Материалы по тегу: ии
|
13.10.2025 [16:45], Руслан Авдеев
Microsoft не хватает ЦОД и серверов в США, причём не только для ИИПроблемы с дата-центрами Microsoft сохранятся дольше, чем рассчитывала компания. Это подчёркивает трудности, с которыми она сталкивается в своём стремлении удовлетворить спрос на облачные технологии, сообщает Bloomberg. Источники, знакомые с внутренними прогнозами Microsoft, сообщают, что во многих облачных регионах на территории США не хватает физического пространства и/или серверов. В некоторых ключевых регионах, включая Северную Вирджинию и Техас, новые подписки на сервисы Azure ограничат до I половины 2026 года. Это дольше, чем компания заявляла ранее. В июле её представитель сообщал, что действующие ограничения сохранятся до конца 2025 года. Нехватка мощностей касается как оборудования с ИИ-ускорителями, так и традиционных серверов, долгое время бывших костяком классических облачных сервисов. Двигателем роста Microsoft является облачное подразделение Azure, которое в 2025 финансовом году принесло более $75 млрд. По темпам развития оно опережает крупнейших конкурентов AWS и Google Cloud. Нехватка серверов для сдачи в аренду клиентам постоянно препятствует выполнению планов гиперскейлеров. В ходе шести последних квартальных отчётов Microsoft последовательно заявляла о неспособности удовлетворить спрос на облачные услуги, у AWS и Google проблемы очень похожие. Представитель Microsoft, впрочем, заявлял, что Azure в США имеет достаточно ресурсов для роста, на пиковые периоды компания может использовать специальные методы распределения мощностей, позволяющие распределить нагрузку между ЦОД, чтобы обеспечить стабильную работу всех пользователей, избегая дефицита ресурсов в отдельных регионах. 
Источник изображения: Microsoft В норме клиенты Azure выбирают облачные регионы с учётом их физической близости и доступных сервисов, но в некоторых случаях, если ресурсов недостаточно, менеджеры Microsoft рекомендуют другие объекты. Тем не менее такие обходные пути могут усложнить работу и увеличить время передачи данных между ЦОД и клиентом. В Hexaware Technologies сообщают, что те, кому не хватает ресурсов Azure, переносят нагрузки в другие места, используют несколько регионов Azure или отправляют в облако только критически важные нагрузки до высвобождения ресурсов. В исключительных случаях Microsoft даже компенсирует дополнительные непредвиденные расходы. По имеющимся данным, Microsoft только за последний год увеличила мощность ЦОД более чем на 2 ГВт. Интенсивные вычислительные потребности ИИ привели к необходимости создания новых дата-центров. Впрочем, сегодня Microsoft не достаёт и ресурсов традиционной облачной инфраструктуры. По словам источников, OpenAI сегодня является крупнейшим облачным клиентом Microsoft, использующим серверы на основе CPU. Кроме того, такие машины применяет и сама Microsoft для обеспечения работы своих приложений. По слухам, некоторые внутренние проекты закрываются в проблемных регионах для экономии ресурсов. 
Источник изображения: Microsoft На ввод в эксплуатацию нового ЦОД «с нуля» могут уйти годы. Впрочем, за пределами США доступность ЦОД значительно выше. Например, многие европейские регионы Microsoft могут регистрировать новых клиентов без ограничений. По словам Microsoft, если в январе 2025 года она надеялась, что соотношение спроса и предложения в США улучшится к июню, то позже в компании стали говорить, что оптимистичным сценарием будет улучшение ситуации к декабрю. Впрочем, развитие компании не прекращается. Недавно пресс-служба отчиталась о введении в действие новых мощностей в Азии. Кроме того, Microsoft развернула для OpenAI первый в мире ИИ-кластер на базе суперускорителей NVIDIA GB300 NVL72. Сейчас компания достраивает «самый передовой» ИИ ЦОД в мире Fairwater, а потом потратит $4 млрд на ещё один такой же.
13.10.2025 [12:14], Сергей Карасёв
IBM представила ускоритель Spyre Accelerator для ИИ-инференсаКорпорация IBM объявила о том, что с конца текущего месяца специализированные ИИ-ускорители Spyre Accelerator станут доступны в составе серверов z17 и LinuxONE 5. А в начале декабря такими картами начнут комплектоваться системы POWER11. О подготовке Spyre Accelerator стало известно в августе прошлого года. Это детище исследовательского подразделения IBM Research. Ускоритель ориентирован на задачи инференса с низкой задержкой. В частности, устройство подходит для работы с генеративными приложениями и ИИ-агентами. 
Источник изображения: IBM Изделие представляет собой плату расширения с интерфейсом PCIe 5.0 x16, в состав которой входит нейропроцессор IBM с 32 ядрами. Кроме того, есть 128 Гбайт памяти LPDDR5. Ускоритель насчитывает в общей сложности 25,6 млрд транзисторов; при производстве применяется 5-нм технология. Заявленное энергопотребление находится на уровне 75 Вт. 
Источник изображения: IBM IBM отмечает, что при использовании традиционных CPU и GPU для решения ресурсоёмких задач в области ИИ возникают сложности с масштабированием и эффективностью. Изделия Spyre Accelerator проектировались с тем, чтобы помочь в устранении указанных недостатков. При необходимости можно объединить до 16 плат в кластер в системе POWER11 и до 48 плат в составе z17. Вкупе с процессорами Telum II, которые лежат в основе z17 и LinuxONE 5, компании смогут одновременно запускать несколько ИИ-моделей. При этом возможен локальный инференс, что минимизирует обращения к сторонним сервисам: это сокращает задержки и способствует повышению безопасности. В качестве потенциальных заказчиков Spyre Accelerator называются финансовые организации, предприятия розничной торговли, государственные структуры, учреждения из сферы здравоохранения, промышленные предприятия и пр.
