Материалы по тегу: hgx
|
13.11.2023 [17:00], Игорь Осколков
NVIDIA анонсировала ускорители H200 и «фантастическую четвёрку» Quad GH200NVIDIA анонсировала ускорители H200 на базе всё той же архитектуры Hopper, что и их предшественники H100, представленные более полутора лет назад. Новый H200, по словам компании, первый в мире ускоритель, использующий память HBM3e. Вытеснит ли он H100 или останется промежуточным звеном эволюции решений NVIDIA, покажет время — H200 станет доступен во II квартале следующего года, но также в 2024-м должно появиться новое поколение ускорителей B100, которые будут производительнее H100 и H200. 
HGX H200 (Источник здесь и далее: NVIDIA) H200 получил 141 Гбайт памяти HBM3e с суммарной пропускной способностью 4,8 Тбайт/с. У H100 было 80 Гбайт HBM3, а ПСП составляла 3,35 Тбайт/с. Гибридные ускорители GH200, в состав которых входит H200, получат до 480 Гбайт LPDDR5x (512 Гбайт/с) и 144 Гбайт HBM3e (4,9 Тбайт/с). Впрочем, с GH200 есть некоторая неразбериха, поскольку в одном месте NVIDIA говорит о 141 Гбайт, а в другом — о 144 Гбайт HBM3e. Обновлённая версия GH200 станет массово доступна после выхода H200, а пока что NVIDIA будет поставлять оригинальный 96-Гбайт вариант с HBM3. Напомним, что грядущие конкурирующие AMD Instinct MI300X получат 192 Гбайт памяти HBM3 с ПСП 5,2 Тбайт/с.  На момент написания материала NVIDIA не раскрыла полные характеристики H200, но судя по всему, вычислительная часть H200 осталась такой же или почти такой же, как у H100. NVIDIA приводит FP8-производительность HGX-платформы с восемью ускорителями (есть и вариант с четырьмя), которая составляет 32 Пфлопс. То есть на каждый H200 приходится 4 Пфлопс, ровно столько же выдавал и H100. Тем не менее, польза от более быстрой и ёмкой памяти есть — в задачах инференса можно получить прирост в 1,6–1,9 раза.  При этом платы HGX H200 полностью совместимы с уже имеющимися на рынке платформами HGX H100 как механически, так и с точки зрения питания и теплоотвода. Это позволит очень быстро обновить предложения партнёрам компании: ASRock Rack, ASUS, Dell, Eviden, GIGABYTE, HPE, Lenovo, QCT, Supermicro, Wistron и Wiwynn. H200 также станут доступны в облаках. Первыми их получат AWS, Google Cloud Platform, Oracle Cloud, CoreWeave, Lambda и Vultr. Примечательно, что в списке нет Microsoft Azure, которая, похоже, уже страдает от недостатка H100.  GH200 уже доступны избранным в облаках Lamba Labs и Vultr, а в начале 2024 года они появятся у CoreWeave. До конца этого года поставки серверов с GH200 начнут ASRock Rack, ASUS, GIGABYTE и Ingrasys. В скором времени эти чипы также появятся в сервисе NVIDIA Launchpad, а вот про доступность там H200 компания пока ничего не говорит.  Одновременно NVIDIA представила и базовый «строительный блок» для суперкомпьютеров ближайшего будущего — плату Quad GH200 с четырьмя чипами GH200, где все ускорители связаны друг с другом посредством NVLink по схеме каждый-с-каждым. Суммарно плата несёт более 2 Тбайт памяти, 288 Arm-ядер и имеет FP8-производительность 16 Пфлопс. На базе Quad GH200 созданы узлы HPE Cray EX254n и Eviden Bull Sequana XH3000. До конца 2024 года суммарная ИИ-производительность систем с GH200, по оценкам NVIDIA, достигнет 200 Эфлопс.
