Материалы по тегу: сбой
|
05.02.2025 [09:10], Руслан Авдеев
Великобритания не может определить объём компенсаций за сбои в ПО Horizon, из-за которых неправомерно осудили сотни людейНациональное контрольно-ревизионное управление Великобритании (NAO) объявило, что Департамент предпринимательства и торговли (DBT) располагает недостаточным объёмом данных, чтобы оценить расходы на компенсацию ущерба гражданам, вовлечённым в скандал со сбойным ПО Horizon, из-за которого пострадали сотрудники Королевской почты, сообщает Computer Weekly. Из-за неверных расчётов ПО Horizon с 1999 года были несправедливо обвинены в махинациях сотни, если не тысячи сотрудников почтовых отделений, а некоторые из них получили не только штрафы, но и реальные тюремные сроки. Пострадавших обвиняли в недостачах и фальсификации бухгалтерской отчётности, на самом деле вызванных ошибками в ПО, предоставленном Fujitsu. Около 900 человек привлекли к ответственности (ранее сообщалось о более 700), а тысячи вынуждены были оплачивать несуществующие недостачи из своего кармана. В прошлом году после официального оправдания почти тысячи бывших руководителей и сотрудников почтовых отделений, ошибочно привлечённых к ответственности, была запущена программы компенсации ущерба Horizon Shortfalls Scheme (HSS). Однако в NAO считают, что выделенные правительством страны средства для покрытия расходов на HSS (£672 млн) и на программу возмещения ущерба осуждённым (£699 млн) не соответствуют реальным расходам. Более того, по данным NAO, расходы департамента уже превысили допустимый годовой лимит на £208 млн именно из-за подготовки к компенсациям. 
Источник изображения: engin akyurt/unsplash.com В NAO заявили, что Почта лишь недавно начала рассылку информации потенциальным жертвам скандала и пока не удалось получить достаточных свидетельств, касающихся вероятного объёма компенсаций, поскольку даже «небольшие и разумные изменения» в предположениях о количестве заявок и размере выплат могут привести к весьма существенному изменению суммы выделенных из бюджета средств. Тем не менее, утверждается, что власти по-прежнему полны решимости обеспечить всем пострадавшим финансовую компенсацию. Система Horizon оказалась центре внимания в 2018 году, когда группа из 555 бывших сотрудников почтовых отделений выступила с иском против Почты Великобритании, чтобы доказать, что именно ошибки в ПО вызвали несоответствия в бухгалтерской отчётности — предполагается, что это крупнейшая судебная ошибка в истории Великобритании, буквально сломавшая жизнь тысячам человек. При этом Fujitsu заявляет, что десятилетиями сообщала о проблемах, которые просто игнорировались ответственными лицами. Почта же утверждает, что ничего не знала об ошибках и вообще зависела в техническом плане от японской компании. Правительству предстоят и расходы, связанные с некорректной работой системы Capture, работавшей до Horizon в 1990-х годах. Выяснилось, что она тоже была причиной недостач, так что теперь Комиссия по пересмотру уголовных дел (Criminal Cases Review Commission) изучает обвинительные приговоры, связанные с этим ПО. Для пострадавших DBT готовит схему компенсаций, аналогичную той, что предусмотрена для жертв Horizon.
04.02.2025 [15:46], Руслан Авдеев
Смешались в кучу базы, люди: в Австралии обнаружились «цифровые двойники» гражданУполномоченная по конфиденциальности данных в Австралии Карли Кайнд (Karly Kind) сообщила, что одно из местных правительственных ведомств не приняло достаточных мер для защиты от «цифровых двойников». Речь идёт о людях, имеющих одинаковые имена и фамилии и даты рождения — их данные в правительственных базах иногда буквально перепутаны, сообщает The Register. Кайнд недавно назначила компенсацию в размере AU$10 тыс. ($6,1 тыс.) пострадавшему гражданину, чьи записи в системе здравоохранения «смешались» с информацией о других гражданах с аналогичными именами, фамилиями и датами рождения. В основном такие ситуации возникают в случаях, когда сотрудники, имеющие доступ к базам, вносят информацию в неверный аккаунт, либо сторонний подрядчик подаёт неверную информацию о клиенте. В данном случае пострадавший пожаловался, что в результате четырёх ошибок государственных служащих в его медицинских записях оказалась информация о трёх разных людях с одинаковыми именами, фамилиями и датами рождения. Выяснилось это после того, как австралийская система медицинского страхования Medicare сообщила пострадавшему, что он близок к лимиту по выплатам и скоро за страховку ему придётся платить больше обычного. Оказалось, что часть походов к врачам его «цифровых двойников» записали на счёт пострадавшего. 
