Материалы по тегу: разработка
|
07.05.2025 [09:05], Владимир Мироненко
IBM разработала инструменты для быстрого создания и интеграции ИИ-агентовIBM планирует укрепить свои позиции на быстрорастущем рынке ИИ-технологий с помощью увеличения инвестиций в США и предложения собственных инструментов, которые помогут клиентам управлять ИИ-агентами для их ключевых бизнес-приложений. Об этом сообщил генеральный директор IBM Арвинд Кришна (Arvind Krishna) в интервью агентству Reuters. Глава IBM заявил, что разработанное компанией ПО позволяет клиентам создавать собственные ИИ-системы, а также интегрировать ИИ-агентов от других провайдеров, включая Salesforce, Adobe и Workday. Это поможет удовлетворить потребность в кастомных решениях во многих областях бизнеса. Подход IBM заключается в том, чтобы предложить полный спектр облачных и ИИ-сервисов остальным компаниям, которые в настоящее время полагаются на лидеров рынка AWS и Microsoft. Особое внимание IBM уделяет внедрению функций ИИ в мультиоблачных платформах, что найдёт спрос среди тех, кому нужны кастомные ИИ-решения, а также в собственные инфраструктуры заказчиков для управления данными. 
Источник изображения: IBM По словам гендиректора IBM, предлагаемые инструменты, позволяющие создавать собственных ИИ-агентов в течение не более пяти минут, основаны на семействе LLM Granite, а также на альтернативных моделях от Meta✴ Platforms и Mistral. IBM сообщила, что уже получила заказы на создание решений на базе генеративного ИИ на $6 млрд. Также компания объявила в апреле о планах инвестировать в течение пяти лет $150 млрд в США, где она в течение более 60 лет производит мейнфреймы. Кришна подчеркнул, что квантовые компьютеры тоже будут производиться в США. Глава IBM отметил, что синергия мейнфреймов, ИИ и квантовых вычислений, как ожидается, создаст надёжный и устойчивый рынок, в который следует инвестировать и который позволит компании использовать эти достижения в течение следующего десятилетия. Кришна добавил, что фокус на технологии и сокращение регулирования со стороны администрации оказали благотворное влияние на экономику США, способствуя её росту. Это позволяет IBM наращивать инвестиции и инновации, тем самым потенциально укрепляя свою конкурентную позицию как поставщика бизнес-решений на основе ИИ.
09.04.2025 [17:48], Руслан Авдеев
ИИ Google Gemini поможет переписать приложения для мейнфреймов и перенести их в облакоНезадолго до анонса новых мейнфреймов IBM z17 компания Google анонсировала новые ИИ-инструменты на основе моделей Gemini и других технологий для модернизации инфраструктуры и переносу нагрузок с в облако Google Cloud. Google Cloud Mainframe Assessment Tool (MAT) на основе ИИ-моделей Gemini уже доступен. Инструмент позволяет оценить и проанализировать общее состояние мейнфреймов, включая приложения и данные. Это даст возможность принимать информированные решения по оптимальной модернизации. MAT обеспечивает глубокий анализ кода, генерирует чёткие объяснения его работы, автоматизирует создание документации и др. Это позволяет ускорить понимание кода мейнфреймов и стимулирует процесс модернизации. Google Cloud Mainframe Rewrite на основе моделей Gemini позволяет модернизировать приложения для мейнфреймов (инструмент доступен в превью-режиме). Он помогает разработчикам переосмыслить и преобразовать код для мейнфреймов, переписав его на современные языки программирования вроде Java и C#. Mainframe Rewrite предлагает IDE для модернизации кода, тестирования и развёртывания модернизированных приложений в Google Cloud. 
