIA H100. В Японии до сих пор нет суперкомпьютера эксафлопсного класса (речь об FP64-производительности), и она получит свой первый такой суперкомпьютер стоимостью $200 млн в 2026 году. В 2027 и 2028 годах, как ожидает Hyperion, Япония построит две или три такие суперкомпьютерные системы стоимостью около $150 млн за единицу, потратив в общей сложности $300–450 млн. В Европе есть несколько преэкзафлопсных систем, и в 2025 году она получит две экзафлопсные системы по оценочной стоимости $350 млн каждая, а в 2026 году здесь появится ещё две или три системы стоимостью около $325 млн. Также следует ожидать строительство двух или трёх машин в 2027 году стоимостью $300 млн каждая и двух или трёх в 2028 году стоимостью $275 млн каждая. То есть в предстоящие несколько лет в Европе будет построено одиннадцать экзафлопсных суперкомпьютеров общей стоимостью $3,4 млрд. 
Источник изображения: LLNL В США установили одну экзафлопсную систему в 2022 году (Frontier в Ок-Риджской национальной лаборатории, ORNL) и две — в 2024 году (Aurora в Аргоннской национальной лаборатории и El Capitan в Ливерморской национальной лаборатории им. Э. Лоуренса). По оценкам The Next Platform, за последние годы Соединённые Штаты потратили $1,4 млрд на установку трёх экзафлопсных машин. Согласно прогнозу Hyperion Research, в Соединённых Штатах в 2025 году установят две экзафлопсные системы стоимостью около $600 млн каждая, в 2026 году — одну или две стоимостью $325 млн каждая и одну или две стоимостью $275 млн каждая в 2027 и 2028 годах. В общей сложности будет потрачено $4,35 млрд на одиннадцать экзафлопсных систем.
23.11.2024 [15:35], Сергей Карасёв
Eviden создаст для Финляндии ИИ-суперкомпьютер Roihu производительностью 49 ПфлопсКомпания Eviden (дочерняя структура Atos) объявила о заключении соглашения с Финским научным IT-центром CSC о создании нового национального суперкомпьютера для задач ИИ. Система под названием Roihu, как ожидается, утроит вычислительную мощность существующих комплексов Puhti и Mahti. Суперкомпьютер Puhti общего назначения, запущенный в 2019 году, построен на платформе Atos BullSequana X400 (X1000). В общей сложности используются 682 узла CPU на процессорах Intel Xeon Cascade Lake-SP с пиковой FP64-производительностью 1,8 Пфлопс. Кроме того, применены 80 узлов GPU, каждый из которых несёт на борту четыре ускорителя NVIDIA V100: быстродействие этой секции — до 2,7 Пфлопс. Основной интерконнект — InfiniBand HDR100. В свою очередь, система Mahti (на изображении), введённая в эксплуатацию в 2020-м, основана на платформе Atos BullSequana XH2000. Суперкомпьютер насчитывает 1404 узла CPU и 24 узла GPU с теоретической пиковой FP64-производительностью 7,5 Пфлос и 2,0 Пфлопс соответственно. Все узлы содержат по два чипа AMD Rome 7H12, тогда как GPU-серверы комплектуются четырьмя ускорителями NVIDIA Ampere A100. 
Источник изображения: CSC В основу нового суперкомпьютера Roihu ляжет гибридная платформа BullSequana XH3000, которая позволяет объединять в рамках одного кластера чипы AMD, Intel и NVIDIA. Теоретическая пиковая производительность заявлена на уровне 49 Пфлопс (точность вычислений не уточняется). Прочие технические характеристики проектируемой машины пока не раскрываются. Стоимость контакта по созданию Roihu оценивается в €60 млн. Систему планируется использовать для широкого спектра задач, включая анализ аудио- и видеозаписей, ресурсоёмкие приложения ИИ в различных областях и традиционные нагрузки, такие как гидродинамика и моделирование климата. Кроме того, мощности суперкомпьютера будут применяться в образовательных целях.
