Материалы по тегу: habana
|
12.04.2024 [21:28], Сергей Карасёв
Dell сумела сократить сроки поставок ИИ-серверов, но теперь компания полагается не только на ускорители NVIDIA, но и на Intel Gaudi3Компании Dell, по сообщению The Register, удалось сократить сроки поставок серверов для задач ИИ в несколько раз. Речь идёт о высокопроизводительных системах с ускорителями на основе GPU, в том числе NVIDIA H100. Спрос на них настолько высок, что производители не справляются с потоком заказов. О текущей ситуации в отрасли рассказал руководитель тайваньского подразделения Dell Теренс Ляо (Terence Liao). В конце 2023 года срок поставок серверов Dell, оборудованных ускорителями H100, составлял в среднем 39 недель, или около 8–9 месяцев. По словам Ляо, с февраля 2024-го отгрузки продукции NVIDIA значительно улучшились, и Dell смогла уменьшить сроки поставок серверов до 8–12 недель, или 2–3 месяцев. Таким образом, время выполнения заказов уменьшилось в три–четыре раза. Тем не менее, дефицит высокопроизводительных ИИ-ускорителей сохраняется. Связано это в том числе с возможностями TSMC по выпуску чипов с применением технологии CoWoS (Chip on Wafer on Substrate). Именно компоновка CoWoS применяется при изготовлении Н100. 
Источник изображения: NVIDIA В сентябре 2023 года спрос на передовые технологии упаковки чипов был настолько высоким, что TSMC заявила о способности удовлетворить только 80 % заказов. Вместе с тем TSMC сообщила о намерении расширить производственные мощности CoWoS на 20 % — это поможет смягчить проблему дефицита ИИ-ускорителей. Между тем Dell приходится искать альтернативы ускорителям NVIDIA. В частности, она намерена использовать ИИ-ускорители Intel Gaudi3. Поддержка Gaudi3 заявлена для сервера Dell XE9680, который также поддерживает ускорители AMD Instinct MI300X. Эта ИИ-платформа наделена 32 слотами для модулей памяти DDR5, восемью разъёмами PCIe 5.0 и шестью портами OSFP 800GbE. Возможна установка 16 накопителей EDSFF3.
10.04.2024 [22:45], Алексей Степин
Intel Gaudi3 готов бросить вызов ИИ-ускорителям NVIDIAС момента анонса ускорителей Intel Habana Gaudi2 минуло два года и всё это время они достойно сражались с решениями NVIDIA, хоть и уступая в чистой производительности, но нередко выигрывая по показателю быстродействия в пересчёте на доллар. Теперь пришло время нового поколения — корпорация Intel анонсировала выпуск чипов Gaudi3 и ускорителей на их основе. Новый ИИ-процессор Gaudi3 взял на вооружение 5-нм техпроцесс TSMC, а также получил чиплетную компоновку, которая, впрочем, на логическом уровне никак себя не проявляет — Gaudi3 с точки зрения хоста остаётся монолитным ускорителем. Был увеличен с 96 до 128 Гбайт объём набортной памяти, но это по-прежнему HBM2e в отличие от решений основного соперника, давно перешедшего на HBM3. 
