Материалы по тегу: cerebras
|
31.08.2024 [14:12], Сергей Карасёв
Cerebras Systems запустила «самую мощную в мире» ИИ-платформу для инференсаАмериканский стартап Cerebras Systems, занимающийся разработкой чипов для систем машинного обучения и других ресурсоёмких задач, объявил о запуске, как утверждается, самой производительной в мире ИИ-платформы для инференса — Cerebras Inference. Ожидается, что она составит серьёзную конкуренцию решениям на основе ускорителей NVIDIA. В основу облачной системы Cerebras Inference положены ускорители WSE-3. Эти гигантские изделия, выполненные с применением 5-нм техпроцесса TSMC, содержат 4 трлн транзисторов, 900 тыс. ядер и 44 Гбайт SRAM. Суммарная пропускная способность встроенной памяти достигает 21 Пбайт/с, а внутреннего интерконнекта — 214 Пбит/с. Для сравнения: один чип HBM3e в составе NVIDIA H200 может похвастаться пропускной способностью «только» 4,8 Тбайт/с. 
Источник изображений: Cerebras По заявлениям Cerebras, новая инференс-платформа обеспечивает до 20 раз более высокую производительность по сравнению с сопоставимыми по классу решениями на чипах NVIDIA в сервисах гиперскейлеров. В частности, быстродействие составляет до 1800 токенов в секунду на пользователя для ИИ-модели Llama3.1 8B и до 450 токенов в секунду для Llama3.1 70B. Для сравнения, у AWS эти значения равны соответственно 93 и 50. Речь идёт об FP16-операциях. Cerebras заявляет, что лучший результат для кластеров на основе NVIDIA H100 в случае Llama3.1 70B составляет 128 токенов в секунду. 