13.10.2025 [11:32], Сергей Карасёв
Одноплатный компьютер Orange Pi 6 Plus получил 12-ядерный чип с NPU и 64 Гбайт ОЗУДебютировал одноплатный компьютер Orange Pi 6 Plus, предназначенный для создания различных устройств с ИИ-функциями. Это могут быть системы промышленной автоматизации, компактные рабочие станции, edge-оборудование, домашние серверы и пр. Изделие построено на процессоре Cix CD8180/CD8160 с 12 ядрами в конфигурации 4 × Arm Cortex-A720 с тактовой частотой до 2,8 ГГц, 4 × Arm Cortex-A720 с частотой 2,4 ГГц и 4 × Arm Cortex-A520 с частотой 1,8 ГГц. В состав чипа входят графический ускоритель Arm Immortalis-G720 MC10 и нейропроцессорный блок (NPU). Суммарная заявленная ИИ-производительность достигает 45 TOPS. 
Источник изображения: Orange Pi Одноплатный компьютер может нести на борту 16, 32 или 64 Гбайт оперативной памяти LPDDR5-5500. Есть два коннектора M.2 2280 M-Key для SSD с интерфейсом PCIe (NVMe), слот для карты microSD, а также разъём M.2 2230 E-Key для адаптера Wi-Fi / Bluetooth. Предусмотрены два сетевых порта 5GbE. В оснащение новинки входят по два порта USB 3.0 Type-C, USB 3.0 Type-А и USB 2.0, интерфейсы HDMI 1.4, eDP и DisplayPort 1.4 (говорится о возможности вывода изображения в формате 4К со скоростью 120 к/с), два гнезда RJ45 для сетевых кабелей, комбинированное аудиогнездо на 3,5 мм. Имеются два интерфейса камеры MIPI CSI (4 линии) и 40-контактная колодка GPIO (UART, I2C, SPI, PWM). Питание подаётся через коннектор USB Type-C (в комплект входит адаптер мощностью 100 Вт). К плате может быть подключён вентилятор охлаждения с ШИМ-управлением. Габариты составляют 115 × 100 мм, масса — 132 г. Заявлена совместимость с Debian, Ubuntu, Android, Windows, ROS2 (Robot Operating System 2).
13.10.2025 [09:31], Руслан Авдеев
«Зелёные» надежды стали пеплом: американские ЦОД активно переходят на питание от угольных электростанций из-за спроса на ИИИз-за высоких цен на природный газ и стремительного роста спроса на электричество американские дата-центры начали активно пользоваться энергией с угольных электростанций, сообщает The Register. По словам экспертов Jefferies, операторы ЦОД стремятся получить всё новые мощности, при этом ускоренный рост нагрузки ожидается в 2026–2028 гг. Взлёт спроса на электричество неожиданно дал второе дыхание угольной энергетики, от которой давно собирались отказываться на государственном уровне не только в США, но и других странах. В Соединённых Штатах её использование выросло на 20 %. Эксперты констатируют, что прогноз по «угольной» генерации повышен на 11 %. Ожидается, что она останется на высоком уровне как минимум до 2027 года. Дело в том, что уголь стало выгоднее использовать по сравнению с природным газом, особенно для уже действующих станций. Ранее эксперты уже предупреждали, что из-за роста спроса на электроэнергию в связи с увеличением числа ЦОД в Соединённых Штатах доступных генерирующих мощностей может не хватить, что приведёт к продлению сроков эксплуатации угольных электростанций. Кроме того, операторы ЦОД и гиперскейлеры, вероятно, откажутся от прежних «зелёных» обещаний и попытаются скрыть реальные экологические показатели своей деятельности. 
Источник изображения: Leo Aki / Unsplash Например, в Омахе одна энергокомпания отказалась от сокращения угольной энергетики из-за необходимости обслуживания ближайших ЦОД. В противном случае вероятен дефицит электричества в округе. При этом продолжение работы угольных электростанций влияет на качество воздуха вблизи них и мешает сокращать выбросы парниковых газов. Некоторые экологи характеризуют уголь как «самый грязный способ производства энергии». В отчёте Morgan Stanley за 2024 год прогнозируется, что к 2030 году дата-центры будут выбрасывать в атмосферу 2,5 млрд т парниковых газов в мировом масштабе, втрое больше, чем без развития ИИ-технологий. Газовые генераторы были бы гораздо предпочтительнее, особенно потому, что их можно размещать на территории самих кампусов ЦОД, хотя текущие цены на газ сделали такой вариант менее привлекательным. Впрочем, как сообщает The Financial Times, застройщики обычно предпочитают электростанции, строительство которых проще организовать. Если операторы ЦОД смогут ввести свои объекты в эксплуатацию быстро и с соблюдением экологических нормативов, они это сделают, но временным решением, скорее всего, станут газовые или угольные электростанции. 
Источник изображения: Adriano/unsplash.com Текущая политика американских властей дополнительно затрудняет внедрение возобновляемых источников энергии. Администрация президента США принимает меры, мешающие развитию возобновляемой энергетики, в том числе фактически замораживающие процесс утверждения проектов ветряной и солнечной генерации, ссылаясь на из высокую стоимость и проблемы с землепользованием. Это критикуется некоторыми экспертами, утверждающими, что возобновляемые источники или малые модульные реакторы (SMR) смогут обеспечить ЦОД электричеством даже с меньшими затратами, чем классические электростанции. Тем не менее, в сентябре Министерство внутренних дел США (занимается природными ресурсами и федеральными землями) заявило, что настоящая экзистенциальная угроза — не изменения климата, а факт, что «гонку вооружений» в сфере ИИ можно проиграть, если электричества будет недостаточно. Схожей позиции придерживаются и в Министерстве энергетики, утверждая, что к изменению климата стоит относиться лишь как к глобальному физическому явлению, ставшему «побочным эффектом» от построения современного мира. В конце сентября министерство заявляло, что намерено отложить вывод из эксплуатации большинства угольных электростанций страны, чтобы удовлетворить кратный рост спроса на электричество в будущем. В конце апреля Трамп поддержал угольный сектор страны, подписав ряд указов для его реанимации. Впрочем, в остальном мире ситуация не лучше.