24.05.2022 [07:00], Игорь Осколков
NVIDIA представила референсные платформы CGX, OVX и HGX на базе собственных Arm-процессоров GraceНа весенней конференции GTC 2022 NVIDIA поделилась подробностями о грядущих серверных Arm-процессорах Grace Superchip и гибридах Grace Hopper Superchip, а на Computex 2022 представила первые референсные платформы на базе этих чипов для OEM-производителей и объявила о расширении программы NVIDIA Certified. Последнее, впрочем, не означает отказ от x86-систем, поскольку программа будет просто расширена. Да и портирование стороннего и собственного ПО займёт некоторое время. Первые несколько десятков моделей серверов от ASUS, Foxconn, GIGABYTE, QCT, Supermicro и Wiwynn появятся в первой половине 2023 года. Представлены они будут в трёх категориях, причём все, за исключением одной, базируются на «сдвоенных» процессорах Grace Superchip, насчитывающих до 144 ядер. 
Источник: NVIDIA Системы серии OVX, представленной ранее, всё так же будут предназначены для цифровых двойников и Omniverse — NVIDIA продолжает наставить на том, что любое современное производство или промышленное предприятие должно быть интеллектуальным. Arm-версия OVA получит неназванные ускорители NVIDIA и DPU Bluefield-3. Новая платформа NVIDIA CGX очень похожа на OVX — она тоже получит DPU Bluefield-3 и до четырёх ускорителей NVIDIA A16. CGX создана специального для облачных гейминга и работы с графикой. А вот новое поколение платформы NVIDIA HGX гораздо интереснее. Оно заметно отличается от предыдущих, которые в основном представляли собой различные комбинации базовых плат NVIDIA с четырьмя или восемью ускорителями, вокруг которых OEM-партнёры строили системы в меру своих умений и фантазий. Нынешняя инкарнация NVIDIA HGX всё же несколько более комплексная, поскольку сейчас предлагается два варианта узлов, специально спроектированных для высокоплотных систем и явно ориентированных на высокопроизводительные вычисления (HPC). 
Источник: NVIDIA Первый вариант — это 1U-лезвие (до 84 шт. в стандартной стойке), которое включает один процессор Grace Superchip, до 1 Тбайт LPDDR5x-памяти с пропускной способностью (ПСП) до 1 Тбайт/с и DPU BlueField-3. Иные варианты сетевого подключения оставлены на усмотрение конечного производителя. Заявленный уровень TDP составляет 500 Вт, так что на выбор доступны системы с воздушным и жидкостным охлаждением. Второй вариант базируется на гибридных чипах Grace Hopper Superchip, объединяющих в себе посредством шины NVLink-C2C процессорную часть с 512 Гбайт LPDDR5x-памяти и ускоритель NVIDIA H100 c 80 Гбайт HBM3-памяти (ПСП до 3,5 Тбайт/с). Помимо DPU BlueField-3 опционально доступен и интерконнект NVLink 4.0, но и здесь вендору оставлена свобода выбора. Уровень TDP для данной платформы составляет 1 кВт, но вот обойтись одним только воздушным охлаждением (а такой вариант есть) при полном заполнении стойки всеми 42-мя 2U-лезвиями будет трудно.
22.03.2022 [18:40], Игорь Осколков
NVIDIA анонсировала 4-нм ускорители Hopper H100 и самый быстрый в мире ИИ-суперкомпьютер EOS на базе DGX H100На GTC 2022 компания NVIDIA анонсировала ускорители H100 на базе новой архитектуры Hopper. Однако NVIDIA уже давно говорит о себе как создателе платформ, а не отдельных устройств, так что вместе с H100 были представлены серверные Arm-процессоры Grace, в том числе гибридные, а также сетевые решения и обновления наборов ПО. 
NVIDIA H100 (Изображения: NVIDIA) NVIDIA H100 использует мультичиповую 2.5D-компоновку CoWoS и содержит порядка 80 млрд транзисторов. Но нет, это не самый крупный чип компании на сегодняшний день. Кристаллы новинки изготавливаются по техпроцессу TSMC N4, а сопровождают их — впервые в мире, по словам NVIDIA — сборки памяти HBM3 суммарным объёмом 80 Гбайт. Объём памяти по сравнению с A100 не вырос, зато в полтора раза увеличилась её скорость — до рекордных 3 Тбайт/с. 
NVIDIA H100 (SXM) Подробности об архитектуре Hopper будут представлены чуть позже. Пока что NVIDIA поделилась некоторыми сведениями об особенностях новых чипов. Помимо прироста производительности от трёх (для FP64/FP16/TF32) до шести (FP8) раз в сравнении с A100 в Hopper появилась поддержка формата FP8 и движок Transformer Engine. Именно они важны для достижения высокой производительности, поскольку само по себе четвёртое поколение ядер Tensor Core стало втрое быстрее предыдущего (на всех форматах). 
