Материалы по тегу: intel
|
19.01.2023 [16:55], Алексей Степин
Dell анонсировала серверы PowerEdge на базе процессоров Sapphire RapidsDell, пусть и с некоторым запозданием, представила сразу несколько модельных рядов серверов на базе новых Intel Xeon Sapphire Rapids. В первую очередь обновление затронуло серию Core, которая получила пять новых моделей: компактный одноюнитовый сервер PowerEdge R660, две вариации PowerEdge R760 высотой 2U, одна из которых, R760xa, рассчитана на установку шести ускорителей: четырёх двухслотовых с теплопакетом 300 Вт в передней корзине и двух компактных (TDP 75 Вт) — в задней. В случае использования только однослотовых плат ускорителей их число можно увеличить до 12, так что это одна из самых высокоплотных и при этом компактных платформ для ускорителей. 
Dell PowerEdge R660/R660xs. Источник изображений: StorageReview Модели R760 и R660 с суффиксом xs относятся к сегменту начального уровня, они лишены некоторых опций, реализованных в основной серии. Также в среди новинок есть серверы PowerEdge R960 и R860 высотой 4U и 2U, интересные тем, что это не двух-, а четырёхпроцессорные системы. В своё время Dell пропустила поколение 4S-платформу на базе Cooper Lake-SP, так что в своём классе это долгожданное обновление. 
Dell PowerEdge R760. Источник изображений: StorageReview Модель Dell PowerEdge C6220 представляет собой модульное шасси высотой 2U c четырьмя вычислительными узлами на базе Sapphire Rapids. Она оснащена фирменной «мультивекторной» системой воздушного охлаждения, достаточно эффективной, чтобы позволить экономию на СЖО. 
Модели начального уровня и модульное шасси PowerEdge C6620 с воздушным охлаждением Для гиперскейлеров компания предлагает Dell HS5610 и HS5620 высотой 1 и 2U соответственно. В этих решениях компания воплотила тенденцию облачных провайдеров к отказу от проприетарных решений: система удалённого управления и мониторинга здесь базируется на OpenBMC и Open Server Manager. Есть среди новинок и модель в башенном форм-факторе, PowerEdge T560. Она поддерживает пару Sapphire Rapids c TDP до 250 Вт и может вмещать 12 полноразмерных накопителей 3,5″, либо 24 — в формате 2,5″. Возможна установка двух полноразмерных ускорителей. 
Серверы PowerEdge с поддержкой NVIDIA SXM5 и Intel Ponte Vecchio Наконец, мощные системы серии XE9680/9640/8640 предназначены для машинного обучения и спроектированы с учётом соответствующих требований. Старшая модель поддерживает установку восьми ускорителей NVIDIA H100 (SXM5), либо восьми A100 (SXM4), а младшая XE8640 — четырёх таких ускорителей. PowerEdge XE9640 интересна ориентацией на использование ускорителей Intel Max (Ponte Vecchio) с поддержкой интерконнекта GPU-GPU. Новые серверы Dell имеют ряд любопытных фирменных особенностей, среди которых выделяется BOSS-N1. Это отдельный RAID-контроллер с поддержкой безопасной загрузки UEFI и предназначенный для установки операционной системы. Как указывает литера N, новинка использует накопители NVMe. Дисковая корзина BOSS-N1 доступна с задней панели сервера и поддерживает функцию горячей замены. 
Источник изображений: StorageReview Не забросила Dell и направление аппаратных RAID-контроллеров, представив в этой серии новинку PERC12, которая, если верить заявлениям, вдвое превосходит по производительности решение предыдущего поколения и вчетверо — показатели PERC10. Контроллер поддерживает PCIe 5.0 и все современные интерфейсы: SATA-3, SAS-4 и NVMe. Также анонсирован контроллер H965e для создания JBOD-массивов с поддержкой SAS-4.
