Материалы по тегу: aws
|
21.01.2023 [16:30], Сергей Карасёв
AWS вложит $35 млрд в расширение мощностей ЦОД в ВирджинииОблачная платформа Amazon Web Services (AWS), по сообщению Bloomberg, намерена значительно расширить инфраструктуру дата-центров в Вирджинии (США). Сообщается, что на строительство новых ЦОД в этом регионе до 2040 года будет выделено приблизительно $35 млрд. Amazon уже имеет значительное присутствие в Северной Вирджинии. Облачный провайдер открыл свой первый кластер ЦОД и офисов в этом регионе в 2006 году, а с 2011-го инвестировал в развитие соответствующей инфраструктуры примерно $35 млрд. Компания не раскрывает количество и точное местоположение своих дата-центров, ссылаясь на коммерческую тайну и соображения безопасности. 
Источник изображения: Amazon О новых планах AWS, как отмечает Datacenter Dynamics, объявили Партнёрство экономического развития Вирджинии и губернатор штата Гленн Янгкин (Glenn Youngkin). Регион привлекателен для операторов ЦОД с точки зрения налоговых льгот и относительно недорогой электроэнергии. Проект предполагает, что AWS построит нескольких новых кампусов дата-центров по всей Вирджинии. Это создаст приблизительно 1000 дополнительных рабочих мест. «Вирджиния является мировым лидером в области инноваций и облачных вычислений. С 2006 года компания AWS инвестировала более $35 млрд в регион, увеличив общий валовой внутренний продукт Содружества Вирджинии почти на $7 млрд, и ежегодно поддерживает тысячи рабочих мест. Опираясь на эти успешные начинания, мы планируем к 2040 году дополнительно инвестировать $35 млрд», — заявил Роджер Венер (Roger Wehner), директор по экономическому развитию AWS. 
Источник изображения: Amazon Amazon активно развивается в Северной Вирджинии, крупнейшем в мире рынке ЦОД. Помимо приобретения земли в округах Лаудон и Принс-Уильям, компания намерена развернуть площадки в округах Фокир, Калпепер и Фэрфакс. Однако некоторые проекты AWS столкнулись с сильным сопротивлением местных жителей, в результате чего часть инициатив была приостановлена. Домовладельцы и гражданские активисты жалуются на высокий уровень шума от дата-центров, который производится круглосуточно и без выходных. Причём никаких мер для решения проблемы не предпринимается. Претензии также связаны с тем, что строительство новых ЦОД предполагается в особых зонах — сельской местности, исторических местах вроде Национального поля битвы в Манассасе, а также в местах захоронений предков многих жителей. Это породило массовые протесты. Наконец, в регионе из-за огромного количества дата-центров возникла нехватка электроэнергии: для питания ЦОД попросту недостаёт линий электропередач.
30.11.2022 [16:55], Алексей Степин
AWS представила пятое поколение аппаратных гипервизоров NitroНа днях крупный провайдер облачных услуг, компания Amazon Web Services представила новые варианты инстансов на базе новейших процессоров Graviton3E, но данный чип — не единственная новинка AWS. Одновременно с Graviton3E было представлено и пятое поколение аппаратных гипервизоров Nitro, существенно выигрывающих по ключевым показателям у решений предыдущего, четвёртого поколения. 
Здесь и далее источник изображений: ServeTheHome Главная идея Nitro — сочетание «кремния» гипервизора, DPU и сопроцессора безопасности с поддержкой Root of Trust в едином чипе. В системах AWS плата с чипом Nitro полностью управляет распределением вычислительных ресурсов и памяти, избавляя от этой нагрузки хост-процессоры. По результатам тестов, проведённых AWS, производительность облачных инстансов с использованием ускорителей Nitro практически не отличается от производительности классической bare metal-системы.  AWS Nitro v5 использует кастомный кристалл, разработанный Annapurna Labs. По сравнению с Nitro v4, количество транзисторов было удвоено, но за счёт этого удалось на 60 % поднять скорость обработки сетевых пакетов, на 30 % снизить латентность, а также, благодаря продвинутому техпроцессу, обеспечить лучшую удельную производительность. 
Платы AWS Nitro v5 используют проприетарные разъёмы Улучшились и другие характеристики: на 50 % выросла пропускная способность памяти и вдвое возросла производительность подсистемы PCI Express. Платы Nitro v5 станут сердцем новых инстансов C7gn, где обеспечат полную изоляцию критически важных подсистем, таких, как прошивки BIOS, BMC и накопителей от гостевого доступа извне и позволят обновлять эти прошивки без влияния на клиентские нагрузки.  Также они возьмут на себя обслуживание сетей VPC/EBS, включая переход на использование SRD вместо TCP, и накопителей Nitro SSD. AWS уже объявила о возможности предварительного тестирования систем C7gn на базе Nitro v5 и новейших процессоров Graviton3/3E.
29.11.2022 [17:12], Алексей Степин
AWS представила Arm-процессор Graviton3E, оптимизированный для задач ИИ и HPCОдин из крупнейших облачных провайдеров, компания Amazon Web Services объявила о доступности новых инстансов EC2 на базе процессора Graviton3E. Новый чип — наследник анонсированного в конце 2021 года Graviton3, 5-нм 64-ядерного процессора на дизайне Arm Neoverse V1 (Zeus) с поддержкой DDR5 и PCI Express 5.0. Graviton3 использует набор команд Armv8.4 c расширениями Neon (4×128 бит) и SVE (2×256 бит) и поддерживает работу с популярными в сфере машинного обучения форматами данных INT8 и BF16. В сравнении c Graviton2 процессор быстрее на 25-60 % при сохранении аналогичного уровня тепловыделения. Дизайн серверов AWS предусматривает наличие трёх процессоров на узел высотой 1U. 
