Материалы по тегу: instinct
|
21.12.2023 [14:51], Сергей Карасёв
Германия построит суперкомпьютер Herder экзафлопсного уровняЦентр высокопроизводительных вычислений HLRS в Штутгарте (Германия) объявил о заключении соглашения с компанией HPE по созданию двух новых суперкомпьютеров — систем Hunter и Herder. Они, как утверждается, предоставят «инфраструктуру мирового класса» для моделирования, ИИ, анализа данных и других ресурсоёмких задач в различных областях. Hunter заменит нынешний флагманский суперкомпьютер HLRS под названием Hawk. В основу Hunter ляжет платформа HPE Cray EX4000: в общей сложности планируется задействовать 136 таких узлов, каждый из которых будет оснащён четырьмя адаптерами HPE Slingshot. Архитектура Hunter предусматривает применение СХД нового поколения Cray ClusterStor, специально разработанной с учётом жёстких требований к вводу/выводу. Кроме того, будет задействована среда HPE Cray Programming Environment, которая предоставляет полный набор инструментов для разработки, портирования, отладки и настройки приложений. 
Источник изображения: HLRS Суперкомпьютер Hunter получит ускорители AMD Instinct MI300A. Утверждается, что это позволит сократить энергопотребление по сравнению с Hawk примерно на 80 % при пиковой производительности. Быстродействие Hunter составит около 39 Пфлопс против 26 Пфлопс у Hawk. Систему планируется ввести в эксплуатацию в 2025 году. Суперкомпьютер экзафлопсного класса Herder заработает не ранее 2027 года. Архитектура предусматривает применение ускорителей, но окончательная конфигурация комплекса будет определена только к концу 2025-го. 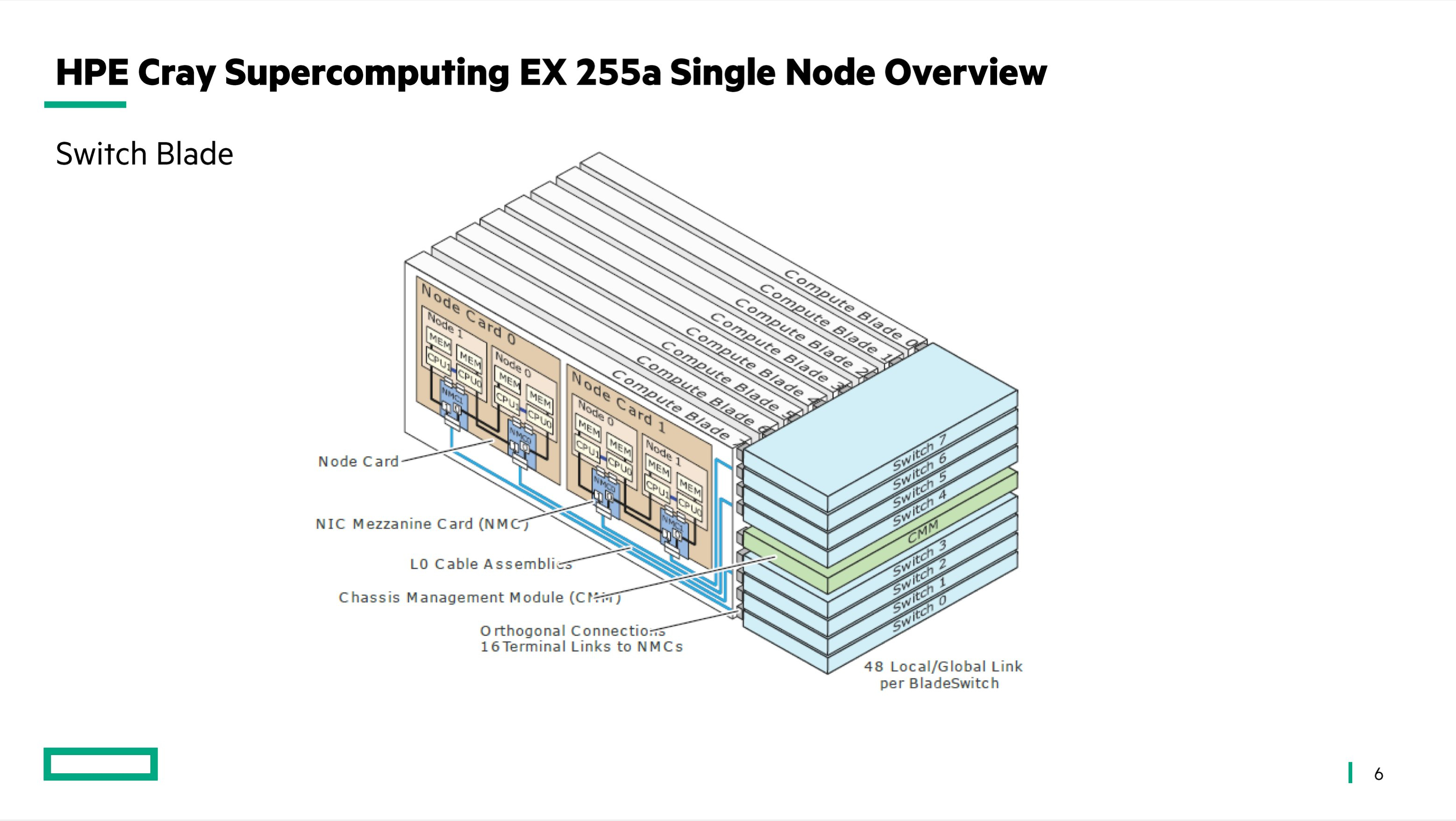
Источник изображения: HPE Общая стоимость Hunter и Herder оценивается в €115 млн. Финансирование будет осуществляться через Центр суперкомпьютеров Гаусса (GCS), альянс трёх национальных суперкомпьютерных центров Германии. Половину средств предоставит Федеральное министерство образования и исследований Германии (BMBF), оставшуюся часть — Министерство науки, исследований и искусств земли Баден-Вюртемберг. Нужно отметить, что в 2024 году в Юлихском исследовательском центре (FZJ) в Германии заработает вычислительный комплекс Jupiter — первый европейский суперкомпьютер экзафлопсного класса. Кроме того, систему такого уровня намерена создать Великобритания.