Источник изображения: Ant Rozetsky / Unsplash Наконец, чтобы снизить риски, возникающие при модернизации, предлагается инструмент Google Cloud Dual Run для глубокого тестирования, сертификации и оценки модернизированных приложений. Инструмент позволяет проверить корректность, полноту и производительность модернизированного кода в ходе миграции и до того, как новое приложение заменит старое. Dual Run сравнивает данные, выдаваемые старой и новой системами, для поиска отличий. Имеются и дополнительные инструменты, разработанные партнёрами Google. Так, Mechanical Orchard предлагает платформу для быстро переписывания приложений на COBOL на современные языки, включая Java, Python и др., без изменения бизнес-логики. Решение позволяет «пошагово» переписывать фрагменты приложений с помощью систем генеративного ИИ с сохранением функциональности и тестировать корректность их работы. Основная цель — создать для облака функциональный эквивалент устаревших решений. 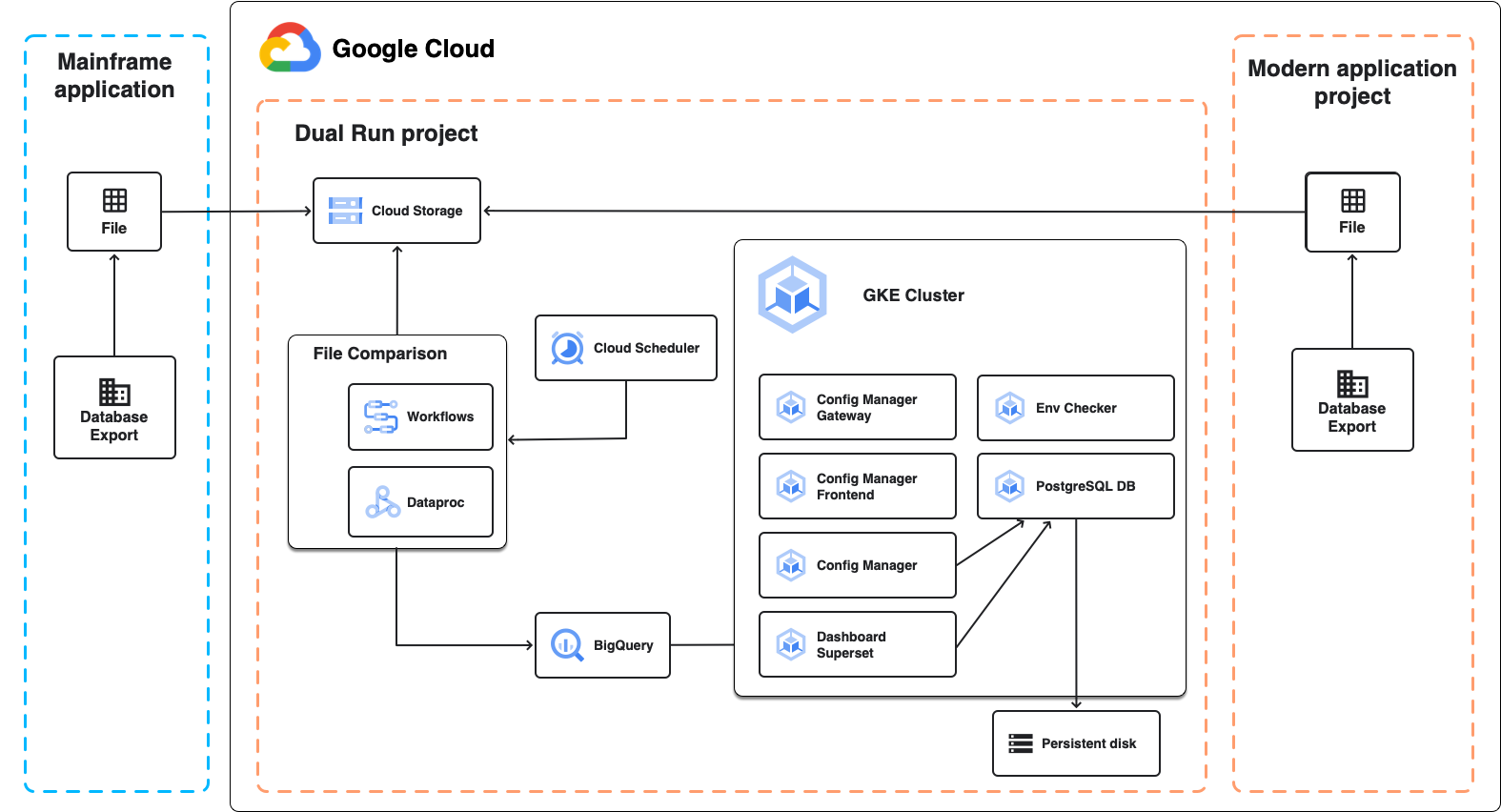
Источник изображения: Google Cloud Кроме того, в рамках новой программы Google Mainframe Modernization with Gen AI Accelerator компания привлекла Accenture, EPAM и Thoughtworks, которые помогут организациям мигрировать с мейнфреймов. На первом этапе производится анализ кода с помощью MAT и Gemini. На втором реализуется пилотный проект с проверкой работоспособности нового кода. На третьем осуществляется полномасштабная миграция в облако. Первые клиенты могут бесплатно (без учёта расходов на Google Cloud) оценить решения в течение 4-8 недель. Мейнфреймы ещё рано списывать со счетов. Согласно данным опроса Kyndryl 500 топ-менеджеров ИТ-индустрии, многие организации интегрируют мейнфреймы с публичными и частными облачными платформами и совершенствуют свои программы модернизации, перемещая некоторые рабочие нагрузки с мейнфреймов или обновляя их.
24.03.2025 [08:30], Владимир Мироненко
NVIDIA представила проект AI-Q Blueprint Platform для создания продвинутых ИИ-агентовПризнавая, что одних моделей, включая свежие Llama Nemotron с регулируемым «уровнем интеллекта», недостаточно для развёртывания ИИ на предприятии, NVIDIA анонсировала проект AI-Q Blueprint, представляющий собой фреймворк с открытым исходным кодом, позволяющий разработчикам подключать базы знаний к ИИ-агентам, которые могут действовать автономно. Blueprint был создан с помощью микросервисов NVIDIA NIM и интегрируется с NVIDIA NeMo Retriever, что упрощает для ИИ-агентов извлечение мультимодальных данных в различных форматах. С помощью AI-Q агенты суммируют большие наборы данных, генерируя токены в 5 раз быстрее и поглощая данные петабайтного масштаба в 15 раз быстрее с лучшей семантической точностью. Проект основан на новом наборе инструментов NVIDIA AgentIQ для бесшовного, гетерогенного соединения между агентами, инструментами и данными, опубликованном на GitHub. Он представляет собой программную библиотеку с открытым исходным кодом для подключения, профилирования и оптимизации команд агентов ИИ, работающих на основе корпоративных данных для создания многоагентных комплексных (end-to-end) систем. Его можно легко интегрировать с существующими многоагентными системами — как по частям, так и в качестве комплексного решения — с помощью простого процесса адаптации, который обеспечивает полную поддержку. 