Материалы по тегу: arm
|
08.05.2025 [23:59], Владимир Мироненко
Квартальная выручка Arm впервые превысила $1 млрд, но акции упали из-за слабого прогнозаArm Holdings объявила результаты IV квартала и всего 2025 финансового года, завершившегося 31 марта 2025 года. Несмотря на рекордную выручку, впервые в истории компании превысившую $1 млрд за квартал, её акции упали в ходе расширенных торгов на 11 % из-за слабого прогноза на I квартал 2026 финансового года, оказавшегося ниже ожиданий Уолл-стрит, а также из-за отказа предоставить прогноз на весь финансовый год, пишет Reuters. «Масштабные мировые пошлины, объявленные президентом США Дональдом Трампом (Donald Trump), и более жёсткие ограничения США на экспорт передовых полупроводников на ключевой рынок микросхем Китая омрачили перспективы полупроводниковых компаний», — отметило новостное агентство. 
Источник изображений: Arm «Учитывая неопределённость глобальной торговой и экономической ситуации, у нас меньше возможностей для обзора, чем обычно, чтобы начать год. В результате мы не считаем целесообразным давать прогноз на весь год», — сообщил финансовый директор Джейсон Чайлд (Jason Child) аналитикам во время телефонной конференции. 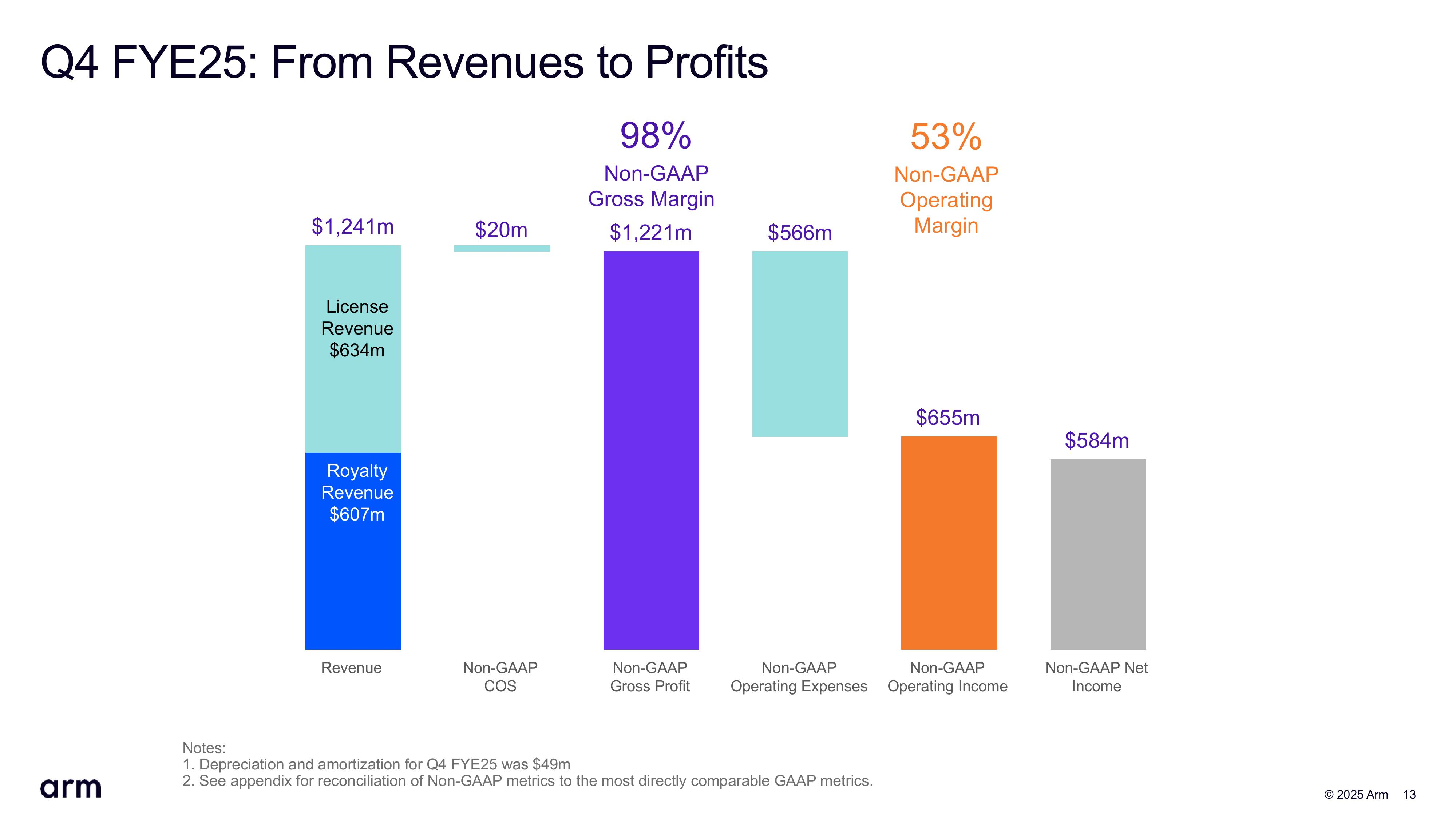 В свою очередь, гендиректор Рене Хаас (Rene Haas) заявил, что растущая доля выручки Arm от роялти за чипы, реализация которых, в свою очередь, связана с продажами таких устройств, как смартфоны и ноутбуки, затрудняет прогнозирование показателей. Выручка Arm за IV финансовый квартал составила $1,24 млрд, превысив результат аналогичного