13.10.2025 [00:30], Владимир Мироненко
Вложи $5 млн — получи $75 млн: NVIDIA похвасталась новыми рекордами в комплексном бенчмарке InferenceMAX v1
b200
gb200
hardware
nvidia
open source
semianalysis
бенчмарк
ии
инференс
рекорд
финансы
энергоэффективность
NVIDIA сообщила о результатах, показанных суперускорителем GB200 NVL72, в новом независимом ИИ-бенчмарке InferenceMAX v1 от SemiAnalysis. InferenceMAX оценивает реальные затраты на ИИ-вычисления, определяя совокупную стоимость владения (TCO) в долларах на миллион токенов для различных сценариев, включая покупку и владение GPU в сравнении с их арендой. InferenceMAX опирается на инференс популярных моделей на ведущих платформах, измеряя его производительность для широкого спектра вариантов использования, а результаты может перепроверить любой желающий, говорят авторы бенчмарка. Суперускоритель GB200 NVL72 победил во всех категориях бенчмарка InferenceMAX v1. Чипы NVIDIA Blackwell показали наилучшую окупаемость инвестиций — вложение в размере $5 млн приносят $75 млн дохода от токенов DeepSeek R1, обеспечивая 15-кратную окупаемость (год назад NVIDIA обещала ROI на уровне 700 %). Также ускорители поколения Blackwell отличаются самой низкой совокупной стоимостью владения. например, оптимизация ПО NVIDIA B200 позволила добиться стоимости всего в два цента на миллион токенов на OpenAI gpt-oss-120b, обеспечив