Материалы по тегу: hardware
|
19.08.2025 [11:03], Руслан Авдеев
Tencent похвасталась, что накопила достаточно ускорителей для обучения новых и обновления существующих ИИ-моделейВ ходе отчёта о работе во II квартале 2025 года президент китайской Tencent Holdings Мартин Лау (Martin Lau) объявил, что компании не нужны дополнительные ИИ-ускорители. Их уже достаточно для обучения систем искусственного интеллекта и обновления готовых моделей, сообщает Datacenter Dynamics. Отвечая на вопрос о продолжающихся переговоров Китая и США об импорте ИИ-чипов в КНР и их влияния на Tencent, представитель компании ответил, что однозначного ответа о ситуации с импортом пока нет. По словам Лау, правительства ведут активные дискуссии, а бизнес ждёт, чем всё закончится. Но пока у компании достаточно чипов для обучения и обновления моделей. Также имеется много вариантов покупки чипов для инференса. По словам Лау, новые ускорители для этой цели могут и не понадобиться — компания вносит многочисленные изменения в ПО, чтобы поднять эффективность инференса. В марте Tencent заявила, что сосредоточилась на повышении эффективности использования доступных ускорителей после триумфа DeepSeek. США давно ограничили продажу ИИ-ускорителей китайским компаниям, и постоянно ужесточали политику. В августе 2025 года NVIDIA и AMD договорились платить США по 15 % от выручки от продаж ускорителей в Китай — в обмен на получение экспортных лицензий на «ослабленные» модели NVIDIA H20 и AMD MI308. Тем временем власти КНР настоятельно рекомендуют местным бизнесам отказаться от покупки американских чипов по соображениям безопасности. 
Источник изображения: Donald Wu/unsplash.com Впрочем, операционные капитальные затраты за II квартал составили ¥17,9 млрд ($2,49 млрд), увеличившись на 149 % в сравнении с аналогичным периодом 2024 года. Такой рост обусловлен в том числе и увеличением инвестиций в ИИ-ускорители и серверы для расширения возможностей компании в сфере искусственного интеллекта. Общие капитальные затраты — ¥19,1 млрд. В 2024 году капитальные затраты Tencent составили $10,6 млрд, более чем втрое больше, чем годом ранее. В отчёте о доходах за IV квартал 2024 года компания заявила, что в 2025 году капитальные затраты составят только несколько десятков процентов от выручки. По словам Лау, годовые целевые показатели затрат пока не пересмотрены, но «амортизационные» отчисления на ИИ продолжают расти. В то же время компания продолжает пользоваться плодами вложений в искусственный интеллект. Финансовые результаты Tencent, связанные с облачными сервисами, не раскрываются. Общая выручка компании за II квартал составила 184,5 млрд юаней ($25,7 млрд), увеличившись на 15 % год к году, валовая прибыль — 105 млрд юаней ($14,62 млрд), на 22 % выше год к году. В ходе конференции, посвящённой квартальным результатам, было отмечено, что рост «облачных» доходов ускорился в сравнении с предыдущими кварталами — выросли доходы от предоставления в аренду ускорителей и API-токенов.
19.08.2025 [09:11], Руслан Авдеев
SoftBank потратит $2 млрд на покупку акций IntelSoftBank Group и Intel заключили соглашение, согласно которому SoftBank инвестирует $2 млрд в акции Intel, сообщает пресс-служба производителя чипов. SoftBank обязалась заплатить по $23 за обыкновенные акции, в понедельник торги закрылись на отметке $23,66. В ходе расширенных торгов цена выросла до $25. Как стало известно CNBC, аналитическая компания FactSet рассчитывает, что инвестиции, объём которых эквивалентен порядка 2 % акций Intel, сделают SoftBank пятым по величине акционером компании, переживающей не лучшие времена. Тем не менее, это своеобразный «вотум доверия» бизнесу, который не смог эффективно воспользоваться бумом ИИ-технологий, потратив значительные средства на производственные мощности, недостаточно востребованные клиентами. В Intel объявили, что ценят доверие, оказанное компании этими инвестициями. Дело в том, что только в прошлом году акции Intel потеряли 60 % своей стоимости, что стало наихудшим результатом за более чем 50 лет истории торгов ценными бумагами компании на бирже. К закрытию торгов в понедельник акции выросли на 18 % с начала 2025 года. 