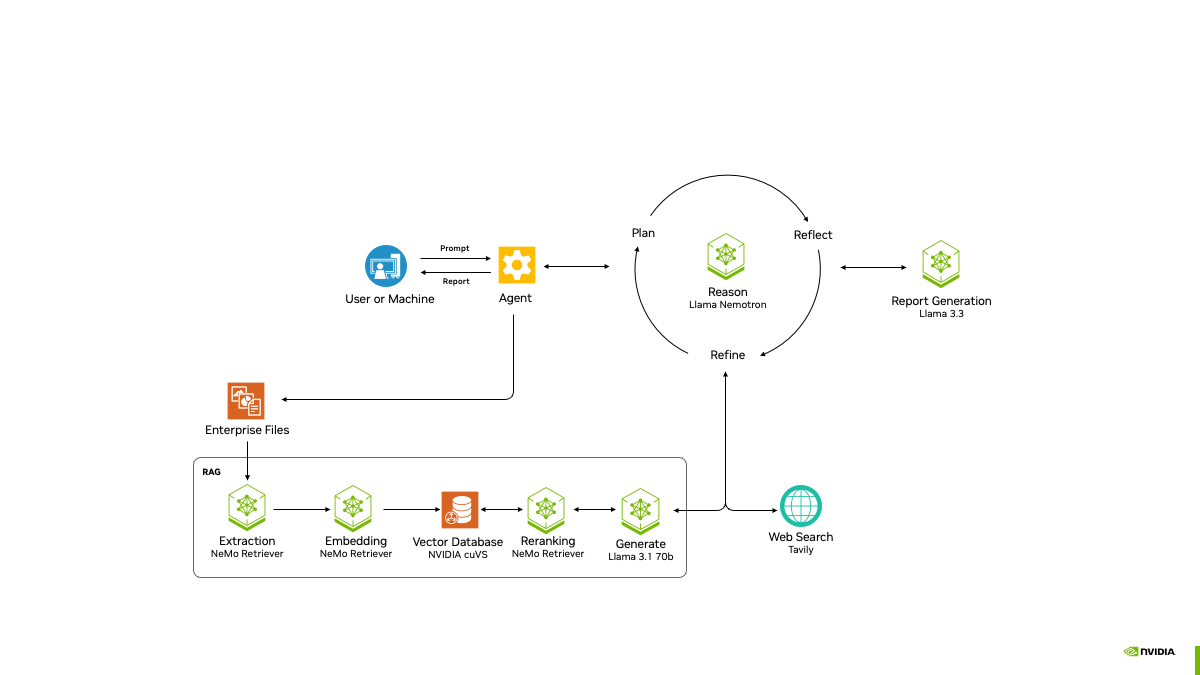 Набор инструментов AgentIQ также повышает прозрачность с полной отслеживаемостью и профилированием системы, что позволяет организациям контролировать производительность, выявлять неэффективность и иметь детальное представление о том, как генерируется бизнес-аналитика. Эти данные профилирования можно использовать с NVIDIA NIM и библиотекой с открытым исходным кодом NVIDIA Dynamo для оптимизации производительности агентских систем. Благодаря этим инструментам предприятиям будет проще объединять команды ИИ-агентов в таких решениях, как Agentforce от Salesforce, поиск Atlassian Rovo в Confluence и Jira, а также ИИ-платформа ServiceNow для трансформации бизнеса, чтобы устранить разрозненность, оптимизировать задачи и сократить время ответа с дней до часов. AgentIQ также интегрируется с такими фреймворками и инструментами, как CrewAI, LangGraph, Llama Stack, Microsoft Azure AI Agent Service и Letta, позволяя разработчикам работать в своей предпочтительной среде. Azure AI Agent Service интегрирован с AgentIQ для обеспечения более эффективных агентов ИИ и оркестровки многоагентных фреймворков с использованием семантического ядра, которое полностью поддерживается в AgentIQ. Возможности ИИ-агентов уже широко используются в различных отраслях. Например, платёжная система Visa использует ИИ-агентов для оптимизации кибербезопасности, автоматизируя анализ фишинговых писем в масштабе. Используя функцию профилирования AI-Q, Visa может оптимизировать производительность и затраты агентов, максимально увеличивая роль ИИ в эффективном реагировании на угрозы, сообщила NVIDIA.
24.03.2025 [01:37], Владимир Мироненко
NVIDIA анонсировала ИИ-модели Llama Nemotron с регулируемым «уровнем интеллекта»NVIDIA анонсировала новое семейство ИИ-моделей Llama Nemotron с расширенными возможностями рассуждения. Основанные на моделях Llama с открытым исходным кодом от Meta✴ Platforms, модели от NVIDIA предназначены для предоставления разработчикам основы для создания продвинутых ИИ-агентов, которые могут от имени своих пользователей независимо или с минимальным контролем работать в составе связанных команд для решения сложных задач. «Агенты — это автономные программные системы, предназначенные для рассуждений, планирования, действий и критики своей работы», — сообщила Кари Бриски (Kari Briski), вице-президент по управлению программными продуктами Generative AI в NVIDIA на брифинге с прессой, пишет VentureBeat. «Как и люди, агенты должны понимать контекст, чтобы разбивать сложные запросы, понимать намерения пользователя и адаптироваться в реальном времени», — добавила она. По словам Бриски, взяв Llama за основу, NVIDIA оптимизировала модель с точки зрения требований к вычислениям, сохранив точность ответов. 
