Материалы по тегу: компьютер
|
13.09.2024 [10:22], Сергей Карасёв
Некогда самый мощный в мире суперкомпьютер Summit уйдёт на покой в ноябреВысокопроизводительный вычислительный комплекс Summit, установленный в Окриджской национальной лаборатории (ORNL) Министерства энергетики США, будет выведен из эксплуатации в ноябре 2024 года. Обслуживать машину становится всё дороже, а по эффективности она уступает современным суперкомпьютерам. Summit был запущен в 2018 году и сразу же возглавил рейтинг мощнейших вычислительных систем мира TOP500. Комплекс насчитывает 4608 узлов, каждый из которых оборудован двумя 22-ядерными процессорами IBM POWER9 с частотой 3,07 ГГц и шестью ускорителями NVIDIA Tesla GV100. Узлы соединены через двухканальную сеть Mellanox EDR InfiniBand, что обеспечивает пропускную способность в 200 Гбит/с для каждого сервера. Энергопотребление машины составляет чуть больше 10 МВт. 
Источник изображения: ORNL FP64-быстродействие Summit достигает 148,6 Пфлопс (Linpack), а пиковая производительность составляет 200,79 Пфлопс. За шесть лет своей работы суперкомпьютер ни разу не выбывал из первой десятки TOP500: так, в нынешнем рейтинге он занимает девятую позицию. 
Источник изображения: ORNL Отправить Summit на покой планировалось в начале 2024-го. Однако затем была запущена инициатива SummitPLUS, и срок службы вычислительного комплекса увеличился практически на год. Отмечается, что этот суперкомпьютер оказался необычайно продуктивным. Он обеспечил исследователям по всему миру более 200 млн часов работы вычислительных узлов. В настоящее время ORNL эксплуатирует ряд других суперкомпьютеров, в число которых входит Frontier — самый мощный НРС-комплекс в мире. Его пиковое быстродействие достигает 1714,81 Пфлопс, или более 1,7 Эфлопс. При этом энергопотребление составляет 22 786 кВт: таким образом, система Frontier не только быстрее, но и значительно энергоэффективнее Summit. А весной этого года из-за растущего количества сбоев и протечек СЖО на аукционе был продан 5,34-ПФлопс суперкомпьютер Cheyenne.
12.09.2024 [11:20], Сергей Карасёв
Начался монтаж модульного ЦОД для европейского экзафлопсного суперкомпьютера JUPITERЮлихский исследовательский центр (Forschungszentrum Jülich) объявил о начале фактического создания модульного дата-центра для европейского экзафлопсного суперкомпьютера JUPITER (Joint Undertaking Pioneer for Innovative and Transformative Exascale Research). Европейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) заключило контракт на создание JUPITER с консорциумом, в который входят Eviden (подразделение Atos) и ParTec. В рамках партнёрства за создание модульного ЦОД отвечает Eviden. После завершения строительства комплекс, как ожидается, объединит около 125 стоек BullSequana XH3000. Общая площадь ЦОД составит примерно 2300 м2. Он будет включать порядка 50 компактно расположенных контейнеров. Благодаря модульной конфигурации ускоряется монтаж систем, а также снижаются расходы на строительство объекта. Суперкомпьютер JUPITER получит энергоэффективные высокопроизводительные европейские Arm-процессоры SiPearl Rhea. CPU-блок будет включать 1300 узлов и иметь производительность около 5 Пфлопс (FP64). Кроме того, в состав машины войдут порядка 6000 узлов с NVIDIA Quad GH200, а общее количество суперчипов GH200 Grace Hopper составит почти 24 тыс. Именно они и обеспечат FP64-производительность на уровне 1 Эфлопс. Узлы объединит интерконнект NVIDIA InfiniBand NDR (DragonFly+). 
