Материалы по тегу: arm
|
13.10.2023 [00:45], Владимир Мироненко
Fujitsu готовит 2-нм 150-ядерный серверный Arm-процессор MONAKA с поддержкой PCIe 6.0 и CXL 3.0Fujitsu провела на этой неделе брифинг для СМИ и аналитиков на заводе в Кавасаки, на котором рассказала о разработке серверного процессора MONAKA, появление которого на рынке запланировано в 2027 году, пишет ресурс MONOist. Впервые о создании нового поколения CPU компания объявила весной этого года, а часть средств на разработку выделило правительство Японии. Как сообщил Наоки Синдзё (Naoki Shinjo), гендиректор подразделения развития передовых технологий Fujitsu, MONAKA представляет собой высокопроизводительный энергоэффективынй процессор нового поколения, который разрабатывается для значительного повышения энергоэффективности ЦОД и обеспечения высокоскоростной обработки данных, необходимой для приложений ИИ и цифровой трансформации. 
Источник изображений: MONOist MONAKA будет основан на процессорной архитектуре Arm с набором инструкций Armv9-A с поддержкой масштабируемых векторных расширений SVE2. Он будет представлять собой 3D-сборку из чиплетов, а и его изготовление будет осуществляться с использованием 2-нм техпроцесса TSMC. По словам Синдзё, у процессора будет около 150 ядер, поддержка памяти DDR5 и интерфейс PCIe 6.0 с CXL 3.0. При этом для работы ему будет достаточно воздушного охлаждения.  Fujitsu ожидает, что MONAKA будет в два раза превосходить по энергоэффективности чипы конкурентов и во столько же раз опережать конкурентов по скорости обработки данных в области вычислений, ориентированных на рабочие нагрузки ИИ. За обеспечение безопасности данных в Armv9-A отвечает архитектура конфиденциальных вычислений Arm Confidential Compute Architecture (CCA). 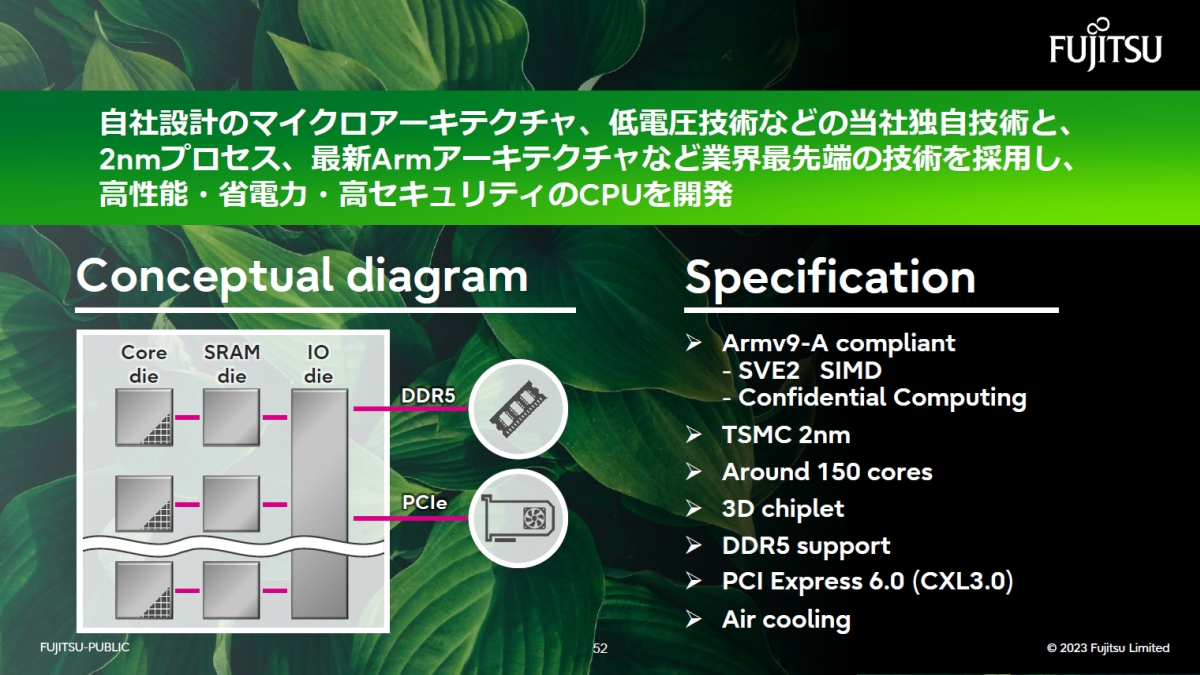 Также сообщается, что в суперкомпьютере-преемнике Fugaku, который будет запущен в 2030 году, будут использоваться процессоры, разработанные с применением технологий, задействованных в MONAKA. В отличие от узкоспециализированных HPC-процессоров FUjitsu A64FX, которые легли в основу Fugaku, чипы MONAKA являются более универсальными решениями.
10.10.2023 [23:20], Сергей Карасёв
NVIDIA выпустит ускорители GB200 и GX200 в 2024–2025 гг.Компания NVIDIA, по сообщению ресурса VideoCardz, раскрыла планы по выпуску ускорителей нового поколения, предназначенных для применения в ЦОД и на площадках гиперскейлеров. NVIDIA указывает лишь ориентировочные сроки выхода решений, поскольку фактические даты зависят от многих факторов, таких как макроэкономическая обстановка, готовность сопутствующего ПО, доступность производственных мощностей и пр. В конце мая нынешнего года NVIDIA объявила о начале массового производства суперчипов Grace Hopper GH200, предназначенных для построения НРС-систем и платформ генеративного ИИ. Эти изделия содержат 72-ядерный Arm-процессор NVIDIA Grace и ускоритель NVIDIA H100 с 96 Гбайт памяти HBM3. Как сообщается, ориентировочно в конце 2024-го или в начале 2025 года на смену Grace Hopper GH200 придет решение Blackwell GB200. Характеристики изделия пока не раскрываются. Но отмечается, что архитектура Blackwell будет применяться как в ускорителях для дата-центров, так и в потребительских продуктах для игровых компьютеров (предположительно, серии GeForce RTX 50). На 2025 год, согласно обнародованному графику, намечен анонс загадочной архитектуры «Х». Речь, в частности, идёт о решении с обозначением GX200. Изделия GB200 и GX200 подойдут для решения задач инференса и обучения моделей. Примечательно, что старшие чипы также получат NVL-версии. Вероятно, вариант GH200 с увеличенным объёмом набортной памяти как раз и будет называться GH200NVL. 
Источник изображения: NVIDIA При этом теперь компания разделяет продукты на Arm- и x86-направления. Первое, судя по всему, так и будет включать гибридные решения GB200 и GX200, а второе, вероятно, вберёт в себя в первую очередь ускорители в форм-факторе PCIe-карт и универсальные ускорители начального уровня серии 40: B40 и X40. Сопутствовать новым чипам будут сетевые решения Quantum (InfiniBand XDR/GDR) и Spectrum-X (Ethernet) классов 800G и 1600G (1.6T). И если в области InfiniBand компания фактически является монополистом, то в Ethernet-сегменте она несколько отстаёт от, например, Broadcom, у которой теперь есть даже выделенные ИИ-решения, Cisco и Marvell. А вот про будущее NVLink компания пока ничего не рассказала.
10.10.2023 [22:09], Руслан Авдеев
Vodafone ускорит внедрение 5G-сетей OpenRAN на базе Arm-систем от AmpereТелеком-гигант Vodafone поддерживает многочисленные проекты в рамках парадигмы OpenRAN, в том числе сотрудничая с лидерами полупроводниковой индустрии. Как сообщает The Register, компания подтвердила сотрудничество с Arm в разработке энергоэффективных чипов для базовых станций 5G. Попутно она взаимодействует и с Intel OpenRAN — концепция, предполагающая строительство мобильной инфраструктуры с использованием элементов, выпускаемых различными производителями. В Vodafone рассчитывают ускорить развитие своей платформы OpenRAN, используя Arm-архитектуру. Предполагается, что это позволит удовлетворить растущий пользовательский спрос на быстрые и «зелёные» мобильные решения. В компании сообщили, что уже работают с производителем Arm-процессоров Ampere Computing и компанией SynaXG, специалистом по выпуску сетевых решений, для тестирования и оценки решений на Arm-архритектуре. Тестирование должно начаться ещё до конца этого года, после чего начнётся интеграция с коммерческим ПО OpenRAN от Fujitsu для последующих испытаний на площадках Vodafone в Испании и Великобритании в I квартале 2024 года. В Vodafone сообщают и о вероятной проверке совместимости с оборудованием других вендоров. 
