Материалы по тегу: компьютер
|
23.05.2023 [15:26], Сергей Карасёв
Intel рассказала о суперкомпьютере Aurora производительностью более 2 ЭфлопсКорпорация Intel в ходе конференции ISC 2023, как сообщает AnandTech, поделилась информацией о проекте Aurora по созданию суперкомпьютера с производительностью экзафлопсного уровня. Эта система создаётся для Аргоннской национальной лаборатории Министерства энергетики США. Изначально анонс HPC-комплекса Aurora состоялся ещё в 2015 году с предполагаемым запуском в 2018-м: ожидалось, что машина обеспечит быстродействие на уровне 180 Пфлопс. Однако реализация проекта значительно затянулась, а технические параметры платформы неоднократно менялись. Пока что развёрнуты тестовый кластер Sunspot. Как теперь сообщается, в конечной конфигурации Aurora объединит 10 624 узла, каждый из которых будет включать два процессора Xeon Max и шесть ускорителей Ponte Vecchio. Таким образом, общее количество CPU будет достигать 21 248, число GPU — 63 744. Быстродействие FP64, как и было заявлено ранее, превысит 2 Эфлопс. 
Источник изображений: Intel (via AnandTech) Каждый процессор оперирует 64 Гбайт памяти HBM, ускоритель — 128 Гбайт. В сумме это даёт соответственно 1,36 Пбайт и 8,16 Пбайт памяти HBM с пиковой пропускной способностью 30,5 Пбайт/с и 208,9 Пбайт/с. В дополнение система сможет использовать 10,9 Пбайт памяти DDR5 с пропускной способностью до 5,95 Пбайт/с. Вместимость подсистемы хранения данных составит 230 Пбайт со скоростью работы до 31 Тбайт/с.  На сегодняшний день Intel поставила более 10 тыс. «лезвий» для Aurora, а это означает, что практически все узлы готовы к окончательному монтажу. Ввод суперкомпьютера в эксплуатацию намечен на текущий год. Для НРС-платформы готовится специализированная научная модель генеративного ИИ — Generative AI for Science, насчитывающая около 1 трлн параметров. Применять Aurora планируется для решения наиболее ресурсоёмких задач в различных областях.
07.04.2023 [20:36], Сергей Карасёв
Google заявила, что её ИИ-кластеры на базе TPU v4 и оптических коммутаторов эффективнее кластеров на базе NVIDIA A100 и InfiniBandКомпания Google обнародовала новую информацию о своей облачной суперкомпьютерной платформе Cloud TPU v4, предназначенной для решения задач ИИ и машинного обучения с высокой эффективностью. Система может использоваться в том числе для работы с крупномасштабными языковыми моделями (LLM). Один кластер Cloud TPU Pod содержит 4096 чипов TPUv4, соединённых между собой через оптические коммутаторы (OCS). По словам Google, решение OCS быстрее, дешевле и потребляют меньше энергии по сравнению с InfiniBand. Google также утверждает, что в составе её платформы на OCS приходится менее 5 % от общей стоимости. Причём данная технология даёт возможность динамически менять топологию для улучшения масштабируемости, доступности, безопасности и производительности. Отмечается, что платформа Cloud TPU v4 в 1,2–1,7 раза производительнее и расходует в 1,3–1,9 раза меньше энергии, чем платформы на базе NVIDIA A100 в системах аналогичного размера. Правда, пока компания не сравнивала TPU v4 с более новыми ускорителями NVIDIA H100 из-за их ограниченной доступности и 4-нм архитектуры (по сравнению с 7-нм у TPU v4). 
Изображение: Google Благодаря ключевым инновациям в области интерконнекта и специализированных ускорителей (DSA, Domain Specific Accelerator) платформа Google Cloud TPU v4 обеспечивает почти 10-кратный прирост в масштабировании производительности по сравнению с TPU v3. Это также позволяет повысить энергоэффективность примерно в 2–3 раза по сравнению с современными DSA ML и сократить углеродный след примерно в 20 раз по сравнению с обычными дата-центрами.
21.03.2023 [19:15], Сергей Карасёв
NVIDIA представила систему DGX Quantum для гибридных квантово-классических вычисленийКомпания NVIDIA в партнёрстве с Quantum Machines анонсировала DGX Quantum — первую систему, объединяющую GPU и квантовые вычисления. Решение использует новую открытую программную платформу CUDA Quantum. Утверждается, что система предоставляет революционно архитектуру для исследователей, работающими с гибридными вычислениями с низкой задержкой. NVIDIA DGX Quantum объединяет средства ускоренных вычислений на базе Grace Hopper (Arm-процессор + ускоритель H100), модели программирования с открытым исходным кодом CUDA Quantum и передовую квантовую управляющую платформу Quantum Machines OPX+. Такая комбинация позволяет создавать ресурсоёмкие приложения, сочетающие квантовые вычисления с современными классическими вычислениями. При этом в числе прочего обеспечивается работа гибридных алгоритмов и коррекция ошибок. 
Источник изображения: NVIDIA Представленное решение предполагает соединение Grace Hopper и Quantum Machines OPX+ посредством интерфейса PCIe. Это обеспечивает задержку менее микросекунды между ускорителем и блоками квантовой обработки (QPU). Отмечается, что OPX+ — это универсальная система квантового управления. Таким образом, можно максимизировать производительность QPU и предоставить разработчикам новые возможности при использовании квантовых алгоритмов. Системы Grace Hopper и OPX+ можно масштабировать в соответствии с потребностями — от QPU с несколькими кубитами до суперкомпьютера с квантовым ускорением. 
Источник изображения: NVIDIA О намерении интегрировать CUDA Quantum в свои платформы уже заявили компании по производству квантового оборудования Anyon Systems, Atom Computing, IonQ, ORCA Computing, Oxford Quantum Circuits и QuEra, разработчики ПО Agnostiq и QMware, а также некоторые суперкомпьютерные центры.