11.01.2023 [03:00], Игорь Осколков
Асимметричный ответ: Intel официально представила процессоры Xeon Sapphire RapidsIntel официально представила серверные процессоры Xeon семейства Sapphire Rapids (SPR), выход которых изрядно задержался, а также ускорители ранее известные как Ponte Vecchio и теперь объединённые вместе с HBM-версиями SPR в отдельную HPC-серию Max. В этом поколении Intel не смогла догнать AMD EPYC Genoa по числу ядер, числу каналов памяти и линий PCIe, но заготовила ассиметричный, хотя и очень странно реализованный ответ. Всего представлено 52 модели с числом P-ядер от 8 до 60 и с TDP от 125 до 350 Вт. По числу ядер это существенный апгрейд по сравнению с Ice Lake-SP (до 40 ядер), да и IPC вырос у Golden Cove на 15 % в сравнении с Sunny Cove. Но это существенный проигрыш в сравнении с Genoa (до 96 ядер), особенно если учитывать их максимальный TDP в 360 Вт (cTDP до 400 Вт). Правда, у Sapphire Rapids есть ещё и экономичный режим работы, в котором энергопотребление снижается на 20 %, а производительность для некоторых нагрузок — всего на 5 %. 
Изображения: Intel Sapphire Rapids предлагают 8 каналов памяти DDR5-4800 (1DPC) и DDR5-4400 (2DPC). 2DPC у Genoa пока что нет. Кроме того, контроллеры поддерживают и модули Optane PMem 300 (Crow Pass), но с учётом того, что производство 3D XPoint прекращено, достаться они могут не всем (впрочем, не всем они и нужны). Ну а маленькая серия Max также включает 64 Гбайт набортной HBM2e-памяти (1,2 Тбайт/с). Остались и отличия в максимальном объёме SGX-анклавов в зависимости от модели CPU. 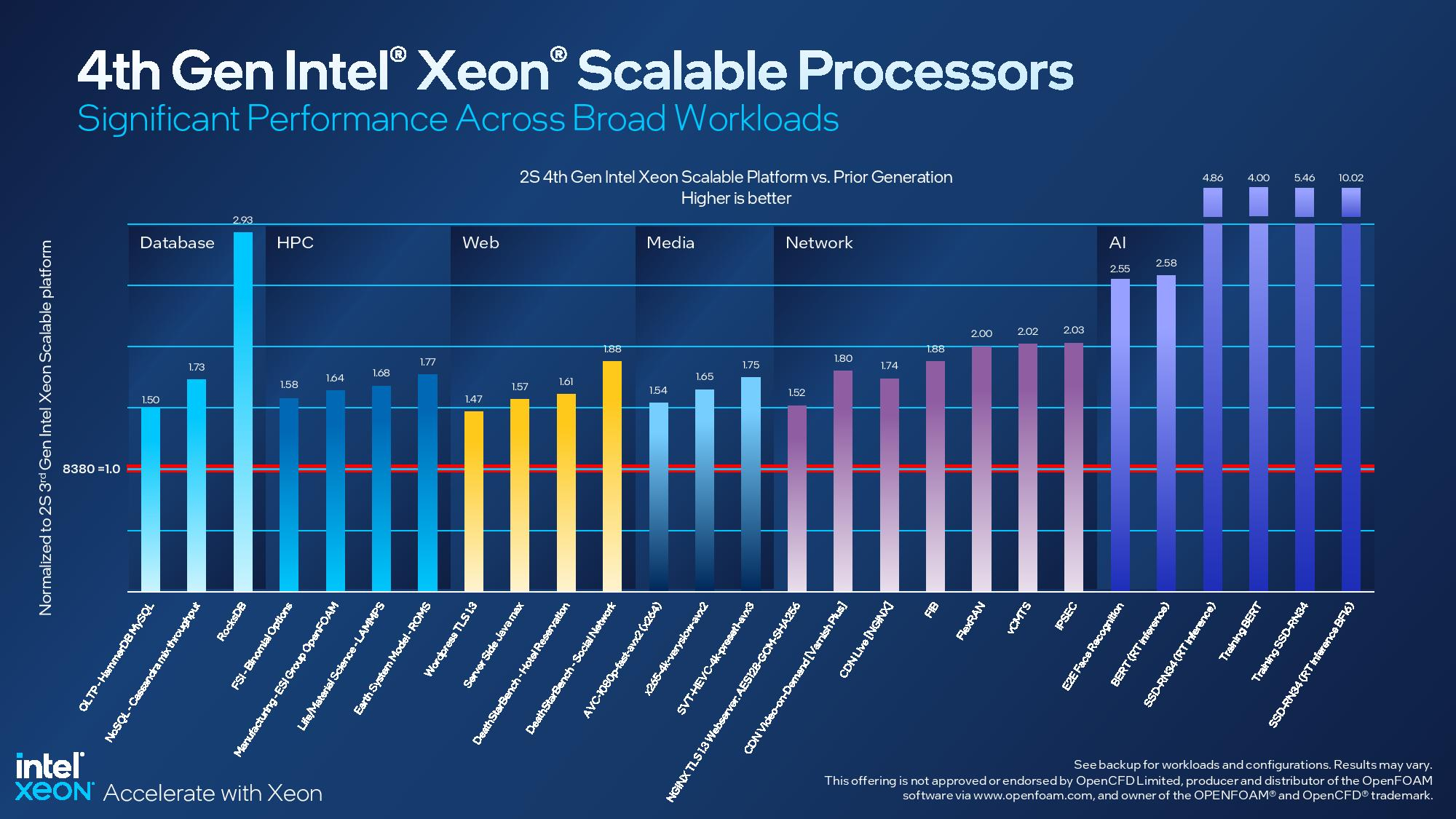 Однако по числу ядер на узел всё равно лидирует Intel. Если AMD поддерживает только 2S-конфигурации, то Intel снова предлагает и 4S, и 8S (а с момента выхода Cooper Lake-SP прошло немало времени) — на процессор доступно до 4 линий UPI 2.0 (16 ГТ/с в сравнении с 11,2 ГТ/с у Ice Lake-SP). В 2S-платформах Sapphire Rapids также формально обгоняет Genoa по числу линий PCIe 5.0, которых тут по 80 шт. на сокет. Формально потому, что в случае Genoa при желании всё же можно получить 160 линий, пожертвовав скоростью шины между CPU, но в односокетном варианте EPYC в любом случае интереснее Xeon. 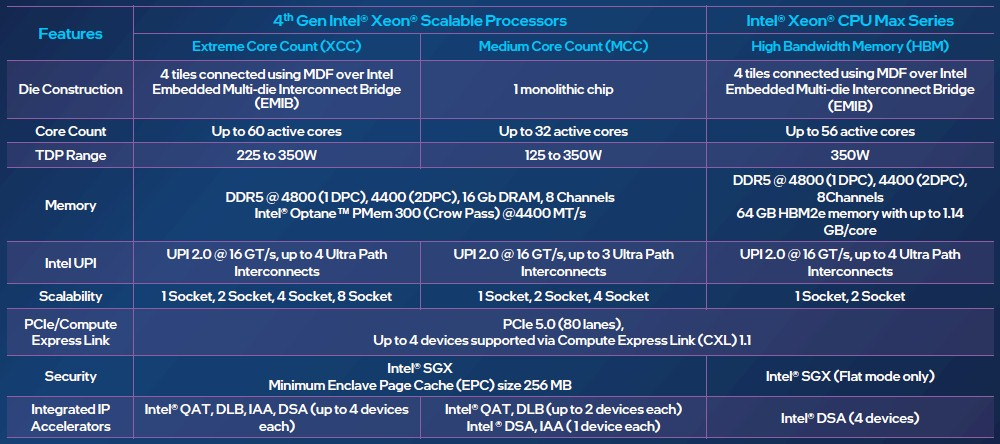 Без нюансов тут не обошлось. Так, при бифуркации до 8 x2 скорость падает до PCIe 4.0. Зато каждый root-комплекс поддерживает CXL 1.1, тогда как у Genoa CXL есть только у половины! Впрочем, поддержка всё равно ограничена 4x CXL-устройствами на CPU. Что ещё более странно, официально заявлена поддержка только устройств Type 1 и Type 2, но не Type 3, хотя последние весьма пригодились бы в ряде конфигураций, где требуется больше относительно недорогой, пусть и несколько более медленной, RAM. 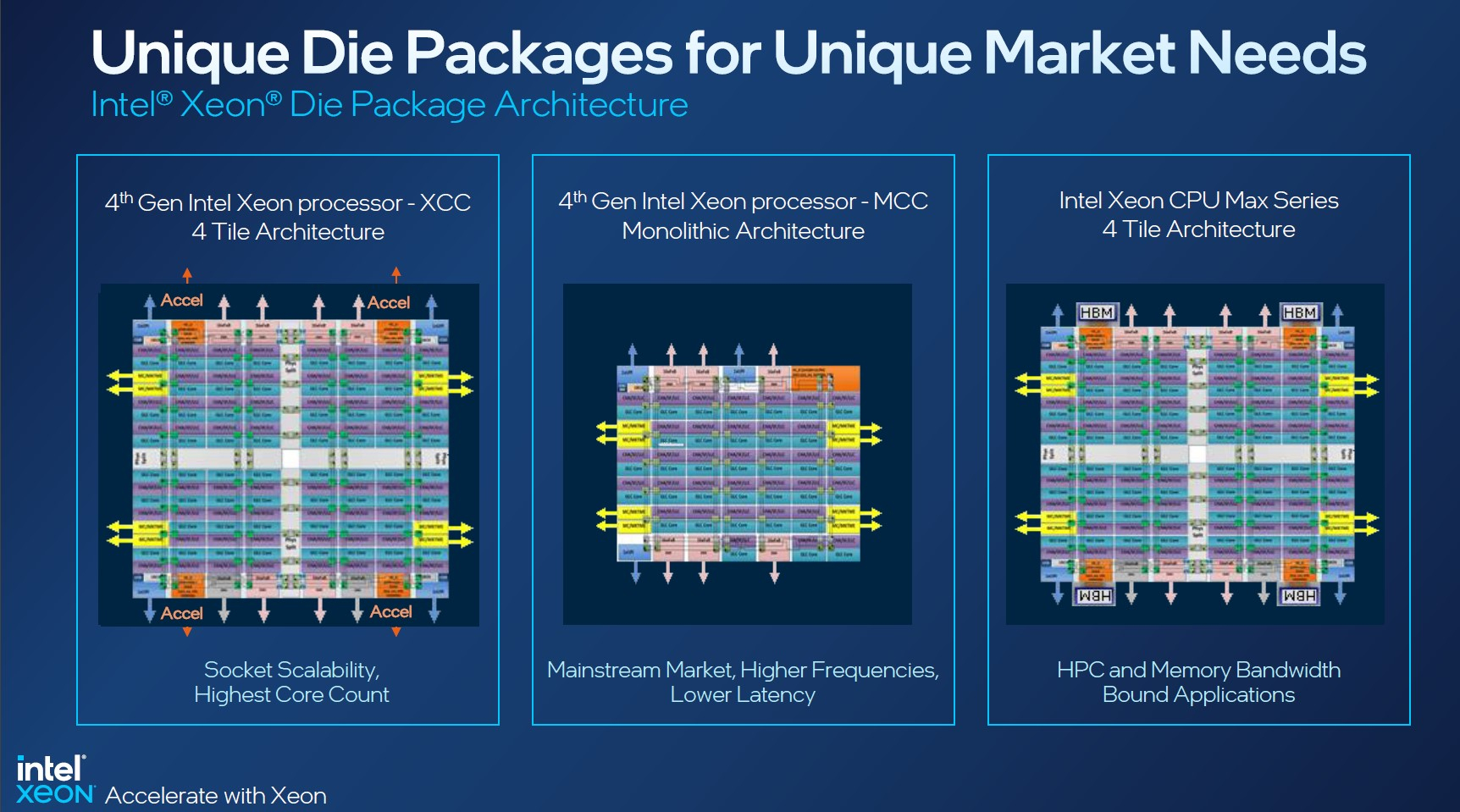 Сохранилось традиционное разделение на серии Platinum (8000), Gold (6000/5000), Silver (4000) и Bronze (3000), к которым теперь добавилась серия Max (9400). Список суффиксов, означающих оптимизацию под те или иные задачи и наличие каких-то особенностей, стал чуть шире: Y (SST-PP 2.0), Q (рассчитаны на работу с СЖО), U (односокетные общего назначения), T (увеличенный жизненный цикл), H (in-memory СУБД, аналитика, виртуализация), N (сетевые решения, в том числе для 5G), облачные P/V/M (IaaS/Paa/медиа), S (СХД и HCI). 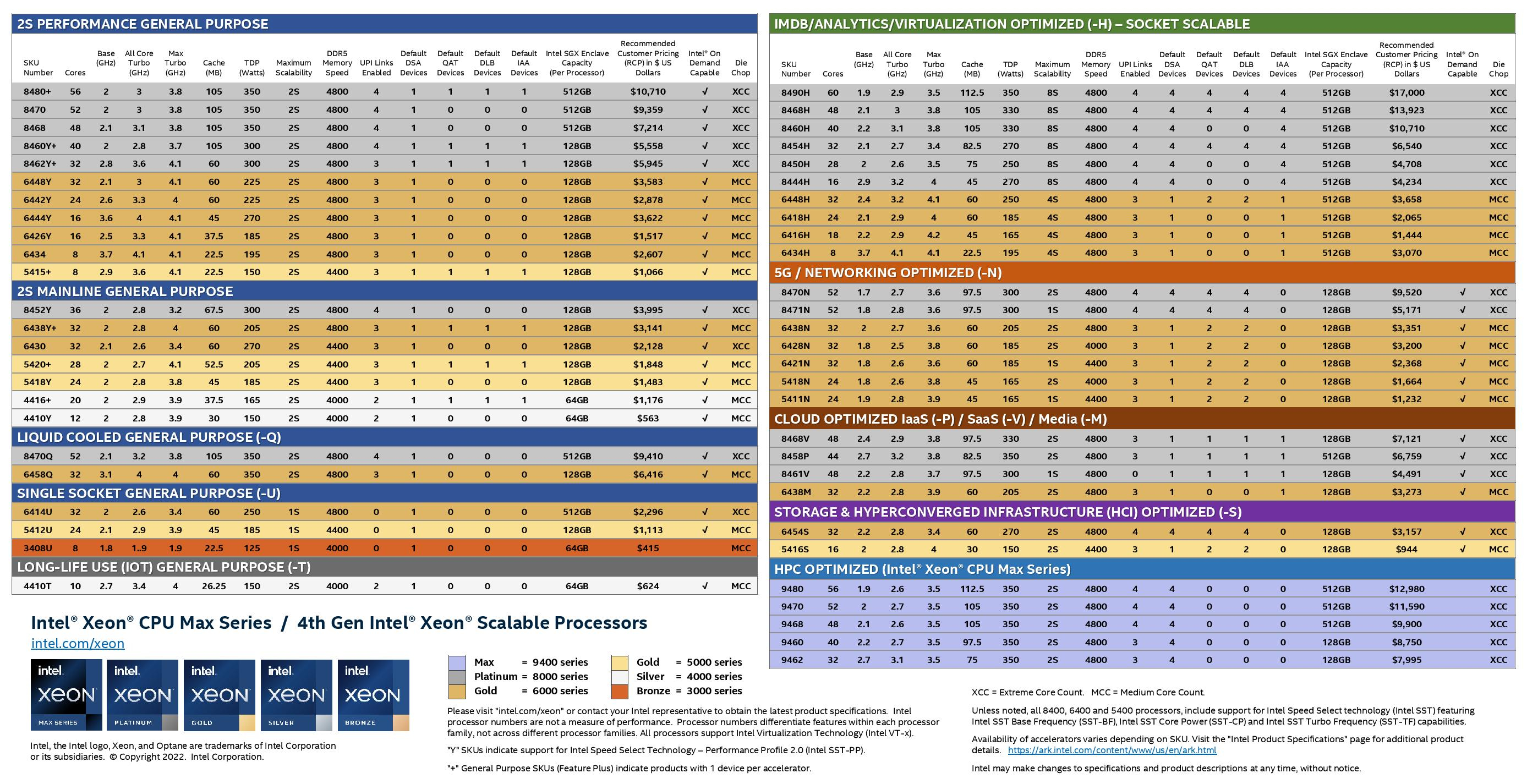 Но некоторые модели также имеют в названии «+». И вот тут начинается самое интересное! Все процессоры получили «традиционную» (в сравнении с Genoa) реализацию AVX-512, включая DL Boost, а также целый новый набор ИИ-инструкций AMX (до 10 раз быстрее обучение и инференс в сравнении с Ice Lake-SP). Есть и всяческие Speed Select, DDIO, TDX, CET и т.д. Но Sapphire Rapids также получили четыре отдельных ускорителя:
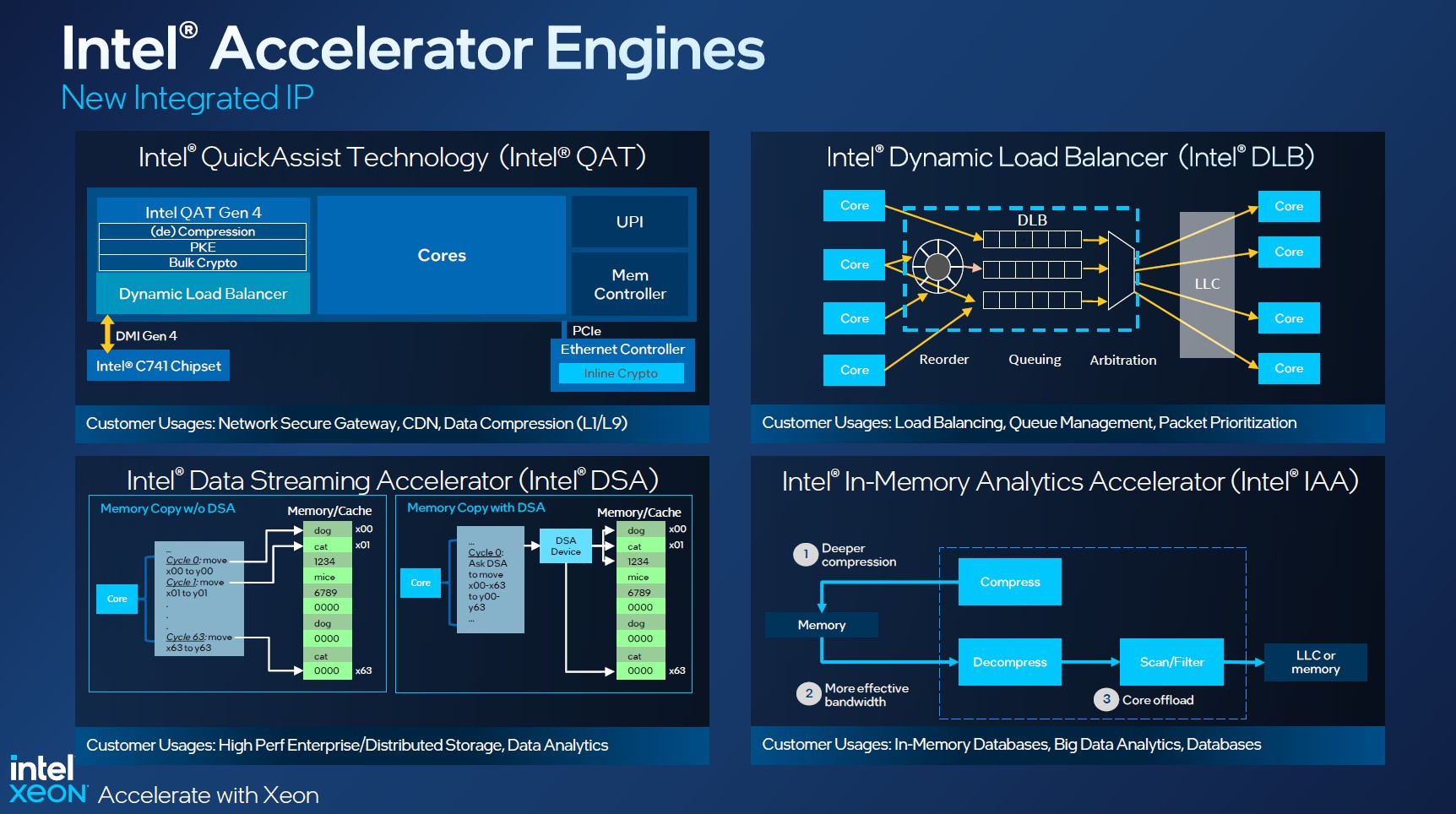 Intel заявляет, что средний прирост производительности Sapphire Rapids в сравнении с Ice Lake-SP составил 1,53 раза. А вот для ряда нагрузок, которые могут задействовать новые ускорители прирост производительности на Вт составляет уже до 2,9 раз! То есть Intel продолжает придерживаться стратегии создания максимально универсальных CPU для различных нагрузок. И действительно, спорить с гибкостью Sapphire Rapids трудно. Но какой ценой это достигается? Т.е. буквально: во сколько это обойдётся заказчику? Ответа пока нет.  Дело в том, что в зависимости от модели отличается число доступных и число активированных ускорителей. Фактически в новом поколении используется два вида кристаллов: XCC, «сшитые» из четырёх отдельных тайлов, и монолитные MCC (до 32 ядер, причём 32-ядерных моделей в серии большинство). У каждого тайла в XCC есть по одному блоку QAT, DSA, DLB и IAA, т.е. суммарно на CPU приходится до четырёх ускорителей каждого типа. В случае MCC может быть по два QAT и DLB и по одному DSA и IAA на процессор. Например, у тех моделей, что помечены «+», активно по одному блоку каждого типа, а минимум один DSA активен есть вообще у всех CPU.  За не активированные по умолчанию ускорители придётся заплатить в рамках программы Intel On Demand (SDSi), причём есть опции как с единовременным платежом за постоянную активацию, так и с оплатой по факту использования (это удобно в случае облаков и платформ по типу HPE Greenlake). Исключением являются H-модели, куда входит и самый дорогой ($17000) 60-ядерный процессор 8490H с полностью разблокированными ускорителями и поддержкой 8S-конфигураций, а также процессоры Max, которым доступно только четыре DSA-блока и 2S-платформы, например, 56-ядерный 9480 ($12980). 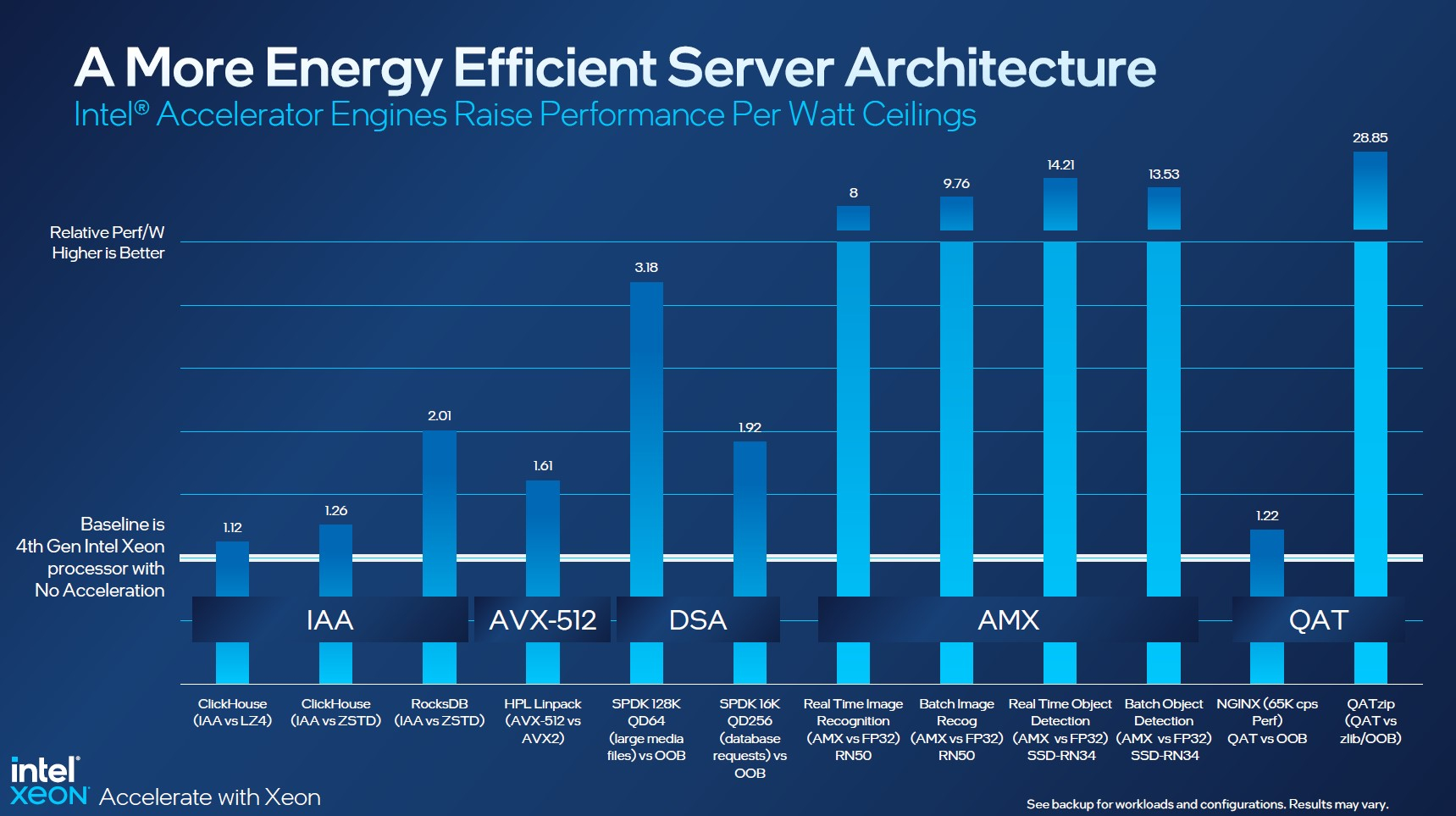 С одной стороны, желание Intel предоставить больше гибкости заказчикам, а заодно чуть увеличить выход годных к продаже процессоров, понятно. С другой — не очень-то и похоже, что CPU без «лишних» ускорителей отдаются с какой-то существенной скидкой. При этом транзисторный бюджет на них всё равно расходуется. Кроме того, есть ещё момент востребованности этих ускорителей и готовности ПО. У Intel есть и опыт ресурсы для помощи разработчикам, но процесс адаптации в любом случае не мгновенен.  Впрочем, у Intel по сравнению с AMD есть и ещё одно важное преимущество — в среднем более высокая доступность процессоров для большинства заказчиков. Так что с Sapphire Rapids может повториться та же история, что с Ice Lake-SP, когда вендоры здесь и сейчас готовы были предложить Intel-платформы.  В целом же, в новом семействе наиболее любопытны Xeon Max, которые, по словам Intel, по сравнению с прошлым поколением в 3,7 раз производительнее в задачах, завязанных на пропускную способность памяти (а это целый пласт HPC-нагрузок), и которые не так уж дороги. Правда, и здесь без приключений не обошлось — несчастный суперкомпьютер Aurora ожидает утомительный апгрейд его 10 тыс. узлов c простых Xeon Sapphire Rapids на Xeon Max — по полчаса на каждый узел.
