Материалы по тегу: бенчмарк
|
11.09.2023 [19:00], Сергей Карасёв
Много памяти, быстрая шина и правильное питание: гибридный суперчип GH200 Grace Hopper обогнал H100 в ИИ-бенчмарке MLPerf InferenceКомпания NVIDIA сообщила о том, что суперчип NVIDIA GH200 Grace Hopper и ускоритель H100 лидируют во всех тестах производительности ЦОД в бенчмарке MLPerf Inference v3.1 для генеративного ИИ, который включает инференс-задачи в области компьютерного зрения, распознавания речи, обработки медицинских изображений, а также работу с большими языковыми моделями (LLM). Ранее NVIDIA уже объявляла о рекордах H100 в новом бенчмарке MLPerf. Теперь говорится, что суперчип GH200 Grace Hopper впервые прошёл все тесты MLPerf. Вместе с тем системы, оснащенные восемью ускорителями H100, обеспечили самую высокую пропускную способность в каждом тесте MLPerf Inference. Решения NVIDIA прошли обновленное тестирование в области рекомендательных систем (DLRM-DCNv2), а также выполнили первый эталонный тест GPT-J — LLM с 6 млрд параметров. Примечательно, что GH200 оказался до 17 % быстрее H100, хотя чип самого ускорителя в обоих продуктах один и тот же. NVIDIA объясняет это несколько факторами. Во-первых, у GH200 больше набортной памяти — 96 Гбайт против 80 Гбайт. Во-вторых, ПСП составляет 4 Тбайт/с, а сам чип является гибридным, так что для передачи данных между LPDDR5x и HBM3 не используется PCIe. В-третьих, GH200 при низкой нагрузке на CPU умеет отдавать часть энергии ускорителю, оставаясь в заданных рамках энергопотребления. Правда, в тестах GH200 работал на полную мощность, т.е. с TDP на уровне 1 кВт (UPD: NVIDIA уточнила, что реально потребление GH200 под полной нагрузкой составляет 750–800 Вт). 
Источник изображений: NVIDIA Отдельно внимание уделено оптимизации ПО — на днях NVIDIA анонсировала открый программный инструмент TensorRT-LLM, предназначенный для ускорения исполнения LLM на продуках NVIDIA. Этот софт даёт возможность вдвое увеличить производительность ускорителя H100 в тесте GPT-J 6B (входит в состав MLPerf Inference v3.1). NVIDIA отмечает, что улучшение ПО позволяет клиентам с течением времени повышать производительность ИИ-систем без дополнительных затрат. 