Материалы по тегу: big data
|
29.06.2025 [00:20], Сергей Карасёв
Speedata представила ускоритель анализа данных и привлекла на развитие $44 млнСтартап Speedata, занимающийся разработкой специализированных чипов для ускорения аналитики данных, провёл раунд финансирования Series B, в ходе которого на развитие получено $44 млн. В общей сложности на сегодняшний день компания привлекла $114 млн. Speedata разработала аналитический сопроцессор (Analytics Processing Unit, APU) под названием Callisto. Утверждается, что в случае рабочих нагрузок Apache Spark это изделие способно обеспечить 100-кратный прирост производительности по сравнению с CPU. Если сравнивать с GPU, то разработчик обещает сокращение капитальных затрат на 91 %, экономию пространства на 94 % и уменьшение потребления электроэнергии на 86 %. Особенность Callisto — использование относительно новой архитектуры CGRA, в разработке которой принимали участие основатели Speedata. Подобно программируемым пользователем вентильным матрицам (FPGA) решения с архитектурой GCRA можно настроить на выполнение определённых задач с максимальной эффективностью. При этом в случае Callisto устранены ограничения с обработкой логики ветвления, с которыми могут сталкиваться GPU, говорит компания. Кроме того, Callisto содержит ряд других оптимизаций для повышения производительности при аналитике данных. 
Источник изображения: Speedata Чип Callisto является основой серверного ускорителя C200. Это решение выполнено в виде карты расширения с интерфейсом PCIe 5.0 х16. Новинка обеспечивает ускорение операций, связанных с аналитикой данных на аппаратном уровне, снижая нагрузку на CPU. Speedata обещает «революционное соотношение цены и производительности», а также возможность обработки огромных массивов информации в рекордно короткие сроки. В систему типоразмера 2U могут быть установлены две карты C200. В качестве примера возможностей новинки компания Speedata приводит обработку некой рабочей нагрузки в фармацевтической области. С использованием APU задача была выполнена за 19 минут по сравнению с 90 часами при применении неспециализированного процессора. Таким образом, обеспечено ускорение в 280 раз. В раунде финансирования Series B приняли участие Walden Catalyst Ventures, 83North, Koch Disruptive Technologies, Pitango First и Viola Ventures, а также ряд стратегических инвесторов, в число которых вошли генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan) и соучредитель Mellanox Technologies Эяль Вальдман (Eyal Waldman). Деньги будут направлены на дальнейшее развитие технологии.
13.02.2025 [23:58], Руслан Авдеев
Big Data для Большого Брата: глава Oracle предложил собрать все-все данные американцев и обучить на них сверхмощный «присматривающий» ИИ
big data
llm
oracle
software
база данных
государство
ии
информационная безопасность
конфиденциальность
сша
По словам главы Oracle Ларри Эллисона (Larry Ellison), если правительства хотят, чтобы ИИ повысил качество обслуживания и защиту граждан, то необходимо собрать буквально всю информацию о них, включая даже ДНК, в единой базе, которую и использовать для обучения ИИ, сообщает The Register. Таким мнением Эллисон поделился с бывшим премьер-министром Великобритании Тони Блэром (Tony Blair) на мероприятии World Governments Summit в Дубае. Глава Oracle считает, что вскоре искусственный интеллект изменит жизнь каждого обитателя Земли во всех отношениях. По его мнению, нужно сообщить правительству как можно больше информации. Для этого необходимо свести воедино все национальные данные, включая геопространственные данные, информацию об экономике, электронные медицинские записи, в т.ч. информацию о ДНК, сведения об инфраструктуре и др. Т.е. передать буквально всё, обучить на этом массиве ИИ, а потом задавать ему любые вопросы. Подобный проект первым можно реализовать в США, говорит Эллисон. Результатами, по мнению мультимиллиардера, станет рост качества здравоохранения благодаря персонализации медицинской помощи, возможность прогнозировать урожайность и оптимизировать на этой основе производство продовольствия. Можно будет анализировать качество почв, чтобы дать рекомендации фермерам — где именно вносить удобрения и улучшать орошение и др. По словам Эллисона, когда все данные будут храниться в одном месте, можно будет лучше заботиться о пациентах и населении в целом, управлять всевозможными социальными сервисами и избавиться от мошенничества. 