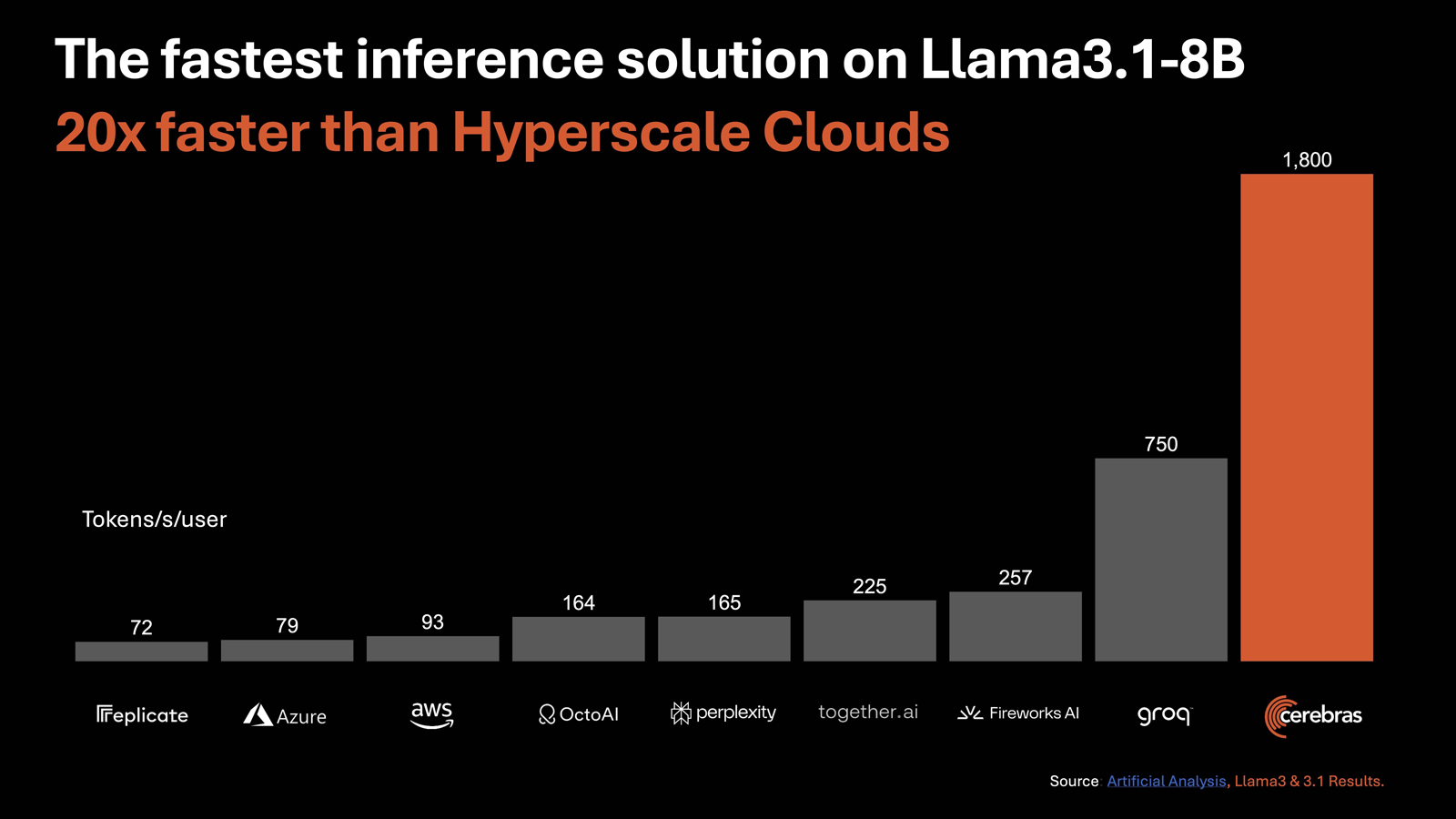 «В отличие от альтернативных подходов, которые жертвуют точностью ради быстродействия, Cerebras предлагает самую высокую производительность, сохраняя при этом точность на уровне 16 бит для всего процесса инференса», — заявляет компания. При этом услуги Cerebras Inference стоят в несколько раз меньше по сравнению с конкурирующими предложениями: $0,1 за 1 млн токенов для Llama 3.1 8B и $0,6 за 1 млн токенов для Llama 3.1 70B. Оплата взимается по мере использования. Cerebras планирует предоставлять инференс-услуги через API, совместимый с OpenAI. Преимущество такого подхода заключается в том, что разработчикам, которые уже создали приложения на основе GPT-4, Claude, Mistral или других облачных ИИ-моделей, не придётся полностью менять код для переноса нагрузок на платформу Cerebras Inference. 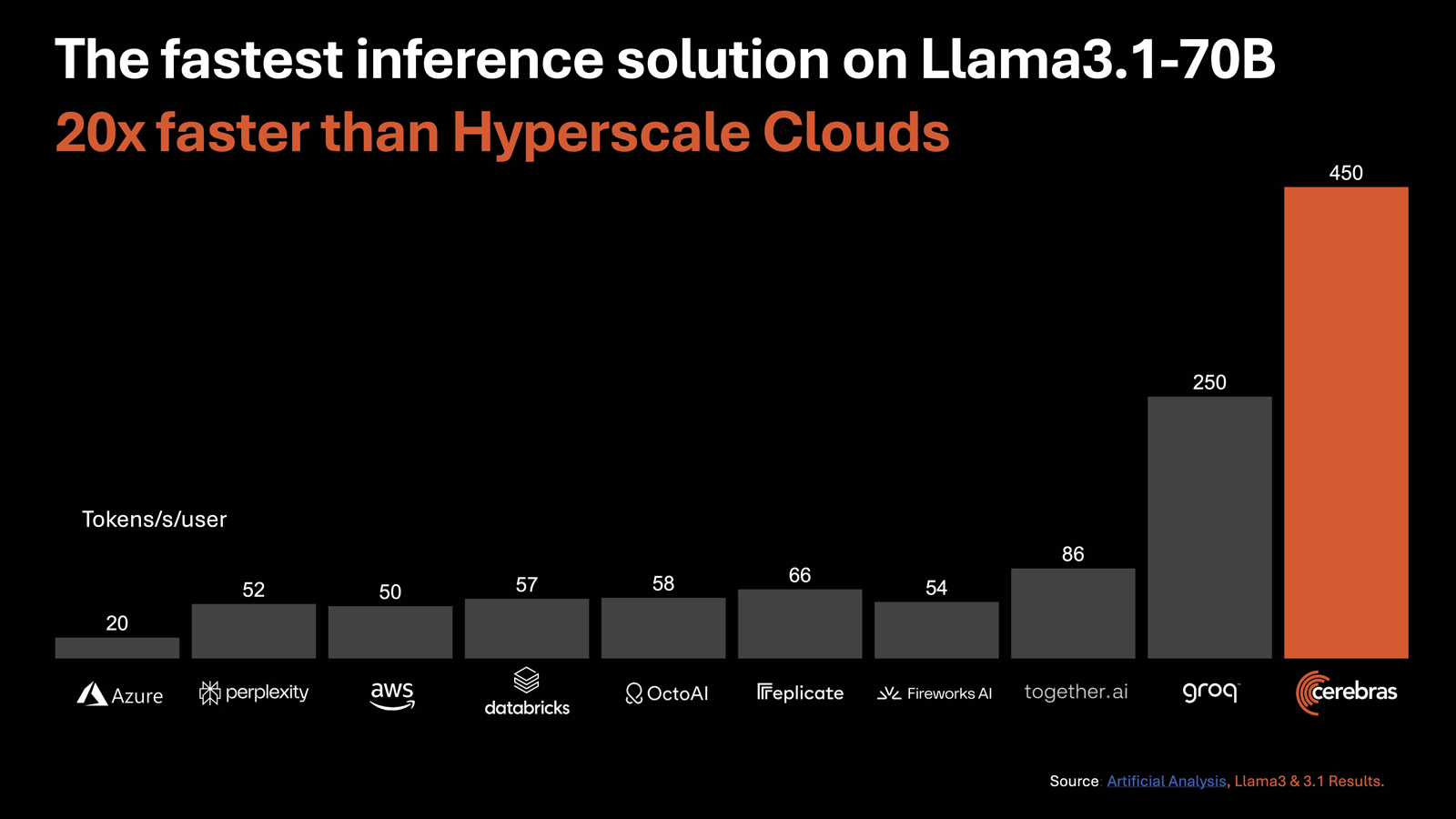 Для крупных предприятий предлагается план обслуживания Enterprise Tier, который предусматривает тонко настроенные модели, индивидуальные условия и специализированную поддержку. Стандартный пакет Developer Tier предполагает подписку по цене от $0,1 за 1 млн токенов. Кроме того, имеется бесплатный доступ начального уровня Free Tier с ограничениями. Cerebras говорит, что запуск платформы откроет качественно новые возможности для внедрения генеративного ИИ в различных сферах.