09.12.2023 [23:16], Сергей Карасёв
Supermicro представила ИИ-серверы с ускорителями AMD Instinct MI300 и СЖОКомпания Supermicro анонсировала серверы AS-8125GS-TNMR2, AS-4145GH-TNMR и AS-2145GH-TNMR, предназначенные для задач НРС и ИИ, в том числе для обучения больших языковых моделей (LLM). Новинки выполнены на аппаратной платформе AMD и оборудованы ускорителями серии Instinct MI300. Модель AS-8125GS-TNMR2 соответствует типоразмеру 8U. Она оснащена двумя процессорами AMD EPYC Genoa с показателем TDP до 400 Вт и восемью ускорителями Instinct MI300X со 192 Гбайт памяти HBM3. Объём оперативной памяти DDR5-4800 RDIMM/LRDIMM может достигать 6 Тбайт (24 слота). Доступны 18 отсеков для SFF-накопителей NVMe/SATA и коннектор M.2 NVMe. Предусмотрены восемь слотов для карт PCIe 5.0 x16 LP и два слота для карт PCIe 5.0 x16 FHFL. Задействована система воздушного охлаждения. Питание обеспечивают шесть или восемь блоков мощностью 3000 Вт с сертификатом 80 Plus Titanium. 
Источник изображений: Supermicro Серверы AS-4145GH-TNMR и AS-2145GH-TNMR выполнены в форм-факторе 4U и 2U соответственно. Первый наделён системой воздушного охлаждения, второй — жидкостного. При этом оба получили четыре чипа Instinct MI300A (24 ядра EPYC Genoa, ускоритель CDNA 3 и 128 Гбайт памяти HBM3). Устройство AS-4145GH-TNMR располагает 24 отсеками для накопителей SFF NVMe/SAS/SATA с возможностью горячей замены и двумя разъёмами для модулей M.2 NVMe или SATA. Есть шесть слотов PCIe 5.0 x16 FHHL и два разъёма PCIe 5.0 x16 AIOM. Задействованы четыре блока питания на 1600 Вт с сертификатом 80 Plus Titanium.  Сервер AS-2145GH-TNMR получил восемь посадочных мест для накопителей SFF NVMe/SAS/SATA и два разъёма для SSD M.2 NVMe или SATA. Доступны четыре слота PCIe 5.0 x16 FHHL и два слота PCIe 5.0 x16 AIOM. За питание отвечают четыре блока на 1600 Вт с сертификатом 80 Plus Titanium.
08.12.2023 [16:31], Сергей Карасёв
Gigabyte представила серверы с ускорителями AMD Instinct MI300 для задач ИИ и HPCКомпания Giga Computing (Gigabyte) анонсировала серверы G383-R80, G593-ZX1 и G593-ZX2 на аппаратной платформе AMD, предназначенные для решения ресурсоёмких задач: это могут быть приложения ИИ и HPC. Все новинки оборудованы ускорителями серии Instinct MI300. Модель G383-R80, выполненная в формате 3U, несёт на борту четыре чипа Instinct MI300A (24 ядра EPYC Genoa, ускоритель CDNA 3 и 128 Гбайт памяти HBM3). Во фронтальной части расположены 8 отсеков для SFF-накопителей NVMe SSD. 
Источник изображений: Gigabyte Могут быть задействованы до 12 слотов расширения для карт FHFL с интерфейсом PCIe 5.0. Есть слот для SSD стандарта М.2 2280/22110 с интерфейсом PCIe 5.0 x4, два сетевых порта 10GbE (Broadcom BCM57416), выделенный порт управления 1GbE, контроллер Aspeed AST2600, два порта USB 3.2 Gen1 и разъём D-Sub. Питание обеспечивают четыре блока мощностью 2200 Вт каждый с сертификатом 80 Plus Titanium. Серверы G593-ZX1 и G593-ZX2, в свою очередь, имеют типоразмер 5U. Они комплектуются двумя процессорами AMD EPYC Genoa с показателем TDP до 300 Вт и восемью ускорителями Instinct MI300X OAM со 192 Гбайт памяти HBM3. Для модулей ОЗУ стандарта DDR5-4800 доступны 24 разъёма. Спереди находятся восемь отсеков для SFF-накопителей NVMe SSD.  Эти серверы оборудованы двумя слотами для SSD формата М.2 2280/22110 с интерфейсом PCIe 3.0 (по одному х1 и х4), двумя портами 10GbE (Intel X710-AT2), выделенным сетевым портом управления 1GbE, контроллером Aspeed AST2600, двумя портами USB 3.2 Gen1 и разъёмом D-Sub. Предусмотрены четыре слота PCIe 5.0 x16 для карт FHHL и восемь слотов PCIe 5.0 x16 для LP-карт. Версия G593-ZX1 получила восемь root-портов, модель G593-ZX2 — четыре. Установлены шесть блоков питания на 3000 Вт с сертификатом 80 Plus Titanium.
07.12.2023 [23:02], Владимир Мироненко
Dell выпустит серверы с ИИ-ускорителями AMD Instinct MI300XDell и AMD объявили о расширении портфеля решений Dell Generative AI Solutions с целью ускорения обработки сложных рабочих нагрузок и предоставления компаниям больше возможностей для развёртывания приложений генеративного ИИ. Новые решения включают серверы Dell PowerEdge XE9680 с ускорителями AMD Instinct MI300X. Сервер будет оснащён восемью ускорителями, что даст общую ёмкость HBM3 1,5 Тбайт и FP16-производительность более 10 Пфлопс. Использование PowerEdge XE9680 с MI300X позволит компаниям сократить занимаемую площадь в ЦОД, снизить совокупную стоимость владения и получить конкурентное преимущество, говорит Dell. Для масштабирования нагрузок компания предлагет Ethernet-фабрику с 400G-коммутаторами PowerSwitch Z9664F-ON. PowerEdge XE9680 поставляется с приложением Dell OpenManage Enterprise для администрирования и мониторинга систем. Также сообщается, что сервер обеспечивает высокую защищённость данных благодаря интегрированной киберзащите и использованию концепции Zero Trust. 
Источник изображения: Dell Dell также пополнила платформу Dell Generative AI Solutions решением Dell Validated Design for Generative AI with AMD, которое упрощает надёжное развёртывание генеративного ИИ. Его выход ожидается в следующем году с ИИ-платформами на базе AMD ROCm и открытых больших языковых моделей (LLM). Dell PowerEdge XE9680 с ускорителями AMD Instinct MI300X и Dell Validated Design for Generative AI with AMD появится на рынке в I половине 2024 года.