пятикратное снижение стоимости одного токена всего за два месяца. NVIDIA B200 первенствовал и по пропускной способности и интерактивности, обеспечив 60 тыс. токенов в секунду на ускоритель и 1 тыс. токенов в секунду на пользователя в gpt-oss с новейшим стеком NVIDIA TensorRT-LLM. NVIDIA сообщила, что постоянно повышает производительность путём оптимизации аппаратного и программного стека. Первоначальная производительность gpt-oss-120b на системе NVIDIA DGX Blackwell B200 с библиотекой NVIDIA TensorRT LLM уже была лидирующей на рынке, но команды NVIDIA и сообщество разработчиков значительно оптимизировали TensorRT LLM для ускорения исполнения открытых больших языковых моделей (LLM). 
Источник изображений: NVIDIA Компания отметила, что выпуск TensorRT LLM v1.0 стал значительным прорывом в повышении скорости инференса LLM благодаря распараллеливанию и оптимизации IO-операций. А у недавно вышедшей модели gpt-oss-120b-Eagle3-v2 используется спекулятивное декодирование — интеллектуальный метод, позволяющий предсказывать несколько токенов одновременно. Это уменьшает задержку и обеспечивает получение ещё более быстрых результатов — пропускная способность выросла втрое, до 100 токенов в секунду на пользователя (TPS/пользователь), а общая производительность на ускоритель выросла с 6 до 30 тыс. токенов. 