NVIDIA H100 CNX (PCIe) TF32 останется форматом по умолчанию при работе с TensorFlow и PyTorch, но для ускорения тренировки ИИ-моделей NVIDIA предлагает использовать смешанные FP8/FP16-вычисления, с которыми Tensor-ядра справляются эффективно. Хитрость в том, что Transformer Engine на основе эвристик позволяет динамически переключаться между ними при работе, например, с каждым отдельным слоем сети, позволяя таким образом добиться повышения скорости обучения без ущерба для итогового качества модели. На больших моделях, а именно для таких H100 и создавалась, сочетание Transformer Engine с другими особенностями ускорителей (память и интерконнект) позволяет получить девятикратный прирост в скорости обучения по сравнению с A100. Но Transformer Engine может быть полезен и для инференса — готовые FP8-модели не придётся самостоятельно конвертировать в INT8, движок это сделает на лету, что позволяет повысить пропускную способность от 16 до 30 раз (в зависимости от желаемого уровня задержки). 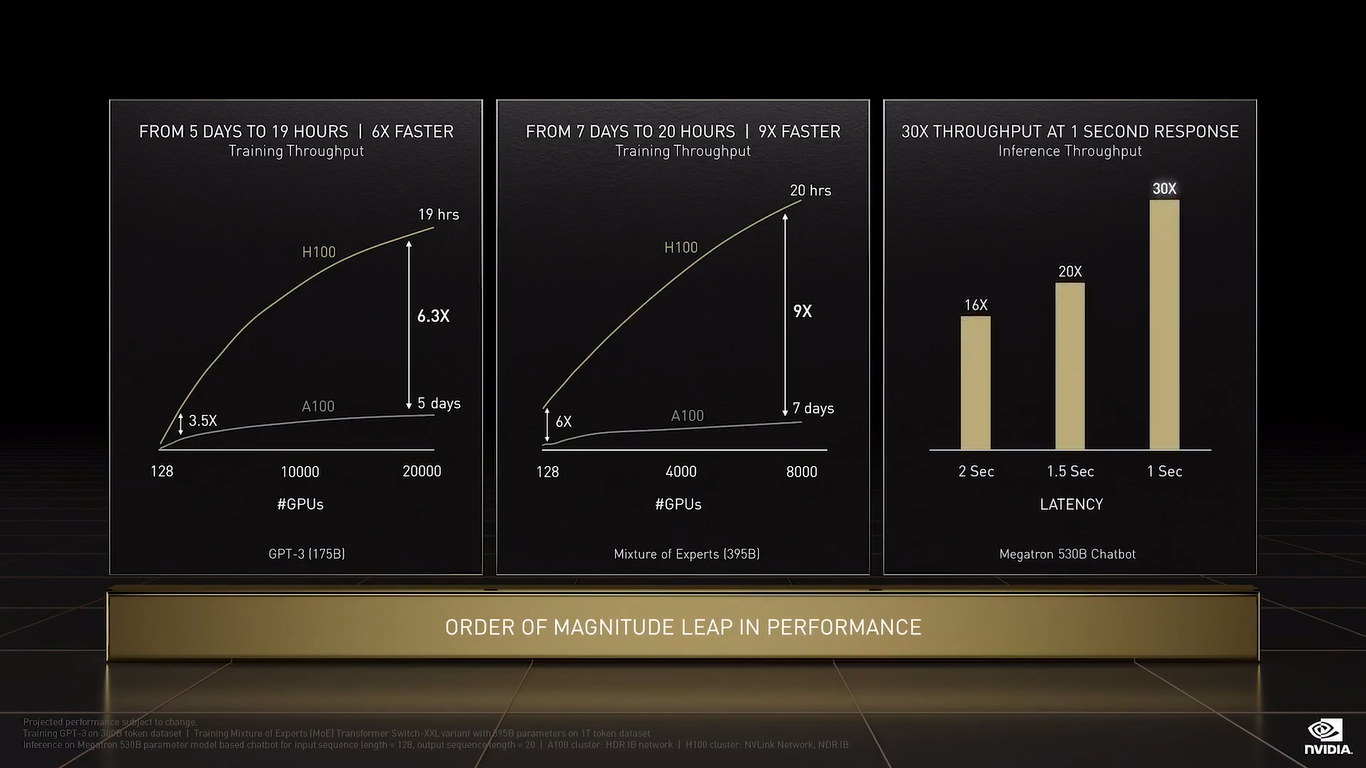 Другое любопытное нововведение — специальные DPX-инструкции для динамического программирования, которые позволят ускорить выполнение некоторых алгоритмов до 40 раз в задачах, связанных с поиском пути, геномикой, квантовыми системами и при работе с большими объёмами данных. Кроме того, H100 получили дальнейшее развитие виртуализации. В новых ускорителях всё так же поддерживается MIG на 7 инстансов, но уже второго поколения, которое привнесло больший уровень изоляции благодаря IO-виртуализации, выделенным видеоблокам и т.д.  Так что MIG становится ещё более предпочтительным вариантом для облачных развёртываний. Непосредственно к MIG примыкает и технология конфиденциальных вычислений, которая по словам компании впервые стала доступна не только на CPU. Программно-аппаратное решение позволяет создавать изолированные ВМ, к которым нет доступа у ОС, гипервизора и других ВМ. Поддерживается сквозное шифрование при передаче данных от CPU к ускорителю и обратно, а также между ускорителями.  