Источник изображений: NVIDIA NVIDIA сообщила, что улучшила новое семейство моделей рассуждений в ходе дообучения, чтобы улучшить многошаговые математические расчёты, кодирование, рассуждения и принятие сложных решений. Это позволило повысить точность ответов моделей до 20 % по сравнению с базовой моделью и увеличить скорость инференса в пять раз по сравнению с другими ведущими рассуждающими open source моделями. Повышение производительности инференса означают, что модели могут справляться с более сложными задачами рассуждений, имеют расширенные возможности принятия решений и позволяют сократить эксплуатационные расходы для предприятий, пояснила компания. Модели Llama Nemotron доступны в микросервисах NVIDIA NIM в версиях Nano, Super и Ultra. Они оптимизированы для разных вариантов развёртывания: Nano для ПК и периферийных устройств с сохранением высокой точности рассуждения, Super для оптимальной пропускной способности и точности при работе с одним ускорителем, а Ultra — для максимальной «агентской точности» в средах ЦОД с несколькими ускорителями. Как сообщает NVIDIA, обширное дообучение было проведено в сервисе NVIDIA DGX Cloud с использованием высококачественных курируемых синтетических данных, сгенерированных NVIDIA Nemotron и другими открытыми моделями, а также дополнительных курируемых наборов данных, совместно созданных NVIDIA. Обучение включало 360 тыс. часов инференса с использованием ускорителей H100 и 45 тыс. часов аннотирования человеком для улучшения возможностей рассуждения. По словам компании, инструменты, наборы данных и методы оптимизации, используемые для разработки моделей, будут в открытом доступе, что предоставит предприятиям гибкость в создании собственных пользовательских рвссуждающих моделей.  Одной из ключевых функций NVIDIA Llama Nemotron является возможность включать и выключать опцию рассуждения. Это новая возможность на рынке ИИ, утверждает компания. Anthropic Claude 3.7 имеет несколько схожую функциональность, хотя она является закрытой проприетарной моделью. Среди моделей с открытым исходным кодом IBM Granite 3.2 тоже имеет переключатель рассуждений, который IBM называет «условным рассуждением». Особенность гибридного или условного рассуждения заключается в том, что оно позволяет системам исключать вычислительно затратные этапы рассуждений для простых запросов. NVIDIA продемонстрировала, как модель может задействовать сложные рассуждения при решении комбинаторной задачи, но переключаться в режим прямого ответа для простых фактических запросов. NVIDIA сообщила, что целый ряд партнёров уже использует модели Llama Nemotron для создания новых мощных ИИ-агентов. Например, Microsoft добавила Llama Nemotron и микросервисы NIM в Microsoft Azure AI Foundry. SAP SE использует модели Llama Nemotron для улучшения возможностей своего ИИ-помощника Joule и портфеля решений SAP Business AI. Кроме того, компания использует микросервисы NVIDIA NIM и NVIDIA NeMo для повышения точности завершения кода для языка ABAP. ServiceNow использует модели Llama Nemotron для создания ИИ-агентов, которые обеспечивают повышение производительности и точности исполнения задач предприятий в различных отраслях. Accenture сделала рассуждающие модели NVIDIA Llama Nemotron доступными на своей платформе AI Refinery. Deloitte планирует включить модели Llama Nemotron в свою недавно анонсированную платформу агентского ИИ Zora AI. Atlassian и Box также работают с NVIDIA, чтобы гарантировать своим клиентам доступ к моделям Llama Nemotron.
17.03.2025 [11:09], Сергей Карасёв
Toshiba открыла в Германии лабораторию инноваций в области HDDКорпорация Toshiba Electronics Europe GmbH объявила о создании лаборатории инноваций в области жёстких дисков в Дюссельдорфе (Германия). Специалисты HDD Innovation Lab займутся оценкой конфигураций систем на базе HDD для крупных IT-развёртываний, таких как сети хранения данных (SAN), масштабные сетевые хранилища (NAS), платформы видеонаблюдения и облачные сервисы. Как отмечает Райнер Каезе (Rainer Kaese), старший менеджер по развитию HDD-направления Toshiba, SSD обеспечивают существенные преимущества перед HDD в плане скоростных показателей. Однако при хранении огромных массивов данных, например, для приложений ИИ, формирование систем большой ёмкости на основе SSD оказывается нецелесообразным с финансовой точки зрения: стоимость изделий на базе флеш-памяти примерно в семь раз выше по сравнению с HDD при сопоставимой вместимости. 
Источник изображения: Toshiba Кроме того, по словам Каезе, корпорация Toshiba продемонстрировали, что 60 жёстких дисков в программно-определяемом хранилище ZFS могут заполнить всю пропускную способность сети 100GbE. Таким образом, для определённых типов задач применение HDD оказывается более выгодным, нежели использование дорогостоящих, но скоростных SSD. Лаборатория HDD Innovation Lab сфокусируется на оценках конфигураций RAID и масштабируемых СХД для корпоративных клиентов, дата-центров и облачных провайдеров. Ключевой особенностью площадки является возможность осуществлять тестирование для различных архитектур. Лаборатория объединяет все основные компоненты СХД на базе жёстких дисков, такие как различные серверы, массивы JBOD, шасси, контроллеры, кабели и сопутствующее ПО. В частности, задействованы одноузловые серверы, поддерживающие до 78 HDD суммарной вместимостью до 2 Пбайт при установке современных накопителей большой ёмкости. Площадка оснащена точным оборудованием для анализа энергопотребления. Лаборатория займётся выполнением оценочных работ для клиентов и партнёров в Европе и на Ближнем Востоке. Результаты тестирования в виде технических документов и отчётов будут доступны на сайте Toshiba Storage.