Источник изображения: Steven Van Elk/unsplash.com Ожидается, что это позволит расширить полупроводниковую и программную экосистему OpenRAN-решений, а расширение числа лучших в своём классе поставщиков, конкурирующих на одном поле, приведёт к ускорению инноваций, повышению энергоэффективности и безопасности на благо пользователей. Впрочем, одним из основных мотивов внедрения OpenRAN всё ещё является экономия средств. Сообщается, что компания уже работает с Intel над похожими разработками. По некоторым данным, ведутся работы над архитектурой специализированного чипсета в лабораториях Vodafone в Испании, а Intel должна создать образцы чипов для начала тестов мобильным оператором. Более того, плоды работ над Arm-решениями хотят сделать достоянием всей мобильной индустрии. В Vodafone утверждают, что это обеспечит мелкие компании необходимой поддержкой, чтобы те тоже смогли внести свой вклад в Open RAN-проекты. Также на этой неделе Vodafone объявила о дополнительных планах запуска коммерческого пилотного OpenRAN-проекта уровня 5G при участии Nokia. Проект будет реализован на севере Италии и предусматривает использование контейнеризованного ПО Nokia на платформе Red Hat OpenShift. Оно будет применяться с оборудованием, включающим серверы Dell PowerEdge XR8000, а также сетевые ускорители Nokia, разработанные совместно с Marvell.
05.10.2023 [13:00], Сергей Карасёв
Первый европейский суперкомпьютер экзафлопсного класса Jupiter получит Arm-чипы SiPearl Rhea и ускорители NVIDIAЕвропейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) заключило контракт на создание НРС-комплекса Jupiter с консорциумом, в который входят Eviden (подразделение IT-услуг французской корпорации Atos) и ParTec, немецкая компания по производству суперкомпьютерного оборудования. Проект Jupiter был анонсирован ещё в июне 2022 года. Речь идёт о создании первого в Европе суперкомпьютера экзафлопсного класса. Система расположится в Юлихском исследовательском центре (FZJ) в Германии. В основу ляжет специализированная модульная архитектура на базе платформы Eviden BullSequana XH3000 с прямым жидкостным охлаждением. По оценкам, общая стоимость проекта составит €273 млн, включая доставку, установку и обслуживание Jupiter. Половина средств поступит непосредственно от EuroHPC JU, а остальная часть — от Федерального министерства образования и исследований Германии и Министерства культуры и науки земли Северный Рейн-Вестфалия. Eviden полагает, что создание суперкомпьютера обойдётся суммарно в €500 млн с учётом затрат на производство системы и её эксплуатацию в течение пяти лет. Строительство НРС-комплекса стартует в начале 2024 года. 
Источник изображения: europa.eu Полностью характеристики Jupiter пока не раскрываются. Но говорится, что суперкомпьютер будет состоять из высокомасштабируемого блока ускорителей (Booster) и тесно связанного с ним кластера общего назначения (Cluster). В состав первого войдут неназванные ускорители NVIDIA и решения Mellanox. Говорится об использовании более 260 км высокопроизводительных кабелей, что обеспечит пропускную способность сети свыше 2000 Тбит/с. В свою очередь, модуль Cluster получит энергоэффективные высокопроизводительные Arm-процессоры SiPearl Rhea, которые специально разработаны для европейских суперкомпьютеров. Ожидается, что производительность Jupiter превысит 1 Эфлопс. Для сравнения: в нынешнем рейтинге TOP500 самым быстрым европейским суперкомпьютером является Lumi в Финляндии. Этот комплекс занимает в списке третье место с быстродействием 309,1 Пфлопс (пиковый показатель достигает 428,7 Пфлопс). Таким образом, Jupiter превзойдёт Lumi по производительности более чем в три раза. Выбор EuroHPC JU в пользу Arm-процессоров SiPearl Rhea — разочарование для AMD и Intel. В частности, Intel в 2022 году объявила о намерении инвестировать €33 млрд в создание исследовательских центров и производственных объектов на территории Европы, включая Германию, Францию, Ирландию, Италию, Польшу и Испанию. Модульная конструкция Jupiter предполагает, что в будущем к системе могут быть добавлены дополнительные узлы, в частности, на процессорах х86, но пока о таких планах ничего не говорится. В любом случае Европа стремится к аппаратной независимости, а поэтому выбор чипов Rhea для Jupiter не является неожиданным. Как и все суперкомпьютеры EuroHPC, комплекс Jupiter будет доступен широкому кругу пользователей в научном сообществе, промышленности и государственном секторе на территории Европы. Мощности системы планируется использовать для задач ИИ, высокоточного моделирования, медицинских исследований, изучения глобальных изменений климата, разработки передовых материалов и других ресурсоёмких задач.
25.09.2023 [12:00], Владимир Мироненко
Oracle завершила миграцию всех своих облачных сервисов на Arm и представила инстансы Ampere A2 c процессорами AmpereOneOracle представила инстансы Ampere A2 следующего поколения на базе 192-ядерных Arm-процессоро AmpereOne, которые станут доступны для клиентов компании позднее в этом году. Как сообщает Oracle, новые инстансы обеспечивают на 44 % лучшее соотношение цены и производительности по сравнению с предложениями на архитектуре x86 и идеально подходят для ИИ-инференса, работы с базами данных, веб-сервисами, рабочих нагрузок транскодирования мультимедиа и поддержки среды выполнения для таких языков, как GO и Java. Инстансы OCI Ampere A2 предлагают до 320 ядер в случае bare metal и до 156 ядер в рамках одной виртуальной машины. Обладая большим объёмом приватного кеша, стабильной рабочей частотой, однопоточными ядрами и новыми функциями управления памятью, инстансы нового поколения позволяют обеспечить ещё более предсказуемую производительность за счёт снижения влияния внешних помех, как происходит в случае SMT, и одновременно предлагают безопасную микроархитектуру для многопользовательских облачных сред. 
Источник изображений: Ampere «То, что происходит с OCI и Ampere, является отражением значительных перемен, происходящих в нашей отрасли, — сказала гендиректор Ampere Рене Джеймс (Renee James). — Времена использования мощности в качестве показателя производительности переходят в эру высокопроизводительных вычислений с низким энергопотреблением. Такие клиенты, как 8X8 и другие, признают, что существует необходимость снизить затраты на инфраструктуру и в то же время сократить выбросы углекислого газа без ущерба для производительности. В нашу эру компьютеров с ИИ новая сила — это меньшая мощность». Клэй Магоуирк (Clay Magouyrk), исполнительный вице-президент Oracle Cloud Infrastructure Development, сообщил, что в связи с быстрым ростом Oracle подошла к пределам доступной мощности, и для дальнейшего масштабирования облака ей необходим рост эффективности в дополнение к производительности: «Вот почему мы используем Ampere для всего: от базы данных Oracle до приложений Fusion, а теперь и для всех наших сервисов OCI. С развитием ИИ-обработки этот сдвиг в вычислениях стал ещё более важным. Ampere — это решение OCI для устойчивого облака». СУБД Oracle Database полностью поддерживается процессорами Ampere. Кроме того, все сервисы OCI, число которых исчисляется сотнями, теперь тоже работают на CPU Ampere. Конечные клиенты могут перенести все свои рабочие нагрузки на платформу Ampere, в том числе задачи инференса, которые поддерживаются библиотеками AI Optimizer от Ampere.
30.06.2023 [21:39], Владимир Мироненко
Глава Oracle считает, что архитектура Intel x86 теряет актуальность для серверовВ 2023 году Oracle планирует потратить значительные средства на приобретение чипов AMD и Ampere Computing для новой инфраструктуры, отметив, что «старая архитектура Intel x86 достигает своего предела». «В этом году Oracle купит GPU и CPU у трёх компаний, — сообщил на прошедшем в среду мероприятии глава Oracle Ларри Эллисон (Larry Ellison). — Мы будем покупать GPU у NVIDIA, мы покупаем у неё на миллиарды долларов США. И потратим в три раза больше на центральные процессоры от Ampere и AMD. Мы по-прежнему тратим больше денег на традиционные чипы». Oracle сообщила, что впервые за 14 лет существования специализированных ПАК Exadata для СУБД она полностью отказалась от процессоров Intel в пользу чипов AMD. В платформе 12-го поколения Exadata X10M в рамках двух предложений Oracle Exadata Machine и управляемого решения Oracle Exadata Cloud@Customer будут использоваться AMD EPYC Genoa. Одной из причин такого перехода, пусть и далеко не самой важной, считается отказ Intel от Optane. 