Изображения: AWS Новый процессор Graviton3E представляет собой дальнейшее развитие Graviton3. Чип оптимизирован с учётом потребностей рынка высокопроизводительных вычислений и основное внимание в его архитектуре уделено повышению производительности на операциях с плавающей запятой и вычислениях с использованием векторной математики. AWS, к сожалению, пока не раскрывает деталей относительно архитектуры Graviton3E, но прирост производительности на векторных операциях относительно обычного Graviton3 может достигать 35 %. Помимо классического теста HPL новый процессор хорошо проявляет себя в тестах, имитирующих медико-биологические и финансовые задачи.  Сценарии нагрузок, характерные для HPC, как правило, активно оперируют перемещением крупных объемов данных. Чтобы оптимизировать этот процесс, в новых инстансах AWS использует сеть на базе Elastic Fabric с новыми адаптерами Elastic Network Adapter (ENA). Такая сеть оперирует т. н. Scalable Reliable Datagram (SRD) вместо всем привычных TCP-пакетов. SRD позволяет организовать повторную отправку пакетов за микросекунды вместо миллисекунд в классическом Ethernet. Сердцем же новых инстансов AWS стало пятое поколение аппаратных гипервизоров Nitro 5. В сравнении с предыдущим поколением, Nitro 5 обладает вдвое более высокой вычислительной производительностью, на 50 % повышенной пропускной способностью памяти, а также позволяет обрабатывать на 60 % больше сетевых пакетов при сниженной на 30 % латентности. 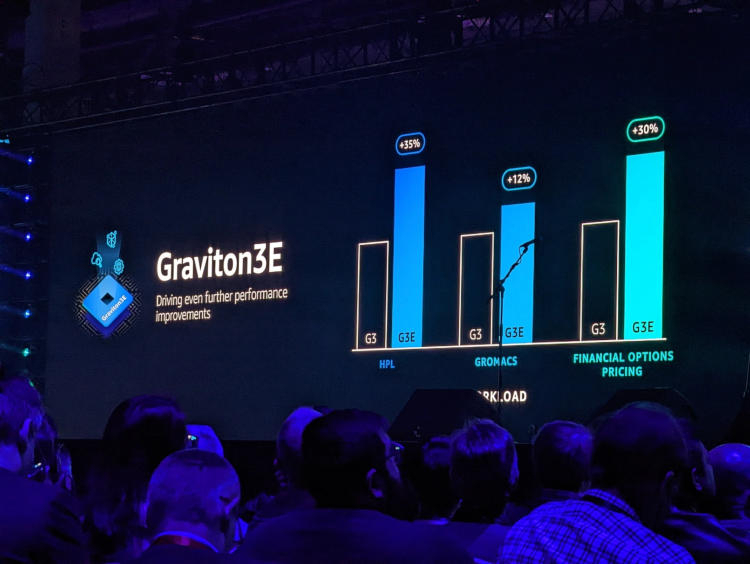
Здесь и далее источник изображений: AWS Инстансы Hpc7g с процессорами Graviton3E получат внутреннюю сеть с пропускной способностью 200 Гбит/с и станут доступны в различных конфигурациях вплоть до 64 vCPU и 128 ГиБ памяти. Аналогичные параметры имеют инстансы C7gn, предназначенные для задач с интенсивным сетевым трафиком: виртуальных маршрутизаторов, сетевых экранов, балансировщиков нагрузки и т.п. Также компания анонсировала инстансы R7iz, в которых используются процессоры Intel Xeon Scalable четвёртого поколения (Sapphire Rapids) с постоянной частотой всех ядер 3,9 ГГц. Они могут иметь конфигурацию до 128 vCPU с 1 ТиБ памяти.
27.07.2022 [17:11], Руслан Авдеев
Жители Северной Вирджинии ополчились против крупных дата-центровЖители Северной Вирджинии всё более и более недовольны распространению дата-центров гиперскейл-класса и готовы активно противостоять их строительству. По данным DataCenter Dynamics, вслед за жителями округа Принс-Уильям (Prince William), жалующихся на невыносимый уровень шума ЦОД Amazon, обитатели округа Фокир (Fauquier) потребовали от властей запретить строительство дата-центра той же компании, которая за последний десяток лет вложила в местные ЦОД более $35 млрд. Примечательно, что Северная Вирджиния десятилетиями является едва ли не крупнейшим хабом для строительства дата-центров в мире, последовательно привлекающим новые компании, объекты и инвестиции. Изначально ЦОД концентрировались преимущественно в округе Лаудон, а теперь распространяются на территорию округов Калпепер (Culpeper), Фокир и Принс-Уильям, жители которых начали вести организованную борьбу с инициативами IT-гигантов и местных властей. 
Фото: Taylor Vick / Unsplash.com В наиболее «пострадавшем» округе Лаудон предложили новые правила зонирования для дата-центров, определяющих, где будущие ЦОД можно строить так, чтобы не побеспокоить местных жителей. Кроме того, предложено пересмотреть экологические стандарты строительства и допустимого уровня шума. Ожидается, что в определённых местах будет прекращено и одобрение строительства ЦОД в ускоренном порядке. Жители округа Калпепер подали в суд, требуя аннулировать разрешение на перезонирование и развитие ЦОД Amazon. В округе Фокир Amazon уже купила более 16 га земли, подала заявку на строительство нового дата-центра и договорилась с местной энергосбытовой компанией Dominion Energy. Изначально местные жители протестовали против строительства 230-кВ линий электропередач над их домами, но потом поняли, что они вообще не понадобятся, если дата-центра не будет. Местных жителей беспокоит не только экология и комфортность окружающей среды, но и экономика — скупка земли для ЦОД поднимает её цены. Кроме того, всё чаще задаётся вопрос, почему налоги для жителей не падают по мере развития дата-центров. О полном отказе от ЦОД речь не идёт, поскольку они обеспечивают около трети местных налоговых поступлений.