Источник изображений здесь и далее: Intel Intel выступила с достаточно серьёзным заявлением о 50 % превосходстве новинки в инференс-сценариях над NVIDIA H100, а также о 40 % преимуществе в энергоэффективности при существенно меньшей стоимости. Звучит многообещающе, особенно на фоне сочетания высоких цен с дефицитом со стороны «зелёных».  Физически, как уже упоминалось, Gaudi3 состоит из двух одинаковых кристаллов, «сшитых» между собой быстрым низколатентным интерконнектом. Архитектурно чип подобен предшественнику и по-прежнему включает блоки матричной математики (MME) и кластеры программируемых тензорных процессоров (TPC), имеющих доступ к разделу быстрой памяти SRAM.  Однако в сравнении с Gaudi2 количество блоков серьёзно выросло: вместо 2 MME в составе Gaudi3 теперь 8 таких блоков, а число тензорных процессоров увеличилось с 24 до 64. Вдвое, то есть с 48 до 96 Мбайт, вырос объём SRAM, а её пропускная способность возросла с 6,4 Тбайт/с до 12,8 Тбайт/с. Логически Gaudi3 делится на ядра DCORE (Deep Learning Core), в состав каждого входит два движка MME, 16 тензорных ядер и 24 Мбайт кеша L2. 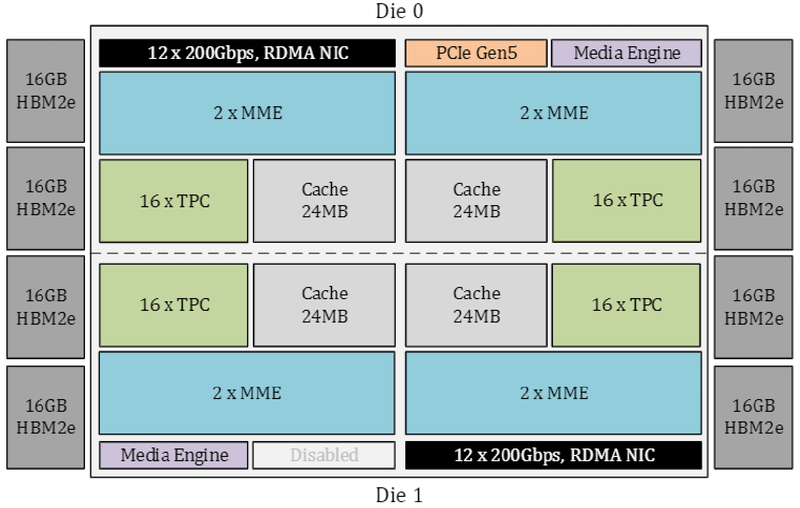
Блок-схема Gaudi3 Усилен также блок медиадвижков, их в новом чипе 14 против 8 у Gaudi2. Всё это не могло не сказаться на тепловыделении: несмотря на применение 5-нм техпроцесса теплопакет у флагманского варианта составляет целых 900 Вт, хотя в новом модельном ряду есть и не столь горячие версии с TDP 600 и 450 Вт. Последний вариант предназначен для экспорта в КНР. 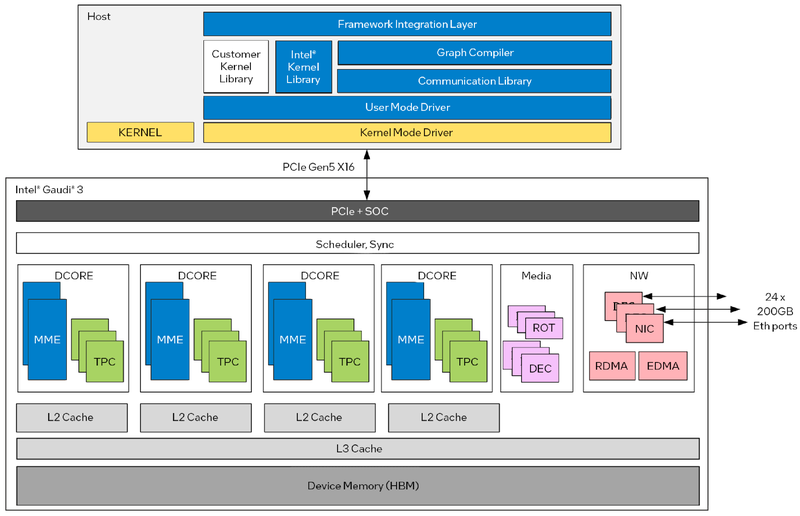
Архитектура Gaudi3 и его программная прослойка Поскольку объём HBM2e был увеличен с 96 до 128 Гбайт, в сборке используется не шесть, а восемь 16-Гбайт кристаллов, что позволило увеличить ПСП с 2,46 до 3,7 Тбайт/с. Работает память на частоте 3,6 ГГц. В составе Gaudi3 также имеется специализированный программируемый блок управления. Он отвечает за формирование очередей, управление прерываниями, синхронизацию, работу планировщика и имеет выход непосредственно на шину PCIe. 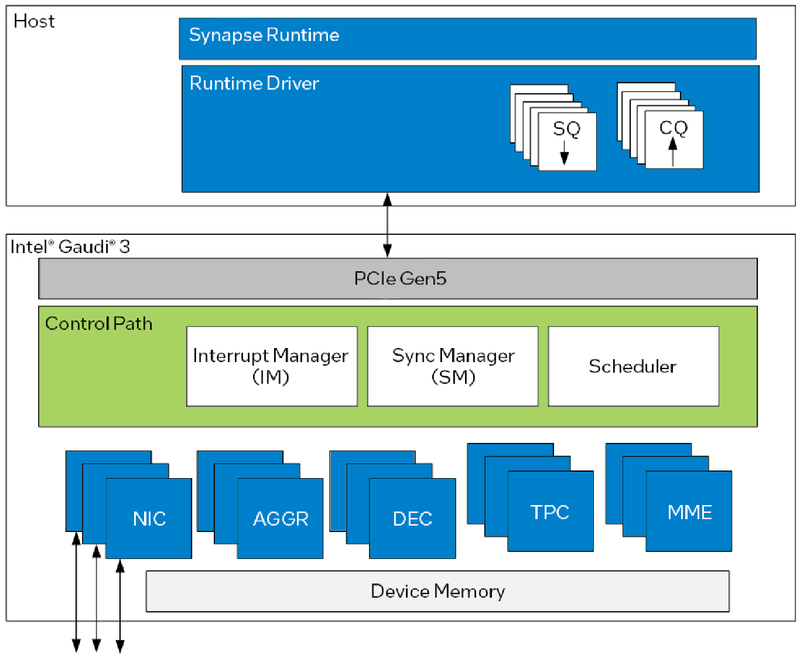
Управляющая подсистема (Control Path) Gaudi3 Сетевая часть всё ещё состоит из 24 контроллеров Ethernet (c RoCE), но появилась поддержка скорости 200 Гбит/с, а значит, вдвое возросла и совокупная производительность сети. Intel подчёркивает, что для масштабирования кластеров на базе Gaudi3 нужна обычная Ethernet-фабрика (а ещё лучше Ultra Ethernet) и нет никакой привязки к конкретному вендору, что является упрёком NVIDIA с её InfiniBand. Наконец, в качестве хост-интерфейса на смену PCI Express 4.0 пришёл PCI Express 5.0 (x16), что также означает подросшую с 64 до 128 Гбайт/с пропускную способность. 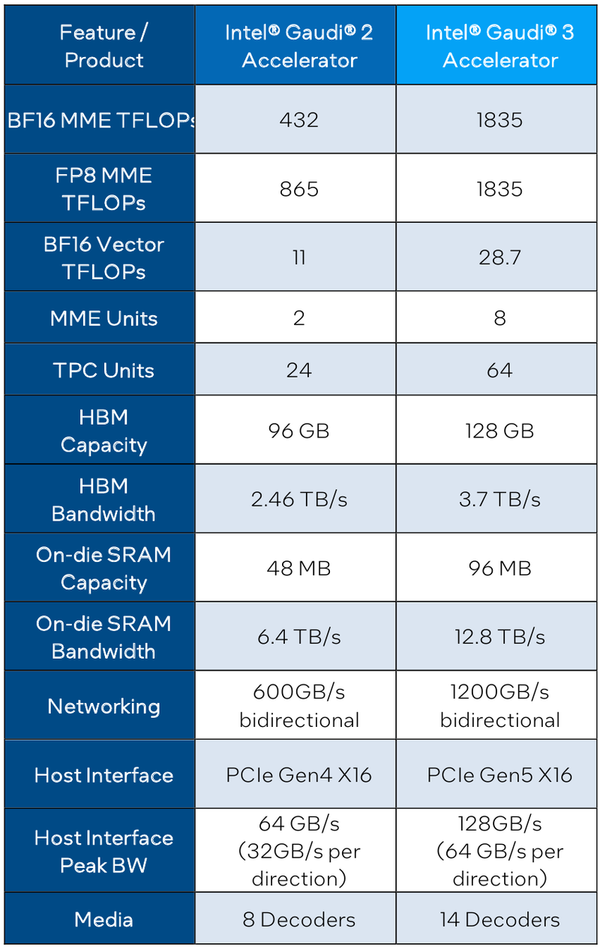