29.11.2022 [12:20], Сергей Карасёв
В Италии официально запущен суперкомпьютер Leonardo — четвёртая по мощности HPC-система в миреСовместная инициатива по высокопроизводительным вычислениям в Европе EuroHPC JU и некоммерческий консорциум CINECA, состоящий из 69 итальянских университетов и 21 национальных исследовательских центров, провели церемонию запуска суперкомпьютера Leonardo. В основу комплекса положены платформы Atos BullSequana X2610 и X2135. Система Leonardo состоит из двух секций — общего назначения и с ускорителями вычислений (Booster). Когда строительство системы будет завершено, первая будет включать 1536 узлов, каждый из которых содержит два процессора Intel Xeon Sapphire Rapids с 56 ядрами и TDP в 350 Вт, 512 Гбайт оперативной памяти DDR5-4800, интерконнект NVIDIA InfiniBand HDR100 и NVMe-накопитель на 8 Тбайт. 
Источник изображения: HPCwire Секция Booster объединяет 3456 узлов, каждый из которых содержит один чип Intel Xeon 8358 с 32 ядрами, 512 Гбайт ОЗУ стандарта DDR4-3200, четыре кастомных ускорителя NVIDIA A100 с 64 Гбайт HBM2-памяти, а также два адаптера NVIDIA InfiniBand HDR100. Кроме того, в состав комплекса входят 18 узлов для визуализации: 6,4 Тбайт NVMe SSD и два ускорителя NVIDIA RTX 8000 (48 Гбайт) в каждом. Вычислительный комплекс объединён фабрикой с топологией Dragonfly+. 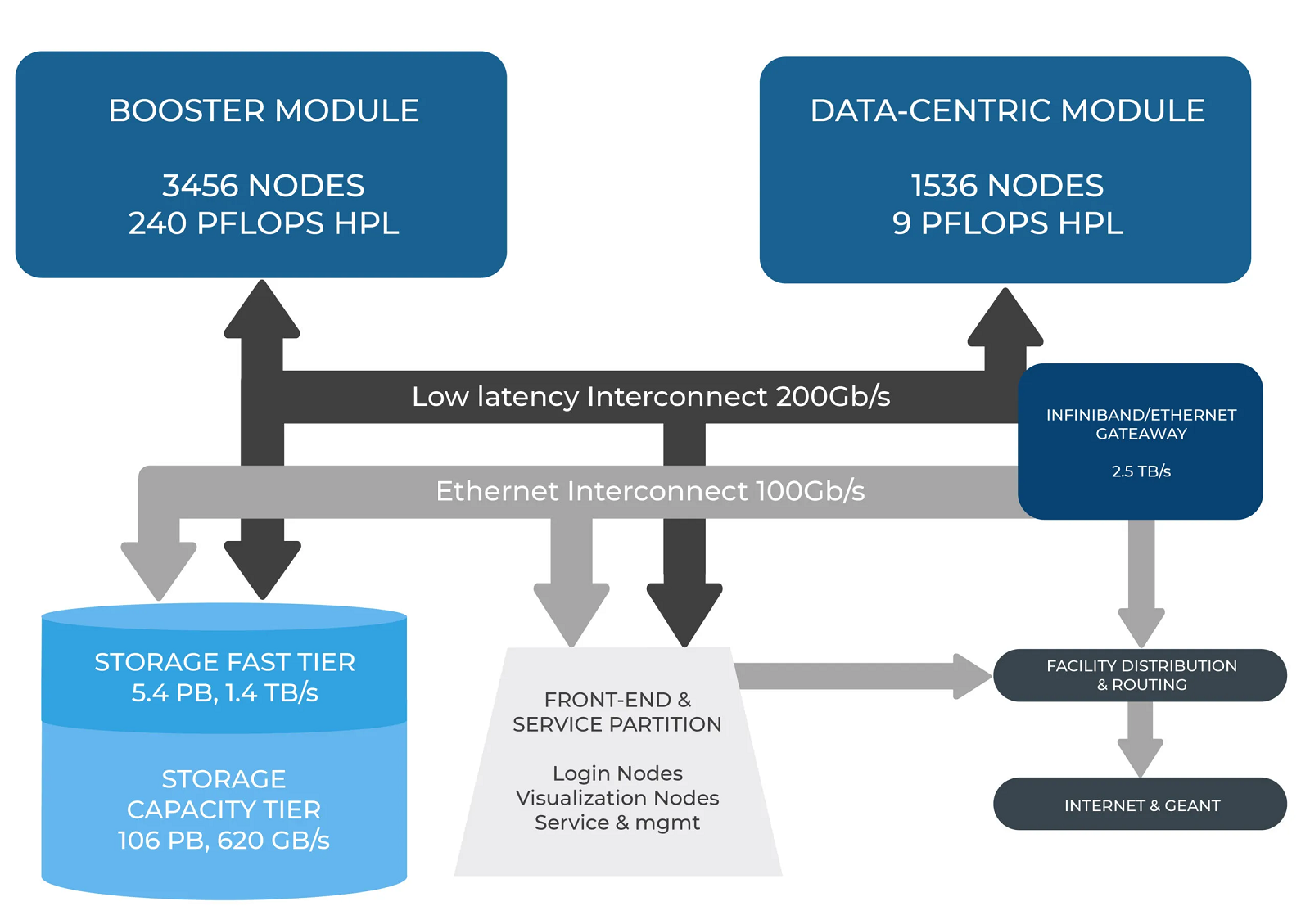
Источник: CINECA Для хранения данных служит двухуровневая система. Производительный блок (5,4 Пбайт, 1400 Гбайт/с) содержит 31 модуль DDN Exascaler ES400NVX2, каждый из которых укомплектован 24 NVMe SSD вместимостью 7,68 Тбайт и четырьмя адаптерами InfiniBand HDR. Второй уровень большой ёмкости (106 Пбайт, чтение/запись 744/620 Гбайт/с) состоит из 31 массива DDN EXAScaler SFA799X с 82 SAS HDD (7200 PRM) на 18 Тбайт и четырьмя адаптерами InfiniBand HDR. Каждый из массивов включает два JBOD-модуля с 82 дисками на 18 Тбайт. Для хранения метаданных используются 4 модуля DDN EXAScaler SFA400NVX: 24 × 7,68 Тбайт NVMe + 4 × InfiniBand HDR. 