21.07.2022 [17:27], Руслан Авдеев
Жители Северной Вирджинии жалуются на «катастрофический шум» от дата-центровКак сообщает портал Data Center Dynamics, домовладельцы и гражданские активисты округа Принс-Уильям (Prince William County) в Северной Вирджинии (США), пожаловались на «катастрофический» шум, издаваемый местными ЦОД. Шум доносится из принадлежащих Amazon дата-центров, расположенных на территории кампуса Tanner Way. Сейчас техногигант ведёт строительство в городе Манассасе, но речь идёт не о шуме стройки. По словам активистов, непрекращающийся шум вызван работой систем воздушного охлаждения на крышах ЦОД, создающих неблагоприятную среду обитания для жильцов района Great Oak, состоящего из 291 домохозяйства. 
Источник изображения: Elyas Pasban/unsplash.com Круглый стол ассоциации домовладельцев округа совместно с ассоциацией города Манассас направили жёсткую жалобу в Наблюдательный совет округа, сообщив о «чрезвычайном промышленном шуме», продолжающемся круглосуточно и без выходных, никаких мер по устранению которого не принимается. По словам местных активистов, шум загрязняет окрестности непрерывно, чему есть аудио- и видеодоказательства. От наблюдательного совета требуют найти решение проблемы. Активисты напоминают о прецедентах — аналогичные жалобы в Аризоне в 2018 году привели к прекращению развития ЦОД в регионе решением местных властей. По данным активистов, пока руководство совета не смогло напрямую решить проблему с ЦОД, и теперь жители требуют приостановки разрешений на работу дата-центров в округе Принс-Уильям до тех пор, пока проблема не будет устранена. 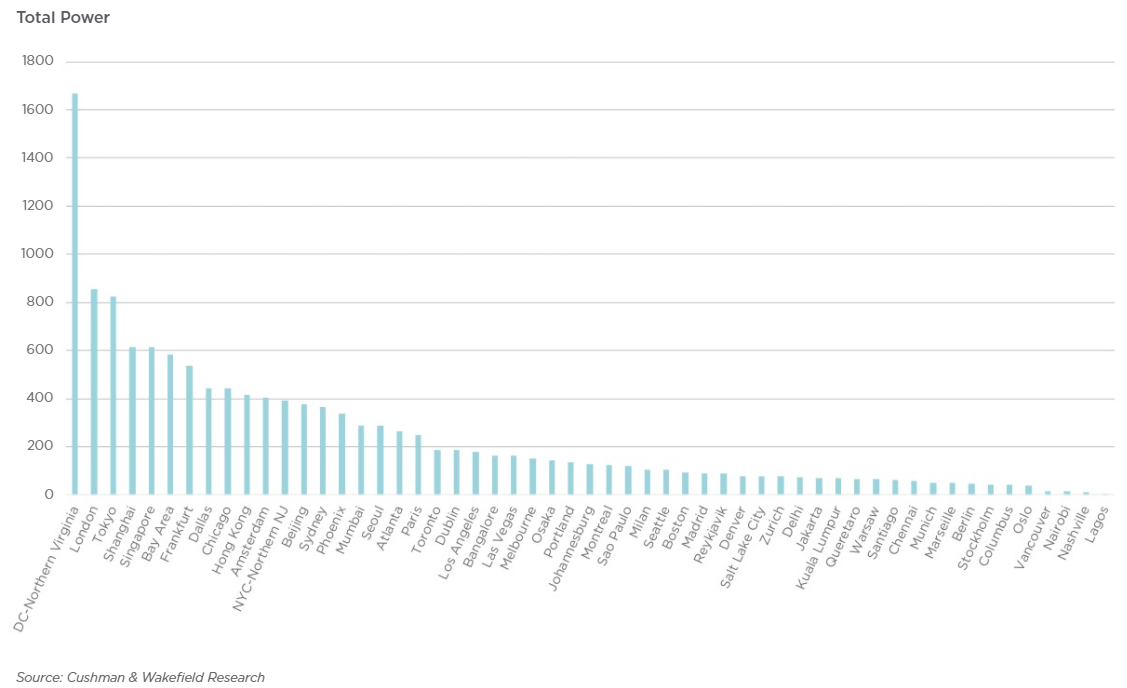 Основная беда в том, что Наблюдательный совет округа намеренно исключил шум от промышленных кондиционеров из правил 1989 года, в соответствии с которыми и строились дата-центры, в результате чего округ потерял законную возможность контролировать работу ЦОД в этом отношении, независимо от того, какой громкости звук издают объекты. Местные жители жалуются на проблемы как с собственным здоровьем, так и с состоянием домашних питомцев. Благодаря местным регуляциям Северная Вирджиния крайне привлекательна для строителей и операторов дата-центров. Текущая ёмкость ЦОД в штате составляет порядка 1,7 ГВт, а через два года, как ожидается, она достигнет 2 ГВт. И это самый крупный в мире рынок ЦОД. Для сравнения — суммарная ёмкость сразу четырёх европейских рынков FLAP только-только добралась до 2 ГВт. Та же Amazon за последний десяток лет вложила в постройку дата-центров в Северной Вирджинии более $35 млрд.
