Материалы по тегу: cpu
|
27.02.2025 [12:51], Сергей Карасёв
Представлен Armv9-процессор Cortex-A320 для IoT-устройств с ИИ-функциямиКомпания Arm анонсировала процессор Cortex-A320 — своё первое сверхэффективное изделие семейство Cortex-A, построенное на архитектуре Armv9. Чип ориентирован на периферийные устройства и IoT-оборудование с поддержкой ИИ-функций. В основу новинки положена архитектура версии Armv9.2-A (Harvard) с поддержкой расширений QARMA3, SVE2, MTE, RAS и криптографическими функциями. Объём кеша первого уровня может составлять 32 или 64 Кбайт. Опционально доступен кеш L2 ёмкостью от 128 до 512 Кбайт, тогда как кеш L3 не предусмотрен. Кроме того, существенно ускорена работа с оперативной памятью. Cortex-A320 — это одноядерный процессор с последовательной выборкой 32-битных инструкций. Благодаря многочисленным обновлениям микроархитектуры, таким как предсказание ветвлений и предварительные выборки, достигается повышение эффективности на 50 % по сравнению с Cortex-A520 и увеличение быстродействия на 30 % в SPECINT2K6 по сравнению с Cortex-A35. 
Источник изображения: Arm По заявлениям Arm, процессор Cortex-A320 обеспечивает 10-кратное повышение производительности на операциях машинного обучения по сравнению с Cortex-A35 (на GEMM int8) и 6-кратное повышение по сравнению с Cortex-A53, самым популярным в мире изделием на архитектуре Armv8-A. На сегодняшний день Cortex-A320 — это наиболее эффективное решение серии Cortex-A для задач машинного обучения. На базе Cortex-A320 могут формироваться кластеры, насчитывающие до четырёх ядер. Блок векторной обработки с технологиями NEON и SVE2 может быть индивидуальным для каждого ядра или использоваться связкой из двух ядер, в том числе в четырёхъядерной конфигурации. Благодаря DSU-120T (оптимизированная версия DynamIQ Shared Unit) возможно формирование кластеров исключительно с ядрами Cortex-A320. Кроме того, новинки поддерживают NPU Ethos-U85, которые позволяют автоматически перекидывать обработку неподдерживаемых типов данных и инструкций на SIMD-блоки Cortex-A320. В целом говорится о возможности запуска на новых чипах моделей с более чем 1 млрд параметров. Процессор Cortex-A320 может применяться в самых разных сферах — от умных колонок и интеллектуальных камер наблюдения до автономных транспортных средств и контроллеров служебных роботов. Кроме того, новый процессор подходит для микроконтроллеров с батарейным питанием и устройств, работающих под управлением операционных систем реального времени (RTOS). Реализованы развитые средства обеспечения безопасности, включая Secure EL2 (Exception Level 2).
25.02.2025 [23:20], Владимир Мироненко
Intel: 288-ядерные процессоры Xeon 6900E — нишевый продуктКомпания Intel провела в понедельник презентацию ряда новых чипов, включая серию серверных процессоров Xeon 6700P и 6500P среднего класса, в ходе которой объявила, что представленный в прошлом году 288-ядерный серверный процессор Xeon 6900E (Sierra Forrest-AP) не будет «широко распространяться» среди OEM-производителей, поскольку его главные потребители — пользователи облачных вычислений с индивидуальными потребностями в чипах, передаёт CRN. Intel добавила, что Xeon 6900E, являющийся флагманом семейства процессоров Xeon 6 Sierra Forest с энергоэффективными ядрами (E-cores), сейчас находится в производстве. Ронак Сингал (Ronak Singhal), старший научный сотрудник Intel и главный архитектор чипов Xeon рассказал, что Xeon 6900E предназначен для удовлетворения потребности облачных клиентов в кастомных чипах. По его словам, один из крупных клиентов уже запустил системы на базе Xeon 6900E. Ранее было объявлено, что компания будет выпускать для AWS кастомные Xeon 6 и ИИ-ускорители. 
Источник изображения: Intel По словам топ-менеджера Intel, те, кому действительно требуется очень большее количество ядер в процессорах обычно относятся к тем клиентам, с которыми компания обычно работает над индивидуальными решениями. За несколько недель до этого Мишель Джонстон Холтхаус (Michelle Johnston Holthaus), врио главы Intel и гендиректор Intel Products, заявила в ходе отчёта о квартальных результатах, что линейка Xeon 6 с E-ядрами не имеет той поддержки, на которую были надежды, также отметив, что это нишевый продукт. 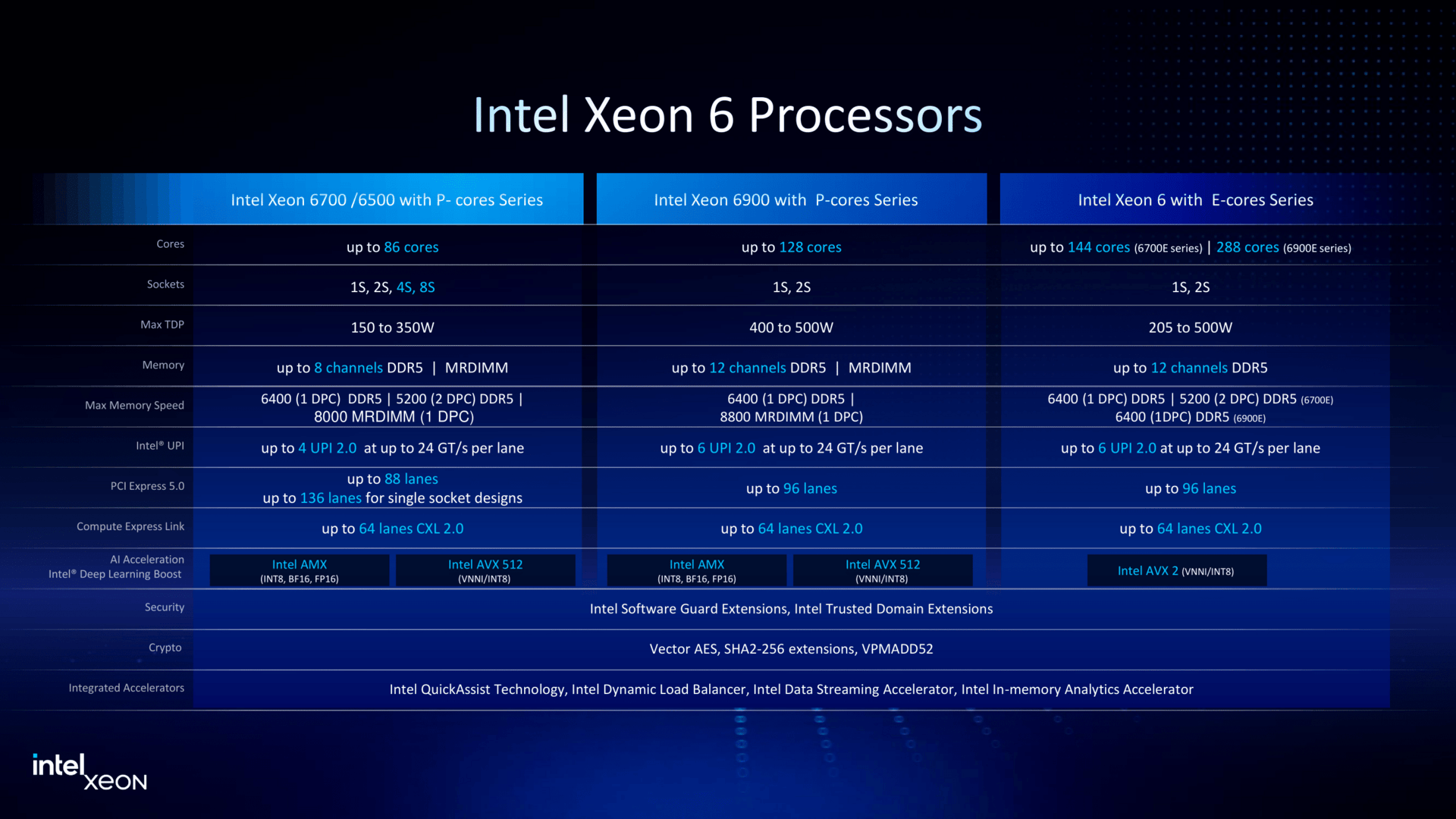
Источник изображения: Intel Несмотря на то, что это семейство Xeon 6 с E-ядрами пока не оправдывает ожиданий, Холтхаус заявила, что Intel по-прежнему возлагает большие надежды на процессоры Xeon следующего поколения с E-ядрами Clearwater Forest, хотя их выпуск пришлось отложить до I половины 2026 года из-за возникших сложностей с технологией упаковки, хотя до этого их планировалось выпустить уже в 2025 году. Clearwater Forest рассматривается компанией как стратегически важный продукт, поскольку он станет первым серверным процессором, использующим техпроцесс Intel 18A, который, как неоднократно заявляла компания, позволит ей превзойти возможности чипов, произведённых TSMC и Samsung. За несколько месяцев до того, как Гелсингер покинул компанию, он заявил, что чип позволит Intel «ускорить рост доли» на рынке.