Источник изображения: Oracle С момента запуска Exadata в 2008 году Oracle полагалась на процессоры Intel Xeon. Но ситуация начала меняться c выходом X9M в 2021 году. Для Oracle Exadata Machine и Oracle Exadata Cloud@Customer компания выбрала чипы Intel Xeon Ice Lake-SP, а в начале 2022 года для облачного решения Oracle Exadata Cloud Infrastructure решила использовать чипы AMD. При этом EPYC Milan использовались в серверах для обеспечения работы баз данных, а Ice Lake-SP — для СХД. Кроме того, на днях Oracle сделала важный шаг — перенесла свою флагманскую СУБД Oracle Database на архитектуру Arm, т.е. на процессоры компании Ampere Computing, в которую в своё время инвестировала. Эллисон отметил, что чипы Ampere Altra намного энергоэффективнее решений AMD и NVIDIA, что поможет ЦОД Oracle соответствовать будущим регуляциям. «Мы перешли на новую архитектуру и к новому поставщику, — сообщил Эллисон. — Мы думаем, что это будущее. Старая архитектура Intel x86 после многих десятилетий на рынке подошла к своему пределу». 
Источник изображения: Oracle Тем не менее, эксперты полагают, что ставка Oracle на архитектуру Arm не помешает её отношениям с AMD в ближайшее время, тем более что Intel и AMD планируют бороться с Arm-процессорами с помощью оптимизированных для облачных платформ чипов с высокой плотностью ядер и улучшенной энергоэффективностью: EPYC Bergamo и Xeon Sierra Forest. Кроме того, разработка, перенос и рефакторинг ПО для Arm требует времени и средств. В свою очередь, представитель Intel сообщил ресурсу CRN в четверг, что компания поставляет Oracle процессоры Xeon Sapphire Rapids «в течение многих месяцев и планирует продолжать поставки Xeon текущего и следующего поколения в будущем». Компании связывают долгие годы совместной работы над аппаратными и программными решениями для клиентов, а сейчас Intel поставляет чипы для облачной инфраструктуры Oracle OCI.
19.05.2023 [10:10], Сергей Карасёв
Ampere представила процессоры AmpereOne: до 192 ядер Arm, 8 каналов DDR5 и 128 линий PCIe 5.0Компания Ampere анонсировала процессоры серии AmpereOne, предназначенные для использования в серверах и оборудовании для дата-центров. Утверждается, что по сравнению с изделиями предыдущих поколений — Ampere Altra и Ampere Altra Max — новые чипы обеспечивают более высокие показатели производительности и энергоэффективности, а также обладают улучшенной масштабируемостью. Процессоры AmpereOne основаны на кастомизированных ядрах собственной разработки Ampere с набором инструкций Arm. Задействована чиплетная компоновка. Изготавливаются решения на предприятии TSMC на основе комбинации технологий с нормами 5 и 7 нм. 
Источник изображений: Ampere В семейство AmpereOne вошли пять моделей — со 136, 144, 160, 172 и 192 ядрами. Каждое ядро способно обрабатывать один поток инструкций. Объём кеша L2 составляет 2 Мбайт в расчёте на ядро; размер кеша L1 — 16 Кбайт для инструкций и 64 Кбайт для данных. Кроме того, есть 64 Мбайт системного кеша. Тактовая частота достигает 3,0 ГГц. 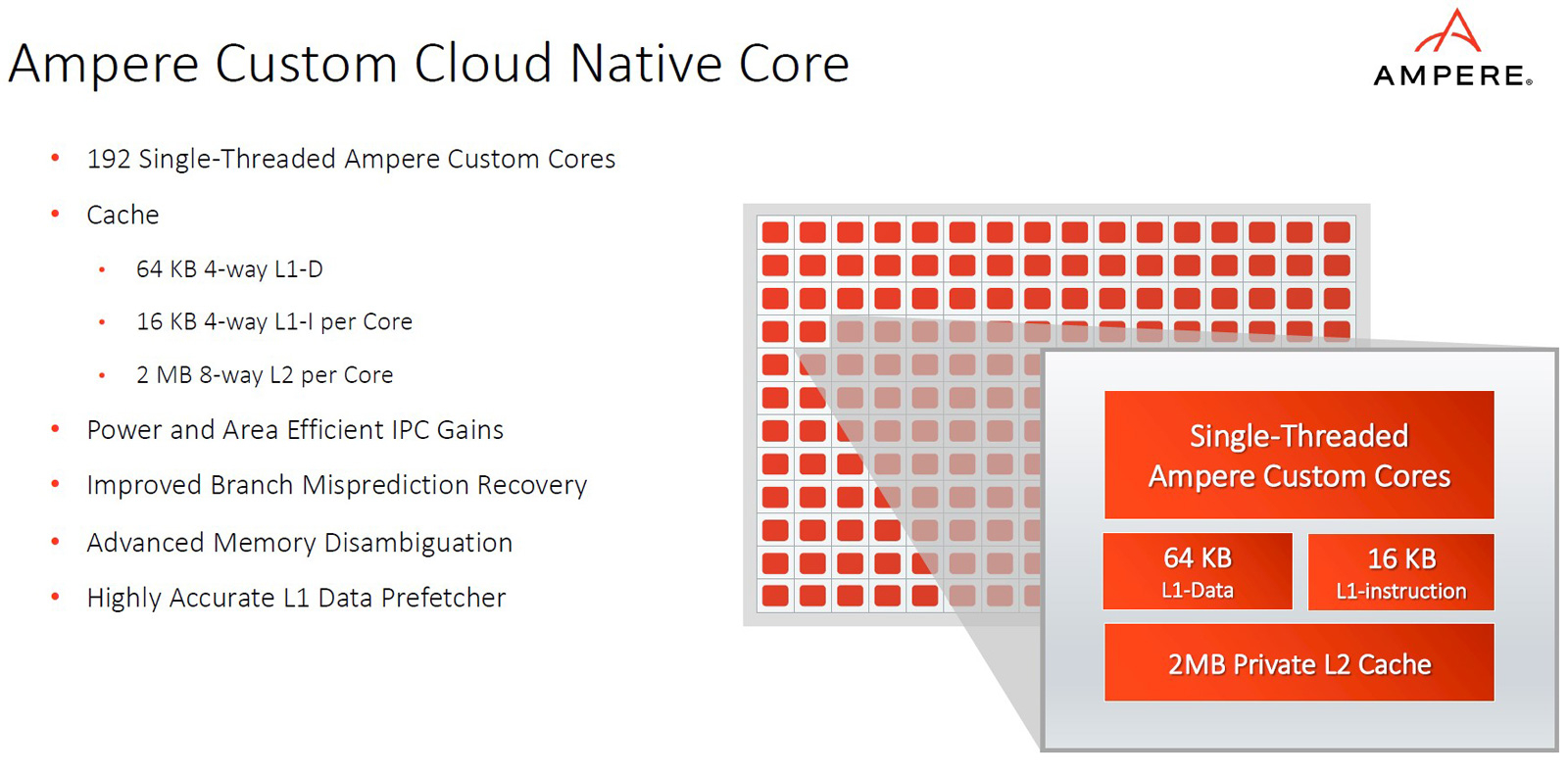
 Конструкция AmpereOne включает восемь каналов памяти DDR5 с поддержкой ECC: сервер может быть оборудован 16 слотами DIMM с возможностью использования до 8 Тбайт ОЗУ. Доступны 128 линий PCIe 5.0. Упомянута поддержка Armv8.6+ и SBSA 5. Чипы имеют исполнение FCLGA (5964-Pin).  Ampere отмечает, что процессоры AmpereOne ориентированы прежде всего на облачные платформы и среды виртуализации. Они обеспечивают высокую плотность вычислений и возможность формирования виртуальных машин, использующих от одного vCPU. Кроме того, достигается высокая производительность при ИИ-нагрузках (BF16). Заявленное энергопотребление AmpereOne составляет 1,8 Вт в расчёте на ядро, или от 200 до 350 Вт на сокет в зависимости от модификации решения. 