квартала годом ранее в размере $928 млн на 34 %, а также консенсус-прогноз аналитиков, опрошенных LSEG, равный $1,23 млрд. При этом выручка от лицензирования за квартал увеличилась на 53 % до $634 млн с $414 млн годом ранее, выручка от роялти выросла на 18 % — с $514 млн до $607 млн. 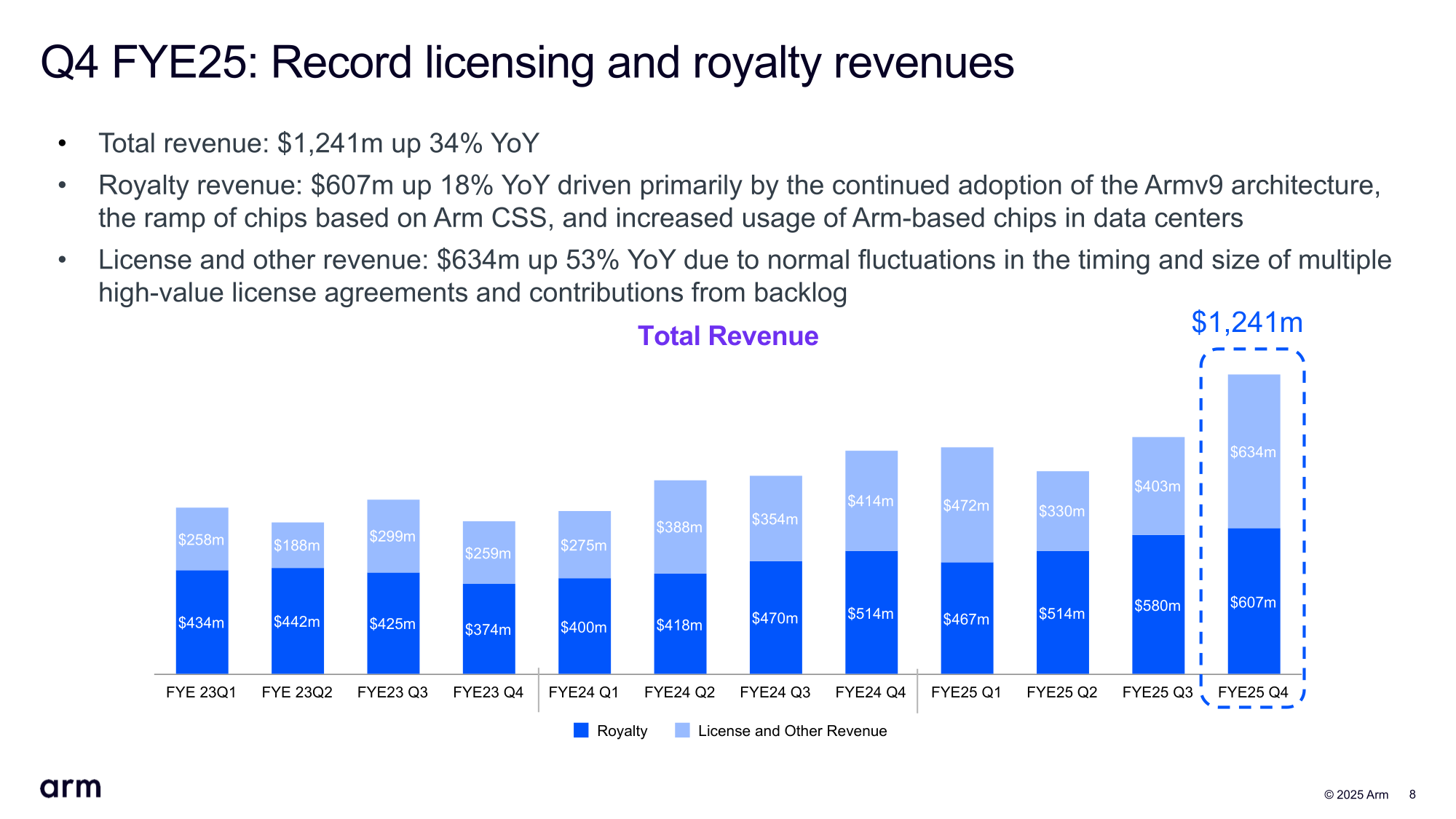 Чистая прибыль (GAAP) упала на 6 % до $210 млн, или 20 центов на акцию, с $224 млн или 21 цента годом ранее. Скорректированная прибыль (non-GAAP) на акцию в размере 55 центов превысила прогноз аналитиков, опрошенных FactSet и LSEG, равный в обоих случаях 52 центам на акцию. По итогам 2025 финансового года выручка компании составила $4 млрд, а доходы от роялти впервые превысили $2 млрд, составив $2,17 млрд. Выручка Arm от лицензирования за год равна $1,84 млрд. 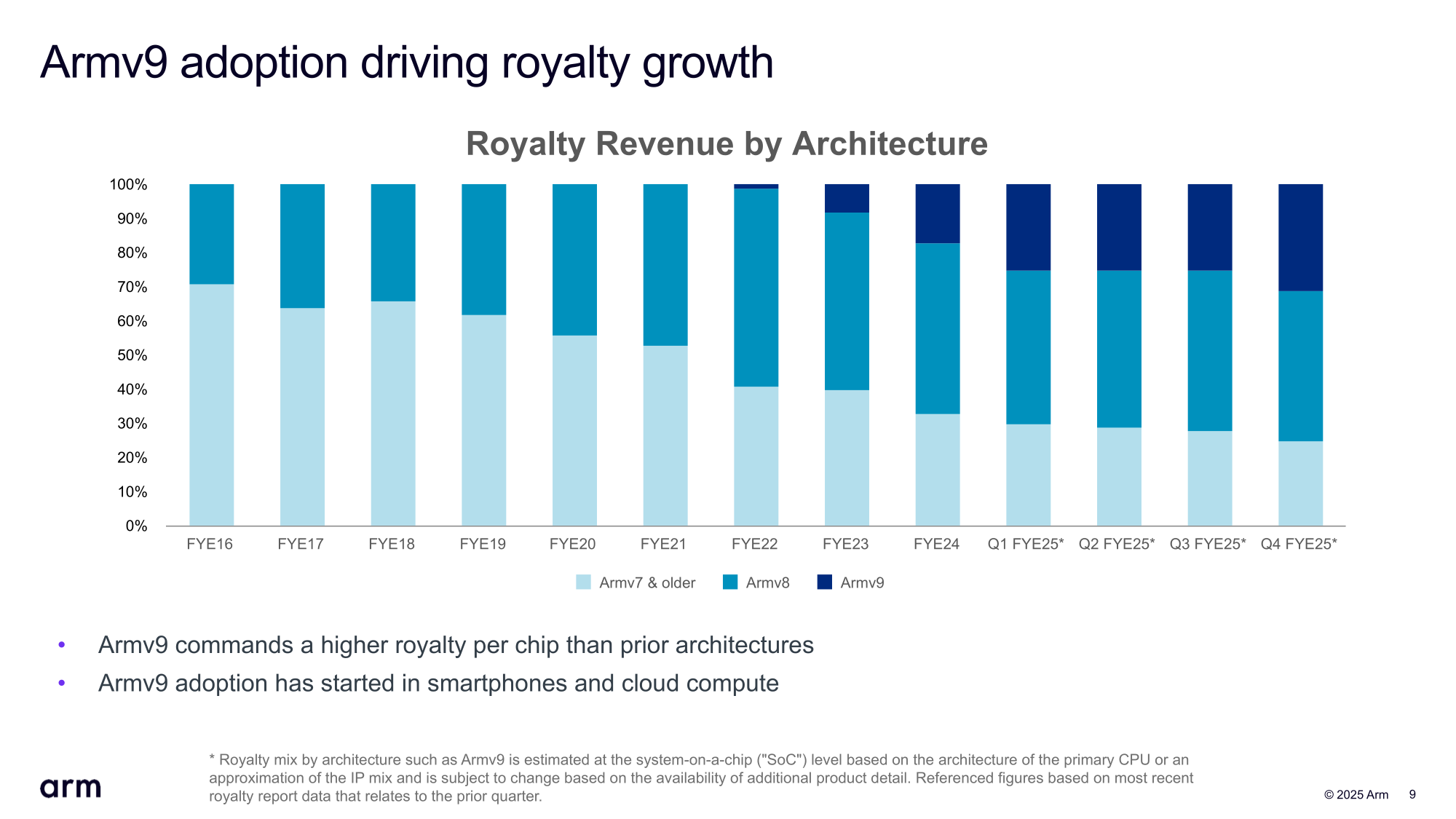 Arm прогнозирует выручку за I квартал 2026 финансового года в размере от $1,00 до $1,10 млрд, что ниже средней оценки аналитиков, опрошенных LSEG, в $1,10 млрд. Прогноз скорректированной прибыли составляет от 30 до 38 центов на акцию по сравнению с оценкой аналитиков в 42 цента на акцию. Как сообщает Reuters, прогноз компании, оказавшийся ниже ожиданий аналитиков, был обусловлен крупной лицензионной сделкой, которую, возможно, не удастся закрыть в течение текущего финансового квартала. Он добавил, рост выручки от роялти составит в I финансовом квартале от 25 до 30 %, что выше, чем в предыдущем квартале. Arm отметила, что быстрый рост использования ИИ от облака до периферии создаёт спрос на энергоэффективные вычисления, который способны удовлетворить её решения, в частности, платформа Arm Neoverse. Она добавила, что NVIDIA запустила суперчип Grace Blackwell на базе Armv9 в серийное производство. 