Изображение: CINECA В настоящее время Leonardo обеспечивает производительность более 174 Пфлопс. Ожидается, что суперкомпьютер будет полностью запущен в первой половине 2023 года, а его пиковое быстродействие составит 250 Пфлопс. Уже сейчас система занимает четвёртое место в последнем рейтинге самых мощных суперкомпьютеров мира TOP500. В Европе Leonardo является второй по мощности системой после LUMI. Leonardo оборудован системой жидкостного охлаждения для повышения энергоэффективности. Кроме того, предусмотрена возможность регулировки энергопотребления для обеспечения баланса между расходом электричества и производительностью. Суперкомпьютер ориентирован на решение высокоинтенсивных вычислительных задач, таких как обработка данных, ИИ и машинное обучение. Половина вычислительных ресурсов Leonardo будет предоставлена пользователям EuroHPC.
10.11.2022 [17:15], Владимир Мироненко
HPE анонсировала недорогие, энергоэффективные и компактные суперкомпьютеры Cray EX2500 и Cray XD2000/6500Hewlett Packard Enterprise анонсировала суперкомпьютеры HPE Cray EX и HPE Cray XD, которые отличаются более доступной ценой, меньшей занимаемой площадью и большей энергоэффективностью по сравнению с прошлыми решениями компании. Новинки используют современные технологии в области вычислений, интерконнекта, хранилищ, питания и охлаждения, а также ПО. 
Изображение: HPE Суперкомпьютеры HPE обеспечивают высокую производительность и масштабируемость для выполнения ресурсоёмких рабочих нагрузок с интенсивным использованием данных, в том числе задач ИИ и машинного обучения. Новинки, по словам компании, позволят ускорить вывода продуктов и сервисов на рынок. Решения HPE Cray EX уже используются в качестве основы для больших машин, включая экзафлопсные системы, но теперь компания предоставляет возможность более широкому кругу организаций задействовать супервычисления для удовлетворения их потребностей в соответствии с возможностями их ЦОД и бюджетом. В семейство HPE Cray вошли следующие системы:
Все три системы задействуют те же технологии, что и их старшие собратья: интерконнект HPE Slingshot, хранилище Cray Clusterstor E1000 и пакет ПО HPE Cray Programming Environment и т.д. Система HPE Cray EX2500 поддерживает процессоры AMD EPYC Genoa и Intel Xeon Sapphire Rapids, а также ускорители AMD Instinct MI250X. Модель HPE Cray XD6500 поддерживает чипы Sapphire Rapids и ускорители NVIDIA H100, а для XD2000 заявлена поддержка AMD Instinct MI210. 
Изображение: Intel В качестве примеров выгод от использования анонсированных суперкомпьютеров в разных отраслях компания назвала:
05.09.2022 [23:00], Алексей Степин
