Материалы по тегу: суперкомпьютер
|
26.02.2024 [13:44], Сергей Карасёв
В России официально представлен суперкомпьютер «Сергей Годунов» производительностью 54,4 ТфлопсВ Институте математики имени С. Л. Соболева Сибирского отделения Российской академии наук (ИМ СО РАН) официально представлен вычислительный комплекс «Сергей Годунов», названный в честь известного советского и российского математика. Монтажом и тестированием системы занимались специалисты группы компаний РСК. Суперкомпьютер создан на базе высокоплотной и энергоэффективной платформы «РСК Торнадо» с жидкостным охлаждением. Каждый из узлов в составе системы оснащён двумя процессорами Intel Xeon Ice Lake-SP с 38 ядрами, работающими на базовой частоте 2,4 ГГц. Производительность кластера на момент запуска составляет 54,4 Тфлопс. Предполагается, что HPC-комплекс поможет повысить эффективность научных исследований и будет способствовать развитию новых технологий. Среди сфер применения суперкомпьютера названы: медицинская электроакустическая томография; моделирование эпидемиологических, экологических, экономических и социальных процессов; вычислительная аэрогидродинамика и задачи оптимизации турбулентных течений; моделирование и построение сценариев развития системы биосфера-экономика-социум с учётом безуглеродного и устойчивого развития и изменения климата; решение обратных задач геофизики прямым методом на основе подхода Гельфанда-Левитана-Крейна». 
Источник изображений: РСК Отмечается, что монтажные и пуско-наладочные работы в рамках проекта произведены в сжатые сроки — за 3,5 недели. В перспективе возможности системы будут расширяться. В частности, в 2024 году планируется осуществить модернизацию, которая позволит более чем вдвое нарастить производительность — до 120,4 Тфлопс.  «У нас появилась возможность решать мультидисциплинарные задачи, моделировать объёмные процессы и предсказывать поведение сложных математических систем. На суперкомпьютере проводятся вычисления по критически важным проблемам и задачам, стоящим перед РФ», — отмечает исполняющий обязанности директора ИМ СО РАН Андрей Миронов. В целом, запущенный комплекс является основным инструментом для проведения исследований и прикладных разработок в академгородке Новосибирска и создания технологической платформы под эгидой Научного совета Отделения математических наук РАН по математическому моделированию распространения эпидемий с учётом социальных, экономических и экологических процессов.
23.02.2024 [19:07], Сергей Карасёв
Австралийский суперкомпьютерный центр внедрит суперчипы NVIDIA Grace Hopper для квантовых исследованийАвстралийский суперкомпьютерный центр Pawsey начнёт использовать решение NVIDIA CUDA Quantum — открытую платформу для интеграции и программирования CPU, GPU и квантовых компьютеров (QPU). Ожидается, что это поможет ускорить развитие перспективного направления квантовых вычислений. Pawsey развернёт в своём Национальном центре инноваций в области суперкомпьютеров и квантовых вычислений восемь узлов с суперчипами NVIDIA GH200. Эти изделия содержат 72-ядерный Arm-процессор Grace и ускоритель H100 с 96 Гбайт HBM3. Объём общей для обоих кристаллов памяти составляет 576 Гбайт (480 Гбайт LPDDR5x). Кристаллы соединены между собой шиной NVLink-C2C, обеспечивающей пропускную способность 900 Гбайт/с. Сообщается, что узлы проектируемой системы будут использовать модульную архитектуру NVIDIA MGX, которая предназначена для построения HPC-систем и комплексов ИИ. Предполагается, что высокопроизводительная гибридная платформа с CPU, GPU и QPU позволит выполнять высокоточные и гибко масштабируемые квантовые симуляции. В рамках проекта будет применяться специализированное ПО NVIDIA cuQuantum для разработки квантовых решений. 
Источник изображения: NVIDIA Национальное научное агентство Австралии (CSIRO) оценивает размер внутреннего рынка квантовых вычислений в $2,5 млрд в год с потенциалом создания до 10 тыс. новых рабочих мест к 2040-му. Для достижения таких показателей необходимо внедрение квантовых вычислений в различных областях, включая астрономию, науки о жизни, медицину, финансы и пр.