21.06.2024 [16:09], Руслан Авдеев
Производитель гигантских ИИ-суперчипов Cerebras Systems готовится к IPOСтартап Cerebras Systems Inc., выпускающий передовые ИИ-чипы и конкурирующий с NVIDIA, по слухам, подал регуляторам США документы для выхода на биржу Nasdaq. По данным Silicon Angle, IPO должно состояться позже в 2024 году. Компания выпускает специализированные и весьма производительные ИИ-чипы размером с кремниевую пластину. У NVIDIA немного конкурентов на мировом рынке, но Cerebras — как раз из их числа. Новейший флагманский чип компании WSE-3 был анонсирован в марте, ему предшествовала модель WSE-2, дебютировавшая в 2021 году. Ожидается, что WSE-3 станет доступен до конца текущего года. 
Источник изображения: Cerebras Cerebras говоит, что WSE-3 имеет в 52 раза больше ИИ-ядер, чем ускоритель NVIDIA H100. Чип будет доступен в составе модуля CS-3 размером с небольшой холодильник с интегрированной системой охлаждения и блоком питания. WSE-3 имеет пиковое быстродействие 125 Пфлопс в разреженных FP16-вычислениях. В компании утверждают, что таких характеристик более чем достаточно для конкуренции с лучшими ускорителями NVIDIA, а её чипы не только быстрее, но и энергоэффективнее. Статус компании, похоже, действительно способной конкурировать NVIDIA, должен привлечь внимание инвесторов. Например, с началом эры ИИ акции NVIDIA выросли почти на порядок, поэтому не исключено, что и Cerebras ожидает впечатляющий успех. По имеющимся данным, Cerebras уведомила регуляторов в Делавэре, где компания официально зарегистрирована, о намерении предложить в ходе ожидающегося раунда инвестиций привилегированные акции с большой скидкой. Хотя в самой Cerebras не комментируют слухи об IPO, Bloomberg сообщил, что компания выбрала Citigroup в качестве ведущего банка для первичного листинга. В Bloomberg отмечают, что IPO состоится не раньше II половины 2024 года, а руководство рассчитывает на оценку не менее $4 млрд, которую компания получила после последнего раунда финансирования серии F, позволившего привлечь $250 млн в 2021 году.
17.06.2024 [08:53], Руслан Авдеев
Cerebras и Dell предложат заказчикам современные ИИ-платформыРазработчик ИИ-суперчипов Cerebras Systems анонсировал сотрудничество с Dell. Вместе компании займутся созданием передовых вычислительных инфраструктур для генеративного ИИ. В рамках сотрудничества будут создаваться масштабируемые решения для ИИ-суперкомпьютеров Cerebras с платформами Dell на базе процессоров AMD EPYC Genoa. Источник изображения: Cerebras По словам участников проекта, новые технологические решения дадут возможность обучать модели, на порядки более крупные, чем те, что есть на данный момент. В частности, будут задействованы системы Dell PowerEdge R6615 на базе AMD EPYC 9354P, которые предоставят потоковый доступ к 82 Тбайт памяти — для обучения моделей практически любого размера. Совместные платформы Cerebras и Dell будут включать ИИ-системы и суперкомпьютеры. Также будет предложена тренировка ИИ-моделей и иные сервисы поддержки машинного обучения. Как утверждают в самой Cerebras, сотрудничество с Dell станет поворотной точкой, открывающие каналы глобальной дистрибуции. Компании предоставят ИИ-оборудование, ПО и экспертизу, что позволит заказчикам упростить и ускорить внедрении современных ИИ-технологий, попутно снизив TCO. В марте Cerebras представила новейшие суперчипы Cerebras WSE-3, а в мае появилась новость, что совместно с Core42 из ОАЭ компания создаст суперкомпьютер Condor Galaxy 3 (CG-3) со 172,8 млн ИИ-ядер.
23.05.2024 [09:57], Александр Бенедичук
Гигантские суперчипы Cerebras натренируют ИИ для армии ГерманииCerebras Systems и Aleph Alpha объединятся для разработки суверенных ИИ-решений в интересах армии Германии, сообщает Datacenter Dynamics. Работы альянса будут вестись совместно с компанией BWI GmbH, государственным поставщиком ИТ-услуг, принадлежащим Министерству обороны Германии. Aleph Alpha развернет первый в Европе ИИ-суперкомпьютер Cerebras CS-3 в своем дата-центре Alpha ONE. «Мы считаем, что партнёрство [с Aleph Alpha] позволит создать совершенно новые архитектуры ИИ-моделей, которые могут быть полезны правительствам и предприятиям по всему миру», — сказал глава Cerebras, отметив, что работа с новыми моделями будет безопасной и защищённой, но не уточнив, что именно под этим подразумевается. 