Источник изображений: Юлихский исследовательский центр Хранилище системы будет включать два раздела: быстрый ExaFLASH и ёмкий ExaSTORE. ExaFLASH будет базироваться на сорока All-Flash СХД IBM Elastic Storage System 3500 с эффективной ёмкостью 21 Пбайт («сырая» 29 Пбайт), скоростью записи 2 Тбайт/с и скоростью чтения 3 Тбайт/с. ExaSTORE будет иметь «сырую» ёмкость 300 Пбайт, а для резервного копирования и архивов будет использоваться ленточная библиотека ёмкостью 700 Пбайт.  «Первые контейнеры для нового европейского экзафлопсного суперкомпьютера доставлены компанией Eviden и установлены на площадке ЦОД. Мы рады, что этот масштабный проект, возглавляемый EuroHPC, всё больше обретает форму», — говорится в сообщении Юлихского исследовательского центра.  Ожидаемое быстродействие JUPITER на операциях обучения ИИ составит до 93 Эфлопс, а FP64-производительность превысит 1 Эфлопс. Стоимость системы оценивается в €273 млн, включая доставку, установку и обслуживание НРС-системы. Общий бюджет проекта составит около €500 млн, часть средств уйдёт на подготовку площадки, оплату электроэнергии и т.д.
11.09.2024 [18:55], Игорь Осколков
Oracle анонсировала зеттафлопсный облачный ИИ-суперкомпьютер из 131 тыс. NVIDIA B200Oracle и NVIDIA анонсировали самый крупный на сегодняшний день облачный ИИ-кластер, состоящий из 131 072 ускорителей NVIDIA B200 (Blackwell). По словам компаний, это первая в мире система производительностью 2,4 Зфлопс (FP8). Кластер заработает в I половине 2025 года, но заказы на bare-metal инстансы и OCI Superclaster компания готова принять уже сейчас. Заказчики также смогут выбрать тип подключения: RoCEv2 (ConnectX-7/8) или InfiniBand (Quantum-2). По словам компании, новый ИИ-кластер вшестеро крупнее тех, что могут предложить AWS, Microsoft Azure и Google Cloud. Кроме того, компания предлагает и другие кластеры с ускорителями NVIDIA: 32 768 × A100, 16 384 × H100, 65 536 × H200 и 3840 × L40S. А в следующем году обещаны кластеры на основе GB200 NVL72, объединяющие более 100 тыс. ускорителей GB200. В скором времени также появятся и куда более скромные ВМ GPU.A100.1 и GPU.H100.1 с одним ускорителем A100/H100 (80 Гбайт). Прямо сейчас для заказы доступны инстансы GPU.H200.8, включающие восемь ускорителей H200 (141 Гбайт), 30,7-Тбайт локальное NVMe-хранилище и 200G-подключение. Семейство инстансов на базе NVIDIA Blackwell пока включает лишь два варианта. GPU.B200.8 предлагает восемь ускорителей B200 (192 Гбайт), 30,7-Тбайт локальное NVMe-хранилище и 400G-подключение. Наконец, GPU.GB200 фактически представляет собой суперускоритель GB200 NVL72 и включает 72 ускорителя B200, 36 Arm-процессоров Grace и локальное NVMe-хранилище ёмкостью 533 Тбайт. Агрегированная скорость сетевого подключения составляет 7,2 Тбит/с. 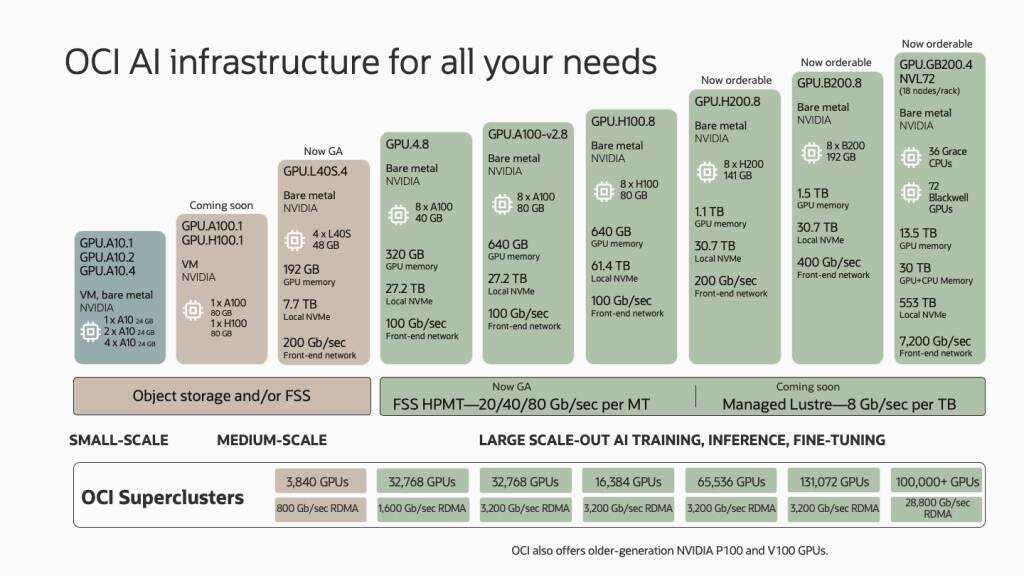
Источник изображения: Oracle Для всех новых инстансов Oracle подготовит управляемое Lustre-хранилище с производительностью до 8 Гбит/с на каждый Тбайт. Кроме того, компания предложит расширенные средства мониторинга и управления, помощь в настройке инфраструктуры для достижения желаемого уровня реальной производительности, а также набор оптимизированного ПО для работы с ИИ, в том числе для Arm.