22.11.2024 [10:15], Сергей Карасёв
Oracle объявила о доступности облачного ИИ-суперкомпьютера из 65 тыс. NVIDIA H200Корпорация Oracle сообщила о доступности облачного суперкластера с ускорителями NVIDIA H200, предназначенного для ресурсоёмких ИИ-нагрузок, включая обучение больших языковых моделей (LLM). Арендовать мощности системы можно по цене от $10 в час в расчёте на GPU. Кластер масштабируется до 65 536 ускорителей. В максимальной конфигурации теоретическое пиковое быстродействие достигает 260 Эфлопс на операциях FP8, что более чем в четыре раза превышает показатели систем предыдущего поколения. Утверждается, что на сегодняшний день это самый высокопроизводительный облачный ИИ-суперкомпьютер, доступный в облаке. Сейчас компания готовится к созданию облачного кластера из 131 тыс. NVIDIA B200. Новые инстансы получили обозначение BM.GPU.H200.8. Каждая виртуальная машина типа Bare Metal (без гипервизора) содержит восемь изделий NVIDIA H200 (141 Гбайт памяти HBM3e), объединённых посредством NVIDIA NVLink. Задействованы два процессора Intel Xeon Platinum 8480+ поколения Sapphire Rapids (56C/112T; до 3,8 ГГц; 350 Вт). Объём системной памяти DDR5 составляет 3 Тбайт. В состав локального хранилища входят восемь NVMe SSD вместимостью 3,84 Тбайт каждый. 
Источник изображения: NVIDIA Кластер использует кастомную RoCE-сеть на базе NVIDIA ConnectX-7 с суммарной пропускной способностью 3200 Гбит/с (восемь каналов по 400 Гбит/с) на узел. Инстансы включают frontend-сеть с пропускной способностью 200 Гбит/с. По данным Oracle, каждый инстанс в суперкластере содержит на 76 % больше памяти HBM по сравнению с виртуальными машинами на основе NVIDIA H100, а пропускная способность памяти увеличена на 40 %. Таким образом, производительность инференса выросла в 1,9 раза.
21.11.2024 [12:23], Руслан Авдеев
Суперкомпьютеры Eviden заняли первые места в рейтинге энергоэффективных систем Green500Входящая в группу Atos компания Eviden объявила, что 55 её суперкомпьютеров вошли в список TOP500 наиболее производительных вычислительных машин, а два из них лидируют в рейтинге наиболее энергоэффективных суперкомпьютеров мира Green500. За последние 10 лет экспоненциально выросла вычислительная мощность, что в том числе обусловлено достижениями в области систем искусственного интеллекта. При этом растёт и энергопотребление — его снижение стало одной из главных задач при разработке и строительстве суперкомпьютеров. В первую десятку рейтинга Green500 вошли три машины Eviden, в каждой из которых применяется проприетарная технология прямого жидкостного охлаждения, предусматривающая охлаждение суперкомпьютера тёплой водой с температурой до +40 °C, это помогает добиться отвода более 97 % тепла. 
Источник изображения: Eviden Первое место в рейтинге занимает модуль JEDI суперкомпьютера JUPITER — первой системы экзафлопсного класса в Европе, созданный EuroHPC. На втором месте — ROMEO 2025, построенный для Университета Реймса Шампань-Арденн (URCA). Шестое место в Green500 занимает ещё один модуль суперкомпьютера JUPITER — JETI. Другими словами, Eviden стремится предлагать клиентам не только высокопроизводительные, но и экоустойчивые, экономичные машины. В TOP500 наиболее производительных суперкомпьютеров из построенных компанией вошли французская система Jean Zay (№ 27), новейший немецкий модуль JETI для JUPITER (№ 18) и система Gefion для Датского центра инноваций в области искусственного интеллекта (DCAI) под номером 21. По словам представителя Eviden, системы компании лидируют в рейтинге Green500 и «укрепляют лидерство Европы» на рынке HPC. Eviden, на которую работает 41 тыс. человек, предлагает решения в области ИИ, облачных платформ и предоставляет услуги более чем в 47 странах. Годовая выручка этого подразделения Atos Group составляет около €5 млрд. Сама же Atos находится не в лучшем состоянии.
19.11.2024 [23:28], Алексей Степин
HPE обновила HPC-портфолио: узлы Cray EX, СХД E2000, ИИ-серверы ProLiant XD и 400G-интерконнект Slingshot
400gbe
amd
epyc
gb200
h200
habana
hardware
hpc
hpe
intel
mi300
nvidia
sc24
turin
ии
интерконнект
суперкомпьютер
схд
Компания HPE анонсировала обновление модельного ряда HPC-систем HPE Cray Supercomputing EX, а также представила новые модели серверов из серии Proliant. По словам компании, новые HPC-решения предназначены в первую очередь для научно-исследовательских институтов, работающих над решением ресурсоёмких задач. 