22.02.2024 [18:45], Руслан Авдеев
Австралийское Минобороны представило мощный суперкомпьютер Taingiwilta, не сказав о нём практически ни словаАвстралийский суперкомпьютер Taingiwilta для нужд Минобороны Австралии должен заработать уже в этом году, но военное ведомство отказывается сообщать хоть какие-то детали о его характеристиках и возможностях. The Register сообщает, что и ответственная за создание машины Defence Science Technology Group отказалась давать комментарии относительно спецификаций системы. Впрочем, представитель разработчика суперкомпьютера всё-таки сообщил, что часть ПО для машины создано в рамках проекта Министерства обороны США Computational Research and Engineering Acquisition Tools and Environments (CREATE). В частности, суперкомпьютер будет использоваться для вычислительной гидродинамики. Потребуются и сложные средства разграничения доступа, поскольку суперкомпьютер будет выполнять как секретные, так и не особенно секретные задачи. 
Фото: Australian Army / SGT Tristan Kennedy Taingiwilta расположен на территории специально построенного объекта Mukarntu. Министерство обороны Австралии впервые анонсировало систему в августе 2022 года, но и тогда представители местных властей отказались раскрывать детали проекта. При этом они заявляли, что Taingiwilta входит в 50 наиболее производительных вычислительных систем мира, поэтому можно предположить, что речь идёт о как минимум 10 Пфлопс — если ориентироваться на актуальный рейтинг TOP500. Профессор Ченнупати Джагадиш (Chennupati Jagadish), президент Австралийской академии наук, говорит, что отсутствие внятной HPC-стратегии ставит под вопрос процветание и безопасность Австралии. В документе «Будущие вычислительные потребности австралийского научного сектора» подчёркивается, что сейчас страна имеет умеренные возможности для высокопроизводительных вычислений, а уже имеющиеся мощности требуют частых и значительных обновлений и имеют ограниченный жизненный цикл.
22.02.2024 [13:34], Сергей Карасёв
HBM мало не бывает: суперкомпьютер OSC Cardinal получил чипы Intel Xeon Max и ускорители NVIDIA H100Суперкомпьютерный центр Огайо (OSC) анонсировал проект Cardinal по созданию нового кластера для задач HPC и ИИ. Гетерогенная система, построенная на серверах Dell PowerEdge с процессорами Intel, будет введена в эксплуатацию во II половине 2024 года. В состав кластера войдут узлы, оборудованные процессорами Xeon Max 9470 семейства Sapphire Rapids. Эти чипы содержат 52 ядра (104 потока) с максимальной тактовой частотой 3,5 ГГц и 128 Гбайт памяти HBM2e. В общей сложности будут задействованы 756 таких процессоров. Каждый узел получит 512 Гбайт DDR5 и NVMe SSD вместимостью 400 Гбайт. Узлы входят в состав серверов Dell PowerEdge C6620. Компанию им составят 16 узлов Dell PowerEdge R660, тоже с двумя Xeon Max 9470, но с 2 Тбайт DDR5 и 12,8 Тбайт NVMe SSD. Все эти узлы объединит 200G-интерконнект Infiniband. Кроме того, будут задействован 32 узла Dell PowerEdge XE9640 с двумя чипами Xeon 8470 Platinum (52C/104T; до 3,8 ГГц), четырьмя ускорителями NVIDIA H100 с 96 Гбайт памяти HBM3 и 1 Тбайт DDR5. Говорится о применении четырёх соединений NVLink и 400G-платформы Quantum-2 InfiniBand. Заявленная пиковая ИИ-производительность (FP8) — около 500 Пфлопс. 
Фото: Ohio Supercomputer Center via The Next Platform Суперкомпьютер обеспечит общую FP64-производительность на уровне 10,5 Пфлопс. Таким образом, по быстродействию кластер приблизительно на 40 % превзойдёт три нынешние машины OSC вместе взятые. При этом Cardinal занимает всего девять стоек и требует пару CDU для работы СЖО. Отмечается, что Cardinal — это результат сотрудничества OSC, Dell Technologies, Intel и NVIDIA. Новый суперкомпьютер придёт на смену системе Owens, которая используется в OSC с 2016 года.