Источник изображения: Stephen Dawson/unsplash.com В последнее время Intel стала предметом дискуссий в Вашингтоне из-за важнейшей роли в IT-сфере. Это единственный американский бизнес, способный выпускать самые передовые чипы. Intel столкнулась с проблемами в развитии своего бизнеса по производству чипов для сторонних компаний, поскольку пока не смог привлечь крупных заказчиков, из-за чего откладывает дальнейшие инвестиции в это направление до получения подтверждённых заказов. Это ставит под вопрос конкурентоспособность Intel с лидерами отрасли, такими как TSMC и Samsung. На прошлой неделе глава Intel Лип-Бу Тан (Lip-Bu Tan) встретился с президентом США Дональдом Трампом (Donald Trump) после того, как тот потребовал отставки руководителя. По имеющимся данным правительство США тоже рассматривает возможность покупки доли в Intel. В то же время SoftBank становится всё более крупным игроком на рынке чипов и ИИ-технологий в целом. В 2016 году компания купила Arm, на тот момент цена сделки составила порядка $32 млрд. Сегодня компания стоит почти $150 млрд. В марте 2025 года SoftBank объявила о намерении приобрести ещё одного разработчика чипов — Ampere Computing за $6,5 млрд. Также она участвует в ИИ-проекте Stargate наряду с OpenAI и Oracle. Вместе они обязались вложить в $100 млрд на начальном этапе и до $500 млрд в следующие четыре года. Как заявляют в SoftBank, эти стратегические инвестиции отражают уверенность компании в том, что производство и поставки передовых чипов в США будут расширяться и дальше, а Intel будет играть в этом ведущую роль.
18.08.2025 [14:09], Владимир Мироненко
OpenAI намерена потратить триллионы долларов на ИИ-инфраструктуру, но для начала их надо где-то найтиГенеральный директор OpenAI Сэм Альтман (Sam Altman) рассчитывает, что со временем компания потратит на создание ИИ-инфраструктуры триллионы долларов — однако нужно найти способ привлечь такие средства для реализации его планов, пишет Bloomberg. «Следует ожидать, что OpenAI потратит триллионы долларов на строительство ЦОД в “недалёком будущем”», — заявил Альтман журналистам в ходе брифинга. Он добавил, что «кучка экономистов» назовёт это безрассудством, на что будет ответ: «Знаете что? Позвольте нам заниматься своим делом». По словам Альтмана, стартап разрабатывает новый способ финансирования. «Мы можем разработать очень интересный новый вид инструмента для финансов и вычислений, который мир ещё не изобрел», — сказал он. Ранее было объявлено, что в течение четырёх лет на инфраструктурный проект Stargate будет израсходовано $500 млрд, но Альтман предполагает выйти далеко за рамки этой суммы. 