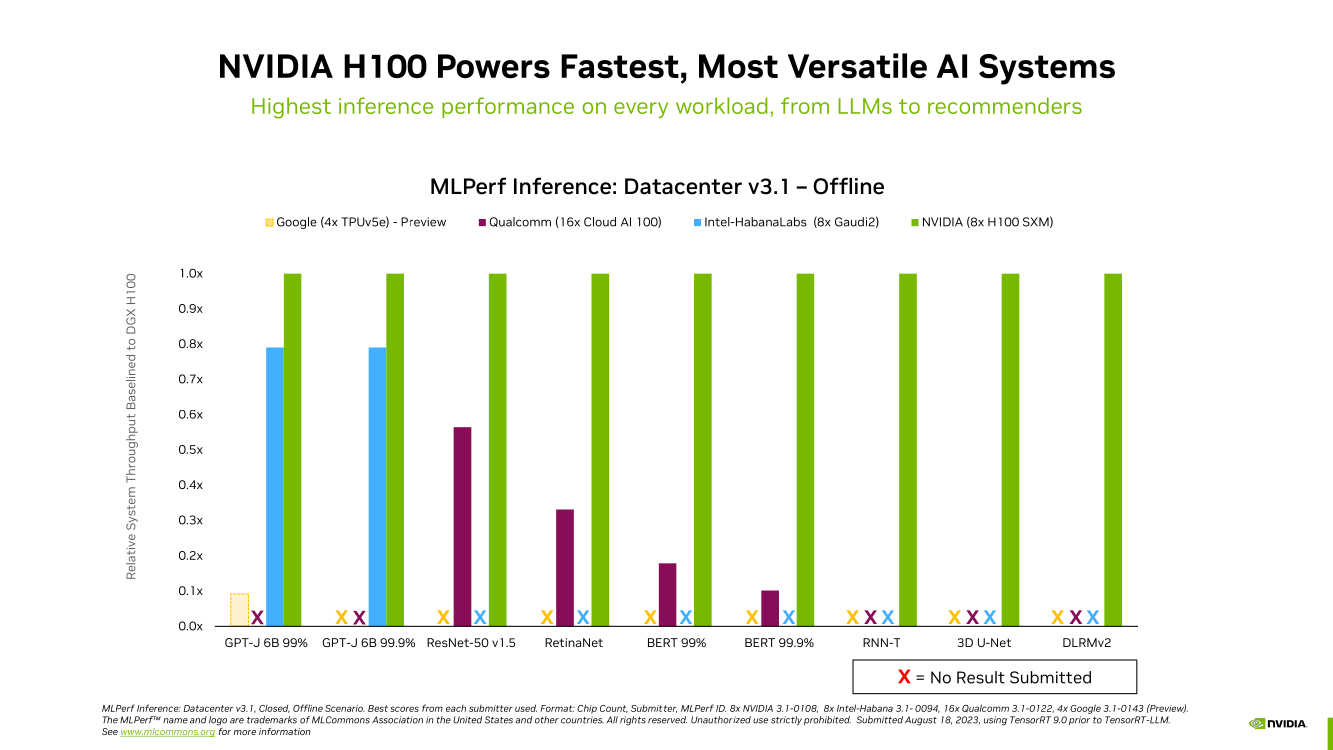 Также отмечается, что модули NVIDIA Jetson Orin благодаря новому ПО показали прирост производительности до 84 % на задачах обнаружения объектов по сравнению с предыдущим раундом тестирования MLPerf. Ускорение произошло благодаря задействованию Programmable Vision Accelerator (PVA), отдельного движка для обработки изображений и алгоритмов компьютерного зрения работающего независимо от CPU и GPU.  Сообщается также, что ускоритель NVIDIA L4 в последних тестах MLPerf выполнил весь спектр рабочих нагрузок, показав отличную производительность. Так, в составе адаптера с энергопотреблением 72 Вт этот ускоритель демонстрирует в шесть раз более высокое быстродействие, нежели CPU, у которых показатель TDP почти в пять раз больше. Кроме того, NVIDIA применила новую технологию сжатия модели, что позволило продемонстрировать повышение производительности в 4,4 раза при использовании BERT LLM на ускорителе L4. Ожидается, что этот метод найдёт применение во всех рабочих нагрузках ИИ. В число партнёров при проведении тестирования MLPerf вошли поставщики облачных услуг Microsoft Azure и Oracle Cloud Infrastructure, а также ASUS, Connect Tech, Dell Technologies, Fujitsu, Gigabyte, Hewlett Packard Enterprise, Lenovo, QCT и Supermicro. В целом, MLPerf поддерживается более чем 70 компаниями и организациями, включая Alibaba, Arm, Cisco, Google, Гарвардский университет, Intel, Meta✴, Microsoft и Университет Торонто.
06.09.2023 [19:20], Алексей Степин
Первые бенчмарки NVIDIA Grace Superchip: не хуже EPYC и быстрее Xeon, а по энергоэффективности намного лучше AMD и Intel144-ядерный Arm-процессор NVIDIA Grace Superchip был продемонстрирован публике ещё весной этого года на конференции GTC 2023. Несмотря на то, что технические характеристики этого решения известны уже давно, первые результаты тестирования компания решила опубликовать только сейчас, вероятно, с подачи Arm, которая готовится к IPO. Производство Grace Superchip уже запущено, а появления ОЕМ-систем на его базе следует ожидать уже во II квартале 2024 года. Напомним, Grace Superchip представляет собой сборку из двух чипов Grace, каждый из которых включает 72 ядра Arm Neoverse V2 (Arm v9) с поддержкой векторных расширений SVE2. Процессор умеет работать с форматами BF16/INT8 и развивает до 7,1 Тфлопс в режиме FP64. С точки зрения системы сборка представляется единым 144-ядерным процессором. 