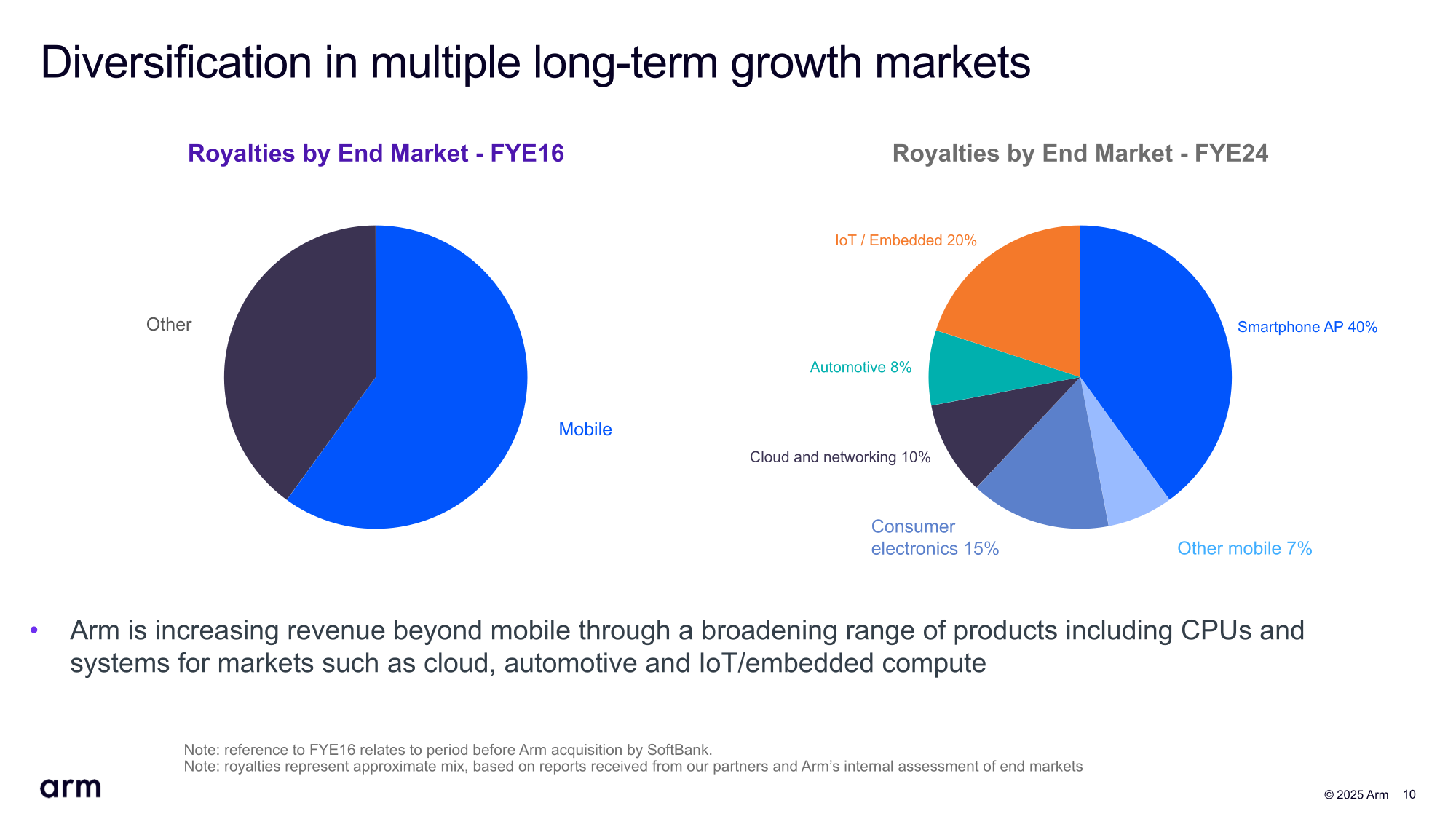 Согласно прогнозу Arm, около 50 % всех новых серверных чипов, поставляемых гиперскейлерам в 2025 году, будут основаны на архитектуре Arm. Эти компании объединяют собственные чипы на базе Armv9 с собственными же ускорителями для запуска ИИ-нагрузок. Так, Google подтвердила, что её чип Axion теперь доступен в 10 регионах и используется примерно 40 из 100 ее крупнейших клиентов, включая Spotify. Microsoft расширила спектр программной поддержки своих чипов Cobalt 100, запустив рабочие нагрузки различных клиентов, включая Databricks, Siemens и Snowflake. Arm также сообщила, что продолжает увеличивать инвестиции в свою экосистему из более чем 22 млн разработчиков ПО, включая новое бесплатное расширение для GitHub Copilot. Кроме того, ПО Arm Kleidi для максимизации производительности ИИ на платформе Arm было установлено более 8 млрд раз на устройствах на базе Arm.
07.05.2025 [11:28], Сергей Карасёв
Ampere представила процессоры AmpereOne M для ИИ-задач: до 192 ядер Arm и 12 каналов памяти DDR5Компания Ampere Computing анонсировала процессоры семейства AmpereOne M, разработанные специально для поддержания ресурсоёмких ИИ-нагрузок в дата-центрах. Утверждается, что чипы подходят для задач инференса, работы с большими языковыми моделями (LLM), генеративным ИИ и пр. О подготовке новых изделий впервые сообщалось летом прошлого года. Конфигурация процессоров