07.12.2023 [16:54], Сергей Карасёв
GigaIO создаст уникальное ИИ-облако с тысячами ускорителей AMD Instinct MI300XКомпания GigaIO объявила о заключении соглашения по созданию инфраструктуры для специализированного ИИ-облака TensorNODE, которое создаётся провайдером TensorWave. В составе платформы будут применяться ускорители AMD Instinct MI300X, оснащённые 192 Гбайт памяти HBM3. Основой TensorNODE послужат мини-кластеры SuperNODE, дебютировавшие летом уходящего года. Особенность этого решения заключается в том, что оно позволяет связать воедино 32 и даже 64 ускорителя посредством распределённого интерконнекта на базе PCI Express. TensorWave будет использовать FabreX для формирования пулов памяти петабайтного масштаба. На первом этапе в начале 2024 года платформа TensorNODE объединит до 5760 ускорителей Instinct MI300X в одном домене. Таким образом, при решении сложных задач можно будет получить доступ более чем к 1 Пбайт памяти с любого узла. Это, как отмечается, позволит обрабатывать даже самые ресурсоёмкие нагрузки в рекордно короткие сроки. 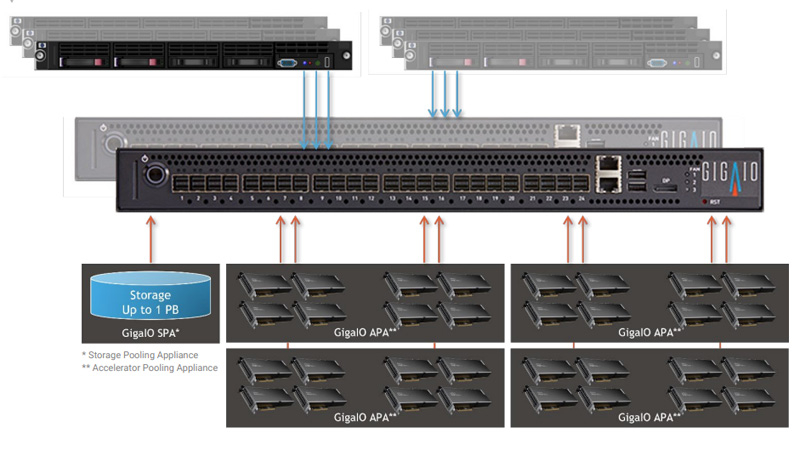
Источник изображения: GigaIO В течение следующего года планируется развернуть несколько систем TensorNODE. Архитектура GigaIO обеспечит улучшенную гибкость по сравнению с традиционными решениями: инфраструктуру можно будет оптимизировать «на лету» для удовлетворения как текущих, так и будущих потребностей в области ИИ и больших языковых моделей (LLM). Отмечается, что TensorNODE полностью базируется на ключевых компонентах AMD. Помимо ускорителей Instinct MI300X, это процессоры EPYC Genoa. Облако TensorWave обеспечит снижение энергозатрат и общей стоимости владения благодаря исключению из конфигурации избыточных серверов и связанного с ними сетевого оборудования.
16.11.2023 [15:29], Сергей Карасёв
В Microsoft Azure появились инстансы ND MI300X v5 с восемью ускорителями AMD Instinct и процессорами Intel XeonКомпания Microsoft анонсировала инстансы Azure ND MI300X v5 на основе ускорителей AMD Instinct MI300X, представленных летом нынешнего года. Эти ВМ ориентированы на ресурсоёмкие ИИ-нагрузки, в частности, на решение задач инференса. Изделия Instinct MI300X несут на борту 192 Гбайт памяти HBM3 с пропускной способностью до 5,2 Тбайт/с. В составе одной виртуальной машины ND MI300X v5 объединены восемь ускорителей, соединённых между собой посредством Infinity Fabric 3.0, а с хостом — по PCIe 5.0. В сумме это даёт 1,5 Тбайт памяти HBM3, что, как отмечает Microsoft, является самой большой ёмкостью HBM, доступной в облаке. Виртуальные машины Azure ND — это дополнение к семейству решений на базе GPU, такие машины специально предназначены для рабочих нагрузок ИИ и глубокого обучения. Microsoft подчёркивает, что в случае ND MI300X v5 используется та же аппаратная платформа, которая применяется и для других ВМ семейства. Она включает процессоры Intel Xeon Sapphire Rapids, 16 каналов оперативной памяти DDR5, а также подключение NVIDIA Quantum-2 CX7 InfiniBand с пропускной способностью 400 Гбит/с на каждый ускоритель и 3,2 Тбит/с на виртуальную машину. 
Источник изображения: AMD По заявлениям Microsoft, на базе ND MI300X v5 могут запускаться самые крупные модели ИИ. Клиенты могут быстро перейти на новые инстансы с других решений серии ND благодаря тому, что открытая платформа AMD ROCm содержит все библиотеки, компиляторы, среды выполнения и инструменты, необходимые для ускорения ресурсоемких приложений.
15.11.2023 [13:57], Сергей Карасёв
Французский суперкомпьютер Adastra одним из первых получит новейшие ускорители AMD Instinct MI300AФранцузское национальное агентство по высокопроизводительным вычислениям (GENCI), по сообщению HPCwire, проводит масштабное обновление суперкомпьютера Adastra, о запуске которого было объявлено два года назад. После апгрейда система сможет решать сложные задачи в области ИИ. Комплекс Adastra находится под управлением Национального вычислительного центра высшего образования Франции (CINES). Система использует платформу HPE Cray EX235A с оптимизированными процессорами AMD EPYC Milan (64 ядра; 2,0 ГГц) и ускорителями AMD Instinct MI250X. Апгрейд предусматривает использование гибридных чипов Instinct MI300A в составе платформы HPE Cray EX4000, оснащённой 14 серверами HPE Cray EX255a Accelerator Blade. В общей сложности будут задействованы 28 узлов, каждый из которых содержит четыре чипа Instinct MI300A. Таким образом, суммарное количество использованных изделий Instinct MI300A равно 112. Задействован 200G-интерконнект HPE Slingshot 11. Об итоговой производительности обновлённого суперкомпьютера Adastra данных пока нет. Но в прежнем виде система занимает 17-ю строку в ноябрьском рейтинге TOP500 с быстродействием 46,1 Пфлопс (FP64). А в мировом рейтинге самых энергоэффективных НРС-систем GREEN500 комплекс Adastra находится на третьей позиции с показателем 58,021 Гфлопс/Вт. 