Источник изображения: Levart_Photographer/unsplash.com Альтман также сообщил, что видит параллели между нынешним инвестиционным ажиотажем в области ИИ и пузырём доткомов в конце 1990-х годов. По его словам, в обоих случаях «умные люди» были «чрезмерно воодушевлены» новой технологией. Но в каждом случае, по его мнению, эта технология была «реальной» и в конечном итоге должна была оказать долгосрочное влияние на деловой мир и общество. Глава OpenAI заявил, что считает развитие ИИ-технологий самым важным событием за очень долгое время, отметив, что «общество в целом» вряд ли пожалеет об огромных инвестициях в ИИ, но также признал, что считает некоторые текущие оценки стартапов «безумными» и «иррациональными»: «Кто-то на этом обожжётся». Несмотря на то, что OpenAI «потратит много денег», в конечном итоге это окупится и принесёт «огромную прибыль», пообещал Сэм Альтман: «Для нас очень разумно продолжать инвестировать прямо сейчас». Планы OpenAI также включают первичное публичное размещение акций в будущем, но Альтман отказался назвать конкретные сроки проведения IPO. «Я думаю, что когда-нибудь нам, вероятно, придётся выйти на биржу», — сказал гендиректор, отметив, что он не очень «хорошо подходит» для должности гендиректора публичной компании. В настоящее время OpenAI завершает сложную корпоративную реструктуризацию, которая продолжается уже несколько месяцев, отмечает Bloomberg.
18.08.2025 [12:58], Сергей Карасёв
AAEON представила вычислительные модули на IoT-платформе MediaTek GenioКомпания AAEON анонсировала вычислительные SMARC-модули uCOM-M700 и uCOM-M510, предназначенные для использования в коммерческой и индустриальной сферах. Новинки могут применяться, в частности, для реализации человеко-машинных интерфейсов. Изделие uCOM-M700 выполнено на чипе MediaTek Genio 700 (MT8390). Этот процессор объединяет два ядра Arm Cortex-A78 с тактовой частотой до 2,2 ГГц и шесть ядер Arm Cortex-A55 с частотой до 2 ГГц. В оснащение входит графический блок Arm Mali-G57 MC3 GPU с производительностью до 4 TOPS. В свою очередь, uCOM-M510 использует процессор MediaTek Genio 510 (MT8370) с аналогичной конфигурацией вычислительных ядер, но максимальной частотой для обоих кластеров в 2 ГГц. Графический узел Arm Mali-G57 MC2 GPU обеспечивает производительность в 3,2 TOPS. 
Источник изображения: AAEON Модели могут нести на борту до 8 Гбайт оперативной памяти LPDDR4. Предусмотрен накопитель eMMC 5.1 вместимостью 16 Гбайт с возможностью расширения до 32, 64 и 128 Гбайт. Поддерживаются интерфейсы HDMI 2.0, DP 1.4 (4К × 2К @ 60 Гц), eDP 1.2 (две линии) и MIPI-DSI (четыре линии), 1GbE, USB 3.0 (×1) и USB 2.0 (×5), UART, I2S, PCIe 2.0, MIPI CSI (×2), SPI (×1), I2C (×5) и пр. Вычислительные модули имеют размеры 82 × 50 мм. Диапазон рабочих температур простирается от 0 до +60 °C. Кроме того, предлагаются версии с расширенным температурным диапазоном — от -40 до +85 °C. Заявлена совместимость с Yocto 4.0 (ядро 5.15), Ubuntu, Android 14, Debian 13 (по запросу).
18.08.2025 [11:55], Руслан Авдеев
ИИ поможет Rolls-Royce стать самым дорогим бизнесом ВеликобританииRolls-Royce сделала ставку на малые модульные ядерные реакторы (SMR). Ожидается, что это поможет удовлетворить спрос на электроэнергию со стороны ИИ ЦОД. По словам руководства компании, эта стратегия может вывести промышленного гиганта в лидеры Лондонской фондовой биржи, сообщает eWeek. На сегодня она подписала с правительством Великобритании соглашение о строительстве первых трёх SMR, каждый из которых рассчитан на выработку 470 МВт электричества. Также Rolls-Royce намерена построить шесть аналогичных реакторов в Чехии, общая мощность которых составит 3 ГВт. Возможно, будут построены и два реактора в Швеции. Кроме того, SMR компании запитают нидерландские ЦОД Equinix. По прогнозам Международного энергетического агентства (IEA), к 2050 году мировой рынок SMR может составить около £500 млрд ($678) из-за огромных энергетических потребностей ИИ. В Rolls-Royse заявили, что спрос со стороны владельцев дата-центров способствовал пятидесятипроцентному росту её полугодовой прибыли. В июле компания сообщила, что спрос на её резервные генераторы для ЦОД очень высок, заказы год к году выросли на 85 %. Ожидается рост выручки в сегменте генерации энергии в среднесрочной перспективе приблизительно на 20 % ежегодно. По оценкам компании, к 2050 году миру потребуется 400 SMR, а стоимость каждого составит до £2,2 млрд ($3 млрд), хотя со временем она будет снижаться по мере роста производства. В Rolls-Royse рассчитывают занять лидирующие позиции на рынке, благо компания уже поставляет реакторы схожей конструкции для многочисленных атомных подводных лодок. 