Tesla рассказала подробности о чипах D1 собственной разработки, которые станут основой 20-Эфлопс ИИ-суперкомпьютера DojoКомпания Tesla уже анонсировала собственный, созданный в лабораториях компании процессор D1, который станет основой ИИ-суперкомпьютера Dojo. Нужна такая система, чтобы создать для ИИ-водителя виртуальный полигон, в деталях воссоздающий реальные ситуации на дорогах. Естественно, такой симулятор требует огромных вычислительных мощностей: в нашем мире дорожная обстановка очень сложна, изменчива и включает множество факторов и переменных. До недавнего времени о Dojo и D1 было известно не так много, но на конференции Hot Chips 34 было раскрыто много интересного об архитектуре, устройстве и возможностях данного решения Tesla. Презентацию провел Эмиль Талпес (Emil Talpes), ранее 17 лет проработавший в AMD над проектированием серверных процессоров. Он, как и ряд других видных разработчиков, работает сейчас в Tesla над созданием и совершенствованием аппаратного обеспечения компании. 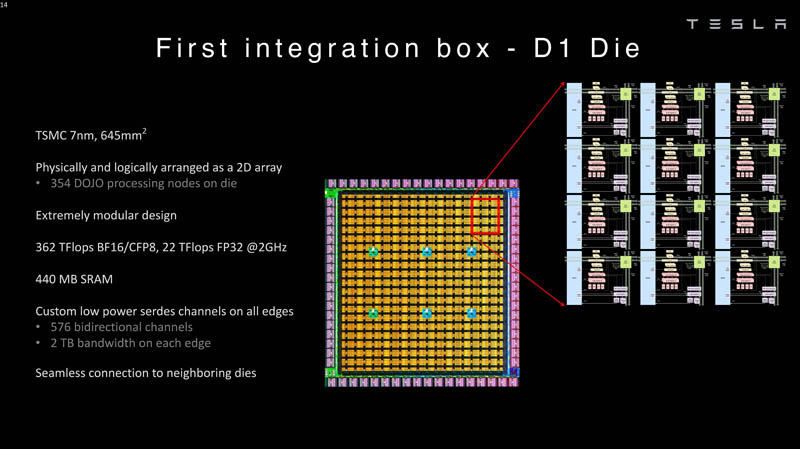
Изображения: Tesla (via ServeTheHome) Главной идеей D1 стала масштабируемость, поэтому в начале разработки нового чипа создатели активно пересмотрели роль таких традиционных концепций, как когерентность, виртуальная память и т.д. — далеко не все механизмы масштабируются лучшим образом, когда речь идёт о построении действительно большой вычислительной системы. Вместо этого предпочтение было отдано распределённой сети хранения на базе SRAM, для которой был создан интерконнект, на порядок опережающий существующие реализации в системах распределённых вычислений. 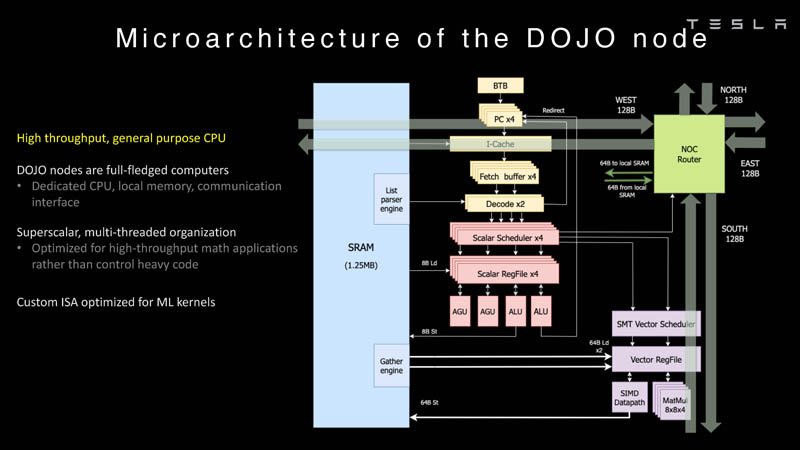 Основой процессора Tesla стало ядро целочисленных вычислений, базирующееся на некоторых инструкциях из набора RISC-V, но дополненное большим количеством фирменных инструкций, оптимизированных с учётом требований, предъявляемых ядрами машинного обучения, используемыми компанией. Блок векторной математики был создан практически с нуля, по словам разработчиков. 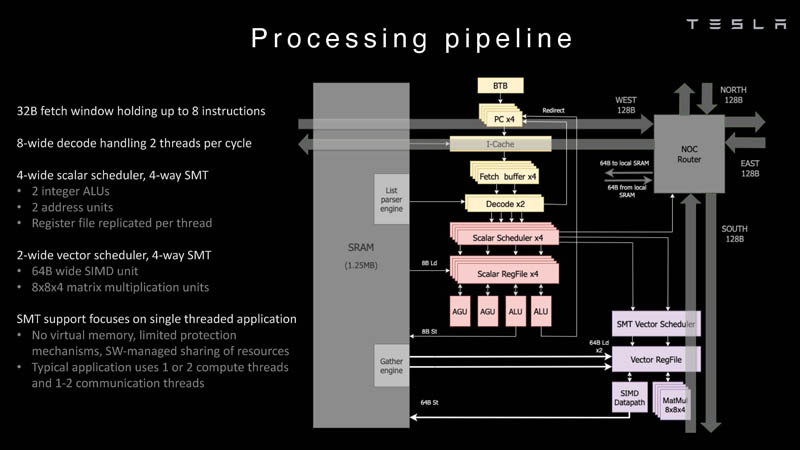 Набор инструкций Dojo включает в себя скалярные, матричные и SIMD-инструкции, а также специфические примитивы для перемещения данных из локальной памяти в удалённую, равно как и семафоры с барьерами — последние требуются для согласования работы c памятью во всей системе. Что касается специфических инструкций для машинного обучения, то они реализованы в Dojo аппаратно. 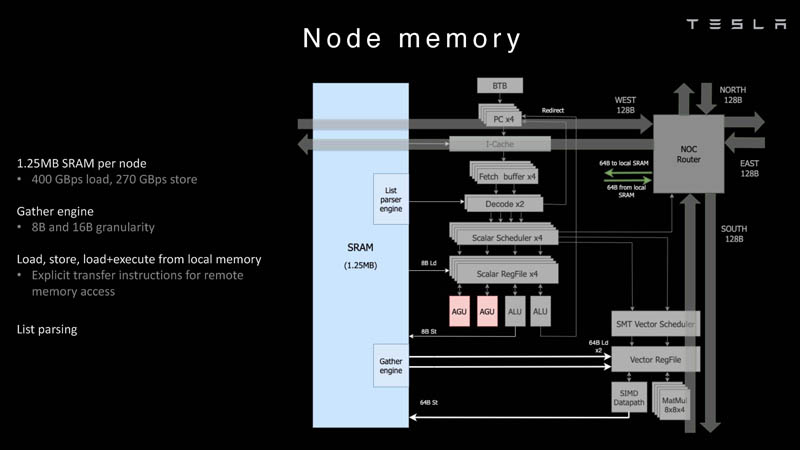 Первенец в серии, чип D1, не является ускорителем как таковым — компания считает его высокопроизводительным процессором общего назначения, не нуждающимся в специфических ускорителях. Каждый вычислительный блок Dojo представлен одним ядром D1 с локальной памятью и интерфейсами ввода/вывода. Это 64-бит ядро суперскалярно. 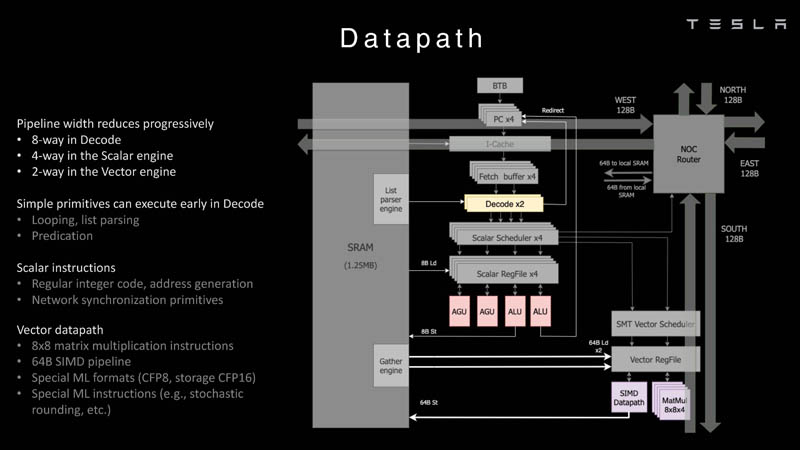 Более того, в ядре реализована поддержка многопоточности (SMT4), которая призвана увеличить производительность на такт (а не изолировать разные задачи друг от друга), поэтому виртуальную память данная реализация SMT не поддерживает, а механизмы защиты довольно ограничены в функциональности. За управление ресурсами Dojo отвечает специализированный программный стек и фирменное ПО. 