Материалы по тегу: cpu
|
30.08.2024 [23:53], Алексей Степин
IBM представила процессор Telum II: 8 × 5,5 ГГц, 2,88 Гбайт L4-кеш, улучшенный ИИ-ускоритель и встроенный DPUНесмотря на доминирование архитектур x86 и Arm, а также растущую популярность RISC-V, востребованность классических мейнфреймов IBM на базе z/Architecture по-прежнему остаётся высокой, и компания продолжает активно развивать данное направление. На этой неделе IBM представила наследника Telum — процессор Telum II, в котором не только получили развитие заложенные ранее идеи, но и были реализованы достаточно серьёзные нововведения. Telum II будет выпускаться Samsung по 5-нм техпроцессу 5HPP (43 млрд транзисторов, 600 мм2). Он по-прежнему имеет восемь ядер с фиксированной рабочей частотой 5,5 ГГц. Сами ядра подверглись усовершенствованию, пусть и достаточно минорному: повышена точность предсказания ветвлений, улучшены механизмы сквозной записи и трансляции адресов. Это должно обеспечить новинке 20 % преимущества в пересчёте на процессорный разъём в сравнении с предшественником. Также благодаря новому техпроцессу удалось снизить площадь ядра на 20 %, а энергопотребление — на 15 %. Для поддержания постоянной тактовой частоты в Telum II используется новый блок управления напряжениями. 
Источник изображений: IBM Серьёзно улучшена подсистема кешей: объём кеш-памяти подрос на 40 %, всего разделов L2-кеша десять. Каждый из них имеет объём 36 Мбайт, а латентность не превышает 3,6 нс. Объёмы виртуальных кешей L3 (11,5 нс) и L4 (48,5 нс) выросли до 360 Мбайт (на процессор) и 2,88 Гбайт (на узел) соответственно. Сама технология виртуального кеширования такова, что текущее свободное место в L2 может использоваться для любой задачи, где может быть востребовано. На 30 % повышена пропускная способность связи чипа с внешним миром, а общение на межузловом уровне теперь шифруется.  Встроенный ИИ-блок в Telum II в сравнении с предыдущим поколением стал вчетверо быстрее — 24 Топс. Сам сопроцессор имеет архитектуру, оптимальную для работы с LLM и нагрузками, в которых активно используется сравнительный анализ структурных или текстовых массивов данных. Есть поддержка INT8/FP16. При этом любой ИИ-ускоритель Telum II может работать с любым из ядер в пределах узла (drawer), что в предельной конфигурации даёт производительность на уровне 192 Топс, а для полностью сконфигурированной системы этот показатель равен 768 Топс. «Снаружи» ИИ-ускоритель доступен в виде набора CISC-инструкций.  А вот блок DPU дебютировал в Telum II впервые. Что интересно, архитектурно он не располагается «позади» PCI Express, как это бывает в системах на базе x86 или Arm, а имеет когерентное подключение к кешу L2 процессорных ядер, и при этом имеет свою подсистему кешей. Применение DPU, по словам IBM, позволило снизить энергозатраты на обслуживание операций ввода-вывода на 70 %. DPU жизненно необходим, поскольку на мейнфреймах будут работать тысячи инстансов, а самим системам теперь полагается и внешний ИИ-ускоритель Spyre. 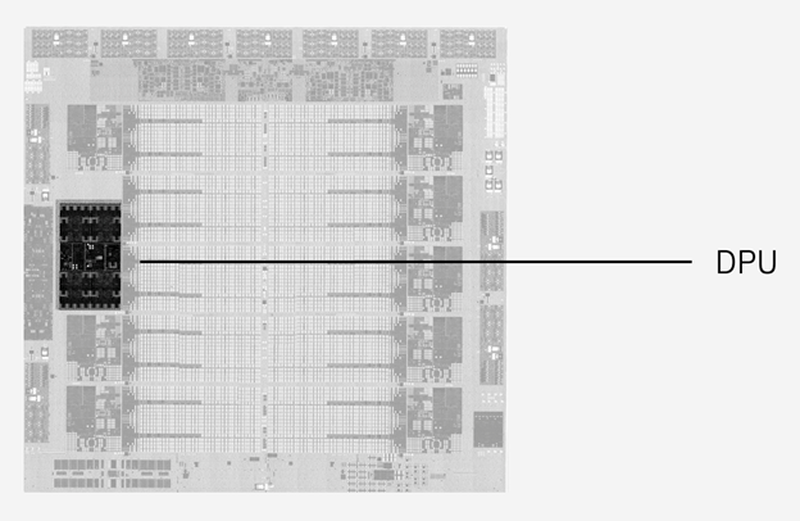 Всего в состав DPU входит четыре кластера по по восемь программируемых микроядер, каждое из которых имеет кеш L1 объёмом 32+32 Кбайт и работает под управлением кастомных протоколов, разработанных IBM. DPU предоставляет шину PCI Express 5.0 и в полной конфигурации c 32 процессорами и 12 модулями расширения по 16 слотов x16 в каждом система на базе Telum II может работать со 192 адаптерами PCIe. 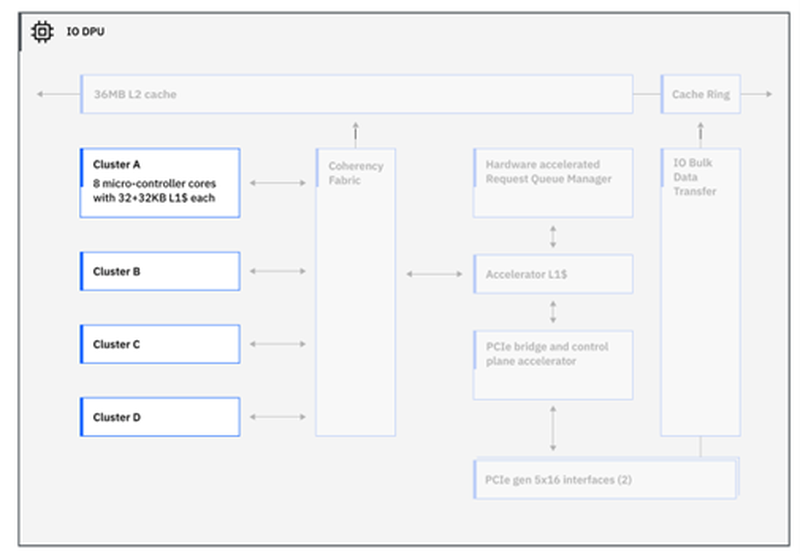 Компания-производитель позиционирует новые системы, как enterpise-решения широкого спектра для сценариев с использованием ИИ, в том числе, в режиме Ensemble AI, в котором одновременно над задачей могут работать модели разного размера и сложности. В этом режиме малая модель выявления мошеннических атак может работать как быстрое средство, а для отдельных, особенно важных транзакций в работу включается более сложная, но и более эффективная модель класса LLM.  Процессоры Telum II станут основой как новых мейнфреймов IBM Z, работающих под управлением классической z/OS, так и Linux. Ожидается, что платформы IBM z17 на базе Telum II будут доступны уже в следующем году.