Источник изображения: Rolls-Royce Объём рынка оценивается в триллионы долларов, при этом в компании рассчитывают на превращение в самый дорогой бизнес Великобритании — у неё есть потенциал обогнать AstraZeneca, HSBC, Shell, Unilever и British American Tobacco. Отмечается, что подразделение Rolls-Royce SMR опережает конкурентов на полтора года в плоскости соблюдения всех европейских нормативных требований. Обладая преимуществами «первопроходца», компания имеет все шансы стать мировым лидером в сфере технологий SMR и создать ключевую экологически чистую технологию Великобритании «на экспорт». Вместе с тем глава Rolls-Royce признаёт, что SMR — непроверенная технология, поскольку ни одного коммерческого реактора такого типа не запущено. Кроме того, хотя такие реакторы должны строиться быстрее традиционных АЭС, высока вероятность, что они всё равно окажутся дорогими, ядерных отходов от них будет не меньше, а обеспечить их безопасность будет сложнее. Более того, энергоёмкие ЦОД, часто строящиеся в засушливых районах, сами по себе потребляют немало воды. SMR же могут дать дополнительную нагрузку на системы водоснабжения, что только усугубит проблему. Тем не менее, техногиганты готовы вкладывать немалые средства в развитие SMR-разработок, пытаясь обеспечить ИИ «чистой» энергией. Google поддерживает проект Kairos Power, являющийся частью федеральной инициативы на $300 млн. Meta✴ подписала контракт на 20 лет с Constellation, предполагающий поставки электроэнергии АЭС Clinton в Иллинойсе, энергокомпания изучает возможность строить SMR на этой площадке. Amazon (AWS) заключила три соглашения, поддерживающие строительство SMR в США. В целом Google, Meta✴ и Amazon также пообещали поддержать глобальные усилия по наращиванию втрое атомных мощностей к 2050 году, призвав ускоренно внедрять новые реакторы в энергетическом секторе.
18.08.2025 [10:10], Руслан Авдеев
Rio AI City: Рио-де-Жанейро станет ИИ-городом при поддержке NVIDIA и OracleВласти Рио-де-Жанейро (Бразилия) анонсировали стратегическое партнёрство с Oracle и NVIDIA. Мэр мегаполиса Эдуардо Паес (Eduardo Paes) объявил о реализации проекта Rio AI City, который призван превратить город в один из главным мировых центров в сфере ИИ, сообщает Datacenter Dynamics. Ведутся переговоры и с другими крупными компаниями. По мнению Паеса, Рио станет ИИ-столицей Бразилии, куда «все захотят». Город закупит оборудование NVIDIA и вычислительные мощности у Oracle. NVIDIA подписала меморандум о взаимопонимании с местной мэрией, предусматривающей покупку ускорителей для ИИ-модели, которую муниципалитет собирается внедрять в рамках проекта Rio AI City. Ещё одно соглашение предусматривает участие в проекте Oracle. Сегодня Oracle управляет в Бразилии двумя облачными регионами — в Сан-Паулу и его окрестностях. Регион Brazil East открыли в 2020 году, а регион Brazil Southeast в соседнем муниципалитете Виньеду — в 2021 году. 