25.02.2025 [18:30], Владимир Мироненко
Granite Rapids в малом формате: Intel представила процессоры Xeon 6500P и 6700PIntel объявила о пополнении семейства процессоров Xeon 6 рядом новинок, включая чипы Granite Rapids-SP Xeon 6700P и 6500P, предназначенные для использования в ЦОД. Одновременно компания представила младшую серию Xeon 6300 для серверов начального уровня, а также Xeon 6 SoC поколения Granite Rapids-D с ускорителями vRAN Boost. Как отметил ресурс The Register, в отличие от Intel Xeon 6900P (Granite Rapids-AP), в новых чипах Xeon с P-ядрами компания не пыталась сравниться с AMD по количеству ядер или чистой вычислительной мощности. Успешно восстановив паритет по количеству ядер со своим конкурентом в сегменте чипов с архитектурой x86, Intel в значительной степени опирается на то, что осталось от её репутации на рынке — на свой набор ускорителей вычислений и более агрессивную ценовую политику — в попытке остановить снижение своей доли в секторе чипов для ЦОД.  В Xeon 6 компания перешла на чиплетную компоновку, отделив I/O-тайлы (Intel 7) от вычислительных тайлов (Intel 3), но сохранив контроллеры памяти в составе последних. В случае 6700P и 6500P I/O-тайлы фактически те же, а вот блоки с ядрами отличаются. В старших 86-ядерных чипах используется пара XCC-чиплетов. В 48-ядерных и 16-ядерных чипах есть по одному вычислительному HCC- и LCC-тайлу соответственно. Это повышает выход годной продукции и позволяет гибко подходить к выбору количества ядер и тактовых частот — до +22 ядер при том же TDP (150–350 Вт) в сравнении с прошлым поколением.  