28.08.2024 [12:32], Сергей Карасёв
Sapphire Rapids Refresh для рабочих станций: Intel Xeon W-2500 и W-3500 получили до 60 ядер и до 112,5 Мбайт кешаКорпорация Intel, по сообщению ресурса VideoCardz, представила процессоры Xeon W-2500 и W-3500 поколения Sapphire Rapids Refresh. Эти чипы предназначены для применения в рабочих станциях и высокопроизводительных настольных компьютерах. Они придут на смену семействам Xeon W-3400 и W-2400. В серию Xeon W-2500 вошли изделия с 26, 22, 18, 14, 12, 10 и 8 ядрами. Во всех случаях поддерживается технология многопоточности. Объём кеша L3 варьируется от 22,5 до 48,75 Мбайт. Версии с 8 и 10 ядрами могут работать с памятью DDR5-4400, все другие модели — с DDR5-4800 (четыре канала). Показатель базовой мощности (Processor Base Power, PBP) варьируется от 175 до 250 Вт. 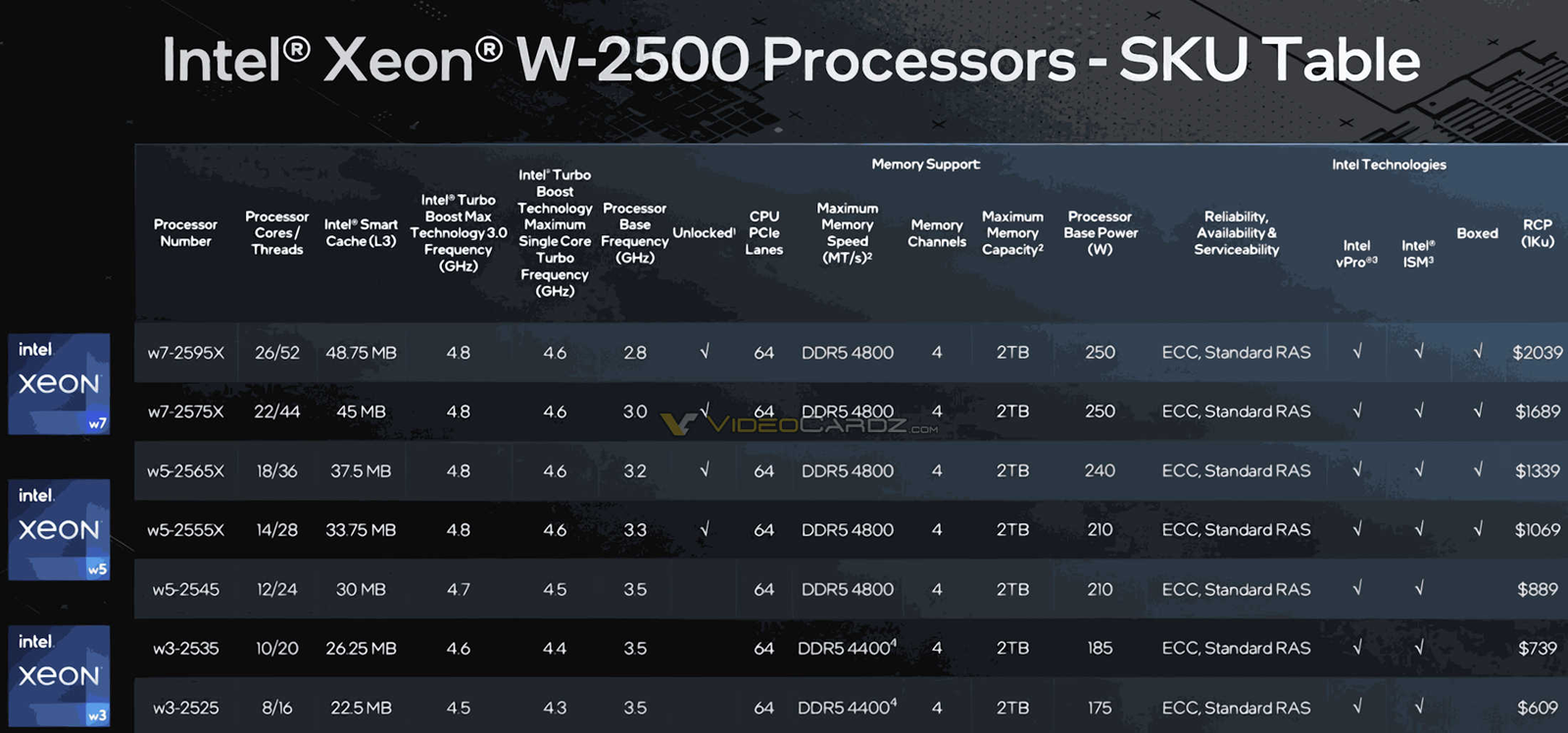
Источник изображений: VideoCardz Семейство Xeon W-2500 возглавляет модель Xeon W7-2595X с 26 ядрами: базовая частота равна 2,8 ГГц, максимальная — 4,8 ГГц. Этот чип, как и другие решения с суффиксом «X», имеет разблокированный множитель, благодаря чему обеспечивается возможность разгона. Все процессоры серии поддерживают 64 линии PCIe 5.0. Цена варьируется от $609 до $2039. 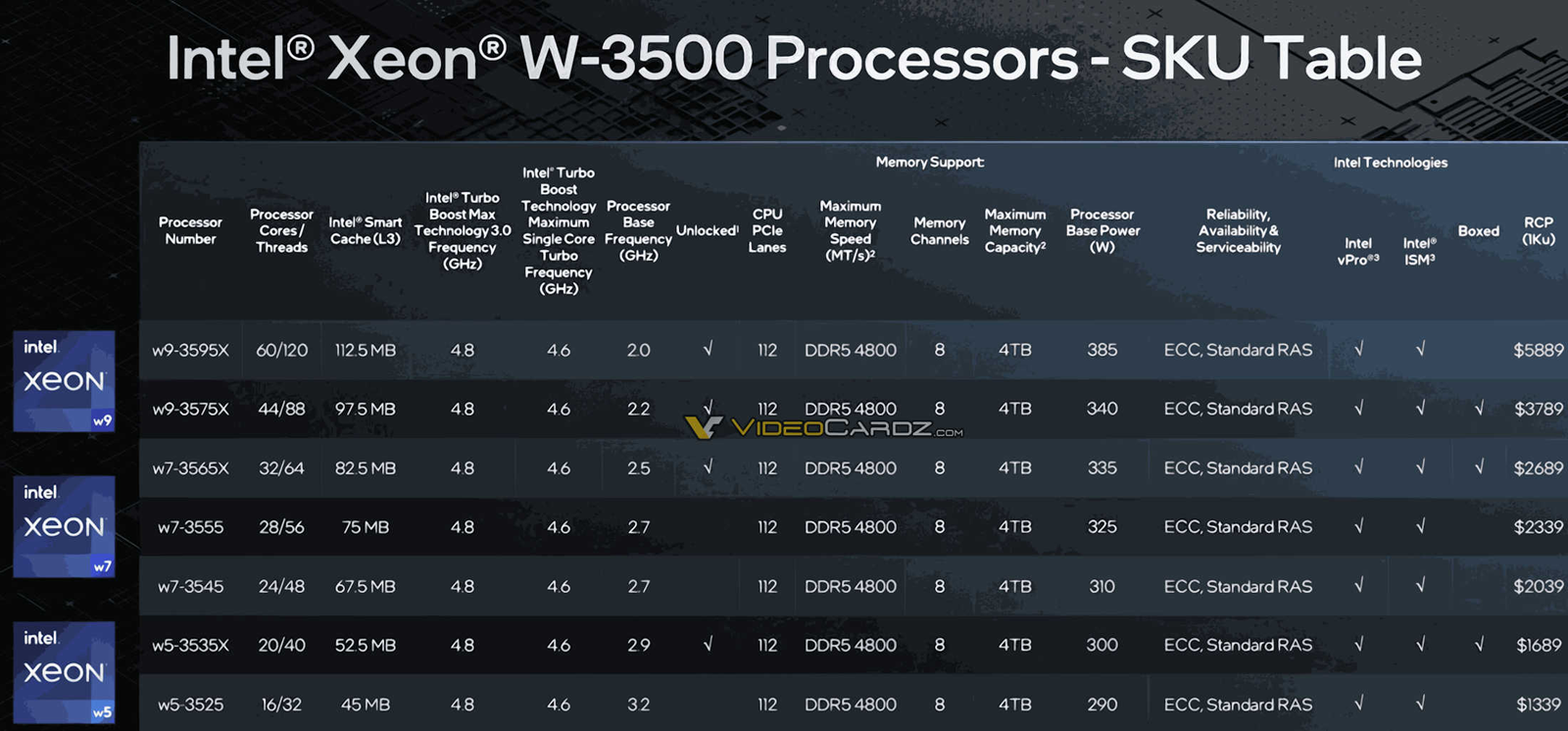 Более мощные изделия Xeon W-3500 насчитывают от 16 до 60 ядер с поддержкой многопоточности. Размер кеша L3 — от 45 до 112,5 Мбайт. Все процессоры могут работать с памятью DDR5-4800 (восемь каналов). Количество линий PCIe 5.0 равно 112. Значение PBP находится в диапазоне от 290 до 385 Вт. На вершине семейства располагается модель Xeon W9-3595X с базовой частотой 2,0 ГГц и максимальной частотой 4,8 ГГц. Цена варьируется от $1339 до $5889. Новые процессоры рассчитаны на работу с материнскими платами на чипсете Intel W790. 