Источник изображения: Ralph Mayhew/unsplash.com Пострадавший подал жалобу ещё в 2019 году, а компенсацию ему присудили именно из-за ошибок со стороны государственных ведомств, не потрудившихся их избежать. С тех пор связанные с проблемой правительственные ведомства приняли меры для устранения путаницы и возможностей неавторизованного доступа к данным, однако, признаётся Кайнд, никакие технические решения не позволят избавиться от банальных человеческих ошибок. По словам Кайнд, сотни австралийцев имеют одинаковые данные и их учётные записи в правительственных базах часто «смешиваются», в результате чего возникают не просто неудобства, а наносится реальный вред. Например, медицинские работники в случае ошибки не могут получить доступ к корректным данным. Могут возникнуть и трудности в финансовых аспектах здравоохранения или проблемы с правительственными службами. Хотя пострадать от этого может лишь небольшой процент австралийцев, потенциальный вред считается значительным.
28.01.2025 [01:31], Владимир Мироненко
Брандмауэры Zyxel USG FLEX и ATP ушли в бесконечную перезагрузку после некорректного обновления сигнатурКак сообщает The Register, тайваньская компания Zyxel предупредила пользователей о том, что некорректное обновление сигнатур, проведённое в ночь с 25-го на 26-е января, вызвало критические ошибки в работе брандмауэров USG FLEX и ATP Series, включая уход устройства в бесконечный цикл перезагрузки. «Мы обнаружили проблему, влияющую на некоторые устройства, которая может вызывать циклы перезагрузки, сбои демона ZySH или проблемы с доступом ко входу, — сообщается в бюллетене Zyxel. — Системный светодиод также может мигать. Обращаем внимание — это не связано с CVE или проблемой безопасности». Zyxel утверждает, что проблема коснулась только брандмауэров USG FLEX и ATP Series (версии прошивки ZLD) с активными лицензиями безопасности. Устройства на платформе Nebula или серии USG FLEX H (uOS) не пострадали. «Проблема возникает из-за сбоя обновления Application Signature Update, а не обновления прошивки. Чтобы решить эту проблему, мы отключили сигнатуры на наших серверах, предотвратив дальнейшее воздействие на брандмауэры, которые не загрузили новые версии сигнатур», — сообщила Zyxel. 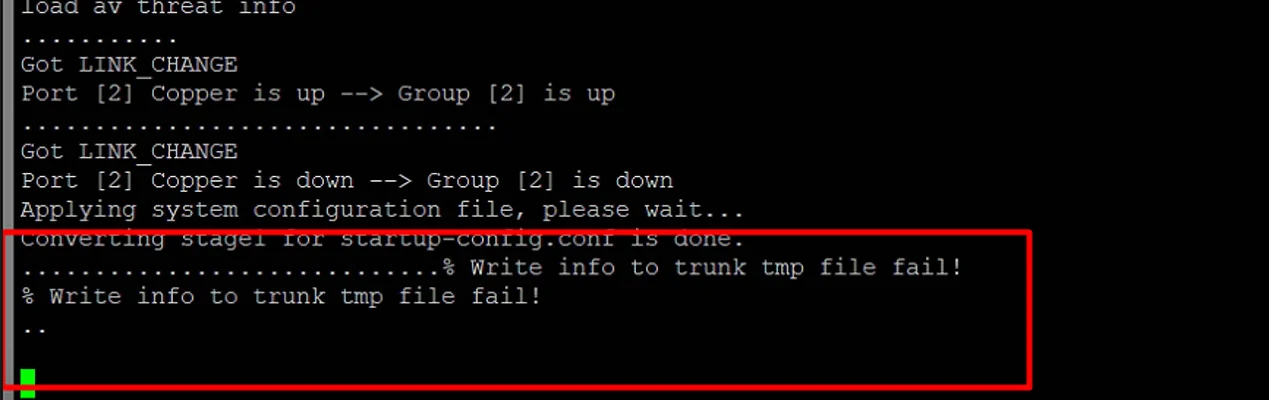
Источник изображения: Zyxel Помимо ухода в цикл перезагрузки, некоторые пользователи после проведения обновления сталкиваются с такими проблемами, как невозможность ввода команд в консоли, необычно высокая загрузка CPU и поступление сообщений о том, что «демон ZySH занят», о формировании дампа памяти (core dump) и т.д. Zyxel сообщила, что вариантов исправления проблемы в удалённом режиме нет. Для этого надо иметь физический доступ к брандмауэру и подключиться к консольному порту. Zyxel подробно описала в отдельном руководстве шаги по восстановлению таким способом, включая создание резервной копии перед установкой новой прошивки. Компания предупредила, что тем, у кого системы работают в режиме Device-HA, следует напрямую обращаться в службу поддержки Zyxel за индивидуальной помощью.