21.02.2024 [21:18], Руслан Авдеев
Итальянские военные захотели создать группировку спутников-суперкомпьютеровМинистерство обороны Италии изучает возможность формирования «военно-космического облака» и поручила поддерживаемому государством подрядчику Leonardo проверить концепцию. По данным The Register, проект Military Space Cloud Architecture (MILSCA) предполагает формирование архитектуры, обеспечивающей правительство и вооружённые силы высокопроизводительными вычислениями и хранилищами данных в космосе. План предусматривает создание группировки спутников, каждый с FP32-производительностью 250 Тфлопс и хранилищем ёмкостью не менее 100 Тбайт данных. Ещё 100 Тбайт будет зарезервировано на Земле. Все ресурсы будут связаны друг с другом для поддержки выполнения задач, касающихся ИИ и анализа данных. Фактически речь идёт о гигантском, разнесённом в пространстве суперкомпьютерном кластере. Для сравнения — в состав кластера HPE Spaceborne-2 на МКС входит ускоритель NVIDIA T4 с FP32-производительностью 8 Тфлопс. 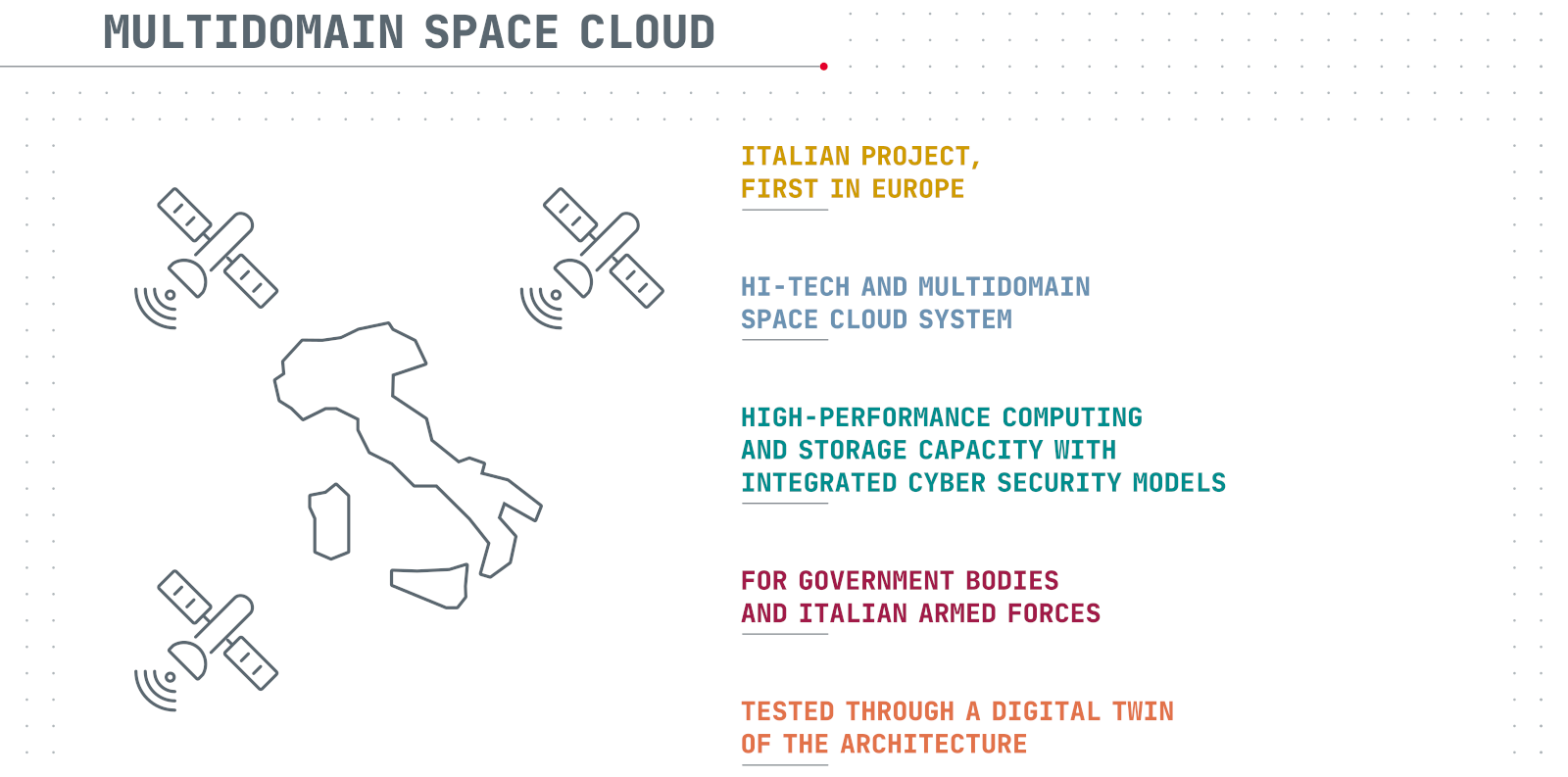
Источник изображения: Leonardo В Leonardo обещают быструю обработку данных на орбите и утверждают, что коммуникации будут менее уязвимы, чем наземные. Пользователи получат гарантированный доступ к телеком-услугам, данным наблюдения за Землёй, а также навигационным сведениям в любое время в любой части планеты. Кроме того, группировка послужит важным «бэкапом» для наземных центров, если с теми что-то случится. Leonardo и её совместные предприятия Telespazio и Thales Alenia Space изучат в ближайшие пару лет целесообразность создания такой группировки. В ходе первой фазы исследований участники проекта определятся с архитектурой всей системы, а в ходе второй попытаются провести симуляцию группировки с помощью «цифрового двойника» на суперкомпьютере Davinci-1. Она поможет заранее выявить потенциальные проблемы и оценить зоны покрытия. 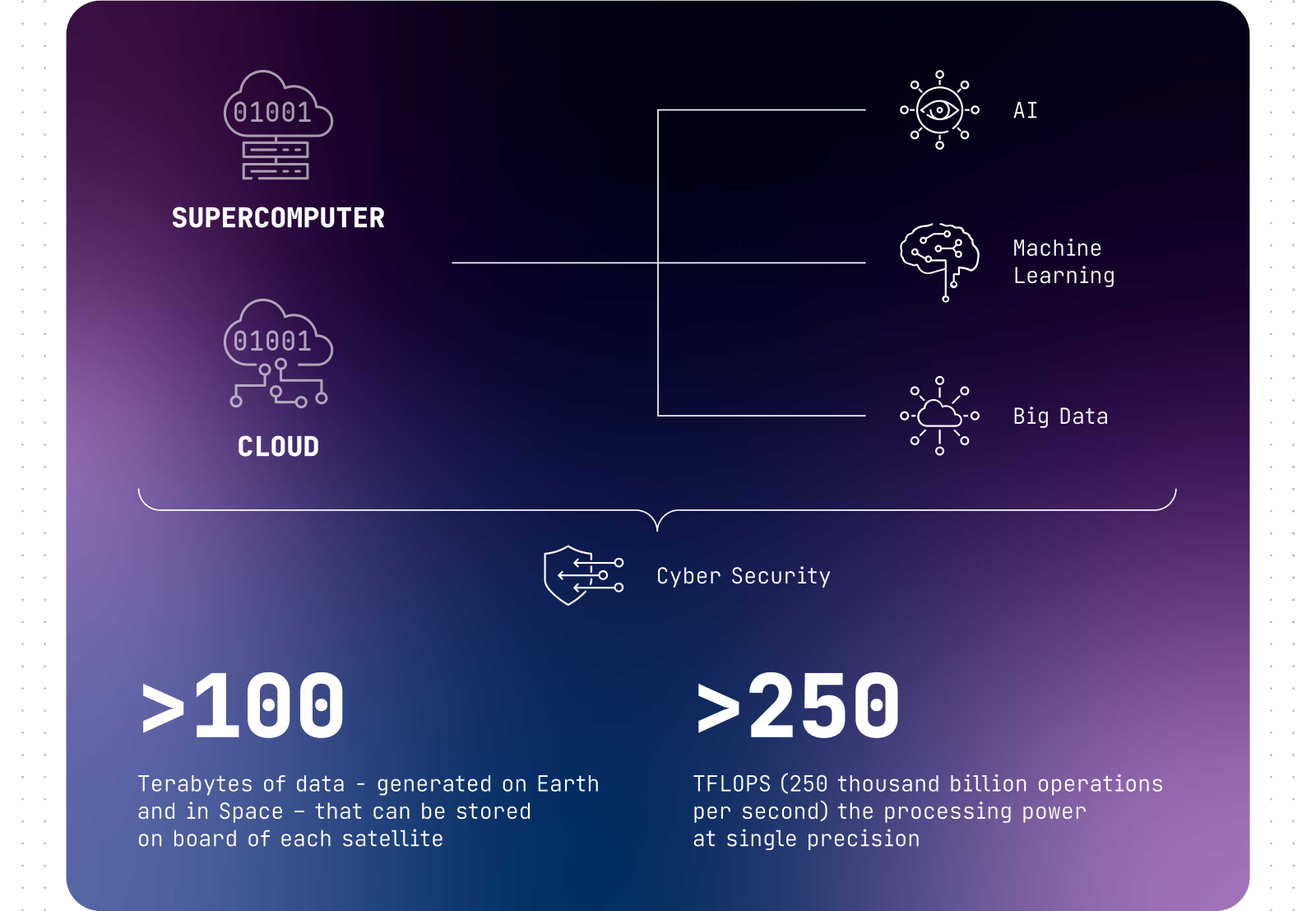