26.05.2022 [11:53], Владимир Мироненко
Материнская компания розничной сети Lidl запустила конкурента AWS в ГерманииSchwarz Group, материнская компания европейской сети розничных продовольственных магазинов Lidl, официально объявила о доступности сервисов своего облачного подразделения StackIT для сторонних клиентов. О планах Schwarz Group по оказанию облачных услуг сторонним ретейлерам стало известно в 2020 году после приобретения ею компании Camao IDC, специализирующейся на разработке программного обеспечения. Сообщается, что Schwarz Group начала работу над облачным сервисом в 2018 году и запустила его для собственных нужд примерно в 2019 году. В ноябре 2021 года Schwarz Group приобрела контрольный пакет акций израильской фирмы по кибербезопасности XM Cyber. До нынешнего дня StackIT предоставляла услуги компаниям Schwarz Group, включая сети супермаркетов Lidl и гипермаркетов Kaufland, компанию по производству продуктов питания Schwarz Produktion и компанию по переработке вторичных отходов PreZero. 
Источник изображения: Schwartz Group / StackIT Помимо услуги колокейшна, StackIT предлагает ряд облачных и инфраструктурных сервисов, включая хранение данных, базы данных, вычислительные инстансы и многое другое. Компания предлагает услуги на базе объекта в австрийском Остермитинге, известного как DC10, и ЦОД в Эльхофене (Германия), известного как DC08. «Благодаря StackIT впервые становится доступным облачное решение, которое на 100 % “Сделано в Германии” и ориентировано на высокие требования и потребности в безопасности предприятий и организаций государственного сектора», — отметил директор по данным Schwarz Digital Рольф Шуман (Rolf Schumann).
02.05.2022 [01:08], Владимир Мироненко
AWS представила инстансы I4i с Intel Xeon Ice Lake-SP и NVMe-накопителями Nitro SSD собственной разработкиAWS представила инстансы I4i со сверхбыстрым хранилищем. Новинки используют Intel Xeon Ice Lake-SP и NVMe-накопители Nitro SSD, разработанные самой Amazon. I4i обеспечивают снижение задержки операций ввода-вывода до 60 % (разброс тоже ниже на 75 %) по сравнению с инстансами I3, а также до 30 % лучшее соотношение цены и производительности. Благодаря использованию сразу нескольких компонентов Nitro, все физические ресурсы узлов доступны инстансам практически полностью. I4i «предназначены для минимизации задержки и максимизации количества транзакций в секунду (TPS) для рабочих нагрузок, которым требуется очень быстрый доступ к наборам данных среднего размера в локальном хранилище. Сюда входят транзакционные базы данных, такие как MySQL, Oracle DB и Microsoft SQL Server, а также базы данных NoSQL: MongoDB, Couchbase, Aerospike, Redis и т.д.». Они также подходят для рабочих нагрузок, требующих высокую производительность вычислений в пересчёте на Тбайт хранилища, таких как аналитика данных и поисковые системы. 
Узлы с Nitro SSD (Изображение: AWS) У всех новинок частота всех ядер в турборежиме составляет 3,5 ГГц; есть поддержка AVX-512 и Intel Total Memory Encryption. Для особо ресурсоёмких задач предлагается инстанс I4i.32xlarge: 128 vCPU, 1 Тбайт RAM (с NUMA), сетевое подключение 75 Гбит/с, 40-Гбит/с доступ к EBS-томам и восемь локальных Nitro SSD суммарной ёмкостью 30 Тбайт. Nitro SSD имеют продвинутую прошивку, отвечающую за реализацию многих функций, включая телеметрию и диагностику на лету, а также управление хранилищем на уровне инстанса для повышения надёжности и обеспечения стабильного уровня производительности. Инстансы I4i уже доступны в регионах AWS US East (Северная Виргиния), US East (Огайо), US West (Орегон) и Европа (Ирландия) по запросу и в качестве спотовых и зарезервированных. Доступны планы Savings, а также выделенные инстансы и выделенные хосты. Клиентам рекомендуется использовать последние AMI, включающие текущие драйверы ENA и поддержку NVMe 1.4.
07.12.2021 [00:36], Алексей Степин
ИИ-ускорители AWS Trainium: 55 млрд транзисторов, 3 ГГц, 512 Гбайт HBM и 840 Тфлопс в FP32GPU давно применяются для ускорений вычислений и в последние годы обросли поддержкой специфических форматов данных, характерных для алгоритмов машинного обучения, попутно практически лишившись собственно графических блоков. Но в ближайшем будущем их по многим параметрам могут превзойти специализированные ИИ-процессоры, к числу которых относится и новая разработка AWS, чип Trainium. На мероприятии AWS Re:Invent компания рассказала о прогрессе в области машинного обучения на примере своих инстансов P3dn (Nvidia V100) и P4 (Nvidia A100). Первый вариант дебютировал в 2018 году, когда модель BERT-Large была примером сложности, и благодаря 256 Гбайт памяти и сети класса 100GbE он продемонстрировал впечатляющие результаты. Однако каждый год сложность моделей машинного обучения растёт почти на порядок, а рост возможностей ИИ-ускорителей от этих темпов явно отстаёт. 