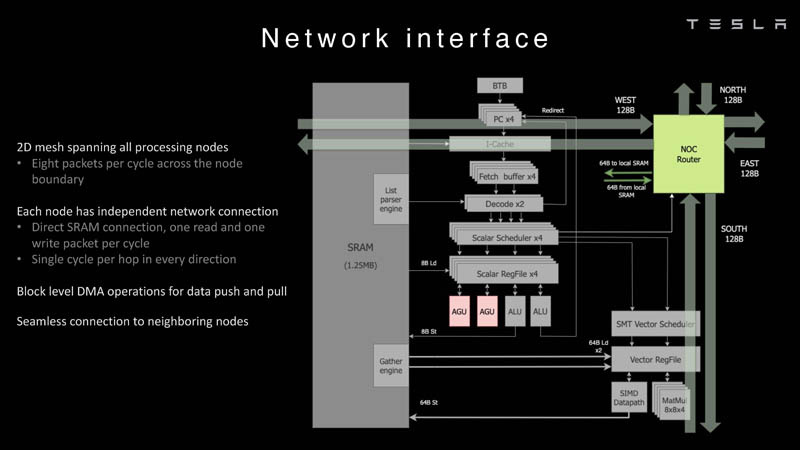 64-бит ядро имеет 32-байт окно выборки (fetch window), которое может содержать до 8 инструкций, что соответствует ширине декодера. Он, в свою очередь, может обрабатывать два потока за такт. Результат поступает в планировщики, которые отправляют его в блок целочисленных вычислений (два ALU) или в векторный блок (SIMD шириной 64 байт + перемножение матриц 8×8×4). 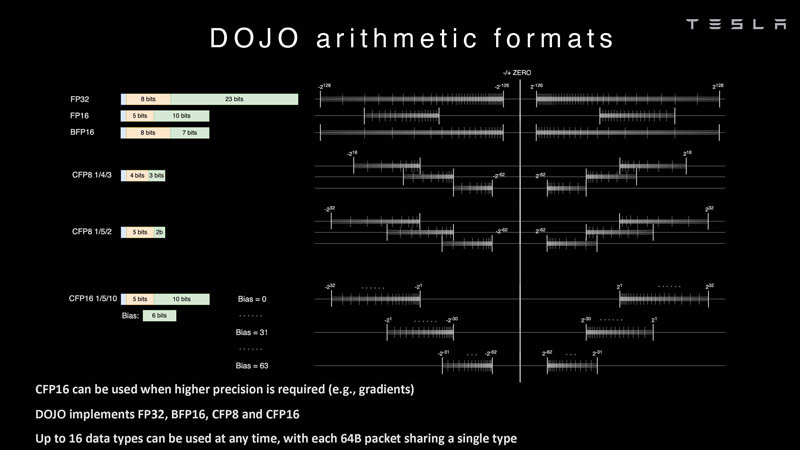 У каждого ядра D1 есть SRAM объёмом 1,25 Мбайт. Эта память — не кеш, но способна загружать данные на скорости 400 Гбайт/с и сохранять на скорости 270 Гбайт/с, причём, как уже было сказано, в чипе реализованы специальные инструкции, позволяющие работать с данными в других ядрах Dojo. Для этого в блоке SRAM есть свои механизмы, так что работа с удалённой памятью не требуют дополнительных операций.  Что касается поддерживаемых форматов данных, то скалярный блок поддерживает целочисленные форматы разрядностью от 8 до 64 бит, а векторный и матричный блоки — широкий набор форматов с плавающей запятой, в том числе для вычислений смешанной точности: FP32, BF16, CFP16 и CFP8. Разработчики D1 пришли к использованию целого набора конфигурируемых 8- и 16-бит представлений данных — компилятор Dojo может динамически изменять значения мантиссы и экспоненты, так что система может использовать до 16 различных векторных форматов, лишь бы в рамках одного 64-байт блока данных он не менялся.  Как уже упоминалось, топология D1 использует меш-структуру, в которой каждые 12 ядер объединены в логический блок. Чип D1 целиком представляет собой массив размером 18×20 ядер, однако доступны лишь 354 ядра из 360 присутствующих на кристалле. Сам кристалл площадью 645 мм2 производится на мощностях TSMC с использованием 7-нм техпроцесса. Тактовая частота составляет 2 ГГц, общий объём памяти SRAM — 440 Мбайт.  Процессор D1 развивает 362 Тфлопс в режиме BF16/CFP8, в режиме FP32 этот показатель снижается до 22 Тфлопс. Режим FP64 векторными блоками D1 не поддерживается, поэтому для многих традиционных HPC-нагрузок данный процессор не подойдёт. Но Tesla создавала D1 для внутреннего использования, поэтому совместимость её не очень волнует. Впрочем, в новых поколениях, D2 или D3, такая поддержка может появиться, если это будет отвечать целям компании. 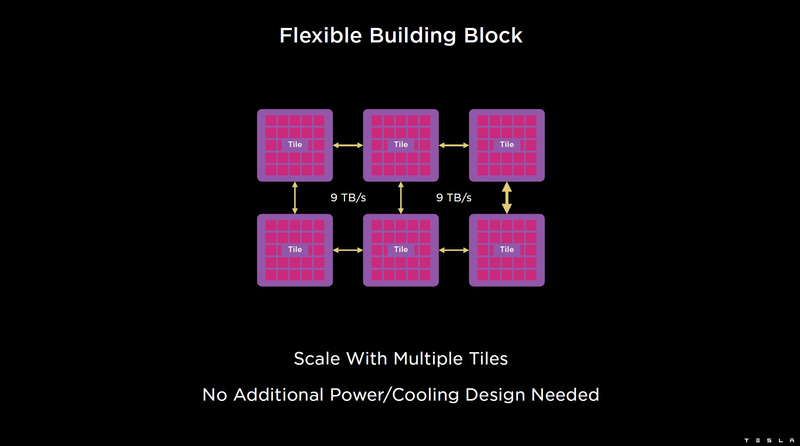 Каждый кристалл D1 имеет 576-битный внешний интерфейс SerDes с совокупной производительностью по всем четырём сторонам, составляющей 18 Тбайт/с, так что узким местом при соединении D1 он явно не станет. Этот интерфейс объединяет кристаллы в единую матрицу 5х5, такая матрица из 25 кристаллов D1 носит название Dojo training tile. 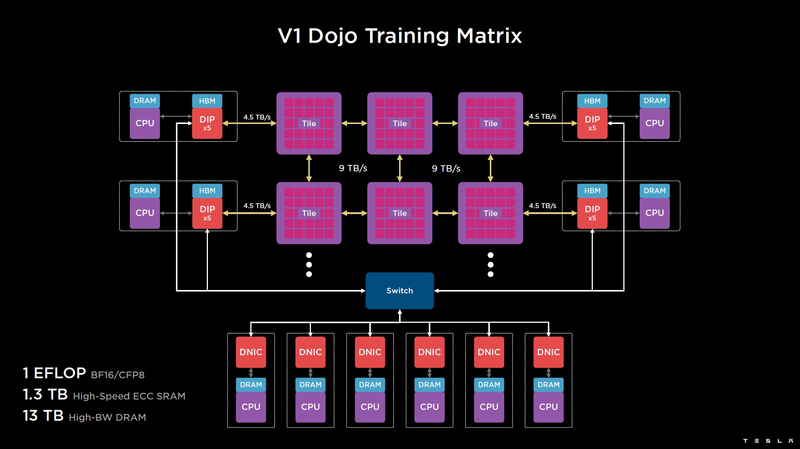 Этот тайл выполнен как законченный термоэлектромеханический модуль, имеющий внешний интерфейс с пропускной способностью 4,5 Тбайт/с на каждую сторону, совокупно располагающий 11 Гбайт памяти SRAM, а также собственную систему питания мощностью 15 кВт. Вычислительная мощность одного тайла Dojo составляет 9 Пфлопс в формате BF16/CFP8. При таком уровне энергопотребления охлаждение у Dojo может быть только жидкостное.  