Источник изображения: Leonardo Оборудование потребует специальной защиты от космической радиации. Также предстоит решить вопросы энергоснабжения и терморегулирования. Кроме того, придётся по возможности минимизировать массу оборудования, доставляемого в космос. Дело осложняется тем, что для получения заданных характеристик придётся использовать достаточно горячие чипы, выполненные по тонким техпроцессам. Leonardo не впервые просят оценить перспективы космических вычислений. В 2022 году совместное предприятие Thales Alenia Space, созданное Leonardo и французской Thales, наняли для оценки перспектив космических ЦОД в рамках исследовательской программы Horizon Europe. Правда, на тот момент речь шла об экопроекте, а не группировке военного назначения. Недавно компания Axiom Space также заявила, что построит и выведет на орбиту ЦОД для поддержки миссий своей коммерческой космической станции. Компания намеревалась снизить зависимость от наземных сервисов. Blue Ring тоже планирует предоставлять вычисления в космосе. Наконец, Lonestar Data Holdings привлекает средства для постройки ЦОД на Луне.
20.02.2024 [23:25], Сергей Карасёв
Поменьше и побольше: у NVIDIA оказалось сразу два ИИ-суперкомпьютера EOSНа днях NVIDIA снова официально представила суперкомпьютер EOS для решения ресурсоёмких задач в области ИИ. Издание The Register обратило внимание на нестыковки в публичных заявлениях компании относительно конфигурации и производительности машины. В итоге NVIDIA признала, что у неё есть две