Источник изображения: Intel
27.08.2024 [16:32], Сергей Карасёв
Xeon 6 на границе: Intel Granite Rapids-D получат поддержку PCIe 5.0, 2 × 100GbE, DDR5-5600 и MCR-DIMMКорпорация Intel раскрыла некоторые технические характеристики SoC Xeon 6 поколения Granite Rapids-D, предназначенных для периферийных решений (edge), в том числе на базе платформы Intel Tiber Edge. Изделия, использующие чиплетную компоновку, появятся на рынке в 2025 году. Процессоры базируются на производительных P-ядрах Redwood Cove. Каждое ядро получило по 64 Кбайт L1-кеша для инструкций и данных, а также L2-кеш объёмом 2 Мбайт. Конструкция SoC включает один или два вычислительных тайла, а также тайл ввода-вывода (I/O), отвечающий за реализацию PCIe, CXL и различных вспомогательных ускорителей. Вычислительные блоки производятся по техпроцессу Intel 3, IO-тайл — по техпроцессу Intel 4. Тайлы «сшиты» посредством EMIB. 
Источник изображения: Intel Xeon 6 Granite Rapids-D будут доступны в модификациях с поддержкой четырёх (2DPC) и восьми каналов памяти. Размеры BGA-упаковок — 77,5 × 50 мм и 77,5 × 56,5 мм соответственно. Говорится о поддержке DDR5-5600 м MCR-DIMM, 32 линий PCIe 5.0, 16 линий PCIe 4.0 и 16 линий CXL 2.0. Возможно использование до восьми Ethernet-портов 1/10/25GbE, до четырёх портов 50GbE или двух портов 100GbE. Ethernet-контроллер поддерживает классификацию пакетов и обработку ACL, предлагает различные планировщики и возможность программируемой обработки трафика. Возможности Intel QAT (Quick Assist Technology) тоже значительно расширены. Во-первых, теперь в состав QAT входит медиаускоритель для обработки потокового видео на лету: (де-)кодирования и транскодирования, масштабирования, обрезки кадра и т.д. Говорится как минимум о поддержка 1080p@30 для AVC/HEVC/AV1. Видеопоток при необходимости можно тут же направить к процессорным ядрам с AMX. Во-вторых, появилась возможность в один проход сжать и зашифровать данные с попутной проверкой их целостности. 
Источник изображения: Intel Чипы также получили поддержку Intel DLB (Dynamic Load Balancer), Intel vRAN Boost, Intel Data Streaming Accelerator (DSA), Intel SGX (Software Guard Extensions), Intel TDX (Trust Domain Extensions). Кроме того, были значительно расширены возможности функции Intel RDT (Resource Director Technology), которая теперь позволяет отслеживать и управлять состоянием IO-устройств, включая PCIe, CXL, интегрированных ускорителей и т.д. Встроенные ИИ-возможности обеспечивает более чем 8-кратный прирост быстродействия в Resnet-50 и более чем 6-кратное увеличение производительности в Visual Transformer по сравнению с Xeon D 2899NTN предыдущего поколения (с AVX512 VNNI) благодаря новым инструкциям AMX. Поддерживается работа в режиме FP16. Intel пока не раскрывает максимальное количество вычислительных ядер у Xeon 6 Granite Rapids-D. Но в ходе презентации был упомянут вариант с 42 ядрами, работающий в связке со 128 Гбайт памяти DDR5-5600/4800. Процессоры будут предлагаться в версиях, оптимизированных для вычислительных нагрузок и edge-приложений с ИИ-функциями.
18.08.2024 [20:47], Руслан Авдеев
Полуфабрикаты: AMD и Supermicro готовы поставлять серверы без CPU, чтобы клиент смог сам выбрать наиболее подхощий чипНа первый взгляд поставка серверного оборудования без процессоров может показаться бессмысленной, но представители AMD и Supermicro рассказали, почему готовы участвовать в подобных проектах. По данным CRN, топ-менеджеры компаний-партнёров заинтересованы в работе с небольшими компаниями, если у тех есть уникальные заказы. В недавнем интервью на конференции SIGGRAPH 2024, один из топ-менеджеров AMD Джеймс Найт (James Knight) заявил, что AMD совместно с Supermicro неоднократно работали по подобной схеме со студиями, участвующими в создании компьютерной графики и другого контента. Сам Найт неоднократно участвовал в создании визуальных эффектов, в том числе для «Аватара», поэтому хорошо знает индустрию изнутри. 