Источник изображения: Cerebras Aleph Alpha основана в 2019 году для создания моделей генеративного ИИ в рамках концепции «суверенитета данных». ЦОД Alpha ONE был запущен в 2022 году в кампусе GovTech в Германии и используется для исследований и разработки ИИ-приложений как предприятиями государственного сектора, так и частными. Здесь Cerebras и Aleph Alpha будут вместе создавать базовые и мультимодальные модели, а также и новые архитектуры ИИ-моделей с использованием CS-3. В основе Cerebras CS-3 лежит ИИ-ускоритель WSE-3 размером с целую кремниевую пластину. Он содержит 4 трлн транзисторов, 900 тыс. ядер и 44 Гбайт SRAM, а его производительность составляет 125 Пфлопс в разреженных FP16-вычислениях.
21.05.2024 [16:36], Руслан Авдеев
Core42 и Cerebras построят в Техасе ИИ-суперкомпьютер с 173 млн ядерБазирующаяся в ОАЭ компания Core42 занялась строительством ИИ-суперкомпьютера, в эксплуатацию объект должны ввести до конца текущего года. HPC Wire сообщает, что компьютер Condor Galaxy 3 (CG-3) получит 192 узла с 5-нм мегачипами Cerebras WSE-3 и 172,8 млн ИИ-ядер. WSE-3 в 50 раз крупнее актуальных ИИ-ускорителей NVIDIA и, конечно, гораздо производительнее. По данным Core42, развёртывание CG-3 в Далласе (Техас) начнётся в июне и завершится в сентябре–октябре. Core42 уже считается значимым игроком на рынке ЦОД, HPC- и ИИ-систем. Машины G42 уже попадали в TOP500 — это системы Artemis (NVIDIA) и POD3 (Huawei). Последняя покинула рейтинг в 2023 году. Суперкомпьютер CG-3, как теперь сообщается, получит 192 узла CS-3. Каждый узел с чипом WSE-3 обеспечивает до 125 Пфлопс (FP16 с разрежением), так что общая производительность Condor Galaxy 3 составит 24 Эфлопс. Всего же Cerebras намеревается построить девять суперкомпьютеров семейства Condor Galaxy. Машины GC-1 и GC-2 на базе чипов WSE-2 также созданы при участии G42. 
Источник изображения: Cerebras Core42 появилась в 2023 году в результате слияния G42 Cloud и G42 Inception AI. Родительская компания G42, основанная в 2018 году, также сотрудничает с NVIDIA, AMD, OpenAI и другими компаниями. G42 не так давно попала под пристальное внимание американских властей. Её подозревали в том, что она помогала Китаю получать доступ к новейшим ускорителям NVIDIA и другому ИИ-оборудованию американских компаний. В результате, как считается, она была вынуждена отказать от сотрудничества с Huawei. Также сообщалось, что G42 заключила с американским правительством взаимовыгодное секретное соглашение — компания обязалась лишить КНР доступа к ускорителям, а в ответ ей самой разрешали сохранить доступ к продукции NVIDIA. Не исключено, что были оговорены и иные пункты. По некоторым данным, именно в то же время, когда было заключено соглашение с руководством США, Microsoft инвестировала в G42 около $1,5 млрд.
19.04.2024 [10:20], Сергей Карасёв
ИИ на воде: Cerebras установит оборудование в плавучем дата-центре NautilusАмериканский стартап Cerebras Systems, занимающийся разработкой ИИ-ускорителей, по сообщению Datacenter Dynamics, арендует площади в дата-центре на барже Nautilus Data Technologies в Калифорнии. В этом плавучем ЦОД применяется запатентованная технология жидкостного охлаждения Nautilus, основанная на использовании забортной воды. Ранее Nautilus объявила, что неназванная компания в области ИИ подписала договор аренды на площадке в Стоктоне в конце 2023 года. Теперь выясняется, что этим клиентом является стартап Cerebras, который проектирует интегрированные чипы WSE (Wafer Scale Engine) размером с кремниевую пластину с сотнями тысяч ядер для работы с крупными ИИ-моделями. 
Источник изображения: Nautilus Дата-центр Nautilus в Стоктоне обладает мощностью 6,5 МВт и предлагает до 55 кВт на стойку. Заявленный уровень PUE — 1,15 вне зависимости от времени года или погодных условий. На объекте установлены резервные генераторы с запасом топлива, которого хватит на 26 часов работы при максимальной нагрузке. Забор воды для охлаждения осуществляется из реки Сан-Хоакин. Обеспечивается круглосуточный мониторинг территории усилиями местной службы безопасности, а также патрулирование наземных и водных путей Министерством внутренней безопасности, Береговой охраной США и Департаментом шерифа округа Сан-Хоакин. В рамках подписанного договора Cerebras арендует 2,5 МВт. В ЦОД будут размещены системы Cerebras CS-3 на основе ускорителей WSE-3. Эти изделия насчитывают 4 трлн транзисторов, содержат 900 тыс. ядер и 44 Гбайт памяти SRAM. Заявленная производительность достигает 125 Пфлопс в FP16-вычислениях.
