Материалы по тегу: sc23
|
13.11.2023 [17:00], Сергей Карасёв
Первый в Европе экзафлопсный суперкомпьютер Jupiter получит 24 тыс. гибридных суперчипов NVIDIA Grace HopperКомпания NVIDIA в ходе конференции по высокопроизводительным вычислениям SC23 сообщила о том, что её суперчип GH200 Grace Hopper станет одной из ключевых составляющих НРС-системы Jupiter — первого европейского суперкомпьютера экзафлопсного класса. 
Узел BullSequana XH3000 (Источник здесь и далее: NVIDIA) Jupiter — проект Европейского совместного предприятия по развитию высокопроизводительных вычислений (EuroHPC JU). Комплекс расположится в Юлихском исследовательском центре (FZJ) в Германии. В создании суперкомпьютера участвуют NVIDIA, ParTec, Eviden и SiPearl. Архитектура системы модульная, что позволяет адаптировать её под разные классы задач. В основу одного из основных блоков Jupiter ляжет платформа Eviden BullSequana XH3000 с прямым жидкостным охлаждением, а в состав каждого узла войдут модули Quad GH200. Общее количество суперчипов составит 23752. В качестве интерконнекта будет применяться NVIDIA Quantum-2 InfiniBand. Быстродействие на операциях обучения ИИ составит до 93 Эфлопс, а FP64-производительность должна достичь 1 Эфлопс. При этом общая потребляемая мощность Jupiter составит всего 18,2 МВт.  Применять систему Jupiter планируется для решения наиболее сложных задач. Среди них — моделирование климата и погоды в высоком разрешении (на базе NVIDIA Earth-2), создание новых лекарственных препаратов (NVIDIA BioNeMo и NVIDIA Clara), исследования в области квантовых вычислений (NVIDIA cuQuantum и CUDA Quantum), промышленное проектирование (NVIDIA Modulus и NVIDIA Omniverse). Ввод Jupiter в эксплуатацию запланирован на 2024 год.
13.11.2023 [16:16], Сергей Карасёв
OSS представила защищённый ИИ-сервер Gen 5 AI Transportable на базе NVIDIA H100Компания One Stop Systems (OSS) на конференции по высокопроизводительным вычислениям SC23 представила сервер Gen 5 AI Transportable, предназначенный для решения задач ИИ и машинного обучения на периферии. Устройство, рассчитанное на монтаж в стойку, выполнено в корпусе уменьшенной глубины. Новинка соответствует американским военным стандартам в плане устойчивости к ударам, вибрации, диапазону рабочих температур и пр. Сервер может применяться в составе мобильных дата-центров, на борту грузовиков, самолётов и подводных лодок. Возможна установка четырёх ускорителей NVIDIA H100 и до 16 NVMe SSD суммарной вместимостью до 1 Пбайт. Говорится о поддержке до 35 одновременных ИИ-нагрузок. Кроме того, могут применяться сетевые решения стандарта 400 Гбит/с. При необходимости можно подключить NAS-хранилище в усиленном исполнении. 
Источник изображения: OSS Для сервера доступны различные варианты охлаждения: воздушное, автономное жидкостное или внешний теплообменник с жидкостным контуром. Поддерживаются различные варианты организации питания с переменным и постоянным током для использования на суше, в воздухе и море. При использовании СЖО ускорители H100, по всей видимости, комплектуются водоблоком EK-Pro NVIDIA H100 GPU WB. Реализована фирменная архитектура Open Split-Flow: она обеспечивает высокую эффективность охлаждения даже при небольшой скорости потока жидкости, что позволяет применять не слишком мощные помпы или помпы, работающие с невысокой скоростью. Микроканалы, фрезерованные на станке с ЧПУ, обладают минимальным гидравлическим сопротивлением потоку. Водоблок имеет однослотовое исполнение. 
Источник изображения: EKWB Предусмотрено проприетарное ПО U-BMC (Unified Baseboard Management Controller) для динамического управления скоростью вентиляторов, мониторинга системы и пр. Сервер подходит для монтажа в большинство 19″ стоек.