Сложность моделей машинного обучения будет расти всё быстрее Когда в прошлом году был представлен вариант P4d, его вычислительная мощность выросла в четыре раза, а объём памяти и вовсе на четверть, в то время как знаменитая модель GPT-3 превзошла по сложности BERT-Large в 500 раз. А теперь и 175 млрд параметров последней — уже ничто по сравнению с 10 трлн в новых моделях. Приходится наращивать и объём локальной памяти (у Trainium имеется 512 Гбайт HBM с суммарной пропускной способностью 13,1 Тбайт/с), и активнее использовать распределённое обучение.  Для последнего подхода узким местом стала сетевая подсистема, и при разработке стека Elastic Fabric Adapter (EFA) компания это учла, наделив новые инстансы Trn1 подключением со скоростью 800 Гбит/с (вдвое больше, чем у P4d) и с ультранизкими задержками, причём доступен и более оптимизированный вариант Trn1n, у которого пропускная способность вдвое выше и достигает 1,6 Тбит/с. Для связи между самими чипами внутри инстанса используется интерконнект NeuroLink со скоростью 768 Гбайт/с. 
Прогресс подсистем сети и памяти в ИИ-инстансах AWS Но дело не только в возможности обучить GPT-3 менее чем за две недели: важно и количество используемых для этого ресурсов. В случае P3d это потребовало бы 600 инстансов, работающих одновременно, и даже переход к архитектуре Ampere снизил бы это количество до 200. А вот обучение на базе чипов Trainium требует всего 130 инстансов Trn1. Благодаря оптимизациям, затраты на «общение» у новых инстансов составляют всего 7% против 14% у Ampere и целых 49% у Volta. 
Меньше инстансов, выше эффективность при равном времени обучения — вот что даст Trainium Trainium опирается на систолический массив (Google использовала тот же подход для своих TPU), т.е. состоит из множества очень тесно связанных вычислительных блоков, которые независимо обрабатывают получаемые от соседей данные и передают результат следующему соседу. Этот подход, в частности, избавляет от многочисленных обращений к регистрам и памяти, что характерно для «классических» GPU, но лишает подобные ускорители гибкости.  В Trainium, по словам AWS, гибкость сохранена — ускоритель имеет 16 полностью программируемых (на С/С++) обработчиков. Есть и у него и другие оптимизации. Например, аппаратное ускорение стохастического округления, которое на сверхбольших моделях становится слишком «дорогим» из-за накладных расходов, хотя и позволяет повысить эффективность обучения со смешанной точностью. Всё это позволяет получить до 3,4 Пфлопс на вычислениях малой точности и до 840 Тфлопс в FP32-расчётах.  AWS постаралась сделать переход к Trainium максимально безболезненным для разработчиков, поскольку SDK AWS Neuron поддерживает популярные фреймворки машинного обучения. Впрочем, насильно загонять заказчиков на инстансы Trn1 компания не собирается и будет и далее предоставлять на выбор другие ускорители поскольку переход, например, с экосистемы CUDA может быть затруднён. Однако в вопросах машинного обучения для собственных нужд Amazon теперь полностью независима — у неё есть и современный CPU Graviton3, и инфереренс-ускоритель Inferentia.
04.12.2021 [03:42], Игорь Осколков
Процессор Amazon Graviton3: 64 ядра Arm, 5-нм техпроцесс, чиплетная компоновка и DDR5 с PCIe 5.0Анонсированный на днях Arm-процессор Graviton3, создававшийся специально для нужд Amazon и AWS, неожиданно оказался по ряду параметров на голову выше ещё даже не вышедших EPYC и Xeon следующего поколения. И это не самый хороший сигнал для AMD, Intel, Qualcomm и прочих производителей. 
Amazon Graviton3. Фото: Ian Colle Graviton3 — первый массовый (самой Amazon и рядом избранных клиентов он используется уже не один месяц) серверный процессор с поддержкой DDR5 и PCIe 5.0. CPU выполнен по 5-нм техпроцессу TSMC и содержит примерно 55 млрд транзисторов. Для удешевления он использует BGA-корпусировку и чиплетную компоновку из семи отдельных кристаллов — два PCIe-контроллера и четыре двухканальных контроллера DDR5 вынесены за пределы собственно CPU. 