Источник изображения: Raphael Nogueira/unsplash.com Rio AI City будет реализован под руководством компании Elea Data Centers, которая строит гигаваттный кампус к западу от Рио, где у неё уже имеется действующий ЦОД RJO1 — он станет первым дата-центром проекта, хотя действует ещё с Олимпийских игр 2016 года. В Elea Data Centers подчеркнули, что многостороннее партнёрство позволяет сделать шаг к реализации проекта Rio AI City — это проект с надёжной инфраструктурой и «чистой» энергией, готовый привлечь таланты и компании, которые станут формировать будущую цифровую эру Бразилии. Завершение строительства 80-МВт RJO2 запланировано на 2026 год. После него будут построены RJO3 и RJO4, которые добавят кампусу ещё 120 МВт. Уже к 2027 году мощность проекта может вырасти до 1,5 ГВт, а к 2032 году — до 3,2 ГВт, благодаря чему Rio AI City превратится в один из крупнейших ЦОД в мире. Впрочем, за это звание ещё придётся побороться.
18.08.2025 [08:59], Руслан Авдеев
Необычные воздушно-алюминиевые генераторы Phinergy пропишутся в ЦОД СШАРазрабатывающая энергетические решения израильская компания Phinergy заключила соглашение с американской электротехнической компанией Rosendin для развёртывания инновационных воздушно-алюминиевые генераторов (AAG) в американских ЦОД, сообщает Datacenter Dynamics. Phinergy была основана в 2009 году, а в 2021 году вышла на IPO в Тель-Авиве. В марте того же года было создано совместное предприятие с Indian Oil для развития систем «воздух-алюминий» в Индии. Rosendin, базирующаяся в Калифорнии, заключила несколько партнерских соглашений в секторе ЦОД для поддержки интеграции систем хранения энергии на базе аккумуляторов и и иных технологий. В рамках партнёрства предлагается замена резервных дизель-генераторов критически важных объектов на AAG Phinergy, которые позволяют генерировать энергию практически без вредных выбросов (в первую очередь CO2), если не считать отработавшие химические компоненты. Алюминиево-воздушные батареи — это первичный химический источник питания, где алюминий (анод) окисляется кислородом воздуха, который восстанавливается на катоде. Такая батарея имеет высокую энергоёмкость, но перезарядить её от другого источника тока невозможно — после того, как алюминий будет израсходован, её нужно заменять. Ключевое преимущество AAG заключается в высокой ёмкости и вместе с тем лёгкости батарей. По словам Phinergy, её AAG способны обеспечить приблизительно 10 МВт∙ч/м3, а дизельное топливо — 4 МВт∙ч. При этом обещано, что AAG будут дешевле дизеля. 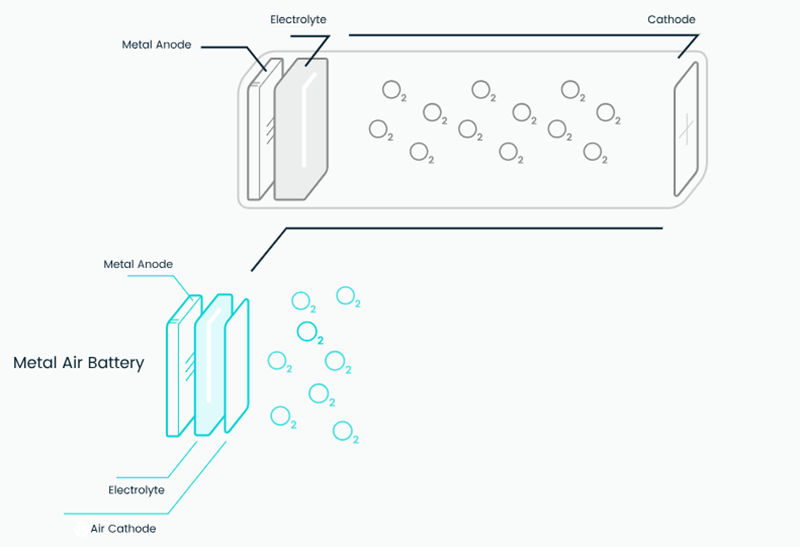