16.05.2023 [09:23], Сергей Карасёв
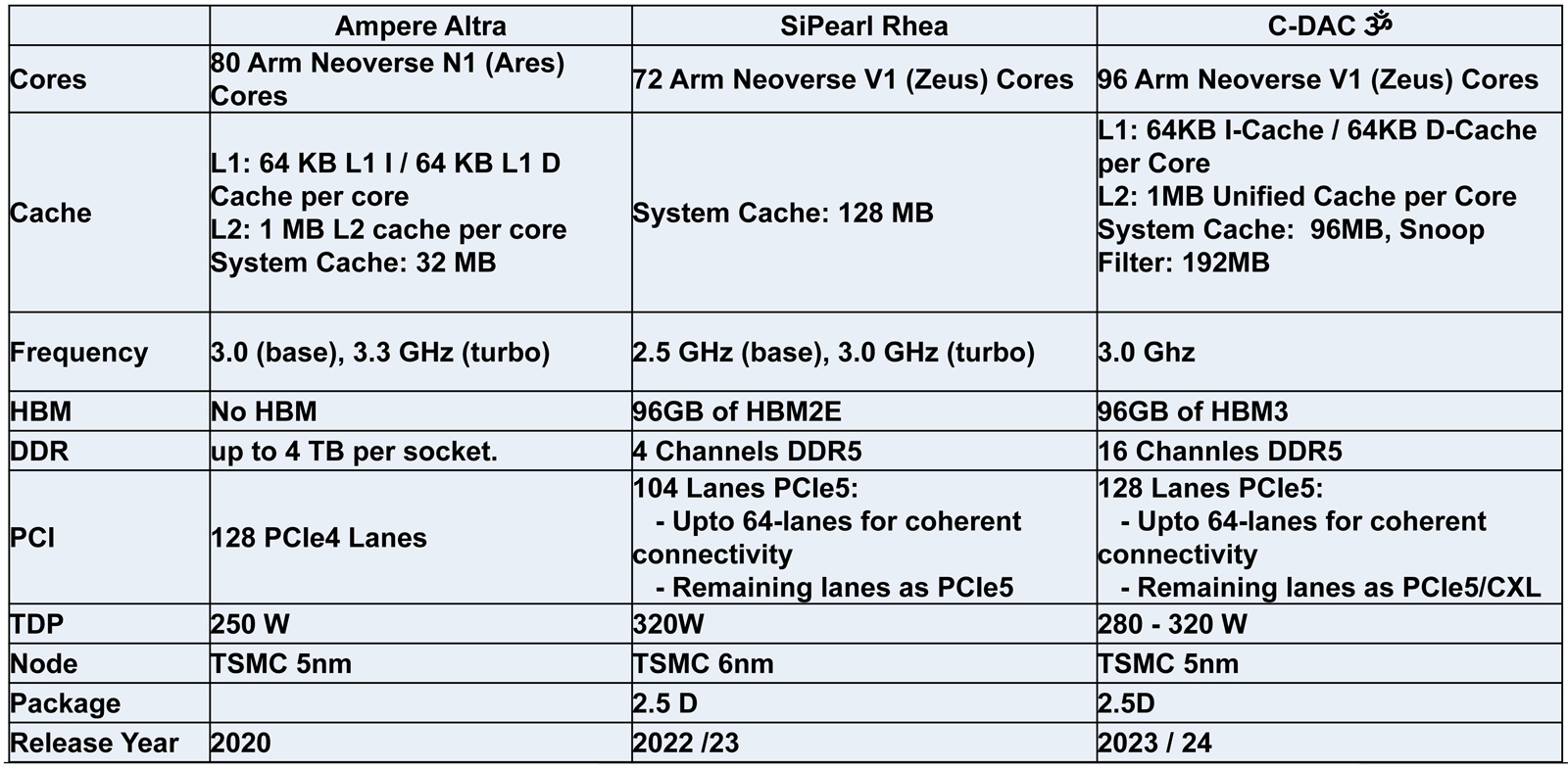
Индия представила свой первый серверный процессор AUM: 96 ядер и 96 Гбайт памяти HBM3Центр развития передовых вычислений (C-DAC) Департамента электроники и информационных технологий Министерства коммуникаций и информационных технологий Индии представил первый в стране процессор для серверов и НРС-систем. Изделие под названием AUM выйдет на коммерческий рынок в текущем или следующем году. Решение имеет чиплетную компоновку на базе двух модулей A48Z, каждый из которых насчитывает 48 вычислительных ядер Zeus с архитектурой Arm. Таким образом, суммарное количество ядер достигает 96. Тактовая частота составляет 3,0 ГГц (до 3,5 ГГц в турбо-режиме); показатель TDP варьируется от 280 до 320 Вт. 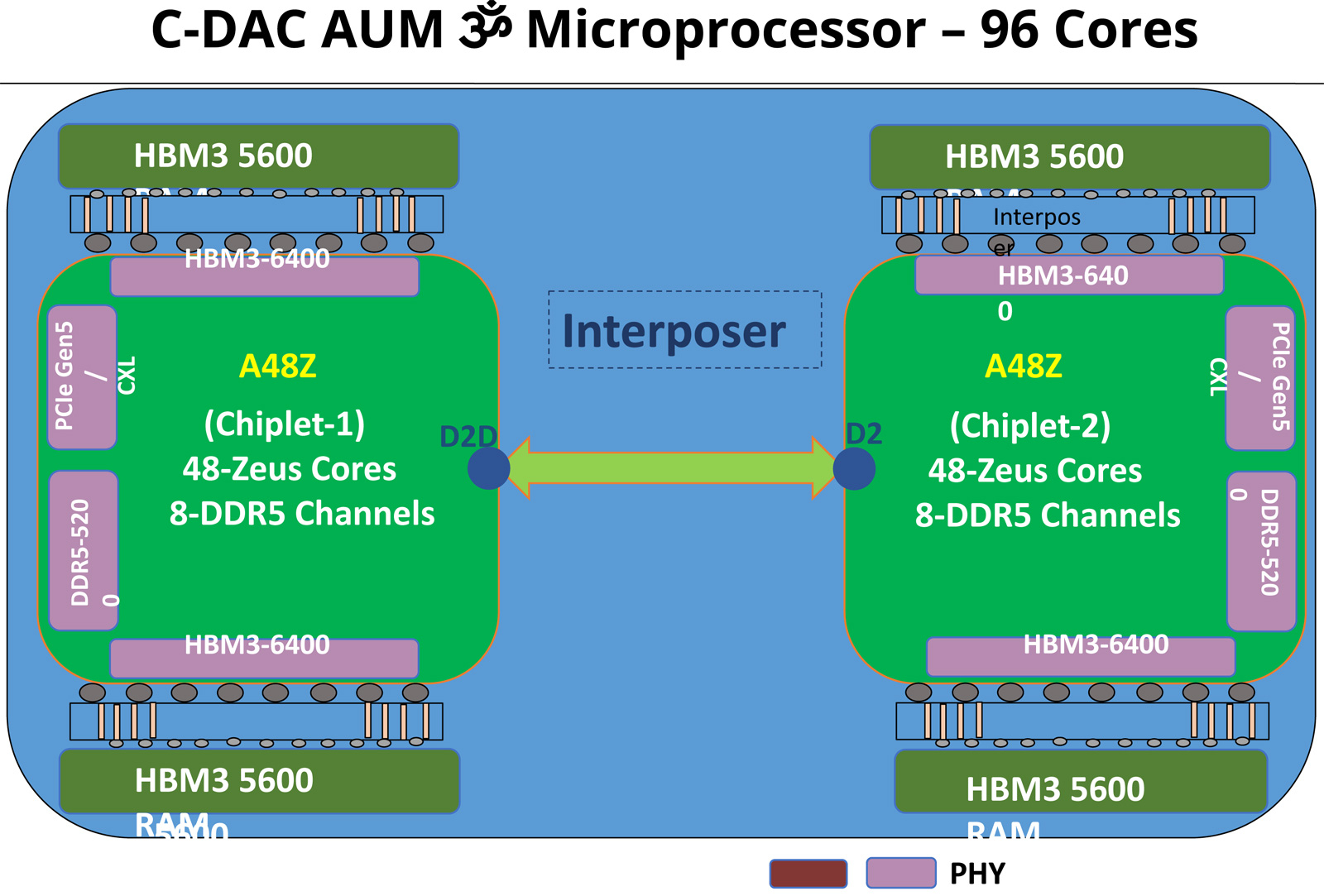
Источник изображений: C-DACC-DAC Новинка будет изготавливаться на предприятии TSMC по 5-нм технологии. Чип содержит 96 Мбайт кеша L2 и 96 Мбайт системного кеша. Изделие получило 96 Гбайт памяти HBM3 и 8-канальный контроллер DDR5-5200; кроме того, имеется доступ к 64 Гбайт памяти HBM3-5600. Таким образом, задействована трёхуровневая подсистема памяти. Упомянуты до 128 линий PCIe 5.0 с поддержкой CXL. 