Источник изображения: Vardan Papikyan / Unsplash По его словам, небольшие студии часто ограничены в средствах и просят о поставках серверов без процессоров, поскольку им ещё предстоит определить, какой именно вариант «железа» будет оптимальным по соотношению цена/производительность для их нагрузок. В качестве примера были приведены две (неназванные) студии, спросившие AMD, есть ли у той партнёры среди поставщиков серверов, согласные взяться за такие «полуготовые» решения. AMD в таком случае может предложить потенциальным покупателям несколько процессоров для выбора наилучшего варианта. Многие партнёры AMD на такой запрос категорически отказывались реагировать, желая заранее знать, сколько ни смогут заработать на такой сделке. Тем не менее, в Supermicro, выручка которой выросла на 110 % до $14,9 млрд в 2024 фискальном году, встретили идею с энтузиазмом, не побоявшись работы с небольшими клиентами. Хотя подобные проекты не приносят ощутимой прямой прибыли, они чрезвычайно важны для AMD и Supermicro в медийном плане, причём в итоге всё выливается в рост прибылей обоих партнёров. «Это не капиталистический и не коммерческий подход, но это именно то, что повышает продажи», — заявляют в AMD, при этом, вероятно, немного лукавя. В Supermicro сослались на одну из студий по созданию визуального контента, которая изначально хотела получить рабочую станцию с СЖО на базе новейших Ryzen AMD Threadripper. Однако в ходе общения с AMD и Supermicrco обсуждение перешло к созданию более дорогой кастомной стоечной системы. По словам одного из партнёров AMD и Supermicro, компании могут совместно решить любую проблему клиента, желая проверить и оценить каждую опцию, находящуюся в пределах их совместной компетенции. Утверждается, что у конкурентов совсем другое мировоззрение.
16.08.2024 [09:20], Алексей Степин
От IoT до ЦОД: Akeana, основанная выходцами из Marvell, представила три семейства ядер RISC-VВ 2021 году выходцы из Marvell и Cavium, стоявшие в своё время за созданием серверных Arm-процессоров ThunderX, основали стартап Akeana, который на днях вышел из т.н. скрытого режима и анонсировал RISC-V ядра собственной разработки. Akeana прямо говорит, что планирует бросить вызов Arm, SiFive, Andes и другим разработчикам чипов с архитектурой RISC-V. За три года Akeana удалось получить от крупных инвесторов, включая Kleiner Perkins, Mayfield и Fidelity, финансирование свыше $100 млн. А на этой неделе Akeana представила целую серию кастомизируемых IP-решений, в том числе три дизайна процессорных ядер с архитектурой RISC-V. 
Источник здесь и далее: Akeana Остальные решения относятся к экосистеме, которую планирует сформировать Akeana. Это система высокоскоростного интерконнекта SCI (Scalable Coherent Interconnect, совместим с AMBA CHI), блоки контроллера прерываний, IOMMU, систему кластеризации и когерентности кешей, блоки векторных и матричных вычислений для ИИ-нагрузок и многое другое, включая разнообразные микроконтроллеры и подсистемы.  Что касается процессорных дизайнов, то компания представила сразу три серии:
 В каждой из серий анонсировано по три-четыре базовых варианта с разной функциональностью, конфигурацией и объёмами кешей. Наибольший интерес представляет, пожалуй, серия 5000, которая позиционируется в качестве достаточно мощных процессоров для использования как в ПК и ноутбуках (в последнем случае предлагается использовать гетерогенный вариант с Akeana 1000 в качестве «малых» ядер), так и в качестве серверной инфраструктурной основы. 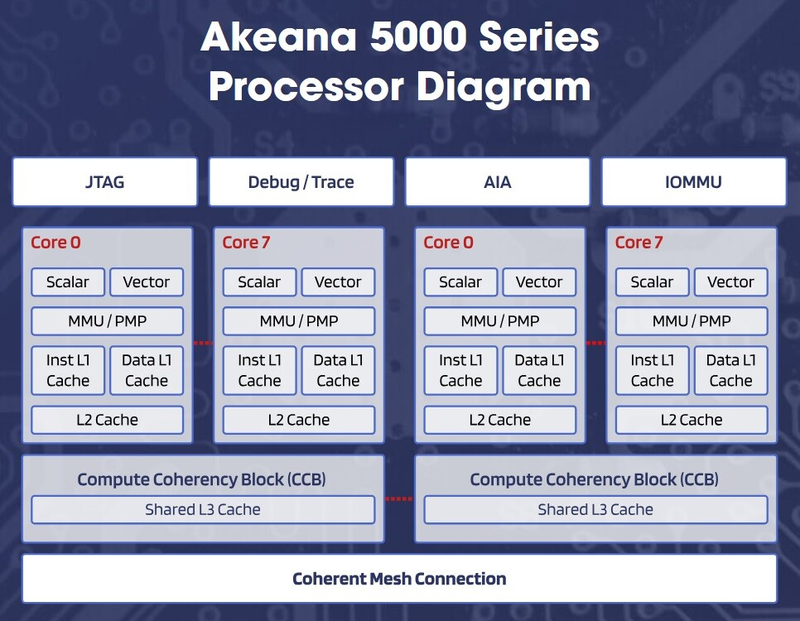 Ядра Akeana поддерживают кластеризацию (до 8 ядер на кластер), но, к сожалению, компания пока не раскрывает пределов масштабирования, тогда как новый дизайн SiFive, как мы уже знаем, позволяет создавать процессоры с числом ядер до 256. Говорить о каких-то реальных прототипах ещё рано, но все три серии ядер Akeana уже доступны для лицензирования клиентами. Очевидно, что экосистема RISC-V вступает в фазу активного развития: одна за другой компании-разработчики представляют всё новые и новые дизайны процессорных ядер и целых платформ, причём в широчайшем диапазоне характеристик — от экономичных микроконтроллеров до многоядерных серверных решений.
