Материалы по тегу: hpc
|
07.03.2025 [15:36], Сергей Карасёв
Стартап Axelera AI анонсировал ИИ-ускоритель TitaniaНидерландский стартап Axelera AI B.V., специализирующийся на разработке ИИ-ускорителей, анонсировал решение Titania — высокопроизводительный, энергоэффективный и масштабируемый чиплет для задач инференса. Полностью технические характеристики изделия пока не раскрываются. Известно, что Titania использует проприетарную модель вычислений в памяти Digital In-Memory Computing (D-IMC). Этот подход, как заявляет Axelera AI, обеспечивает ИИ-производительность свыше 50 TOPS на ядро (эквивалентная точность FP32) и энергоэффективность на уровне 15 TOPS на 1 Вт затрачиваемой энергии. Решение Titania базируется на открытой архитектуре RISC-V. Несколько чиплетов могут быть объединены в виде модуля SiP (System-in-Package). Использование D-IMC обеспечивает практически линейную масштабируемость производительности без значительного увеличения затрат на питание и охлаждение. В качестве потенциальных областей применения Titania названы НРС-платформы, корпоративные дата-центры, робототехника, автомобилестроение и пр. 
Источник изображения: Axelera AI Одновременно с анонсом Titania стартап Axelera AI объявил о привлечении до €61,6 млн от EuroHPC JU в рамках проекта Digital Autonomy with RISC-V for Europe (DARE). Компания Axelera AI будет поддерживать EuroHPC в области разработки суперкомпьютерной экосистемы мирового класса в Европе. В частности, стартап планирует расширять свои научно-исследовательские и опытно-конструкторские подразделения в Нидерландах, Италии и Бельгии. Отмечается также, что основанная в 2021 году компания Axelera AI за три года существования получила инвестиции на общую сумму более $200 млн.
12.02.2025 [23:28], Руслан Авдеев
Евросоюз направит €200 млрд на развитие ИИ, чтобы не отстать от США и Китая в этой сфереЕвросоюз объявил о намерении направить €200 млрд (около $206 млрд) на развитие ИИ в рамках инициативы InvestAI — это, как ожидается, позволит конкурировать с США и Китаем на рынке систем искусственного интеллекта, сообщает The Verge. По словам главы Еврокомиссии Урсулы фон дер Ляйен (Ursula von der Leyen), €50 млрд (около $51 млрд) будет выделено надгосударственными структурами союза, ещё €150 млрд (около $154 млрд) потратит группа частных инвесторов European AI Champions Initiative. По её мнению, Европа должна стать одним из ведущих «ИИ-континентов», а это значит, что необходимо принять образ жизни, где ИИ используется повсюду. Чиновница не согласилась с утверждениями, что Европа «опоздала» к гонке между США и Китаем — она уверена, что гонка далека от завершения. По словам фон дер Ляйен, инициатива InvestAI на €200 млрд поможет ускорить строительство в ЕС «гигафабрик», необходимых для обучения сложных моделей непосредственно в Европе. Как отмечает Euronews, ещё в декабре прошлого года в рамках EuroHPC было объявлено о строительстве семи первых «гигафабрик», а вскоре будет объявлено о ещё пяти. Они получат порядка 100 тыс. самых современных ускорителей. Это примерно вчетверо больше, чем у ИИ-фабрик, строящихся сегодня. Основная цель — обеспечить доступ к высокопроизводительным вычислениям даже мелким компаниям. 