Узел EC2 C7g. Здесь и ниже изображения Amazon AWS Более того, их упаковка использует передовые решения с каналами длиной менее 55 мкм, что вдвое меньше, чем у других серверных CPU. Уменьшение длины проводников положительно сказывается на энергоэффективности, которая очень важна для любого гиперскейлера. Этим же объясняется и относительно небольшое по современным меркам число ядер (всего 64) и их частота (2,6 ГГц). Всё это позволило добиться энергопотребления примерно в 100 Вт. 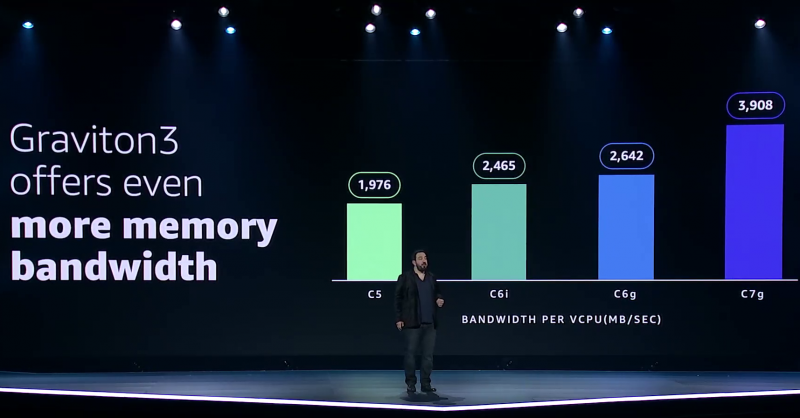 Есть и ещё один важный плюс в сохранении числа ядер — переход на DDR5-4800 позволил не только достичь пиковой суммарной пропускной способности памяти в 300 Гбайт/с на чип, но и повысить реальную скорость работы с памятью каждого vCPU (фактически ядра) в полтора раза по сравнению с прошлым поколением. Та же ситуация и с PCIe 5.0 — для достижения той же пропускной способности, что ранее, нужно вдвое меньше линий.  Для удешевления используются готовые IP-блоки сторонних компаний и, судя по всему, ядра тоже несильно отличаются от референсов Arm. А вот какие именно, узнаем не сразу, поскольку Amazon явно не указала, будут ли это Neoverse V1 (Zeus) или N2 (Perseus). Вероятно, это всё же V1 (ARMv8.5-A), поскольку по описанию Graviton3 похожи именно на эту архитектуру. Новые ядра стали значительно «шире» прежних — они забирают 8 инструкций, декодируют от 5 до 8 из них и отправляют на исполнение сразу 15 инструкций. Соответственно и число исполнительных блоков по сравнению с Neoverse-N1 (Graviton2) практически удвоилось. 