Источник изображения: Phinergy Phinergy ориентируется на дата-центры как на ключевых потребителей своих решений и утверждает, что её батареи способны обеспечить отказоустойчивую работу ЦОД гиперскейл-уровня в течение нескольких дней. В компании подчёркивают, что сотрудничество с Rosendin станет новым этапом для масштабирования воздушно-алюминиевой технологии в секторе ЦОД, одном из самых быстрорастущих энергетических рынков. В Rosendin же заявляют, что новое решение отвечает растущей потребности ЦОД в надёжном, безуглеродном энергоснабжении в связи с расширением рынка дата-центров. Технология Phinergy также была выбрана европейской организацией Net Zero Innovation Hub for Data Centers, куда входят Data4, Google, Microsoft, Vertiv и Schneider Electric, выбрал её в качестве ключевой технологии для ускорения перехода к ЦОД с нулевыми выбросами. Это позволит компании масштабироваать свои системы резервного питания до мегаваттного уровня и ускорить их развёртывание. Современным ИИ ЦОД действительно требуются гигантские системы резервного питания.
17.08.2025 [18:08], Руслан Авдеев
Google потратит $9 млрд на развитие облачной и ИИ-инфраструктуры в Оклахоме — часть пойдёт на обучение электриковКомпания Google взяла обязательство вложить $9 млрд в расширение собственной облачной и ИИ-инфраструктуры на территории штата Оклахома (США). Инвестиции направят на развитие кампуса ЦОД в Стиллуотере (Stillwater) и расширение уже имеющегося объекта в Прайоре (Prior), сообщает Datacenter Dynamics. Часть выделенных средств будет потрачена на программы образования и развития персонала. В марте 2025 года стало известно, что Google подала заявку на строительство кампуса ЦОД в Стиллоутере. Тогда было объявлено, что на него потратят $3 млрд, а площадь кампуса составит более 160 га. Подробных данных о кампусе нет, но согласно проекту плана экономического развития от августа 2024 года, предполагается построить до шести зданий, каждое площадью почти 29 тыс. м2. На каждом этапе строительства предполагается строить по одному ЦОД. Объект в Прайоре Google анонсировала ещё в 2007 году, запуск состоялся в 2011-м. С тех пор дата-центр регулярно расширялся. Университет Оклахомы (University of Oklahoma) и Университет штата Оклахома (Oklahoma State University) готовы участвовать в инициативе Google AI for Education Accelerator. В её рамках можно будет получить сертификаты Google Career Certificates, а также доступ к бесплатным курсам обучения ИИ-навыкам. Также Google финансирует в Оклахоме национальную программу обучения, созданную для подготовки квалифицированных электриков — Electrical Training Alliance. 
Источник изображения: Gerson Repreza/unsplash.com Ранее Оклахома никогда не считалась крупным рынком ЦОД и сопутствующих технологий. Среди недавно анонсировавших проекты ЦОД в Оклахоме — компании Cerebras, Damac и CoreWeave с Core Scientific. По слухам, кампус площадью около 138 га готовит и Meta✴. Также есть данные, что в мае подана заявка на строительство кампуса площадью более 200 га в Талсе (Tulsa), но что за компания стоит за проектом, не разглашается.