Источник изображения: ev / Unsplash Конечно, такая система баз данных может стать предшественницей тотальной системы наблюдения — о необходимости чего-то подобного мультимиллиардер говорил ещё в прошлом году, намекая, что реализовать такой проект могла бы именно Oracle. Постоянный надзор за населением в режиме реального времени с анализом данных системами машинного обучения Oracle, по его словам, позволит всем «вести себя наилучшим образом». Oracle уже является крупным правительственным и военным подрядчиком в США и готова помочь другим странам реализовать подобные всеобъемлющие ИИ-проекты. Все данные, конечно, предполагается поместить в одну большую систему за авторством Oracle. Как заявил Эллисон, Oracle уже строит ЦОД ёмкостью 2,2 ГВт и стоимостью $50–$100 млрд. Именно на таких площадках будет учиться «сверхмощный» ИИ. Поскольку такие модели очень дороги, свои собственные клиентам, вероятно, обучать и не придётся, зато такие площадки позволят сделать несколько разных крупных моделей. В мире всего несколько компаний, способных обучать модели такого масштаба. В их числе, конечно, Oracle с собственной инфраструктурой. Компания присоединилась к ИИ-мегапроекту Stargate, реализация которого в течение следующих четырёх лет обойдётся в $500 млрд.
03.02.2025 [15:06], Сергей Карасёв
Разработчик гипермасштабируемых аналитических хранилищ Ocient выбрал чипы AMD EPYC GenoaКомпания Ocient, специализирующаяся на разработке гипермасштабируемых аналитических хранилищ данных, объявила о заключении соглашения о сотрудничестве с AMD с целью повышения производительности, снижения затрат и максимизации эффективности ресурсоёмких вычислений и рабочих нагрузок ИИ. Ocient была основана