27.01.2025 [12:39], Руслан Авдеев
Латвия и Швеция расследуют повреждение очередного кабеля в Балтийском море, арестовано судно, следовавшее из российской Усть-ЛугиВ последнее время инциденты с кабельной инфраструктурой в Балтийском море происходят почти регулярно. Очередное происшествие зарегистрировано в воскресенье утром — уже третье за последние три месяца, сообщает Bloomberg. Как сообщает шведский сайт Expressen, судно Vezhen (зарегистрировано на Мальте), предположительно участвовавшее в инциденте, арестовано в шведских территориальных водах. На борту находятся представители шведских властей. По данным издания, пострадал подводный кабель между латвийским городом Вентспилс (Ventspils) и островом Готландом (Швеция). Клиенты не остались без связи, а для передачи данных используются обходные маршруты, доложил латвийский телеком-провайдер State Radio and Television Center (LVRTC). Уже начато уголовное расследование, в котором участвуют власти других стран НАТО. По имеющимся данным, повреждена часть кабеля, находящаяся в исключительной экономической зоне Швеции. По информации LVRTC, есть основания полагать, что кабель получил серьёзные повреждения. Поскольку он проложен на глубине около 50 м, оценить его состояние можно будет только при ремонте. 
Источник изображения: Shaah Shahidh/unsplash.com В ноябре 2024 года китайское судно обвинили в обрыве двух подводных телеком-кабелей в Балтийском море, а в декабре того же года случился обрыв энергокабеля и четырёх телекоммуникационных кабелей. Страны НАТО занялись организацией защиты кабельной инфраструктуры в регионе в рамках инициативы Baltic Sentry и других проектов. Так, в декабре появилась информация о тестировании плавучих беспилотников для патрулирования территориальных вод стран блока, в начале января НАТО анонсировала программу Baltic Sentry по защите кабелей, а Швеция выделила три корабля и самолёт для патрулирования. Наконец, буквально на днях Германия объявила о запуске в Балтийском море подводного патрульного беспилотника израильского производства. Впрочем, умысел в повреждении кабельной инфраструктуры можно подвергнуть сомнению. Не так давно сообщалось, что спецслужбы не выявили намеренных действий одного из кораблей в ходе недавнего инцидента — виной всему, вероятно, просто низкая квалификация экипажа.