Сравнительные характеристики Gaudi2 и Gaudi3 Все эти улучшения позволяют Intel говорить о теоретической производительности в 2–4 раза более высокой, нежели было достигнуто в поколении Gaudi2. Наибольший прирост заявлен для операций с форматом BF16 на MME, что вполне закономерно, учитывая большее количество самих MME. 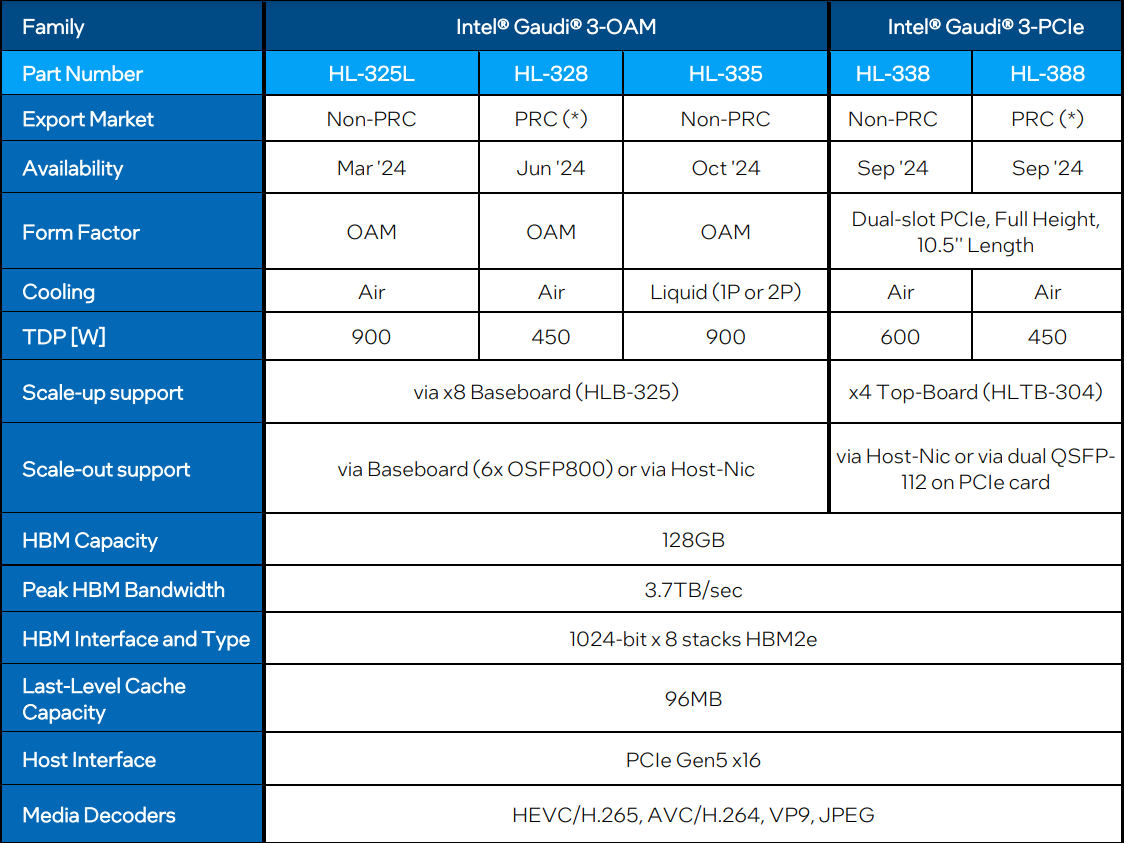 На практике результаты, демонстрируемые Gaudi3, выглядят также достаточно многообещающе: в тестах на обучение популярных нейросетей преимущество над Gaudi2 ни разу не составило менее 1,5x, а в отдельных случаях даже превысило 2,5x. 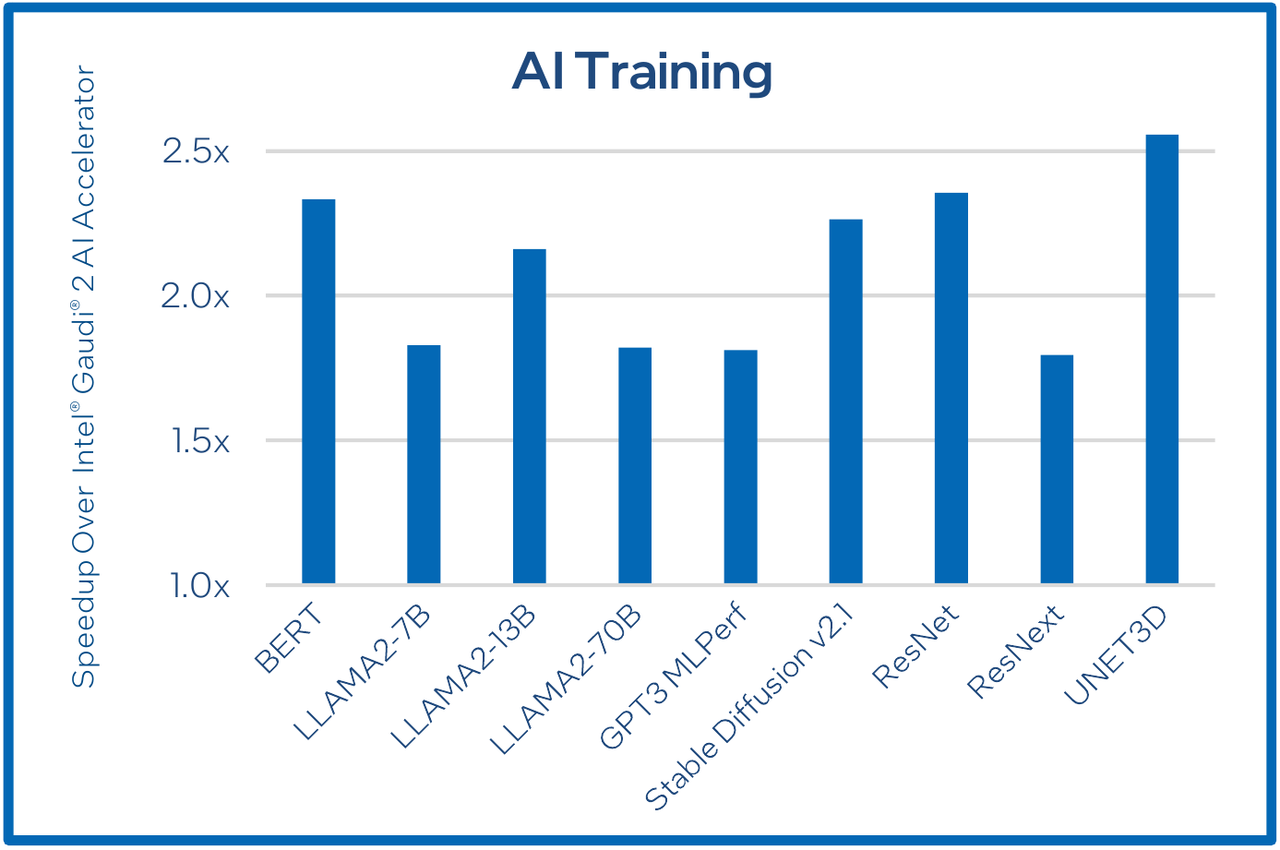 В инференс-тестах отрыв оказался чуть меньше, но и здесь минимальна разница составляет полтора раза. Что немаловажно для инференс-сценариев, серьёзно улучшились показатели латентности. Отчасти это заслуга не только серьёзно подросших «мускул» нового процессора, но и наличие большего объёма HBM, что позволяет разместить в памяти больше параметров и расширить контекстное окно. 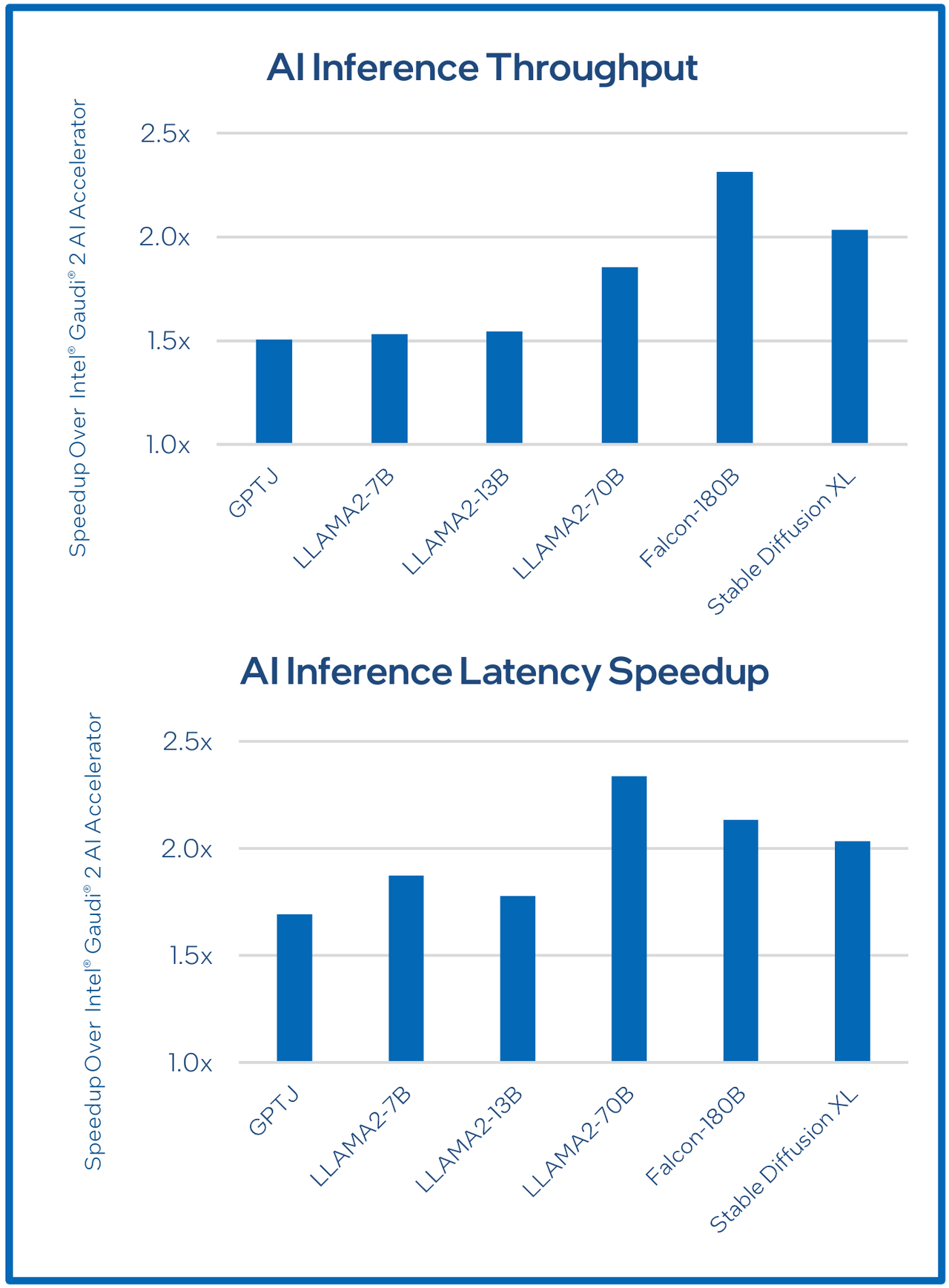 Опубликовала Intel и результаты сравнительного тестирования Gaudi3 против NVIDIA H100 в MLPerf, где новинка действительно выступила весьма достойно, в худшем случае демонстрируя 90% от производительности H100, а в отдельных тестах опережая конкурента более чем в 2,5 раза. Примерно так же распределились результаты и в тестах на энергоэффективность. 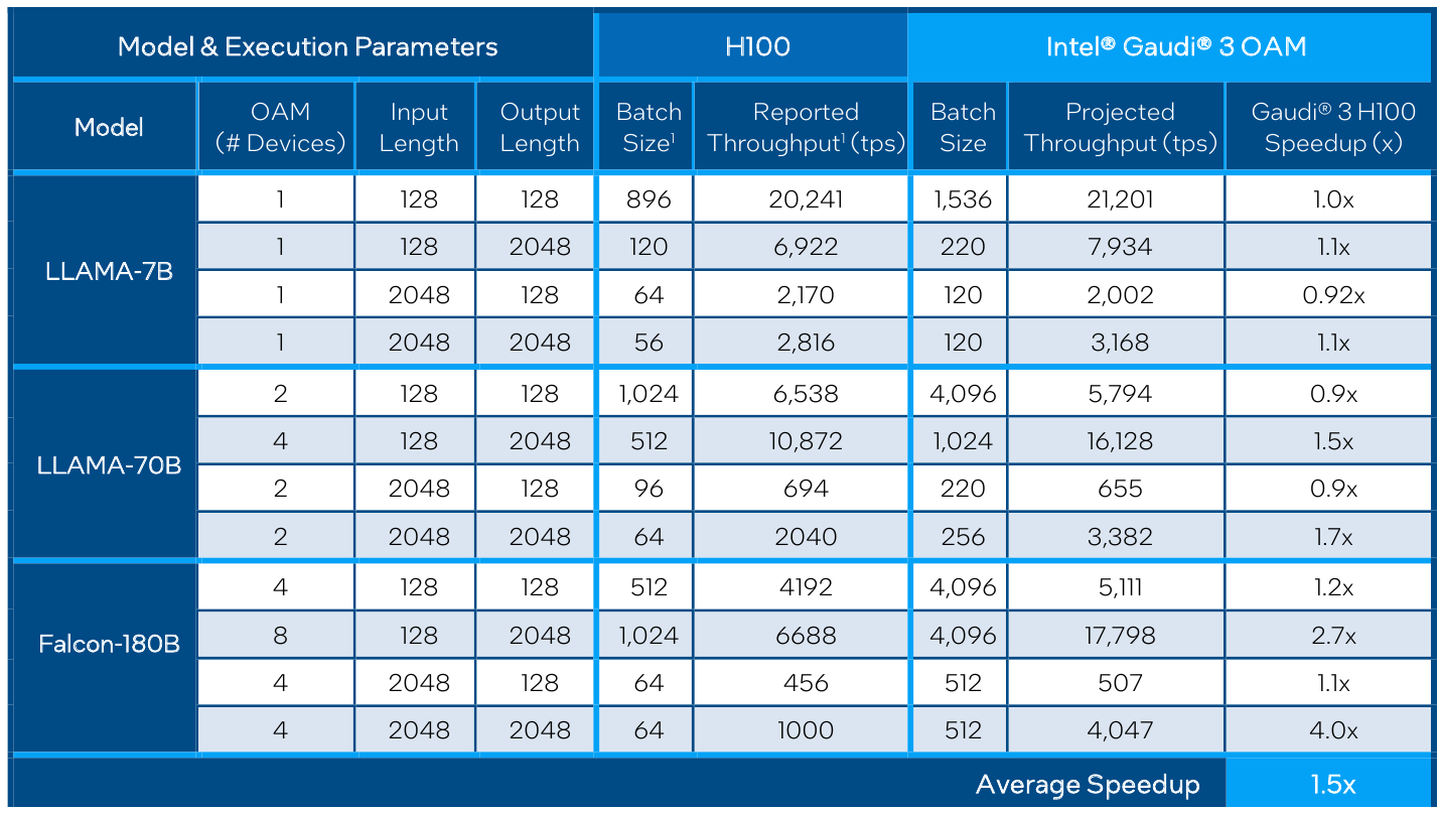 Что же касается инженерно-технической реализации, то на этот раз Intel представила сразу несколько вариантов ускорителей на базе Gaudi3, отличающихся как теплопакетом, так и конструктивом. Самым быстрым вариантом в семействе является модуль HL-325L OCP. Он выполнен в формате мезонинной платы OCP OAM 2.0 и поддерживает теплопакет 900 Вт для воздушного охлаждения и 1200 Вт — для жидкостного. 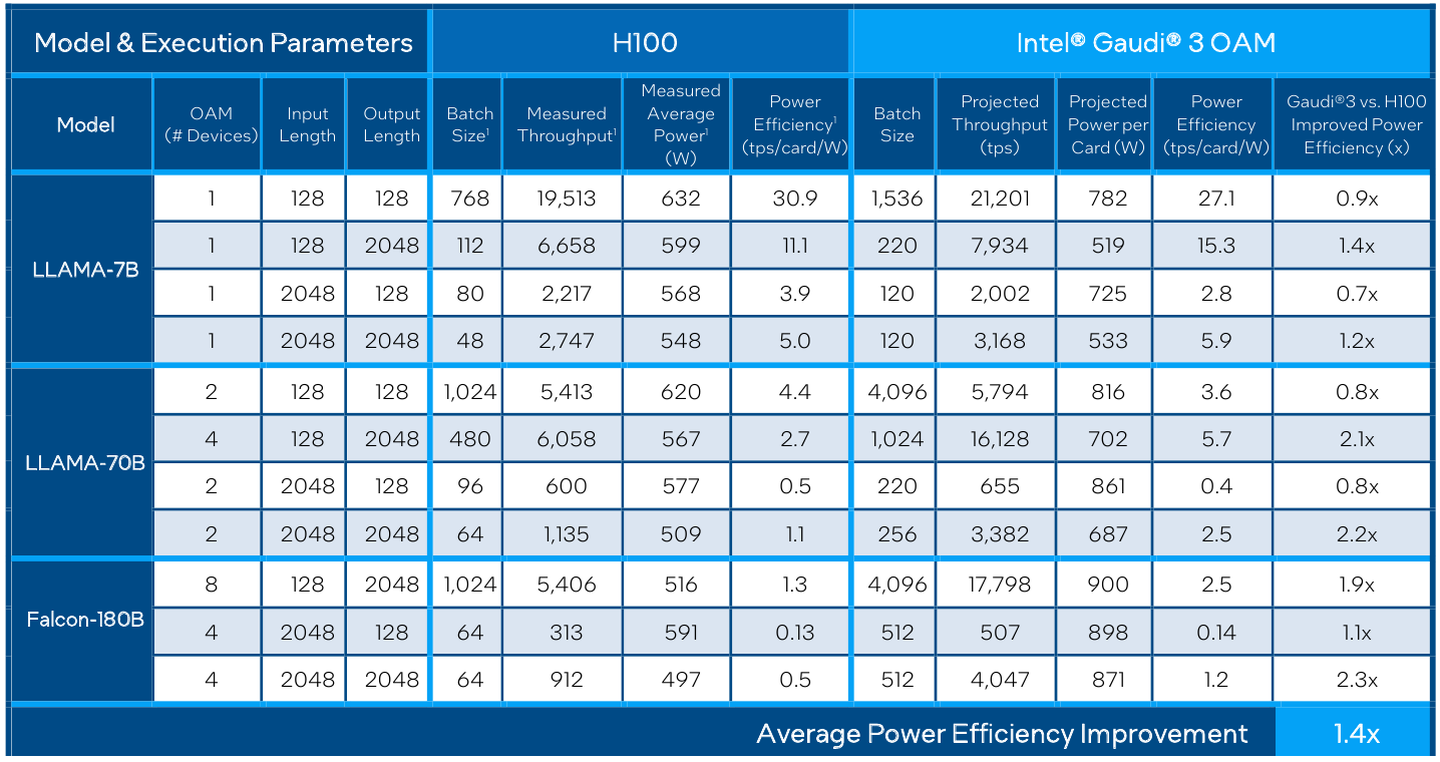 Для этой модели была специально разработана новая UBB-плата HLB-325L, приходящая на смену HLBA-225. Она поддерживает установку восьми ускорителей HL-325L, причём 21 сетевое подключение на каждом из них позволяет реализовать интерконнект по схеме «все со всеми», а оставшиеся подключения сведены через PAM4-ретаймеры в шесть 800GbE-портов OSFP для дальнейшего масштабирования кластера. Имеется и вывод PCI Express 5.0 с помощью PCIe-ретаймеров, также установленных на плате. HLB-325L рассчитана на питание 54 В, которое в последнее время становится всё популярнее в новых ЦОД и HPC-системах. 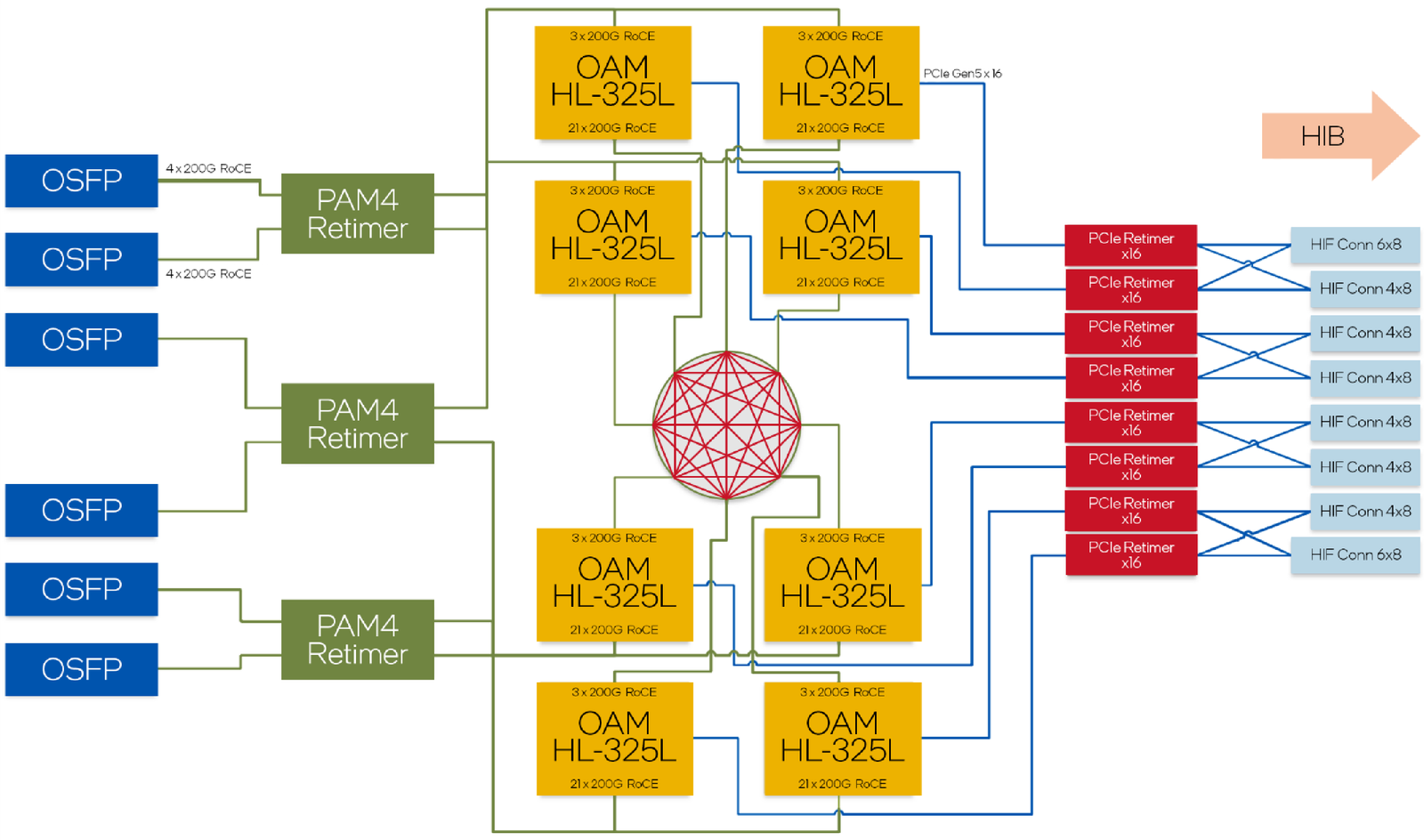
Топология базовой платы HLB-325L с восемью Gaudi3 Другой вариант Gaudi3 — ускоритель HL-338. Он представляет собой стандартную плату расширения PCIe с двумя внешними портами QSFP112 400GbE. Поддерживаются теплопакеты вплоть до 600 Вт при стандартном воздушном охлаждении. Дополнительный мостик HLTB-304, устанавливаемая поверх четырёх ускорителей HL-338, обеспечивает интерконнект за счёт 18 набортных линков 200GbE. Такая реализация кластера на базе Gaudi3 по понятным причинам будет несколько менее производительной, нежели вариант с OAM-модулями, но позволит обойтись стандартными аппаратными средствами и корпусами серверов. 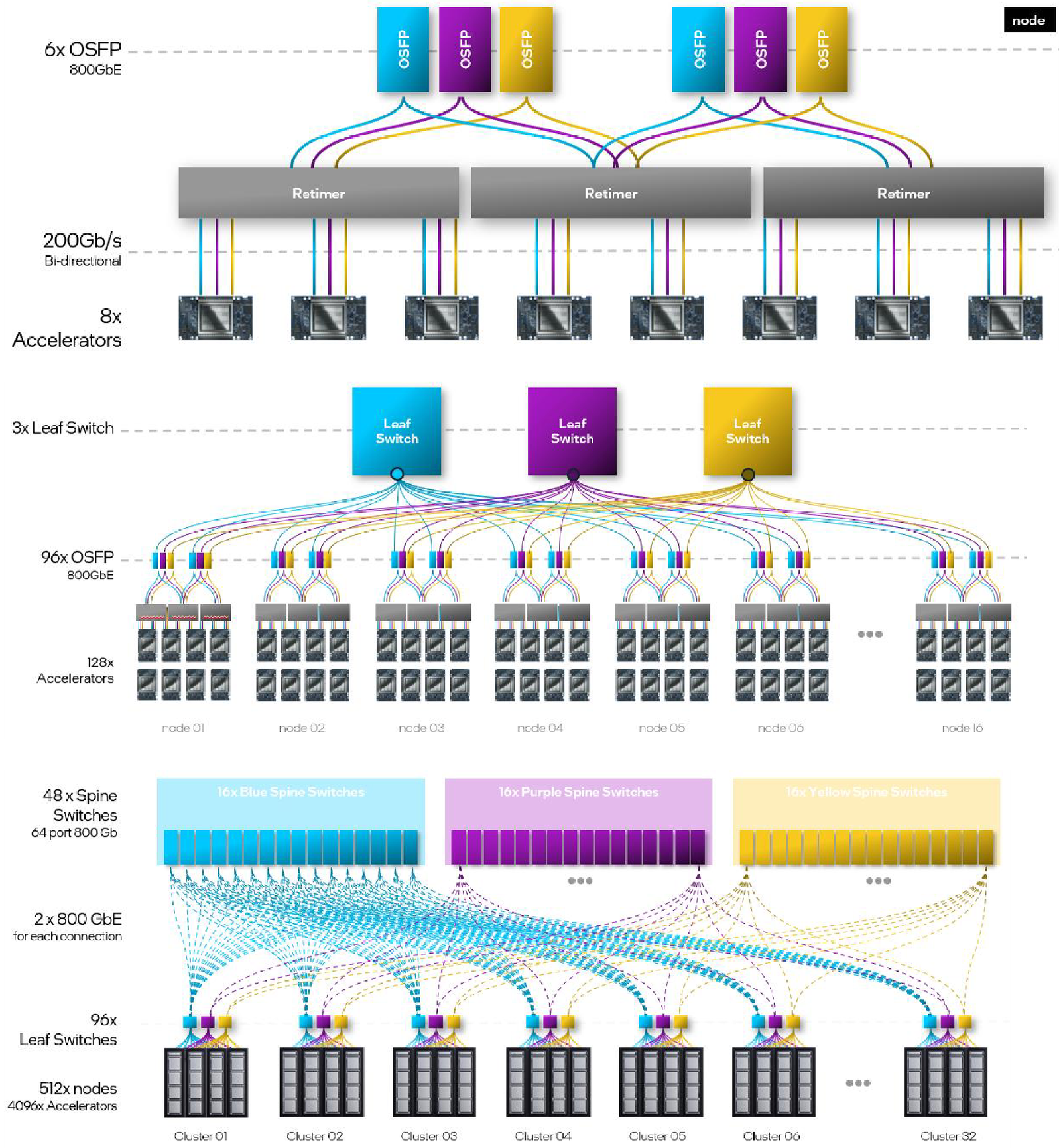