15.08.2024 [09:36], Алексей Степин
256 × RISC-V: SiFive представила высокопроизводительные ядра P870-D для серверов и СХДОткрытая архитектура RISC-V, которая, как многие надеются, станет конкурентом Arm не только в компактных и экономичных устройствах, но и в серверных системах, продолжает развиваться. Один из ведущих разработчиков в этой сфере, компания SiFive, анонсировала новое ядро P870-D. Как следует из системы обозначений, принятой SiFive, это высокопроизводительное (Performance) ядро, а суффикс D означает Datacenter. Новинка предназначена для серверных процессоров с количеством ядер до 256. Дизайн P870-D нельзя назвать полностью новым, поскольку он основан на ядре P870, анонсированном в конце 2023 года. Данное решение предназначалось для создания процессоров с числом ядер до 32 и включало в себя два 128-бит векторных блока, при этом каждые четыре ядра группировались в кластер, использовавший разделяемый кеш L2. 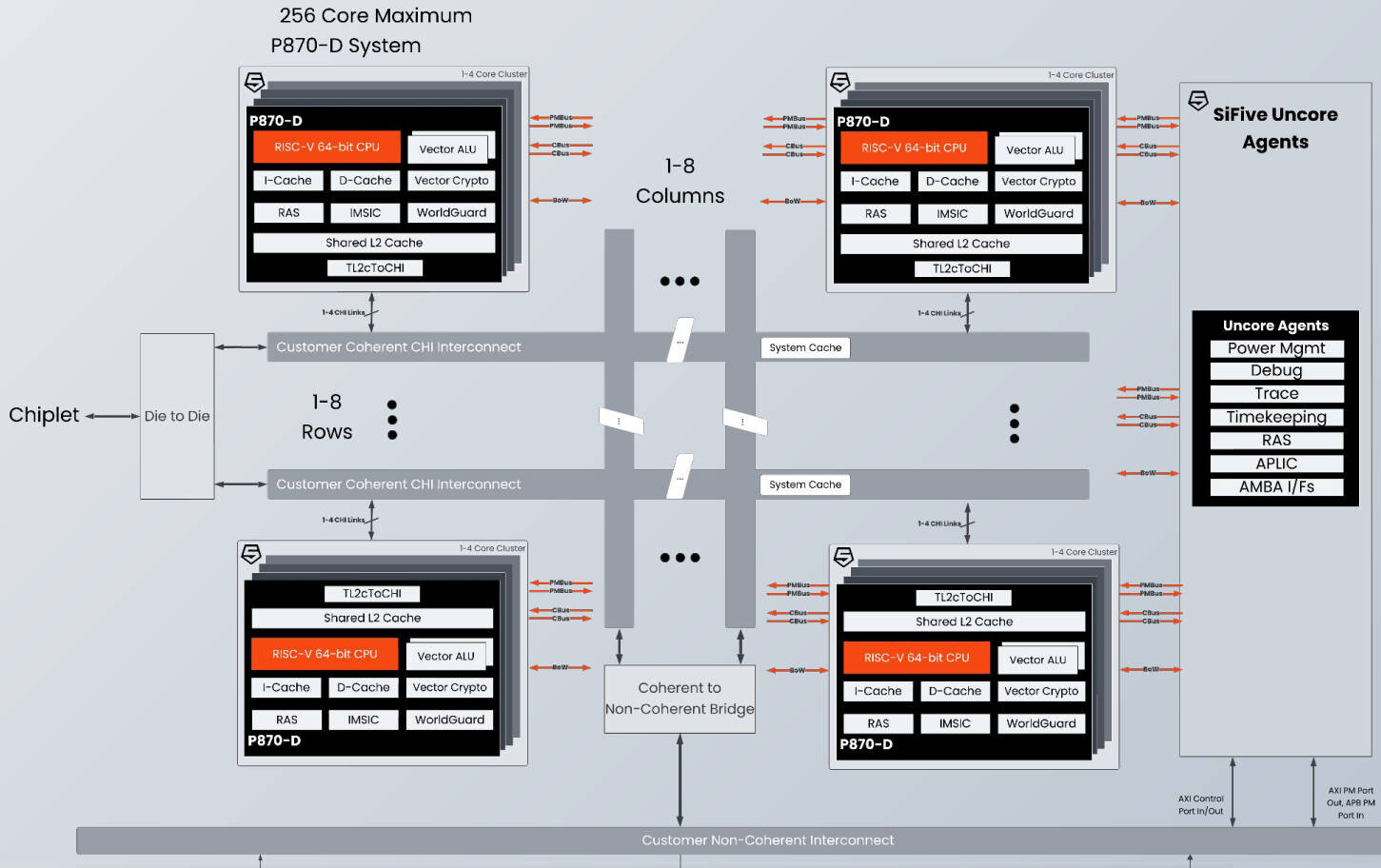
Источник здесь и далее: SiFive P870-D сохранило черты предшественника. Это 64-бит ядро с поддержкой внеочередного исполнения инструкций и шириной декодера 6. В нём реализована поддержка набора инструкций RVA 23, Vector 1.0 и Vector Crypto. Появилась поддержка функций обеспечения повышенной надёжности RAS (Reliability, availability and serviceability). Контроль чётности присутствует уже на уровне регистровых файлов, а на всех уровнях подсистемы кешей имеется коррекция ошибок SECDED ECC. Но это не всё, в P870D есть поддержка AMBA CHI (4 порта). Это нововведение позволило SiFive существенно улучшить масштабирование — P870-D может служить основой для процессоров с числом ядер до 256, включая гетерогенные, в том числе возможны многочиповые дизайны и варианты с поддержкой CXL. Сами ядра по-прежнему группируются в кластеры по четыре, а CHI-подключение может обеспечиваться как встроенным мостом, так и внешним чиплетом. 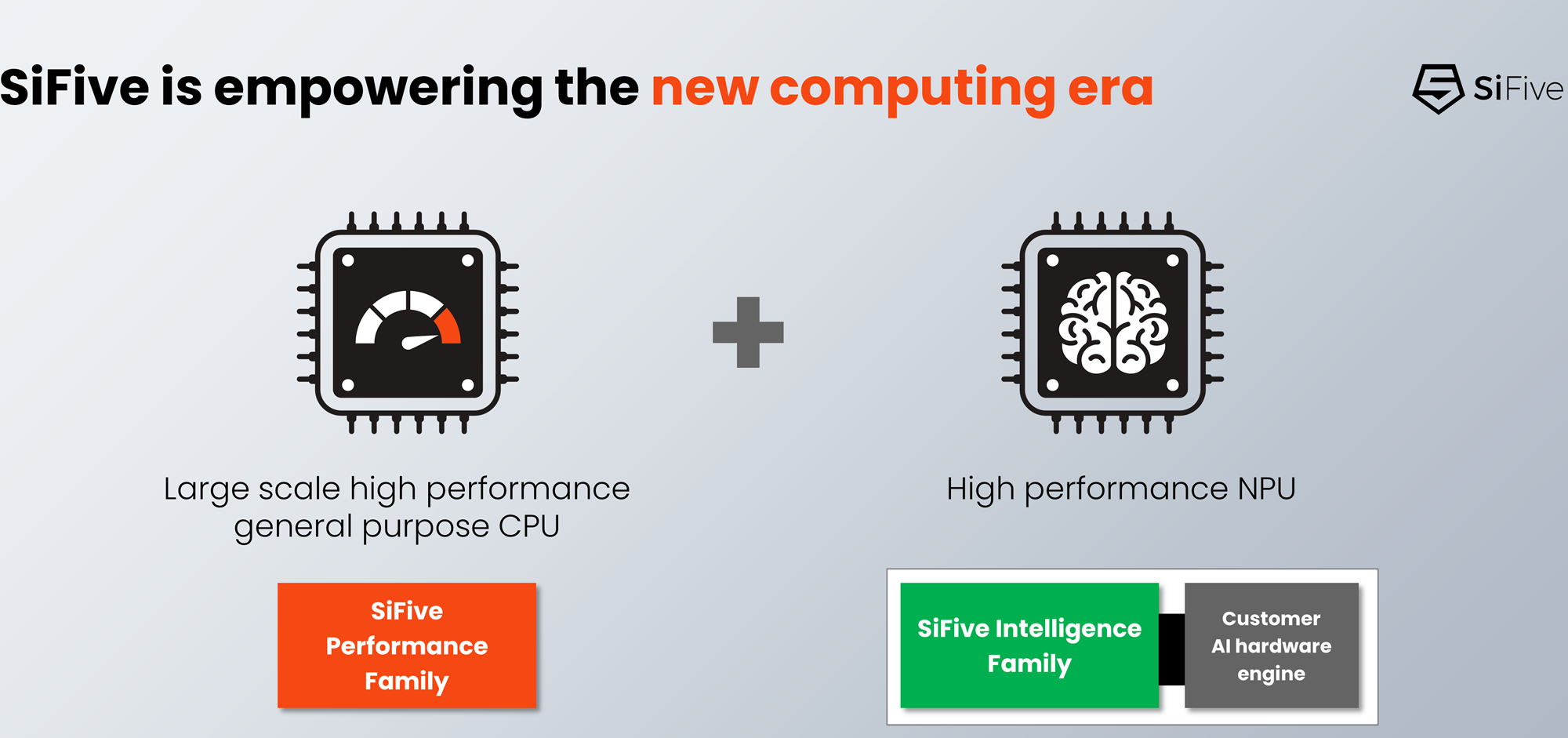 Также в состав P870-D входит распределённый масштабируемый блок IOMMU, платформа безопасности WorldGuard и uncore-агент, ответственный за питание, отладку, трассировку и т.д. Есть и контроллер прерываний Advanced Interrupt Architecture (AIA) с поддержкой Message Signal Interrupts (MSI) и виртуализации. В настоящее время это самое мощное ядро в арсенале SiFive, основными его конкурентами названы Arm Cortex-X2 и AMD Zen 4c. Однако перекоса в сторону исключительно производительности у P870-D нет. Поскольку данный дизайн ориентирован на современные высокоплотные ЦОД и платформы периферийных вычислений, разработчики уделили серьёзное внимание вопросам энергопотребления и тепловыделения. Впрочем, точных данных по этим параметрам пока приведено не было. 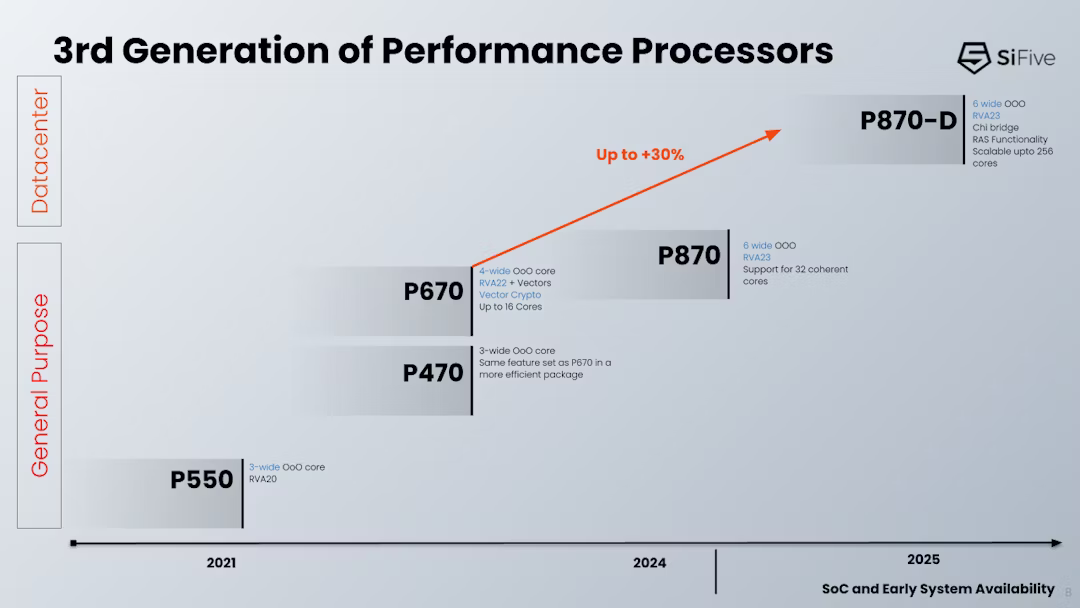 Компания активно сотрудничает с партнерами по экосистеме RISC-V. Так, уже заключено соглашение с Arteris, которая выпустит референсные платформы валидации на базе P870-D и X280 с интегрированной поддержкой Arteris Network-on-Chip (NoC), что должно упростить дальнейшую разработку сложных гетерогенных чипов с функциями ИИ (за счёт блоков SiFive Intelligence) и ускорить вывод на рынок решений на базе таких чипов. Образцы чипов на базе SiFive P870-D уже поставляются ведущим партнёрам компании, а начало массового производства намечено на конец текущего 2024 года. Зарубежные аналитики полагают, что за энергоэффективными платформами на базе открытых стандартов большое будущее. К 2030 году решения, подобные SiFive P870-D, как ожидается, займут более 40 % всего рынка серверных процессоров.