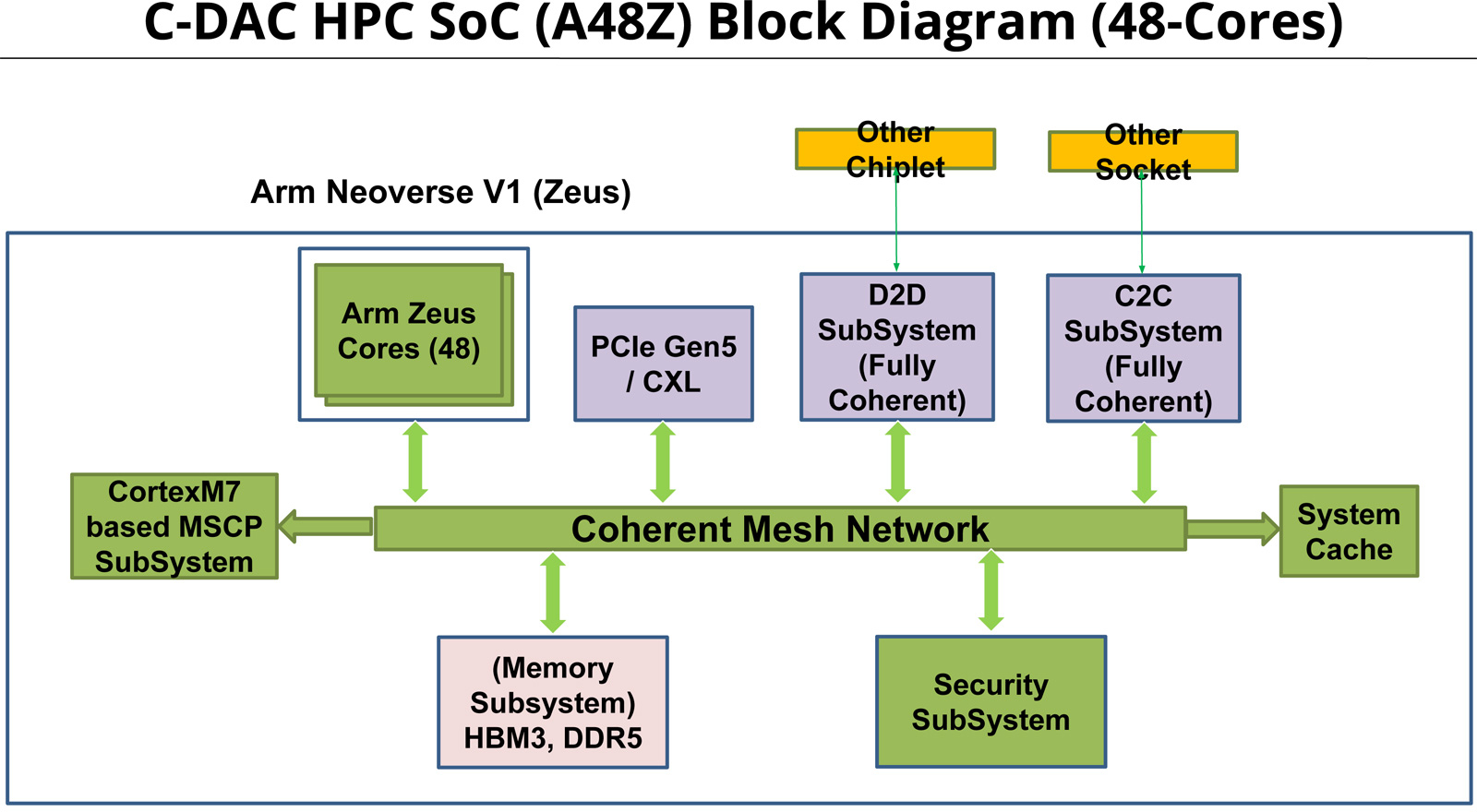 Процессор AUM может применяться в двухсокетных серверах. Заявленная производительность превышает 4,6 Тфлопс в расчёте на разъём. Реализованы различные средства обеспечения безопасности, в том числе функция Secure Boot и криптографические алгоритмы. 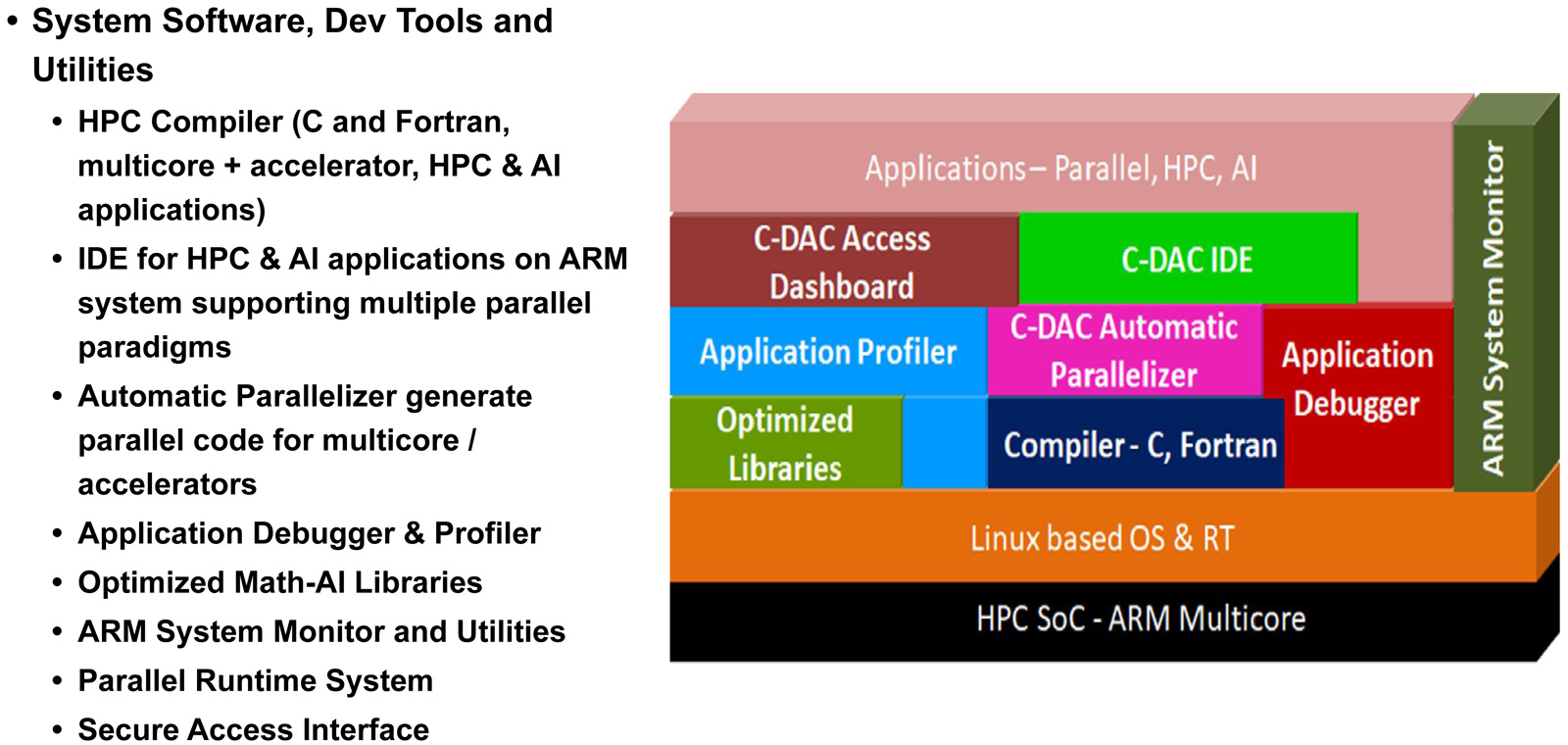
22.03.2023 [00:09], Алексей Степин
NVIDIA показала сдвоенный серверный суперпроцессор Grace SuperchipПроект NVIDIA Grace весьма амбициозен: компания всерьёз намерена ворваться с его помощью на рынок высокопроизводительных серверных процессоров, где всё ещё доминируют решения Intel и AMD. Об этом чипе было объявлено ещё на конференции GTC 2022, а на GTC 2023 глава компании, наконец, показал его вживую. В рамках продолжающегося роста плотности упаковки вычислительных мощностей в современных ЦОД на первый план выдвинулась не голая производительность, а соотношение производительности к уровню энергопотребления и тепловыделения. По сочетанию этих параметров x86 далеко не оптимальна, и тут у NVIDIA есть все шансы. С анонсом Grace Superchip NVIDIA провозглашает (впрочем, уже не в первый раз) смерть «закона Мура» — пришло время оптимизации и отказа от устаревших, по мнению компании, вычислительных архитектур. 