10.09.2024 [14:55], Сергей Карасёв
TACC ввёл в эксплуатацию Arm-суперкомпьютер Vista на базе NVIDIA GH200 для ИИ-задачТехасский центр передовых вычислений (TACC) при Техасском университете в Остине (США) объявил о том, что мощности нового НРС-комплекса Vista полностью доступны открытому научному сообществу. Суперкомпьютер предназначен для решения ресурсоёмких задач, связанных с ИИ. Формальный анонс машины Vista состоялся в ноябре 2023 года. Тогда говорилось, что Vista станет связующим звеном между существующим суперкомпьютером TACC Frontera и будущей системой TACC Horizon, проект которой финансируется Национальным научным фондом (NSF). Vista состоит из двух ключевых частей. Одна из них — кластер из 600 узлов на гибридных суперчипах NVIDIA GH200 Grace Hopper, которые содержат 72-ядерный Arm-процессор NVIDIA Grace и ускоритель H100/H200. Обеспечивается производительность на уровне 20,4 Пфлопс (FP64) и 40,8 Пфлопс на тензорных ядрах. Каждый узел содержит локальный накопитель вместимостью 512 Гбайт, 96 Гбайт памяти HBM3 и 120 Гбайт памяти LPDDR5. Интероконнект — Quantum 2 InfiniBand (400G). Второй раздел суперкомпьютера объединяет 256 узлов с процессорами NVIDIA Grace CPU Superchip, содержащими два кристалла Grace в одном модуле (144 ядра). Узлы укомплектованы 240 Гбайт памяти LPDDR5 и накопителем на 512 Гбайт. Интерконнект — Quantum 2 InfiniBand (200G). Узлы произведены Gigabyte, а за интеграцию всей системы отвечала Dell. 
Источник изображения: TACC Общее CPU-быстродействие Vista находится на отметке 4,1 Пфлопс. В состав комплекса входит NFS-хранилише VAST Data вместимостью 30 Пбайт. Суперкомпьютер будет использоваться для разработки и применения решений на основе генеративного ИИ в различных секторах, включая биологические науки и здравоохранение.
03.09.2024 [14:09], Руслан Авдеев
Бразильская Petrobras купит пять суперкомпьютеров Lenovo за $89 млнБразильская государственная нефтегазовая компания Petrobras намерена потратить $89 млн на покупку пяти новых супекомпьютеров Lenovo, которая смогла выиграть тендер, предложив лучшую по сравнению с Atos и Dell цену. По данным Datacenter Dynamics, системы разместят на территории принадлежащего компании инновационного центра Cenpes в Рио-де-Жанейро. Ожидается, что сборка начнётся в текущем году, а в ввод в эксплуатацию состоится в следующем. Немного технической информации доступно только об одном суперкомпьютере производительностью до 73 Пфлопс, который заменит принадлежащие компании машины Fênix, Atlas и Dragão. В марте 2023 года Petrobras внедрила свой первый ИИ-суперкомпьютер Tatu, построенный Atos на основе 224 ускорителей NVIDIA с 80 Гбайт памяти. А в 2022 году компания развернула систему Pegasus. 