Тайлы могут объединяться в ещё более производительные матрицы, но как именно физически организован суперкомпьютер Tesla, не вполне ясно. Для связи с внешним миром используются блоки DIP — Dojo Interface Processors. Это интерфейсные процессоры, посредством которых тайлы общаются с хост-системами и на долю которых отведены управляющие функции, хранение массивов данных и т.п. Каждый DIP не просто выполняет IO-функции, но и содержит 32 Гбайт памяти HBM (не уточняется, HBM2e или HBM3). 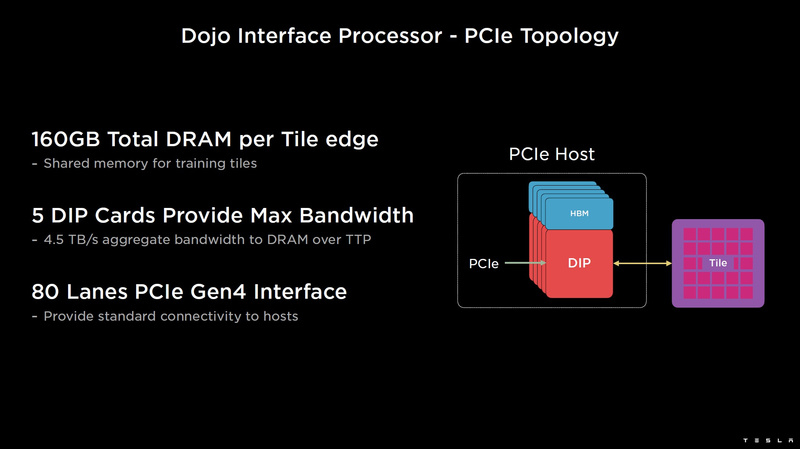 DIP использует полностью свой транспортный протокол (Tesla Transport Protocol, TTP), разработанный в Tesla и обеспечивающий пропускную способность 900 Гбайт/с, а поверх Ethernet — 50 Гбайт/с. Внешний интерфейс у карточек — PCI Express 4.0, и каждая интерфейсная карта несёт пару DIP. С каждой стороны каждого ряда тайлов установлено по 5 DIP, что даёт скорость до 4,5 Тбайт/с от HBM-стеков к тайлу.  В случаях, когда во всей системе обращение от тайла к тайлу требует слишком много переходов (до 30 в случае обращения от края до края), система может воспользоваться DIP, объединённых снаружи 400GbE-сетью по топологии fat tree, сократив таким образом, количество переходов до максимум четырёх. Пропускная способность в этом случае страдает, но выигрывает латентность, что в некоторых сценариях важнее. 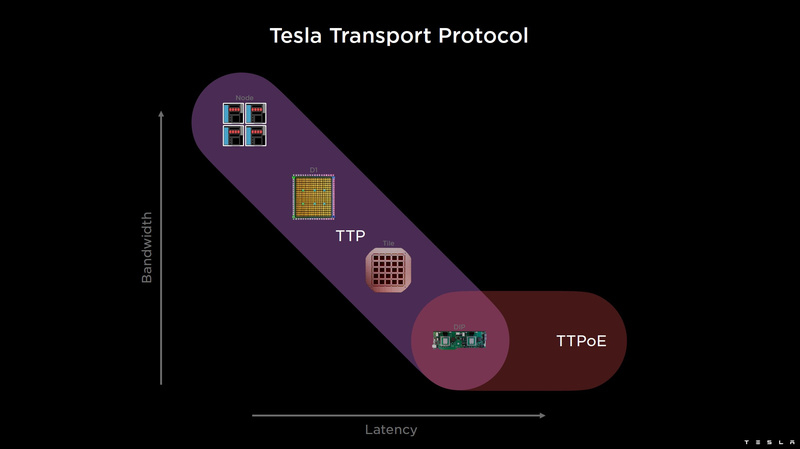 В базовой версии суперкомпьютер Dojo V1 выдаёт 1 Эфлопс в режиме BF16/CFP8 и может загружать непосредственно в SRAM модели объёмом до 1,3 Тбайт, ещё 13 Тбайт данных можно хранить в HBM-сборках DIP. Следует отметить, что пространство SRAM во всей системе Dojo использует единую плоскую адресацию. Полномасштабная версия Dojo будет иметь производительность до 20 Эфлопс. Сколько сил потребуется компании, чтобы запустить такого монстра, а главное, снабдить его рабочим и приносящим пользу ПО, неизвестно — но явно немало. Известно, что система совместима с PyTorch. В настоящее время Tesla уже получает готовые чипы D1 от TSMC. А пока что компания обходится самым большим в мире по числу установленных ускорителей NVIDIA ИИ-суперкомпьютером.
22.07.2022 [21:52], Алексей Степин
Бразильская нефтегазовая компания Petrobras получит самый мощный суперкомпьютер в Латинской Америке — PegasusСовременный суперкомпьютер, а лучше несколько, стремится иметь любая страна или корпорация, и гонка HPC-решений проходит не только между США и Китаем — так, крупнейшая бразильская нефтегазовая компания Petrobras анонсировала создание нового кластера в Рио-де-Жанейро. Будущий суперкомпьютер получил имя Pegasus, и он должен стать самой мощной HPC-системой в латиноамериканском регионе с производительностью около 21 Пфлопс. Система будет включать в себя 2016 ускорителей неизвестной пока модели и 678 Тбайт оперативной памяти, а в качестве интерконнекта планируется использовать 400-Гбит/с сеть. Вероятно, это будeт InfiniBand NDR. 