26.01.2025 [22:28], Владимир Мироненко
Великобритания изучает возможности защиты подводных кабелей от диверсийОбъединённый комитет по стратегии национальной безопасности (JCNSS) парламента Соединённого Королевства начал исследование возможностей Великобритании обеспечить защиту подводных интернет-кабелей, связывающих страну с остальным миром. Мотивом названа возросшая угроза диверсионной деятельности со стороны России, Китая и других «враждебных» государств, пишет ComputerWeekly. Комитет, контролирующий принятие правительством решений по национальной безопасности, поставил задачу оценить готовность Великобритании к потенциальным атакам на критически важные подводные коммуникационные кабели. Работа началась после заявления министра обороны Джона Хили (John Healey) о том, что Россия нацелилась на подводную инфраструктуру и интернет-кабели Великобритании после того, как российский «шпионский» корабль вошёл в британские воды. Шпионским кораблём министр назвал исследовательское судно «Янтарь», обнаруженное в территориальных водах Великобритании 20 января 2025 года. По словам британского чиновника, российское исследовательское судно занималось «сбором разведданных и картографированием критически важной подводной инфраструктуры Великобритании». Председатель парламентского комитета Мэтт Вестерн (Matt Western) отметил, что 99 % данных страны проходят по подводным интернет-кабелям (для острова это естественно), что делает их легкой целью для иностранных государств, стремящихся тайно нанести ущерб Великобритании. 
Источник изображения: Marcus Woodbridge / Unsplash Глобальная сеть насчитывает около 500 кабелей, по которым проходит 95 % всего интернет-трафика. Кабели зачастую проложены в отдалённых местах, что затрудняет их мониторинг и ведёт к удорожанию его стоимости. Великобританию с другими странами связывают около 60 кабелей, так что повреждение одного-двух кабелей особых проблем не вызовет. Однако одновременное повреждение нескольких кабелей в результате диверсии может привести к значительным сбоям связи. Согласно Национальному реестру рисков Великобритании 2025 года (National Risk Register 2025), при разумно наихудшем сценарии потеря трансатлантических кабельным систем, соединяющих Великобританию с остальным миром, приведёт к «значительному сбою» в работе основных служб страны, включая финансовый сектор, который зависят от зарубежных ЦОД и поставщиков услуг. За последнее время в прибрежных водах стран Северной Европы произошло несколько инцидентов, в результате которых были повреждены кабели. В частности, в конце 2024 года из-за кораблей сначала пострадала пара интернет-кабелей, а позднее — электрический кабель и ещё четыре телеком-кабеля. Впрочем, причиной обрывов названа низкая квалификация экипажей судов, а не диверсия. В январе 2025 года Великобритания вместе с союзниками объявила о начале операции Nordic Warden для отслеживания потенциальных угроз подводной инфраструктуре и мониторинга деятельности «теневого» флота России. В рамках операции будет использоваться ИИ для анализа данных из различных источников, включая автоматическую идентификационную систему, используемую судами для передачи своего местоположения, для оценки рисков, представляемых судами в районах нахождения подводных кабелей.
23.01.2025 [15:13], Руслан Авдеев
Не Китай: Тайвань назвал «естественный износ» причиной последних отключений подводных интернет-кабелейВ Министерстве цифровых технологий Тайваня обнародовали причину отключений двух подводных интернет-кабелей, ведущих к островам Мацзу (Mazu), которые были оборваны утром 22 января. По официальным данным, в этом виновен «естественный износ», сообщает Reuters. С начала года произошли уже четыре сбоя в работе подводной интернет-инфраструктуры острова, тогда как за предыдущие два года было зарегистрировано всего три инцидента. Острова Мацзу с населением около 14 тыс. человек находятся недалеко от побережья материкового Китая, и для обеспечения их интернет-доступом пришлось активировать резервные коммуникации, в том числе беспроводные. Похожий инцидент произошёл в начале января, но тогда тайваньские власти возложили ответственность на Китай. В данном же случае никаких подозрительных судов на момент потери связи рядом с кабелем замечено не было. Ожидается, что работу кабелей восстановят к концу следующего месяца. 