в 2016 году. Компания предлагает платформу на основе реляционной базы данных с массовым параллелизмом, которая способна анализировать огромные объёмы информации (триллионы строк) за секунды или минуты. Хранилище Ocient Hyperscale Data Warehouse (OHDW) использует архитектуру Compute Adjacent Storage Architecture (CASA) для устранения узких мест в сетевой инфраструктуре и обеспечения максимально быстрого доступа к данным. Функция Zero Copy Reliability отвечает за высокую надёжность хранения информации без репликации с помощью кодирования с контролем чётности. 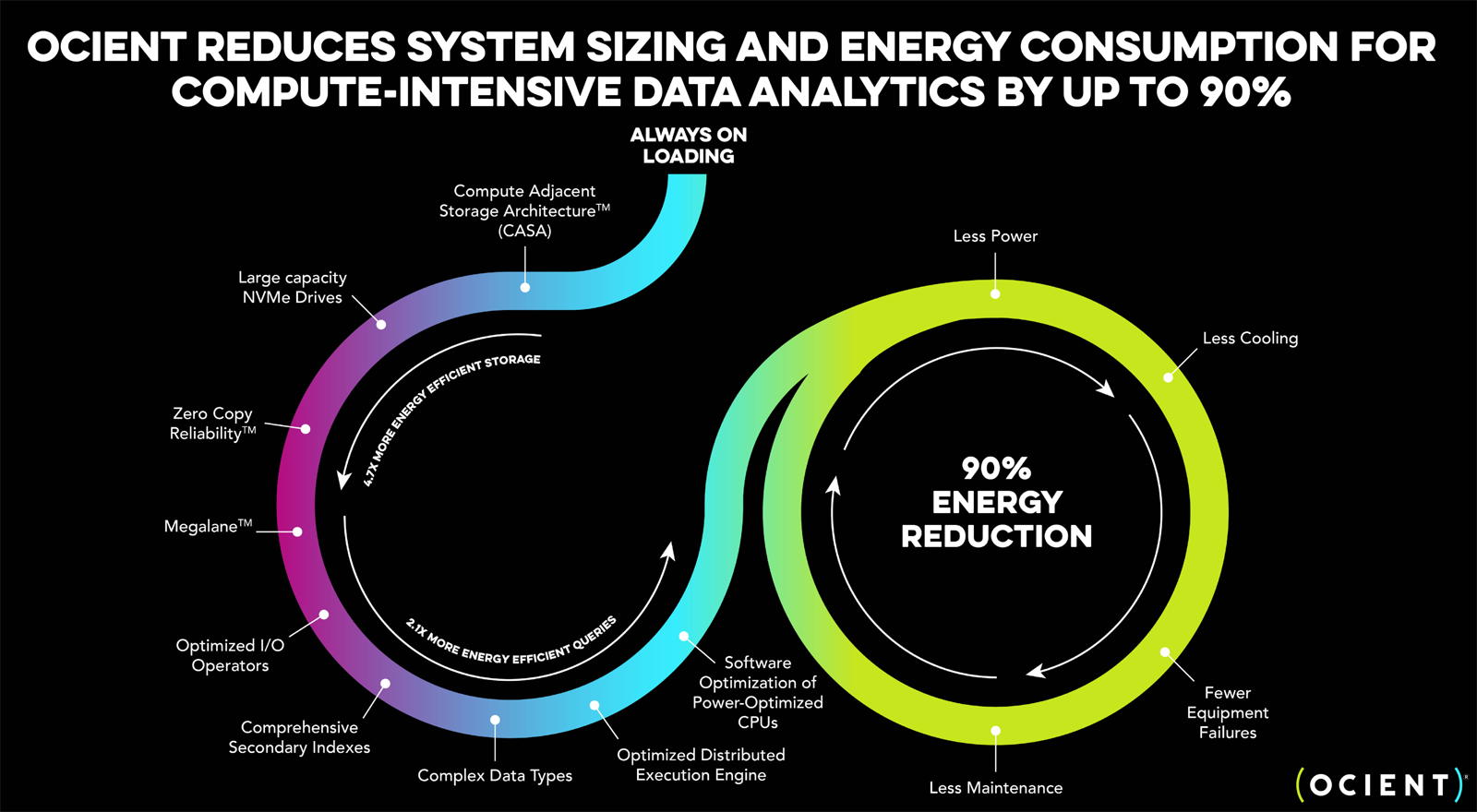
Источник изображения: Ocient Генеральный директор Ocient Крис Гладвин (Chris Gladwin) отмечает, что задачи ИИ и аналитики больших данных создают огромную вычислительную нагрузку на ЦОД по всему миру. Это означает, что повышение эффективности оборудования и программного обеспечения имеет решающее значение для снижения расходов, уменьшения энергопотребления и улучшения производительности. В этой связи Ocient сделала выбор в пользу процессоров AMD EPYC 9654 поколения Genoa с 96 вычислительными ядрами, которые придут на смену 28-ядерным чипам Intel Xeon Gold 6348 семейства Ice Lake-SP. Говорится, что благодаря более высокой плотности ядер изделия AMD обеспечат трёхкратный рост производительности для ресурсоёмких вычислительных задач. При этом снизятся эксплуатационные расходы, что обусловлено повышением быстродействия и энергоэффективности. Плюс к этому достигается гибкость масштабирования.
10.06.2024 [22:02], Владимир Мироненко