Источник изображения: Anthony DELANOIX/unsplash.com Из €200 млрд на строительство «гигафабрик» выделят €20 млрд. По словам руководства ЕС, «гигафабрики», финансируемые в рамках InvestAI, должна стать крупнейшими в мире государственно-частными партнёрствами по разработке надёжных решений в сфере искусственного интеллекта. Изначально средства для InvestAI будут поступать от действующих программ с «цифровым» компонентом, вроде Horizon Europe и InvestEU. Вклад могут внести и государства — члены Евросоюза. Примечательно, что в понедельник президент Франции Эммануэль Макрон (Emmanuel Macron) объявил об инвестициях в одни только французские ИИ-проекты €109 млрд (около $112 млрд). Он отметил, что эти проекты смогут составить конкуренцию американскому $500-млрд проекту Stargate, на них Франция сразу выделит гигаватт атомной энергии. Кроме того, вложиться во французские ЦОД обещали и представители ОАЭ. Евросоюз стал одним из первых мировых игроков, принявших всеобъемлющие правила для рынка ИИ — «Закон об ИИ» был подписан 2024 году. США раскритиковали эти нормы, назвав нормативную среду Евросоюза «авторитарной цензурой». За океаном считают, что чрезмерное регулирование способно буквально убить отрасль. Примечательно, что США и Великобритания отказались подписывать декларацию на Парижском ИИ-саммите, которая обязывает страны-участницы обеспечить «открытость, инклюзивность, прозрачность, этичность, безопасность, надежность» искусственного интеллекта и т. д.
12.02.2025 [00:50], Владимир Мироненко
AMD и французские атомщики вместе займутся развитием технологий для ИИ-инфраструктур будущегоAMD объявила о подписании соглашения о намерениях с французским Комиссариатом по атомной энергии и альтернативным источникам энергии (CEA) с целью совместной работы над созданием передовых технологий, компонентов и системных архитектур, которые определят будущее ИИ-вычислений. Сотрудничество позволит использовать сильные стороны обеих организаций в разработке энергоэффективных систем и технологий для вычислительной инфраструктуры следующего поколения, необходимых для поддержки самых ресурсоёмких в мире рабочих ИИ-нагрузок в различных областях — от энергетики до медицины. AMD и CEA планируют провести в 2025 году симпозиум, посвящённый будущему ИИ-вычислений, который соберёт европейских и глобальных разработчиков технологий, стартапы, суперкомпьютерные центры, университеты и политиков с целью укрепления сотрудничества в разработке современных вычислительных технологий ИИ. В CEA отметили, что сотрудничество с AMD является значительным шагом на пути к укреплению международного партнёрства в области HPC, позволяя объединить экспертные знания мирового уровня для удовлетворения растущих потребностей в обслуживании ИИ-нагрузок. В свою очередь, в AMD подчеркнули, что в сотрудничестве с CEA и ведущими французскими инженерами компания стремится приблизить передовые исследования в области ИИ к реальным приложениям, развивая системные архитектуры, которые отвечают требованиям будущих рабочих нагрузок, одновременно расширяя возможности для совместных исследований и разработок США и Франции. 
Источник изображения: AMD Большая часть электроэнергии во Франции производится АЭС, что позволяет обеспечивать внутренние потребности, а также поставлять излишки за рубеж. Франция рассматривает это как ключевой фактор для привлечения инвесторов, стремящихся развивать инфраструктуру энергоёмких ЦОД в стране. По словам президента Франции Эммануэля Макрона (Emmanuel Macron), это позволит разместить в стране 20 % всех ЦОД в мире. В понедельник Макрон объявил, что объём частных инвестиций в ИИ-сектор страны составит в ближайшие несколько лет около €109 млрд.
11.02.2025 [16:24], Владимир Мироненко
ИИ ЦОД за 20 недель: G42 и DataOne построят крупнейший во Франции суперкомьютер на чипах AMD InstinctХолдинг G42 из Абу-Даби (ОАЭ) объявил о стратегических инвестициях во Франции в партнёрстве с недавно образованной DataOne, которая сама себя называет первым в Европе оператором гига-ЦОД для ИИ. Вместе компании в кратчайшие сроки построят в Гренобле ИИ ЦОД, оснащённый ускорителями AMD Instinct. Ожидается, что объект будет полностью введён в эксплуатацию к середине 2025 года. Вычислительные возможности нового ЦОД позволят французским компаниям и учёным разрабатывать передовые модели ИИ, агентов и приложения, а также проводить различные исследования. Реализацией проекта будет заниматься компания Core42, дочернее предприятие G42, совместно с DataOne. По словам главы DataOne Шарля-Антуана Бейни (Charles-Antoine Beyney), на развёртывание крупнейшего ИИ-суперкомпьютера в Европе потребуется всего 20 недель. Для сравнения: кластер xAI Colossus был построен за 122 дня. Как заявила Лиза Су (Lisa Su), председатель и генеральный директор AMD, стратегическое сотрудничество с G42 поможет активизировать французскую экосистему ИИ, предоставив вычислительную мощность, необходимую для поддержки местных стартапов и новаторов, занимающихся передовыми разработками, которые укрепляют французскую экономику. «Работа с G42 является ещё одним примером нашей приверженности объединению открытых экосистем с ведущими в отрасли технологиями ИИ AMD, что обеспечивает возможность государственным учреждениям и частным предприятиям использовать весь потенциал ИИ», — подчеркнула Лиза Су. 