Источник изображения: Thomas Tucker/unsplash.com В 2023 году китайское судно обвинили в повреждении цифровой подводной магистрали Taiwan-Matsu No. 2. В начале января 2025 года были оборваны четыре оптоволокна управляемого тайваньской Chunghwa Telecom кабеля у побережья Тайваня. Предполагается, что кабель повредило зарегистрированное в Камеруне судно Shunxin 39, шедшее из тайваньского порта Цзилун (Keelung) в Южную Корею. В ноябре 2024 года китайское судно Yi Peng 3 заподозрили в намеренном повреждении кабелей C-Lion1 и BCS East-West в балтийском море. В конце декабря того же года судно Eagle S повредило в Балтике несколько интернет-кабелей и один силовой. Причиной инцидента названа низкая квалификация экипажа. Тем не менее, страны НАТО заявили о новой оборонной инициативе в Балтийском море для защиты подводной инфраструктуры. Швеция уже выделила для этого три корабля и самолёт, а Германия запустила в море подводный патрульный беспилотник.
21.01.2025 [13:05], Руслан Авдеев
Спецслужбы США и ЕС: причиной обрывов кабелей в Балтийском море стали не диверсии, а низкая квалификация экипажейОбрывы подводных кабелей в Балтийском море оказались неприятными случайностями, а не результатами диверсий. Если ранее некоторые западные политики подозревали во всём Россию, то теперь представители спецслужб США и Евросоюза пришли к иным выводам, сообщает The Washington Post. Издание ссылается на высокопоставленные источники в американских и европейских спецслужбах. По словам сохранивших анонимность представителей трёх стран, участвующих в расследованиях, изучение обстоятельств серии инцидентов, которые привели к критическим повреждениям энергетических и коммуникационных подводных линий, всё ещё продолжается. В своё время некоторые политики поспешили обвинить Россию в гибридных атаках на инфраструктуру. Тем не менее, по данным источников, специалисты из США и полудюжины европейских стран, участвующих в расследовании, не нашли свидетельств того, что коммерческие суда, протащившие якоря, сделали это намеренно. 
Источник изображения: Dorian Mongel/unsplash.com Анализ переговоров и собранные улики говорят, что в инцидентах виновны неопытные команды, обслуживавшие находящиеся в неудовлетворительном состоянии суда. По данным источников из США, имеются «ясные свидетельства» того, что повреждения в каждом случае, похоже, были случайными. Представители ЕС согласились с выводами американцев. Тем не менее, силы НАТО усилили патрулирование в Балтийском море, а Швеция выделила на эти нужды три судна и самолёт. Расследования в первую очередь связаны с тремя инцидентами, произошедшими в Балтийском море за последние 18 месяцев, в которых сыграли роль корабли, путешествовавшие либо в российские порты, либо из них. Подозревалось, что они повредили инфраструктуру, передававшую газ, электричество или интернет-трафик на севере Европы. В последнем из случаев Финляндия арестовала нефтяной танкер, подозревавшийся в повреждении энергетического кабеля, связывавшего страну с Эстонией, а также трёх интернет-кабелей. До этого в поле зрения спецслужб попадал зарегистрированный в Гонконге контейнеровоз Newnew Polar Bear, повредивший газопровод в Финском заливе в октябре 2023 года, а также китайский корабль Yi Peng 3, оборвавший два телекоммуникационных кабеля в ноябре прошлого года.