12.11.2023 [18:51], Сергей Карасёв
ORCA Computing предоставит Польше две квантовые вычислительные системыБританский разработчик квантовых систем ORCA Computing выбран Познаньским центром суперкомпьютерных и сетевых технологий (PSNC) в Польше в качестве поставщика двух квантовых компьютеров. Эти системы призваны ускорить решение задач в ряде научных и прикладных областей, включая биологию, химию и машинное обучение. Речь идёт о квантовых фотонных компьютерах ORCA Computing PT-1. Они будут установлены в центре высокопроизводительных вычислений PSNC в Познане в ноябре и декабре нынешнего года и интегрированы в существующую HPC-инфраструктуру. Ситсемы закуплены в рамках проекта EuroHPC-PL. Квантовые компьютеры PT-1 используют источник одиночных фотонов и программируемые сети светоделителей для реализации квантовой памяти. Результаты вычислений представляют собой сложную статистику, где количество фотонов отражает вероятность распределения. Система может быть интегрирована с классическими HPC-платформами. Доступен специализированный комплект для разработки, который поддерживает гибридные квантово-классические алгоритмы с QPU и GPU. 
Источник изображения: ORCA Computing Технология ORCA Computing предусматривает использование одиночных фотонов в качестве носителя. Это не только позволяет системе естественным образом взаимодействовать с оптическими сетями, но также обеспечивает модульность и гибкость архитектуры с возможностью последующего обновления. Задействована проприетарная технология мультиплексирования для управления синхронизацией, частотой и маршрутизацией одиночных фотонов: данная методика позволяет достигать высокой плотности данных, что даёт возможность осуществлять полномасштабные квантовые вычисления с гораздо меньшим количеством компонентов.
11.11.2023 [23:59], Алексей Степин
СуперДупер: GigaIO SuperDuperNODE позволяет объединить посредством PCIe сразу 64 ускорителяКомпания GigaIO, чьей главной разработкой является система распределённого интерконнекта на базе PCI Express под названием FabreX, поставила новый рекорд — в новой платформе разработчикам удалось удвоить количество одновременно подключаемых PCIe-устройств, увеличив его с 32 до 64. О разработках GigaIO мы рассказывали читателям неоднократно. Во многом они действительно уникальны, поскольку созданная компанией композитная инфраструктура позволяет подключать к одному или нескольким серверам существенно больше различных ускорителей, нежели это возможно в классическом варианте, но при этом сохраняет высокий уровень утилизации этих ускорителей. 
GigaIO SuperNODE. Источник изображений здесь и далее: GigaIO В начале года компания уже демонстрировала систему с 16 ускорителями NVIDIA A100, а летом GigaIO представила мини-кластер SuperNODE. В различных конфигурациях система могла содержать 32 ускорителя AMD Instinct MI210 или 24 ускорителя NVIDIA A100, дополненных СХД ёмкостью 1 Пбайт. При этом система в силу особенностей FabreX не требовала какой-либо специфической настройки перед работой. 
FabreX позволяет физически объединить все типы ресурсов на базе существующего стека технологий PCI Express На этой неделе GigaIO анонсировала новый вариант своей HPC-системы, получившей незамысловатое название SuperDuperNODE. В ней она смогла удвоить количество ускорителей с 32 до 64. Как и прежде, система предназначена, в первую очередь, для использования в сценариях генеративного ИИ, но также интересна она и с точки зрения ряда HPC-задач, в частности, вычислительной гидродинамики (CFD). Система SuperNODE смогла завершить самую сложную в мире CFD-симуляцию всего за 33 часа. В ней имитировался полёт 62-метрового авиалайнера Конкорд. Хотя протяжённость модели составляет всего 1 сек, она очень сложна, поскольку требуется обсчёт поведения 40 млрд ячеек объёмом 12,4 мм3 на протяжении 67268 временных отрезков. 29 часов у системы ушло на обсчёт полёта, и ещё 4 часа было затрачено на рендеринг 3000 4К-изображений. С учётом отличной масштабируемости при использовании SuperDuperNODE время расчёта удалось сократить практически вдвое. Как уже упоминалось, FabreX позволяет малой кровью наращивать число ускорителей и иных мощных PCIe-устройств на процессорный узел при практически идеальном масштабировании. Обновлённая платформа не подвела и в этот раз: в тесте HPL-MxP пиковый показатель утилизации составил 99,7 % от теоретического максимума, а в тестах HPL и HPCG — 95,2 % и 88 % соответственно. Компания-разработчик сообщает о том, что программное обеспечение FabreX обрело завершённый вид и без каких-либо проблем обеспечивает переключение режимов SuperNODE между Beast (система видна как один большой узел), Swarm (множество узлов для множества нагрузок) и Freestyle Mode (каждой нагрузке выделен свой узел с заданным количеством ускорителей). Начало поставок SuperDuperNODE запланировано на конец года. Партнёрами, как и в случае с SuperNODE, выступят Dell и Supermicro.