Изображение: GENCI
22.10.2023 [14:06], Сергей Карасёв
Видео дня: строительство 2-Эфлопс суперкомпьютера El CapitanЛиверморская национальная лаборатория им. Э. Лоуренса (LLNL) Министерства энергетики США опубликовала видео (см. ниже), демонстрирующее процесс сборки вычислительного комплекса El Capitan, которому предстоит стать самым мощным суперкомпьютером мира. В текущем рейтинге TOP500 лидирует система Frontier, установленная в Национальной лаборатории Окриджа (ORNL), также принадлежащей Министерству энергетики США. Быстродействие Frontier достигает 1,194 Эфлопс. Суперкомпьютер El Capitan сможет демонстрировать производительность более 2 Эфлопс (FP64). Сборка комплекса началась в июле нынешнего года, а ввод в эксплуатацию запланирован на середину 2024-го. Стоимость проекта оценивается приблизительно в $600 млн. В основе El Capitan — платформа HPE Cray Shasta. Применена гибридная архитектура AMD с APU Instinct MI300A: изделие содержит 24 ядра с микроархитектурой Zen 4 общего назначения, блоки CDNA 3 и 128 Гбайт памяти HBM3. 
Источник изображения: LLNL Отмечается, что в проекте El Capitan задействованы сотни сотрудников LLNL и отраслевых партнёров. Суперкомпьютер состоит из тысяч вычислительных узлов и требует столько же энергии, сколько город среднего размера. В течение нескольких лет специалисты готовили инфраструктуру для El Capitan, создавая подсистемы электропитания и охлаждения, устанавливая компоненты и монтируя сетевые соединения. После запуска суперкомпьютер будет использоваться для решения задач в сферах ядерной энергетики, национальной безопасности, здравоохранения, изменений климата и пр.
23.03.2022 [01:10], Алексей Степин
Анонсирован ускоритель AMD Instinct MI210: половинка MI250 в форм-факторе PCIe-картыAMD продолжает активно осваивать рынок ускорителей и ИИ-сопроцессоров. Вслед за сверхмощными Instinct MI250 и MI250X, анонсированными ещё осенью прошлого года, «красные» представили новинку — ускоритель Instinct MI210. Это менее мощная, одночиповая версия ускорителя с архитектурой CDNA 2, дополняющая семейство MI200 и имеющая более универсальный форм-фактор PCIe-карты. Если Instinct MI250/250X существует только как OAM-модуль, то новый Instinct MI210 имеет вид обычной платы расширения с разъёмом PCI Express 4.0. Это неудивительно, ведь MI250 физически невозможно уложить в тепловые и энергетические рамки, обеспечиваемые таким форм-фактором, поскольку два чипа Aldebaran требуют 560 Вт против привычных для PCIe-плат 300 Вт. Для питания MI210 используется как слот PCIe, так и 8-контактный разъём EPS12V.  Поскольку ускоритель на борту новинки только один, она вдвое уступает MI250/250X по всем параметрам, но всё равно обеспечивает весьма неплохую производительность во всех форматах вычислений. Стоит отметить, что функциональные возможности MI210 не уменьшились. Осталась, например, поддержка Infinity Fabric 3.0 — соответствующие разъёмы расположены в верхней части карты, и она поддерживает работу в кластерном режиме из двух или четырёх ускорителей. 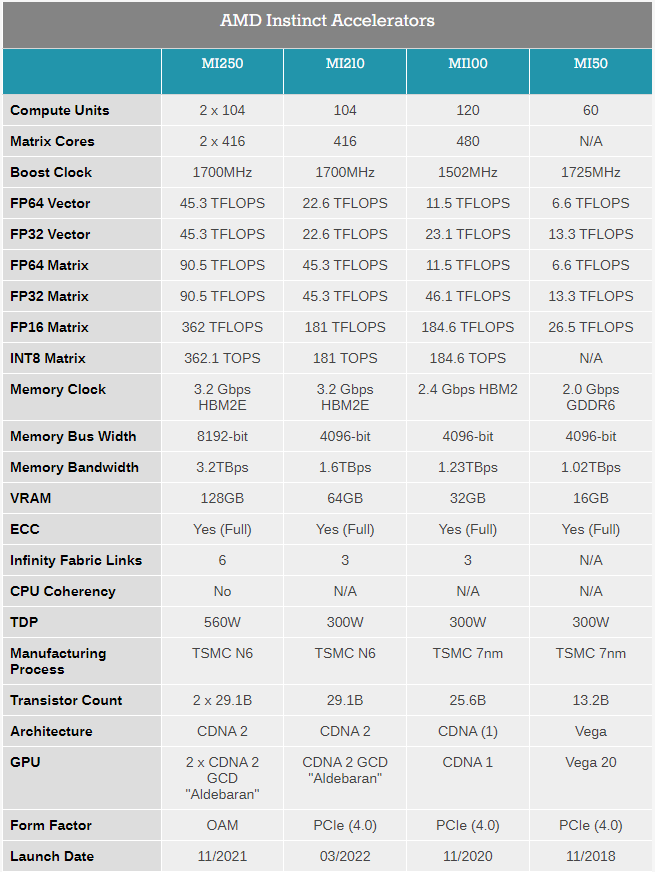
Таблица опубликована AnandTech В MI210 используется более простой вариант Aldebaran с одним кристаллом. Что интересно, по количеству вычислительных блоков этот вариант уступает более старому MI100 (104 CU против 120, 416 матричных ядер против 480). Однако последний использует первую итерацию архитектуры CDNA и работает на меньшей частоте — 1500 против 1700 МГц у новинки. В некоторых форматах вычислений MI100 может быть быстрее, но разница крайне незначительна. 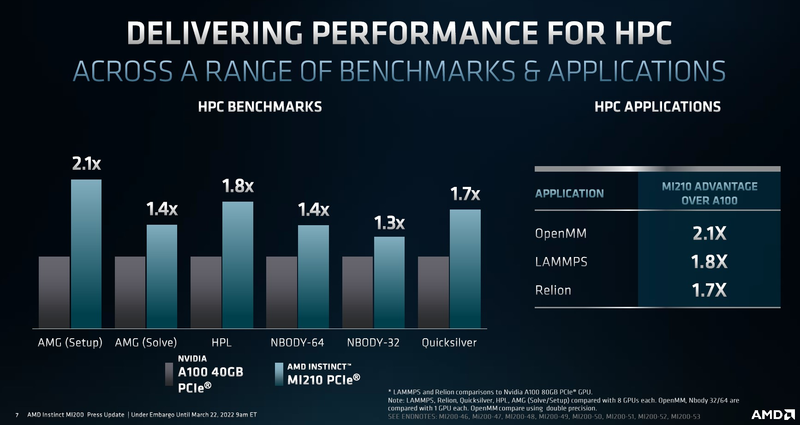
Производительность AMD Instinct MI210 в сравнении с NVIDIA A100 40GB PCIe CDNA2 позволяет использовать уникальные форматы данных, вроде packed FP32, однако это требует поддержки со стороны разработчиков, что несколько затруднит создание универсального ПО, способного полностью задействовать возможности MI210. Но в первую очередь, это ускоритель, не «зажимающий» FP64-производительность: свыше 22 Тфлопс в векторных операциях и 45 Тфлопс — в матричных. Сервер с одним или несколькими MI210 может использоваться в качестве универсальной платформы разработки ПО для суперкомпьютеров на базе более мощных ускорителей AMD Instinct MI250/250X. Новинка уже доступна у традиционных партнёров AMD по выпуску серверов, включая ASUS, Dell, HPE, Supermicro и Lenovo, которые также предлагают более мощные решения на базе MI250/250X.