Масштабирование и кластеризация Gaudi3 Первые пробные партии ускорителей на базе Gaudi3 поступят избранным партнёрам Intel уже в этом полугодии. Вариант OAM с воздушным охлаждением уже тестируется в квалификационных лабораториях компании, а образцы с жидкостным охлаждением появятся позднее в этом квартале. В новинке заинтересованы Dell, HPE, Lenovo и Supermicro. Массовые поставки стартуют в III квартале 2024 года. Последними на рынке появятся PCIe-версии, их поставки намечены на IV квартал. 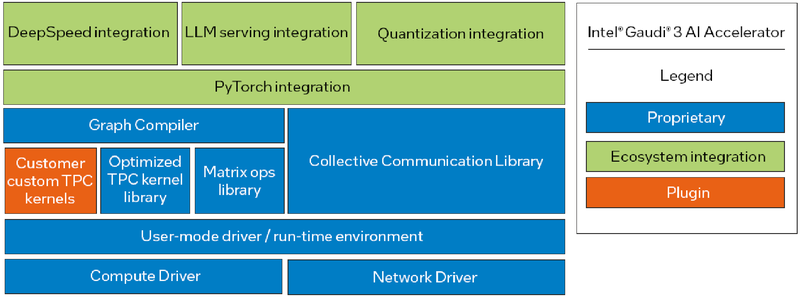
Программная экосистема Intel Gaudi Intel Gaudi3 выглядит весьма неплохо. В нём устранены узкие места, свойственные Gaudi2, что позволяет тягаться на равных с NVIDIA H100 и H200, и даже заметно превосходить их в некоторых сценариях. Однако NVIDIA уже анонсировала архитектуру Blackwell. Впрочем, основная борьба развернётся не на аппаратном, а на программном уровне — Intel вслед за AMD упростила работу с PyTorch, что позволит перенести множество нагрузок на Gaudi. А там, глядишь, и UXL станет хоть какой-то альтернативой CUDA.
28.03.2024 [14:31], Сергей Карасёв
Intel Gaudi2 остаётся единственным конкурентом NVIDIA H100 в бенчмарке MLPerf InferenceКорпорация Intel сообщила о том, что её ИИ-ускоритель Habana Gaudi2 остаётся единственной альтернативой NVIDIA H100, протестированной в бенчмарке MLPerf Inference 4.0. При этом, как утверждается, Gaudi2 обеспечивает высокое быстродействие в расчёте на доллар, хотя именно чипы NVIDIA являются безоговорочными лидерами. Отмечается, что для платформы Gaudi2 компания Intel продолжает расширять поддержку популярных больших языковых моделей (LLM) и мультимодальных моделей. В частности, для MLPerf Inference v4.0 корпорация представила результаты для Stable Diffusion XL и Llama v2-70B. Согласно результатам тестов, в случае Stable Diffusion XL ускоритель H100 превосходит по производительности Gaudi2 в 2,1 раза в оффлайн-режиме и в 2,16 раза в серверном режиме. При обработке Llama v2-70B выигрыш оказывается более значительным — в 2,76 раза и 3,35 раза соответственно. Однако на большинстве этих задач (кроме серверного режима Llama v2-70B) решение Gaudi2 выигрывает у H100 по показателю быстродействия в расчёте на доллар. 
Источник изображений: Intel В целом, ИИ-ускоритель Gaudi2 в Stable Diffusion XL показал результат в 6,26 и 6,25 выборок в секунду для оффлайн-режима и серверного режима соответственно. В случае Llama v2-70B достигнут показатель в 8035,0 и 6287,5 токенов в секунду соответственно. 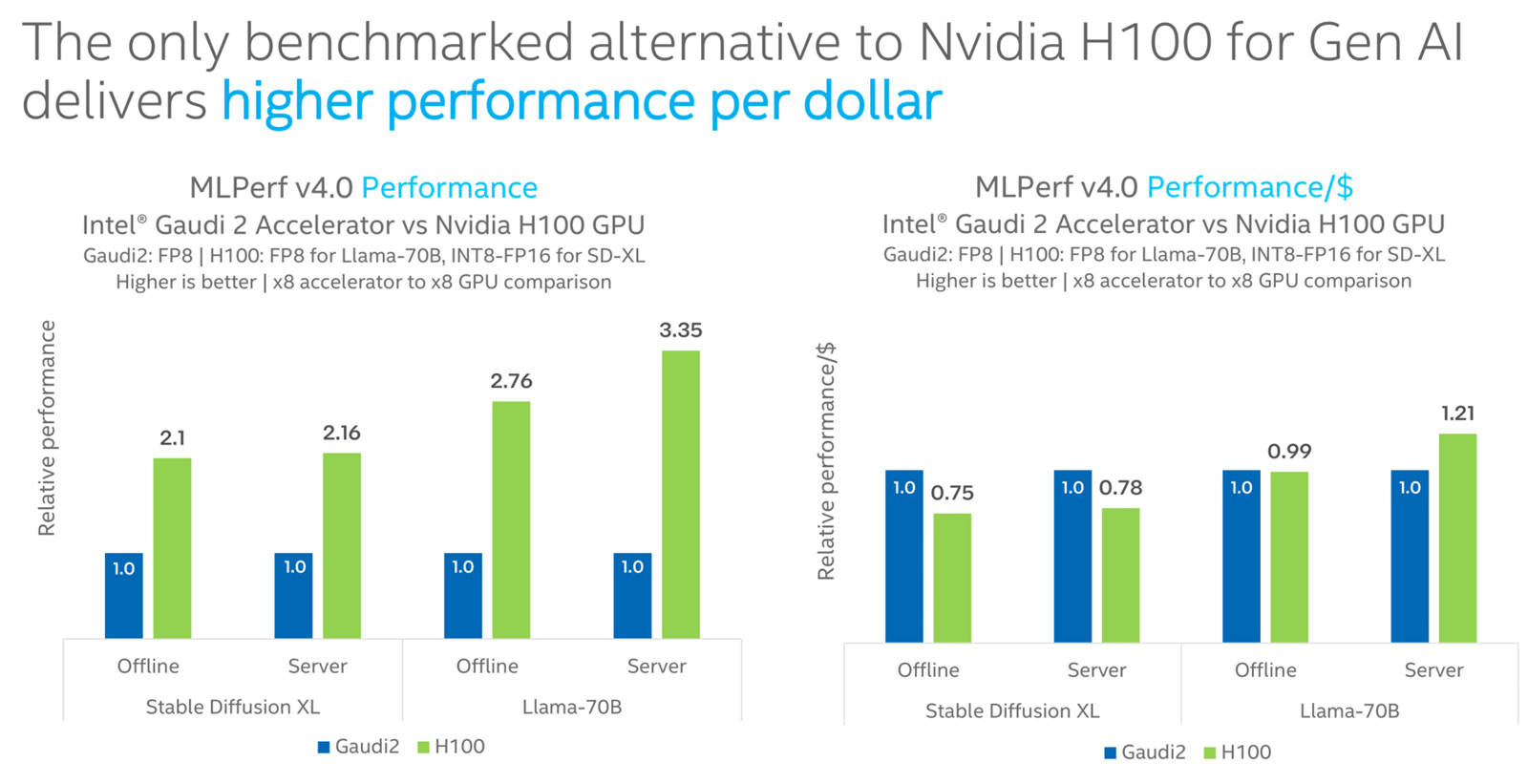 Говорится также, что серверные процессоры Intel Xeon Emerald Rapids благодаря улучшениям аппаратной и программной составляющих в бенчмарке MLPerf Inference v3.1 демонстрируют в среднем в 1,42 раза более высокие значения по сравнению с чипами Xeon Sapphire Rapids. Например, для GPT-J с программной оптимизацией и для DLRMv2 зафиксирован рост быстродействия примерно в 1,8 раза.