включает от 96 до 192 кастомизированных 64-бит ядер на базе Arm v8.6+. Имеется 16 Кбайт кеша инструкций и 64 Кбайт кеша данных L1 в расчёте на ядро, а также 2 Мбайт L2-кеша на ядро. Объём системного кеша составляет 64 Мбайт. Реализованы 12 каналов DDR5-5600 (поддерживается один модуль DIMM на канал) с возможностью адресации до 3 Тбайт памяти. 
Источник изображений: Ampere Конструкция чипов включает 96 линий PCIe 5.0 с поддержкой бифуркации до режима x4 и возможностью использования до 24 дискретных подключённых устройств. Упомянуты средства виртуализации, шифрование памяти, поддержка прерываний I2C, GPIO, QSPI и GPI, системный и сторожевой таймеры. Предусмотрены развитые функции обеспечения безопасности, включая повышение производительности криптографических алгоритмов RNG, SHA512, SHA3. На сегодняшний день в серию AmpereOne M входят шесть моделей с тактовой частотой от 2,6 до 3,6 ГГц. Показатель TDP варьируется от 239 до 348 Вт. Благодаря интеллектуальной сети с высокой пропускной способностью и большому количеству однопоточных вычислительных ядер обеспечивается линейное масштабирование производительности в зависимости от текущей рабочей нагрузки. Возможна динамическая оптимизация мощности. 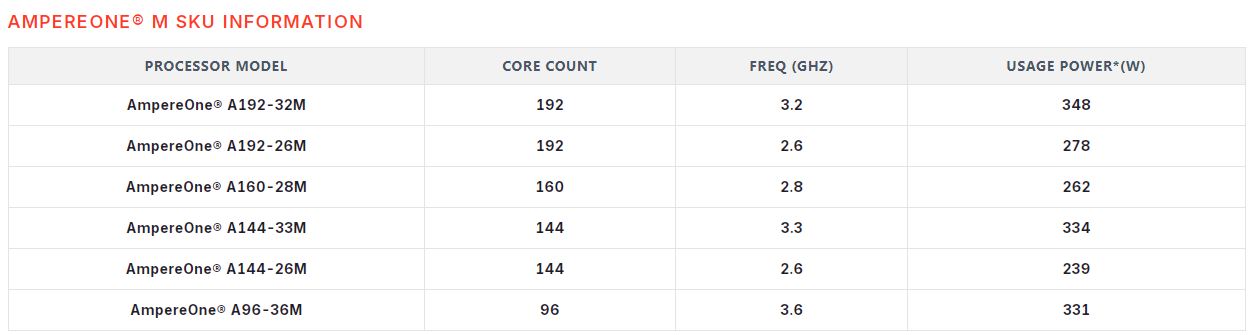 Процессоры используют 7228-контактный разъём FCLGA. При производстве применяется 5-нм технология TSMC. По заявлениям Ampere, новые CPU подходят для применения в составе систем для серверных стоек высокой плотности. Благодаря этому достигается снижение эксплуатационных расходов по сравнению с ИИ-инфраструктурой на базе GPU.