В то же время такой подход ограничивает количество доступных каждому процессору каналов памяти — их в 6500P/6700P всего восемь с возможностью установки до 4 Тбайт RAM. Поддерживается DDR5-6400 (1DPC) и DDR5-5200 (2DPC). С другой стороны, для двухсокетных серверов с 32 DIMM не придётся изощряться с размещением слотов памяти, сохранив традиционную архитектуру плат, охлаждения и шасси в целом. Кроме того, некоторые CPU помимо обычных модулей также поддерживают MRDIMM DDR5-8000 (1 DPC). Наконец, есть и поддержка до 64 линий CXL 2.0, что теоретически также позволит нарастит доступную память. 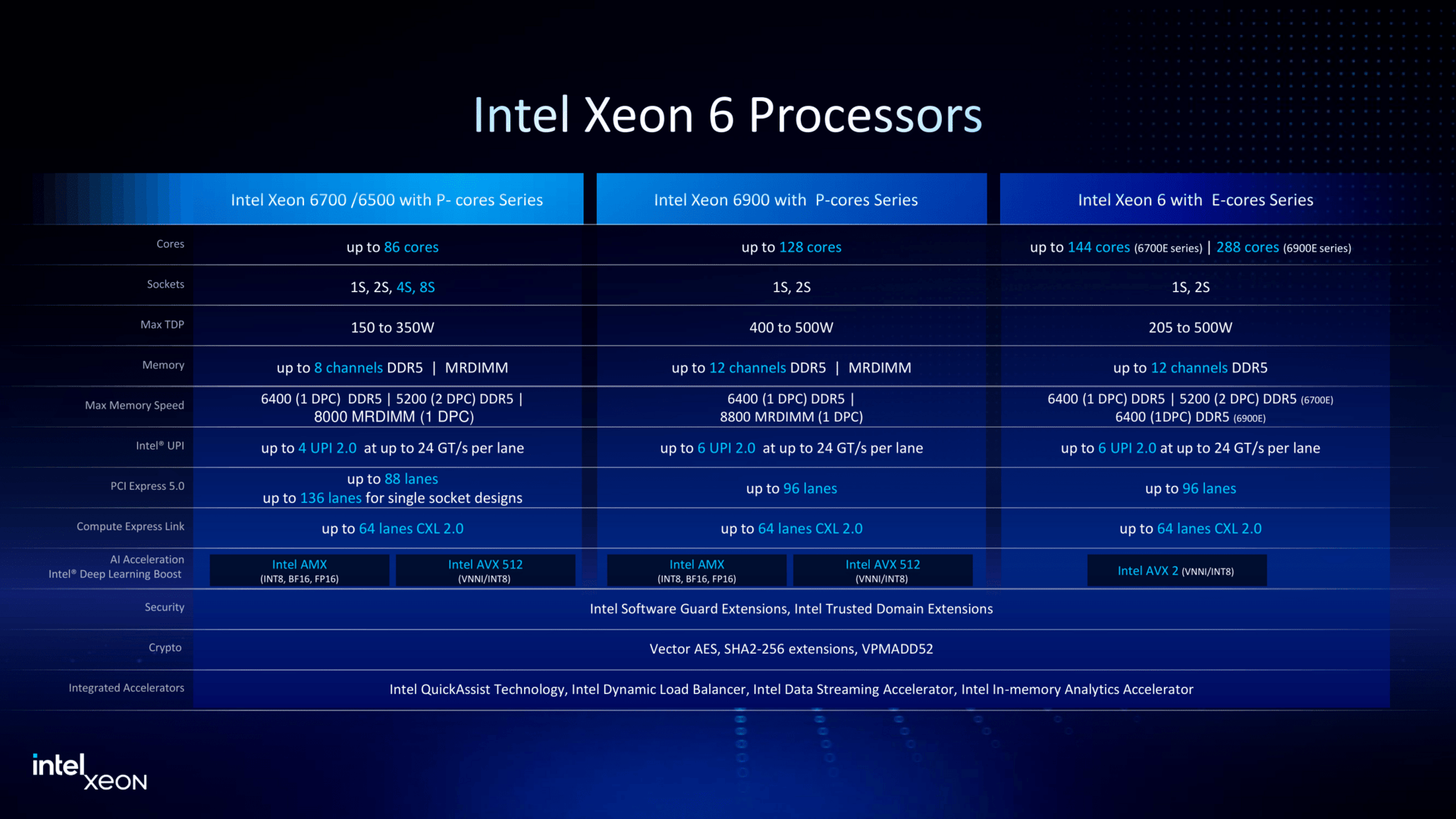 В односокетных конфигурациях R1S-чипы поддерживают до 136 линий PCIe 5.0 (взамен ненужных UPI) против 88 линий у обычных многосокетных процессоров. В новых CPU также вернулась поддержка 4S- и 8S-конфигураций (до четырёх линий UPI 2.0 24 ГТ/с на CPU), которой были лишены и Emerald Rapids, и Xeon 6 6900P. Таким образом, Intel по-прежнему остаётся единственным поставщиком многосокетных x86-платформ для SAP HANA и аналогичных рабочих нагрузок, которым требуется одновременно много памяти и много ядер, а по сравнению с Sapphire Rapids новинки значительно быстрее. Объём L3-кеша теперь составляет от 48 Мбайт до 336 Мбайт. 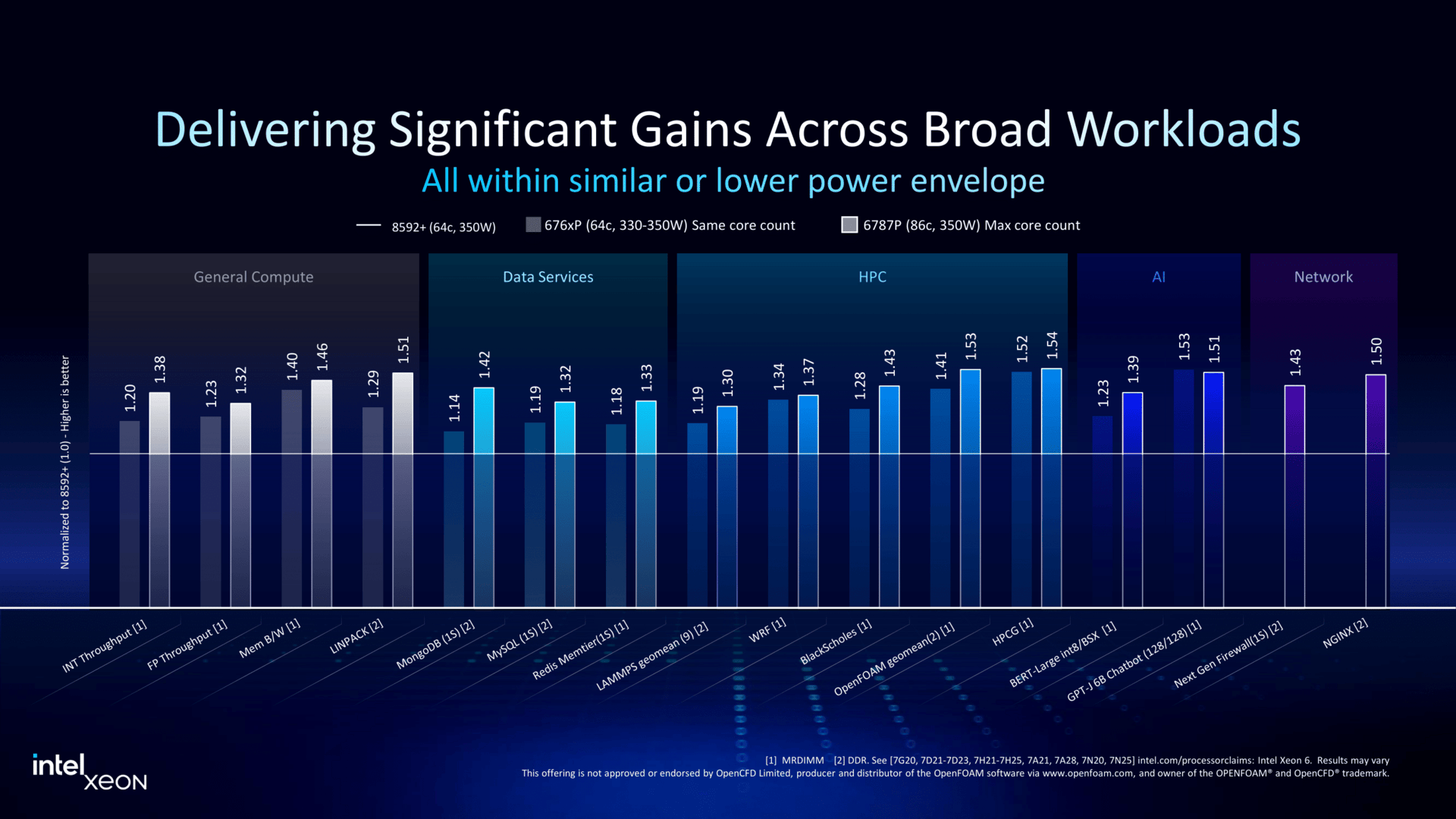 Intel заявила, что чипы серии 6700P обеспечат от 14 % до 54 % прироста производительности по сравнению с флагманскими чипами Xeon Emerald Rapids. Intel по-прежнему в значительной степени опирается на интегрированные ускорители, чтобы получить преимущество по производительности по сравнению с конкурентами. Компания уже много лет встраивает кастомные ускорители в процессоры для выполнения нагрузок шифрования, безопасности, хранения, аналитики, обработки сетевого трафика и ИИ. В то же время у некоторых моделей по-прежнему активно лишь по два или три, а не по четыре акселератора DSA/DLB/IAA/QAT. Ещё одно отличие — поддержка 1024 или 2048 ключей TDX для защиты конфиденциальности в зависимости от модели. Примечательно, что NVIDIA добавила в Blackwell поддержку TDX.  