15.12.2023 [16:57], Сергей Карасёв
Intel показала ИИ-ускоритель Habana Gaudi3Корпорация Intel на мероприятии AI Everywhere показала ИИ-ускоритель следующего поколения — изделие Gaudi3, которое появится на коммерческом рынке в 2024 году. Новинка призвана составить конкуренцию решению NVIDIA H100, которое применяется в составе многих ИИ-платформ по всему миру. Gaudi3 придёт на смену ускорителю Gaudi2, который дебютировал в мае 2022 года. Данное устройство оснащено 96 Гбайт памяти HBM2e с пропускной способностью 2,45 Тбайт/с. Показатель TDP достигает 600 Вт. Gaudi3 будет существенно лучше Gaudi2, хотя полные характеристики пока не раскрываются. Однако демонстрация чипа говорит о высокой степени готовности продукта. 
Источник изображений: Intel В целом, ничего существенно нового глава Intel о новинке не рассказал. Так, производительность BF16-вычислений увеличена приблизительно в четыре раза по сравнению с Gaudi2. Пропускная способность HBM-памяти выросла в полтора раза, а пропускная способность сети — вдвое. Ускоритель Gaudi3 будет изготавливаться с применением 5-нм технологии против 7-нм у предшественника. В конструкцию Gaudi3 входят восемь сборок HBM, тогда как у решения второго поколения их шесть. 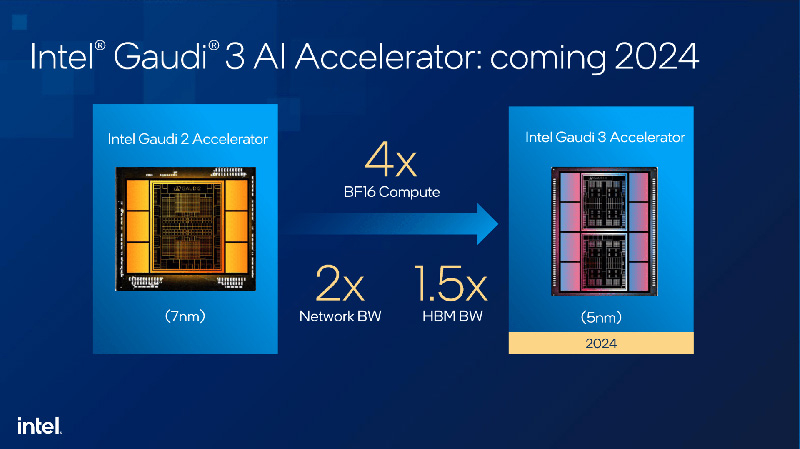 Ранее говорилось, что Gaudi3 можно будет применять в серверах с воздушным и жидкостным охлаждением. Во втором случае речь идёт о двухфазной системе на основе хладагента среднего давления. Причём в этой СЖО не будут использоваться полифторалкильные вещества (PFAS, «вечные химикаты»).
02.12.2023 [23:17], Сергей Карасёв
ИИ-ускорители Intel Gaudi3 получат двухфазное жидкостное охлаждение VertivКомпании Intel и Vertiv объявили о заключении соглашения о сотрудничестве, в рамках которого планируется разработка эффективной СЖО для ускорителей Gaudi3: эти решения, предназначенные для ресурсоёмких ИИ-задач, увидят свет в 2024 году. Сообщается, что Gaudi3 можно будет использовать в составе серверов с воздушным и жидкостным охлаждением. В первом случае допускается работа при тепловой нагрузке до 40 кВт с температурой окружающего воздуха на входе до +35 °C. В качестве альтернативы предлагается применять двухфазное жидкостное охлаждение. Такое решение протестировано при совокупной мощности ИИ-ускорителей до 160 кВт с использованием на входе воды с температурой от +17 до +45 °C. Эта система на основе хладагента среднего давления, как утверждается, поможет заказчикам реализовать повторное использование тепла, одновременно улучшив показатели эффективности использования воды (WUE) и энергии (PUE). Кроме того, клиенты смогут снизить совокупную стоимость владения (TCO). 
Источник изображения: Vertiv Системы двухфазного жидкостного охлаждения отводят тепло более эффективно по сравнению с другими решениями. Однако в последнее время технология столкнулась с критикой. Проблема заключается в том, что в таких системах используются фтористые соединения, такие как Novec от 3M, который недавно был снят с производства из-за опасений по поводу того, что состав может представлять угрозу для здоровья людей. Как сообщает ресурс Datacenter Dynamics, ссылаясь на заявления представителей Vertiv, в СЖО для Gaudi3 не будут применяться полифторалкильные вещества (PFAS, «вечные химикаты»), будущее которых находится под вопросом. Однако пока не уточняется, какую именно альтернативную жидкость намерена использовать компания.
14.11.2023 [03:20], Алексей Степин
Intel показала результаты тестов ускорителя Max 1550 и рассказала о будущих чипах Gaudi3 и Falcon ShoresВ рамках SC23 корпорация Intel продемонстрировала ряд любопытных слайдов. На них присутствуют результаты тестирования ускорителя Max 1550 с архитектурой Xe, а также планы относительно следующего поколения ИИ-ускорителей Gaudi. 