архитектурно похожих системы под одним и тем же именем. Впрочем, полной ясности это не внесло. НРС-комплекс EOS изначально был анонсирован почти два года назад — в марте 2022-го. Тогда речь шла о кластере, объединяющем 576 систем NVIDIA DGX H100, каждая из которых содержит восемь ускорителей H100 — в сумме 4608 шт. Суперкомпьютер, согласно заявлениям NVIDIA, обеспечивает ИИ-быстродействие на уровне 18,4 Эфлопс (FP8), тогда как производительность на операциях FP16 составляет 9 Эфлопс, а FP64 — 275 Пфлопс.  Вместе с тем в ноябре 2023 года NVIDIA объявила о том, что ИИ-суперкомпьютер EOS поставил ряд рекордов в бенчмарках MLPerf Training. Тогда говорилось, что комплекс содержит 10 752 ускорителя H100, а его FP8-производительность достигает 42,6 Эфлопс. Представители компании сообщили, что суперкомпьютер, использованный для MLPerf Training с 10 752 ускорителями H100, «представляет собой другую родственную систему, построенную на той же архитектуре DGX SuperPOD». Вместе с тем комплекс, занявший 9-е место в TOP500 от ноября 2023 года — это как раз версия EOS с 4608 ускорителями, представленная на днях в рамках официального анонса. Но... цифры всё не сходятся! В TOP500 FP64-производительность EOS составляет 121,4 Пфлопс при пиковом значении 188,7 Пфлопс. Сама NVIDIA, как уже было отмечено выше, называет цифру в 275 Пфлопс. Таким образом, суперкомпьютер, участвующий в рейтинге TOP500, мог содержать от 2816 до 3161 ускорителя H100 из 4608 заявленных. С чем связано такое несоответствие, не совсем ясно. Высказываются предположения, что у NVIDIA могли возникнуть сложности с обеспечением стабильности кластера на момент составления списка TOP500, поэтому система была включена в него в урезанной конфигурации.