Источник изображения: AMD Инвестиции G42 входят в пакет частных инвестиций в ИИ-инфраструктуру страны на €109 млрд, анонсированный президентом Франции Эммануэле Макроном (Emmanuel Macron) в качестве ответа на представленный в США проект Stargate. Ранее было объявлено о планах ОАЭ вложить при участии фонда MGX €30–50 млрд в проект по созданию кампуса ИИ ЦОД во Франции. В G42 называют инвестиции в ИИ одним из главных направлений своей деятельности. Деятельность холдинга получила поддержку Microsoft, инвестировавшей в него $1,5 млрд. В прошлом году G42 договорился с Cerebras о строительстве в Техасе ИИ-суперкомпьютера со 173 млн ядер.
31.01.2025 [07:02], Сергей Карасёв
Tesla наращивает вычислительные мощности для обучения человекоподобного робота OptimusГлава Tesla Илон Маск (Elon Musk) сообщил о том, что компания расширяет вычислительную инфраструктуру, необходимую для обучения человекоподобного робота Optimus. По словам Маска, в долгосрочной перспективе этот проект может принести более $10 трлн. Предполагается, что антропоморфные машины Optimus смогут выполнять самые разные задачи в быту и на производствах, взаимодействия с людьми. Но для разработки ИИ-систем робота требуются огромные вычислительные ресурсы. Маск подчёркивает, что обучение такой машины — гораздо более сложная задача, нежели обучение интеллектуальных автомобилей с автопилотом. Глава Tesla говорит, что у человекоподобного робота, вероятно, в 1000 раз больше функций, чем у транспортного средства. Это не означает, что обучение масштабируется в 1000 раз, но прирост вычислительных мощностей на порядок всё же необходим. «Потребности в обучении для гуманоидного робота Optimus, по всей видимости, как минимум в 10 раз превышают то, что требуется для создания полнофункционального умного автомобиля», — заявил Маск. 
Источник изображения: channeliam.com Он не стал вдаваться в подробности о том, какая инфраструктура нужна компании для обучения Optimus. Ранее сообщалось, что Tesla планирует ввести в эксплуатацию дата-центр с 50 тыс. ускорителей NVIDIA H100. Кроме того, у компании есть кластер Dojo на базе собственных ускорителей D1. Маск говорит, что с учётом потенциала проекта Optimus даже инвестиции в размере $500 млрд в вычислительные ресурсы могут быть оправданными, хотя такую сумму Tesla на текущем этапе вкладывать не планирует. Вероятно, указанная сумма — это отсылка к проекту Stargate. Tesla потратила более $10 млрд на капитальные затраты в 2024 году. Примерно столько же средств компания намерена выделить в 2025 и 2026 годах. Ранее Маск говорил, что небольшое количество роботов Optimus будет задействовано на предприятиях Tesla до конца 2024-го. На коммерческом рынке эти человекоподобные машины, как ожидается, появятся в 2026 году.