Источник изображения: Davi Costa/unsplash.com Неназванная 73-Пфлопс система будет наиболее масштабной из пяти новых суперкомпьютеров и, как сообщают в Petrobras, станет самой «экоэффективной» в Латинской Америке. Компания намерена использовать суперкомпьютер для обработки сейсмоданных и создания симуляций процессов под земной поверхностью. Это поможет выявлять новые запасы нефти и газа. Как сообщают в компании, покупка новых суперкомпьютеров является для Petrobras делом стратегической важности, она позволит компании оставаться технологическим лидером нефтегазового сектора. Обновление парка суперкомпьютеров входит в стратегический план компании на 2024–2028 гг., который, помимо финансирования модернизации Cenpes, включает обязательства, связанные с декарбонизацией и энергетическим переходом.
03.09.2024 [11:04], Сергей Карасёв
Стартап xAI Илона Маска запустил ИИ-кластер со 100 тыс. ускорителей NVIDIA H100Илон Маск (Elon Musk) объявил о том, что курируемый им стартап xAI запустил кластер Colossus, предназначенный для обучения ИИ. На сегодняшний день в состав этого вычислительного комплекса входят 100 тыс. ускорителей NVIDIA H100, а в дальнейшем его мощности будут расширяться. Напомним, xAI реализует проект по созданию «гигафабрики» для задач ИИ. Предполагается, что этот суперкомпьютер в конечном итоге будет насчитывать до 300 тыс. новейших ускорителей NVIDIA B200. Оборудование для платформы поставляют компании Dell и Supermicro, а огромный дата-центр xAI расположен в окрестностях Мемфиса (штат Теннесси). «В эти выходные команда xAI запустила кластер Colossus для обучения ИИ со 100 тыс. карт H100. От начала до конца всё было сделано за 122 дня. Colossus — самая мощная система обучения ИИ в мире», — написал Маск в социальной сети Х. 
Источник изображения: WebProNews По его словам, в ближайшие месяцы вычислительная мощность платформы удвоится. В частности, будут добавлены 50 тыс. изделий NVIDIA H200. Маск подчёркивает, что Colossus — это не просто еще один кластер ИИ, это прыжок в будущее. Основное внимание в рамках проекта будет уделяться использованию мощностей Colossus для расширения границ ИИ: планируется разработка новых моделей и улучшение уже существующих. Ожидается, что по мере масштабирования и развития система станет важным ресурсом для широкого сообщества ИИ, предлагая беспрецедентные возможности для исследований и инноваций. Запуск столь производительного кластера всего за 122 дня — это значимое достижение для всей ИИ-отрасли. «Удивительно, как быстро это было сделано, и для Dell Technologies большая честь быть частью этой важной системы обучения ИИ», — сказал Майкл Делл (Michael Dell), генеральный директор Dell Technologies.
02.09.2024 [12:12], Сергей Карасёв
HPE создала суперкомпьютер Iridis 6 на платформе AMD для Саутгемптонского университетаКомпания НРЕ поставила в Саутгемптонский университет в Великобритании высокопроизводительный вычислительный комплекс Iridis 6, построенный на аппаратной платформе AMD. Использовать суперкомпьютер планируется для проведения исследований в таких областях, как геномика, аэродинамика и источники питания нового поколения. В основу Iridis 6 положены серверы HPE ProLiant Gen11 на процессорах AMD EPYC семейства Genoa. Задействованы 138 узлов, каждый из которых насчитывает 192 вычислительных ядра и несёт на борту 3 Тбайт памяти. Таким образом, в общей сложности используются 26 496 ядер. В частности, в состав Iridis 6 включены четыре узла с 6,6 Тбайт локального хранилища, а также три узла входа с хранилищем вместимостью 15 Тбайт. Используется интерконнект Infiniband HDR100. В HPE сообщили, что в настоящее время система обеспечивает производительность HPL (High-Performance Linpack) на уровне примерно 1 Пфлопс. В дальнейшем количество узлов планируется увеличивать, что позволит поднять быстродействие. 