Intel утверждает, что в дополнение к увеличению числа ядер и инструкций за такт (IPC) в новом поколении процессоров с криптографическими движками и поддержкой AMX это позволяет одному серверному чипу Xeon 6 заменить до десяти систем Cascade Lake, по крайней мере, для таких рабочих нагрузок, как классификация изображений и работа веб-сервера Nginx с TLS. По словам Intel, её новые чипы обеспечивают преимущество по сравнению с новейшими процессорами AMD EPYC Turin в производительности в 62 % для Nginx с TLS, 17 % для MongoDB, 52 % в бенчмарке HPCG, 43 % в программной среде OpenFOAM и 2,17x в ResNet-50. 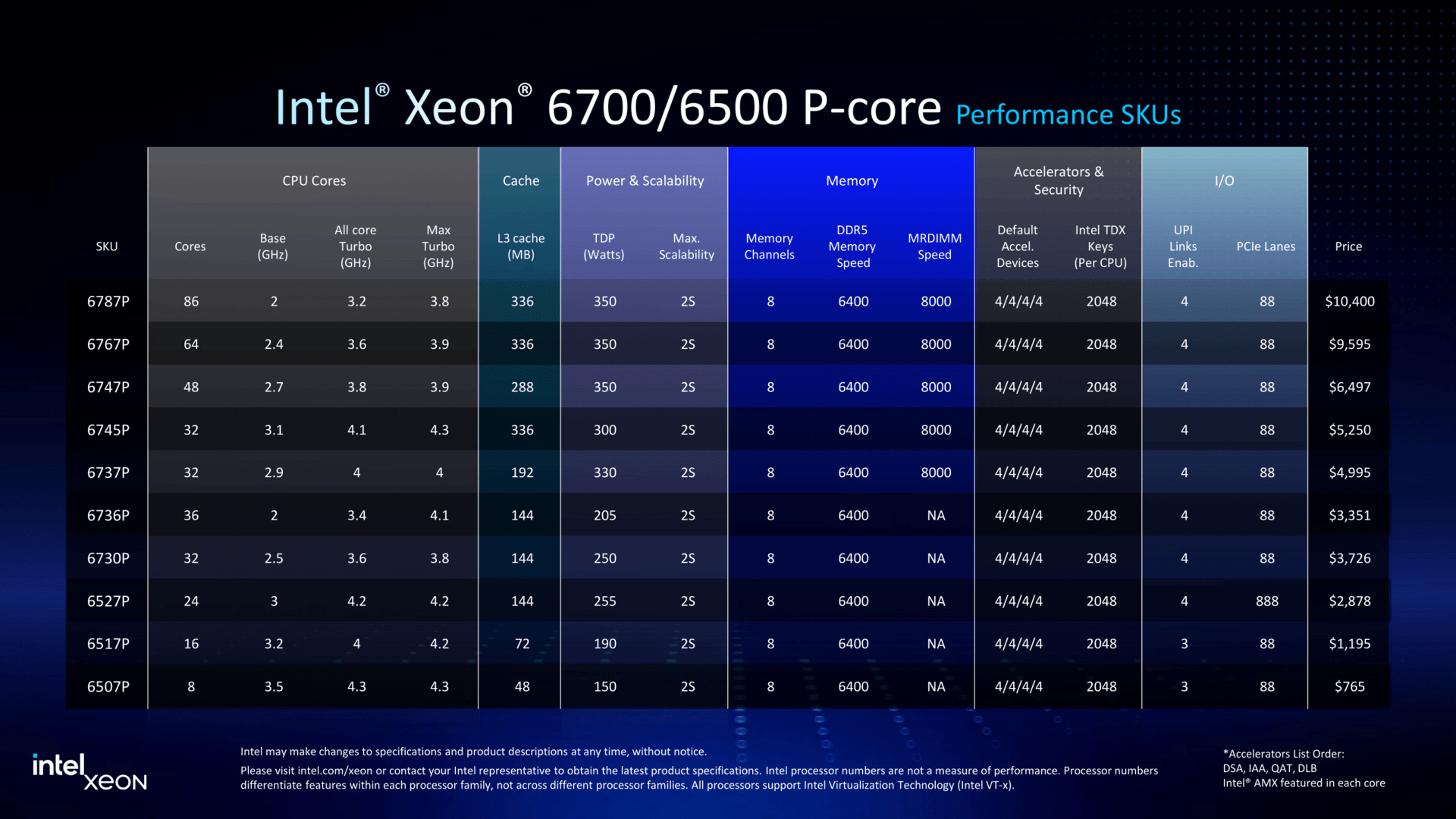 The Register также отметил, что выход процессоров Intel Xeon 6 серий 6700P и 6500P демонстрирует выросшую агрессивнось Intel в отношении ценообразования. Intel традиционно дороже из расчёта за ядро по сравнению с AMD. Но теперь Intel пытается соответствовать своему конкуренту в ценах при любом количестве ядер или на целевых рынках. Компания даже незаметно снизила цены на 6900P в конце прошлого года, всего через несколько месяцев после запуска. 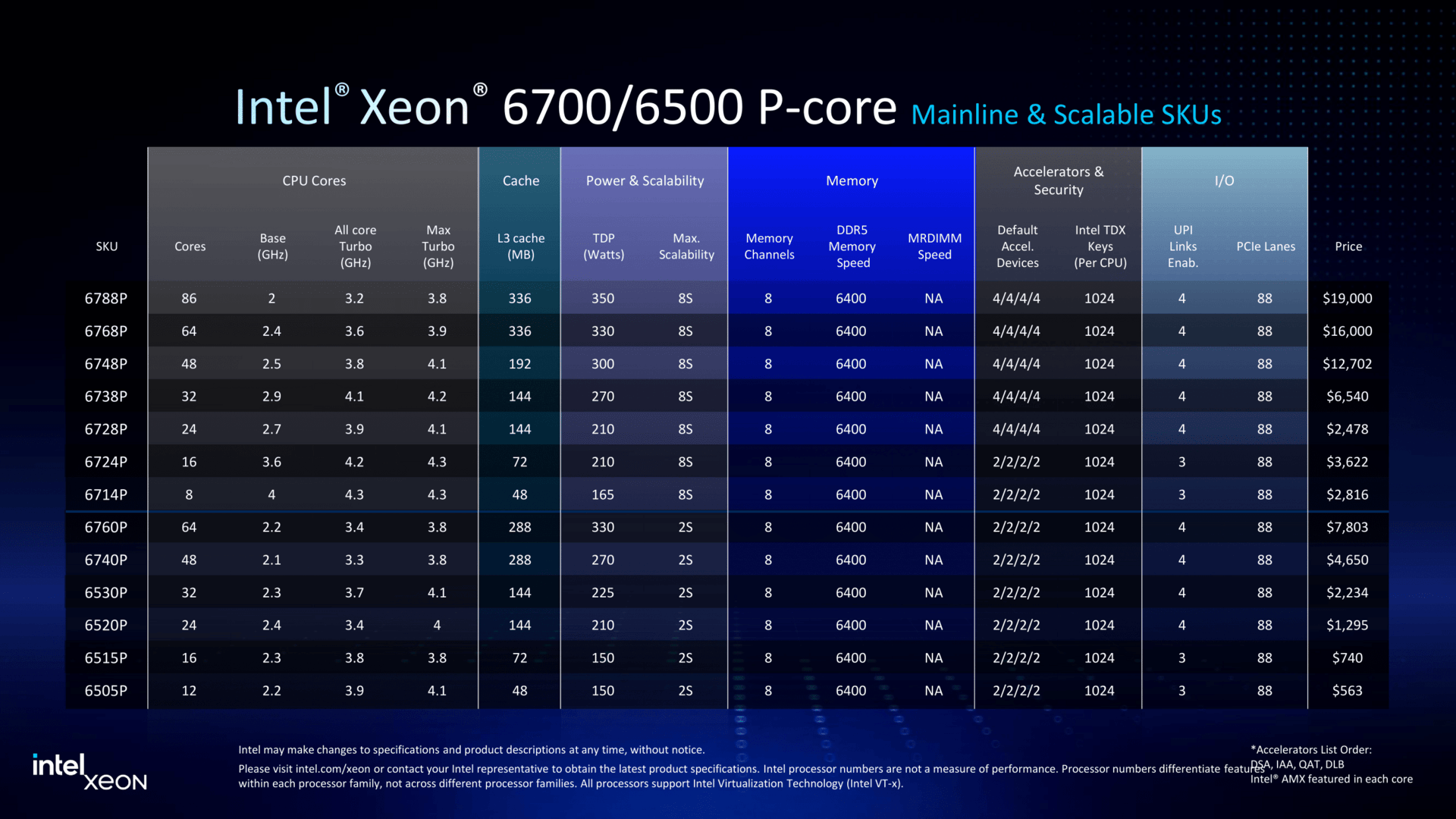 Единственным исключением являются поддерживающие 4S- и 8S-конфигурации процессоры, у которых нет конкурентов на рынке x86-чипов. Стоимость CPU доходит до $19 тыс./шт. Естественно, здесь стоит сделать традиционную оговорку, что и AMD, и у Intel рекомендованные цены указаны за партии от 1 тыс. шт., но на практике их реальная стоимость будет варьироваться в зависимости от объёма заказа и нужд конкретного клиента, да и просто договорённостей с продавцами, интеграторами и другими участниками цепочки поставок. 