30.01.2025 [08:58], Владимир Мироненко
Суперкомпьютер Aurora стал доступен исследователям со всего мираАргоннская национальная лаборатория (ANL) Министерства энергетики США объявила о доступности суперкомпьютера Aurora экзафлопсного класса для исследователей по всему миру. Как указано в пресс-релизе, благодаря широким возможностям моделирования, ИИ и анализа данных, Aurora будет способствовать прорывам в целом ряде областей, включая проектирование самолётов, космологию, разработку лекарств и исследования в сфере ядерной энергетики. Майкл Папка (Michael Papka), директор Argonne Leadership Computing Facility (ALCF), вычислительного центра Управления науки Министерства энергетики США, отметил, что уже первые проекты с использованием Aurora продемонстрировали его огромным потенциал. «С нетерпением ждём, как более широкое научное сообщество будет использовать систему для преобразования своих исследований», — заявил он. Aurora уже зарекомендовала себя как один мировых лидеров по производительности ИИ, заняв первое место в бенчмарке HPL-MxP в ноябре 2024 года, отметила ANL. Возможности машины для выполнения ИИ-задач используются учёными для открытия новых материалов для аккумуляторов, разработки новых лекарств и ускорения исследований в области термоядерной энергии. Перед его развёртыванием команда под руководством ANL продемонстрировала потенциал Aurora, используя его для обучения моделей ИИ для моделирования белков. 
Источник изображения: ANL В числе первых проектов, реализуемых с помощь Aurora, — разработка высокоточных моделей сложных систем, таких как кровеносная система человека, ядерные реакторы и сверхновые звезды. Кроме того, способность суперкомпьютера к обработке огромных наборов данных имеет решающее значение для анализа растущих потоков данных из крупных исследовательских установок, таких как Усовершенствованный источник фотонов (APS) Аргоннской национальной лаборатории, научные объекты Управления науки Министерства энергетики США (DoE) и Большой адронный коллайдер Европейской организации ядерных исследований (CERN). Чтобы гарантировать готовность Aurora к использованию для научных исследования с первого дня запуска, при его создании применили так называемое совместное проектирование. Используя этот подход, команда Aurora разработала в тандеме аппаратное и программное обеспечение для оптимизации производительности и удобства использования. Это потребовало многолетнего сотрудничества между ALCF, Intel, HPE и исследователями по всей стране, участвующими в проекте Exascale Computing Project (ECP) Министерства энергетики США и программе Aurora Early Science Program (ESP) центра. Пока велись работы по монтажу Aurora, команды ECP и ESP запускали приложения для стресс-тестирования оборудования, одновременно оптимизируя свой код для максимально эффективной работы в системе. В результате десятки научных приложений, а также широкий спектр ПО и инструментов разработки были готовы ещё до того, как Aurora ввели в строй, говорится в пресс-релизе.
19.01.2025 [22:43], Сергей Карасёв
Германия запустила «переходный» 48-Пфлопс суперкомпьютер Hunter на базе AMD Instinct MI300AЦентр высокопроизводительных вычислений HLRS при Штутгартском университете в Германии объявил о вводе в эксплуатацию НРС-системы Hunter. Этот суперкомпьютер планируется использовать для решения широко спектра задач в области инженерии, моделирования погоды и климата, биомедицинских исследований, материаловедения и пр. Кроме того, комплекс будет применяться для крупномасштабного моделирования, ИИ-приложений и анализа данных. О создании Hunter сообщалось в конце 2023 года: соглашение на строительство системы стоимостью примерно €15 млн было заключено с HPE. Проект финансируется Федеральным министерством образования и исследований Германии и Министерством науки, исследований и искусств Баден-Вюртемберга. Hunter базируется на той же архитектуре, что El Capitan — самый мощный в мире суперкомпьютер. Задействована платформа Cray EX4000, а каждый из узлов оснащён четырьмя адаптерами HPE Slingshot. Суперкомпьютер использует комбинацию из APU Instinct MI300A и процессоров EPYC Genoa. Как отмечает The Register, в общей сложности система объединяет 188 узлов с жидкостным охлаждением и насчитывает суммарно 752 APU и 512 чипов Epyc с 32 ядрами. Применена СХД HPE Cray Supercomputing Storage Systems E2000, специально разработанная для суперкомпьютеров HPE Cray. 