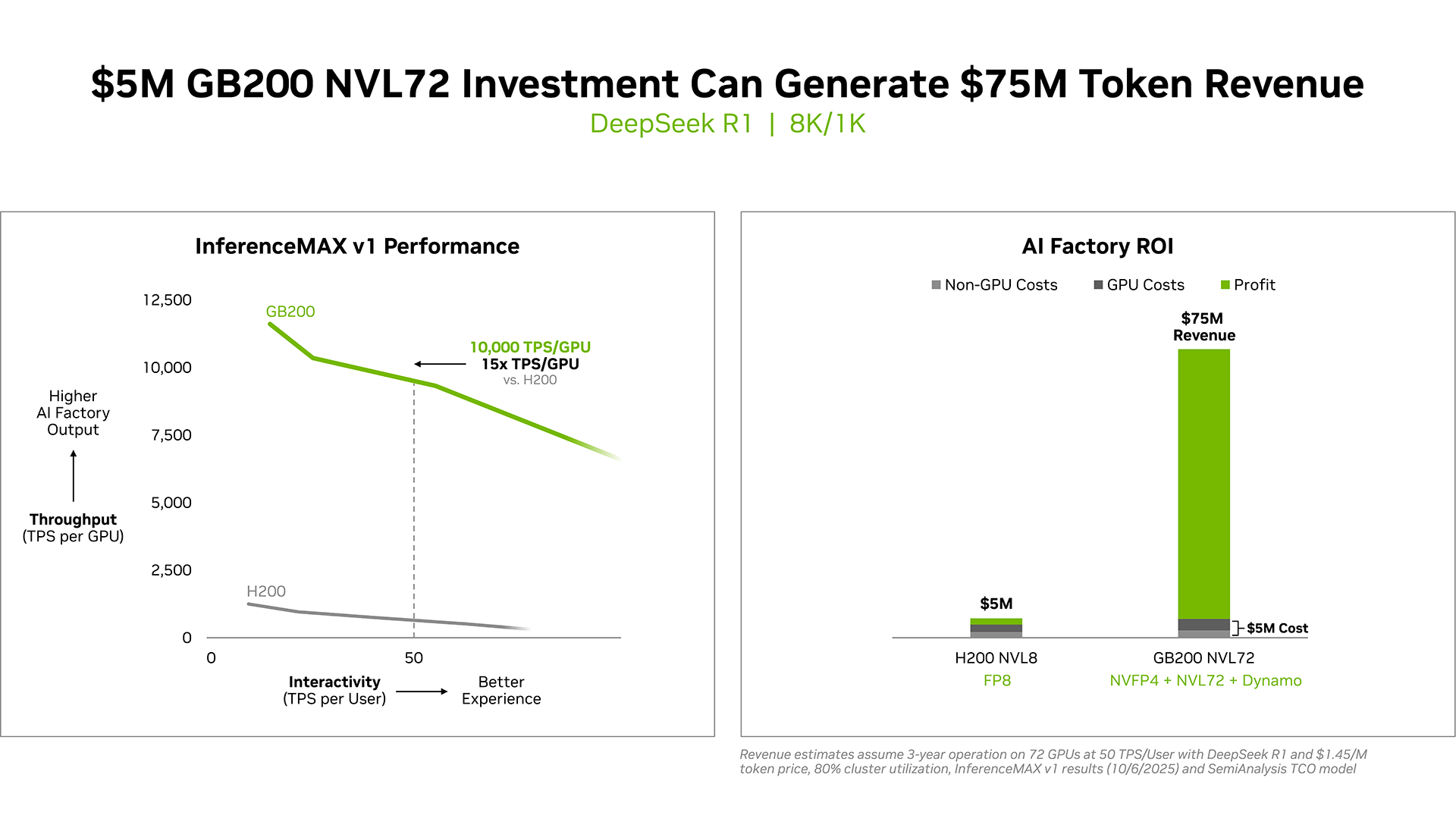 Для моделей с «плотной» архитектурой (Dense AI), таких как Llama 3.3 70b, которые требуют значительных вычислительных ресурсов из-за большого количества параметров и одновременного использования всех параметров в процессе инференса, NVIDIA Blackwell B200 достиг нового рубежа производительности в бенчмарке InferenceMAX v1, отметила NVIDIA. Суперускоритель показал более 10 тыс. токенов/с (TPS) на GPU при 50 TPS на пользователя, т.е. вчетверо более высокую пропускную способность на GPU по сравнению с NVIDIA H200. 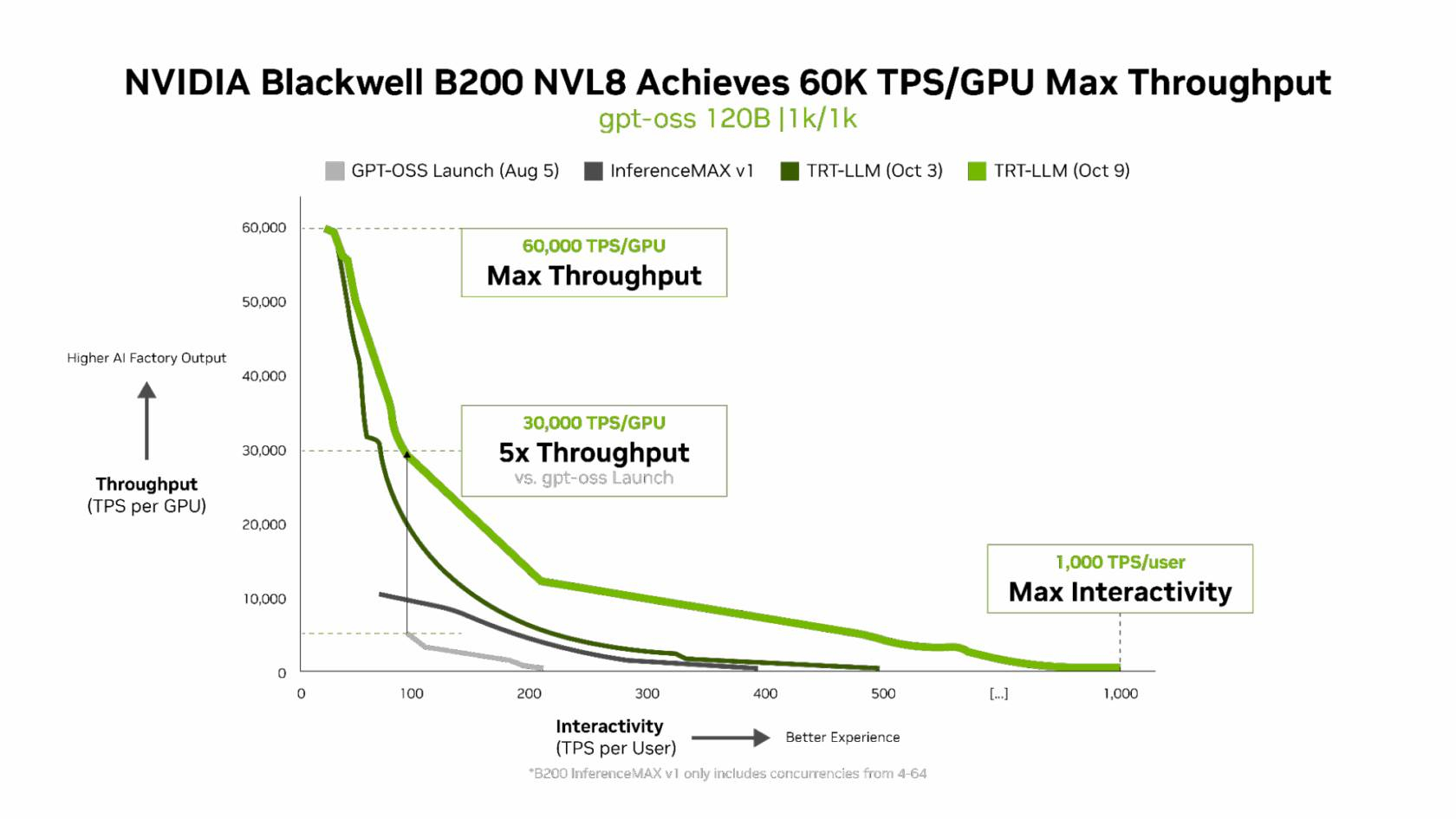 NVIDIA подчеркнула, что такие показатели, как количество токенов на Вт, стоимость на миллион токенов и TPS/пользователь не уступают по важности пропускной способности. Фактически, для ИИ-фабрик с ограниченной мощностью ускорители с архитектурой Blackwell обеспечивают до 10 раз лучшую производительность на МВт по сравнению с предыдущим поколением и позволяют получать более высокий доход от токенов. 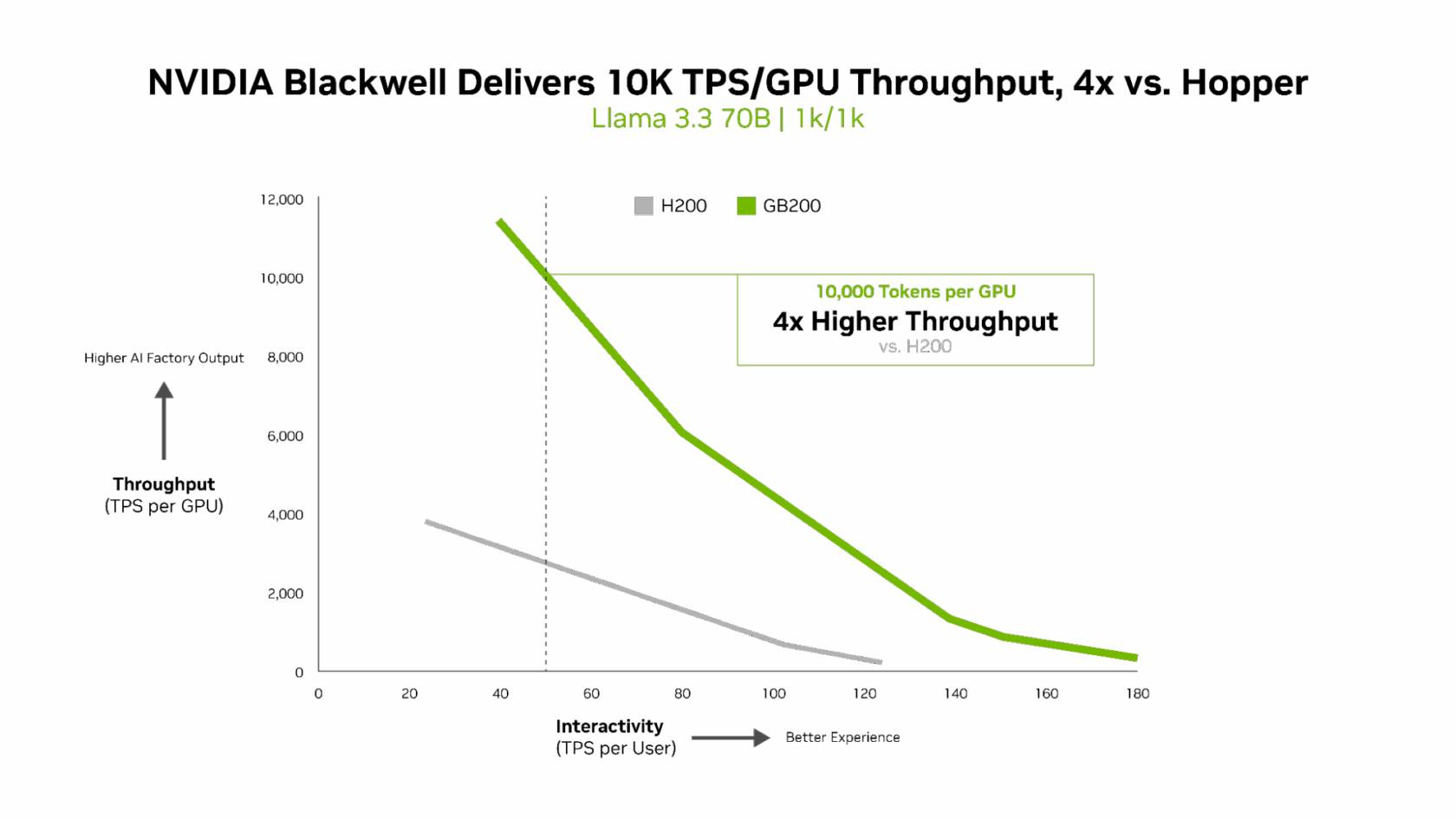 Компания отметила, что стоимость обработки одного токена (Cost per Token) имеет решающее значение для оценки эффективности ИИ-модели и напрямую влияет на эксплуатационные расходы. NVIDIA утверждает, что в целом архитектура NVIDIA Blackwell позволила снизить стоимость обработки миллиона токенов в 15 раз по сравнению с предыдущим поколением. 