02.04.2025 [18:06], Руслан Авдеев
Arm собиралась купить Alphawave ради передовой технологии SerDes для выпуска ИИ-чипов — теперь её хочет купить QualcommПринадлежащий SoftBank разработчик архитектурных решений для полупроводников — компания Arm недавно собиралась приобрести британскую Alphawave для получения критически важной технологии, необходимой для создания ИИ-ускорителей. Об этом сообщили Reuters три независимых источника, «знакомых с вопросом». Теперь над покупкой Alphawave раздумывает Qualcomm, уточняет SiliconAngle. Alphawave владеет интеллектуальной собственностью, связанной с полупроводниковыми технологиями, и даже обсуждала с инвестиционными банкирами возможность продажи — после того как Arm и другие потенциальные покупатели выразили интерес к приобретению компании. Однако, по данным двух источников, в итоге было решено отказаться от сделки. На фоне новостей акции Alphawave взлетели на 21 % — рекордный рост с сентября 2021 года. По данным на конец торгов в понедельник капитализация компании составила £707 млн ($914 млн), а цена акции — 93,5 пенса. Arm рассчитывала получить от Alphawave технологию создания SerDes-блоков, которые определяют скорость передачи данных на чип и с него. Эта технология критически важна для ИИ-систем, таких как ChatGPT, где тысячи чипов должны работать согласованно. Так, SerDes является ключевым преимуществом Broadcom, помогая компании привлекать клиентов вроде Google и OpenAI. 
Источник изображения: Arm Arm с головным офисом в Великобритании на 90 % принадлежит японской SoftBank Group. Компания сама не разрабатывает чипы, а продаёт «основные строительные блоки» для их создания, а также прочую интеллектуальную собственность. Основные доходы Arm получает за счёт лицензионных отчислений от других бизнесов, а также роялти за каждый проданный чип, использующий её технологии. Недавно сообщалось, что она рассчитывает, что её архитектура займёт 50 % на рынке чипов для ЦОД уже к концу 2025 года. У AWS, Google Cloud и Microsoft Azure уже есть собственные серверные Arm-процесоры: Graviton, Axion и Cobalt 100. Конечно, компания стремилась повысить прибыль и выручку, в том числе не исключалась самостоятельная разработка чипов и прямая конкуренция с собственными клиентами. Планы покупки Alphawave частично раскрылись в декабре 2024 года в ходе судебной тяжбы с Qualcomm. Однако руководство Arm заявило, что речь шла об обычном обмене идеями между менеджерами. Тем не менее, в ходе того же процесса в феврале стало известно, что компания искала специалистов, способных вывести на рынок чип собственной разработки. Теперь же выяснилось, что Qualcomm сама не прочь приобрести Alphawave — компания должна сделать предложение до 29 апреля или полностью отказаться от сделки. У Arm нет столь передовой технологии SerDes, какой располагает Alphawave. Хотя подробностей немного, известно, что SerDes-блоки служат основой многомиллиардных полупроводниковых бизнесов Broadcom и Marvell Technology. По прогнозам Bernstein, соответствующий рынок к 2028 году вырастет до $60 млрд. NVIDIA также разработала собственный вариант SerDes и уже заявила о намерении продавать лицензии на него другим компаниям. Создание передовых решений в этой сфере критически важно для выпуска ИИ-чипов, способных выгодно отличаться от продукции конкурентов. При этом, по мнению экспертов, разработка SerDes с нуля требует специфических навыков и около двух лет. Покупка Alphawave смогла бы сэкономить Arm значительное количество времени и ресурсов.
01.04.2025 [14:53], Владимир Мироненко
Arm намерена занять 50 % рынка чипов для ЦОД к концу 2025 года — NVIDIA ей в этом поможетСогласно прогнозу Arm Holdings, к концу 2025 года доля процессоров с Arm-архитектурой на мировом рынке CPU для ЦОД вырастет до 50 % с 15 % в 2024 году. В интервью агентству Reuters Мохамед Авад (Mohamed Awad), руководитель подразделения инфраструктурных решений Arm, отметил, что благодаря более низкому энергопотреблению, чем у процессоров Intel и AMD, Arm-чипы становятся все более популярными среди компаний, занимающихся облачными вычислениями. Журналист ресурса The Register обратился в Arm Holdings с просьбой пояснить, благодаря чему компания рассчитывает добиться столь стремительного роста доли на рынке. Как сообщили в британской компании, принадлежащей японскому конгломерату Softbank, её прогноз в значительной степени основан на росте поставок ИИ-серверов. Мохамед Авад сообщил The Register, что в течение следующих нескольких лет, как ожидает компания, продажи ИИ-серверов вырастут на 300 %. «Для этого увеличения энергоэффективность больше не является конкурентным преимуществом — это базовое отраслевое требование. Именно здесь вычислительная платформа Arm Neoverse является явным лидером и предпочтительной платформой для ведущих партнёров отрасли, включая AWS, Google, Microsoft и NVIDIA», — заявил он. 