Источник изображения: НРЕ Отмечается, что Iridis 6 приходит на смену суперкомпьютеру Iridis 4, который имел немногим более 12 тыс. вычислительных ядер. При этом новая система будет сосуществовать с комплексом Iridis 5, который использует процессоры Intel Xeon Gold 6138, AMD 7452 и AMD 7502, а также ускорители NVIDIA Tesla V100, GTX 1080 Ti и А100. Эта машина была запущена в 2018-м и заняла 354-е место в списке TOP500 самых мощных суперкомпьютеров мира, опубликованном в июне того же года. Быстродействие Iridis 5 достигает 1,31 Пфлопс.
30.08.2024 [12:43], Сергей Карасёв
Fujitsu займётся созданием ИИ-суперкомпьютера Fugaku Next зеттафлопсного уровняМинистерство образования, культуры, спорта, науки и технологий Японии (MEXT) объявило о планах по созданию преемника суперкомпьютера Fugaku, который в своё время возглавлял мировой рейтинг ТОР500. Ожидается, что новая система, рассчитанная на ИИ-задачи, будет демонстрировать FP8-производительность зеттафлопсного уровня (1000 Эфлопс). В нынешнем списке TOP500 Fugaku занимает четвёртое место с FP64-быстродействием приблизительно 442 Пфлопс. Реализацией проекта Fugaku Next займутся японский Институт физико-химических исследований (RIKEN) и корпорация Fujitsu. Создание системы начнётся в 2025 году, а завершить её разработку планируется к 2030-му. На строительство комплекса MEXT выделит ¥4,2 млрд ($29,06 млн) в первый год, тогда как общий объём государственного финансирования, как ожидается, превысит ¥110 млрд ($761 млн). MEXT не прописывает какой-либо конкретной архитектуры для суперкомпьютера Fugaku Next, но в документации ведомства говорится, что комплекс может использовать CPU со специализированными ускорителями или комбинацию CPU и GPU. Кроме того, требуется наличие передовой подсистемы хранения, способной обрабатывать как традиционные рабочие нагрузки ввода-вывода, так и ресурсоёмкие нагрузки ИИ. 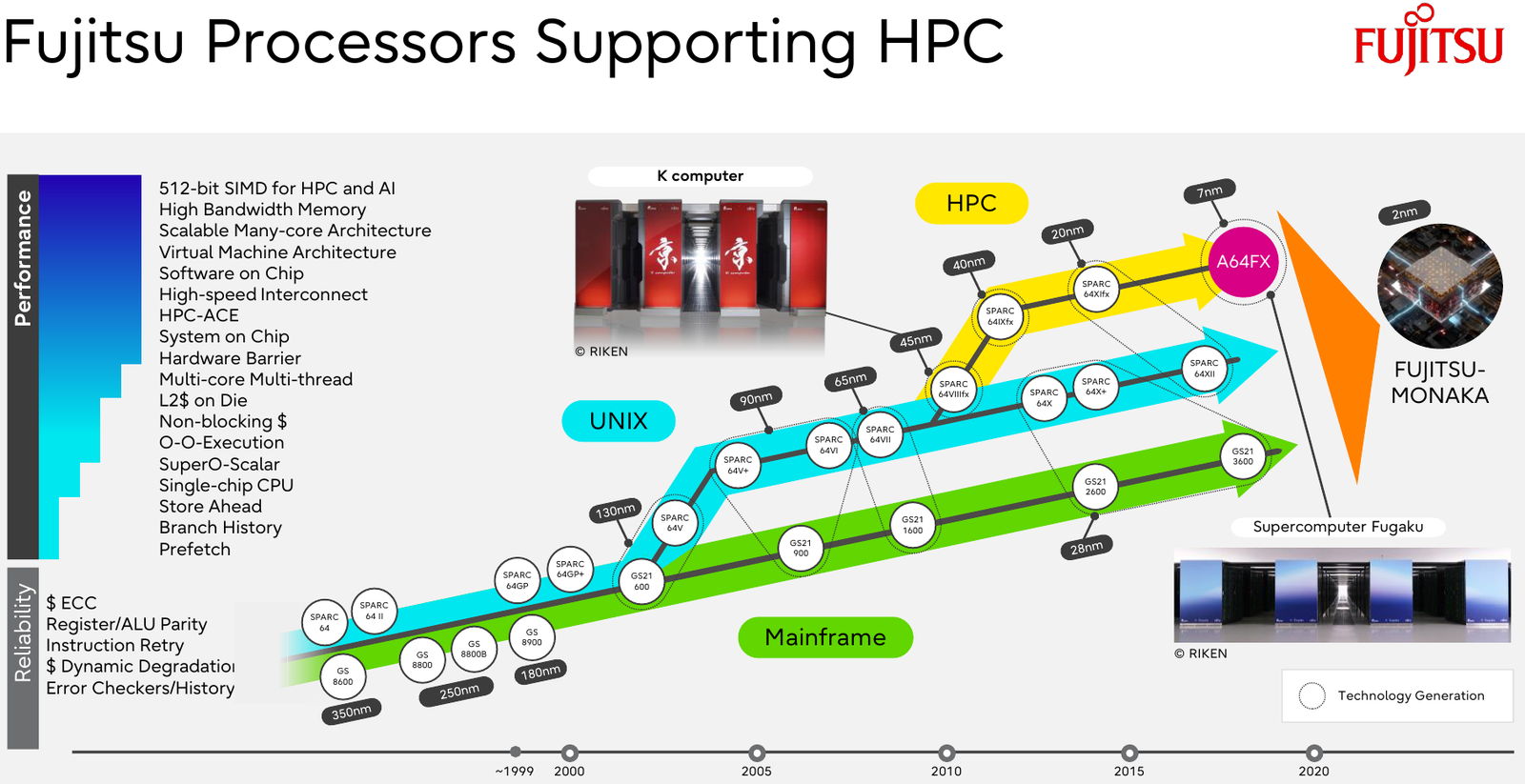