13.03.2025 [23:30], Владимир Мироненко
Бывший глава Google предупредил об опасности стремления США к доминированию в области ИИ
software
безопасность
ии
информационная безопасность
китай
прогноз
разработка
санкции
сша
ускоритель
цод
Бывший глава Google Эрик Шмидт (Eric Schmidt) опубликовал статью «Стратегия сверхразума» (Superintelligence Strategy), написанную в соавторстве с Дэном Хендриксом (Dan Hendrycks), директором Центра безопасности ИИ, и Александром Вангом (Alexandr Wang), основателем и генеральным директором Scale AI, в которой высказывается мнение о том, что США следует воздержаться от реализации аналога «Манхэттенского проекта» для достижения превосходства в области ИИ, поскольку это спровоцирует упреждающие киберответы со стороны, например, Китая, пишет The Register. Авторы статьи утверждают, что любое государство, которое создаст супер-ИИ, будет представлять прямую угрозу для других стран, и они, стремясь обеспечить собственное выживание, будут вынуждены саботировать такие проекты ИИ. Любая «агрессивная попытка одностороннего доминирования в области ИИ приведёт к превентивному саботажу со стороны конкурентов», который может быть реализован в виде шпионажа, кибератак, тайных операций по деградации обучения моделей и даже прямого физического удара по ИИ ЦОД. Авторы считают, что в области ИИ мы уже близки к доктрине взаимного гарантированного уничтожения (Mutual Assured Destruction, MAD) времён Холодной войны. Авторы дали нынешнему положению название «гарантированное взаимное несрабатывание ИИ» (Mutual Assured AI Malfunction, MAIM), при котором проекты ИИ, разрабатываемые государствами, ограничены взаимными угрозами саботажа. 
Источник изображения: Igor Omilaev/unsplash.com Вместе с тем ИИ, как и ядерные программы в своё время, может принести пользу человечеству во многих областях, от прорывов в разработке лекарств до автоматизации процессов производства, использование ИИ важно для экономического роста и прогресса в современном мире. Согласно статье, государства могут выбрать одну из трех стратегий.
Комментируя предложение Комиссии по обзору экономики и безопасности США и Китая (USCC) о госфинансирования США своего рода «Манхэттенского проекта» по созданию суперинтеллекта в какому-нибудь укромном уголке страны, авторы статьи предупредили, что Китай отреагирует на этот шаг, что приведёт лишь к длительному дисбалансу сил и постоянной нестабильности. 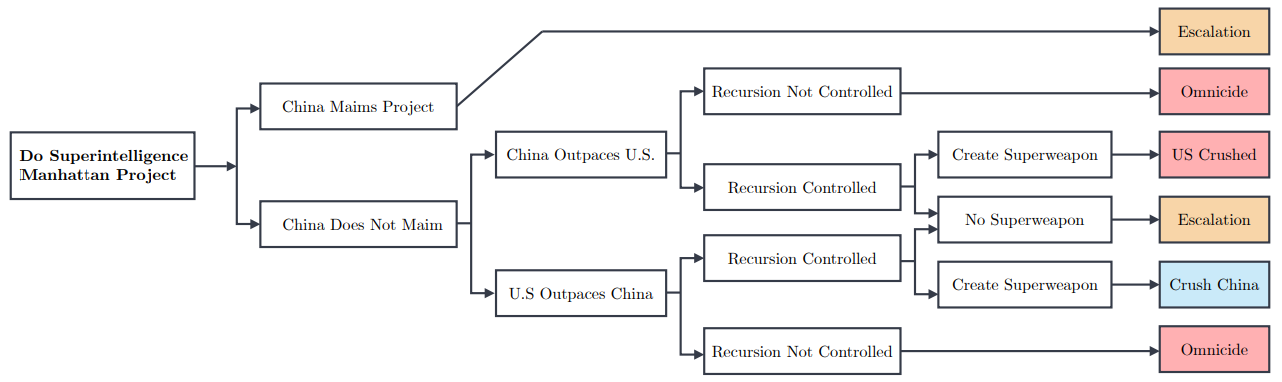
Источник: Superintelligence Strategy: Expert Version Авторы статьи считают, что государства должны отдавать приоритет доктрине сдерживания, а не победе в гонке за искусственный сверхразум. MAIM подразумевает, что попытки любого государства достичь стратегической монополии в области ИИ столкнутся с ответными мерами со стороны других стран, а также приведут к соглашениям, направленным на ограничение поставок ИИ-чипов и open source моделей, которые по смыслу будут аналогичны соглашениям о контроле над ядерным оружием. Чтобы обезопасить себя от атак на государственном уровне с целью замедлить развитие ИИ, в статье предлагается строить ЦОД в удалённых местах, чтобы минимизировать возможный ущерб, пишет Data Center Dynamics. Тот, кто хочет нанести ущерб работе других стран в сфере ИИ, может начать с кибератак: «Государства могут “отравить” данные, испортить веса и градиенты моделей, нарушить работу ПО, которое обрабатывают ошибки ускорителей и управляет питанием и охлаждением…». 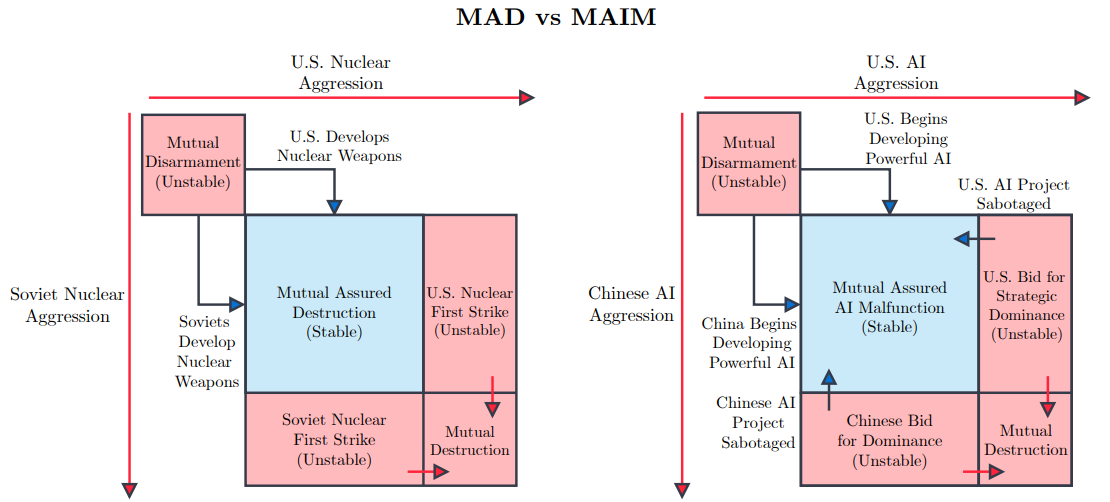