Не хочешь конкурировать — купи: Databricks приобрела Tabular за $1+ млрд, чтобы унифицировать озёра данныхАмериканский стартап в сфере аналитики больших данных и машинного обучения Databricks объявил о приобретении компании по управлению данными Tabular. Точная сумма сделки не раскрывается, но глава Databricks Али Годси (Ali Ghodsi) сообщил в интервью CNBC, что стоимость покупки превышает $1 млрд. Соучредители Tabular присоединятся к Databricks, где будут работать над объединением клиентских баз и сообществ Tabular и Databricks. Компания Tabular была основана ими в 2021 году. Она предлагает продукты для управления данными, созданные на основе Apache Iceberg — проекта, которым создатели Tabular занимались в Netflix и позже передали в дар фонду Apache Software Foundation. Iceberg — открытый формат для таблиц сверхбольших данных. Databricks предлагает объектно-ориентированное озеро данных Lakehouse на базе собственного открытого формата Delta Lake. 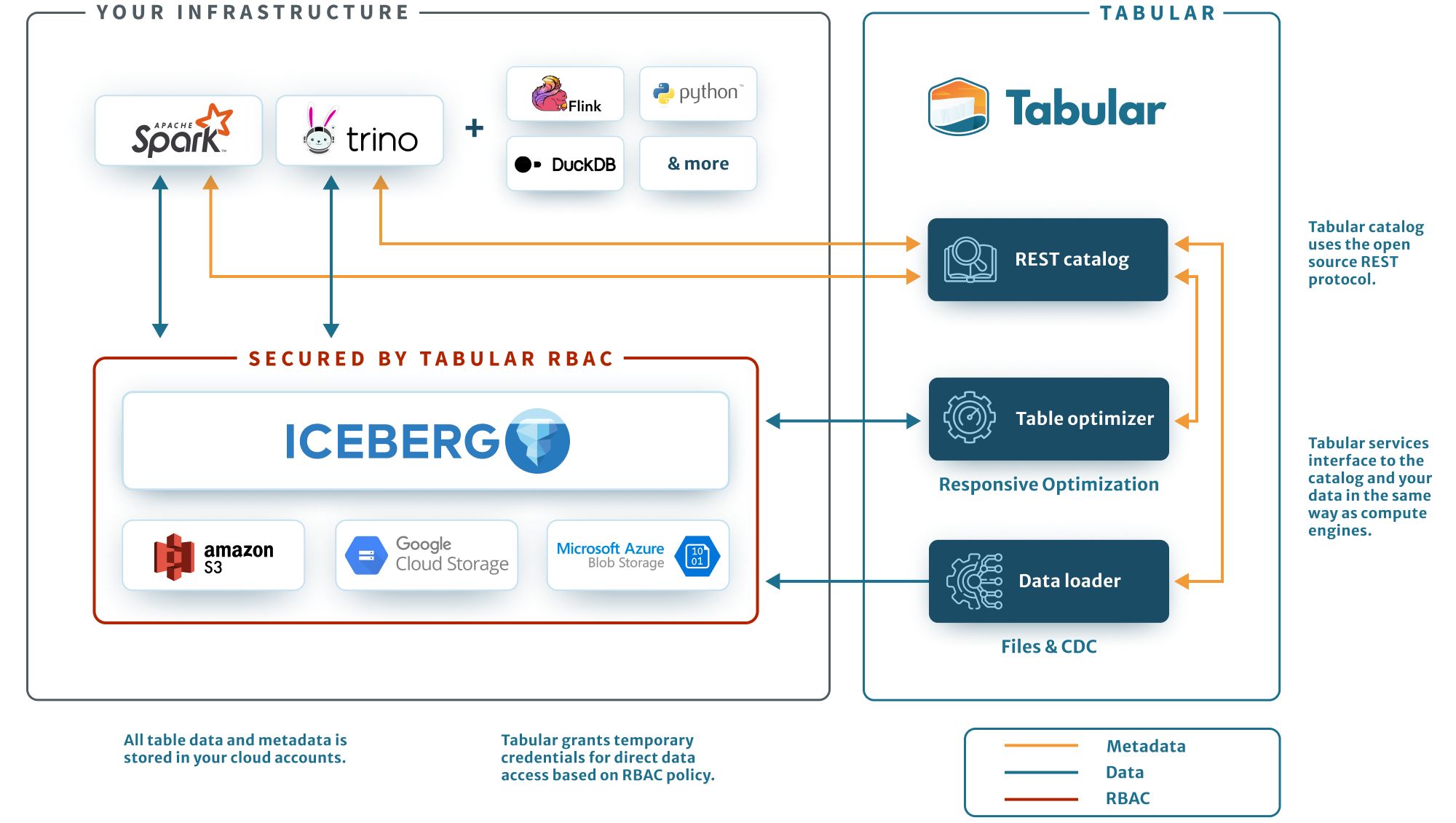
Источник изображения: Tabular С момента создания Delta Lake в проекте приняли участие более 500 разработчиков. Более 10 тысю компаний по всему миру используют Delta Lake для обработки в среднем более 4 Эбайт данных каждый день. Это быстрорастущий бизнес, но Iceberg-решения не менее популярны и конкурируют с решениями Databricks, отметил ресурс Blocks & Files. При этом о полной совместимости между Iceberg и Delta Lake речи не было. Но в 2023 году компания также представила UniForm-таблицы, позволяющие работать с Delta Lake, Iceberg и Hudi. А после поглощения Databricks будет тесно сотрудничать с сообществами Delta Lake и Iceberg для разработки совместимых форматов озёр данных. В краткосрочной перспективе это будет реализовано в рамках Delta Lake UniForm, а в долгосрочной перспективе будет создан единый, открытый и общий стандарт. |
|