13.03.2024 [22:40], Алексей Степин
Больше флопс за те же ватты: Cerebras представила царь-ускоритель WSE-3 и подружилась с QualcommКомпания Cerebras Systems, известная своими разработками в области сверхбольших ИИ-процессоров, рассказала о третьем поколении чипов Wafer Scale Engine. В своё время компания произвела фурор, представив процессор, занимающий всю площадь кремниевой пластины (46225 мм2). В первом поколении WSE речь шла о 1,2 трлн транзисторов при 400 тыс. ядер и 18 Гбайт сверхбыстрой памяти. WSE-2 состоял из 2,6 трлн транзисторов, имел 850 тыс. ядер и 40 Гбайт интегрированной памяти. В WSE-3 разработчики перешли на использование 5-нм техпроцесса TSMC, что позволило разместить на пластине такого же размера уже 4 трлн транзисторов, составляющих 900 тыс. ядер и 44 Гбайт SRAM. Суммарная пропускная способность набортной памяти достигает 21 Пбайт/с, а внутреннего интерконнекта — 214 Пбит/с. 
Источник изображений: Cerebras Казалось бы, выигрыш в количестве ядер по сравнению с WSE-2 не так уж велик, однако на этот раз Cerebras сделала упор на архитектуру. Если верить заявлениям разработчиков, WSE-3 практически вдвое быстрее WSE-2 при сопоставимом уровне энергопотребления (15 кВт) и той же цене: 125 Пфлопс против 75 Пфлопс в разреженных FP16-вычислениях. WSE-3 в 62 раза быстрее NVIDIA H100, хотя и сам чип WSE-3 в 57 раз больше. 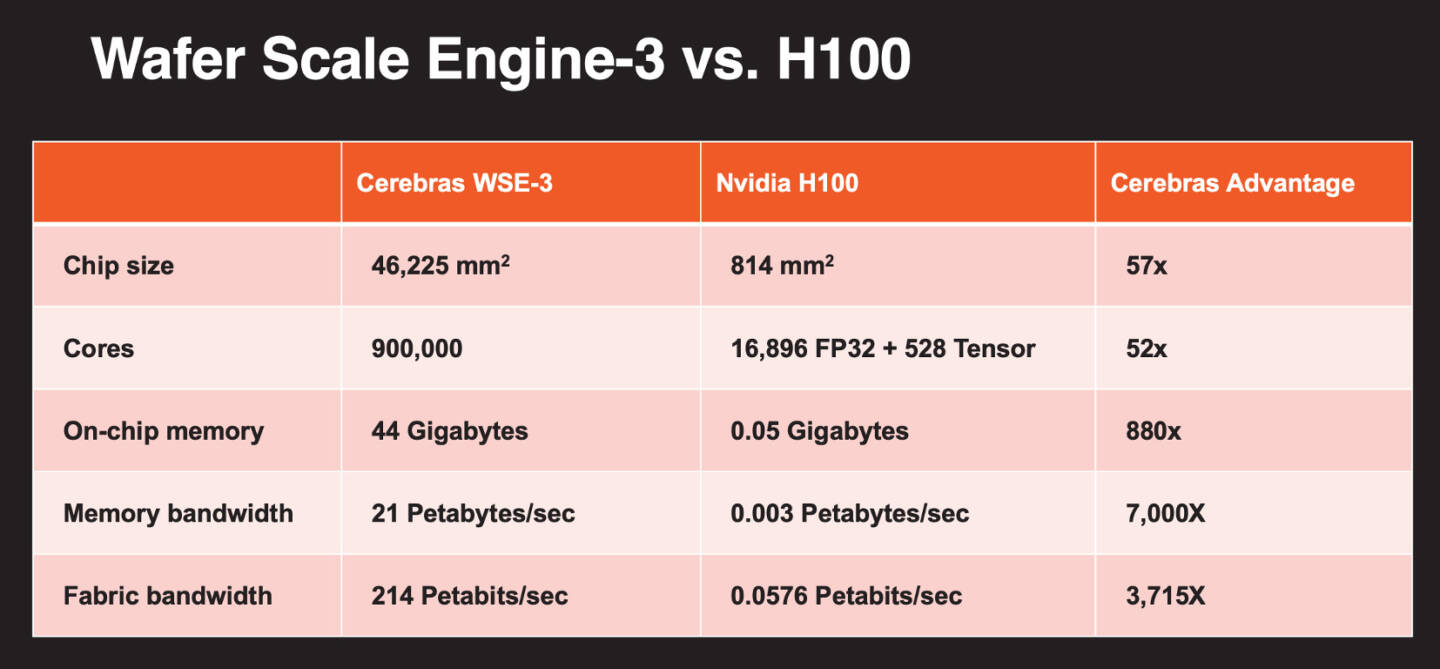 WSE-3 по-прежнему требует специфического окружения. Он станет сердцем новой системы CS-3 (23 кВт), содержащей всю необходимую сопутствующую инфраструктуру, включая СЖО, подсистемы питания, а также сетевого интерконнекта Ethernet. Последний не изменился и состоит из 12 каналов со скоростью 100 Гбит/с. Для подготовки «сырых» данных по-прежнему будет использоваться внешний суперсервер. А для их хранения будут использоваться узлы MemoryX ёмкостью до 1200 Тбайт (1,2 Пбайт). 