27.12.2024 [15:00], Руслан Авдеев
В Балтийском море порваны сразу четыре интернет-кабеля и один силовойФинские власти сообщили о высадке на нефтяной танкер, подозреваемый в умышленных обрывах нескольких кабелей в Балтийском море. 25 декабря от якоря корабля Eagle S пострадал 658-МВт подводный HVDC-кабель Estlink 2 между Финляндией и Эстонией, сообщает Datacenter Dynamics. Почти в то же время были оборваны три интернет-кабеля, связывающие две страны. Два из них принадлежат финскому оператору Elisa, а третий — китайской Citic. Кроме того, был повреждён интернет-кабель Cinia между Финляндией и Германией. Финское транспортное и коммуникационное агентство Traficom объявило, что проблемы с кабелями могут вызвать перебои со связью у клиентов. Сейчас регулятор расследует последствия инцидентов, взаимодействуя с операторами. О расследовании сообщала и финская полиция. По данным финского Национального бюро расследований (NBI), следствие рассматривает инцидент, как преступное причинение ущерба при отягчающих обстоятельствах. Местная таможенная служба ведёт предварительное расследование на борту и выясняет детали, касающиеся груза. Утверждается, что кабель Estlink 2 на 658 МВт был оборван именно в том время, когда над ним проходил нефтяной танкер Eagle S, шедший из Санкт-Петербурга (Россия) в Порт-Саид (Египет). По данным финских властей, полиция Хельсинки и местная береговая охрана провели на нём «тактическую операцию». Власти приняли меры для расследования происшествия с судном, доступ им на борт обеспечили береговая охрана и финские военные вертолёты. 
Источник изображения: Finnish Border Guard Сообщается, что ремонт силового кабеля начнётся в конце недели, но расписание, помимо прочего, зависит от погодных условий и прочих факторов. Также сообщается, что инцидент не повлиял на безопасность снабжения Финляндии и она защищена от сбоев в электроснабжении и телеком-секторе. Инцидент произошёл всего через месяц после того, как другой корабль подозревался в намеренном повреждении якорем двух ВОЛС на дне Балтийского моря. Тогда на корабль высадился датский военный десант, расследование всё ещё продолжается. Не так давно пострадала и наземная кабельная инфраструктура, связывающая Швецию и Финляндию. Финский премьер-министр Петтери Орпо (Petteri Orpo) в свете последних событий подчеркнул опасность «теневого флота» в Балтийском море.
25.12.2024 [16:50], Руслан Авдеев
От дна океана до космоса: проект НАТО HEIST занялся созданием резервного космического интернетаВ начале февраля 2024 года ракета поразила судно Rubymar в Красном море. Повреждённое судно тонуло неделями, на 70 км протащив за собой якорь, разорвавший три интернет-кабеля, на которые приходилось четверть интернет-трафика между Европой и Азией. На ремонт кабелей ушли месяцы. Теперь в рамках проекта HEIST в НАТО начали тестировать систему перенаправления трафика через околоземное пространство, сообщает IEEE Spectrum. На подводные волоконно-оптические линии связи приходится более 95 % межконтинентального интернет-трафика. Общая протяжённость 500-500 кабелей, проложенных по дну, составляет 1,2 млн км. По некоторым оценкам, ВОЛС обеспечивают финансовые транзакции более чем на $10 трлн ежедневно. Сами кабели находятся глубоко, они довольно тонкие и, по сути, не имеют никакой защиты на глубине. Если значительный ущерб может нанести повреждение одного или нескольких кабелей, то настоящая катастрофа для владельцев и пользователей может произойти, если атака произойдёт на государственном уровне. 