08.11.2021 [20:00], Игорь Осколков
AMD анонсировала Instinct MI200, самые быстрые в мире ускорители вычислений на базе CDNA 2В прошлом году AMD окончательно развела ускорители для графики и вычислений, представив Instinct MI100, первый продукт на базе архитектуры CDNA, который позволил компании противостоять NVIDIA. Теперь же AMD подготовила новую версию архитектуры CDNA 2 и ускорители MI200 на неё основе. Новинки, согласно внутренним тестам, в ряде задач на голову выше того, что сейчас может предложить NVIDIA. 
AMD Instinct MI200 в OAM-варианте (Здесь и ниже изображения AMD) Циркулировавшие ранее слухи оказались верны — MI200 являются двухчиповыми решениями с 2.5D-упаковкой кристаллов (GCD) самих ускорителей, четырёх линий Infinity Fabric между ними и восьми стеков памяти HBM2e (8192 бит, 1600 МГц, 128 Гбайт, 3,2 Тбайт/c). В данном случае используется мостик EFB (Elevated Fanout Bridge), который позволяет задействовать стандартные подложки, что удешевляет и упрощает производство и тестирование ускорителей, не потеряв при этом в производительности и, что важнее, без существенного увеличения задержек в обмене данными. 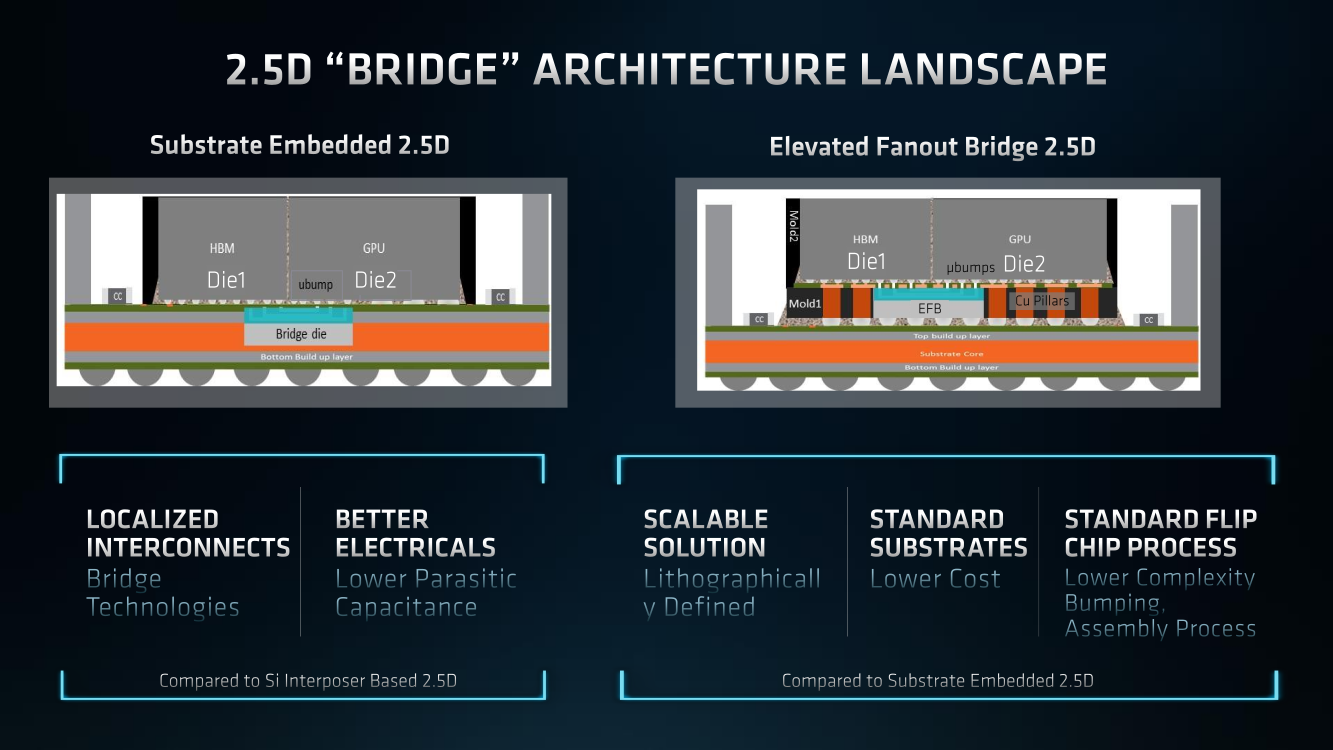 Несмотря на то, что в составе ускорителя два GCD, системе они представляются как единое целое с общей же памятью. Каждый GCD в случае CDNA 2 включает 112 CU (Compute Unit), но в конечных продуктах они задействованы не все. CU разбиты на четыре группы (с индивидуальным планировщиком) с общим L2-кешем объёмом 8 Мбайт и пропускной способностью 6,96 Тбайт/с, который поделён на 32 отдельных блока. А сами блоки имеют индивидуальные подключения к контроллерам памяти в GCD.  