Источник изображения: Arm Holdings Как утверждает Arm Holdings, Arm-архитектура всё чаще используется гиперскейлерами AWS, Google, Microsoft в своих чипах. По оценкам Bernstein Research, в 2023 году почти 10 % серверов по всему миру содержат Arm-процессоры приложений в качестве «основных мозгов», и половина из них была развёрнута Amazon, сообщившей, что у нее в облаке используется более 2 млн чипов Graviton собственной разработки. В свою очередь, Google объявила в 2024 году о выпуске собственного процессора Axion на базе Neoverse V2 для своих ЦОД, а Microsoft сообщила в конце прошлого года об общедоступности в облаке Azure инстансов с использованием процессоров собственной разработки Cobalt 100. Расширение использования этими провайдерами облачных услуг Arm-процессоров может объяснить часть роста, который Авад прогнозирует на этот год, но продукты NVIDIA также, вероятно, составят значительную долю, полагает The Register. Например, система DGX GB200 NVL72 включает 36 процессора NVIDIA Grace и 72 ускорителя Blackwell B200, что составляет 2592 ядра Arm Neoverse V2, и они, вероятно, будут востребованы в этом году, отметил ресурс. Также не следует забывать о других решениях для ЦОД, которые имеют ядра на базе Arm-архитектуры, такие как SmartNIC и DPU — BlueField-3 от NVIDIA, а также карты Nitro в серверах AWS.
22.03.2025 [14:10], Сергей Карасёв
GL.iNet Comet — компактный IP-KVM с поддержкой Fingerbot для нажатия физических кнопокКомпания GL.iNet анонсировала компактное решение Comet GL-RM1 — устройство удалённого управления IP-KVM (Keyboard, Video, Mouse). Новинка может применяться для дистанционного включения/выключения и перезагрузки компьютеров, в том числе посредством нажатия на физические кнопки. В основу Comet положен процессор с четырьмя ядрами Arm Cortex-A7, функционирующими на частоте 1,5 ГГц. Объём оперативной памяти DDR3 составляет 1 Гбайт, встроенной флеш-памяти eMMC — 8 Гбайт. Предусмотрены сетевой порт 1GbE и интерфейс HDMI с поддержкой формата 2К (2160 × 1440@60). Заявлена возможность аппаратного кодирования материалов H.264 с задержкой 30–60 мс. 
Источник изображения: GL.iNet Новинка располагает портом USB 2.0 Type-C для эмуляции мыши/клавиатуры, а также гнездом RJ45 для сетевого кабеля. Кроме того, имеется разъём USB 2.0 Type-A для подключения периферийных устройств, таких как Fingerbot: это специальный умный переключатель, который позволяет удалённо нажимать на физические кнопки, например, на кнопку включения питания на компьютерном корпусе. Дополнительно предлагается небольшая плата управления питанием ATX. Comet имеет размеры 80 × 60 × 17,5 мм и весит 85 г. В комплект поставки входят кабели Ethernet и USB. Питание (5 В / 2 А) подаётся через дополнительный порт USB Type-C. Заявленное энергопотребление составляет около 3 Вт. В качестве ОС применяется «лёгкая» сборка Linux с поддержкой таких функций, как удалённое управление KVM, виртуальная клавиатура, буфер обмена, настройка качества изображения, поворот экрана, передача файлов, доступ к BIOS и пр. Оформить предварительный заказ на GL.iNet Comet (GL-RM1) можно по цене $69 или $80,9 вместе с платой управления питанием ATX. В дальнейшем стоимость возрастёт до $89 и $104,9 соответственно.
20.03.2025 [13:53], Руслан Авдеев
SoftBank решила купить производителя Arm-процессоров Ampere Computing за $6,5 млрдSoftBank Group подтвердила покупку производителя Arm-чипов Ampere Computing. Сделка оценивается в $6,5 млрд и, как ожидается, будет закрыта во II половине 2025 года, сообщает Silicon Angle. Оба главных акционера Ampere — Oracle Corp. и Carlyle Group — согласились продать свои доли в компрании. После покупки Ampere будет действовать как независимое дочернее подразделение SoftBank, штаб-квартира компании по-прежнему останется в Санта-Кларе (Калифорния). Основанная в 2017 году бывшим вице-президентом Intel Рене Джеймс (Renee James) компания специализируется на выпуске серверных Arm-процессоров. Самой производительной моделью является AmpereOne M, поставки которого начались в декабре 2024 года. Процессор получил до 192 ядер и большую пропускную способность памяти, чем его предшественники. Также компания работает над разработкой ещё более производительного CPU Aurora который получит 512 ядер, HBM-память и выделенный ИИ-модуль. 
Источник изображения: Ampere В SoftBank заявили, что покупают Ampere, в которой трудятся около 1 тыс. специалистов по полупроводникам, поскольку будущее «искусственного суперинтеллекта» требует прорывных вычислительных мощностей. Опыт Ampere в сфере чипов и HPC поможет ускорить соответствующие процессы и углубляет приверженность SoftBank к ИИ-инновациям в США. По имеющимся данным, Ampere впервые рассматривала продажу в сентябре 2024 года, позже компания наняла финансового консультанта для оценки перспектив. SoftBank выразила потенциальный интерес к покупке в январе 2025 года, а в прошлом месяце сообщалось, что переговоры о сделке идут весьма успешно. SoftBank уже является ключевым игроком на рынке чипов благодаря доле в Arm Holdings, купленной за $32 млрд в 2016 году. Arm вышла на IPO в 2023 году, но SoftBank всё ещё владеет крупнейшей долей компании. В прошлом июле SoftBank заключила сделку о покупке ещё одного производителя чипов — компании Graphcore, которая, как и Arm, базируется в Великобритании. Graphcore разрабатывает ИИ-ускорители. Сообщалось, что SoftBank может способствовать сотрудничеству Ampere и Graphcore в деле создания ИИ-серверов.