Источник: Superintelligence Strategy: Expert Version Снизить вероятность атак поможет и прозрачность разработок. ИИ можно использовать для оценки безопасности других ИИ-проектов, что позволит избежать атак на «гражданские» ЦОД. Вместе с тем не помешает и прозрачность цепочек поставок. Поскольку ИИ-ускорители существуют в реальном, а не виртуальном мире, отследить их перемещение не так уж трудно. Таким образом, даже устаревшие или признанные негодными чипы не смогут попасть на чёрный рынок — их предлагается утилизировать с той же степенью ответственности, что и химические или ядерные материалы. Впрочем, соблюдение всех этих рекомендаций не устранит главную проблему — зависимость от Тайваня в плане производства передовых чипов, которая является критической для США, говорят авторы статьи. Поэтому западным странам следует разработать гарантированные цепочки поставок ИИ-чипов. Для этого потребуются значительные инвестиции, но это необходимо для обеспечения конкурентоспособности.
06.02.2025 [16:46], Руслан Авдеев
Индия должна стать лидером в создании малых «рассуждающих» ИИ-моделей, заявил Сэм АльтманНа заключительном этапе азиатского турне глава OpenAI Сэм Альтман (Sam Altman) заявил, что Индия способна стать одним из лидеров в гонке ИИ, особенно — в деле создании малых «рассуждающих» моделей (SLM). Альтман выразил интерес к динамичной экосистеме местных разработчиков, которая может стать ключевым элементом расширения OpenAI, сообщает DigiTimes. По словам Альтмана, Индия стала вторым по величине рынком для компании, поскольку за последний год число пользователей утроилось. Во время визита Альтман встретился с представителями правительства страны. Хотя затраты на разработку новых моделей по-прежнему высоки, Альтман признал, что прогресс в области ИИ может значительно снизить зависимость от дорогостоящего оборудования, а отдача от вложений в ИИ будет расти экспоненциально. Это приведёт к ежегодному десятикратному снижению стоимости «единиц интеллекта» — условного измерения вычислительной эффективности ИИ. По словам бизнесмена, мир достиг стадии невероятного прогресса в сфере «дистилляции» моделей. 
Источник изображения: Shubhangee Vyas/unsplash.com Хотя обучение даже малых моделей остаётся довольно дорогим, именно небольшие модели с возможностью «рассуждений» приведут буквально к взрыву креативности. И Индия должна быть на переднем крае прогресса. Альтман особенно выделил потенциал проектов в здравоохранении и образовании, где ИИ способен стать движущей силой преобразований. Сейчас индийские компании обратили внимание на открытые модели, включая DeepSeek. Стоит отметить, что в ходе визита в Индию в июне 2023 года Альтман охарактеризовал шансы страны на создание ИИ-моделей уровня ChatGPT как «совершенно безнадёжные». Теперь же он приятно удивлён достижениями Индии в этой области. Глава OpenAI отдельно пояснил, что прежние высказывания относились к трудностям конкуренции с IT-гигантами при создании экономически эффективных моделей. Альтман отдельно подчеркнул, что стоимость API OpenAI значительно упала, и намекнул, что в будущем тоже возможно появление open source инициатив. Индия активно продвигает ИИ-проекты в рамках инициативы IndiaAI, подкреплённой инвестициями в объёме ₹103,7 млрд рупий ($1,2 млрд). Местную большую языковую модель (LLM) власти намерены создать в течение десяти месяцев. Представители Министерства коммуникаций и информационных технологий Индии заявили, что создание базовой структуры уже завершено, теперь усилия разработчиков направлены на создание вариантов моделей, соответствующих уникальным языковым и культурным требованиям страны.