13.02.2024 [18:03], Владимир Мироненко
В Казахстане построят суперкомпьютер при участии компании Presight AI из ОАЭМинистерство цифрового развития, инновации и аэрокосмической промышленности Республики Казахстан (МЦРИАП РК), АО «Фонд национального благосостояния «Самрук-Қазына» и компания Presight AI Ltd. из ОАЭ подписали соглашение о создании суперкомпьютера в Казахстане и строительства ЦОД для его размещения, сообщается на сайте МЦРИАП РК. Проект будет выполнен в два этапа. В ходе первого этапа будут установлены вычислительные мощности в существующем ЦОД АО «НИТ» (оператор ИКТ электронного правительства), а на втором этапе будет построен новый ЦОД со значительными вычислительными мощностями. 
Источник изображения: МЦРИАП РК Как сообщается в пресс-релизе, со стороны рынка, высших учебных заведений, научного сообщества и государственных органов имеется потребность в создании технологической инфраструктуры (суперкомпьютер) для успешного развития инструментов ИИ. В стране появился ряд стартапов и зрелых компаний, занимающихся внедрением ИИ, такие как Cerebra, ForUS.Data, GoatChat.AI, Higgsfield AI, AI Labs, Sergek Group и др. Также отмечено, что запуск технологической HPC-инфраструктуры определит лидерство Казахстана в Центральной Азии в сфере развития ИИ, который предоставит возможность аренды вычислительных мощностей для сопредельных стран. Ранее МЦРИАП РК сообщило о расширении сотрудничества с Объединёнными Арабскими Эмиратами (ОАЭ) с целью реализации проектов в области дата-центров и ИИ.
12.02.2024 [08:54], Сергей Карасёв
EuroHPC развернёт в Европе специализированные индустриальные суперкомпьютерыЕвропейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) объявило о начале приёма заявок от заинтересованных площадок для размещения специализированных суперкомпьютеров промышленного уровня. Речь идёт о вычислительных комплексах не ниже среднего класса, специально разработанных с учётом норм безопасности, конфиденциальности и целостности данных в индустриальном сегменте. К таким системам обычно предъявляются более высокие требования, нежели к суперкомпьютерам для решения научных задач. 
Суперкомпьютер Leonardo. Источник изображения: EuroHPC JU / Cineca EuroHPC JU планирует закупить новые вычислительные комплексы совместно с консорциумом частных партнёров. С выбранными площадками будут заключены соглашения о размещении и эксплуатации оборудования. EuroHPC JU приобретёт как минимум один промышленный суперкомпьютер в 2024 году. Подробности о проекте не раскрываются, но известно, что общий вклад ЕС в его реализацию составит €12,2 млн. Новые промышленные суперкомпьютеры будут совместно финансироваться из бюджета EuroHPC JU, полученного в рамках Программы «Цифровая Европа» (DEP), а также за счёт взносов государств-участников организации. При этом EuroHPC JU покроет до 35 % затрат на приобретение вычислительных комплексов. Развёртывание этих систем поможет удовлетворить растущий спрос на вычислительные ресурсы со стороны индустриальных заказчиков. В целом, инициатива должна способствовать «повышению инновационного потенциала предприятий в Европе».