Источник изображений: HPE Обновление касается всех компонентов HPE Cray Supercomputing EX. Открывают список новые процессорные модули HPE Cray Supercomputing EX4252 Gen 2 Compute Blade. В их основе лежит пятое поколение серверных процессоров AMD EPYС Turin, которое на сегодняшний день является самым высокоплотным x86-решениями. Новые модули позволят разместить до 98304 ядер в одном шкафу. Отчасти это также заслуга фирменной системы прямого жидкостного охлаждения. Она охватывает все части суперкомпьютера, включая СХД и сетевые коммутаторы. Начало поставок узлов намечено на весну 2025 года. 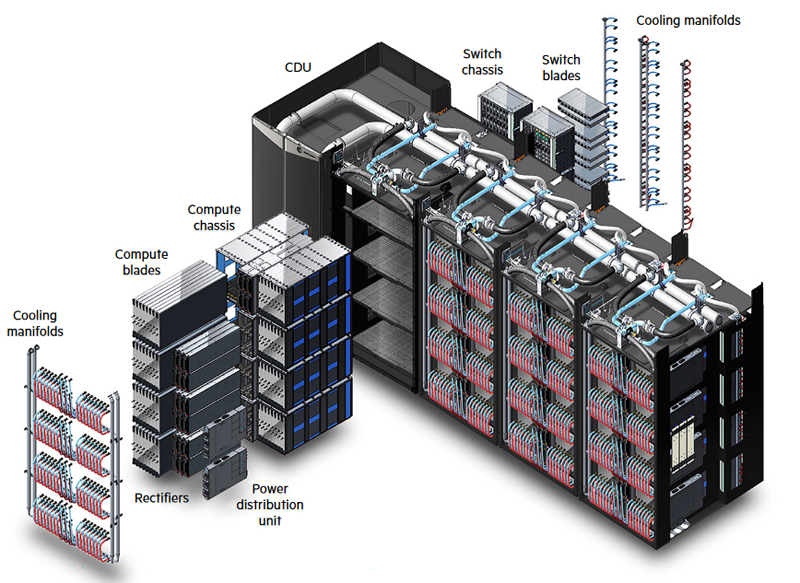 Процессорные «лезвия» дополнены новыми GPU-модулями HPE Cray Supercomputing EX154n Accelerator Blade, позволяющими разместить в одном шкафу до 224 ускорителей NVIDIA Blackwell. Речь идёт о новейших сборках NVIDIA GB200 NVL4 Superchip. Этот компонент появится на рынке позднее — HPE говорит о конце 2025 года. Обновление коснулось и управляющего ПО HPE Cray Supercomputing User Services Software, получившего новые возможности для пользовательской оптимизации вычислений, в том числе путём управления энергопотреблением. Апдейт получит и фирменный интерконнект HPE Slingshot, который «дорастёт» до 400 Гбит/с, т.е. станет вдвое быстрее нынешнего поколения Slingshot. Пропускная способность коммутаторов составит 51,2 Тбит/c. В новом поколении будут реализованы функции автоматического устранения сетевых заторов и адаптивноой маршрутизации с минимальной латентностью. Дебютирует HPE Slingshot interconnect 400 осенью 2024 года.  Ещё одна новинка — СХД HPE Cray Supercomputing Storage Systems E2000, специально разработанная для применения в суперкомпьютерах HPE Cray. В сравнении с предыдущим поколением, новая система должна обеспечить более чем двукратный прирост производительности: с 85 и 65 Гбайт/с до 190 и 140 Гбайт/с при чтении и записи соответственно. В основе новой СХД будет использована ФС Lustre. Появится Supercomputing Storage Systems E2000 уже в начале 2025 года.  Что касается новинок из серии Proliant, то они, в отличие от вышеупомянутых решений HPE Cray, нацелены на рынок обычных ИИ-систем. 5U-сервер HPE ProLiant Compute XD680 с воздушным охлаждением представляет собой решение с оптимальным соотношением производительности к цене, рассчитанное как на обучение ИИ-моделей и их тюнинг, так и на инференс. Он оснащён восемью ускорителями Intel Gaudi3 и двумя процессорами Intel Xeon Emerald Rapids. Новинка поступит на рынок в декабре текущего года.  Более производительный HPE ProLiant Compute XD685 всё так же выполнен в корпусе высотой 5U, но рассчитан на жидкостное охлаждение. Он будет оснащаться восемью ускорителями NVIDIA H200 в формате SXM, либо более новыми решениями Blackwell, но последняя конфигурация будет доступна не ранее 2025 года, когда ускорители поступят на рынок. Уже доступен ранее анонсированный вариант с восемью ускорителями AMD Instinict MI325X и процессорами AMD EPYC Turin.