17.08.2025 [14:15], Сергей Карасёв
Inspur разработала СЖО для мегаваттных стоек с 3-кВт ИИ-ускорителямиКитайская компания Inspur Information представила передовую систему двухфазного жидкостного охлаждения для ИИ-платформ следующего поколения, таких как суперускоритель Metabrain SD200. Решение может использоваться для отвода тепла от серверных стоек мегаваттного класса. Inspur отмечает, что из-за стремительного развития ИИ наблюдается тенденция к повышению плотности вычислений. Это приводит к быстрому увеличению энергопотребления стоек с серверным оборудованием. Различные компании, такие как Aligned, JetCool и CyrusOne, разрабатывают решения для стоек мощностью 300 кВт, тогда как крупные ЦОД-операторы и гиперскейлеры готовятся к появлению мегаваттных установок. В таких условиях возможностей стандартных систем охлаждения становится недостаточно. 
Источник изображения: Inspur Двухфазная СЖО Inspur способна охлаждать кристаллы мощностью более 3000 Вт, тогда как показатель теплосъёма превышает 250 Вт на квадратный 1 см2. Благодаря изоляции хладагента предотвращается коррозия, что сводит к минимуму риск коротких замыканий, снижает износ и отказы компонентов, говорит компания. Ключевыми преимуществами новой СЖО названы надёжность и долговечность, отсутствие утечек, простота эксплуатации, безопасная работа IT-оборудования, а также уменьшение общей стоимости владения по сравнению с другими аналогичными решениями. При разработке системы специалистам Inspur Information удалось преодолеть узкие места управления температурой и давлением фазового перехода, а также решить проблемы дисбаланса потока и перегрева во время скачков нагрузки: утверждается, что в конфигурации с 200 чипами отклонение распределения потока составляет менее 10 %, а разница температур — менее 2 °C. Применяется специально разработанный хладагент низкого давления, который безопасен для окружающей среды. Несмотря на отсутствие риска утечки, рабочее давление системы составляет менее 1 МПа.
16.08.2025 [15:16], Сергей Карасёв
Inspur представила суперускоритель Metabrain SD200 для ИИ-моделей с триллионами параметровКитайская компания Inspur создала суперускоритель Metabrain SD200 для наиболее ресурсоёмких задач ИИ. Система, как утверждается, может работать с моделями, насчитывающими более 1 трлн параметров. Платформа Metabrain SD200 объединяет 64 карты в единый суперузел с унифицированной памятью. В основу положены открытая архитектура 3D Mesh и проприетарные коммутаторы Open Fabric Switch. Иными словами, ускорители на базе GPU, распределённые по разным серверам, объединяются посредством высокоскоростного интерконнекта в единый домен. Суперускоритель предоставляет доступ к 4 Тбайт VRAM и 64 Тбайт основной RAM. Благодаря этому возможен одновременный запуск четырёх китайских ИИ-моделей с открытым исходным кодом, включая DeepSeek R1 и Kimi K2. Кроме того, поддерживается совместная работа нескольких ИИ-агентов в режиме реального времени. 
Источник изображения: Inspur Для Metabrain SD200 заявлена низкая задержка при передаче данных, которая исчисляется «сотнями наносекунд». В распространённых сценариях инференса, предполагающих обработку небольших пакетов данных, по величине задержки система превосходит распространённые отраслевые решения. В составе новой платформы задействованы средства оптимизации. В частности, инструмент Smart Fabric Manager автоматически формирует оптимальные маршруты данных на основе характеристик нагрузки. Metabrain SD200 совместим с распространёнными фреймворками, такими как PyTorch, vllm и SGLang: благодаря этому возможен быстрый перенос существующих моделей и ИИ-агентов без необходимости переписывать программный код с нуля. Таким образом, значительно снижается стоимость миграции. В целом, реализованная технология удалённого vGPU позволяет ускорителям, распределённым по разным серверам, взаимодействовать столь же эффективно, как если бы они находились на одном хосте. При этом достигается восьмикратное расширение адресного пространства, что обеспечивает полную загрузку ресурсов и эффективную работу даже при использовании ИИ-моделей с триллионами параметров. |
|