Источник изображений здесь и далее: NVIDIA Процессор NVIDIA Grace воплощает в себе все современные тенденции, начиная с отказа от монолитного кристалла. Сборка Grace Superchip состоит из двух кристаллов, каждый из которых включает в себя 72 ядра Arm Neoverse V2 (Arm v9), поддерживающих векторные расширения SVE2 и оптимизированные для ИИ форматы BF16/INT8. Кристаллы соединены между собой шиной NVLink-C2C, обеспечивающей пропускную способность 900 Гбайт/с.  В сборку интегрированы чипы памяти LPDDR5x общим объёмом до 960 Гбайт, причём каждый кристалл имеет свою шину доступа к памяти с производительностью 500 Гбайт/с. При этом с точки зрения ПО Grace Superchip представляется единым 144-ядерным процессором с ПСП на уровне 1 Тбайт/с. 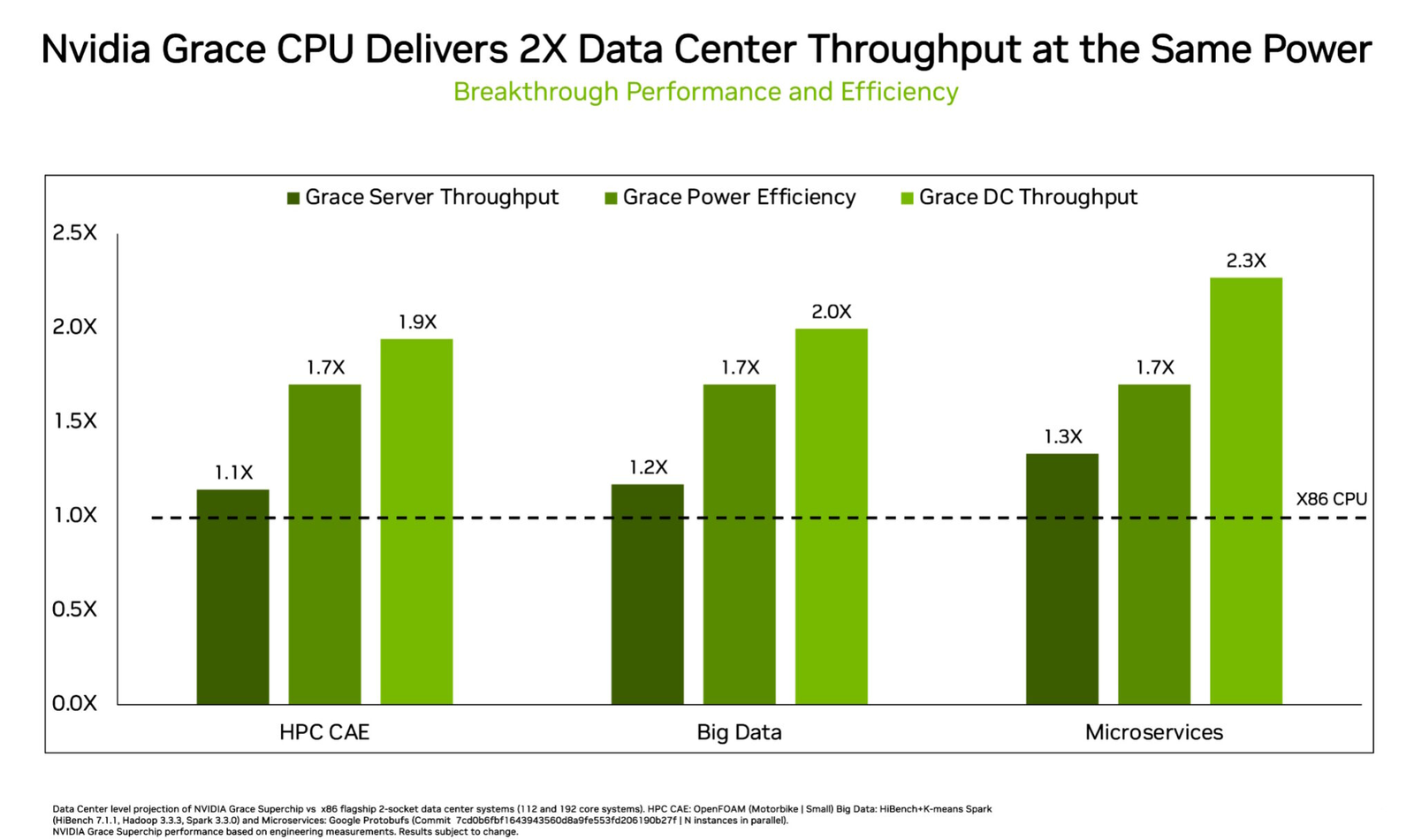 Для достижения схожих параметров в мире x86 требуется двухпроцессорная платформа AMD Genoa, куда более сложная технически и гораздо менее энергоэффективная, но при этом обладающая всеми недостатками NUMA-систем. Достаточно сравнить энергопотребление: 900 Вт против 500 у нового решения NVIDIA. 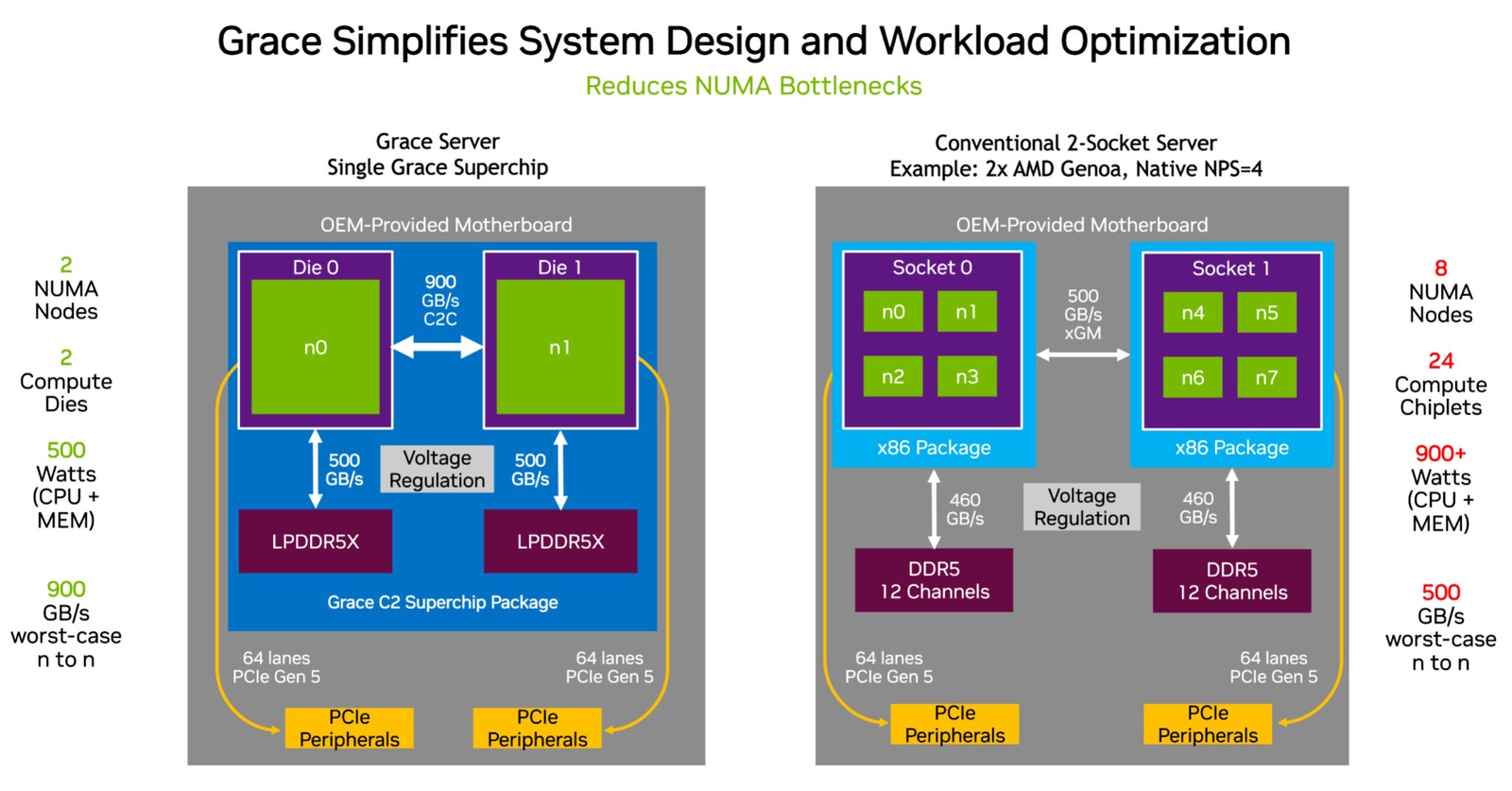 NVIDIA есть чем гордиться: при сопоставимом уровне энергопотребления Grace Superchip превосходит своих конкурентов из мира x86 в 2,3 раза при запуске микросервисов, вдвое опережает их в приложениях с интенсивным обменом данными с памятью и почти вдвое — в задачах симуляции вычислительной гидродинамики. В ряде других научно-технических задач преимущество может быть и более чем двукратным. 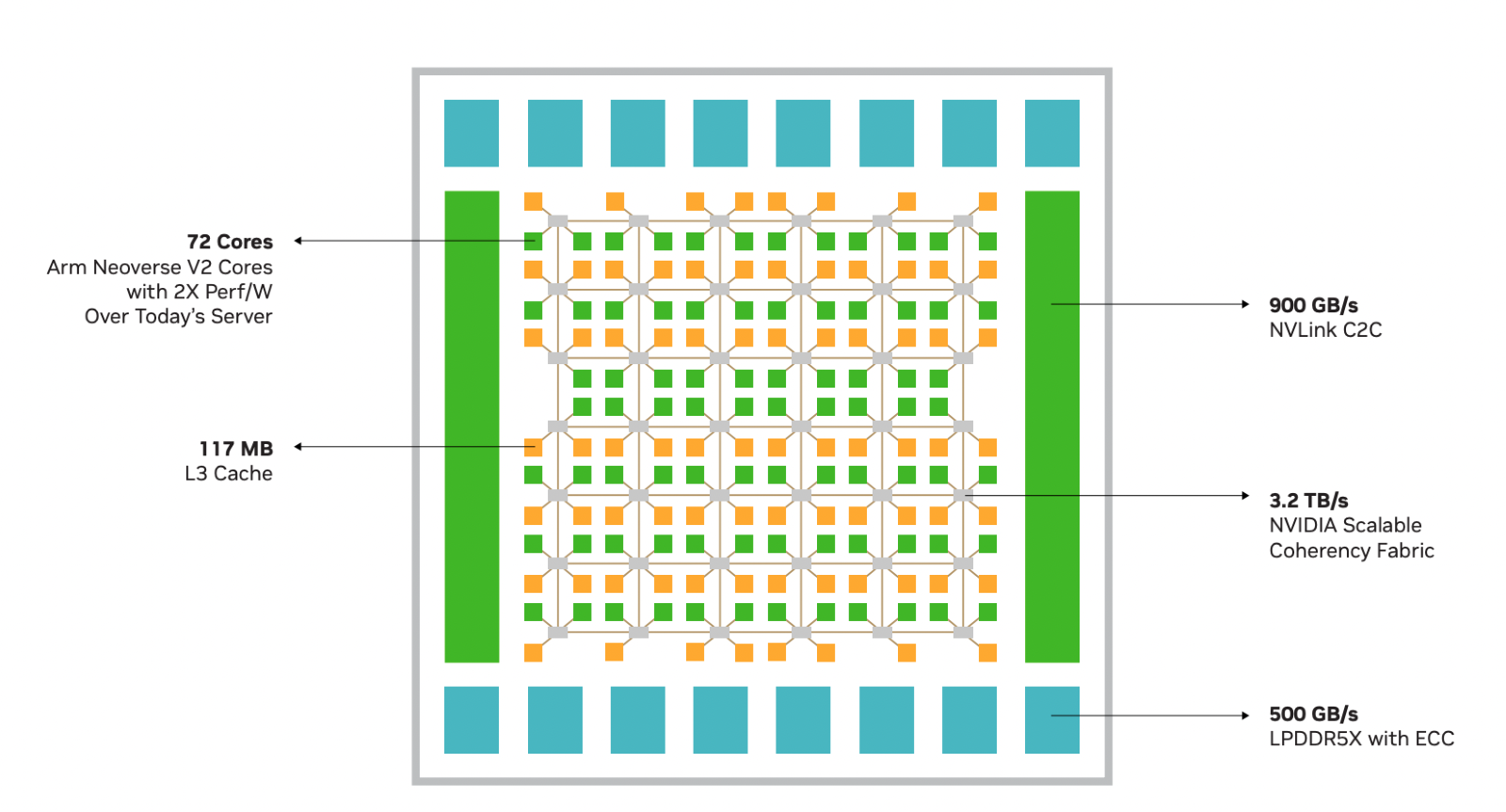 Это достигнуто в том числе благодаря изначальной оптимизации дизайна процессора с упором на максимальную производительность передачи данных. Внутренне Grace организован по принципу меш-сети с распределённой системой кеширования на базе специальных узлов коммутации CSN (Cache Switch Nodes). Называется эта сеть Scalable Coherency Fabric, она имеет пропускную способность 3,2 Тбайт/с, а объём кеша L3 составляет 117 Мбайт на кристалл и 234 Мбайт совокупно.  