Важное отличие CDNA 2 заключается в «подтягивании» производительности векторных FP64- и FP32-вычислений — они исполняются с одинаковой скоростью в отличие от CDNA первого поколения. Кроме того, появилась поддержка сжатых (packed) инструкций для операций FMA/FADD/FMUL для FP32-векторов. Второй крупный апдейт касается матричных вычислений. Для них теперь тоже есть отдельная поддержка FP64, и с той же производительностью, что и для FP32. Новые инструкции рассчитаны на блоки 16×16×4 и 4×4×4. 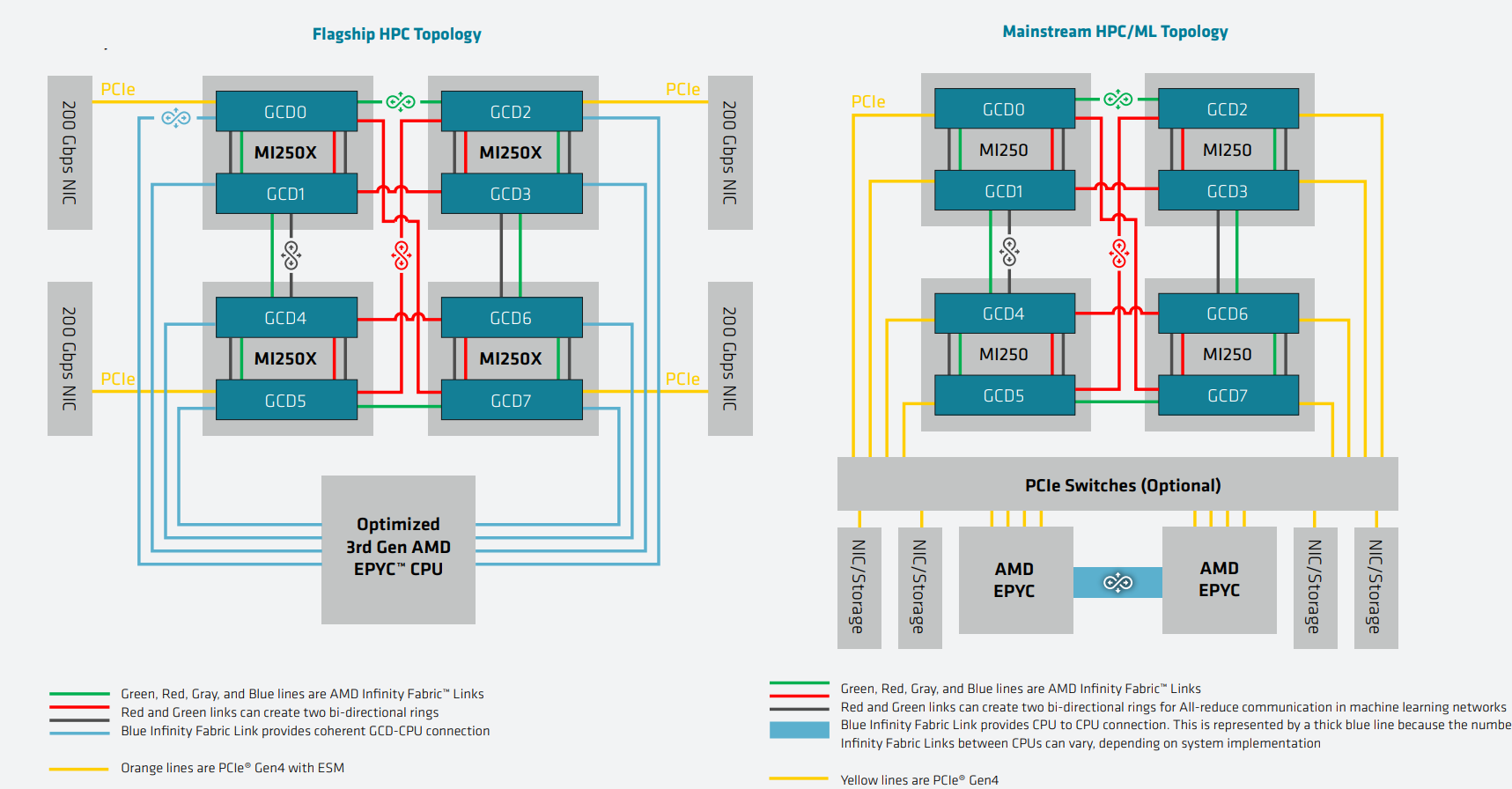 Поддержка FP16/BF16 в матричных ядрах, конечно, тоже есть, что позволяет задействовать их и для ИИ-задач, а не только HPC. Подспорьем для них в некоторых задачах будут два блока VCN (Video Codec Next) в каждом GCD. Они поддерживают декодирование H.264/AVC, H.265/HEVC, VP9 и JPEG, а также кодирование H.264/H.265, что потенциально позволит более эффективно работать ИИ-алгоритмам с изображениями и/или видео. 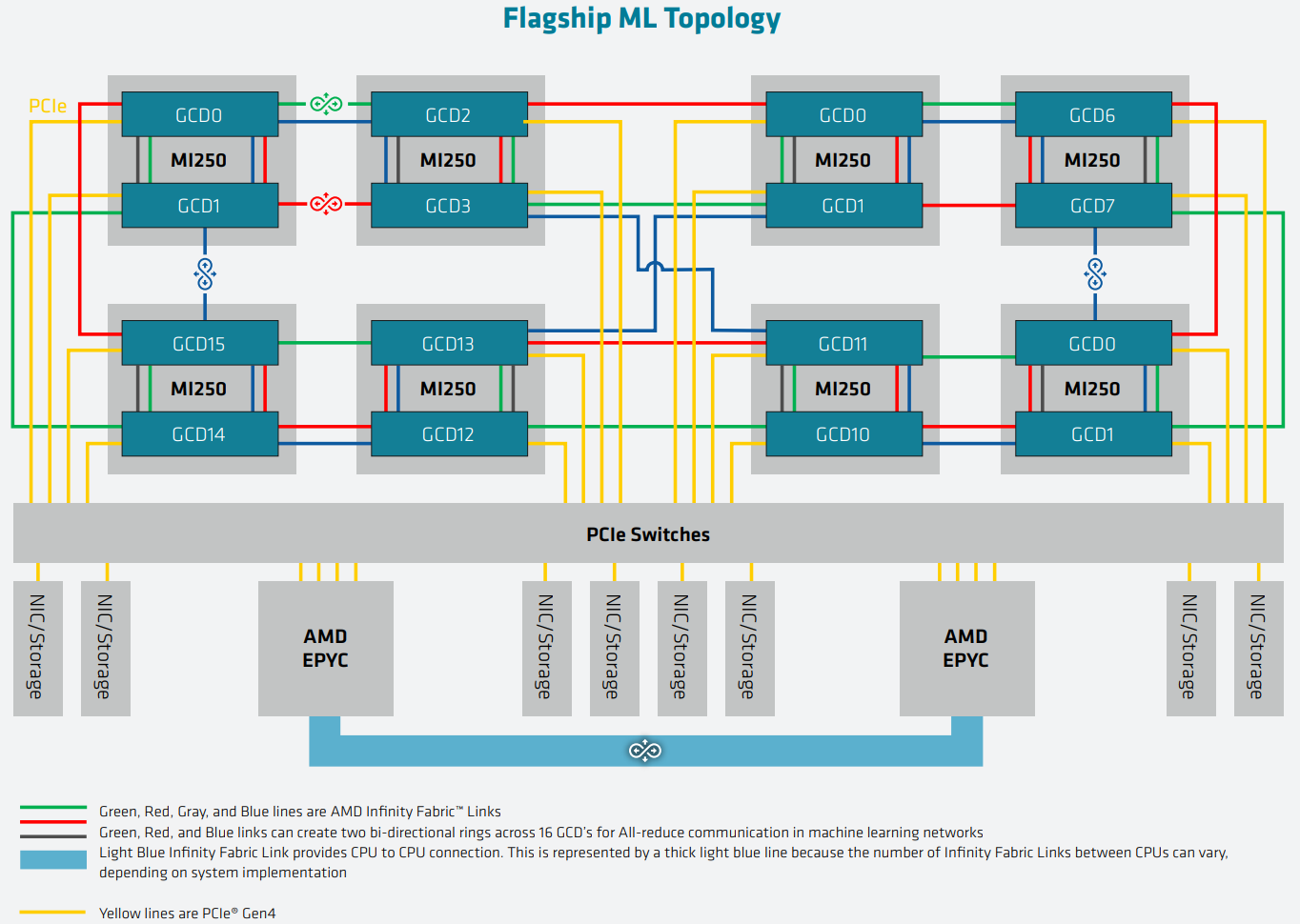 Для обмена данными между ускорителями и CPU используется единая шина Infinity Fabric (IF) с поддержкой кеш-когерентности. Всего на ускоритель приходится до восьми внешних линий IF, а суммарная скорость обмена данными может достигать 800 Гбайт/c. В наиболее плотной компоновке из четырёх MI200 и одного EPYC каждый ускоритель имеет по две линии для связи с CPU и со своим соседом. Причём внутренние и внешние IF-линии образуют два двунаправленных кольца между ускорителями. Каждая IF-линия опирается на x16-подключение PCIe 4.0, но в данном случае есть ряд оптимизаций конкретно под HPC-системы HPE Cray.  Дополнительно у каждого ускорителя есть собственный root-комплекс, что позволяет напрямую подключить сетевой адаптер класса 200G. И это явный намёк на возможность непосредственного RDMA-соединения с внешними хранилищами, поскольку в такой схеме на локальные NVMe-накопители линий попросту не остаётся. Более простые топологии уже предполагают использование половины линий IF в качестве обычного PCIe-подключения и задействуют коммутатор(-ы) для связи с CPU и NIC. В этом случае IF-подключение остаётся только между процессорами. Зато в одной системе можно объединить восемь MI200.  