Источник изображения: HLRS HLRS оценивает пиковую теоретическую FP64-производительность Hunter в 48,1 Пфлопс на операциях двойной точности, что практически вдвое выше, чем у предшественника Hawk. В режимах BF16 и FP8 быстродействие, как ожидается, будет варьироваться от 736 Пфлопс до 1,47 Эфлопс. При этом Hunter потребляет на 80% меньше энергии, нежели Hawk. 
Источник изображения: Штутгартский университет Отмечается, что Hunter задуман как переходная система, которая подготовит почву для суперкомпьютера HLRS следующего поколения под названием Herder. Ввести этот комплекс в эксплуатацию планируется в 2027 году. Предполагается, что он обеспечит производительность «в несколько сотен петафлопс».
17.01.2025 [22:46], Руслан Авдеев
Aligned Data Centers получила $12 млрд на расширение парка ИИ ЦОДТехасский оператор ЦОД Aligned Data Centers объявил о привлечении $12 млрд на постройку ИИ ЦОД мощностью 5 ГВт в Северной и Южной Америках. $5 млрд поступило в виде акционерного капитала из фондов, подконтрольных Macquarie Asset Management, ещё $7 млрд — в виде долговых обязательств, сообщает SiliconAngle. В Aligned заявляют, что у неё уникальное положение на рынке — у компании более 10 лет опыта в создании систем охлаждения энергоёмких дата-центров. Последнее поколение фирменных СЖО DeltaFlow~ позволяет повысить плотность размещения ресурсов до 300 кВт на стойку. Также компания разработала систему воздушного охлаждения Delta3 (Delta Cube). Aligned Data Centers управляет многочисленными колокейшн-объектами. Также она строит дата-центры для гиперскейлеров и корпоративных клиентов. В США компания управляет объектами в Чикаго, Далласе, Финиксе, Солт-Лейк-Сити и Северной Вирджинии. Новые площадки строятся в Вирджинии, Иллинойсе, Мэриленде и Огайо. В мае 2024 года Aligned купила бразильского оператора ЦОД OData, у которого уже были объекты в Бразилии, Чили, Мексике и Колумбии. Наконец, компания инвестировала в канадского оператора QScale SEC. 
Источник изображения: Aligned Data Centers Быстрый рост ИИ в последние годы вызвал и рост спроса на высокопроизводительные дата-центры, способные вместить тысячи ускорителей одновременно. В результате бизнес Aligned значительно вырос. Упомянутая австралийская Macquarie совсем недавно сообщила, что выделит до $5 млрд на ИИ ЦОД Applied Digital — ещё одного американского оператора дата-центров.
17.01.2025 [01:07], Алексей Степин
США готовятся к созданию суперкомпьютера нового поколения с 10 Пбайт RAMСуперкомпьютеру Crossroads (ATS-3), расположенному в Лос-Аламосской национальной лаборатории (LANL) Министерства энергетики США (DoE), не так уж много лет. Система мощностью 30 Пфлопс запущена в 2023 году, но ей уже готовится замена в лице суперкомпьютера нового поколения под кодовым названием ATS-5. Министерство энергетики совместно с Национальным управлением по ядерной безопасности (NNSA) раскрыли некоторые детали, касающиеся этого проекта. Главной задачей ATS-5 станет запуск высокоточных 3D-симуляций для оценки перспектив модернизации и поддержания в актуальном состоянии ядерного арсенала США. Симуляции со столь высокой детализацией очень сложны и относятся к классу «геройских» (hero-class). Их прогон может занимать несколько месяцев, но ATS-5 должен не только сократить это время до дней, но и обеспечить обработку нескольких таких симуляций параллельно. 