Изображение: Intel При этом компания применила иной подход, нежели обычно — вместо демонстрации результатов, полученных в стенах самой Intel, слово было предоставлено Аргоннской национальной лаборатории Министерства энергетики США, где летом этого года было завершён монтаж суперкомпьютера экза-класса Aurora, занимающего нынче второе место в TOP500.  В этом HPC-кластере применены OAM-модули Max 1550 (Ponte Vecchio) с теплопакетом 600 Вт. Они содержат в своём составе 128 ядер Xe и 128 Гбайт памяти HBM2E. Интерфейс Xe Link позволяет общаться напрямую восьми таким модулям, что обеспечивает более эффективную масштабируемость. 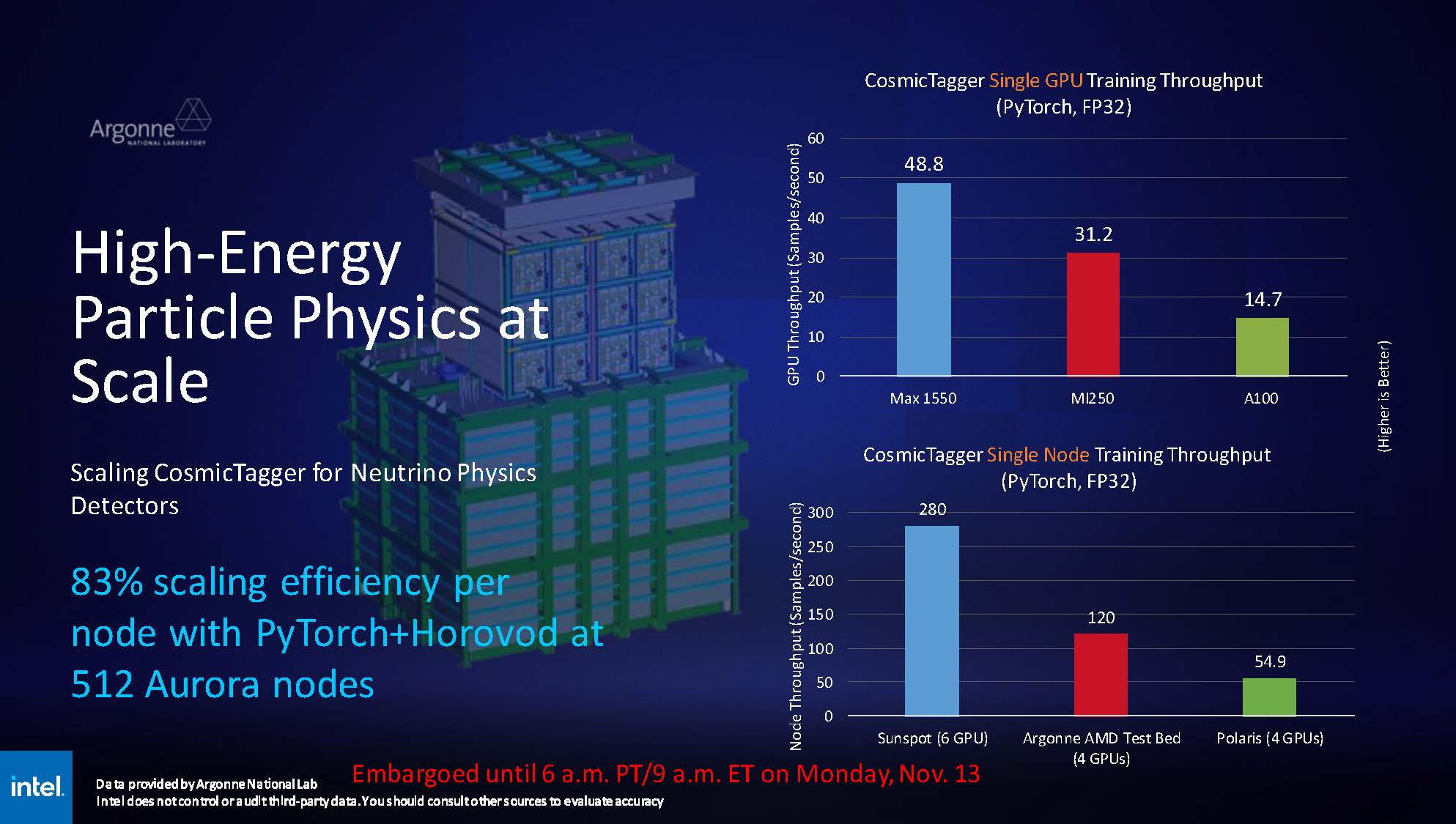
Источник изображений здесь и далее: Intel via ServeTheHome Хотя настройка вычислительного комплекса Aurora ещё продолжается, уже имеются данные о производительности Max 1550 в сравнении с AMD Instinct MI250 и NVIDIA A100. В тесте физики высоких частиц, использующих сочетание PyTorch+Horovod (точность вычислений FP32), ускорители Intel уверенно заняли первое место, а также показали 83% эффективность масштабирования на 512 узлах Aurora.  В тесте, симулирующем поведение комплекса кремниевых наночастиц, ускорители Max 1550, также оказались первыми как в абсолютном выражении, так и в пересчёте на 128-узловой тест в сравнении с системами Polaris (четыре A100 на узел) и Frontier (четыре MI250 на узел). Написанный с использованием Fortran и OpenMP код доказал работоспособность и при масштабировании до более чем 500 вычислительных узлов Aurora. 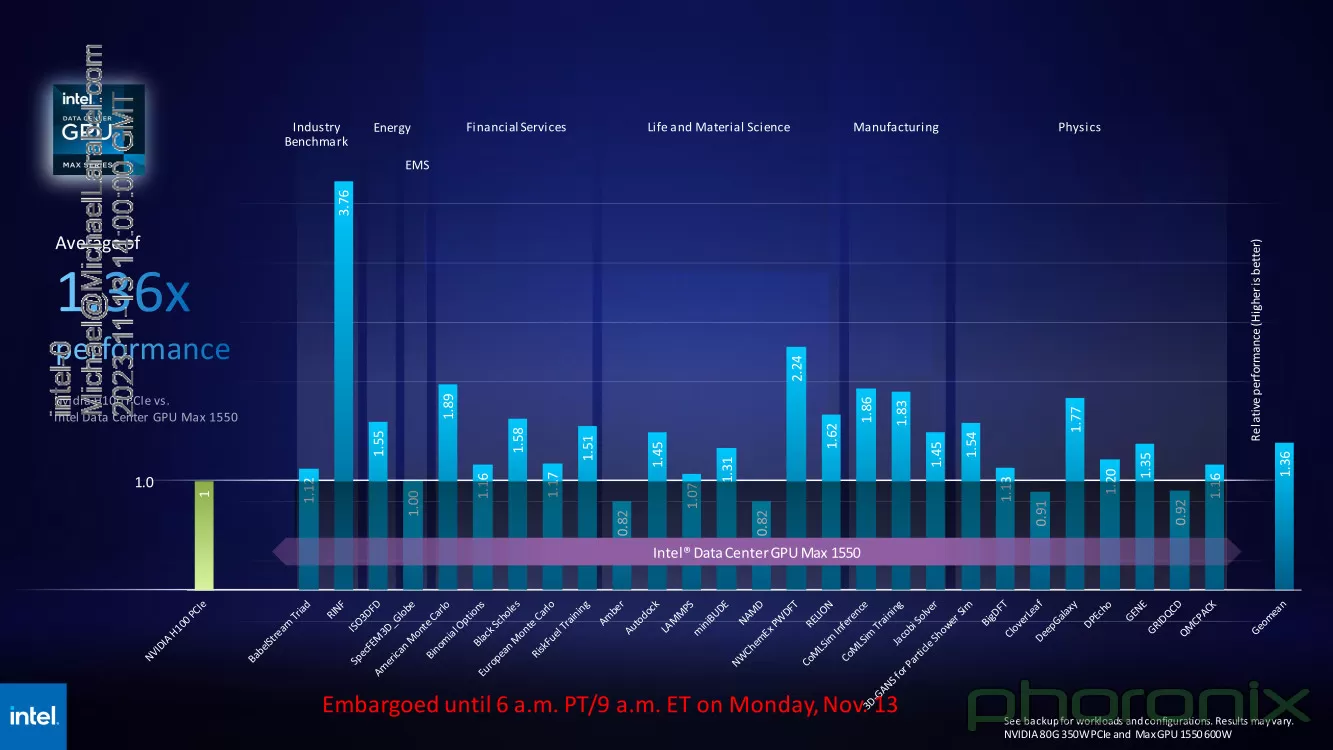
Источник изображения: Intel via Phoronix В целом, ускорители Intel Max 1550 демонстрируют хорошие результаты и не уступают NVIDIA H100: в некоторых задачах их относительная эффективность составляет не менее 0,82, но в большинстве других тестов этот показатель варьируется от 1,0 до 3,76. Очевидно, что у H100 появился достойный соперник, который, к тому же, имеет меньшую стоимость и большую доступность. Но сама NVIDIA уже представила чипы (G)H200, а AMD готовит Instinct MI300.  Системы на базе Intel Max доступны в различном виде: как в облаке Intel Developer Cloud, так и в составе OEM-решений. Supermicro предлагает сервер с восемью модулями OAM, а Dell и Lenovo — решения с четырьями ускорителями в этом же формате. PCIe-вариант Max 1100 доступен от вышеуказанных производителей, а также у HPE. 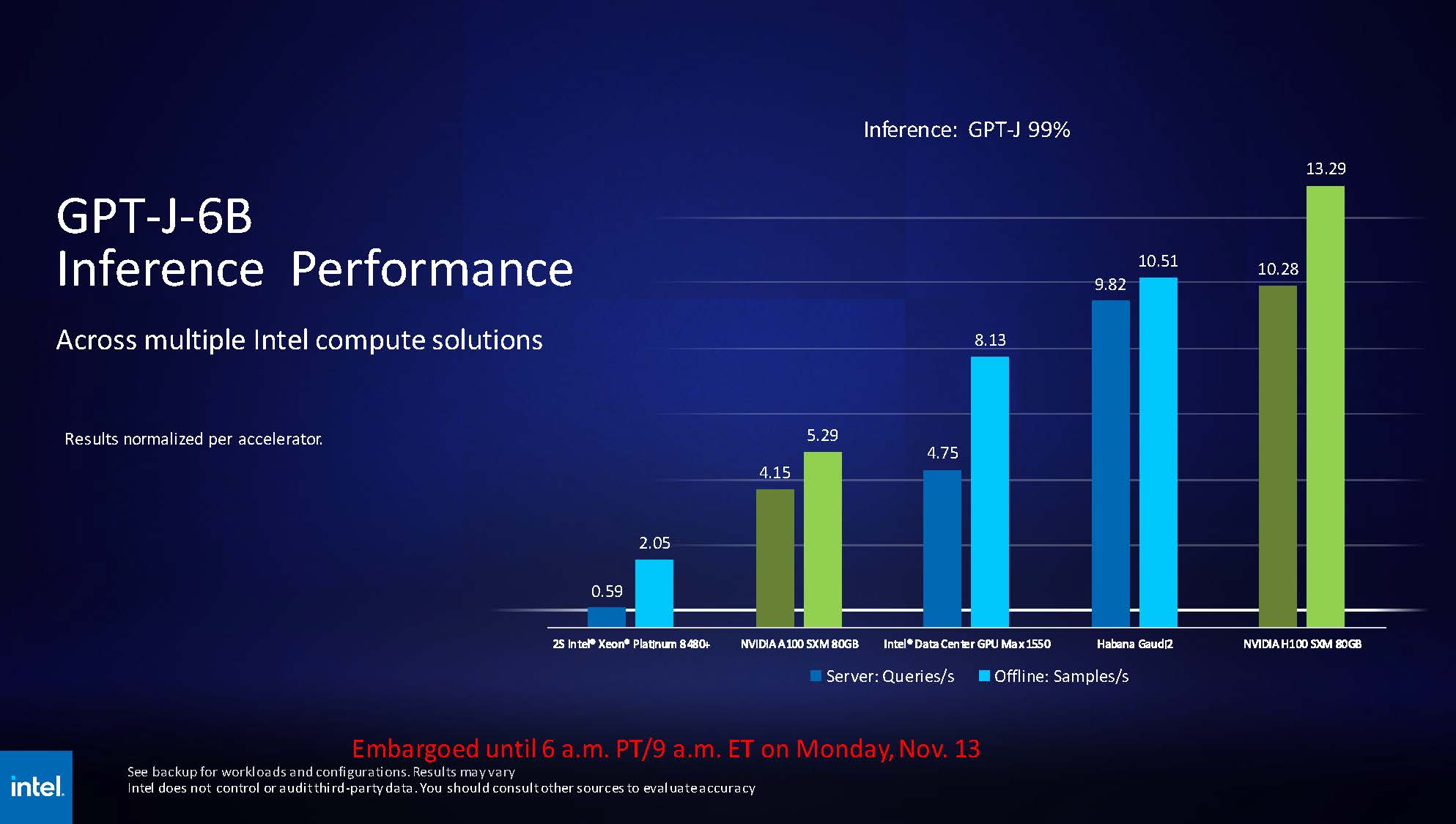 Помимо ускорителей Max, Intel привела и новые данные о производительности ИИ-сопроцессоров Gaudi2. Компания продолжает активно совершенствовать и оптимизировать программную экосистему Gaudi. В результате, в инференс-системе на базе модели GPT-J-6B результаты ускорителей Gaudi2 уже сопоставимы с NVIDIA H100 (SXM 80 Гбайт), а A100 существенно уступает как Gaudi2, так и Max 1550.  Но самое интересное — это сведения о планах относительно следующего поколения Gaudi. Теперь известно, что Gaudi3 будет производиться с использованием 5-нм техпроцесса. Новый чип будет в четыре раза быстрее в вычислениях BF16, а также получит вдвое более мощную подсистему памяти и в 1,5 раза больше памяти HBM. Увидеть свет он должен в 2024 году. 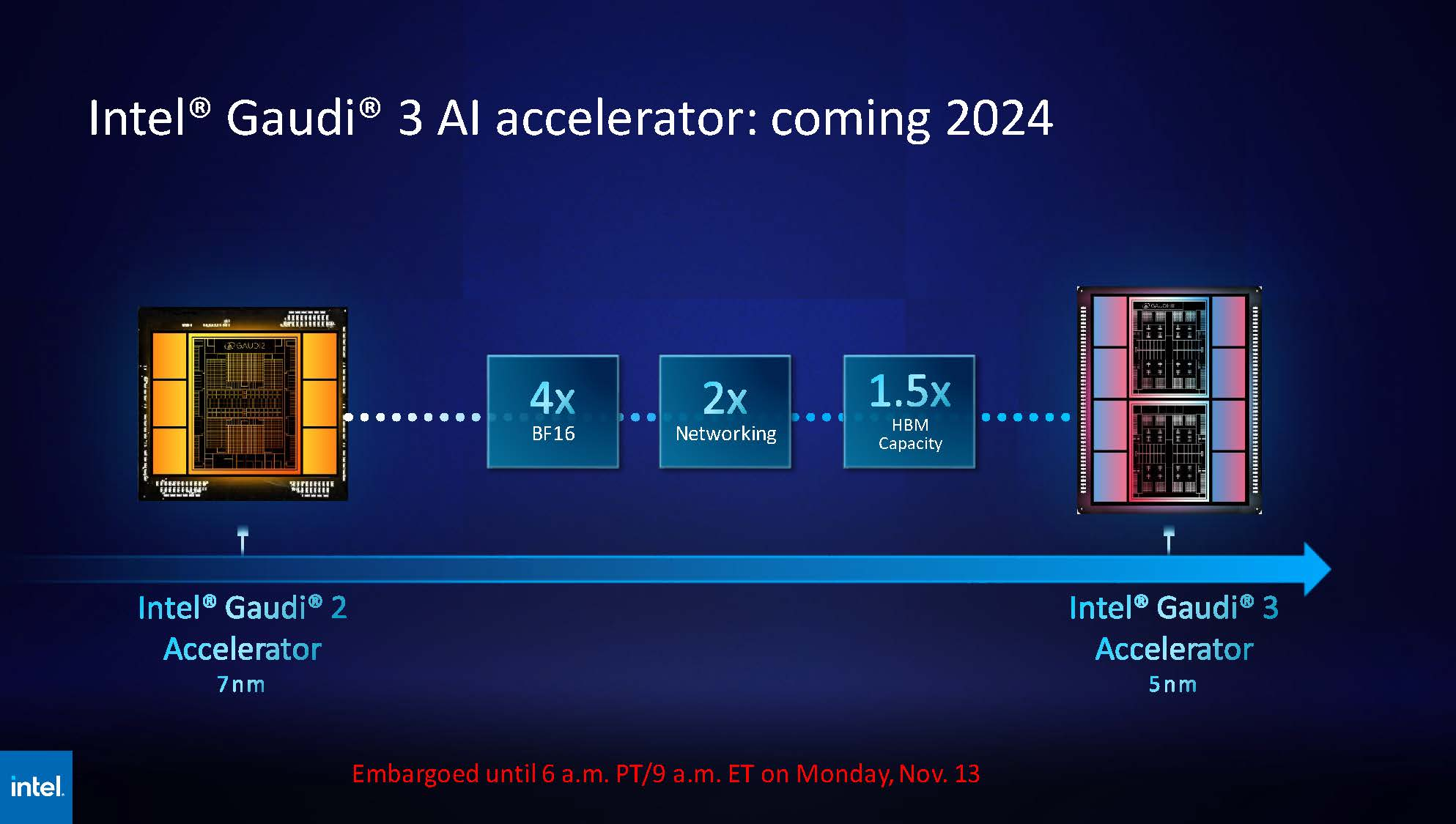 Заодно компания напомнила, что процессоры Xeon Emerald Rapids будут представлены ровно через месяц, а Granite Rapids появятся в 2024 году. В 2025 появится чип Falcon Shores, который теперь должен по задумке Intel сочетать в себе GPU и ИИ-сопроцессор. Он объединит архитектуры Habana и Xe в единое решение с тайловой компоновкой, памятью HBM3 и полной поддержкой CXL. 