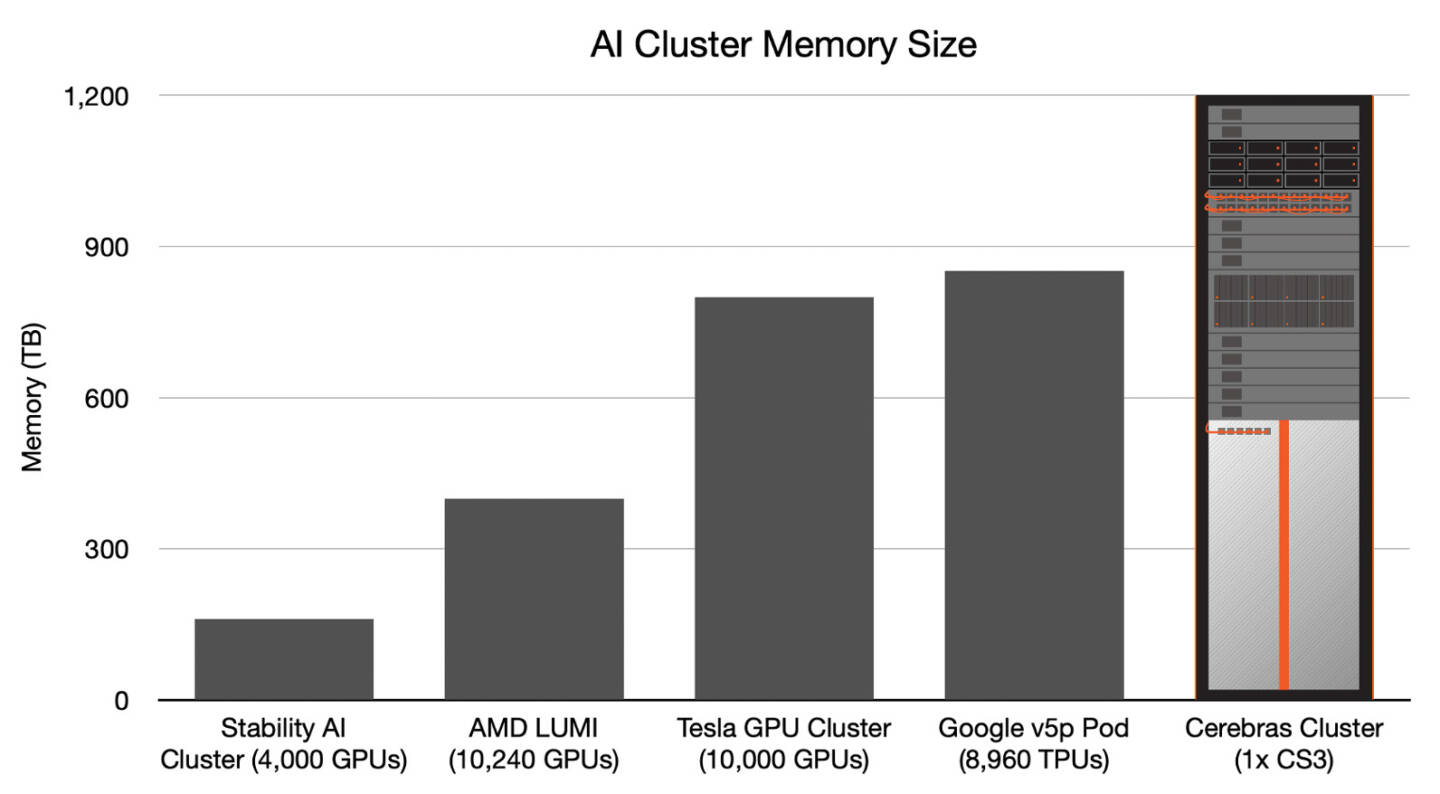 Главной задачей CS-3 станет «натаскивание» сверхбольших языковых моделей, в 10 раз превышающих по количеству параметров GPT-4 и Google Gemini. Cerebras говорит о 24 трлн параметров, причём без необходимости различных ухищрений для эффективного распараллеливания процесса обучения, что требуется в случае с GPU-кластерами. По словам компании, для обучения Megatron 175B на таких кластерах требуется 20 тыс. строка кода Python/C++/CUDA, а в случае WSE-3 потребуется лишь 565 строк на Python.  CS-3 поддерживает масштабирование вплоть до 2048 систем. Такая конфигурация вкупе с MemoryX сможет обучить модель типа Llama 70B всего за день. Первый суперкомпьютер на базе CS-3 — 8-Эфлопс Condor Galaxy 3 — будет скромнее и получит всего 64 стойки CS-3, которые разместятся в Далласе (США). В совокупности с уже имеющимися кластерами на базе CS-1 и CS-2 вычислительная мощность систем Cerebras должна достигнуть 16 Эфлопс. В сотрудничестве c группой G42 запланировано создание ещё шести систем CS-3, что в сумме позволит довести производительность до 64 Эфлопс.  Condor Galaxy 3 будет отличаться от предшественников ещё одним нововведением: в рамках сотрудничества с Qualcomm Cerebras установит в новом кластере существенное число инференс-ускорителей Qualcomm Cloud AI100 Ultra. Каждый такой ускоритель имеет 64 ядра, 128 Гбайт памяти LPDDR4x, потребляет 140 Вт и развивает 870 Топс на INT8-операциях. Причём програмнный стек полностью интегрирован, что позволит в один клик запустить обученные WSE-3 модели на ускорителях Qualcomm. 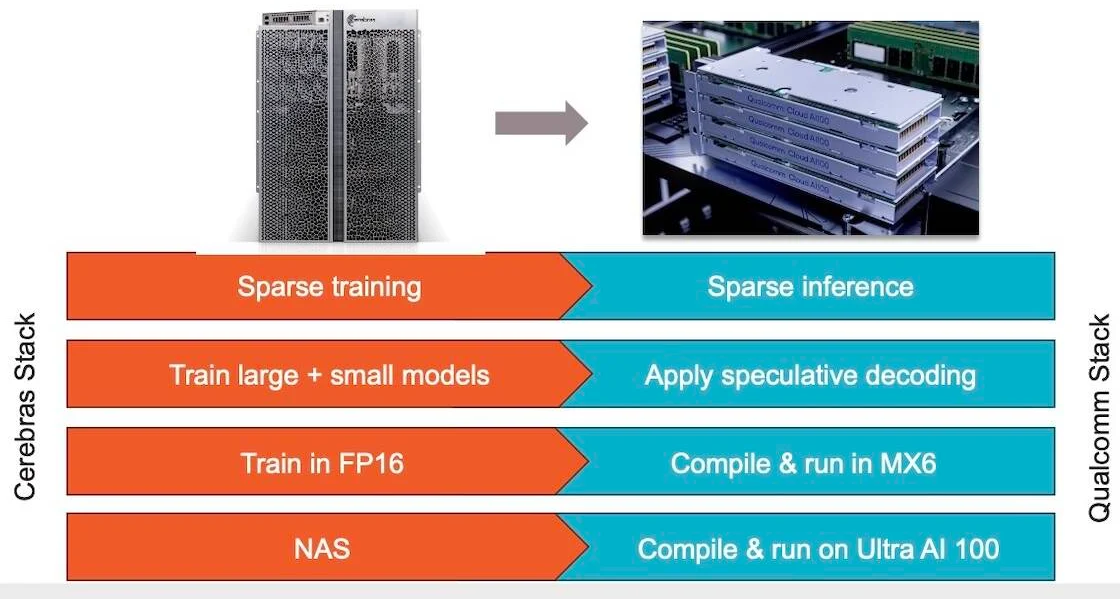 Сотрудничество Cerebras и Qualcomm носит официальный характер, его целью является оптимизация ИИ-моделей для запуска на AI100 Ultra с учетом различных продвинутых техник, таких как разреженные вычисления, спекулятивное исполнение (сочетание малых LLM для получения быстрого результата с проверкой большой LLM), использование «сжатого» формата MxFP6 для весов и других. Благодаря мощностям, предоставляемым WSE-3, цикл разработки, оптимизации и тестирования таких моделей удастся существенно ускорить, что в итоге должно обеспечить десятикратное улучшение удельной производительности новых решений.