Монтаж Crossroads. Источник здесь и далее LANL NNSA не сообщает о том, будет ли ATS-5 относится к системам экзафлопсного класса, но судя по употреблению термина «post-exascale system» и сложности планируемых для запуска симуляций, новый суперкомпьютер будет достаточно мощным. Известен уровень его энергопотребления — порядка 20 МВт. Для сравнения, Frontier (1,35 Эфлопс FP64) потребляет 21 МВт, а El Capitan (1,74 Эфлопс FP64) — около 30 МВт. По замыслу DoE, ATS-5 станет модульной системой со смешанной архитектурой, сфокусированной не только на HPC-задачах (FP64), но и на ИИ-сценариях с их упрощёнными форматами вычислений. Упор делается на размещении данных ближе к вычислительным узлам, увеличении объёмов памяти (в настоящее время заявлено 10,1 Пбайт) и ускорении её работы.  В качестве интерконнекта может быть применена смесь технологий InfiniBand и Ethernet, развивающая от 100 до 300 Гбайт/с в каждом направлении. Модульность означает возможность замены ускорителей и процессоров на протяжении всего срока эксплуатации ATS-5. Помимо ускорителей NVIDIA рассматривается возможность использования квантовых ускорителей, а также чипов Cerebras, Groq и SambaNova. ПО практически целиком должно быть open source, но и от CUDA при необходимости отказываться не будут. Министерство энергетики США надеется разместить контракт на постройку ATS-5 в мае текущего года. Поставки оборудования должны начаться в конце 2026 или начале 2027 гг, а ввод системы в строй намечен на август-сентябрь 2027 года. Тогда же будет выведен из строя Crossroads (ATS-3).
16.01.2025 [17:10], Руслан Авдеев
Австралийская Macquarie выделит до $5 млрд на ИИ ЦОД Applied DigitalВенчурные капиталисты пока не боятся возможного финансового «пузыря», связанного с ИИ-технологиями, поэтому вливают миллиарды долларов в новые ИИ ЦОД. Так, австралийская финансовая компания Macquarie сообщила о намерении вложить $5 млрд в проекты американского оператора дата-центров Applied Digital, сообщает The Register. Техасский оператор работает на рынке ИИ и HPC относительно недавно, но это не мешает ему на равных соперничать с сильными конкурентами с более богатой историей. Во многом история компания напоминает путь CoreWeave, вышедшей на рынок HPC-объектов приблизительно в 2022 году и свернувшей бизнес по майнингу криптовалют. Applied Digital, как и CoreWeave и Lambda Labs, предлагает услуги ЦОД и облачные сервисы на базе ускорителей NVIDIA. Австралийские инвестиции, в том числе в ходе начального раунда финансирования в объёме $900 млн, позволят компании продолжить работу над кампусом Ellendale High Performance Computing в Северной Дакоте мощностью 100 МВт (до 400 МВт в перспективе), а также вернуть порядка $300 млн, ранее инвестированных в объект в виде акционерного капитала. 