Источник изображения: Intel via Phoronix Следует отметить, что такая унификация вполне реальна: Intel весьма активно развивает универсальный, гибкий и открытый стек технологий в рамках проекта oneAPI. В него входят все необходимые инструменты — от компиляторов и системных библиотек до средств интеграции с популярными движками аналитики данных, моделями и библиотеками искусственного интеллекта.
11.11.2023 [15:23], Сергей Карасёв
MLPerf: Intel улучшила производительность Gaudi2, но лидером остаётся NVIDIA H100Консорциум MLCommons обнародовал результаты тестирования различных аппаратных решений в бенчмарке MLPerf Training 3.1, который оценивает производительность на ИИ-операциях. Отмечается, что корпорация Intel смогла существенно увеличить быстродействие своего ускорителя Habana Gaudi2, но безоговорочным лидером остаётся NVIDIA H100. Тесты проводились на платформе Xeon Sapphire Rapids. Отмечается, что для некоторых задач Intel реализовала поддержку FP8-вычислений, благодаря чему производительность поднялась в два раза по сравнению с показателями, которые этот же ускоритель демонстрировал ранее. Согласно результатам тестов, в бенчмарке GPT-3 ускоритель Gaudi2 ровно в два раза проигрывает решению NVIDIA H100. То же самое касается теста Stable Diffusion: при этом нужно отметить, что Gaudi2 использовал формат BF16, а H100 — FP16. В ResNet эти ускорители демонстрируют сопоставимую производительность. В тесте BERT чип H100 при использовании FP8-вычислений показал значительное преимущество перед Gaudi2, который использовал формат BF16. 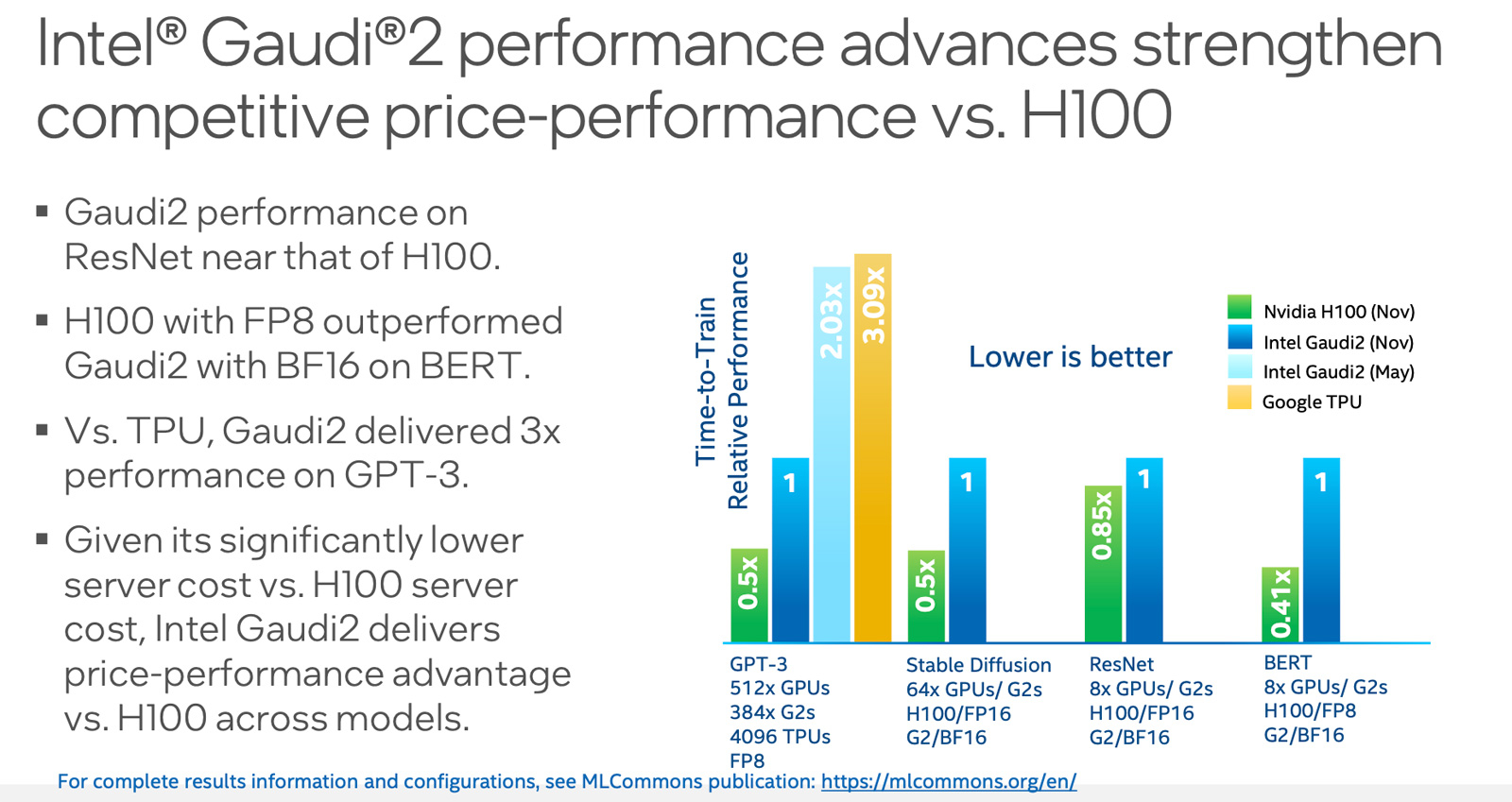
Источник изображения: MLCommons Сама Intel отмечает, что с внедрением поддержки FP8 система с 384 ускорителями Gaudi2 способна завершить обучение GPT-3 за 153,58 мин. При использовании 64 чипов Gaudi2 тест Stable Diffusion может быть завершён за 20,2 мин (BF16). Для тестов BERT и ResNet-50 на восьми ускорителях Gaudi2 (BF16) результат составляет 13,27 и 15,92 мин соответственно. Вместе с тем стоимость и доступность ускорителей Intel, как считается, существенно лучше, чем у решений NVIDIA.
10.05.2022 [22:46], Игорь Осколков
Intel анонсировала ИИ-ускорители Habana Gaudi2 и GrecoНа мероприятии Intel Vision было анонсировано второе поколение ИИ-ускорителей Habana: Gaudi2 для задач глубокого обучения и Greco для инференс-систем. Оба чипа теперь производятся с использованием 7-нм, а не 16-нм техпроцесса, но это далеко не единственное улучшение. Gaudi2 выпускается в форм-факторе OAM и имеет TDP 600 Вт. Это почти вдвое больше 350 Вт, которые были у Gaudi, но второе поколение чипов значительно отличается от первого. Так, объём набортной памяти увеличился втрое, т.е. до 96 Гбайт, и теперь это HBM2e, так что в итоге и пропускная способность выросла с 1 до 2,45 Тбайт/с. Объём SRAM вырос вдвое, до 48 Мбайт. Дополняют память DMA-движки, способные преобразовывать данные в нужную форму на лету. 