Рио-де-Жанейро. Источник: Pixabay Суперкомпьютеры активно применяются в нефтегазовой отрасли в самых различных сценариях, от поиска новых месторождений до повышения эффективности существующих процессов переработки природных ресурсов. Petrobras уже располагает солидными вычислительными мощностями, составляющими 42 Пфлопс. Главной задачей Pegasus будет обработка обширных массивов данных в рамках геологоразведывательного проекта EXP100, а также поиск способов ускорить начало разработок новых нефтегазовых полей в проекте PROD1000. 
Машинный зал Dragão. Источник: Agência Petrobras В июне 2021 года компания Petrobras запустила систему Dragão с 200 Тбайт памяти и 100G-интерконнектом. Система на базе процессоров Xeon Gold 6230R занимает 60 место в TOP500 с пиковой теоретической производительностью 14,01 Пфлопс. Также у Petrobras есть машины Atlas (8,84 Пфлопс) и Fênix (5,37 Пфлопс). Для сравнения — система HPC5, принадлежащая итальянской нефтегазовой компании Eni S.p.A., сейчас находится на 12 месте TOP500 и имеет пиковую теоретическую производительность 51,72 Пфлопс. До момента ввода в строй Pegasus, который запланирован на декабрь 2022 года, Dragão продолжит оставаться мощнейшей латиноамериканской HPC-системой. К концу 2022 года компания намеревается нарастить свой пул вычислительных мощностей до 80 Пфлопс, но пока явно отстаёт от графика. Впрочем, темпы роста впечатляют: ещё в 2018 году в распоряжении Petrоbras было лишь 3 Пфлопс.
15.06.2022 [23:40], Алексей Степин
Анонсирован первый европейский суперкомпьютер экзафлопсного класса — JUPITERВсемирная гонка суперкомпьютеров экзафлопсного класса продолжается, и теперь в игру, наконец, вступил Евросоюз — консорциума EuroHPC сегодня раскрыл некоторые подробности о первой европейской система подобного уровня. Им станет машина под названием JUPITER (Joint Undertaking Pioneer for Innovative and Transformative Exascale Research), которая должна будет войти в строй в следующем году. Система будет смонтирована в Юлихском исследовательском центре (FZJ) в Германии. Сведений об аппаратной начинке JUPITER пока не так много, но в конструкции нового HPC-монстра будет применён тот же модульный подход, что был опробован на его предшественнике, суперкомпьютере JUWELS. Последний вступил в строй в 2018 году и на данный момент содержит несколько кластеров и бустеров с различной архитектурой. 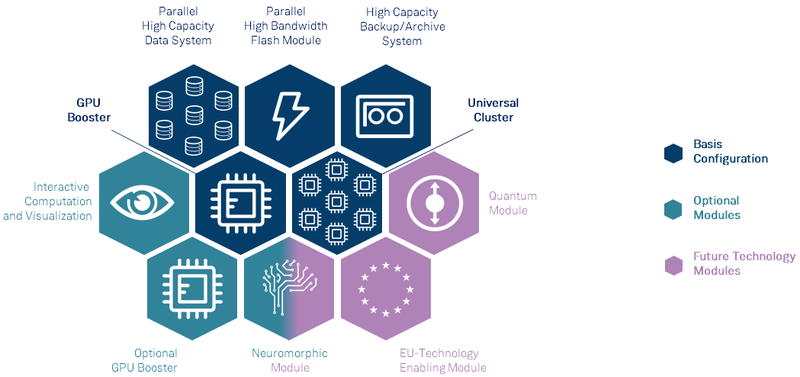
Архитектура европейской экзафлопсной системы включает необычные средства. Источник: FZJ Новая система получит отдельные модули, куда входят вычислительные узлы, пулы памяти, узлы с различными ускорителями, узлы визуализации и т.д. Более того, она может быть дополнена блоками, которые содержат нейроморфные и квантовые системы, а также любые вычислительные модули, построенные на технологиях Евросоюза. Стоимость JUPITER оценивается примерно в €502 млн. Половину оплатит EuroHPC, четверть предоставит Министерство образования и науки Германии, оставшаяся четверть придётся на долю Министерства культуры и науки Северной Рейн-Вестфалии. 
Машинный зал JUWELS. Источник: FZJ Проектировщики уделят серьёзное внимание энергоэффективности новой системы. Ожидается, что её потребление составит около 15 МВт, то есть она будет экономичнее нынешнего лидера TOP500 в лице Frontier. Для питания JUPITER планируется задействовать возобновляемые источники энергии, а СЖО будет использовать теплоноситель с относительно высокой рабочей температурой. Рассматривается возможность утилизации выделяемого системой тепла, как это реализовано в финском LUMI. 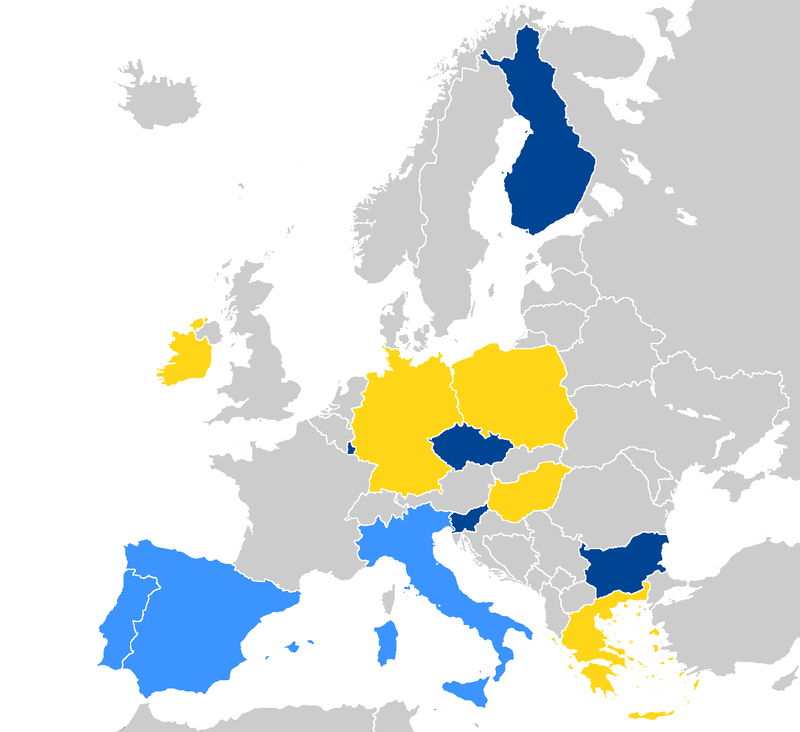
Страны, уже запустившие системы EuroHPC отмечены тёмно-синим, светло-синие — в процессе, жёлтым отмечены новички. Источник: EuroHPC Консорциум также анонсировал ещё четыре, более скромных суперкомпьютера. Это греческий DAEDALUS, венгерский LEVENTE, ирландский CASPIr и польский EHPCPL. В течение следующих нескольких лет EuroHPC планирует ввести в строй ещё минимум два суперкомпьютера экзафлопсного класса, так что гонка за зеттафлопом станет ещё интереснее. Впрочем, и Европе, и США надо опасаться в первую очередь Китая.