Источник изображения: Fujitsu Предполагается, что каждый узел Fugaku Next обеспечит пиковую производительность в «несколько сотен Тфлопс» для вычислений с двойной точностью (FP64), около 50 Пфлопс для вычислений FP16 и примерно 100 Пфлопс для вычислений FP8. Для сравнения, узлы системы Fugaku демонстрирует быстродействие FP64 на уровне 3,4 Тфлопс и показатель FP16 около 13,5 Тфлопс. Для Fugaku Next предусмотрено применение памяти HBM с пропускной способностью в несколько сотен Тбайт/с против 1,0 Тбайт/с у Fugaku. По всей видимости, в состав Fugaku Next войдут серверные процессоры Fujitsu следующего поколения, которые появятся после изделий MONAKA. Последние получат чиплетную компоновку с кристаллами SRAM и IO-блоками ввода-вывода, обеспечивающими поддержку DDR5, PCIe 6.0 и CXL 3.0. Говорится об использовании 2-нм техпроцесса.
29.08.2024 [16:41], Руслан Авдеев
Илон Маск показал ИИ-суперкластер Tesla Cortex из 50 тыс. ускорителей NVIDIAИлон Маск (Elon Musk) продолжает наращивать вычислительные мощности своих компаний. Как сообщает Tom’s Hardware, он поделился сведениями об ИИ-суперкластере Cortex. По данным Tom's Hardware, недавнее дополнение завода Giga Texas компании Tesla будет состоять из 70 тыс. ИИ-серверов, а также потребует 130 МВт энергии на обеспечение вычислений и охлаждения на момент запуска, к 2026 году мощность вырастет до 500 МВт. На опубликованном в социальной сети X видео Илона Маска показан машинный зал: по 16 IT-стоек в ряд, по два ряда на коридор. Каждая стойка вмещает восемь ИИ-серверов, а в середине каждого ряда видны стойки без таковых. В видео можно разглядеть порядка 16–20 рядов, поэтому довольно грубый подсчёт позволяет предположить наличие около 2 тыс. серверов с ускорителями, т.е. менее 3 % от запланированной ёмкости. В ходе июльского финансового отчёта Tesla Илон Маск рассказал, что Cortex будет крупнейшим обучающим кластером Tesla на сегодняшний день и будет состоять из 50 тыс. ускорителей NVIDIA H100 и 20 тыс. ускорителей Tesla D1 собственной разработки. Это меньше, чем Маск прогнозировал раньше, в июне он сообщал, что Cortex будет включать 50 тыс. D1. Правда, сообщалось, что на момент запуска будут применяться только решения NVIDIA, а разработки Tesla появятся позже. 