Сборка Grace Superchip. Источник изображения: NVIDIA В качестве соперников Grace Superchip были избраны платформы на базе AMD EPYC Genoa 9654 (2 процессора, 192 ядра) и Intel Xeon Sapphire Rapids 8480+ (также 2 процессора, 112 ядер). Итог довольно любопытен: несмотря на заметное отставание в количестве ядер от системы AMD, решение NVIDIA сумело достичь паритета в подавляющем большинстве тестов, а в сценарии аналитики графов даже продемонстрировало 1,4-кратное превосходство. 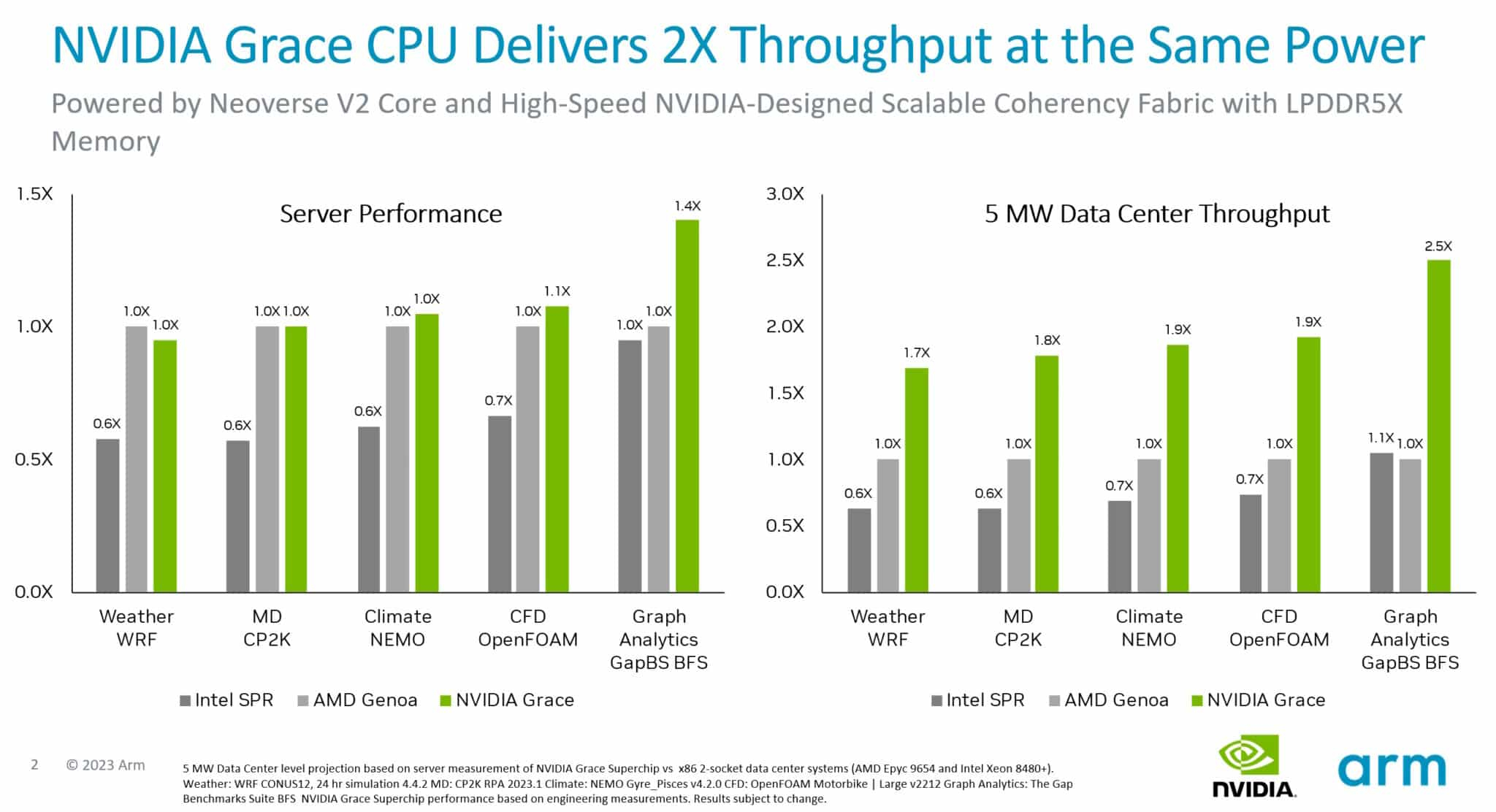
Источник изображения: NVIDIA Возможно, тут новинке помогла мощная подсистема памяти: Grace Superchip оснащается набором чипов LPDDR5x объёмом 960 Гбайт с совокупной ПСП 1 Тбайт/с. Но куда интереснее результаты, приведённые к уровню энергопотребления — сборка Grace Superchip буквально разгромила решения на базе x86-64. Выигрыш в этом случае составил от 70 % до 150 %! Полученные результаты достаточно неплохо согласуются с официальными данными об энергопотреблении систем-участниц тестирования — это 720 и 700 Вт у решений AMD и Intel соответственно против 500 Вт у NVIDIA Grace Superchip. Если опубликованные сегодня результаты будут подтверждены независимыми тестами, можно говорить о появлении у серверных решений x86 серьёзнейшего конкурента. Впрочем, ценовая политика NVIDIA в отношении Grace Superchip пока остаётся тайной.