08.11.2023 [20:00], Игорь Осколков
Счёт на секунды: ИИ-суперкомпьютер NVIDIA EOS с 11 тыс. ускорителей H100 поставил рекорды в бенчмарках MLPerf TrainingВместе с публикацией результатов MLPerf Traning 3.1 компания NVIDIA официально представила новый ИИ-суперкомпьютер EOS, анонсированный ещё весной прошлого года. Правда, с того момента машина подросла — теперь включает сразу 10 752 ускорителя H100, а её FP8-производительность составляет 42,6 Эфлопс. Более того, практически такая же система есть и в распоряжении Microsoft Azure, и её «кусочек» может арендовать каждый, у кого найдётся достаточная сумма денег. 
Изображения: NVIDIA Суммарно EOS обладает порядка 860 Тбайт памяти HBM3 с агрегированной пропускной способностью 36 Пбайт/с. У интерконнекта этот показатель составляет 1,1 Пбайт/с. В данном случае 32 узла DGX H100 объединены посредством NVLink в блок SuperPOD, а за весь остальной обмен данными отвечает 400G-сеть на базе коммутаторов Quantum-2 (InfiniBand NDR). В случае Microsoft Azure конфигурация машины практически идентичная с той лишь разницей, что для неё организован облачный доступ к кластерам. Но и сам EOS базируется на платформе DGX Cloud, хотя и развёрнутой локально.   В рамках MLPerf Training установила шесть абсолютных рекордов в бенчмарках GPT-3 175B, Stable Diffusion (появился только в этом раунде), DLRM-dcnv2, BERT-Large, RetinaNet и 3D U-Net. NVIDIA на этот раз снова не удержалась и добавила щепотку маркетинга на свои графики — когда у тебя время исполнения теста исчисляется десятками секунд, сравнивать свои