Источник изображений: Applied Digital Кампус в Эллендейле (Ellendale) — лишь одна из площадок Applied Digital, в которые Macquarie готова вложить средства. В соответствии с новым соглашением, она получила преимущественное право участвовать в новых проектах, связанных с ИИ ЦОД в следующие 30 месяцев на сумму $4,1 млрд. В Applied Digital заявляют, что с сегодняшними ценами на строительство у компании будет значительная часть средств, необходимых для создания HPC-объектов мощностью более 2 ГВт, включая кампус в Эллендейле. Место, по-видимому, привлекательное для таких объектов — две неизвестных компании готовы потратить до $250 млрд на строительство в штате гигаваттных ИИ ЦОД. Пока не сообщается, когда, где и сколько дата-центров Applied Digital в итоге построят, но, согласно пресс-релизу, объекты получат жидкостное охлаждение. Вероятнее всего, как и в Северной Дакоте, другие объекты получат ускорители NVIDIA. Не исключено даже использование 120-кВт GB200 NVL72. В сентябре NVIDIA вместе с другими инвесторами сама вложила в оператора $160 млн. Большая часть инвестиций, вероятно, вернётся в виде заказов на чипы и подписки AI Enterprise. Что касается Macquarie, она фактически выкупила себе 15 % в бизнесе Applied HPC, а оператор сохранил за собой 85 %. 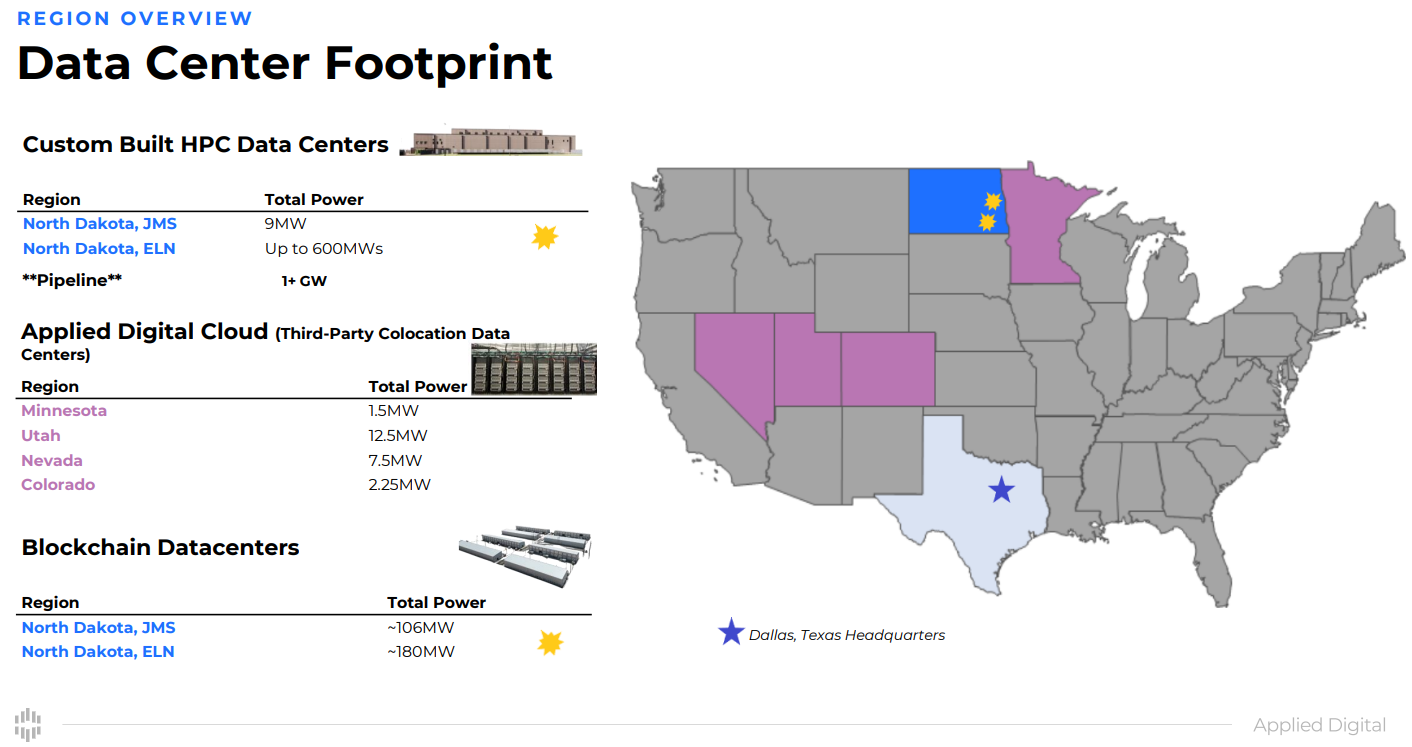 $1,5 млрд обычно достаточно для создания ЦОД с 16 тыс. ускорителей уровня NVIDIA H100 для последующей сдачи в аренду. В течение четырёх лет это принесёт около $5,27 млрд выручки при благоприятных условиях. С учётом уровня окупаемости инвестиций нетрудно понять, почему многие инвесторы желают участвовать в подобных проектах. Не мешает и высокий спрос на ускорители — иногда они используются в качестве залога при крупных кредитах. Так, в апреле 2024 года Macquarie помогла привлечь Lambda порядка $500 млн заёмного финансирования под залог ускорителей NVIDIA. Среди крупнейших бенефициаров таких сделок — CoreWeave, по данным Crunchbase, только в 2024 году получившая $9,9 млрд финансирования и заёмных средств. Деньги под залог ускорителей она брала ещё в 2023 году. |
|