27.01.2024 [22:18], Сергей Карасёв
Разработчик гигантских ИИ-чипов Cerebras намерен провести IPO во II половине 2024 годаАмериканский стартап Cerebras Systems, занимающийся разработкой чипов для систем машинного обучения и других ресурсоёмких задач, по информации Bloomberg, намерен осуществить первичное публичное размещение акций (IPO) во II половине текущего года. Соответствующие переговоры уже ведутся с консультантами. Cerebras была основана в 2015 году. Она является разработчиком интегрированных чипов WSE (Wafer Scale Engine) размером с кремниевую пластину, которые содержат сотни тысяч тензорных ядер для работы с крупными ИИ-моделями. Компания осуществила несколько раундов финансирования, получив оценку на уровне $4 млрд. В число инвесторов входят Alpha Wave Ventures, Altimeter, Benchmark, Coatue, Eclipse, Moore и VY. 
Источник изображения: Cerebras Как сообщает Bloomberg, ссылаясь на информацию, полученную от осведомлённых источников, Cerebras ведёт переговоры о дополнительном привлечении средств в частном порядке перед IPO. Ожидается, что в рамках выхода на биржу оценочная стоимость стартапа превысит $4 млрд. Переговоры на тему публичного размещения акций продолжаются, но окончательное решение по данному вопросу пока не принято. В июле 2023 года Cerebras объявила о создании первого из девяти запланированных ИИ-суперкомпьютеров. Система под названием Condor Galaxy 1 (CG-1) стоимостью $100 млн расположена в Санта-Кларе (Калифорния, США). Она обеспечивает производительность FP16 на уровне 2 Эфлопс. В проекте приняла участие холдинговая группа G42 из ОАЭ. Кроме того, Cerebras сообщила о намерении поддержать пилотный проект Национального исследовательского ресурса по искусственному интеллекту (NAIRR), который реализуется Национальным научным фондом США (NSF). Cerebras предоставит специалистам NAIRR удалённый доступ к вычислительным ресурсам своего суперкомпьютера.