19.11.2024 [17:30], Сергей Карасёв
1,742 Эфлопс: El Capitan стал самым мощным в мире суперкомпьютером рейтинга TOP500Ливерморская национальная лаборатория им. Э. Лоуренса (LLNL) Министерства энергетики США (DOE), Администрация по национальной ядерной безопасности США (NNSA), компании AMD и HPE официально представили El Capitan — самый производительный в мире суперкомпьютер. Эта машина возглавила ноябрьский рейтинг мощнейших вычислительных систем TOP500. Комплекс El Capitan создан специалистами HPE Cray. Суперкомпьютер обладает FP64-быстродействием 1,742 Эфлопс в тесте Linpack (HPL), тогда как пиковый теоретический показатель достигает 2,746 Эфлопс. Прежний лидер TOP500 — система Frontier — с производительностью 1,353 Эфлопс теперь находится на втором месте рейтинга. Машина Aurora, так и не прибавившая в производительности, хотя и заявленная когда-то как 2-Эфлопс система, занимает теперь третье место. В основу El Capitan легла платформа HPE Cray Shasta. Используется гибридная архитектура AMD с APU Instinct MI300A: изделие содержит 24 ядра Zen 4 общего назначения, блоки CDNA 3 и 128 Гбайт памяти HBM3. В общей сложности в составе суперкомпьютера объединены 11 136 узлов, каждый из которых несёт на борту четыре экземпляра Instinct MI300A. Применён интерконнект HPE Slingshot-11 с пропускной способностью 200 Гбит/с. Система включает узлы Rabbit, которые формируют дезагрегированное NVMe-хранилище с прямым PCIe-подключением к вычислительным узлам. 
Источник изображений: LLNL Суммарное количество ядер CPU и GPU в составе El Capitan достигает 11 039 616, объём памяти — 5,4375 Пбайт. За отвод тепла отвечает система прямого жидкостного охлаждения HPE. Заявленная энергетическая эффективность составляет 58,89 Гфлопс/Вт: с таким показателем машина оказалась на 18-м месте в списке «зелёных» суперкомпьютеров GREEN500, но с учётом масштаба и общего энергопотребления 29,58 МВт — это хороший показатель. Система охлаждения HPC-объекта использует 28 тыс. т воды. Отмечается, что El Capitan станет главным вычислительным ресурсом для Tri-lab — группы, в которую вместе с LLNL входят Сандийские национальные лаборатории (SNL) и Лос-Аламосская национальная лаборатория (LANL). Использовать мощности нового суперкомпьютера планируется для обеспечения национальной безопасности и решения сложных задач, связанных с ядерным оружием. В частности, El Capitan обеспечит беспрецедентные возможности моделирования и имитации, необходимые для Программы управления ядерными запасами NNSA. Кроме того, НРС-комплекс поможет в модернизации и создании нового оружия, такого как боеголовки W87-1 и W93, которые в настоящее время находятся на стадии разработки.  Отмечается также, что на 10-й позиции в рейтинге TOP500 оказался суперкомпьютер Tuolumne, также построенный в рамках проекта LLNL и NNSA. Фактически Tuolumne — это младший брат El Capitan: машина использует ту же архитектуру на базе Instinct MI300A, но обладает примерно на порядок меньшей FP64-производительностью 208,10 Пфлопс с пиковым значением 288,88 Пфлопс. Применять мощности Tuolumne планируется для «несекретных» задач, таких как исследования в области энергетической безопасности, изменений климата, вычислительной биологии, разработки лекарственных препаратов следующего поколения и пр. Стоит отметить, что Frontier — не единственная система, которая уступила пальму первенства более новым НРС-комплексам в ноябрьском рейтинге TOP500. Та же участь постигла самый мощный суперкомпьютер Европы LUMI, который опустился с пятого на восьмое место. На пятой позиции оказалась совершенно новая система HPC6, расположенная в центре нефтегазовой компании Eni в Феррера-Эрбоньоне (Италия). Её производительность достигает 477,9 Пфлопс при пиковом показателе 606,97 Пфлопс.