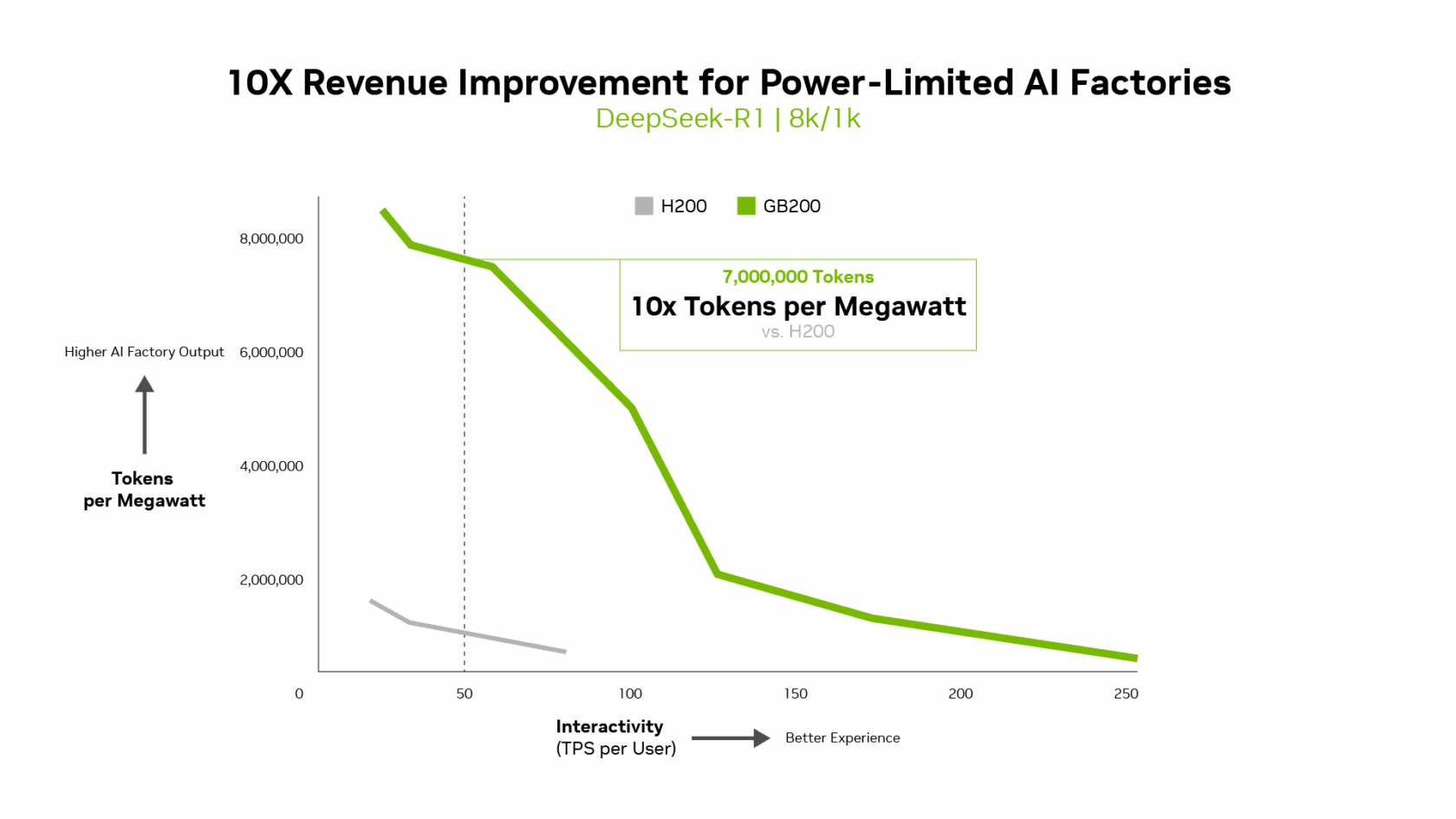 В InferenceMAX используется метод оценки эффективности Pareto front, определяющий наилучшее (компромиссное) сочетание различных факторов для оценки производительности ускорителя. Это показывает, насколько Blackwell лучше конкурентов справляется с балансом стоимости, энергоэффективности, пропускной способности и скорости отклика. Системы, оптимизированные только для одной метрики, могут демонстрировать пиковую производительность «в вакууме», но такая «экономика» не масштабируется в производственных средах. 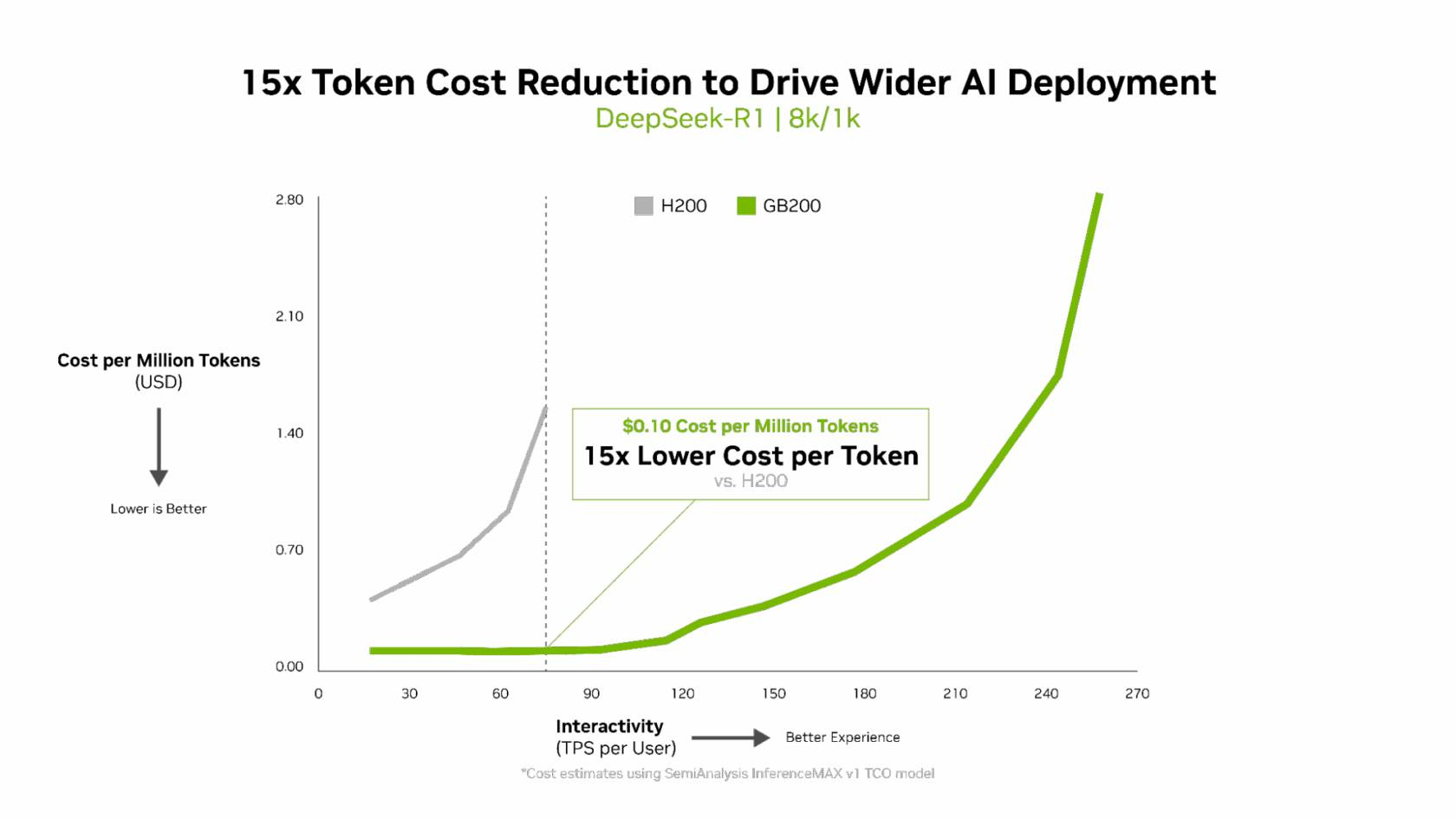 Компания отметила, что ИИ переходит от экспериментальных пилотных проектов к ИИ-фабрикам — инфраструктуре, которая производит интеллектуальные решения, преобразуя данные в токены и решения в режиме реального времени. Фреймворк NVIDIA Think SMART помогает предприятиям ориентироваться в этом переходе, демонстрируя, как полнофункциональная платформа инференса обеспечивает измеримую окупаемость инвестиций. Обещая 15-кратную окупаемость инвестиций и непрерывный рост производительности за счёт ПО, NVIDIA не просто лидирует в текущей гонке ИИ-технологий, но и задаёт правила для следующего этапа, где экономика будет определять победителей рынка, пишет The Tech Buzz. Для предприятий, делающих ставку на конкурирующие платформы в своих стратегиях по развёртыванию ИИ, результаты таких бенчмарков должны побудить к пересмотру выбора ИИ-инфраструктуры.