Память внутри GPU также может быть изолирована, а сам ускоритель оснащается неким аппаратным брандмауэром, который отслеживает трафик на шинах и блокирует несанкционированный доступ даже при наличии у злоумышленника физического доступа к машине. Это опять-таки позволит без опаски использовать H100 в облаке или в рамках колокейшн-размещения для обработки чувствительных данных, в том числе для задач федеративного обучения.  NVIDIA HGX H100 Но главная инновация — это существенное развитие интерконнекта по всем фронтам. Суммарная пропускная способность внешних интерфейсов чипа H100 составляет 4,9 Тбайт/с. Да, у H100 появилась поддержка PCIe 5.0, тоже впервые в мире, как утверждает NVIDIA. Однако ускорители получили не только новую шину NVLink 4.0, которая стала в полтора раза быстрее (900 Гбайт/с), но и совершенно новый коммутатор NVSwitch, который позволяет напрямую объединить между собой до 256 ускорителей! Пропускная способность «умной» фабрики составляет до 70,4 Тбайт/с.  Сама NVIDIA предлагает как новые системы DGX H100 (8 × H100, 2 × BlueField-3, 8 × ConnectX-7), так и SuperPOD-сборку из 32-х DGX, как раз с использованием NVLink и NVSwitch. Партнёры предложат HGX-платформы на 4 или 8 ускорителей. Для дальнейшего масштабирования SuperPOD и связи с внешним миром используются 400G-коммутаторы Quantum-2 (InfiniBand NDR). Сейчас NVIDIA занимается созданием своего следующего суперкомпьютера EOS, который будет состоять из 576 DGX H100 и получит FP64-производительность на уровне 275 Пфлопс, а FP16 — 9 Эфлопс.  Компания надеется, что EOS станет самой быстрой ИИ-машиной в мире. Появится она чуть позже, как и сами ускорители, выход которых запланирован на III квартал 2022 года. NVIDIA представит сразу три версии. Две из них стандартные, в форм-факторах SXM4 (700 Вт) и PCIe-карты (350 Вт). А вот третья — это конвергентный ускоритель H100 CNX со встроенными DPU Connect-X7 класса 400G (подключение PCIe 5.0 к самому ускорителю) и интерфейсом PCIe 4.0 для хоста. Компанию ей составят 400G/800G-коммутаторы Spectrum-4.