Сервер на базе NVIDIA Grace не только может потреблять меньше энергии, но и будет существенно проще конструктивно, поскольку модуль Grace Superchip содержит не только процессорные ядра и память, но также и регуляторы напряжения. От платформы на базе нового процессора требуется только PCIe 5.0 — у нового чипа есть два набора по 64 линии. Причём линии с поддержкой CXL 2.0, так что проблем с расширением доступного объёма памяти новинка испытывать не будет.  Даже компактные серверы высотой 1U смогут вместить две сборки Grace Superchip, что даст 288 ядер и почти 2 Тбайт оперативной памяти — труднодостижимый в таких габаритах показтель для более традиционных конструктивов процессоров и системных плат. Сравнительно невысокий теплопакет позволит таким решениям обходиться традиционным воздушным охлаждением.  При этом есть и вариант Grace Hopper, сочетающий в одном модуле кристалл Grace и новейший GPU H100, причём параметрами PCI Express последний ограничен не будет благодаря NVLink-C2C. NVIDIA уже начала первичные поставки Grace, а начало полномасштабного производства ожидается во второй половине года. Новыми процессорами заинтересовались крупные производители оборудования, включая ASUS, Atos, GIGABYTE, HPE, QCT, Supermicro, Wistron и ZT Systems.  Лос-Аламосская национальная лаборатория объявила, что использует NVIDIA Grace в новом суперкомпьютере Venado, который поможет учёным в исследованиях новых материалов и возобновляемых источников энергии. Ряд крупных европейских и азиатских ЦОД также рассматривает перспективы применения новых процессоров NVIDIA. В частности, одной из систем на базе Grace станет кластер Alps в Швейцарском национальном компьютерном центре.