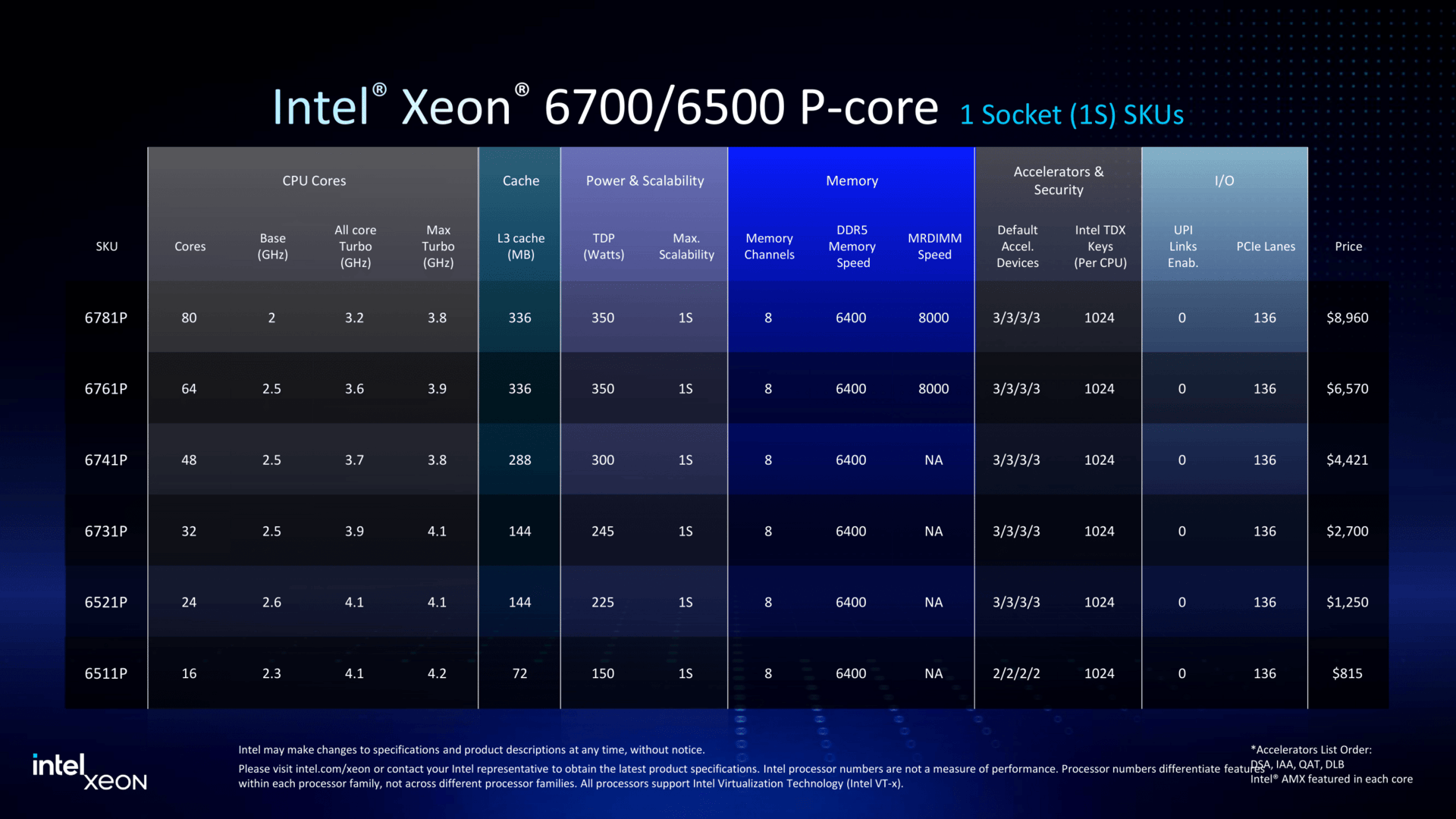 Наконец, у Intel появилось одно неожиданное преимущество перед AMD — «кремний» Xeon по-прежнему делается на собственных фабриках в США, тогда как AMD всё ещё зависит от тайваньской TSMC. Если новая администрация США введёт тариф на импорт полупроводников в размере 25 % и более, то Intel Xeon 6 наверняка окажутся выгоднее AMD EPYC. Intel также объявила, что Xeon 6 рекомендуются в качестве хост-процессоров для платформ NVIDIA MGX и HGX. Заявлена и поддержка OCP DC-HMS.
25.02.2025 [13:00], Сергей Карасёв
Granite Rapids-D для 5G с ИИ: дебютировали чипы Intel Xeon 6 SoC для сетевых и периферийных устройствКорпорация Intel представила чипы Xeon 6 SoC семейства Granite Rapids-D, рассчитанные на использование в сетевом оборудовании, а также встраиваемых устройствах с ИИ-функциями. Чипы поддерживают технологию Intel QAT (QuickAssist Technology) для ускорения криптографических операций, компрессии и обработки сетевого трафика. На сегодняшний день в серию Xeon 6 SoC вошли 13 моделей с количеством вычислительных ядер от 12 до 42. Все они имеют четыре канала памяти DDR5 с частотой 4800, 5600 или 6400 МГц. Показатель TDP находится в диапазоне от 110 до 235 Вт, а турбо-частота при использовании всех ядер достигает 2,9 ГГц.  Большинство процессоров располагают интегрированным контроллером Ethernet 200G или 100G (за исключением Xeon 6533P-B). Некоторые модификации обладают поддержкой vRAN Boost и содержат ускоритель для транскодирования медиаданных. При этом все изделия поддерживают расширения AMX (Advanced Matrix Extensions), обеспечивающие ускорение рабочих нагрузок ИИ и машинного обучения. 