10.11.2022 [17:15], Владимир Мироненко
HPE анонсировала недорогие, энергоэффективные и компактные суперкомпьютеры Cray EX2500 и Cray XD2000/6500Hewlett Packard Enterprise анонсировала суперкомпьютеры HPE Cray EX и HPE Cray XD, которые отличаются более доступной ценой, меньшей занимаемой площадью и большей энергоэффективностью по сравнению с прошлыми решениями компании. Новинки используют современные технологии в области вычислений, интерконнекта, хранилищ, питания и охлаждения, а также ПО. 
Изображение: HPE Суперкомпьютеры HPE обеспечивают высокую производительность и масштабируемость для выполнения ресурсоёмких рабочих нагрузок с интенсивным использованием данных, в том числе задач ИИ и машинного обучения. Новинки, по словам компании, позволят ускорить вывода продуктов и сервисов на рынок. Решения HPE Cray EX уже используются в качестве основы для больших машин, включая экзафлопсные системы, но теперь компания предоставляет возможность более широкому кругу организаций задействовать супервычисления для удовлетворения их потребностей в соответствии с возможностями их ЦОД и бюджетом. В семейство HPE Cray вошли следующие системы:
Все три системы задействуют те же технологии, что и их старшие собратья: интерконнект HPE Slingshot, хранилище Cray Clusterstor E1000 и пакет ПО HPE Cray Programming Environment и т.д. Система HPE Cray EX2500 поддерживает процессоры AMD EPYC Genoa и Intel Xeon Sapphire Rapids, а также ускорители AMD Instinct MI250X. Модель HPE Cray XD6500 поддерживает чипы Sapphire Rapids и ускорители NVIDIA H100, а для XD2000 заявлена поддержка AMD Instinct MI210. 
Изображение: Intel В качестве примеров выгод от использования анонсированных суперкомпьютеров в разных отраслях компания назвала:
04.10.2022 [22:57], Алексей Степин
Intel Labs представила нейроморфный ускоритель Kapoho Point — 8 млн электронных нейронов на 10-см платеКомпания Intel уже не первый год развивает направление нейроморфных процессоров — чипов, имитирующих поведение нейронов головного мозга. Уже во втором поколении, Loihi II, процессор получил 128 «ядер», эквивалентных 1 млн «цифровых нейронов», однако долгое время этот чип оставался доступен лишь избранным разработчикам Intel Neuromorphic Research Community через облако. Но ситуация меняется, пусть и спустя пять лет после анонса первого нейроморфного чипа: компания объявила о выпуске платы Kapoho Point, оснащённой сразу восемью процессорами Loihi II. Напомним, что они производятся с использованием техпроцесса Intel 4 и состоят из 2,3 млрд транзисторов, образующих асинхронную mesh-сеть из 128 нейроморфных ядер, модель работы которых задаётся на уровне микрокода. 
Источник изображений: Intel Labs Площадь кристалла нейроморфоного процессора Intel второго поколения составляет всего 31 мм2. Судя по всему, активного охлаждения Loihi II не требует: даже в первой реализации в виде PCIe-платы Oheo Gulch кулером оснащалась только управляющая ПЛИС, но не сам нейроморфный чип. В своём интервью ресурсу AnandTech Майк Дэвис (Mike Davies), глава проекта, отметил, что в реальных сценариях, выполняемых в человеческом масштабе времени, речь идёт о цифре порядка 100 милливатт, хотя в более быстром масштабе чип, естественно, может потреблять и больше. 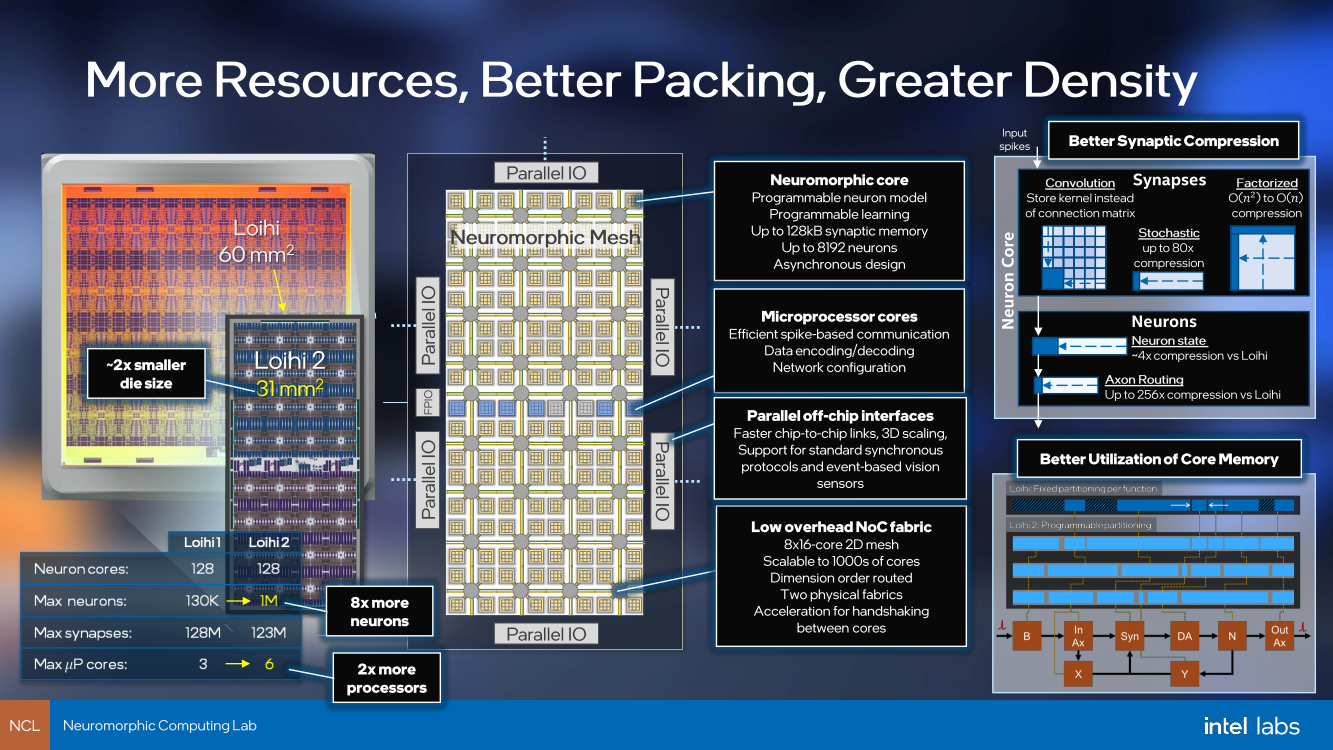
Архитектура и особенности строения Loihi II. По нажатию открывается полноразмерная версия Новый модуль, по словам компании, способен эмулировать до 1 млрд синапсов, а в задачах оптимизации с большим количеством переменных (до 8 миллионов, эквивалентно количеству «нейронов»), где нейроморфная архитектура Intel очень сильна, он может опережать традиционные процессоры в 1000 раз. Каждое ядро имеет свой небольшой пул быстрой памяти объёмом 192 Кбайт. Шесть выделенных ядер отвечают за управление нейросетью Loihi II; также в составе чипа имеются аппаратные ускорители кодирования-декодирования данных. Новинка изначально создана модульной: благодаря интерфейсному разъёму несколько плат Kapoho Point можно устанавливать одна над другой. Поддерживаются «бутерброды» толщиной до 8 плат, в деле опробован, однако, вдвое более тонкий вариант, но даже четыре Kapoho Point дают 32 миллиона нейронов в совокупности. Для коммуникации с внешним миром используется интерфейс Ethernet: в чипе реализована поддержка скоростей от 1 (1000BASE-KX) до 10 Гбит/с (10GBase-KR). Размеры каждой платы невелики, всего 4×4 дюйма (102×102 мм). 
Платы Kapoho Point позволяют легко расширять нейросеть на базе Loihi II В отличие от первого поколения Loihi, доступ к которому можно было получить лишь виртуально, через облако, системы на базе Kapoho Point уже доставлены избранным клиентам Intel, и речь идёт о реальном «железе». В число первых клиентов входит Исследовательская лаборатория ВВС США (Air Force Research Laboratory, AFRL), для задач которой такие достоинства Loihi II, как компактность и экономичность являются решающими. 