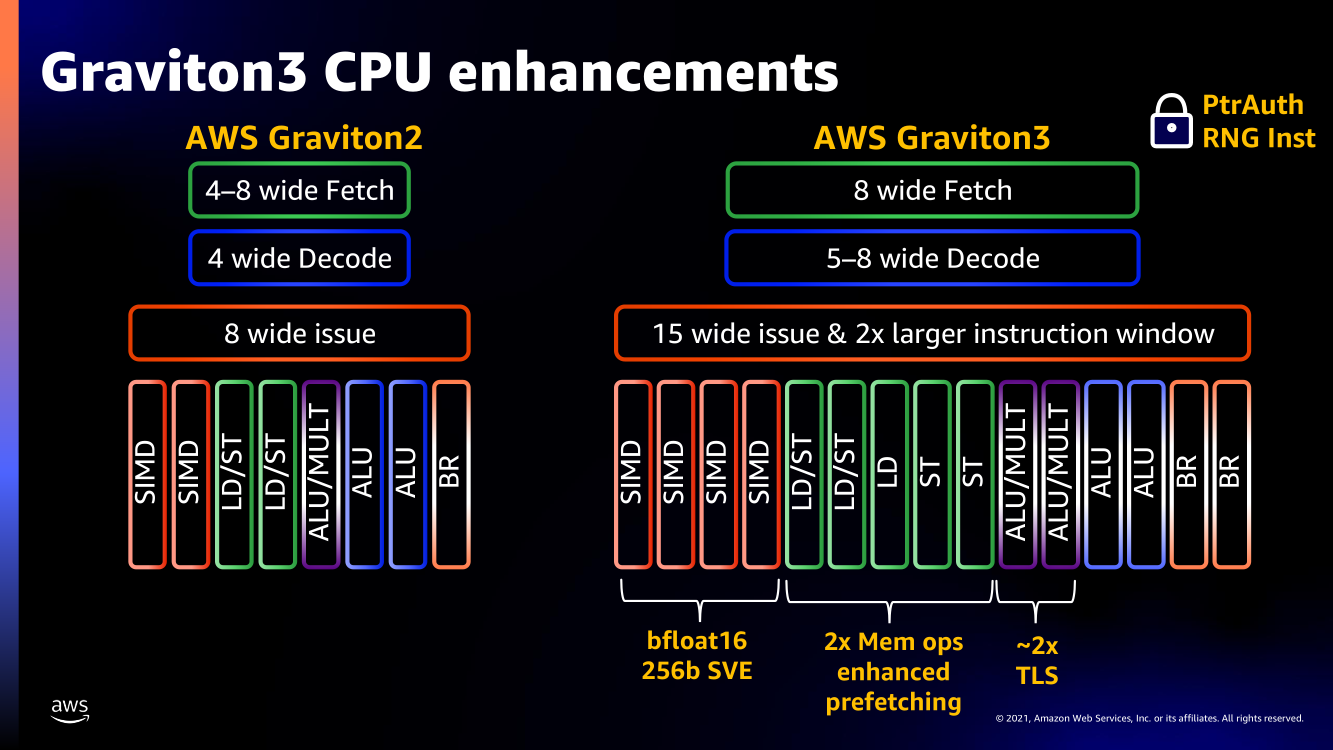  Кроме того, они обзавелись поддержкой 256-бит векторных инструкций SVE, что повысило не только скорость выполнения «классических» FP-операций (например, для задач медиакодирования и шифрования), но и благодаря поддержке bfloat16 позволило утверждать Amazon, что новые чипы годятся и для инференса. Среди упомянутых ранее мер защиты есть, например, принудительное шифрование оперативной памяти, изолированные кеши для каждого vCPU (ядра), аппаратная защита стека. 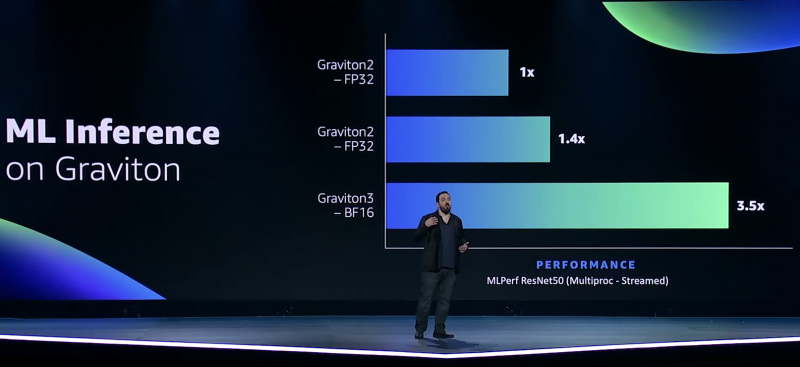
В подписи второго столбца явная опечатка В целом, средний прирост производительности Graviton3 по сравнению с Graviton2 составил 25 %, но в некоторых задачах он достигает 60 %. И всё это при сохранении того же уровня энергопотребления и тепловыделения. Всё это позволило уместить в одном 1U-узле с воздушным охлаждением сразу три процессора Graviton3. И они разительно отличаются от грядущих 128-ядерных процессоров Altra Max и EPYC Bergamo, которые Ampere и AMD позиционируют как решения для гиперскейлеров. Зато в чём-то похожи на Yitian 710 от Alibaba Cloud. 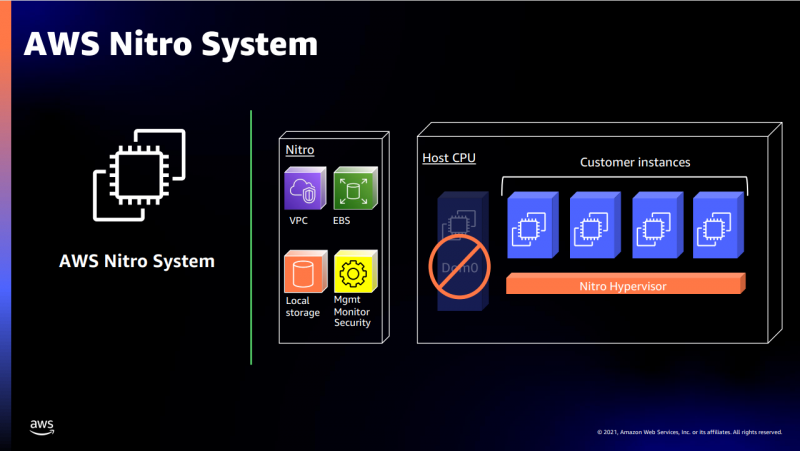 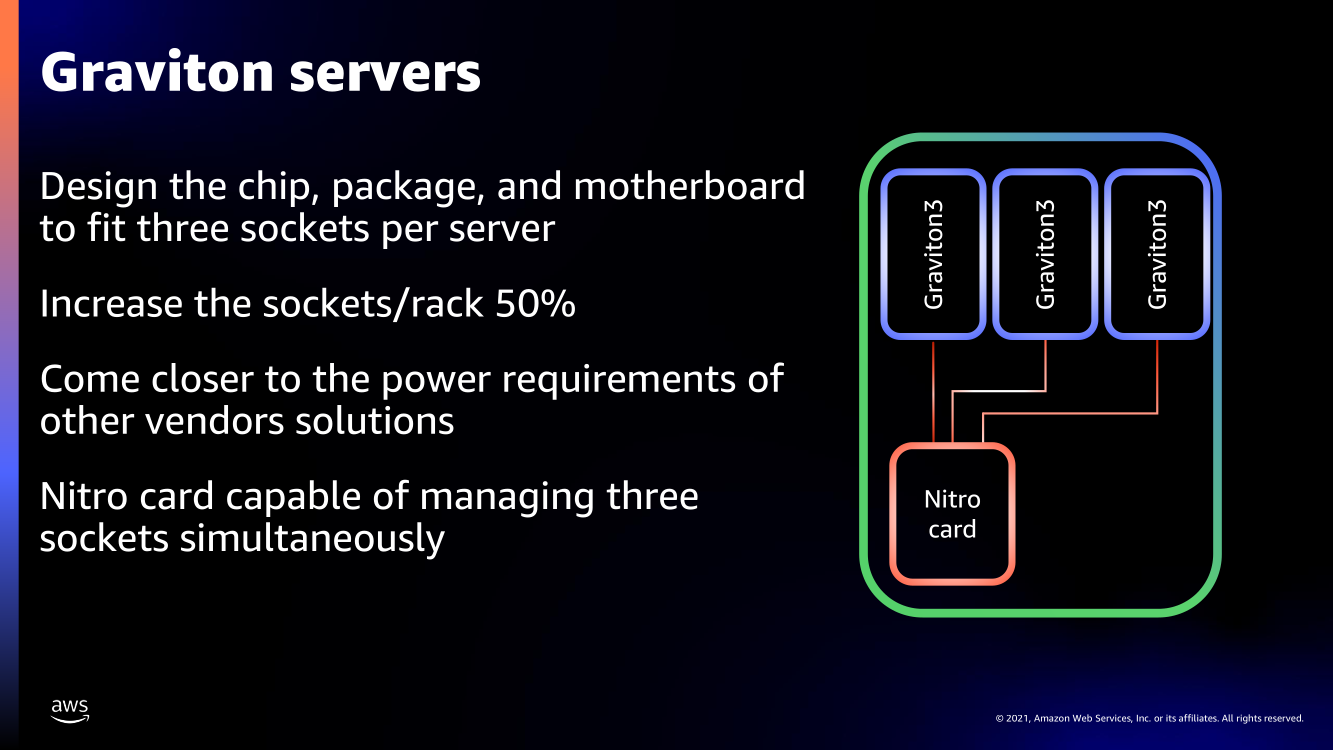 Но CPU — это лишь часть платформы, фундамент для которой несколько лет назад заложило появление чипов Nitro. Их сейчас стоило бы назвать DPU/IPU, хотя на момент их появления такого понятия, можно сказать, и не было. Nitro берёт на себя все задачи по обслуживанию гипервизора, обеспечению безопасности, работе с хранилищем и сетью и т.д., высвобождая, с одной стороны, все ресурсы CPU, памяти и SSD для обработки задачи клиента, а с другой — позволяя практически полностью дезагрегировать всю инфраструктуру. 