Источник изображения: Alexander Shatov/unsplash.com Кластер Cortex предназначен в первую очередь для обучения автопилота Full Self Driving (FSD), сервиса Cybertaxi и роботов Optimus, ограниченное производство которых должно начаться в 2025 году для использования на заводах компании. Также Маск анонсировал планы потратить $500 млн на суперкомпьютер Dojo в Буффало (штат Нью-Йорк), также принадлежащий Tesla. Первым же в «коллекции» Маска заработал Memphis Supercluster, принадлежащий xAI и оснащённый 100 тыс. NVIDIA H100. Со временем эта система получит 300 тыс. ускорителей NVIDIA B200, но задержки с их производством заставили отложить реализацию проекта на несколько месяцев.
24.08.2024 [14:02], Сергей Карасёв
Суперкомпьютер Cray-1 из коллекции сооснователя Microsoft Пола Аллена уйдёт с молоткаАукционный дом Christie's объявил три аукциона под общим названием Gen One — Innovations from the Paul G. Allen Collection: с молотка уйдут сотни предметов, связанных с компьютерной историей, из коллекции сооснователя Microsoft Пола Аллена (Paul Allen). Аллен основал Microsoft вместе с Биллом Гейтсом в 1975 году. В 1983-м он покинул эту корпорацию, занявшись инвестированием, а в 2011 году стал одним из основателей компании Stratolaunch Systems. Аллен скончался в 2018 году в возрасте 65 лет. 
Источник изображений: Christie's Из коллекции Пола Аллена на аукцион Christie's выставлен, в частности, суперкомпьютер Cray-1, анонсированный в 1975 году. Эта машина с начальной стоимостью почти $8 млн (сейчас это чуть больше $46 млн) обладает производительностью 160 Мфлопс. Система имеет уникальную С-образную форму, благодаря которой удалось уменьшить количество проводов внутри корпуса. За время производства было построено всего около 80 экземпляров Cray-1. Выставленная на аукцион система была выведена из эксплуатации и использовалась в качестве демонстрационного образца Cray Research. Это один из семнадцати экземпляров, которые, как считается, сохранились на сегодняшний день. И это первый суперкомпьютер Cray-1, выставленный на торги. Оценочная стоимость лота составляет $150–$250 тыс.  В коллекцию также входит суперкомпьютер Cray-2 1985 года. Как и его предшественник, эта система имеет цилиндрическую С-образную форму. Комплекс с ценой около $16 млн на момент выхода (сейчас это около $47 млн) обеспечивает быстродействие в 1,9 Гфлопс. Всего было продано 25 таких суперкомпьютеров. Эта конкретная модель, проданная REI, считается самой долговечной системой Cray-2: она была выведена из эксплуатации в 1999 году. Ожидается, что цена на аукционе окажется в диапазоне $250–$350 тыс. С молотка также уйдёт суперкомпьютер CDC 6500 1967 года, который оценивается в $200–$300 тыс. Это была первая система, способная выполнять 1 млн инструкций в секунду. Изначально её цена составляла $8 млн (почти $75 млн в современной валюте). На аукцион выставлены несколько мейнфреймов: среди них — DEC PDP10 KA10 и KI10 производства 1968 и 1974 годов соответственно, а также IBM 7090 от 1959 года.  На торги выставлены различные настольные компьютеры (например, Xerox Star 1108 Personal Computer), ранние компьютеры Apple, шифровальная машина Enigma времен Второй мировой войны, микрокомпьютеры (такие как SOL-20 Terminal Microcomputer и MITS Altair 8800b Microcomputer), цифровой компьютер Kenbak-1, персональный компьютер Пола Аллена Compaq и многие другие экспонаты, имеющие историческую ценность. С молотка также уйдут записи Microsoft, произведения научной фантастики, обеденное меню с «Титаника», метеорит, письмо Альберта Эйнштейна президенту Рузвельту с предупреждением об опасности ядерного оружия и скафандр, который носил астронавт Эд Уайт в 1965 году. |
|