Изображения: Intel/Habana В Gaudi2 имеется два основных типа вычислительных блоков: Matrix Multiplication Engine (MME) и Tensor Processor Core (TPC). MME, как видно из названия, предназначен для ускорения перемножения матриц. TPC же являются программируемыми VLIW-блоками для работы с SIMD-операциями. TPC поддерживают все популярные форматы данных: FP32, BF16, FP16, FP8, а также INT32, INT16 и INT8. Есть и аппаратные декодеры HEVC, H.264, VP9 и JPEG.  Особенностью Gaudi2 является возможность параллельной работы MME и TPC. Это, по словам создателей, значительно ускоряет процесс обучения моделей. Фирменное ПО SynapseAI поддерживает интеграцию с TensorFlow и PyTorch, а также предлагает инструменты для переноса и оптимизации готовых моделей и разработки новых, SDK для TPC, утилиты для мониторинга и оркестрации и т.д. Впрочем, до богатства программной экосистемы как у той же NVIDIA пока далеко. 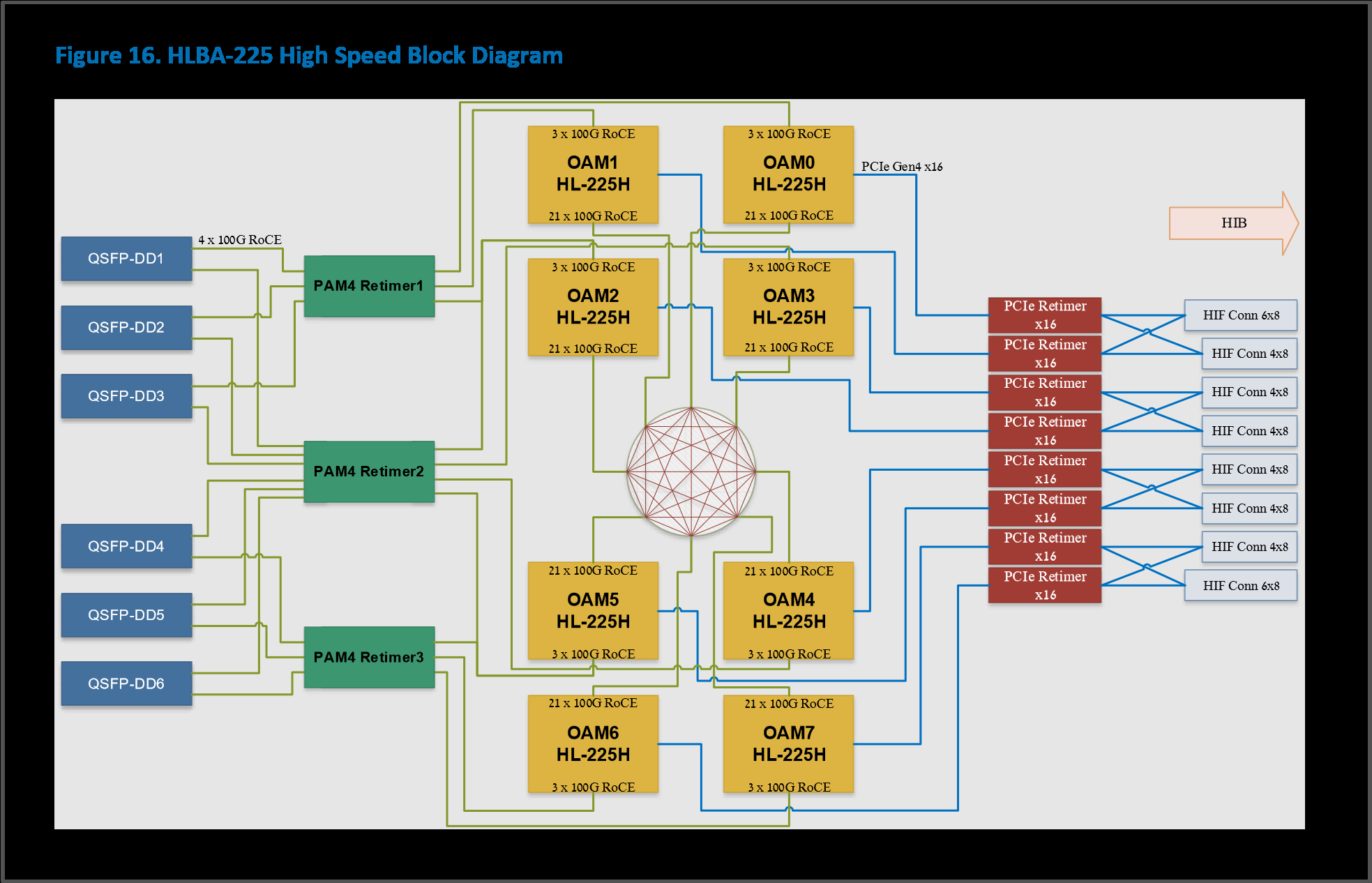 Интерфейсная часть новинок включает PCIe 4.0 x16 и сразу 24 (ранее было только 10) 100GbE-каналов с RDMA ROcE v2, которые используются для связи ускорителей между собой как в пределах одного узла (по 3 канала каждый-с-каждым), так и между узлами. Intel предлагает плату HLBA-225 (OCP UBB) с восемью Gaudi2 на борту и готовую ИИ-платформу, всё так же на базе серверов Supermicro X12, но уже с новыми платами, и СХД DDN AI400X2. 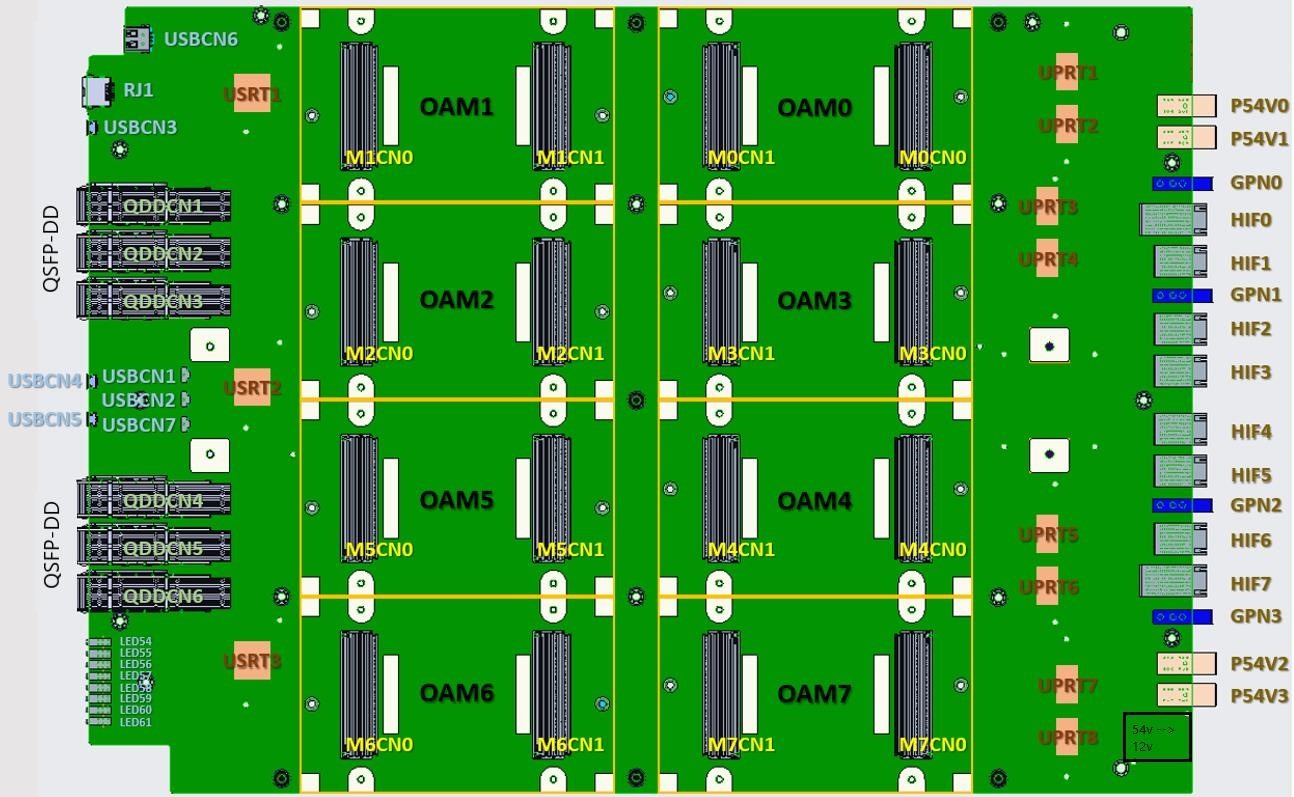 Наконец, самое интересное — сравнение производительности. В ряде популярных нагрузок новинка оказывается быстрее NVIDIA A100 (80 Гбайт) в 1,7–2,8 раз. На первый взгляд результат впечатляющий. Однако A100 далеко не новы. Более того, в III квартале этого года ожидается выход ускорителей H100, которые, по словам NVIDIA, будут в среднем от трёх до шести раз быстрее A100, а благодаря новым функциям прирост в скорости обучения может быть и девятикратным. Ну и в целом H100 являются более универсальными решениями. 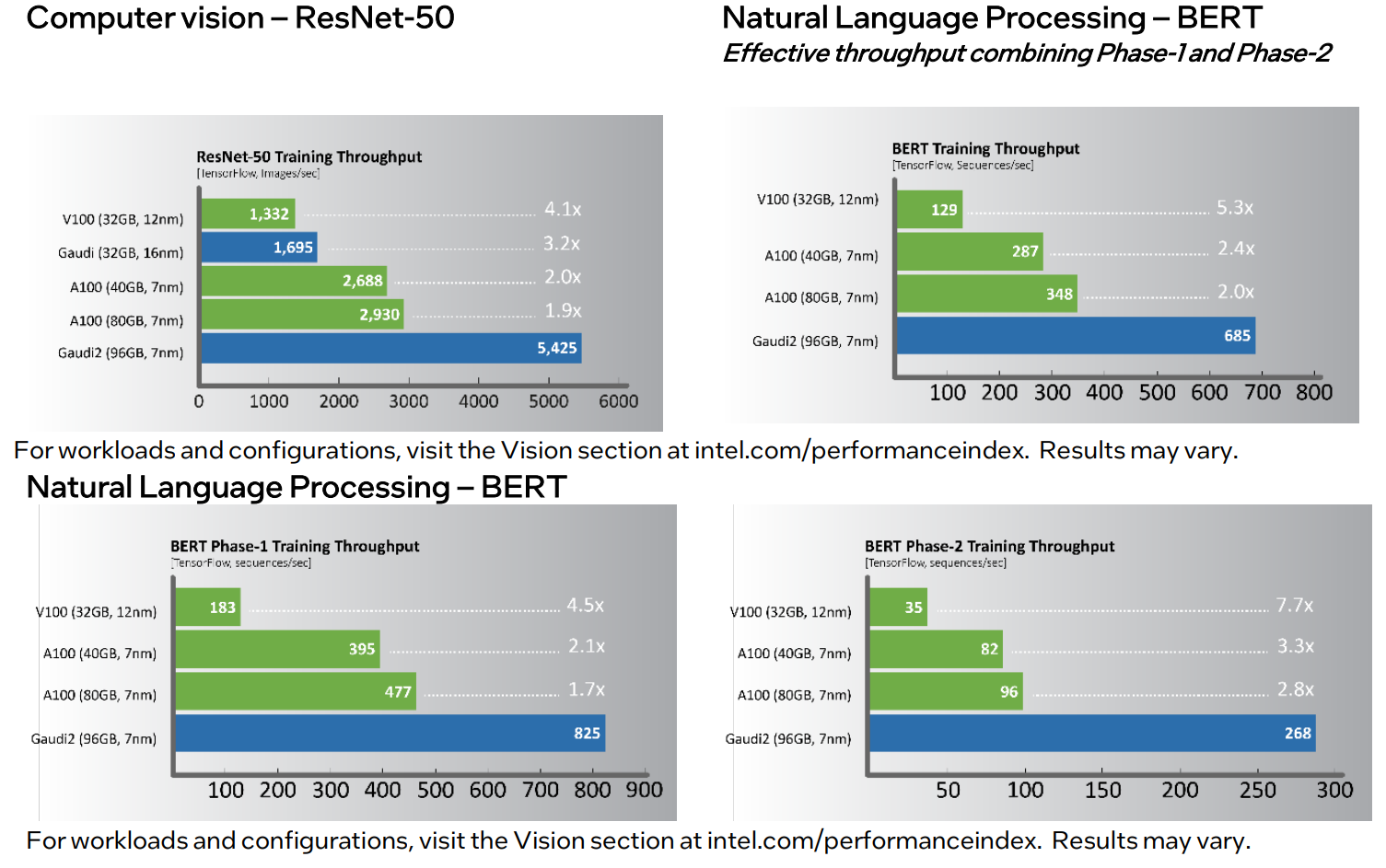 Gaudi2 уже доступны клиентам Habana, а несколько тысяч ускорителей используются самой Intel для дальнейшей оптимизации ПО и разработки чипов Gaudi3. Greco будут доступны во втором полугодии, а их массовое производство намечено на I квартал 2023 года, так что информации о них пока немного. Например, сообщается, что ускорители стали намного менее прожорливыми по сравнению с Goya и снизили TDP с 200 до 75 Вт. Это позволило упаковать их в стандартную HHHL-карту расширения с интерфейсом PCIe 4.0 x8.  Объём набортной памяти всё так же равен 16 Гбайт, но переход от DDR4 к LPDDR5 позволил впятеро повысить пропускную способность — с 40 до 204 Гбайт/с. Зато у самого чипа теперь 128 Мбайт SRAM, а не 40 как у Goya. Он поддерживает форматы BF16, FP16, (U)INT8 и (U)INT4. На борту имеются кодеки HEVC, H.264, JPEG и P-JPEG. Для работы с Greco предлагается тот же стек SynapseAI. Сравнения производительности новинки с другими инференс-решениями компания не предоставила.  Впрочем, оба решения Habana выглядят несколько запоздалыми. В отставании на ИИ-фронте, вероятно, отчасти «виновата» неудачная ставка на решения Nervana — на смену так и не вышедшим ускорителям NNP-T для обучения пришли как раз решения Habana, да и новых инференс-чипов NNP-I ждать не стоит. Тем не менее, судьба Habana даже внутри Intel не выглядит безоблачной, поскольку её решениям придётся конкурировать с серверными ускорителями Xe, а в случае инференс-систем даже с Xeon. |
|