12.08.2024 [09:53], Владимир Мироненко
Mercury Research: Intel под натиском AMD теряет долю на рынке CPUIntel постепенно теряет лидирующие позиции на рынке серверных, настольных и мобильных процессоров, хотя по-прежнему удерживает его львиную долю, пишет The Register со ссылкой на исследование Mercury Research, сделанное по итогам II квартала 2024 года. Согласно данным Mercury Research, Intel потеряла год к году несколько п.п. доли рынка в каждой из трёх основных категорий CPU — серверных, настольных и мобильных — в то время как доля AMD выросла. Самых больших успехов AMD добилась в сегменте серверных процессоров, где увеличила долю рынка на 5,6 % до 24,1 % поставок, что также превышает показатель предыдущего квартала. В сегменте мобильных устройств доля поставок AMD выросла на 3,8 % до 20,3 % по сравнению с аналогичным периодом прошлого года, что также немного больше показателей I квартала. 
Источник изображения: Obie Fernandez / Unsplash Вместе с тем суммарные поставки процессоров во II квартале снизились по сравнению с I кварталом, что, как отметили аналитики, ниже обычных сезонных колебаний. Mercury Research объясняет сокращение рынка гораздо более низкими поставками в сегментах Интернета вещей (IoT) и систем на кристалле (SoC) — рынках встраиваемых решений — из-за более слабого спроса на эти чипы, особенно на SoC AMD для игровых консолей. Также сократились поставки мобильных процессоров начального уровня, в основном используемых в Chromebook. Если учитывать этот нюанс, то Intel фактически увеличила общую долю рынка — на 7 % по сравнению с прошлым годом, что в Mercury Research объясняют сокращением выпуска AMD SoC. Хотя AMD увеличила общую долю клиентских и серверных решений, этого оказалось недостаточно для компенсации резкого сокращения поставок SoC, заявил президент Mercury Research Дин Маккаррон (Dean McCarron). 
Источник изображения: Intel Intel завершила II квартал 2024 года с убытками в размере $1,61 млрд, хотя годом ранее у неё была в аналогичном квартале чистая прибыль в размере $1,48 млрд. В связи с этим компания объявила план по сокращению расходов, включающий увольнение более 16 000 сотрудников — не менее 15 % персонала — и сокращение капитальных вложений более чем на 20 % до $25–27 млрд. Ранее Intel была вынуждена признать наличие проблем у некоторыми из своих процессоров Raptor Lake 13-го и 14-го поколений, и выпускает исправление микрокода для их устранения, которое включено в обновления BIOS. Руководитель Intel Пэт Гелсингер (Pat Gelsinger), объяснил слабые показатели II квартала ограничениями США на экспорт поставок чипов в Китай, но, как отметил The Register, на этом также отразился тот факт, что у компании нет популярных ИИ-ускорителей, тогда как на фоне бума ИИ в поставках для ЦОД преобладают именно такие чипы. В свете этого тренда Mercury Research отметила, что и AMD, и Intel показали скромное увеличение поставок серверных CPU во II квартале, что примечательно, поскольку «рынок обычных серверных процессоров значительно замедлился из-за переключения спроса ЦОД на ИИ-ускорители». 