Источник изображения: HEIST Поэтому НАТО запустила пилотный проект HEIST (hybrid space-submarine architecture ensuring infosec of telecommunications). HEIST должен помочь в быстром определении точного местоположения повреждённого участка кабеля. Кроме того, проект направлен на создание «обходных путей» передачи данных в случае обрыва. В числе прочего предусматривается и передача информации через спутники на орбите. В 2025 году планируется начать испытания на южном побережье Швеции — интеллектуальные системы, возможно, позволят определять места разрывов с точностью до метра. Кроме того, будут вестись работы над протоколами быстрого перенаправления данных на доступные спутники. Также эксперты будут разбираться в правилах использования подводных кабелей — пока нет единого органа, контролирующего их работу. В проекте приняли участие исследователи из Исландии, Швеции, Швейцарии, США и других стран. 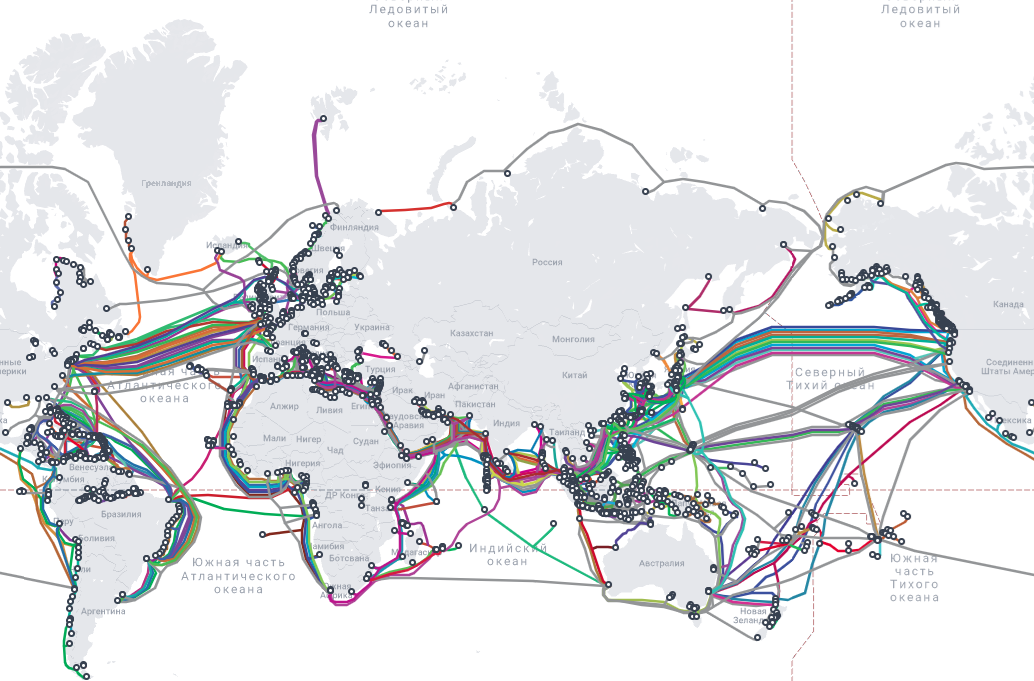
Источник изображения: Submarine Cable Map В TeleGeography напоминают, что безо всяких диверсий ежегодно происходит около 100 обрывов кабелей. Большинство из них устраняются специально оборудованными судами. На весьма дорогой ремонт может уйти от нескольких дней, недель или месяцев. В некоторых случаях речь может идти даже о годах. До сих пор у операторов связи и даже некоторых стран не было альтернатив на случай обрыва. Например, Исландию, на базе ЦОД которой работают многие финсервисы и выполняется много облачных вычислений, связывают с Европой и Северной Америкой всего четыре кабеля. Спутники способны помочь в передаче данных, но главным ограничением является их малая пропускная способность, которая на порядки меньше, чем у оптоволокна — единицы Гбит/с против десятков или сотен Тбит/с. HEIST предполагает развитие спутниковой связи, в том числе с использованием лазеров для коммуникаций. Над похожими проектами работают NASA, Starlink и Amazon. В NASA уверены, что лазеры смогут ускорить передачу минимум в 40 раз. Впрочем, это всё ещё далеко до пропускной способности кабелей, да и лазеры имеют ряд технических ограничений, мешающих повсеместному применению. Над повышением пропускной способности и сокращением времени задержки и будут работать в HEIST, хотя пока ни один из способов не является панацеей. Заявляется, что вся работа HEIST будет максимально публичной — люди смогут активно обсуждать и критиковать идеи, и способствовать его быстрому развитию.