Источник изображений: Intel На вершине семейства находится чип Xeon 6726P-B с 42 ядрами, TDP 235 Вт, базовой частотой 2,3 ГГц (повышается до 2,9 ГГц), поддержкой четырёхканальной памяти DDR5-6400 и 200GbE-контроллером: стоит изделие $3795. Младшая версия Xeon 6503P-B с 12 ядрами, TDP в 110 Вт, частотой 2,0–2,6 ГГц, поддержкой DDR5-4800 и 100GbE-контроллером оценена в $934. 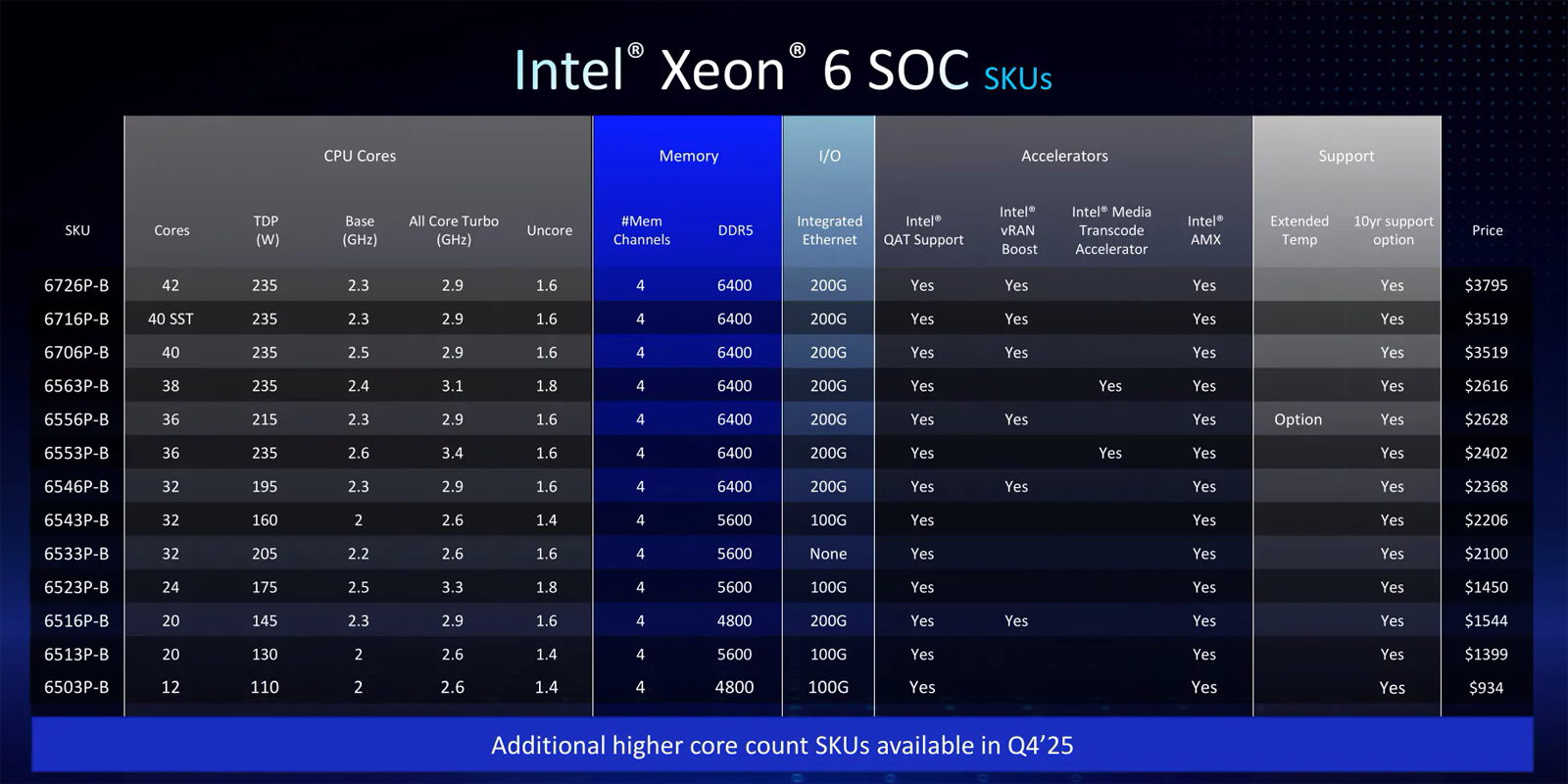 Отмечается, что в IV квартале текущего года серия Xeon 6 SoC пополнится вариантами, насчитывающими до 72 вычислительных ядер. Кроме того, корпорация Intel сообщила, что процессоры следующего поколения Clearwater Forest на основе энергоэффективных ядер E-Core, которые придут на смену Sierra Forest, будут выпущены в I половине 2026 года.
25.02.2025 [12:45], Сергей Карасёв
Привет из 2019-го: Intel представила восьмиядерные процессоры Xeon 6300 для серверов начального уровняКорпорация Intel анонсировала процессоры Xeon 6300, о подготовке которых стало известно около недели назад. Чипы рассчитаны на применение в серверах начального уровня — прежде всего в односокетных моделях. Как отмечается, изделия Xeon 6300 представляют собой обновление семейства Xeon E-2400, дебютировавшего в декабре 2023 года. Обе серии относятся к поколению Raptor Lake. При этом, по заявлениям Intel, по производительности Xeon 6300 превосходят предшественников в 1,3 раза. Платформа Xeon 6300 обеспечивает поддержку до 128 Гбайт двухканальной оперативной памяти DDR5-4800 (ЕСС), до 16 линий PCIe 5.0 (CPU) и до 24 линий PCIe 4.0 (CPU + PCH), а также до 15 портов USB 3.2. 
Источник изображений: Intel В основу процессоров Xeon 6300 положены производительные Р-ядра. На сегодняшний день серия включает восемь моделей с четырьмя, шестью и восемью ядрами, поддерживающими технологию многопоточности (8, 12 или 16 потоков инструкций). Максимальная тактовая частота в турбо-режиме достигает 5,7 ГГц (см. таблицу). Объем кеша L3 в зависимости от модели составляет 12, 18 или 24 Мбайт. Показатель TDP варьируется от 55 до 95 Вт. Цена — от $199 до $545. 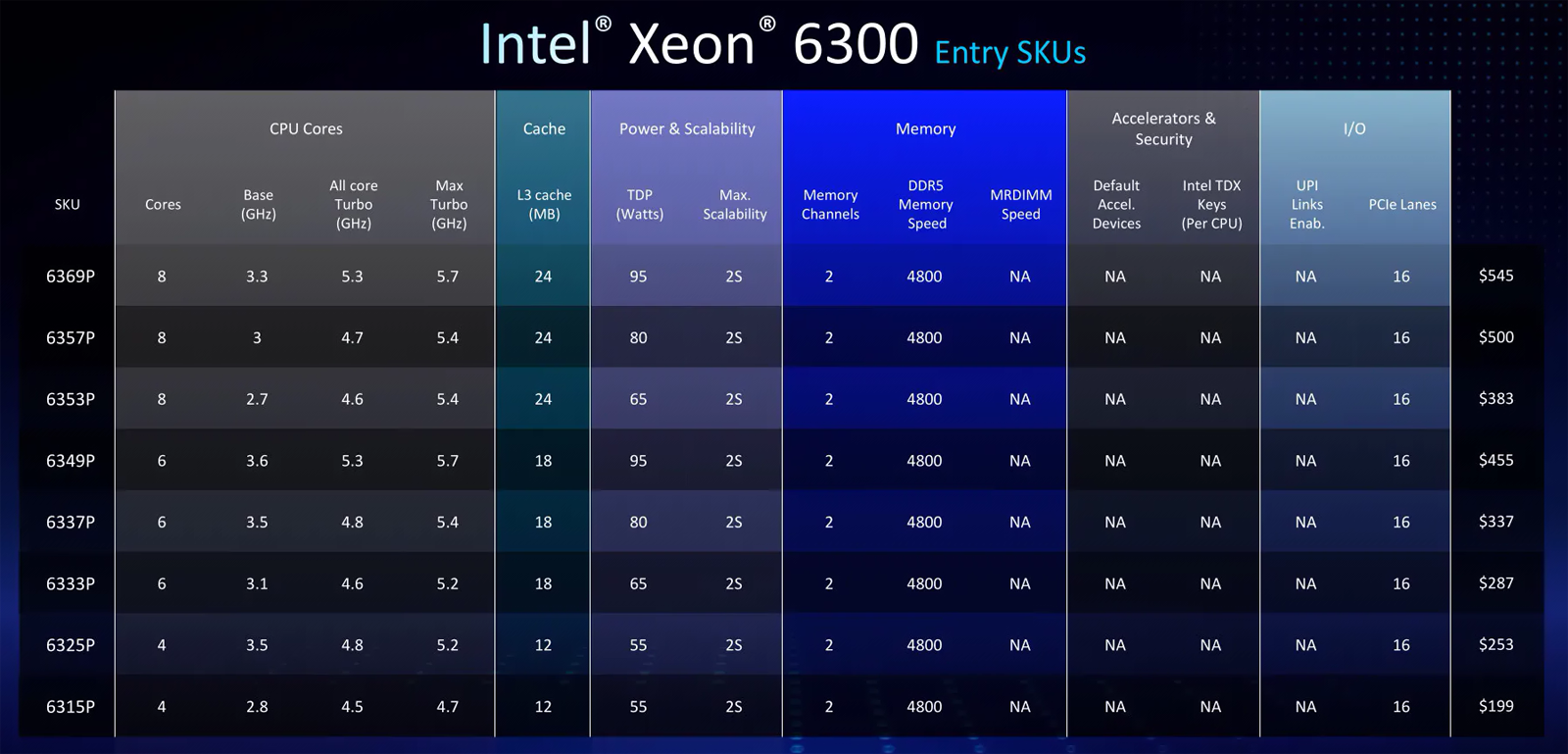 Как отмечает ServeTheHome, процессорам Xeon 6300 будет трудно конкурировать с существующими чипами AMD EPYC 4004, которые содержат до 16 ядер (32 потока инструкций). Поэтому анонс Xeon 6300 следует рассматривать скорее в качестве унификации брендинга серверных чипов Xeon и незначительного апдейта ранее существовавших изделий Xeon E-2400. Кстати, отдельные материнские платы и серверы под Xeon E-2400 совместимы с процессорами Xeon 6300.