12.10.2025 [14:51], Сергей Карасёв
Graphcore, спасённая SoftBank, воспрянула духом — штат в Великобритании удвоится, а в разработку в Индии инвестируют $1 млрдБританский стартап Graphcore, занимающийся созданием специализированных ИИ-ускорителей, по сообщению Datacenter Dynamics, намерен инвестировать в Индии до $1 млрд в течение следующих 10 лет. При этом в Бангалоре на юге страны будет сформирован кампус для разработки ИИ-решений. Компания Graphcore, основанная в Бристоле в 2016 году, проектирует ускорители нового класса под названием Intelligence Processing Unit (IPU). Архитектура таких изделий основана на применении особых «тайлов» — это область кристалла, содержащая вычислительную логику и некоторое количество быстрой памяти. В июле прошлого года фирму Graphcore за неназванную сумму приобрела японская холдинговая корпорация SoftBank Group, которая активно развивает направление ИИ. Как отмечает Graphcore, на базе нового ИИ-кампуса в Индии будут сформированы около 500 новых рабочих мест. Планируется привлекать специалистов в области проектирования логических схем, дизайна, тестирования и пр. Инженеры Graphcore в Бангалоре займутся разработкой передовых ИИ-решений, которые в перспективе помогут в решении глобальных проблем в области общественного здравоохранения, экологической устойчивости и пр. 
Источник изображения: Graphcore Говорится, что с 2015 года SoftBank Group инвестировала в различные инициативы в Индии более $12 млрд. Создаваемая в Бангалоре площадка будет способствовать реализации комплексной стратегии SoftBank Group по трансформации в ведущего мирового поставщика ИИ-платформ. Напомним, японская корпорация участвует в масштабном проекте Stargate по развитию ИИ-инфраструктуры в США: предполагается, что суммарные затраты в рамках данной инициативы достигнут $500 млрд. Между тем Graphcore заявила о намерении увеличить численность персонала. Ожидается, что в ближайшие два года количество сотрудников в британском представительстве вырастет примерно вдвое, достигнув 750 человек. Речь идёт о привлечении разработчиков чипов и ПО, а также специалистов в сфере ИИ. При этом два года назад состояние компании было не лучшим. Из-за проблем с финансами она закрыла офис в Китае, свернула операции в Норвегии, Японии и Южной Корее, а также сократила пятую часть штата.
11.10.2025 [11:45], Сергей Карасёв
Молдова стала участником европейской суперкомпьютерной программы EuroHPC JUЕвропейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) объявило о том, что Молдова стала 37-м государством, присоединившимся к данному проекту. Решение принято в ходе очередного заседания Совета управляющих EuroHPC JU. Отмечается, что с января 2012 года Молдова активно участвует в инициативах Европейского союза по исследованиям и инновациям. В частности, в рамках программы Horizon 2020 специалистам из академических кругов, исследовательских институтов, органов государственной власти и индустриального сектора Молдовы предоставляется доступ к суперкомпьютерам EuroHPC. 
Источник изображения: EuroHPC JU Теперь Молдова стала полноправным участником EuroHPC: ожидается, что это позволит укрепить взаимодействие между страной и другими европейскими исследователями. В частности, молдавские ученые смогут подавать заявки на исследовательские и инновационные инициативы EuroHPC JU, финансируемые по программе Horizon Europe. Речь идёт о разработке суперкомпьютерных технологий и сопутствующих программных продуктов. Кроме того, Молдова сможет принять участие в запуске фабрик ИИ (EuroHPC AI Factories), которые формируются по всей Европе. Эти площадки призваны помочь в создании высококонкурентной и инновационной европейской экосистемы ИИ. Молдова присоединилась к другим государствам — участникам программы EuroHPC JU, которые не являются членами Евросоюза. В их число также входят Албания, Исландия, Израиль, Черногория, Северная Македония, Норвегия, Сербия, Турция и Великобритания. Эти страны сотрудничают с ЕС с целью достижения стратегической независимости в области HPC, ИИ, квантовых вычислений и суперкомпьютерных технологий. В настоящее время EuroHPC JU курирует реализацию 13 проектов по созданию фабрик ИИ. Недавно при участии EuroHPC JU был официально введён в эксплуатацию первый в Европе суперкомпьютер экзафлопсного класса — система JUPITER (Joint Undertaking Pioneer for Innovative and Transformative Exascale Research), которая размещена в Юлихском исследовательском центре (FZJ) в Германии. EuroHPC JU также разворачивает европейскую инфраструктуру квантовых вычислений, интегрируя квантовые технологии с существующими суперкомпьютерами.
11.10.2025 [11:42], Сергей Карасёв
OpenAI создаст в Аргентине кампус Stargate мощностью 500 МВтOpenAI и энергетическая компания Sur Energy, по сообщению Reuters, подписали соглашение о сотрудничестве, которое предусматривает строительство в Аргентине масштабного кампуса дата-центров для задач ИИ. Проект будет реализован в рамках инициативы Stargate. Напомним, что Stargate — это совместное предприятие OpenAI, SoftBank и Oracle по развитию ИИ-инфраструктуры в США: ожидается, что суммарные затраты на реализацию проекта достигнут $500 млрд. При этом также планируется строительство площадок Stargate в других странах в рамках инициативы OpenAI for Countries. Комплекс ЦОД, созданием которого займутся OpenAI и Sur Energy, станет первым объектом Stargate в Латинской Америке. Речь идёт о строительстве кампуса мощностью до 500 МВт. Суммарные затраты на создание объекта могут составить до $25 млрд. Ожидается, что это будет одна из крупнейших инвестиций в технологическую и энергетическую инфраструктуру в истории Аргентины. Финансирование проекта будет осуществляться через совместное предприятие Sur Energy и неназванного международного разработчика облачных систем. При этом OpenAI выступит в качестве потребителя вычислительных мощностей дата-центра после его ввода в эксплуатацию. 