20.03.2025 [01:10], Владимир Мироненко
Анонсированы суперускорители на Rubin и Rubin Ultra, в которых NVIDIA не будет ошибаться в подсчётахNVIDIA анонсировала ИИ-ускорители следующего поколения Rubin, которые придут на смену Blackwell Ultra во II половине 2026 года. Выход Rubin Ultra запланирован на II половину 2027 года. Компанию им составят Arm-процессоры Vera. Серия названа в честь астронома Веры Купер Рубин (Vera Florence Cooper Rubin), известной своими исследованиями тёмной материи. NVIDIA отметила, что в названии предыдущих ускорителей была «допущена ошибка». В Blackwell каждый чип состоит из двух GPU, но, например, в названии GB200/GB300 NVL72 упоминается только 72 GPU, хотя речь фактически идёт о 144 GPU. Поэтому, начиная с Rubin компания будет использовать новую схему наименований, которая больше не учитывает количество чипов, а относится исключительно к количеству GPU. Таким образом, следующее поколение суперускорителей, упакованных в ту же стойку Oberon, что используется для Grace Blackwell, получило название Vera Rubin NVL144. Rubin во многом повторяет дизайн Blackwell, поскольку R200 всё так же включает два кристалла GPU (в составе SXM7), способных выдавать до 50 Пфлопс в вычислениях FP4 (без разреженности), и 288 Гбайт памяти в восьми стеках 12-Hi, но на этот раз уже HBM4 с общей пропускную способностью 13 Тбайт/с (2048-бит шина). Кристаллы GPU будут изготовлены по техпроцессу TSMC N3P, а компанию им составят два IO-чиплета, отвечающие за все внешние коммуникации, пишет SemiAnalysis. Всё вместе будет упаковано посредством CoWoS-L. TDP новинок не указывается. 
Источник изображений: NVIDIA Чипы перейдут на интерконнект NVLink 6 со скоростью 1,8 Тбайт/с в каждую сторону (3,6 Тбайт/с в дуплексе), что вдвое выше, чем у текущего поколения NVLink 5. Аналогичным образом вырастет и коммутационная способность NVSwitch, а также NVLink C2C. Впрочем, при сохранении прежней схемы, когда один CPU обслуживает два модуля GPU, каждому из последних, по-видимому, достанется половина пропускной способности шины. Собственно процессор Vera получит 88 кастомных (а не Neoverse CSS в случае Grace) 3-нм Arm-ядра, причём с SMT, что даст 176 потоков. Каждый CPU получит порядка 1 Тбайт LPDDR-памяти и будет вдвое быстрее Grace при теплопакете в районе 50 Вт.  По словам NVIDIA, VR200 NVL144 будет в 3,3 раза быстрее: 3,6 Эфлопс в FP4-вычислениях для инференса и 1,2 Эфлопс в FP8 для обучения. Суммарный объём HBM-памяти составит более 20,7 Тбайт, системной памяти — 75 Тбайт. Внешняя сеть будет представлена адаптерами ConnectX-9 SuperNIC со скоростью 1,6 Тбит/с на порт, что вдвое больше, чем у ConnectX-8, обслуживающих GB300.  Во II половине 2027 года появится ускоритель Rubin Ultra (R300) с FP4-производительностью более 100 Пфлопс (без разреженности), объединяющий сразу четыре GPU, два IO-чиплета и 16 стеков HBM4e-памяти 16-Hi общим объёмом 1 Тбайт (32 Тбайт/с) в упаковке SXM8. Более того, ускорители, по-видимому, получат ещё и LPDDR-память. Процессор Vera перекочует в новую платформу без изменений, один CPU будет приходиться на четыре GPU. Внутренней шиной станет NVLink 7, которая сохранит скорость NVLink 6, зато получит вчетверо более производительные коммутатор NVSwitch. А вот внешнее подключение по-прежнему будут обслуживать адаптеры ConnectX-9.  Новая стойка Kyber полностью поменяет компоновку. Узлы теперь напоминают вертикальные блейд-серверы, используемые в суперкомпьютерах. Каждый узел (VR300) будет включать один процессор Vera и один ускоритель Rubin Ultra. Всего таких узлов будет 144, что в сумме даёт 144 CPU, 576 GPU и 144 Тбайт HBM4e. Суперускоритель Rubin Ultra NVL576 будет потреблять 600 кВт и обеспечит быстродействие в 15 Эфлопс для инференса (FP4) и 5 Эфлопс для обучения (FP8). При этом упоминается, что объём быстрой (fast) памяти составит 365 Тбайт, но сколько из них достанется CPU, не уточняется. Дальнейшие планы NVIDIA включают выход во II половине 2028 года первого ускорителя на новой архитектуре Feynman, названной в честь физика-теоретика Ричарда Филлипса Фейнмана (Richard Phillips Feynman). Сообщается, что Feynman будет полагаться на память HBM «следующего поколения» и, вероятно, на CPU Vera. Это поколение также получит коммутаторы NVSwitch 8 (NVL-Next), сетевые коммутаторы Spectrum7 и адаптеры ConnectX-10.