17.02.2025 [12:22], Сергей Карасёв
Intel выпустила процессоры Twin Lake с четырьмя и восемью ядрами E-CoreВ ассортименте корпорации Intel появились процессоры семейства Twin Lake, рассчитанные на применение в таких устройствах, как компьютеры небольшого форм-фактора и одноплатные изделия. По сути, чипы Twin Lake представляют собой обновление решений Alder Lake-N. Сообщается, что вычислительные ядра Twin Lake базируются на архитектуре Gracemont, как и у Alder Lake-N, но по сравнению с прародителями имеют несколько более высокие частоты. Предусмотрен встроенный графический ускоритель Intel UHD Graphics. Показатель TDP в зависимости от модификации варьируется от 6 до 15 Вт. 
Источник изображения: Intel Конструкция Twin Lake включает исключительно энергоэффективные ядра E-Core, тогда как производительные ядра P-Core не предусмотрены. Таким образом, технология многопоточности не поддерживается. Объём кеш-памяти L3 у всех новинок составляет 6 Мбайт. На сегодняшний день в семейство входят четыре чипа: Intel Core 3 Processor N355, Intel Core 3 Processor N350, Intel Processor N250 и Intel Processor N150. Первые два наделены восемью ядрами, два других — четырьмя. Максимальная частота в турбо-режиме достигает 3,9 ГГц (см. таблицу). Поддерживается работа с оперативной памятью DDR4-3200, DDR5-4800 и LPDDR5-4800, максимальный объём которой может достигать 16 Гбайт. Возможен вывод изображения через интерфейсы eDP 1.4b, DP 1.4, HDMI 2.1, MIPI-DSI 1.3. При производстве применяется технология Intel 7 (исполнение — FCBGA1264). 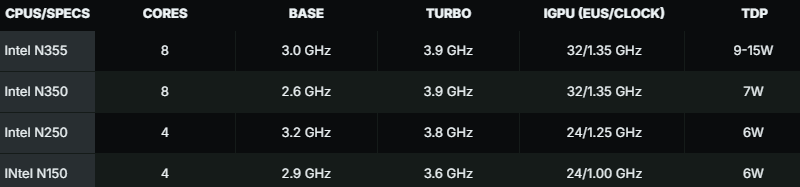
Источник изображения: wccftech.com Сетевые источники отмечают, что с точки зрения реальной производительности процессоры семейства Twin Lake практически идентичны сопоставимым по характеристикам изделиям серии Alder Lake-N.
14.02.2025 [09:45], Сергей Карасёв
Arm выпустит собственные чипы для ЦОД, а их первым покупателем станет Meta✴Британская компания Arm, 90 % которой принадлежит японскому холдингу SoftBank, выйдет на рынок процессоров для серверов, ориентированных на крупные дата-центры. Как сообщает газета Financial Times, эти изделия дебютируют в текущем году, а их первым заказчиком станет Meta✴ Platforms. Весной 2024 года сообщалось, что Arm намерена разработать собственный ИИ-чип. Тогда говорилось, что его массовый выпуск будет налажен к осени 2025-го на мощностях контрактного производителя. В частности, холдинг SoftBank вёл переговоры на соответствующую тему с TSMC. 
Источник изображения: Arm Как теперь стало известно, первым изделием собственной разработки Arm станет серверный CPU, а не ИИ-чип. Архитектура готовящегося решения предполагает возможность кастомизации под нужды заказчика. Этим воспользуется Meta✴, которая активно расширяет инфраструктуру ЦОД, а перспективе намерена потратить «сотни миллиардов долларов» на развитие ИИ-экосистемы. Рене Хаас (Rene Haas), генеральный директор Arm, отметил, что компания намерена официально представить процессор предстоящим летом. При этом вдаваться в подробности о технических характеристиках изделия он не стал. Выход Arm на рынок аппаратных решений будет означать серьёзное изменение бизнес-модели: ранее компания зарабатывала на лицензировании своих разработок другим участникам рынка, в том числе поставщикам решений для дата-центров и облачных платформ. Вместе с тем в ИИ-сегменте Arm увеличивает выручку путём постоянного повышения лицензионных сборов за свои технологии и благодаря взиманию роялти за каждый чип, продаваемый другими компаниями. Недавно также сообщалось, что SoftBank вскоре может заключить сделку по покупке разработчика серверных Arm-чипов Ampere за $6,5 млрд. Таким образом, японский холдинг и подконтрольная ему британская Arm готовятся составить серьёзную конкуренцию другим игрокам рынка процессоров для серверов. У AWS, Google Cloud и Microsoft Azure уже есть собственные серверные Arm-процесоры: Graviton, Axion и Cobalt 100.
04.02.2025 [13:52], Сергей Карасёв
Уязвимость в процессорах AMD позволяет загрузить модифицированный микрокодСпециалисты Google Security Team сообщили об обнаружении опасной уязвимости в проверке подписи микрокода для процессоров AMD на архитектуре от Zen1 до Zen4. Уязвимость даёт возможность загрузить модифицированный микрокод, позволяющий скомпрометировать технологию виртуализации с шифрованием SEV (Secure Encrypted Virtualization) и SEV-SNP (Secure Nested Paging), а также вмешаться в работу Dynamic Root of Trust for Measurement (DRTM). Успешная эксплуатация «дыры» может привести к потере защиты конфиденциальности. Проблема заключается в том, что процессоры используют небезопасную хеш-функцию при проверке подписи обновлений микрокода. Брешь позволяет злоумышленнику с привилегиями локального администратора загрузить вредоносный микрокод CPU. Исследователи подготовили пример атаки на AMD EPYC 7B13 (Milan) и Ryzen 9 7940HS (Phoenix), в результате которой функция RDRAND вместо возврата случайного числа всегда возвращает 4. AMD подготовила патчи для защиты функций SEV в EPYC 7001 (Naples), EPYC 7002 (Rome), EPYC 7003 (Milan и Milan-X), а также EPYC 9004 (Genoa, Genoa-X и Bergamo/Siena) и Embedded-вариантов EPYC 7002/7003/9004. Для устранения проблемы требуется обновление микрокода чипов. Уязвимость получила идентификатор CVE-2024-56161. Они признана достаточно опасной — 7.2 (High) по шкале CVSS. 