Возможности SDK Lava Одновременно с анонсом Kapoho Point компания Intel обновила и фреймворк Lava. В отлчиие от SDK первого поколения Nx новая открытая программная платформа разработки сделана аппаратно-независимой, что позволит разрабатывать нейро-приложения не только на платформе, оснащённой чипами Loihi II.
29.07.2022 [14:18], Алексей Степин
Бесславный конец Optane: полмиллиарда убытков и полный отказ от технологииВ своё время совместная инициатива Intel и Micron, целью которой стало создание принципиально нового типа энергонезависимой памяти 3D XPoint, наделало много шума. Первые же выпущенные на основе данной технологии SSD показали великолепные результаты. Эту память сегодня мы знаем как Optane, и, увы, с надеждами на появление новых решений на её основе придётся распрощаться. Тревожные звонки раздавались давно: в 2018 году Micron вышла из бизнеса, уступив своё производство 3D XPoint партнёру, а сама Intel отказалась от идеи выпуска потребительских накопителей на базе Optane. Но, по крайней мере, на тот момент она сосредоточила усилия на выпуске серверных решений. В их число вошёл и принципиально новый продукт: энергонезависимые модули DCPMM/PMem.  Они устанавливались в обычные слоты DIMM, не слишком сильно уступали в производительности классической оперативной памяти и позволяли кардинально нарастить объём доступной памяти за меньшую стоимость, нежели при использовании только DRAM. Казалось бы, память Optane нашла свою, пусть и довольно экзотическую нишу, что подтверждалось и многочисленными результатами тестов систем с Optane DCPMM, в том числе, в научных задачах. Но грянул гром! По результатам II квартала 2022 года Intel сообщила, что изрядно похудевшее к этому моменту подразделение Optane принесло $559 млн убытков. Решение списать текущие запасы готовых решений и чипов по графе «убытки» окончательно доказывает то, что Intel действительно намеревается покончить с этой страницей своей истории. Равно как и с SSD — соответствующее подразделение продано компании SK Hynix.  На данный момент сама Intel официально подтвердила отказ от Optane: в рамках новой стратегии оптимизации бизнеса IDM 2.0 компания закроет подразделения, не являющиеся решающими в стратегическом отношении, либо просто недостаточно прибыльные. Впрочем, поддержка клиентов, уже вложившихся в Optane будет продолжена. Сама же Intel отметила, что переход на CXL позволит хотя бы отчасти заменить Optane PMem. Из альтернатив технологии Optane, тоже не слишком популярных, можно вспомнить Samsung Z-SSD и Toshiba/Kioxia XL-Flash. Таким образом, приходится расстаться с мечтой о твердотельных накопителях не просто надёжных, но и лишённых традиционной медлительности NAND при операциях записи, особенно мелкоблочных. Стоимость производства чипов 3D XPoint даже во втором поколении, когда память удалось сделать четырёхслойной, всё же оказалась слишком высокой для того, чтобы устройства на её основе стали действительно выгодными для Intel.
04.07.2022 [22:18], Алексей Степин
Intel разработала фотонный техпроцесс с интегрированным мультиволновым массивом лазеровФотоника сулит немалые преимущества, и особенно ярко они проявятся в случае достижения высокой степени интеграции — если внешний источник лазерного излучения может существенно усложнить систему и сделать её более дорогой, то интегрированный на кремниевую пластину, напротив, многое упрощает. Неудивительно, что разработчики, бьющиеся над созданием гибридных фотонных чипов, нацелены именно на такой вариант. Ранее мы рассказывали о варианте Synopsys и Juniper Networks, которые также планируют использовать интегрированные лазеры в рамках возможностей техпроцесса PH18DA компании Tower Semiconductor, а сейчас успеха добилась корпорация Intel. 
Традиционные оптические модуляторы достаточно громоздки. Источник: Intel Labs Научно-исследовательское подразделение компании, Intel Labs, сообщает, что на базе «существующего кремниевого-фотонного техпроцесса для пластин диаметром 300 мм» удалось создать интегрированный лазерный массив, работающий с восемью длинами волн. Это хорошо отработанная технология, на её основе Intel уже производит оптические трансиверы, что открывает дорогу к достаточно быстрому началу производству фотонных чипов со встроенными лазерными массивами. 
Вариант Intel использует компактные кольцевые микромодуляторы. Источник: Intel Labs В технологии используются лазерные диоды с распределённой схемой обратной связи (distributed feedback, DFB), которая позволяет добиться высокой точности как в мощности излучения в пределах 0,25 дБ, так и в спектральных характеристиках, где отклонения в границах используемых спектров не превышают 6,5%. Достигнутые параметры превышают аналогичные показатели классических полупроводниковых лазеров. Компания также отмечает, что применённая ей новая технология кольцевых микромодуляторов, отвечающих за конверсию электрического сигнала в оптический, существенно компактнее более традиционных решений других разработчиков. Такой подход позволяет поднять удельную плотность фотонных линий передачи данных, то есть, при прочих равных условиях, чип, оснащённый интерконнектом Intel, будет иметь более «широкую» оптическую шину с более высокой пропускной способностью. 
В технологии используется массив из 8 лазеров. Источник: Intel Labs Технология гибридной фотоники со встроенными лазерами, использующая мультиплексирование с разделением по длине волны (dense wavelength division multiplexing, DWDM), делает высокоскоростной оптический интерконнект возможным, но до успеха Intel данная технология упиралась именно в точность разделения спектра и в достаточно высокое энергопотребление источников излучения. В настоящее время уже ведутся работы по созданию специального чиплета, который позволит вывести оптический интерконнект за пределы кремниевой пластины, а это в перспективе даст возможность как для фотонного соединения между центральным процессором и памятью или GPU, так и для реализации будущих ещё более скоростных версий стандарта PCI Express или его наследника. 
Дорога к высокоскоростному оптическому интерконнекту открыта! Источник: Intel Labs Ayar Labs, один из пионеров в освоении гибридных электронно-оптических технологий однако считает, что у подхода Intel есть и недостатки. Сам по себе оптический интерконнект, конечно, может быть производительнее классического, и к тому же он не подвержен помехам. Однако лазерные диоды по природе своей достаточно капризны, а глубокая интеграция источника излучения в чип при выходе хотя бы одного лазера из строя делает всю схему бесполезной. В своих решениях Ayar Labs полагается на внешний лазерный модуль SuperNova.
09.06.2022 [21:00], Алексей Степин
Серия процессоров Intel Atom P5000 Snow Ridge пополнилась новыми моделямиКорпорация Intel на этой неделе уделила немало внимания серии экономичных процессоров Atom. Помимо новых моделей в серии C5000 Parker Ridge появились и новые чипы в семействе P5000 Snow Ridge. Эта 10-нм SoC-платформа дебютировала в 2020 году, её главное назначение — использование в беспроводном 5G-оборудовании, а главной отличительной особенностью можно назвать развитую сетевую подсистему. Последняя предлагает тесную интеграцию со 100GbE-контроллером Intel Ethernet 800 с поддержкой коммутации и технологии QAT. Изначально в серии было всего четыре модели с номерами серии P5900, количеством ядер Tremont от 8 до 24 и литерой B в названии — от «Base Station». Теперь семейство пополнилось девятью новыми моделями с индексами от P5300 до P5700. Сравнить характеристики всех чипов P5000 можно на сайте Intel, воспользовавшись этой ссылкой. 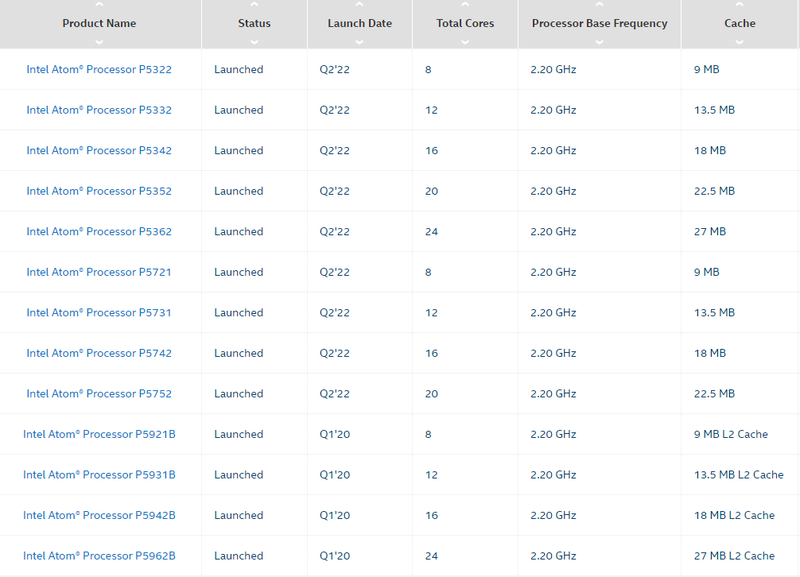
Модельный ряд Intel Atom P5000. Источник: Intel Хотя базовая частота у всех новинок осталась прежней и составляет 2,2 ГГц, объём кеша на кластер из четырёх ядер равен 4,5 Мбайт, а количество линий PCIe составляет 32 шт., есть и отличия. Для новых моделей заявлена поддержка вдвое большего максимального объёма оперативной памяти, 256 Гбайт против 128 Гбайт у чипов с литерой B. Есть и некоторые изменения в подсистеме памяти: младшие версии с номерами P5300 поддерживают либо DDR4-2400, либо 2666, тогда как для P5700 сохранена поддержка DDR4-2933. 