19.11.2024 [12:57], Руслан Авдеев
Dell отобрала у Supermicro крупный заказ на ИИ-серверы для xAI Илона МаскаОснованный Илоном Маском (Elon Musk) стартап xAI, похоже, отнял все прежние заказы на ИИ-серверы у испытывающей не лучшие времена Supermicro, чтобы передать их её конкурентам. Как сообщает UDN, выгодоприобретателями станет Dell, а также её партнёры Inventec и Wistron. Для Supermicro, которой и без того грозит делистинг с Nasdaq, это станет очередным ударом. Ранее Dell и Supermicro поставляли оборудования компаниям Илона Маска, в т.ч. xAI и Tesla. Официально сообщалось, что xAI закупила ИИ-серверы с жидкостным охлаждением у Supermicro. Но после того, как Министерство юстиции США начало расследование деятельности поставщика в связи с вероятными махинациями с бухгалтерской отчётностью и нарушением санкционного режима, акции компании обрушились. После этого, по данным UDN, компании Маска и приняли решения передать заказы другим исполнителям. Среди поставщиков ИИ-серверов у Dell хорошие возможности получения заказов. Например, Wistron выпускает материнские платы для ИИ-серверов компании и выполняет некоторые задачи по сборке — партнёры станут одними из основных бенефициаров краха Supermicro. Фактически Wistron уже расширяет производственные мощности для удовлетворения спроса, в частности на трёх заводах на Тайване, а также в Мексике. В Wistron смотрят в будущее с большим оптимизмом и ожидают, что спрос на ИИ-серверы будет расти «трёхзначными» значениями в процентном отношении. 
Источник изображения: Bermix Studio/unsplash.com Inventec также является крупным поставщиком Dell и тоже получит свою долю «пирога» от заказа Supermicro. Компания давно участвует в производстве ИИ-систем и входит в тройку ведущих партнёров Dell, участвующих в сборке серверов. В 2024 году компания поставляла машины на чипах семейства NVIDIA Hopper, но в I квартале 2025 года она сможет поставлять уже варианты на платформе NVIDIA Blackwell — с ускорителями B200 и B200A. Считается, что у компании есть свободные производственные мощности в Мексике, поэтому она сможет нарастить выпуск ИИ-серверов для компаний, ранее работавших с Supermicro. 
Фото: Michael Dell Одной из ключевых причин проблем Supermicro считается задержка с подачей финансовых документов, из-за чего компания рискует покинуть биржу Nasdaq. Чтобы избежать делистинга, Supermicro должна была объяснить задержки с подачей материалов и подать доклад по форме K-10 к 16 ноября, но сделать этого не успела. Впрочем, первые неприятности у Supermicro начались значительно раньше, когда Hindenburg Research опубликовала разгромный доклад о финансовой отчётности компании. Если Supermicro дождётся делистинга на бирже, это приведёт к серьёзными финансовыми последствиями, включая стремительное падение акций и необходимость немедленного погашения долга $1,725 млрд по конвертируемым облигациям — обычно такие «триггеры» учитываются в соглашениях и активируются при делистинге. Буквально на днях сообщалось, что Supermicro лишилась заказа от индонезийской YTL Group (YTLP) на поставку суперускорителей NVIDIA GB200 NVL72 для одного из крупнейших в Юго-Восточной Азии ИИ-суперкомпьютеров. Теперь поставками будет заниматься только Wiwynn, которая принадлежит всё той же Wistron. При этом сама Wiwynn сейчас судится с X (Twitter), которой владеет Илон Маск.