14.06.2022 [16:33], Владимир Мироненко
В Финляндии официально запущен LUMI, самый мощный суперкомпьютер в ЕвропеHPE и EuroHPC официально ввели в эксплуатацию вычислительную систему LUMI, установленную в ЦОД центре IT Center for Science (CSC) в Каяани (Финляндия), которая на данный момент считается самым мощным суперкомпьютером в Европе. LUMI — это первая система предэкзафлопсного класса, созданная в рамках совместного европейского проекта EuroHPC. LUMI будет в основном использоваться для решения важных для общества задач, включая исследования в области изменения климата, медицины, наук о жизни и т.д. Система будет применяться для приложений, связанных с высокопроизводительными вычислениями (HPC), искусственным интеллектом и аналитикой данных, а также в областях их пересечения. Для отдельных пользователей суперкомпьютер будет доступен в рамках второй пилотной фазы в августе, а полностью укомплектованная система станет общедоступной в конце сентября. 
Суперкомпьютер LUMI (Фото: Pekka Agarth) Суперкомпьютер стоимостью €202 млн принадлежит EuroHPC (JU). Половина из этой суммы была предоставлена Евросоюзом, четверть — Финляндией, а остальная часть средств поступила от остальных членов консорциума, включающего 10 стран. По состоянию на 30 мая LUMI занимал третье место в списке TOP500 самых быстрых суперкомпьютеров мира. Сейчас его производительность составляет 151,9 Пфлопс при энергопотреблении 2,9 МВт. LUMI (снег в переводе с финского) базируется на системе HPE Cray EX. Система состоит из двух комплексов. Блок с ускорителями включает 2560 узлов, каждый из которых состоит из одного 64-ядерного кастомного процессора AMD EPYC Trento и четырёх AMD Instinct MI250X. Второй блок под названием LUMI-C содержит только 64-ядерные CPU AMD EPYC Milan в 1536 двухсокетных узлах, имеющих от 256 Гбайт до 1 Тбайт RAM. 
Дата-центр LUMI (Фото: Fade Creative) LUMI также имеет 64 GPU NVIDIA A40, используемых для рабочих нагрузок визуализации, и узлы с увеличенным объёмом памяти (до 32 Тбайт на кластер). Основной интерконнект — Slingshot 11. Хранилище LUMI построено на базе СХД Cray ClusterStor E1000 c ФС Lustre: 8 Пбайт SSD + 80 Пбайт HDD. Также есть объектное Ceph-хранилище ёмкостью 30 Пбайт. Агрегированная пропускная способность СХД составит 2 Тбайт/с. В ближайшее время суперкомпьютер получит дополнительные узлы. После завершения всех работ производительность суперкомпьютера, как ожидается, вырастет примерно до 375 Пфлопс, а пиковая производительность потенциально превысит 550 Пфлопс. Общая площадь комплекса составит порядка 300 м2, а энергопотребление вырастет до 8,5 МВт. Впрочем, запас у площадки солидный — от ГЭС она может получить до 200 МВт. «Мусорное» тепло идёт на обогрев местных домов.
13.06.2022 [16:34], Руслан Авдеев
Площадка для будущего 2-Эфлопс суперкомпьютера El Capitan готова: 85 МВт + мощная система охлажденияНациональное управление ядерной безопасности (NNSA) при Министерстве энергетики США официально закончило реконструкцию ЦОД при Ливерморской национальной лаборатории (LLNL) в рамках проекта Exascale Computing Facility Modernization. Обновлены энергетическая система и система охлаждения местного вычислительного центра для использования вычислительных мощностей экзафлопсного уровня. Первой новой действующей системой NNSA станет 2-Эфлопс суперкомпьютер El Capitan, предназначенный для выполнения задач Ливерморской лаборатории, Лос-Аламосской национальной лаборатории и Сандийской национальной лаборатории. По словам представителя NNSA, экзафлопсные вычисления помогут стране в важных, неотложных проектах модернизации вооружений. 
Источник изображения: Department of Energy Обновление позволит Ливерморской лаборатории выполнять ресурсоёмкие задачи, 3D-моделирование и симуляцию процессов, связанных с реализацией военных проектов — это необходимо для того, чтобы соответствовать требованиям к сертификации Программы сопровождения ядерного арсенала, реализуемой под эгидой NNSA, основной миссией которой декларируется расширение возможностей американских средств ядерного сдерживания. Сейчас стадия обновления ЦОД завершена и намечен переход к следующим этапам. В результате реализации проекта более, чем удвоилась охлаждающая мощность объекта — теперь он способен ежедневно поглощать количество тепла, достаточного для того, чтобы растопить 28 тыс. тонн льда. Энергетическая мощность ЦОД увеличена с 45 до 85 МВт, а в процессе строительства были обновили линии электропередач, подстанции и управляющее оборудование. Ожидается, что итоговая производительность El Capitan составит более 2 Эфлопс, а потреблять он будет порядка 30–35 МВт. Проработать он должен до 2029 года, однако параллельно будет строиться ещё один суперкомпьютер нового поколения. Некоторые предполагают, что подобные площадки станут последними в своём роде, в первую очередь из-за проблем с электропитанием. |
|