Intel NetSec Accelerator card. Источник: Intel (via ServeTheHome) Теплопакеты достаточно высокие, от 48 до 83 Вт, что отчасти продиктовано наличием продвинутой сетевой подсистемы. Она может быть сконфигурирована в различных режимах, у P5300 это от 8×10GbE до 1×100GbE, P5700 может поддерживать от 8 портов 25GbE с шифрованием, а в режиме 2×100GbE один порт обязательно будет резервным. Сетевой движок QAT третьего поколения сохранился у всех моделей. Режим коммутатора доступен только для P5700. 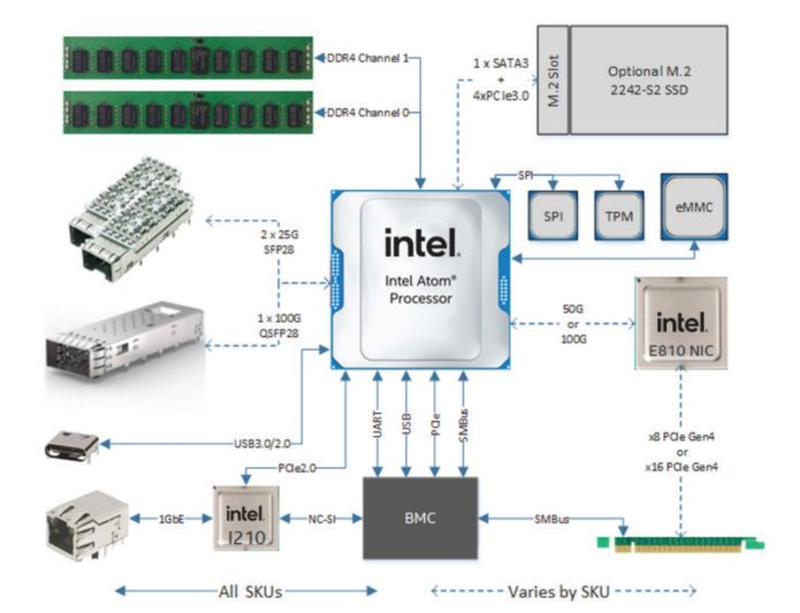
Intel NetSec — полноценная x86-система в виде PCIe-адаптера. Источник: Intel (via ServeTheHome) Новые процессоры Intel Atom P5000 могут служить и основой для современных сетевых ускорителей — компания продемонстрировала плату NetSec Accelerator, спроектированную Silicom и несущую на борту 8-ядерный P5721 или 16-ядерный P5742. Ускоритель имеет либо 2 корзины SFP28 (25GbE), либо корзину QSFP28 (100GbE), свой BMC и опциональный накопитель M.2 2242 в дополнение к 256 Гбайт набортной eMMC. По сути, это полноценная x86-платформа в форм-факторе PCIe-платы. Интерфейс, в зависимости от модели, PCIe 4.0 x8, либо x16, теплопакет у старшего варианта может достигать 115 Вт, поэтому плата использует дополнительное питание. Производительность в дуплексном режиме с полноценным шифрованием в реальном времени — 25 и 50 Гбит/с. Интересно, что новинка не позиционируется как IPU, но и термин DPU компанией не используется.
09.06.2022 [16:37], Сергей Карасёв
Intel представила первые процессоры серии Atom C5000 Parker RidgeКорпорация Intel анонсировала первые шесть процессоров семейства Atom C5000 (Parker Ridge), предназначенных для применения в серверном и сетевом оборудовании. Дебютировали изделия с обозначениями C5325, C5320, C5315, C5310, C5125 и C5115, которые изготавливаются по 10-нм техпроцессу. В зависимости от модификации чипы содержат четыре или восемь ядер (Tremont). Технология многопоточности не поддерживается. Тактовая частота модели C5310 составляет 1,6 ГГц. Версии C5325, C5320 и C5315 функционируют на частоте 2,4 ГГц, а C5125 и C5115 — 2,8 ГГц. Поддерживается работа с двухканальной оперативной памятью DDR4, частота которой может составлять 2400 или 2933 МГц (см. характеристики отдельных моделей в таблице ниже). Максимально поддерживаемый объём ОЗУ у всех решений равен 256 Гбайт. Все изделия наделены 9 Мбайт кеша второго уровня. Показатель TDP варьируется от 32 до 50 Вт. Это, как отмечает ресурс ServeTheHome, заметивший появление новинок в базе Intel, довольно много для изделий такого класса. 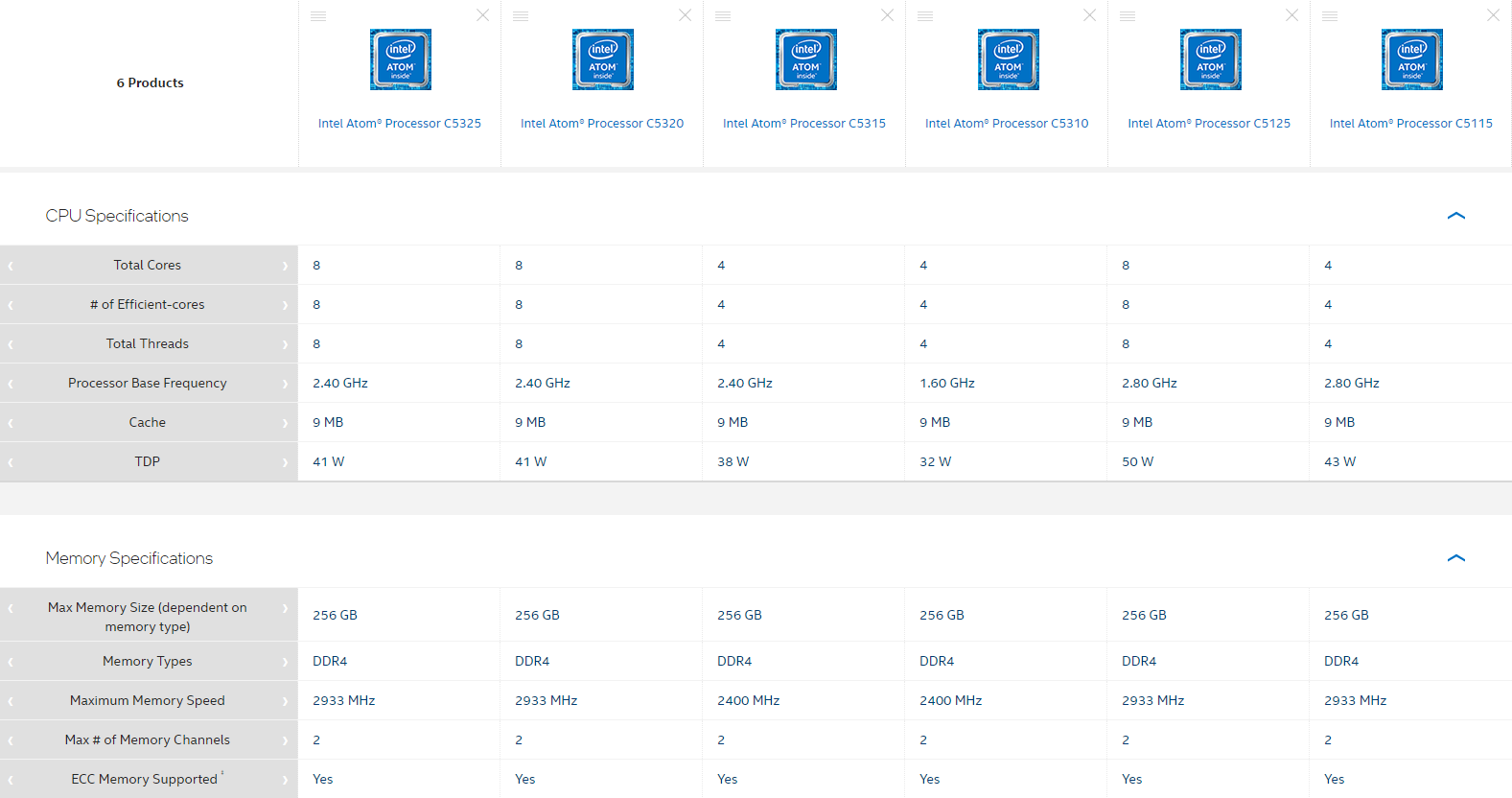
Источник: Intel Процессоры различаются количеством поддерживаемых линий PCIe — 12, 16 или 32. Чипы позволяют задействовать 12 или 16 портов SATA и восемь USB-портов в конфигурации 4 × USB 2.0 и 4 × USB 3.0. Все процессоры поддерживают технологию Intel QuickAssist (QAT) второго поколения (шифрование 20 Гбит/с), средства виртуализации Virtualization Technology (VT-x), инструкции AES, технологии Intel Trusted Execution и Enhanced Intel SpeedStep. Отличительной же чертой серии являются встроенные сетевые интерфейсы (до 8 шт., до 50GbE), которые есть в четырёх из шести представленных моделей.
16.05.2022 [23:41], Алексей Степин
Intel: UCIe объединит разнородные чиплеты внутри одной упаковки и за её пределамиШина PCI Express давно стала стандартом де-факто: она не требует много контактов, её производительность в пересчёте на линию уже достигла ≈4 Гбайт/с (32 ГТ/с) в версии PCIe 5.0, а использование стека CXL сделает PCI Express поистине универсальной. Но для соединения чиплетов или межпроцессорной коммуникации эта шина в текущем её виде подходит не лучшим образом. Но использование проприетарных технологий существенно ограничивает потенциал чиплетных решений, и для преодоления этого ограничения в марте этого года 10-ю крупными компаниями-разработчиками, включая AMD, Qualcomm, TSMC, Arm и Samsung, был основан новый стандарт Universal Chiplet Interconnect Express (UCIe). 