03.02.2025 [15:21], Сергей Карасёв
Реальные затраты DeepSeek на создание ИИ-моделей на порядки выше заявленных, но достижений компании это не умаляетКитайский стартап DeepSeek наделал много шума в Кремниевой долине, анонсировав «рассуждающую» ИИ-модель DeepSeek R1 c 671 млрд параметров. Утверждается, что при её обучении были задействованы только 2048 ИИ-ускорителей NVIDIA H800, а затраты на данные работы составили около $6 млн. Это бросило вызов многим западным конкурентам, таким как OpenAI, а акции ряда крупных ИИ-компаний начали падать в цене. Однако, как сообщает ресурс SemiAnalysis, фактические расходы DeepSeek на создание ИИ-инфраструктуры и обучение нейросетей могут быть гораздо выше. Стартап DeepSeek берёт начало от китайского хедж-фонда High-Flyer. В 2021 году, ещё до введения каких-либо экспортных ограничений, эта структура приобрела 10 тыс. ускорителей NVIDIA A100. В мае 2023 года с целью дальнейшего развития направления ИИ из High-Flyer была выделена компания DeepSeek. После этого стартап начал более активное расширение вычислительной ИИ-инфраструктуры. По данным SemiAnalysis, на сегодняшний день DeepSeek имеет доступ примерно к 10 тыс. изделий NVIDIA H800 и 10 тыс. NVIDIA H100. Кроме того, говорится о наличии около 30 тыс. ускорителей NVIDIA H20, которые совместно используются High-Flyer и DeepSeek для обучения ИИ, научных исследований и финансового моделирования. Таким образом, в общей сложности DeepSeek может использовать до 50 тыс. ускорителей NVIDIA при работе с ИИ, что в разы больше заявленной цифры в 2048 ускорителей. 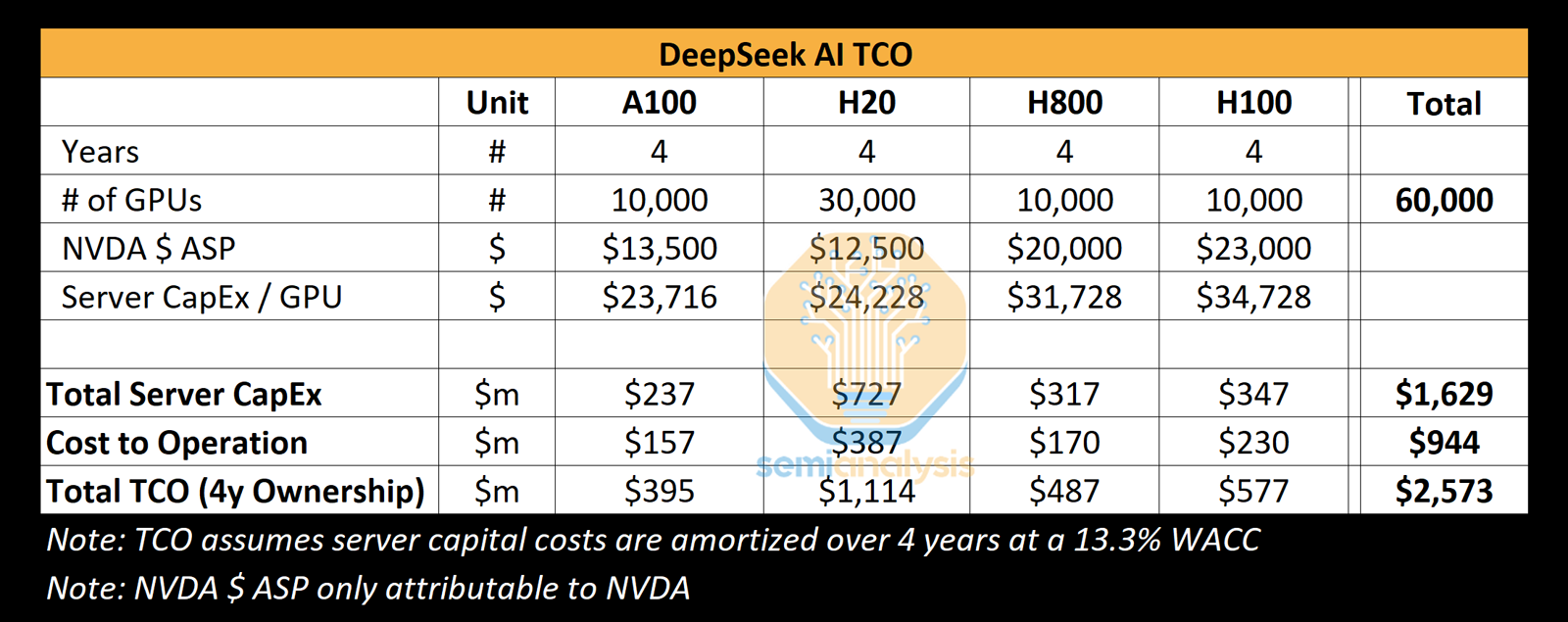
Источник изображения: SemiAnalysis Кроме того, SemiAnalysis сообщает, что общие капитальные затраты на ИИ-серверы для DeepSeek составили около $1,6 млрд, тогда как операционные расходы могут достигать $944 млн. Это подрывает заявления о том, что DeepSeek заново изобрела процесс обучения ИИ и инференса с существенно меньшими инвестициями, чем лидеры отрасли. Цифра в $6 млн не учитывает затраты на исследования, тюнинг модели, обработку данных и пр. На самом деле, как подчёркивается, DeepSeek потратила более $500 млн на разработки с момента своего создания. И всё же DeepSeek имеет ряд преимуществ перед другими участниками глобального ИИ-рынка. В то время как многие ИИ-стартапы полагаются на внешних поставщиков облачных услуг, DeepSeek эксплуатирует собственные дата-центры, что позволяет быстрее внедрять инновации и полностью контролировать разработку, оптимизируя расходы. Кроме того, DeepSeek остаётся самофинансируемой компанией, что обеспечивает гибкость и позволяет более оперативно принимать решения. Плюс к этому DeepSeek нанимает специалистов исключительно из Китая, уделяя особое внимание не формальным записям в аттестатах, а практическим навыкам работы и способностям эффективно выполнять поставленные задачи. Некоторые ИИ-исследователи в DeepSeek зарабатывают более $1,3 млн в год, что говорит об их высочайшей квалификации.