29.11.2023 [01:21], Руслан Авдеев
Cerebras, критиковавшая NVIDIA за сотрудничество с Китаем, сама оказалась связана с компанией, ведущей дела с ПекиномХотя стартап Cerebras, занимающийся разработкой чипов, раскритиковал NVIDIA за попытки обойти санкционные ограничения в отношении Китая и призвал соблюдать не букву, но дух американского закона, у компании, похоже, нашлись свои скелеты в шкафу. Как сообщает The Register, сейчас в США расследуют деятельность клиента Cerebras — группы G42, возможно, помогавшей Поднебесной обходить санкционные ограничения. Американские спецслужбы подозревают, что базирующаяся в ОАЭ многопрофильная компания G42 поставляет в Китай передовые технологии. Для своих ИИ-исследований компания обратилась к Cerebras с целью постройки суперкомпьютерного кластера Condor Galaxy за $100 млн, а всего стартап намерен построить девять подобных объектов на $900 млн. При этом узлы кластера используют разработанные Cerebras чипы WSE-2, подходящие для обучения ИИ-систем. 
Источник изображения: Arthur Wang/unsplash.com Как показывают предварительные результаты расследования американских журналистов, властей и спецслужб, G42 пытается сотрудничать с Пекином и работает с китайскими компаниями вроде Huawei, давно находящимися под санкциями. В самой G42 утверждают, что принимают все меры для того, чтобы соблюдать американские ограничения. При этом, по данным журналистов, G42 считают прокси-компанией для работы в интересах КНР, помогающей Пекину получать вычислительные ресурсы и подсанкционные технологии. По словам главы Cerebras Эндрю Фельдмана (Andrew Feldman), его компания точно не будет вести бизнес с Китаем. Бизнесмен попал в неловкую ситуацию после того, как появилась информация о тесных связях G42 с Пекином. На запрос журналистов в Cerebras заявили, что кластеры Condor Galaxy находятся в США, а G42 получает к ним облачный доступ, так что любая активность контролируется и соответствует американским законам — государства-противники не имеют прямого доступа к ИИ-системам. Фельдман якобы не знал о сомнительном статусе G42, а в стартапе подчеркнули, что не комментируют слухи. Бюро промышленности и безопасности США уже обратилось к поставщикам облачных инфраструктур для консультаций о целесообразности дополнительных ограничений доступа к их услугам из некоторых стран. В частности, бюро интересует, как операторы намерены выявлять разработчиков ИИ-моделей, вызывающих обеспокоеность властей и что можно предпринять для устранения угроз. Кроме того, президент США предложил новые правила, согласно которым облакам потребуется докладывать о деятельности иностранцев, связанной с обучением больших языковых моделей (LLM).
21.11.2023 [00:34], Руслан Авдеев
Cerebras раскритиковала NVIDIA за «вооружение» Китая ИИ-ускорителямиГлава Cerebras Эндрю Фельдман (Andrew Feldman) подверг критике NVIDIA за попытки компании уложиться в нормы, установленные новыми экспортными ограничениями США в отношении Китая, чтобы продолжить поставки ИИ-ускорителей в Поднебесную. Как передаёт The Register, такое поведение Фельдман назвал «неамериканским» и сравнил техногиганта с торговцем ИИ-оружием. По словам Фельдмана, NVIDIA буквально единолично «вооружила» Китай, поставив огромное количество ускорителей. Хотя компания действовала в рамках закона, это не снимает с неё моральной ответственности. Сама Cerebras тоже разрабатывает чипы для систем машинного обучения и других ресурсоёмких задач, но намерена соблюдать «дух, а не букву» введённых в октябре США новых правил, ограничивающих поставки ИИ-оборудования в США. Правила и без того фактически отрезают Пекин от поставок разработанных в США передовых ускорителей, но уже ходят слухи, что NVIDIA готовит новые продукты для того, чтобы обойти и эти ограничения. Раньше она уже выпустила «ухудшенные» A800 и H800, теперь тоже попавшие под ограничения. Неанонсированные чипы H20, L20 и L2 якобы представляют собой менее производительные версии более быстрых вариантов, поставляющихся для стран, не попавших под санкции. NVIDIA уже предупреждала, что новые ограничения способны сказаться на её финансовых результатах. 
Фото: Cerebras Вместе с тем сама Cerebras в этом году заключила контракт на $900 млн для строительства девяти ИИ-суперкомпьютеров на чипах WSE-2 для компании G42 из ОАЭ, которую неоднократно обвиняли в связях со структурами, занятых, к примеру, шпионажем в пользу властей ОАЭ. В данном случае компания не усматривает моральной дилеммы. Cerebras с самого начала приняла решение не вести дел с Китаем, а также обещает соблюдать рекомендации американских госорганов, касающиеся поставок полупроводников на Ближний Восток. Фельдман считает, что компании не должны пытаться обойти ограничения. В частности, компания отслеживала, чтобы её чипы «не поставлялись в одно место на Ближнем Востоке, чтобы вскоре исчезнуть и появиться совсем в другом, там, куда они не должны были бы поставляться». Как заявляют в Cerebras, когда вы пытаетесь обойти правила, вы выглядите «не по-американски». Конечно, обойти санкционные ограничения пытается не только NVIDIA, но и, например, Intel, которая ранее в этом году представила ухудшенную версию ускорителей Habana Gaudi для продажи на китайском рынке — правда, новейшие ограничения, похоже, не дадут поставлять в Китай и их. Некоторые сигналы о желании обойти санкции поступают и от AMD, хотя нет точных данных, когда начнутся продажи адаптированных под санкции решений и начнутся ли они вообще. |
|