Изображение: UCIe Consortium Уже первая реализация UCIe должна превзойти PCI Express во многих аспектах: если линия PCIe 5.0 представляет собой четыре физических контакта с пропускной способностью 32 ГТ/с, то UCIe позволит передавать по единственному контакту до 12 Гбит/с, а затем планка будет повышена до 16 Гбит/с. При этом энергопотребление у UCIe ниже, а эффективность — выше. На равном с PCIe расстоянии новый стандарт может быть вчетверо производительнее при том же количестве проводников. В перспективе эта цифра может быть увеличена до 10–20 раз, то есть, узким местом между чиплетами UCIe явно не станет. Более того, новый интерконнект не только изначально совместим с CXL, но и гораздо лучше приспособлен к задачам дезагрегации. Иными словами, быстрая связь напрямую между чиплетами возможна не только в одной упаковке или внутри узла, но и за его пределами. 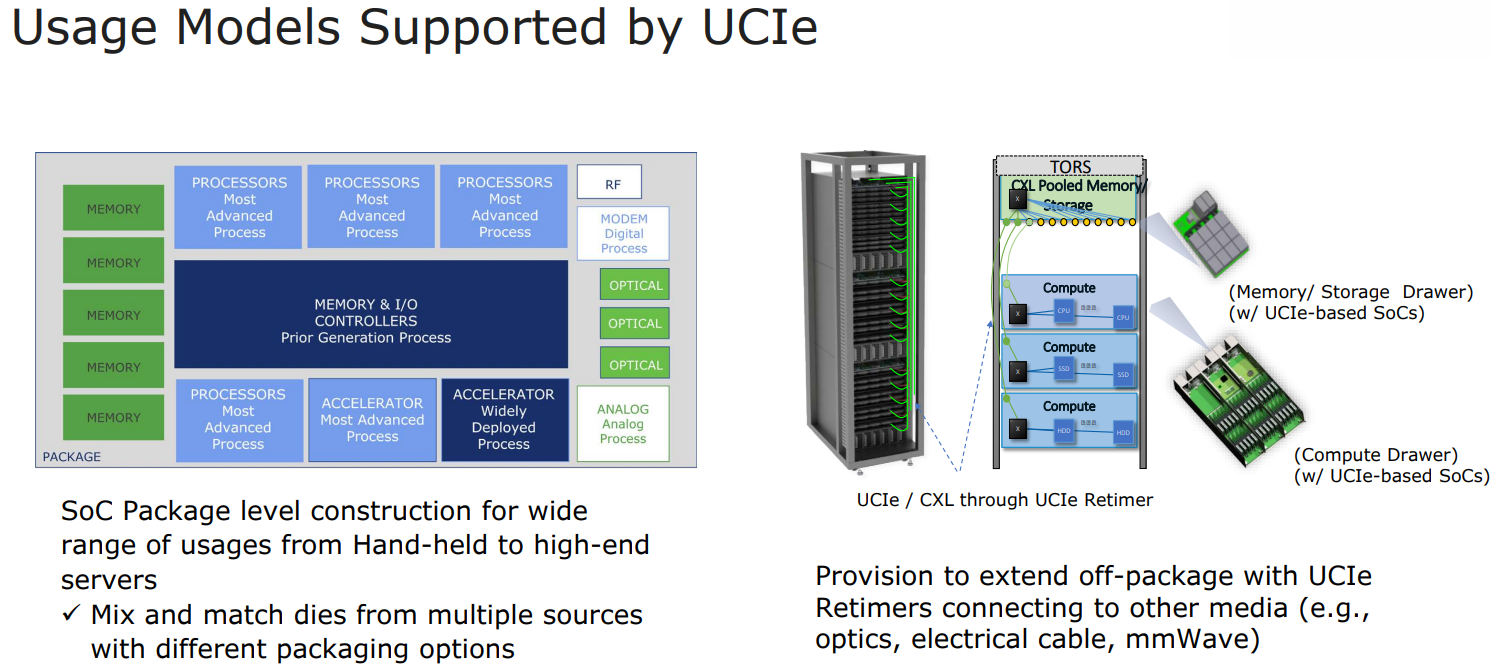
Изображение: UCIe Consortium Весьма заинтересована в новом стандарте Intel, которая планирует использовать UCIe таким образом, что в процессорах нового поколения ядра x86 смогут соседствовать с Arm или RISC-V. При этом планируется обеспечить совместимость UCIe с технологиями упаковки Intel EMIB и TSMC CoWoS, заодно добавив поддержку других шин, в том числе Arm AMBA, а также возможность легкой конвертации в проприетарные протоколы других разработчиков. В настоящее время Intel уже есть несколько примеров использования UCIe. Так, в одном из вариантов с помощью новой шины к процессорным ядрам подключаются ускорители и блок управления, а упаковка EMIB используется для подключения чипа к дезагрегированной памяти DDR5 и линиям PCI Express.
10.05.2022 [22:46], Игорь Осколков
Intel анонсировала ИИ-ускорители Habana Gaudi2 и GrecoНа мероприятии Intel Vision было анонсировано второе поколение ИИ-ускорителей Habana: Gaudi2 для задач глубокого обучения и Greco для инференс-систем. Оба чипа теперь производятся с использованием 7-нм, а не 16-нм техпроцесса, но это далеко не единственное улучшение. Gaudi2 выпускается в форм-факторе OAM и имеет TDP 600 Вт. Это почти вдвое больше 350 Вт, которые были у Gaudi, но второе поколение чипов значительно отличается от первого. Так, объём набортной памяти увеличился втрое, т.е. до 96 Гбайт, и теперь это HBM2e, так что в итоге и пропускная способность выросла с 1 до 2,45 Тбайт/с. Объём SRAM вырос вдвое, до 48 Мбайт. Дополняют память DMA-движки, способные преобразовывать данные в нужную форму на лету. 
Изображения: Intel/Habana В Gaudi2 имеется два основных типа вычислительных блоков: Matrix Multiplication Engine (MME) и Tensor Processor Core (TPC). MME, как видно из названия, предназначен для ускорения перемножения матриц. TPC же являются программируемыми VLIW-блоками для работы с SIMD-операциями. TPC поддерживают все популярные форматы данных: FP32, BF16, FP16, FP8, а также INT32, INT16 и INT8. Есть и аппаратные декодеры HEVC, H.264, VP9 и JPEG.  