18.03.2025 [10:09], Сергей Карасёв
Микроконтроллер Raspberry Pi RP2350 поступил в продажу по цене от $0,8Компания Raspberry Pi объявила о начале продаж микроконтроллера RP2350, который является основой крошечной платы Raspberry Pi Pico 2, дебютировавшей в августе прошлого года. Кроме того, RP2350 применяется в ряде других изделий, например, в составе микроплаты Pico W5. Микроконтроллер содержит по два ядра Arm Cortex-M33 и RISC-V Hazard3 с тактовой частотой 150 МГц. Нужный кластер выбирается при инициализации изделия, то есть, использовать одновременно блоки Cortex-M33 и RISC-V нельзя. Устройство располагает 520 Кбайт памяти SRAM. За безопасность отвечают средства Arm TrustZone. 
Источник изображения: Raspberry Pi Raspberry Pi RP2350 обеспечивает поддержку 2 × UART, 2 × SPI, 2 × I2C, 24 × PWM и пр. Изделие на программном уровне совместимо с микроконтроллером Raspberry Pi RP2040. Предусмотрены варианты исполнения RP2350A (QFN-60; 7 × 7 мм; 30 × GPIO) и RP2350B (QFN-80; 10 × 10 мм; 48 × GPIO). Кроме того, к выпуску готовятся модификации RP2354A и RP2354B в аналогичных исполнениях, дополненные 2 Мбайт флеш-памяти Stacked Flash. При заказе по отдельности стоимость RP2350A и RP2350B составляет соответственно $1,1 и $1,2. Микроконтроллеры также можно приобрести оптом в катушках размером 7" и 13": в первом случае изделия обойдутся в $0,9 и $1,0 за единицу (500 штук в катушке), во втором — в $0,8 и $0,9 за штуку (3400 и 2500 единиц в катушке). Компания Raspberry Pi предоставляет для микроконтроллеров подробную документацию, которая поможет в реализации различных проектов: это могут быть устройства IoT, встраиваемые системы промышленного класса, потребительские продукты и пр.
13.03.2025 [11:14], Сергей Карасёв
Texas Instruments представила самый маленький в мире Arm-микроконтроллерКомпания Texas Instruments анонсировала изделие MSPM0C1104 — это, как утверждается, самый компактный в мире микроконтроллер, выполненный на архитектуре Arm: площадь новинки составляет всего 1,38 мм2 (в исполнении DSBGA). Решение предназначено для использования в носимых медицинских приборах, персональных электронных гаджетах и других устройствах с жёстко ограниченным пространством внутри корпуса. Микроконтроллер оснащён 32-битным ядром Arm Cortex-M0+ с тактовой частотой до 24 МГц. Есть 1 Кбайт памяти SRAM и до 16 Кбайт флеш-памяти. Реализована поддержка 1 × UART, 1 × I2C, 1 × SPI, 18 × GPIO. Есть аналого-цифровой преобразователь (АЦП) с поддержкой до десяти внешних каналов и встроенный датчик температуры. 
Источник изображений: Texas Instruments Напряжение питания может варьироваться от 1,62 до 3,6 В. Реализованы различные режимы с пониженным энергопотреблением: Run — 87 мкА/МГц, Stop — 609 мкА при 4 МГц или 311 мкА при 32 кГц, а также Standby — 5 мкА с сохранением содержимого памяти SRAM. Диапазон рабочих температур простирается от -40 до +125 °C. Микроконтроллер Texas Instruments MSPM0C1104 доступен в следующих вариантах исполнения:
 Для новинки Texas Instruments предоставляет референсные проекты и набор средств разработки для быстрого прототипирования. В частности, доступен комплект LaunchPad с интерфейсной платой. Цена микроконтроллера начинается с $0,2 при поставках партиями от 1000 штук.
01.03.2025 [15:45], Сергей Карасёв
MikroTik представила устройство RDS2216 — гибрид Arm-сервера, NAS и коммутатораКомпания MikroTik анонсировала необычную стоечную систему RDS2216, которая фактически объединяет несколько устройств в корпусе формата 1U. Новинка может выполнять функции сервера с архитектурой Arm, сетевого хранилища данных (NAS) и коммутатора. В основу решения положен процессор Annapurna Labs AL73400 (AWS Graviton). Чип объединяет 16 Armv8-ядер Cortex-A72 с частотой до 2 ГГц. В оснащение входят 32 Гбайт оперативной памяти DDR4 и 128 Мбайт флеш-памяти NAND. Задействован коммутационный чип Marvell Prestera 98DX4310 с частичной L3-разгрузкой. 
Источник изображений: MikroTik Система располагает двумя портами 10GbE с разъёмами RJ45, четырьмя портами SFP28 25GbE, двумя портами QSFP28 100GbE, а также четырьмя 10GbE-портами SFP+. Плюс к этому предусмотрены разъём 1GbE и консольный порт (RJ45). Имеются два порта USB 3.0 Type-A, а также пара SFF-8644. Сервер может нести на борту до 20 накопителей U.2 NVMe толщиной 7 мм (PCIe 3.0 x2) и поддержкой TCG OPAL. Кроме того, могут быть установлены два внутренних модуля М.2 с интерфейсом SATA.  Питание обеспечивают два блока с возможностью горячей замены, а за охлаждение отвечают десять вентиляторов. Диапазон рабочих температур простирается от -20 до +50 °C. В качестве программной платформы применяется RouterOS v7 (Special ROSE Edition). Эта система поддерживает такие функции, как шифрование данных, моментальные снимки, сжатие и совместное использование хранилища по протоколам NFS, iSCSI, SMB, NVMe/TCP. Устройство выполнено в оригинальном оливковом цвете. В продажу MikroTik RDS2216 поступит по ориентировочной цене $1950 без установленных накопителей. |
|