28.06.2021 [13:22], Алексей Степин
Обновление NVIDIA HGX: PCIe-вариант A100 с 80 Гбайт HBM2e, InfiniBand NDR и Magnum IO с GPUDirect StorageНа суперкомпьютерной выставке-конференции ISC 2021 компания NVIDIA представила обновление платформы HGX A100 для OEM-поставщиков, которая теперь включает PCIe-ускорители NVIDIA c 80 Гбайт памяти, InfiniBand NDR и поддержку Magnum IO с GPUDirect Storage. В основе новинки лежат наиболее продвинутые на сегодняшний день технологии, имеющиеся в распоряжении NVIDIA. В первую очередь, это, конечно, ускорители на базе архитектуры Ampere, оснащённые процессорами A100 с производительностью почти 10 Тфлопс в режиме FP64 и 624 Топс в режиме тензорных вычислений INT8.  HGX A100 предлагает 300-Вт версию ускорителей с PCIe 4.0 x16 и удвоенным объёмом памяти HBM2e (80 Гбайт). Увеличена и пропускная способность (ПСП), в новой версии ускорителя она достигла 2 Тбайт/с. И если по объёму и ПСП новинки догнали SXM-версию A100, то в отношении интерконнекта они всё равно отстают, так как позволяют напрямую объединить посредством NVLink только два ускорителя.  В качестве сетевой среды в новой платформе NVIDIA применена технология InfiniBand NDR со скоростью 400 Гбит/с. Можно сказать, что InfiniBand догнала Ethernet, хотя не столь давно её потолком были 200 Гбит/с, а в плане латентности IB по-прежнему нет равных. Сетевые коммутаторы NVIDIA Quantum 2 поддерживают до 64 портов InfiniBand NDR и вдвое больше для скорости 200 Гбит/с, а также имеют модульную архитектуру, позволяющую при необходимости нарастить количество портов NDR до 2048. Пропускная способность при этом может достигать 1,64 Пбит/с.  Технология NVIDIA SHARP In-Network Computing позволяет компании заявлять о 32-крантом превосходстве над системами предыдущего поколения именно в области сложных задач машинного интеллекта для индустрии и науки. Естественно, все преимущества машинной аналитики используются и внутри самого продукта — технология UFM Cyber-AI позволяет новой платформе исправлять большинство проблем с сетью на лету, что минимизирует время простоя.  Отличным дополнением к новым сетевым возможностями является технология GPUDirect Storage, которая позволяет NVMe-накопителям общаться напрямую с GPU, минуя остальные компоненты системы. В качестве программной прослойки для обслуживания СХД новая платформа получила систему Magnum IO с поддержкой вышеупомянутой технологии, обладающую низкой задержкой ввода-вывода и по максимуму способной использовать InfiniBand NDR. 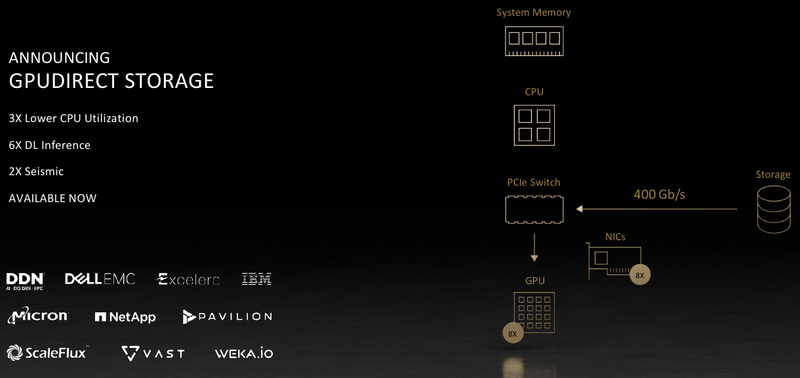 Три новых ключевых технологии NVIDIA помогут супервычислениям стать ещё более «супер», а суперкомпьютерам следующего поколения — ещё более «умными» и производительными. Достигнуты договорённости с такими крупными компаниями, как Atos, Dell Technologies, HPE, Lenovo, Microsoft Azure и NetApp. Решения NVIDIA используются как в индустрии — в качестве примера можно привести промышленный суперкомпьютер Tesla Automotive, так и в ряде других областей.  В частности, фармакологическая компания Recursion использует наработки NVIDIA в области машинного обучения для поиска новых лекарств, а национальный научно-исследовательский центр энергетики (NERSC) применяет ускорители A100 в суперкомпьютере Perlmutter при разработке новых источников энергии. И в дальнейшем NVIDIA продолжит своё наступление на рынок HPC, благо, она может предложить заказчикам как законченные аппаратные решения, так и облачные сервисы, также использующие новейшие технологии компании. |
|