20.12.2024 [16:10], Руслан Авдеев
Fujitsu заявила, что неоднократно предупреждала Почту Великобритании о проблемах с ПО Horizon, сломавших жизнь сотням людейВ ходе расследования Horizon Inquiry, посвящённого скандалу с британской почтовой службой, вскрылись неприглядные факты. Ошибки в ПО Horizon, из-за которых многих сотрудников несправедливо обвинили в мошенничестве, перекладываются почтой и разработчиком ПО, компанией Fujitsu, друг на друга, сообщает The Register. Fujitsu заявляет, что сообщала об ошибках в ПО, которые игнорировались ответственными лицами. Почта же утверждает, что ничего не знала и вообще зависела от японской компании. В своё время ПО Horizon стало причиной множества бухгалтерских сбоев, в результате которых сотрудники британской почтовой службы подверглись преследованию, в том числе уголовному. По словам юристов Fujitsu, поставщик IT-платформы Horizon не несёт ответственности за десятки сломанных жизней. Компания якобы в течение 25 лет сообщала почте о багах, ошибках и дефектах ПО и их влиянии на бухгалтерию государственной организации. Расследование началось в 2021 году и продолжается до сих пор. 
Источник изображения: Michael Jasmund / Unsplash Horizon представляет собой систему электронных терминалов продаж (EPOS) и финансового учёта, использующуюся Почтовой службой Великобритании. Она внедрялась компанией ICL, которую позже приобрела Fujitsu. С 1999 по 2015 гг. 736 управляющих почтовыми отделениями были неправомерно обвинены в мошенничестве — на деле причиной неточностей в бухгалтерии были ошибки ПО. В результате многие бывшие сотрудники почты стали банкротами, другие попали в тюрьму, а некоторые свели счёты с жизнью. Хотя многие обвинения сняли в судах, 60 человек по разным причинам не дожили до оправдания. Юридический представитель почты отрицает, что руководство знало о проблемах, а адвокат бывшей главы структуры Паулы Веннеллс (Paula Vennells) отрицает, что та знала о проблемах с Horizon. Представитель Fujitsu заявил, что компания установила как минимум 70 причастных, в отношении которых есть свидетельства того, что они всё время знали о проблеме. В том числе речь идёт о членах совета директоров Почтовой службы Великобритании, её топ-менеджерах и сотрудниках службы безопасности, а также командах, участвовавших в расследовании инцидентов. Утверждается, что почта пыталась замять и скрыть свою ответственность за скандал и несправедливо пытается обвинить во всём Fujitsu и другие «третьи стороны». В числе прочего почта пыталась выдать себя за «подчинённого партнёра» Fujitsu, находящегося от той в «технически зависимом» состоянии, но расследованием заявления не подтверждаются. 
Источник изображения: Joanna Kosinska / Unsplash Представитель Почтовой службы, в свою очередь, заявил, что та сожалеет о том, что положилась на японскую компанию, понадеявшись на надёжность Horizon. В результате ложное предположение об отсутствии ошибок якобы помешало вовремя принять меры — сыграло роль и желание защитить бренд и экономические интересы компании, а иерархия в организации не давала низовым сотрудникам дать делу об ошибках ход. Кроме того, руководящие должности занимали недостаточно компетентные люди, что привело к ряду управленческих ошибок. Обмена ключевой информации о Horizon в рамках почтовой структуры не происходило ни «вертикально», ни «горизонтально». Адвокат Саманта Лик (Samantha Leek), защищающая интересы непосредственно бывшей главы Почтовой службы Великобритании Веннелс, заявила, что бывшие коллеги подзащитной из числа топ-менеджеров не передали важную информацию о Horizon ни совету директоров, ни генеральному директору. Утверждается, что бывшая глава почты «опустошена» фактом того, что с ней не поделились сведениями и не имеет желания «показывать пальцами» на других или спекулировать, почему информацию не передали. Это не единственный случай в Великобритании, когда ПО проверенных компаний становится причиной катастрофических событий. В своё время ERP-система Oracle фактически довела до банкротства муниципалитет Бирмингема (крупнейший в Европе) — история не закончена до сих пор, а расходы превысили сотню миллионов фунтов. |
|