05.02.2024 [16:21], Сергей Карасёв
Cadence представила суперкомпьютер Millennium M1 для вычислительной гидродинамики с ИИКомпания Cadence анонсировала систему Millennium Enterprise Multiphysics Platform: это, как утверждается, первое в отрасли программно-аппаратное решение для проектирования и анализа мультифизических систем. Суперкомпьютер, получивший название Cadence Millennium M1 CFD, ориентирован на решение задач в области вычислительной гидродинамики (CFD). Отмечается, что CFD используется для сокращения длительных циклов проектирования и уменьшения количества дорогостоящих экспериментов. Такие решения востребованы в аэрокосмической, оборонной, автомобильной, электронной и других отраслях. 
Источник изображения: Cadence Суперкомпьютер Millennium M1 использует узлы с традиционными CPU, дополненные ускорителями на базе GPU — до 32 ускорителей на стойку и с возможностью масштабирования до 5 тыс. GPU на кластер и более. Задействован высокоскоростной интерконнект. При этом Cadence пока не раскрывает точные характеристики системы, но говорит, что она в 20 раз энергоэффективнее традиционных CPU-кластеров. Кроме того, машина позволяет создавать цифровых двойников с функцией визуализации. 
Источник изображения: Cadence Отмечается, что ключевой особенностью Millennium M1 является специализированное ПО. Оно может использоваться для решения задач моделирования турбулентных течений — Large Eddy Simulation (LES). Быстрое генерирование высококачественных синтетических данных позволяет ИИ-алгоритмам находить оптимальные решения без ущерба для точности. В целом, как утверждается, суперкомпьютер Millennium M1 расширяет возможности LES в аэрокосмической, автомобильной, энергетической и других отраслях благодаря сокращению времени выполнения расчётов с дней до часов. Система доступна в двух вариантах — облачном (минимум 8 ускорителей) и локальном (минимум 32 ускорителя). В первом случае машина размещается на платформе Cadence и масштабируется по мере необходимости. Во втором случае система размещается локально в IT-инфраструктуре заказчика.
02.02.2024 [13:29], Сергей Карасёв
Lenovo построит в Германии энергоэффективный суперкомпьютер на базе AMD EPYC Genoa и NVIDIA H100
amd
epyc
genoa
h100
hardware
hpc
lenovo
nvidia
германия
отопление
суперкомпьютер
энергоэффективность
Компания Lenovo объявила о заключении контракта с Падерборнским университетом в Германии (University of Paderborn) на создание нового НРС-комплекса, мощности которого будут использоваться для обеспечения исследований в рамках Национальной программы высокопроизводительных вычислений (NHR). В основу суперкомпьютера лягут двухузловые серверы ThinkSystem SD665 V3. Конфигурация каждого узла включает два процессора AMD EPYC Genoa и до 24 модулей оперативной памяти DDR5-4800. Применена технология прямого жидкостного охлаждения Lenovo Neptune Direct Water Cooling (DWC). Кроме того, НРС-комплекс будет использовать GPU-серверы ThinkSystem SD665-N V3, несущие на борту четыре ускорителя NVIDIA H100, связанные между собой посредством NVLink. Общее количество ядер составит более 136 тыс. Для подсистемы хранения выбрана платформа IBM ESS 3500, обеспечивающая возможности гибкого использования SSD (NVMe) и HDD. Новый суперкомпьютер расположится в Падерборнском центре параллельных вычислений (PC2). Монтаж оборудования планируется произвести во II половине текущего года. За интеграцию будет отвечать pro-com DATENSYSTEME GmbH. Ожидается, что по сравнению с нынешней системой центра Noctua 2 (на изображении), построенной Atos, готовящийся суперкомпьютер будет обладать примерно вдвое более высокой производительностью. Быстродействие Noctua 2 составляет до 4,19 Пфлопс (Linpack) для CPU-ядер и до 1,7 Пфлопс (Linpack) для GPU-блоков. 
Источник изображения: University of Paderborn Особое внимание при строительстве суперкомпьютера будет уделяться энергетической эффективности. Благодаря использованию источников питания с жидкостным охлаждением и полностью изолированных стоек более 97 % вырабатываемого тепла может быть передано непосредственно в систему циркуляции тёплой воды. Применение теплообменников и блоков распределения охлаждающей жидкости (CDU) обеспечивает температуру носителя в обратном контуре выше 45 °C, что позволяет повторно использовать генерируемое тепло. |
|