Источник изображения: AMD Mercury Research сообщила, что рост у Intel наблюдался в основном в сегменте сетевых и периферийных процессоров, а не традиционных процессоров для ЦОД, где доходы Intel, по её данным, были стабильными. Что касается процессоров Arm, то по данным Mercury Research, доля рынка ПК с этой архитектурой снизилась до 10 % с 11 % в I квартале, несмотря на широко разрекламированный запуск серии Windows-компьютеров Copilot+ PC на базе чипов Qualcomm в мае этого года. По словам Mercury Research, падение было вызвано значительным снижением спроса на процессоры для Chromebook и снижением поставок Arm-компьютеров Apple Mac. Поставки систем класса Copilot+ PC были слишком малы, чтобы компенсировать это падение.
10.08.2024 [11:49], Владимир Мироненко
Уязвимость Sinkclose в процессорах AMD позволяет вывести из строя компьютер без возможности восстановленияЭнрике Ниссим (Enrique Nissim) и Кшиштоф Окупски (Krzysztof Okupski), исследователи из компании IOActive, занимающейся вопросами безопасности обнаружили уязвимость в чипах AMD, выпускаемых с 2006 года или, возможно, даже раньше, которая позволяет вредоносному ПО проникать настолько глубоко в систему, что во многих случая её проще выбросить, чем пытаться восстановить, пишет ресурс Wired. Получившая идентификатор CVE-2023-31315 с высоким уровнем опасности (CVSS 7,5) уязвимость была названа исследователями Sinkclose. Уязвимость позволяет злоумышленникам с привилегиями уровня ядра ОС (Ring 0) получать привилегии Ring -2 и устанавливать вредоносное ПО, которое очень сложно обнаружить. 
Источник изображения: AMD Благодаря Sinkclose злоумышленники могут изменять настройки одного из самых привилегированных режимов процессора AMD — SMM, предназначенного для обработки общесистемных функций, таких как управление питанием и контроль оборудования, даже если включена блокировка SMM. Эта уязвимость может использоваться для отключения функций безопасности и внедрения на устройство постоянного, практически необнаруживаемого вредоносного ПО. Ring -2 изолирован и невидим для ОС и гипервизора, поэтому любые вредоносные изменения, внесённые на этом уровне, не могут быть обнаружены или исправлены инструментами безопасности, работающими в ОС. Вредоносное ПО, известное как буткит, которое обходит антивирусные инструменты и потенциально невидимо для операционной системы, предоставляет хакеру полный доступ для вмешательства в работу компьютера и наблюдения за её активностью. По словам Окупски, единственный способ обнаружить и удалить вредоносное ПО, установленное с помощью SinkClose — это физическое подключение с помощью программатора SPI Flash и сканирование памяти на наличие вредоносного ПО. Полные сведения об уязвимости будут представлены исследователями на конференции DefCon в докладе «AMD Sinkclose: Universal Ring -2 Privilege Escalation». Исследователи говорят, что предупредили AMD об уязвимости в октябре прошлого года, и не сообщали о баге почти 10 месяцев, чтобы дать AMD больше времени для устранения проблемы. Комментируя сообщение исследователей, компания AMD указала в заявлении для Wired на сложность использования уязвимости в реальных сценариях, поскольку злоумышленникам требуется доступ на уровне ядра. В ответ исследователи заявили, что подобные уязвимости выявляются в Windows и Linux практически каждый месяц. Они отметили, что опытные хакеры, спонсируемые государством, которые могут воспользоваться Sinkclose, вероятно, уже обладают методами использования подобных уязвимостей. Как ожидают исследователи, для компьютеров с Windows патчи против Sinkclose будут интегрированы в обновления, которыми производители компьютеров поделятся с Microsoft. Исправления для серверов, встраиваемых систем и Linux-машин могут быть более пошаговыми и ручными; для Linux это будет частично зависеть от дистрибутива. AMD указала в заявлении, что уже приняла меры по смягчению последствий для своих процессоров EPYC и AMD Ryzen для настольных и мобильных систем, а дополнительные исправления для встроенных процессоров появятся позже. Согласно AMD, уязвимость имеется в следующих чипах:
UPD 11.08.2024: патчи не получат Ryzen 1000, 2000 и 3000, а также Threadripper 1000 и 2000. Не упомянуты и Ryzen 9000 с Ryzen AI 300, но в этих процессорах уязвимость наверняка устранена ещё до их выхода на рынок. UPD 21.08.2024: Ryzen 3000 всё-таки получит патчи против Sinkclose.
03.08.2024 [12:33], Сергей Карасёв
128 P-ядер, 504 Мбайт кеша и TDP 500 Вт: утекли характеристики Intel Xeon Granite RapidsВ распоряжении сетевых источников, по сообщению ресурса VideoCardz, оказалась информация о характеристиках части процессоров Intel Xeon 6 семейства Granite Rapids, в основу которых лягут производительные ядра P-core. Речь идёт о чипах Xeon 6900P, которые, как ожидается, появятся на рынке в текущем квартале. Формальная презентация Xeon 6 Granite Rapids состоялась в начале июня текущего года — вместе с изделиями Xeon 6 Sierra Forest, построенными на энергоэффективных ядрах E-core. Для платформы Xeon 6 предусмотрено использование разъёмов LGA-4710 и LGA-7529: в первом случае заявлена поддержка чипов с TDP до 350 Вт и 8-канальной памяти, во втором — 500 Вт и 12-канальной памяти. При этом в обоих вариантах возможно построение двухсокетных серверов. 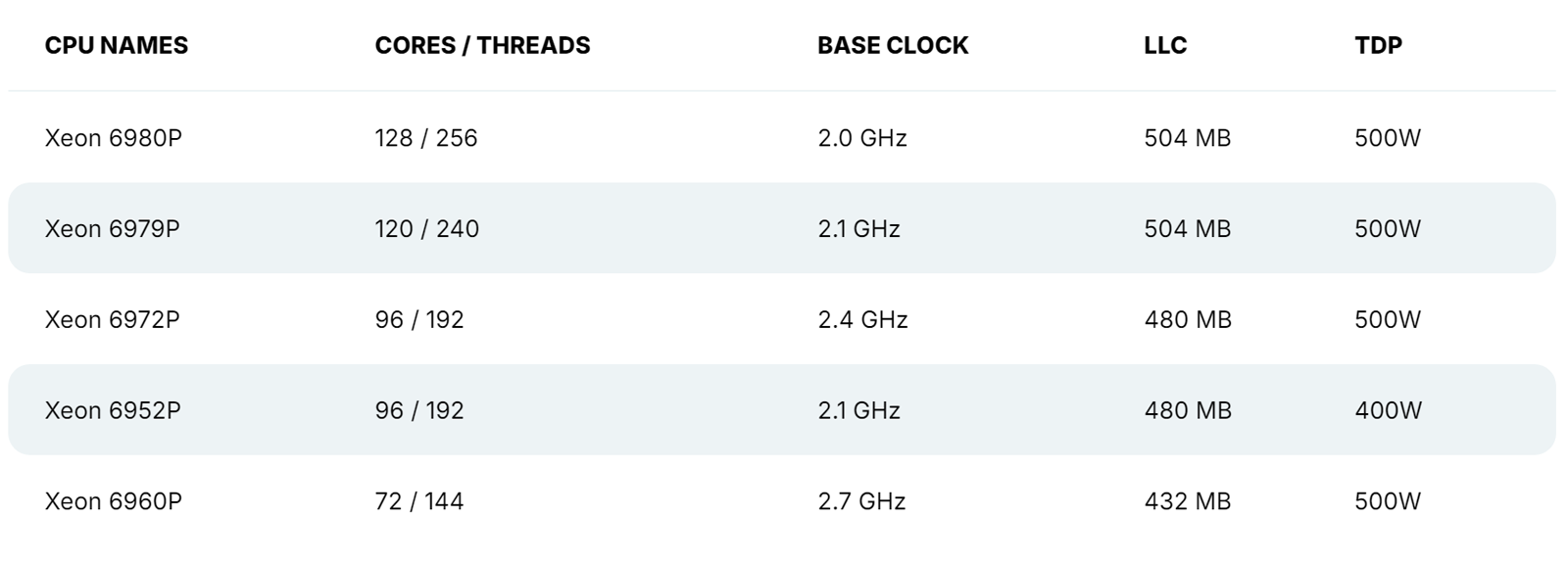
Источник изображения: Wccftech Как стало известно, в семейство Xeon 6 Granite Rapids войдут модели с 32, 44, 56, 72, 96, 120 и 128 ядрами Redwood Cove. Они получат поддержку SMT и до 504 Мбайт L3-кеша. Величина TDP составит до 500 Вт. В частности, говорится о подготовке процессоров Xeon Platinum 6980P, 6979P, 6972P, 6952P и 6960P. Их базовая тактовая частота варьируется от 2,0 до 2,7 ГГц (см. характеристики). Для чипов Xeon 6 Granite Rapids заявлена поддержка памяти DDR5-6400 и MCR-8800, до 96 линий PCIe Gen 5.0/CXL 2.0 и до 6 линий UPI 2.0.