Источник изображения: OpenAI «Мы с гордостью объявляем о планах запуска Stargate Argentina — нового инфраструктурного проекта в партнёрстве с одной из ведущих энергетических компаний страны, Sur Energy», — заявил генеральный директор OpenAI Сэм Альтман (Sam Altman). Ранее OpenAI анонсировала проект Stargate Norway — первый в Европе дата-центр, создающийся в рамках программы OpenAI for Countries: объект мощностью 230 МВт расположится в Норвегии. Кроме того, OpenAI построит ИИ ЦОД Stargate в Южной Корее. В начале сентября стало известно о том, что компания Альтмана рассчитывает построить в Индии дата-центр мощностью не менее 1 ГВт. А крупнейший кампус Stargate будет создан в ОАЭ, если, конечно, опять не появятся проблемы с поставками ускорителей NVIDIA. Вместе с тем недавно в США заработали первые ИИ ЦОД флагманского кампуса OpenAI Stargate.
10.10.2025 [17:37], Руслан Авдеев
Подобранные ИИ бактерии спасут ЦОД от дефицита медиПричиной следующего экзистенциального кризиса интернета, похоже, станут не дезинформация и не дипфейки. По словам основателя стартапа Endolith Лиз Деннетт (Liz Dennett), индустрия ЦОД остро нуждается в меди, для которой найден обновлённый способ добычи, сообщает IEEE Spectrum. Вся современная IT-инфраструктура зависит от меди. Создание ИИ ЦОД лишь ускоряет рост спроса, поскольку для одного дата-центра гиперскейл-уровня требуется более 2 тыс. т меди или около 27 т/МВт. McKinsey прогнозирует, что только развитие линий электропередачи может привести к росту годового спроса на медь в мире до 37 млн т к 2031 году. Хуже того, запасы доступной меди истощаются — более 70 % мировых резервов находятся в рудах, трудно поддающихся обработке, а это десятки миллиардов тонн. При этом потенциал таких «непривлекательных» запасов огромен. В 2023 году Деннетт основала стартап Endolith для извлечения меди из нерентабельных ныне источников. Помогут в этом микроорганизмы. Эволюционировавшие естественным путём бактерии оказались довольно эффективны для добычи меди из «сложных» руд вроде халькопирита и энаргита. При этом они хорошо переносят воздействие неблагоприятной среды, и при добыче меди с их помощью потребуется меньше энергии, чем при использовании традиционных методов вроде высокотемпературной плавки или химического выщелачивания, оставляющих после себя большое количество отходов. 
Источник изображения: Endolith Бактерии ускоряют естественный процесс биовыщелачивания. Микроорганизмы можно подобрать к химическому составу разных пород, что позволит извлекать больше металла и окажет меньшее влияние на окружающую среду. Для этого используется ИИ. Свойства тысяч микробов учитываются при моделировании процессов получения меди. Это позволяет прогнозировать, какие штаммы оптимально подойдут для тех или иных условий, не полагаясь на медленный метод проб и ошибок. Технологию уже изучают некоторые крупные производители меди, включая BHP. Разрабатываемые Endolith «биоинкубаторы» представляют собой полевые установки для выращивания и доставки специально подобранных микроорганизмов. Они могут быть развёрнуты за считанные дни и адаптированы под местные условия. Скептики отмечают, что биовыщелачивание — технология довольно старая и исторически малопригодная для работы с рудами вроде халькопирита. О том, что развитие рынка ИИ со многом зависит от наличия чистой меди, говорилось ещё в конце 2024 года. Более того, есть и ещё один источник металла, который поможет справиться с дефицитом. В январе 2025 года сообщалось, что телеком-компании смогут заработать миллиарды долларов, сдав в переработку старые медные кабели.
10.10.2025 [16:34], Руслан Авдеев
Google вложит €5 млрд в ИИ и облако в БельгииВ следующие два года Google намерена потратить дополнительные €5 млрд ($5,8 млрд) в облачную и ИИ-инфраструктуру Бельгии. Инвестиции пойдут на расширение ЦОД в Сен-Гислене (Saint-Ghislain) и позволят создать ещё 300 постоянных рабочих мест, сообщает Datacenter Dynamics. Дополнительно компания намерена объединить усилия с Eneco, Luminous и Renner для строительства наземных ветряных электростанций. Google намерена укрепить свои позиции в Бельгии, поэтому расширяет инвестиции и создаёт новые возможности для преобразований страны с помощью ИИ. О проекте упомянул и премьер-министр страны Барт де Вевер (Bart Albert Liliane De Wever), заявив, что инвестиции Google — весомый символ доверия к Бельгии как к центру цифровых инноваций и устойчивого развития. По его словам, расширяя передовую облачную и ИИ-инфраструктуру в стране, создавая рабочие места для квалифицированных сотрудников и новые источники безуглеродной энергии, Бельгия укрепляет собственную экономику и ускоряет переход на возобновляемую энергию. Проект имеет для неё и стратегическое значение, позволяя укрепиться в роли лидера в формировании цифрового будущего Европы. 
Источник изображения: Google В 2009 году Google впервые открыла дата-центр в Бельгии, там расположен облачный регион компании Europe-west1. Кампус в Сен-Гислене — первый кампус Google в Европе, неоднократно расширявшийся. По состоянию на апрель 2024 года он занимал территорию 90 га, где размещалось пять ЦОД и солнечная электростанция. Также она строит кампус в Фарсьене (Farciennes, провинция Эно), проект стартовал в апреле 2024 года. По информации Google, с 2007 года гиперскейлер уже инвестировал более €5 млрд в инфраструктуру ЦОД в Бельгии. AWS управляет локальной зоной доступности в Брюсселе, но не имеет облачного региона в стране. Microsoft управляет облачным регионом в Бельгии, получившим название belgiumcentral. Впрочем, приоритетными для Google и других компаний остаются США. Только на ИИ и облачную инфраструктуру в Оклахоме Google готова потратить $9 млрд, не считая других проектов. |
|