27.01.2025 [13:16], Сергей Карасёв
В Евросоюзе появится суверенная облачная платформа Virt8raРяд европейских технологических организаций, по сообщению ресурса ITPro, объединили усилия с целью создания суверенной облачной платформы, призванной обеспечить переносимость и совместимость между сервисами различных поставщиков облачных услуг. Проект получил название Virt8ra. В инициативе принимают участие Arsys, BIT, Гданьский политехнический университет (Gdańsk Tech), Infobip, IONOS, Kontron, Mondragon и Oktawave, а координатором выступает OpenNebula Systems. Вычислительные мощности и ресурсы хранения данных планируется предоставлять во многих странах Евросоюза, включая Хорватию, Нидерланды, Польшу, Германию, Словению и Испанию. «Благодаря этому сотрудничеству мы вносим вклад в укрепление цифрового суверенитета Европы и стимулируем инновации на всём континенте», — отметил Йоже Орехар (Jože Orehar), руководитель подразделения облачных платформ Kontron. Virt8ra является частью масштабной программы IPCEI-CIS (Important Project of Common European Interest on Next Generation Cloud Infrastructure and Services) — это европейский проект развития облачной инфраструктуры и услуг следующего поколения. Инициатива, одобренная Европейской комиссией в декабре 2023 года, поддерживается 12 государствами — членами ЕС. Проект направлен на стимулирование исследований и увеличение инвестиций в технологии периферийных и облачных вычислений в ЕС, а также на создание децентрализованной периферийной инфраструктуры. 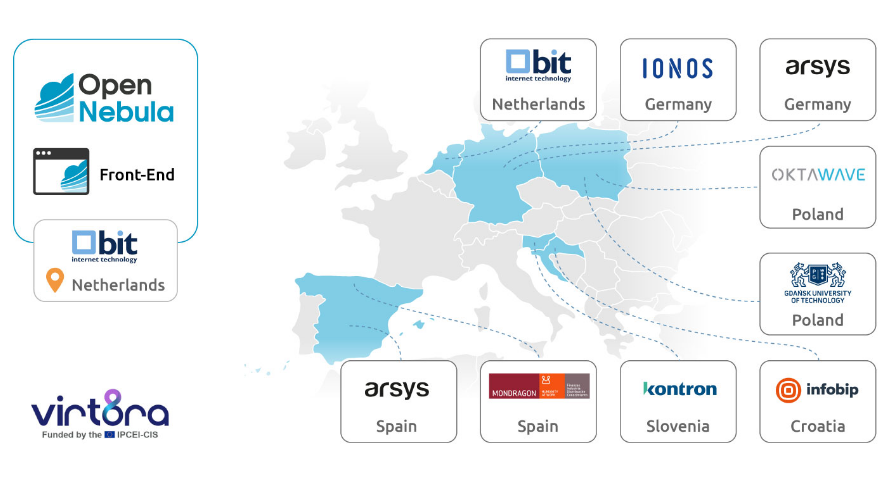
Источник изображения: OpenNebula Systems В рамках Virt8ra более 30 европейских компаний разрабатывают стек ПО с открытым исходным кодом для виртуализации. Целью является создание надёжной системы для управления цифровыми инфраструктурами, которая предоставит европейским предприятиям и государственным организациям улучшенную гибкость, технологический суверенитет и возможность получить полный контроль над своими IT-средами без ограничений, связанных с действующими моделями лицензирования и поддержки. Инфраструктура Virt8ra рассматривается как способ снижения зависимости компаний и госструктур Евросоюза от гиперскейлеров и облачных провайдеров из США. Текущая версия платформы поддерживает централизованное управление физическими ресурсами, виртуальными машинами и кластерами Kubernetes, а также обеспечивает возможность миграции, что позволяет клиентам развёртывать, запускать и переносить приложения между разными регионами и поставщиками облачных услуг.
24.01.2025 [23:38], Владимир Мироненко
Платформа GenAI от DigitalOcean упростит создание ИИ-агентовОблачный провайдер DigitalOcean представил платформу GenAI, которая позволяет использовать базовые модели от сторонних поставщиков для создания и развёртывания агентов ИИ за считанные минуты без необходимости глубоких знаний в области ИИ или машинного обучения. Как сообщает DigitalOcean, интуитивно понятная работа в GenAI позволяет клиентам вне зависимости от уровня подготовки настраивать агентов с доступом к надёжным конвейерам данных и многоагентным командам. DigitalOcean GenAI позволяет компаниям создавать чат-боты на основе базовых моделей сторонних поставщиков (Anthropic, Meta✴, Mistral и др.) для анализа документов, семантического поиска, создания изображений и т.д. Платформа создана так, чтобы быть независимой от фреймворков. Платформа упрощает и создание агентов, специфичных для конкретных вариантов использования, привнося контекстные данные в базовые LLM. Клиенты смогут не только извлекать неструктурированные данные из файлов, но и структурированные данные из баз данных или обращаясь к API, чтобы дополнять подсказки и задействовать Retrieval Augmented Generation (RAG), обеспечивая агентам доступ к точной и актуальной информации. С помощью вызываемых функций можно дописать кастомный код, чтобы расширить возможности своего агента. 
Источник изображения: DigitalOcean Встроенные ограничители (guardrails) позволяют повысить достоверность ответов агента, помогая отфильтровывать неправильные или ненадлежащие результаты. А возможность частных подключений и наличие готового интерфейса для чат-ботов упрощают запуск этих агентов на веб-сайте клиента. В будущем появится возможность обращаться к источникам данным по URL, поддержка конвейеров AgentOps и CI/CD, тонкая настройка моделей и многое другое. |
|