Узел с Nitro SSD Впрочем, Amazon пошла ещё дальше — теперь она самостоятельно закупает NAND-чипы и производит SSD, тоже под управлением Nitro. То есть у компании под контролем практически полный стек современных аппаратных решений: CPU, DPU, SSD, ИИ-ускорители для обучения (Trainium) и инференса (Inferentia). Она активно переносит на него собственные сервисы и предлагает их клиентам. И именно это и должно обеспокоить крупных вендоров, поскольку их решения вряд ли позволят добиться такого же уровня TCO, а гиперскейлеров, желающих перейти на аналогичную модель, немало.  UPD 06.12.21: презентация новых процессоров стала доступна публично, поэтому в материал добавлены некоторые иллюстрации, а в галерее ниже приведены результаты тестов производительности.
07.10.2021 [18:09], Руслан Авдеев
AWS потратила на дата-центры $35 млрд в одной только Северной ВирджинииЗа прошедшие 10 лет облачный провайдер AWS потратила $35 млрд на строительство инфраструктуры на севере штата Вирджиния (США). Строительство такого масштаба оказало важное влияние на региональную экономику. Обычно гиперскейлеры не делятся детальными сведениями о своих затратах на ЦОД, но в данном случае речь идёт об отчёте, который призван показать, как сотрудничество местных органов власти и индустрии дата-центров может положительно влиять на возможности развития региона. Сегодня Amazon относится к числу техногигантов, способных играть ведущие роли при создании облачных систем. На северо-востоке штата сейчас находится более 50 дата-центров, формирующих крупнейшее в мире облачное пространство. При этом кластер в Северной Вирджинии — это только часть инфраструктуры AWS, включающей шесть облачных регионов на территории США и 25 по всему миру. Однако именно регион US-East исторически является наиболее важным и крупным для AWS, поскольку здесь развёрнуто сразу шесть зон доступности (AZ).  Провайдеры облачных сервисов сыграли важную роль для развития финансовых систем всего мира в период пандемии. В то же время и заработок AWS в 2020 году составил $45 млрд — больше, чем у многих подразделений Amazon, связанных с торговлей. Деятельность Amazon в штате позволяет акцентировать внимание на двух фактах — по данным компании, создание облачных кластеров несёт большие преимущества для локальных экономик, но вместе с тем требует финансирования в объёмах, доступных лишь немногим компаниям. 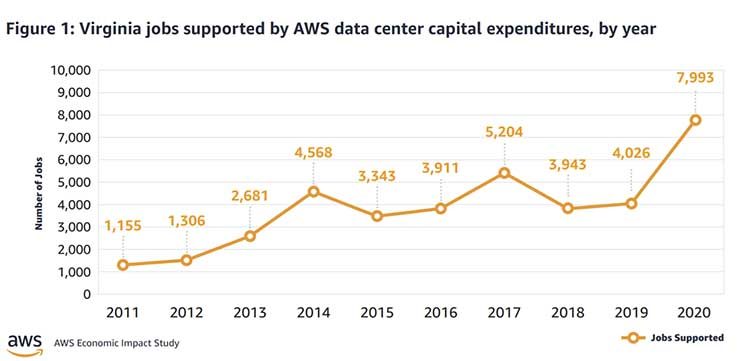
datacenterfrontier.com Расширение проекта Amazon в Северной Вирджинии потребовало закупки местных земель, строительства большего числа дата-центров — это позволяет с запасом обеспечить корпоративный спрос на облачные решения. Прямым следствием становится появление рабочих мест среди местных жителей и рост затрат на местах на обслуживание инфраструктуры, обеспечение безопасности, а также рост поступлений налогов в местные бюджеты:
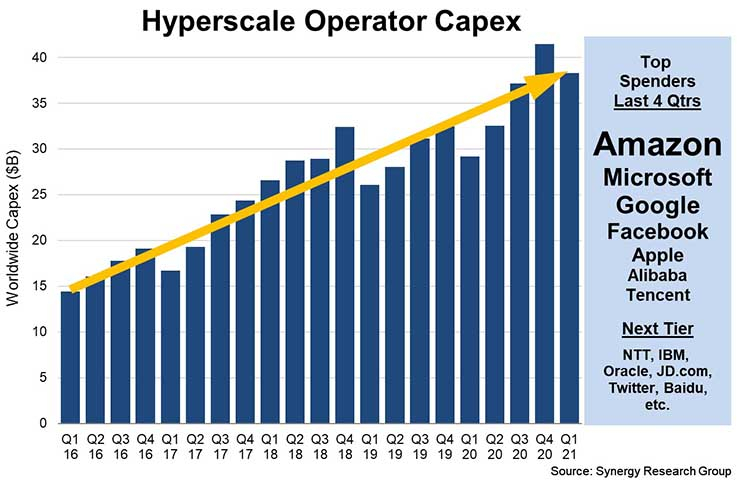 Инвестиции объёмом $35 млрд в Вирджинии — самые масштабные для одного штата. Такие большие расходы соответствуют масштабным потребностям в затратах, необходимых для создания соответствующей инфраструктуры — конкурирующие компании вроде Google, Microsoft и Facebook✴ обычно тратят на строительство каждого облачного кампуса от $600 млн до $4 млрд. Тем не менее, в последнее время капитальные вложения всей индустрии выросли почти на треть. |
|