Особенностью Gaudi2 является возможность параллельной работы MME и TPC. Это, по словам создателей, значительно ускоряет процесс обучения моделей. Фирменное ПО SynapseAI поддерживает интеграцию с TensorFlow и PyTorch, а также предлагает инструменты для переноса и оптимизации готовых моделей и разработки новых, SDK для TPC, утилиты для мониторинга и оркестрации и т.д. Впрочем, до богатства программной экосистемы как у той же NVIDIA пока далеко. 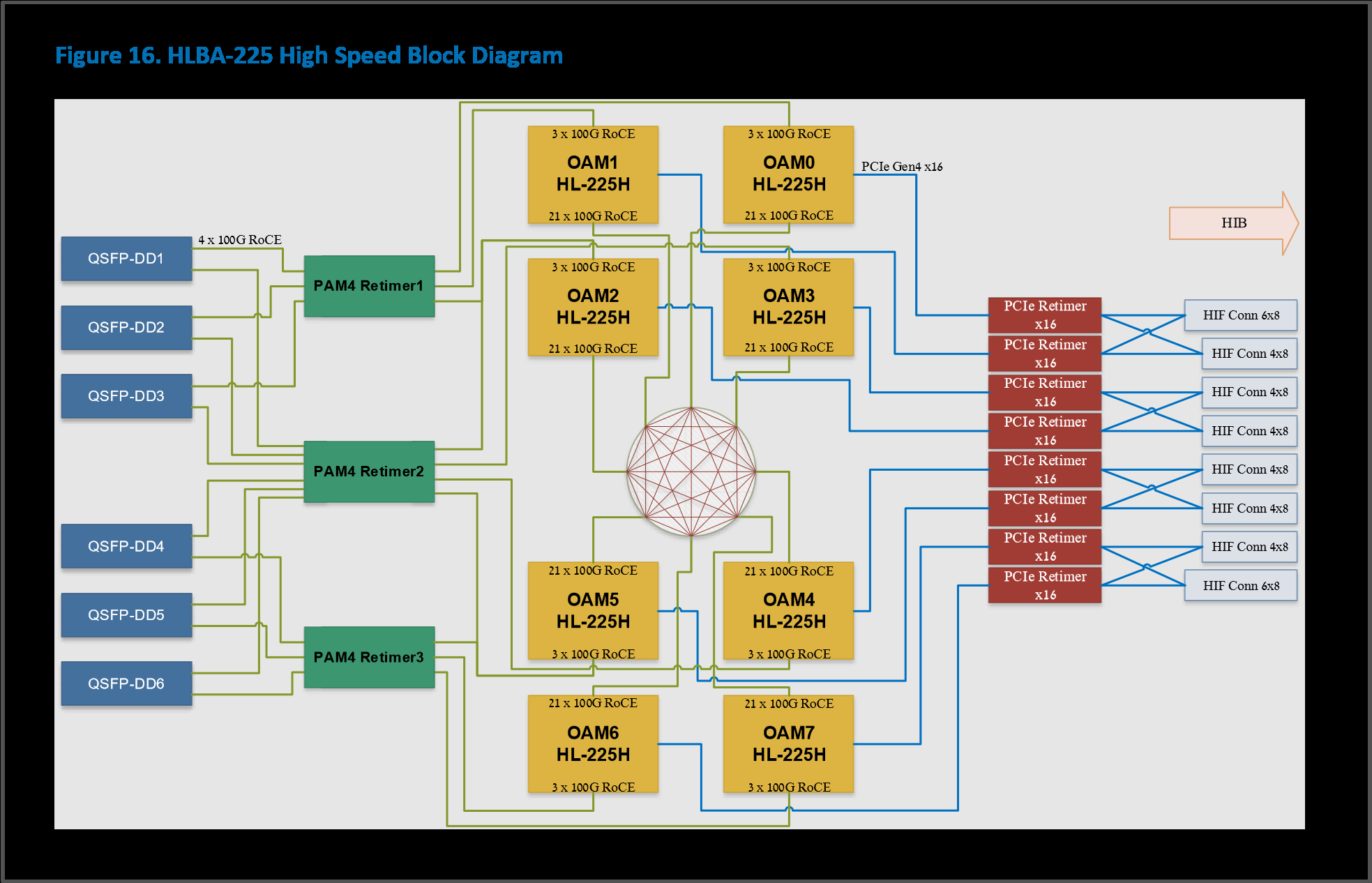 Интерфейсная часть новинок включает PCIe 4.0 x16 и сразу 24 (ранее было только 10) 100GbE-каналов с RDMA ROcE v2, которые используются для связи ускорителей между собой как в пределах одного узла (по 3 канала каждый-с-каждым), так и между узлами. Intel предлагает плату HLBA-225 (OCP UBB) с восемью Gaudi2 на борту и готовую ИИ-платформу, всё так же на базе серверов Supermicro X12, но уже с новыми платами, и СХД DDN AI400X2. 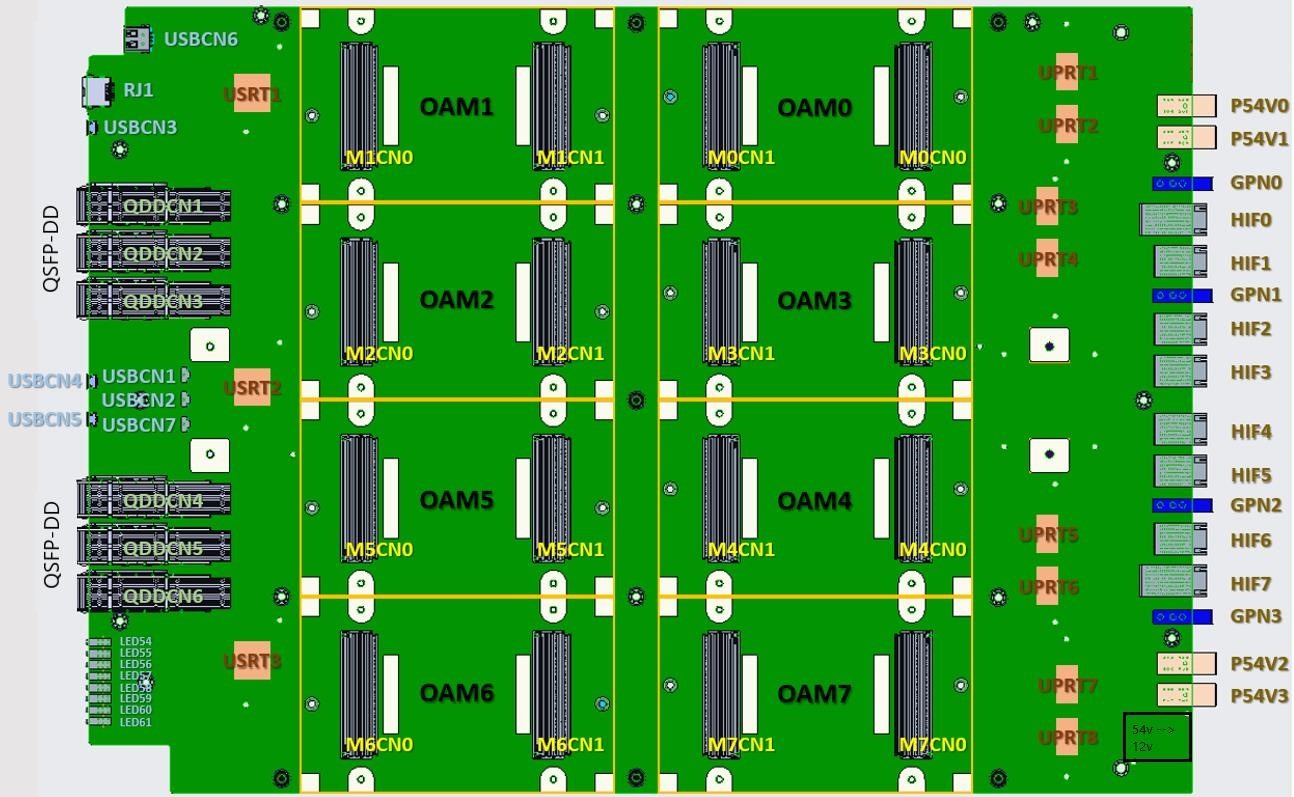 Наконец, самое интересное — сравнение производительности. В ряде популярных нагрузок новинка оказывается быстрее NVIDIA A100 (80 Гбайт) в 1,7–2,8 раз. На первый взгляд результат впечатляющий. Однако A100 далеко не новы. Более того, в III квартале этого года ожидается выход ускорителей H100, которые, по словам NVIDIA, будут в среднем от трёх до шести раз быстрее A100, а благодаря новым функциям прирост в скорости обучения может быть и девятикратным. Ну и в целом H100 являются более универсальными решениями. 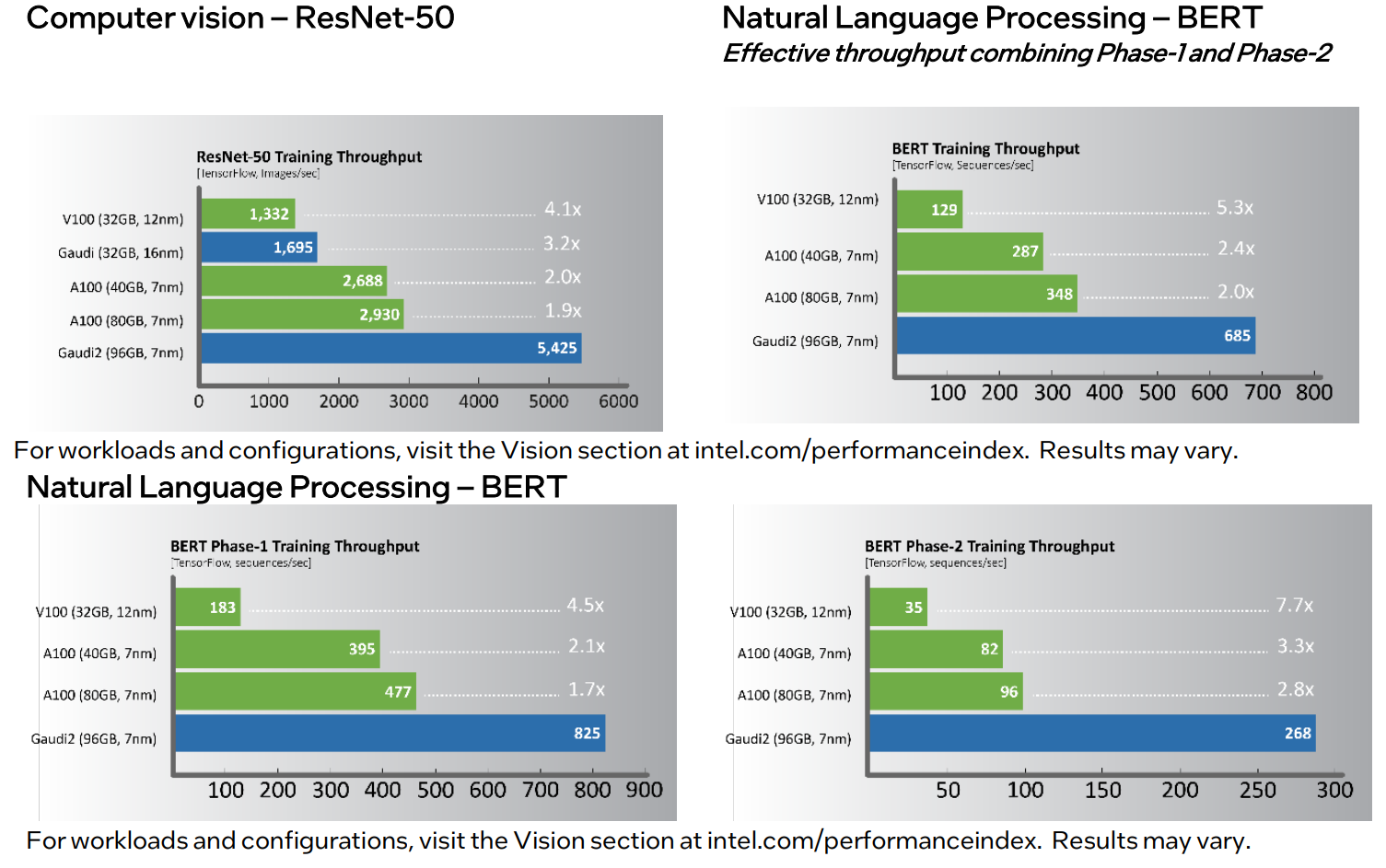 Gaudi2 уже доступны клиентам Habana, а несколько тысяч ускорителей используются самой Intel для дальнейшей оптимизации ПО и разработки чипов Gaudi3. Greco будут доступны во втором полугодии, а их массовое производство намечено на I квартал 2023 года, так что информации о них пока немного. Например, сообщается, что ускорители стали намного менее прожорливыми по сравнению с Goya и снизили TDP с 200 до 75 Вт. Это позволило упаковать их в стандартную HHHL-карту расширения с интерфейсом PCIe 4.0 x8.  Объём набортной памяти всё так же равен 16 Гбайт, но переход от DDR4 к LPDDR5 позволил впятеро повысить пропускную способность — с 40 до 204 Гбайт/с. Зато у самого чипа теперь 128 Мбайт SRAM, а не 40 как у Goya. Он поддерживает форматы BF16, FP16, (U)INT8 и (U)INT4. На борту имеются кодеки HEVC, H.264, JPEG и P-JPEG. Для работы с Greco предлагается тот же стек SynapseAI. Сравнения производительности новинки с другими инференс-решениями компания не предоставила.  Впрочем, оба решения Habana выглядят несколько запоздалыми. В отставании на ИИ-фронте, вероятно, отчасти «виновата» неудачная ставка на решения Nervana — на смену так и не вышедшим ускорителям NNP-T для обучения пришли как раз решения Habana, да и новых инференс-чипов NNP-I ждать не стоит. Тем не менее, судьба Habana даже внутри Intel не выглядит безоблачной, поскольку её решениям придётся конкурировать с серверными ускорителями Xe, а в случае инференс-систем даже с Xeon. |
|