01.08.2024 [23:55], Алексей Степин
Arm-процессоры AWS Graviton4 успешно конкурируют с актуальными Intel Xeon, а иногда обгоняют даже AMD EPYCВсего за пять лет Amazon успела разработать и внедрить четыре поколения серверных Arm-процессоров Graviton. 4-нм Graviton4 получили 96 ядер и 12 каналов памяти DDR5-5600, а также поддержку PCIe 5.0. Всё это дало AWS основание утверждать, что Graviton4 производительнее предшественника на 30 %, а пропускная способность памяти у него выше на 75 %. Насколько это соответствует истине, выяснил ресурс Phoronix, который заодно сравнил новинки с другими современными процессорами. В тестировании Phoronix приняли участие следующие модели Graviton:

Источник: AWS Платформа Graviton в последней итерации выглядит вполне достойно. Она использует современный набор инструкций Arm, а по количеству ядер и каналов памяти сопоставима с новейшими решениями Intel и AMD. Производительность по мере смены поколений у Graviton растёт практически линейно, за исключением перехода от первого поколения ко второму, что легко объясняется возросшим сразу вчетверо количеством ядер. Что касается Graviton4, то новые процессоры в среднем быстрее Graviton3 примерно в 1,55 раза, а первенца серии они превосходят в 10,4 раза. В некоторых случаях выигрыш выходит далеко за рамки теоретических 1,5x, поскольку у Graviton4 более совершенная архитектура, новее набор инструкций, вдвое больший объем кеша на ядро и существенно более производительная подсистема памяти. Такое поведение, к примеру, характерно для тестов srsRAN, задач криптографии и особенно работы с базами данных. 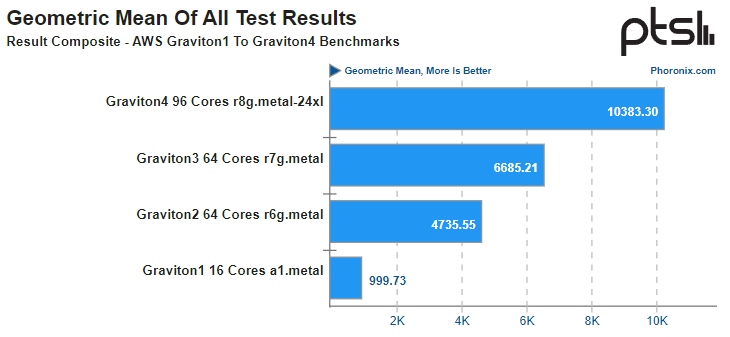
Источник здесь и далее: Phoronix В другом исследовании Phoronix процессорам Graviton4 довелось столкнуться с серьёзными соперниками из мира x86, включая 128-ядерный AMD EPYC 9754 (Bergamo) и 144-ядерные Intel Xeon 67xx (Sierra Forest), а также с ближайшим конкурентом по Arm-платформе, 128-ядерным процессором Ampere Altra Max. К сожалению, метрик энергопотребления в текущей версии инстанса r8g.metal-24xl получить не удалось, но и без этого результаты получены весьма интересные. С первых тестов очевидно, что Altra Max уже не соперник современным решениям, несмотря на сопоставимое количество ядер — сказывается не самая новая архитектура. А вот Graviton4 чувствует себя неплохо и в тестах на компиляцию может опережать даже AMD EPYC 9754. Хороша новинка и в базах данных, она лишь немного уступает процессорам Genoa и зачастую опережает 144-ядерное решение Intel c E-ядрами. И даже в HPC-нагрузках, для которых характерно активное использование FP-вычислений у Graviton4 всё хорошо! Неплохо себя детище AWS чувствует и в сценариях (де-)компрессии данных и кодировании видео. 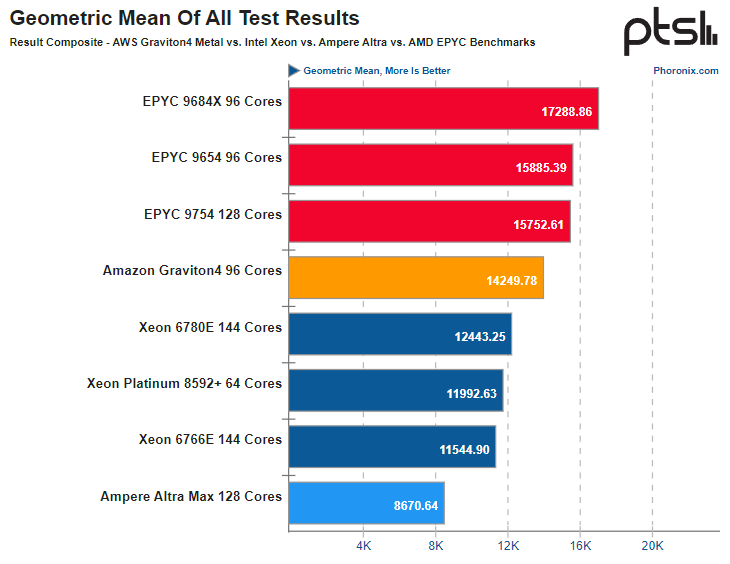 В итоговом зачёте AWS Graviton4 уверенно занимает место в середине таблицы, опережая оба Xeon — и 64-ядерный Platinum 8592+ (Emerald Rapids), и 144-ядерный Xeon 6780E, но до уровня AMD EPYC 9754 всё же несколько недотягивая. Это вполне даёт основание считать, что платформа AWS Graviton достигла зрелости. Она вполне конкурентоспособна даже на фоне x86-монстров. Более того, на сегодня Graviton4 можно считать самым продвинутым серверным процессором с архитектурой AArch64. Впрочем, вскоре предстоят сражения с Granite Rapids, Turin и AmpereOne (а на подходе ещё и Aurora с HBM). |
|