18.11.2024 [13:38], Руслан Авдеев
Foxlink запустила мощнейший на Тайване суперкомпьютер для малого и среднего бизнесаFoxlink Group (Cheng Uei Precision Industry) открыла крупнейший на Тайване суперкомпьютерный центр Ubilink (Ubilink.AI). По данным DigiTimes, центр предназначен для обслуживания предприятий малого и среднего бизнеса (SME), которые не могут позволить себе собственных вычислительных мощностей. Хотя основной деятельностью Foxlink является производство разъёмов, компания расширяет бизнес, осваивая решения для управления электропитанием и коммуникаций, а также выпуск энергетических модулей. Центр Ubilink создан дочерней Shinfox Energy совместно с Asustek Computer и японской Ubitus, занимающейся предоставлением облачных услуг. В Ubitus сообщили, что инфраструктура Ubilink включает 128 серверов Asus, 1024 ускорителя NVIDIA H100 и интерконнект NVIDIA Quantum-2 InfiniBand. Конфигурация обеспечивает до 45,82 Пфлопс (FP64) — система занимает 31-е место в рейтинге TOP500. В будущем станут применять и более современные B100 и B200 — когда те будут доступны. Ожидается, что в 2025 году суммарно будет установлено 10 240 ускорителей H100, B100 и B200. Представители местных властей уже заявили, что Ubilink существенно улучшит позиции Тайваня на рынке ИИ-вычислений, на котором территория сегодня занимает 26-е место. В Asustek добавляют, что достигнутая производительность в 45,82 Пфлопс заметно превышает плановые 40 Пфлопс. Кроме того, центр имеет PUE на уровне 1,2 — ранее ожидалось, что удастся добиться энергоэффективности лишь на уровне 1,38. Благодаря использованию опыта Shinfox Energy в области возобновляемой энергетики, Ubilink стал первым в Азии суперкомпьютерным центром, использующим «зелёные» источники энергии — клиенты могут воспользоваться вычислениями без существенного ущерба окружающей среде. 
Источник изображения: UBITUS Предполагается, что Ubilink компенсирует отсутствие мощностей для местных малых и средних компаний, не имеющих доступа к значительным вычислительным ресурсам. Предлагая доступные вычислительные мощности, центр позволяет таким бизнесам расширить свои портфели предложений и конкурировать даже на мировом уровне. Суперкомпьютер уже востребован местными разработчиками чипов, компаний, занимающихся их упаковкой и тестированием, биотехнологическими бизнесами, а также исследовательскими институтами различной направленности. Из-за высокого спроса Foxlink уже рассматривает вторую и третью фазы расширения проекта.
17.11.2024 [11:32], Сергей Карасёв
NEC создаст в Японии суперкомпьютер на базе Intel Xeon 6900P и AMD Instinct MI300A для исследований термоядерного синтезаКорпорация NEC займётся созданием нового НРС-комплекса, который планируется ввести в эксплуатацию в Японии в июле 2025 года. Система, базирующаяся на компонентах AMD и Intel, будет использоваться для различных исследований и разработок в области термоядерного синтеза. Заказ на создание суперкомпьютера поступил от Национальных институтов квантовой науки и технологий Японии (QST) при Национальном агентстве исследований и разработок (ANID), а также от Национального института термоядерных наук (NIFS) в составе Национальных институтов естественных наук (NINS). Система будет установлена в Институте термоядерной энергии Rokkasho (входит в QST) в Аомори (Япония). Основой проектируемого суперкомпьютера послужат 360 узлов NEC LX 204Bin-3, в состав каждого из которых войдут два процессора Intel Xeon 6900P поколения Granite Rapids (всего 720 чипов) и память DDR5 MRDIMM. Кроме того, будут задействованы 70 узлов NEC LX 401Bax-3GA, несущих на борту по четыре ускорителя AMD Instinct MI300A (в общей сложности 280 изделий). Говорится о применении интерконнекта InfiniBand с 400G-коммутаторами NVIDIA QM9700, а также хранилища DDN EXAScaler ES400NVX2 вместимостью 42,2 Пбайт с файловой системой Lustre. Для управления рабочими нагрузками будет использоваться софт Altair PBS Professional. 
Источник изображения: NEC Ожидается, что производительность суперкомпьютера достигнет 40,4 Пфлопс. Это в 2,7 раза больше суммарных показателей двух нынешних НРС-систем, установленных в рамках независимых проектов QST и NIFS. Учёные намерены применять новый НРС-комплекс для точного прогнозирования экспериментов и создания сценариев работы для Международного экспериментального термоядерного реактора (ITER). Кроме того, мощности суперкомпьютера будут востребованы исследовательскими группами токамака Satellite Tokamak JT-60SA и электростанции DEMO (DEMOnstration Power Plant), использующей термоядерный синтез. |
|