Чипы ускорителей MI250X изготовлены по 6-нм техпроцессу FinFet, содержат 58 млрд транзисторов и предлагают 220 CU, включающих 880 ядер для матричных вычислений и 14080 шейдерных ядер второго поколения. У MI250 их 208, 832 и 13312 соответственно. Для обеих моделей уровень TDP составляет 500 или 560 Вт, поэтому поддерживается как воздушное, так и жидкостное охлаждение. В дополнение к OAM-версиям MI250(X) чуть позже появится и более традиционная PCIe-модель MI210.  Для сравнения — у NVIDIA A100 объём и пропускная способность памяти (тоже HBM2e) составляют до 80 Гбайт и 2 Тбайт/с соответственно. Шина же NVLink 3.0 имеет пропускную способность 600 Гбайт/c, а коммутатор NVSwitch для связи между восемью ускорителями — 1,8 Тбайт/с. Потребление SXM3-версии составляет 400 Вт. Стоит также отметить, что первая версия A100 появилась ещё весной 2020 года, и скоро ожидается анонс следующего поколения ускорителей на базе архитектуры Hopper. На носу и выход ускорителей Intel Xe Ponte Vecchio.  И если про первые мы пока ничего толком не знаем, то вторые, похоже, уже проиграли MI250X в «голой» производительности как минимум по одной позиции (FP32). AMD говорит, что создавала Instinct MI200 как серию универсальных ускорителей, пригодных и для «классических» HPC-задач, и для ИИ. Отсюда и практически пятикратная разница в пиковой FP64-производительности с NVIDIA A100. 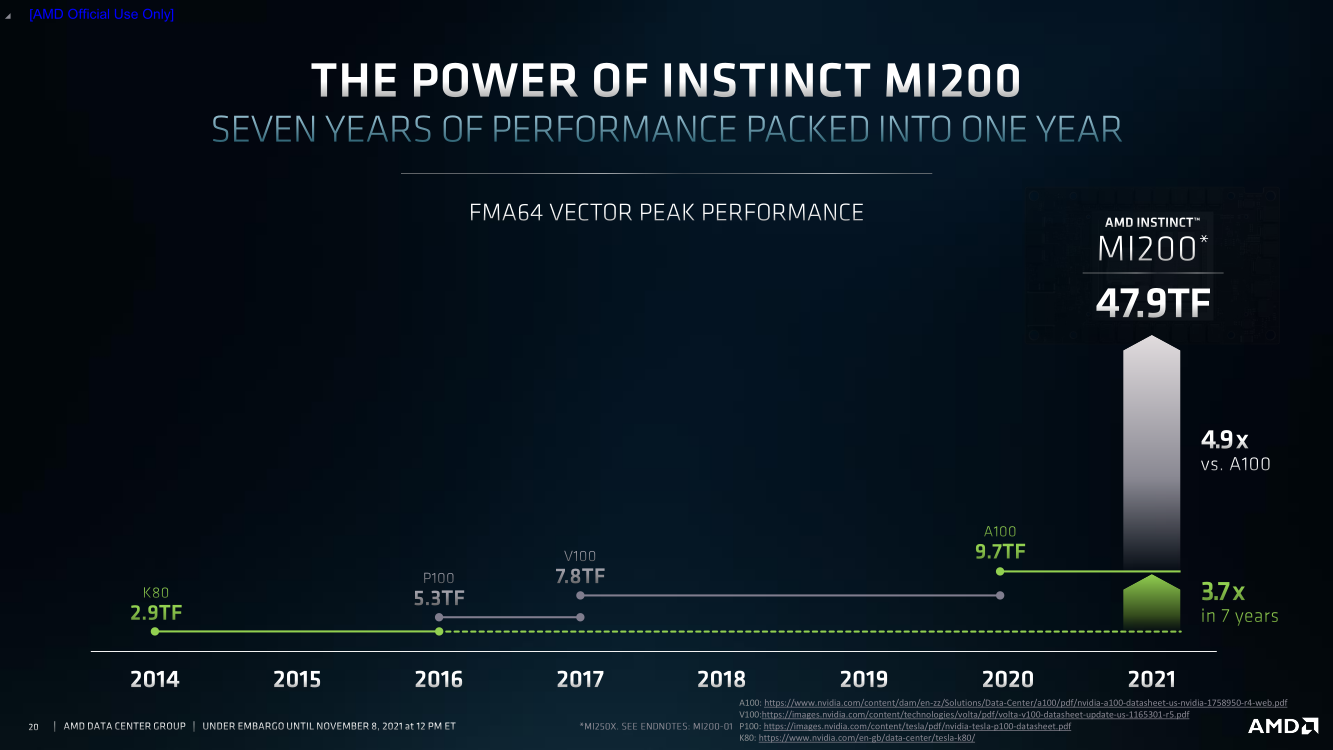 Но вот с нейронками всё не так однозначно. Предпочтительным форматом для обучения у NVIDIA является собственный TF32, поддержка которого есть в Tensor-ядрах Ampere. Ядра для матричных вычислений в CDNA2 про него ничего не знают, поэтому сравнить производительность в лоб нельзя. Разница в BF16/FP16 между MI250X и A100 уже не так велика, так что AMD говорит о приросте в 1,2 раза для обучения со смешанной точностью. 