результаты с кратно меньшими по количеству ускорителей кластерами несколько неспортивно. Любопытно, что и на этот раз сравнивать H100 приходится с Habana Gaudi 2, поскольку Intel не стесняется показывать результаты тестов. 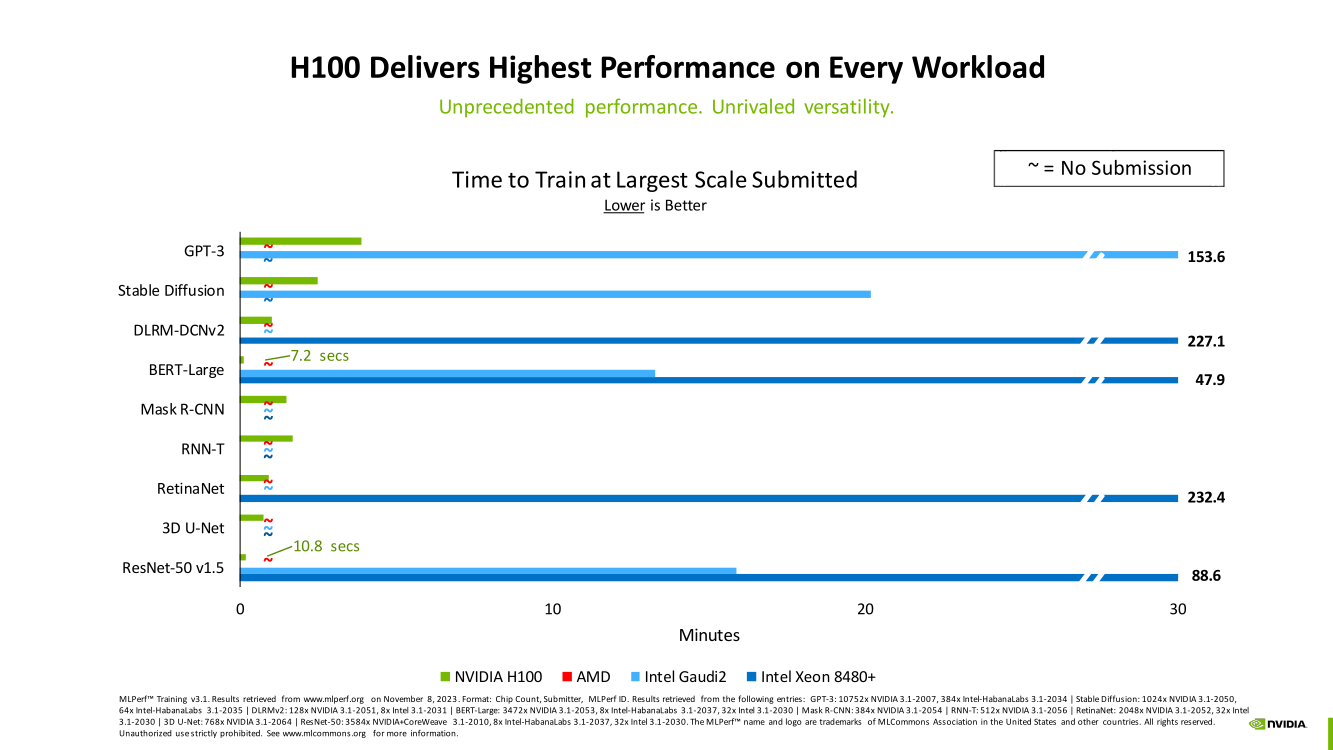 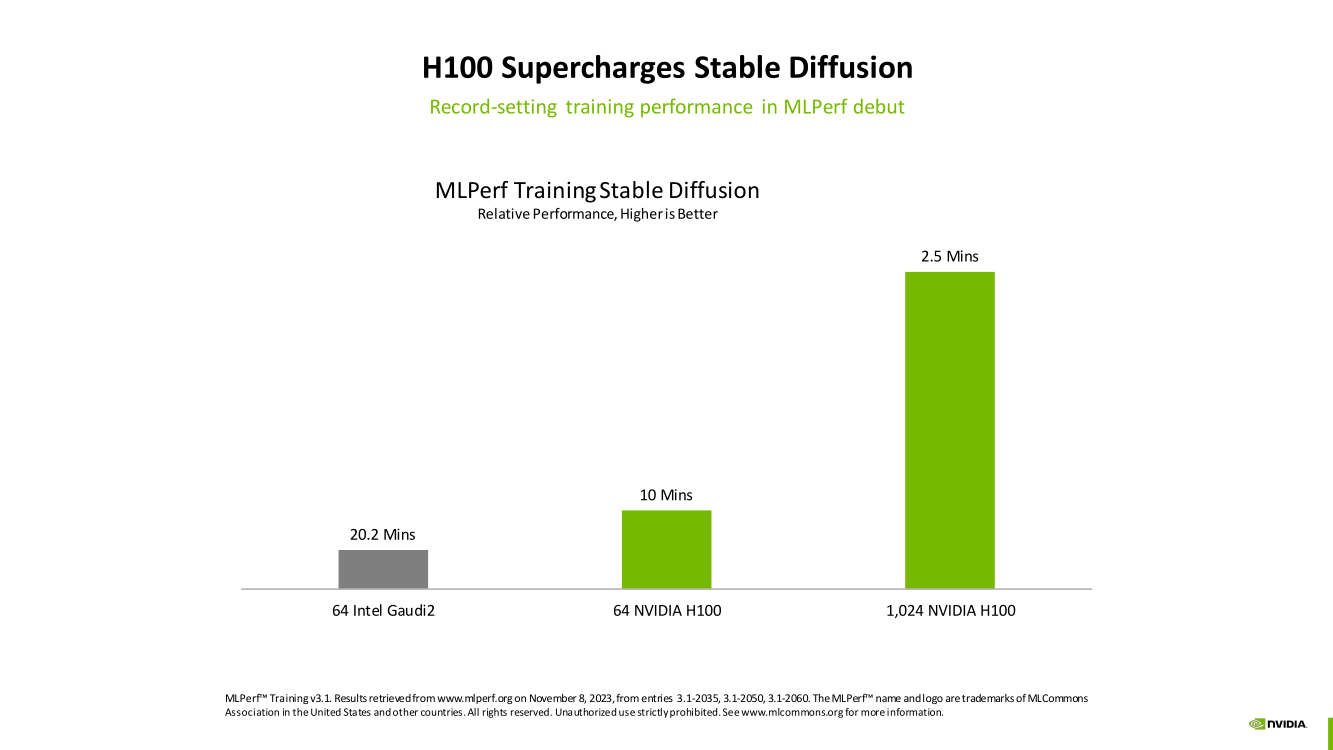 NVIDIA очередной раз подчеркнула, что рекорды достигнуты благодаря оптимизациям аппаратной части (Transformer Engine) и программной, в том числе совместно с MLPerf, а также благодаря интерконнекту. Последний позволяет добиться эффективного масштабирования, близкого к линейному, что в столь крупных кластерах выходит на первый план. Это же справедливо и для бенчмарков из набора MLPerf HPC, где система EOS тоже поставила рекорд. 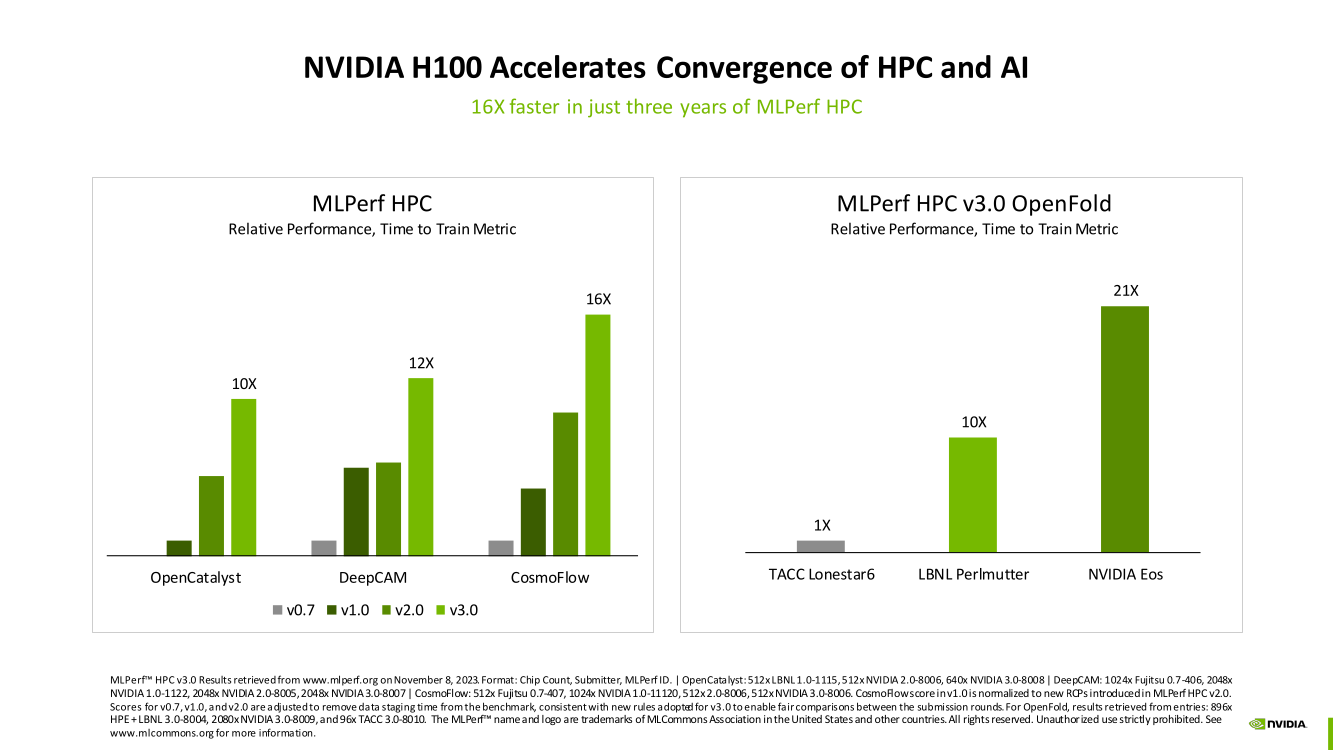 |
|