20.01.2023 [15:28], Алексей Степин
NVIDIA Grace Superchip получит 144 Arm-ядра, 960 Гбайт набортной памяти LPDDR5x и 128 линий PCIe 5.0, а TDP составит 500 ВтGrace можно назвать одним из самых амбициозных проектов NVIDIA. О намерении ворваться на рынок мощных серверных процессоров компания объявила ещё на GTC 2022, но до недавних пор о чипах Grace были доступны лишь общие сведения. Однако ситуация меняется. NVIDIA явно располагает рабочим «кремнием», и на днях опубликовала пару деталей о Grace Superchip. Ожидается, что официальный анонс новинки состоится в марте этого года на GTC 2023. Эта сборка включает в себя два 72-ядерных кристалла Grace, использующих ядра Arm Neoverse V2. Данное ядро использует набор инструкций Armv9, а также имеет четыре 128-битных блока векторных расширений SVE2, блоки для работы с матрицами и поддержку BF16/INT8. Объём кеша L1 составляет по 64 Кбайт для инструкций и данных, L2 — 1 Мбайт на ядро, а общий объём L3 на сборку достигает 234 Мбайт. 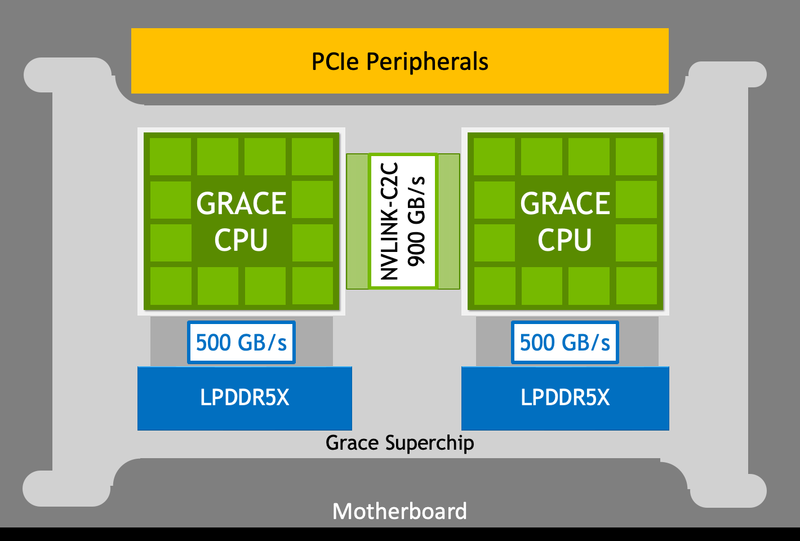
Блок-схема сборки Grace Superchip. Источник изображений здесь и далее: NVIDIA Между собой кристаллы соединены шиной NVLink C2C с пропускной способность 900 Гбайт/с, и работают они как единый 144-ядерный процессор. Но это ещё не всё: каждый из кристаллов соединен со своим банком памяти LPDDR5x ECC шиной с пропускной способностью 500 Гбайт/с (т.е. суммарно на чип получается 1 Тбайт/с). Совокупный объём памяти может достигать 960 Гбайт. 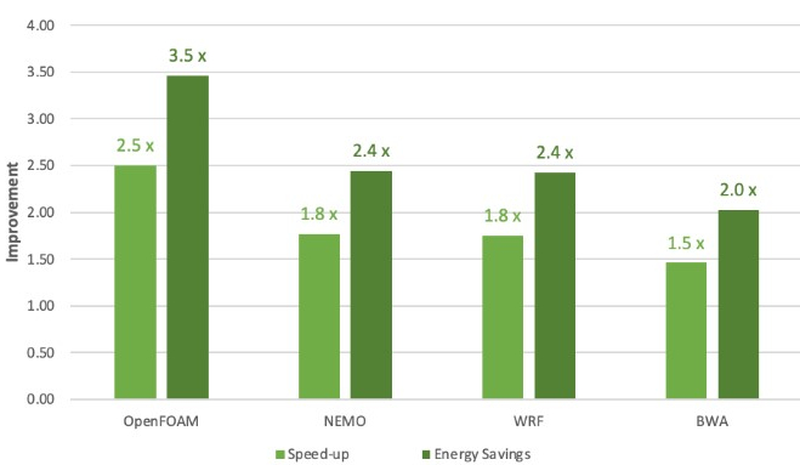
Сравнение производительности и энергоэффективности Grace Superchip с двумя AMD EPYC 7763 (Milan) Сборка Grace Superchip общается с внешним миром посредством восьми комплексов PCIe 5.0 x16 (всего 128 линий, поддерживается бифуркация). Чип при теплопакете 500 Вт (вместе с набортной памятью) способен развивать 7,1 Тфлопс на вычислениях двойной точности. С учетом интегрированной памяти это делает Grace Superchip интересной альтернативой AMD Genoa. 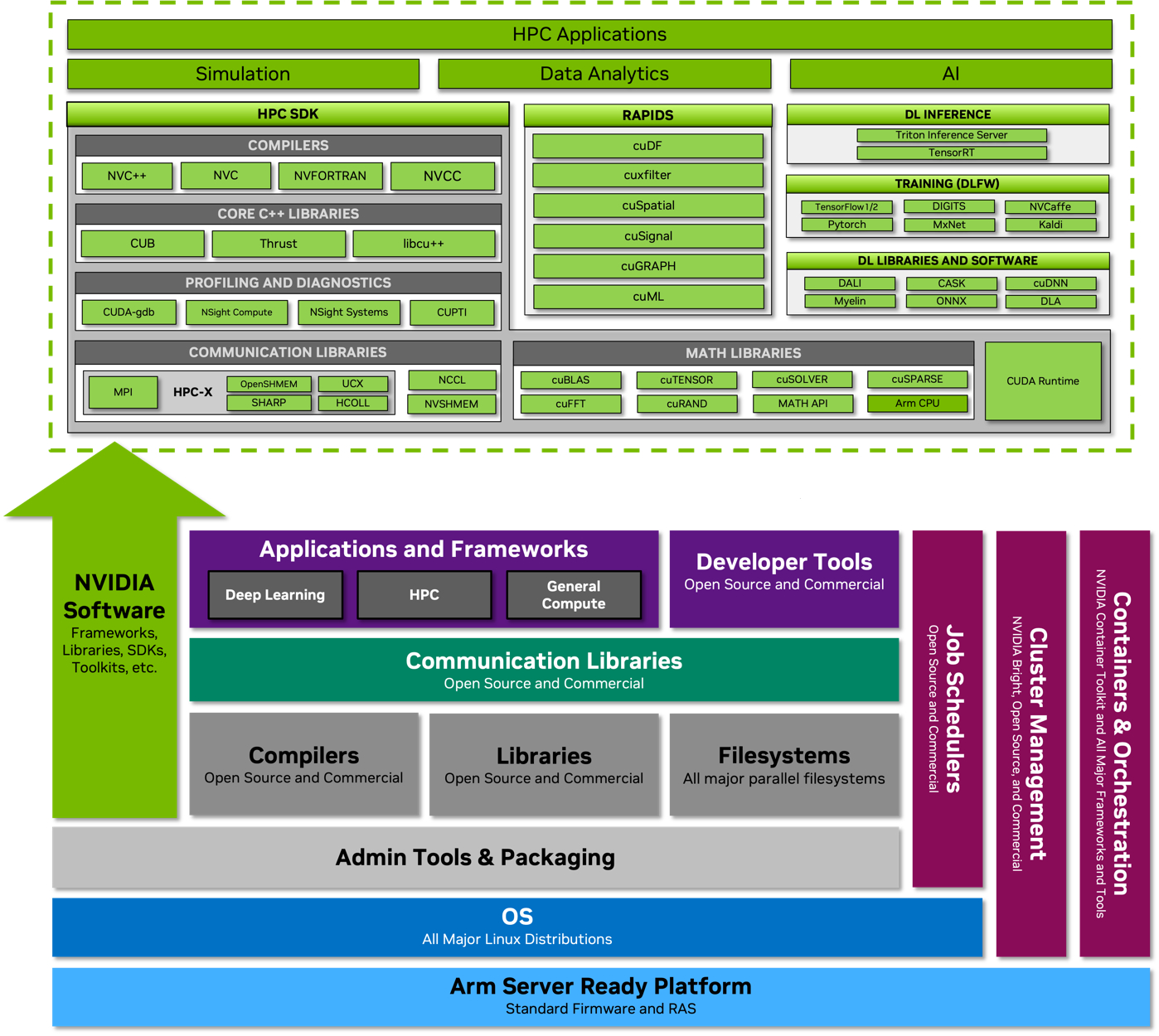
Программная экосистема платформы NVIDIA Grace. По клику открывается полноразмерная версия. Помимо данных о производительности в режиме FP64 компания уже опубликовала результаты тестов новинки в HPC-нагрузках, где сравнила своё детище с двухсокетной системой на базе AMD EPYC 7763. Выигрыш в производительности составляет от 1,5x до 2,5x, но что не менее важно — Grace Superchip намного эффективнее энергетически, здесь преимущество может достигать 3,5x. В условиях высокоплотных ЦОД или HPC-кластеров это может стать решающим. |
|