Источник изображения: AMD Отмечается, что Google впервые уведомила AMD об уязвимости 25 сентября 2024 года. При этом в связи с широкой распространённостью процессоров AMD и разветвлённой сетью их поставок Google сделала единовременное исключение из стандартной политики раскрытия информации об уязвимостях и отложила публичное уведомление до 3 февраля 2025-го. Кроме того, Google не стала раскрывать полные детали о «дыре», чтобы предотвратить возможные атаки. Все подробности и инструменты будут опубликованы 5 марта 2024 года.
02.02.2025 [15:50], Владимир Мироненко
Intel отложила выпуск Xeon Clearwater Forest — рынок пока не готов, да и с упаковкой проблемыВ ходе отчёта за IV квартал 2024 года Intel рассказала о будущих продуктах и продвижении в развёртывании новых технологий. Компания сообщила, что будет наращивать производство с использованием техпроцесса Intel 18A (1,8 нм) во II половине 2025 года, но нового Xeon Clearwater Forest с E-ядрами ждать в этом году не стоит, пишет ServeTheHome. В августе 2024 года Intel заявила о запуске тестового производства Clearwater Forest и Panther Lake с использованием техпроцесса Intel 18A и новой технологии упаковки, а в сентябре продемонстрировала образец Clearwater Forest, планируя начать серийное производство этих чипов в III квартале 2025 года. 288-ядерный чип Sierra Forest-AP (6900E) предполагалось запустить в массовое производство в I квартале 2025 года. Однако в ходе квартального отчёта со-генеральный директор Intel Мишель Джонстон Холтхаус (MJ Holthaus) сообщила, что компания добилась «прогресса в (разработке) Clearwater Forest, первом серверном продукте с использованием Intel 18A», который планирует выпустить в I половине уже 2026 года. По её словам, причина переноса заключается в пока низком спросе на Xeon, «изобилующие E-ядрами». «Мы увидели, что это скорее нишевый рынок, и мы не видим, чтобы объём материализовался на нём так быстро, как мы ожидали», цитирует The Register её слова. Далее она добавила, что особенности упаковки Foveros 3D также стали причиной переноса выпуска серверного чипа на 2026 год. 
Источник изображения: Intel Как отмечает ServeTheHome, общая тенденция на рынке серверов заключается в том, что ИИ-серверы в дефиците их довольно легко продать. Вместе с тем они очень дороги, поэтом компании стоят перед выбором: купить ИИ-системы, которые прослужат ещё год-два, или же купить серверы с самыми современным CPU, чтобы консолидировать нагрузки (например, 8:1) и избавиться от старых систем. Само появление таких процессоров — одна из крупнейших революций в области серверов за более чем десять лет, сообщили в ServeTheHome. И пока что многие заказчики делают выбор в пользу ИИ-серверов. Эта тенденция влияет на других игроков рынка, включая, например, Ampere. А раз так, то нет смысла отдавать производственные мощности 18A и тратить силы на быстрое решение проблем с упаковкой Clearwater Forest, который будет не слишком востребован — пока будет достаточно и Sierra Forest. Компания также передумала выпускать на рынок ускорители Falcon Shores.
29.01.2025 [13:00], Сергей Карасёв
Intel незаметно снизила рекомендованные цены на процессоры Xeon 6Корпорация Intel, по сообщению ресурса Tom's Hardware, без громких анонсов существенно снизила рекомендованные цены (RCP) на серверные процессоры Xeon 6 поколения Granite Rapids. В результате, с точки зрения стоимости в пересчёте на одно вычислительное ядро изделия Intel стали дешевле конкурирующих чипов AMD EPYC Genoa. Процессоры Xeon 6900P (Granite Rapids), официально представленные 24 сентября 2024 года, стали самыми дорогими решениями с архитектурой x86 в истории. В частности, цена флагманской модели Xeon 6980P со 128 ядрами на момент выхода на рынок составляла $17 800, или приблизительно $139 в пересчёте на одно ядро. Впрочем, после обновления прайс-листа эти чипы стали гораздо более доступными. 
Источник изображения: Intel В зависимости от модели снижение цены варьируется от $1585 за 96-ядерный Xeon 6972P до $5340 за упомянутый Xeon 6980P: эти чипы теперь стоят соответственно $10 220 и $12 460. В плане процентного снижения три из пяти представителей Xeon 6 Granite Rapids подешевели на 30 %, один (Xeon 6972P) — на 13 % и один (Xeon 6952P) — на 20 %. Подчёркивается, что Intel официально не объявляла о снижении стоимости процессоров, но эти корректировки отражены в онлайн-базе данных корпорации на сайте ark.intel.com, причём сделаны они были ещё в декабре 2024 года. Таким образом, новые цены на момент написания данного материала являются действительными. 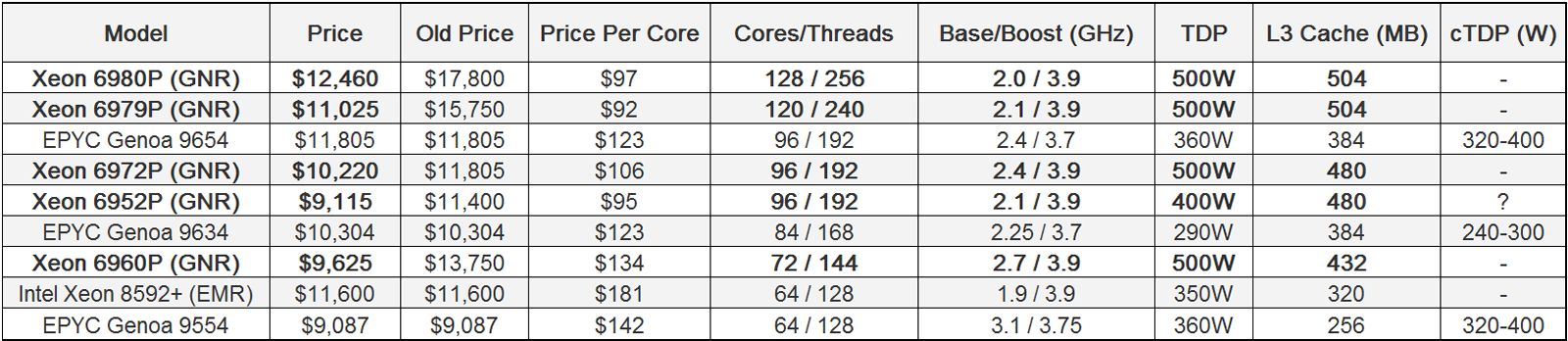
Источник изображения: Tom's Hardware Благодаря снижению стоимости 128-ядерный Intel Xeon 6980P в пересчёте на ядро стал дешевле 96-ядерного AMD EPYC 9654 — $97 против $123. То же самое касается и других представителей семейства Intel Granite Rapids в сравнении с их прямыми конкурентами AMD EPYC. Следует учесть, что речь идёт о рекомендованных ценах (Recommended Customer Price) в партиях от 1 тыс. шт. Путём снижения стоимости чипов корпорация Intel, вероятно, рассчитывает увеличить их продажи и тем самым улучшить финансовое положение. В III квартале 2024 финансового года, который был закрыт 30 сентября, компания получила $13,28 млрд выручки, что на 6 % меньше результата годичной давности. При этом Intel сообщила о чистом убытке в размере $16,99 млрд, тогда как годом ранее она завершила аналогичный квартал с чистой прибылью в размере $310 млн. |
|