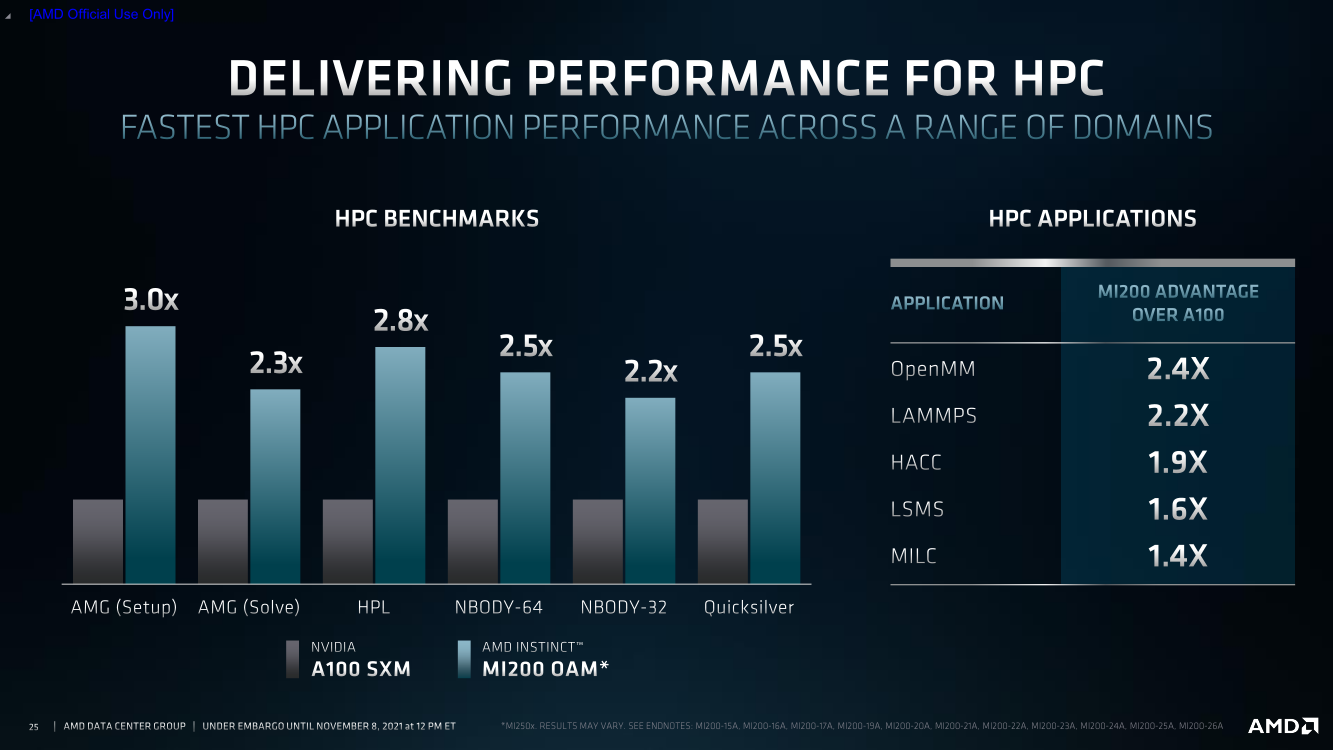 Данные по INT8 и INT4 в презентацию не вынесены, что неудивительно. Пиковый показатель для обоих форматов у MI250X составляет 383 Топс, тогда как тензорные ядра NVIDIA A100 выдают 624 и 1248 Топс соответственно. В данном случае больший объём памяти сыграл бы на руку MI200 в задачах инференса для крупных моделей. Наконец, у A100 есть ещё одно преимущество — поддержка MIG (Multi-Instance GPU), которая позволяет более эффективно задействовать имеющиеся ресурсы, особенно в облачных системах.  Вместе с Instinct MI200 была анонсирована и новая версия открытой (open source) платформы ROCm 5.0, которая обзавелась поддержкой и различными оптимизациями не только для этих ускорителей, но и, например, Radeon Pro W6800. В этом релизе компания уделит особое внимание расширению программной экосистемы и адаптации большего числа приложений. Кроме того, будет развиваться и новый портал Infinity Hub, где будет представлено больше готовых к использованию контейнеров с популярным ПО с рекомендациями по настройке и запуску.  AMD Instinct MI200 появятся в I квартале 2022 года. Новинки, в первую очередь MI210, будут доступны у крупных OEM/ODM-производителей: ASUS, Atos (X410-A5 2U1N2S), Dell Technologies, Gigabyte (G262-ZO0), HPE, Lenovo и Supermicro. Ускорители Instinct MI250X пока остаются эксклюзивом для систем HPE Cray Ex. Именно они вместе с «избранными» процессорами AMD EPYC (без уточнения, будут ли это Milan-X) станут основой для самого мощного в США суперкомпьютера Frontier.  Окончательный ввод в эксплуатацию этого комплекса запланирован на будущий год. Ожидается, что его пиковая производительность превысит 1,5 Эфлопс. При этом он должен стать самой энергоэффективной системой подобного класса. А адаптация ПО под него позволит несколько потеснить NVIDIA CUDA в некоторых областях. И это для AMD сейчас, пожалуй, гораздо важнее, чем победа по флопсам. |
|