13.07.2022 [16:13], Алексей Степин
128-ядерный Arm-процессор Alibaba T-Head Yitian 710 показал отличные результаты в SPEC CPU2017Не секрет, что китайские гиганты, такие, как Huawei и Alibaba Cloud, разрабатывают собственные серверные процессоры на базе архитектуры Arm. Однако информации об этих чипах, как правило, не очень много и пользоваться общепринятыми на западе тестами и рейтингами разработчики не спешат, что, к слову, характерно и для китайских суперкомпьютеров. Alibaba Cloud представила чип Yitian 710 ещё осенью прошлого года. Этот процессор построен на базе архитектуры Armv9 и максимально может иметь 128 ядер с частотой до 3,2 ГГц. Однако результаты проверки чипа в популярном тесте SPEC CPU2017 были опубликованы только сейчас. 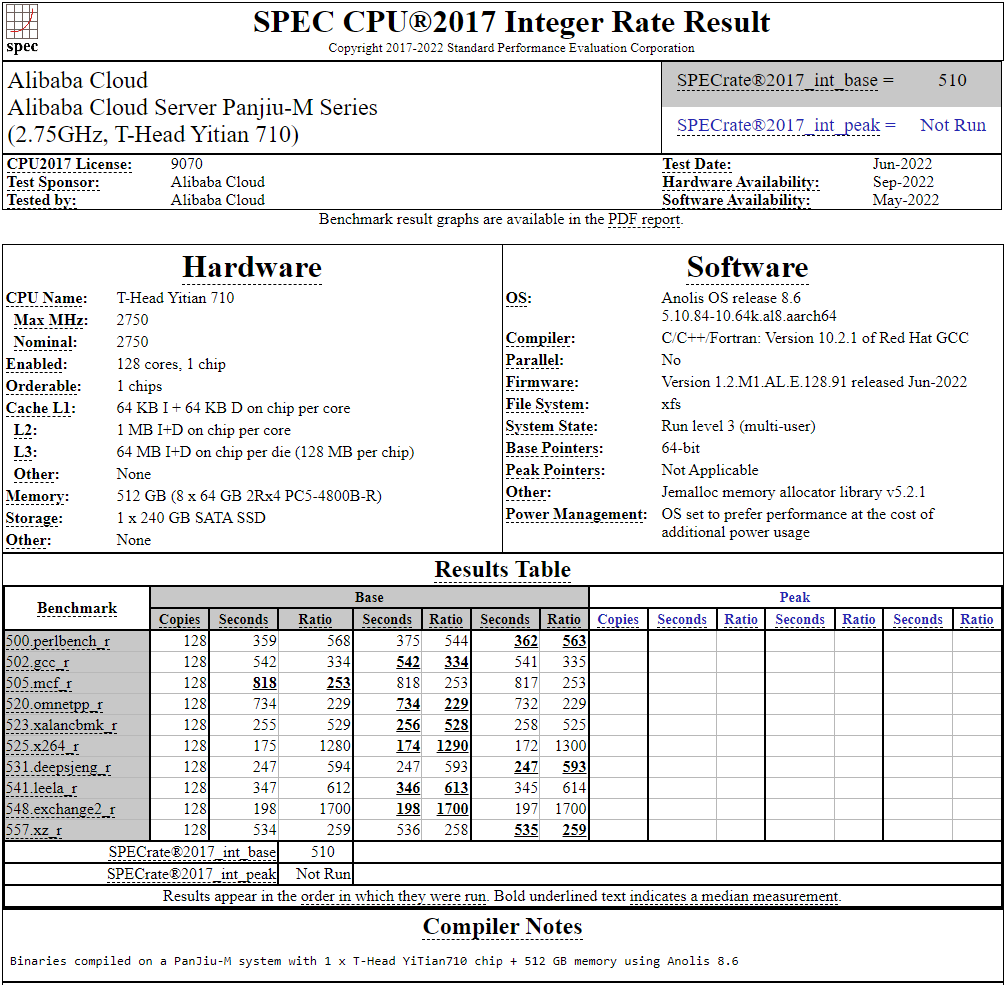 Процессор тестировался в составе референс-сервера Panjiu. Применялась 128-ядерная версия с частотой 2,75 ГГц, 1 Мбайт кеша L2 на ядро и 64 Мбайт кеша L3 на кристалл (128 Мбайт на сборку). Последнее позволяет говорить о том, что Alibaba также использует в своих процессорах чиплетную компоновку. 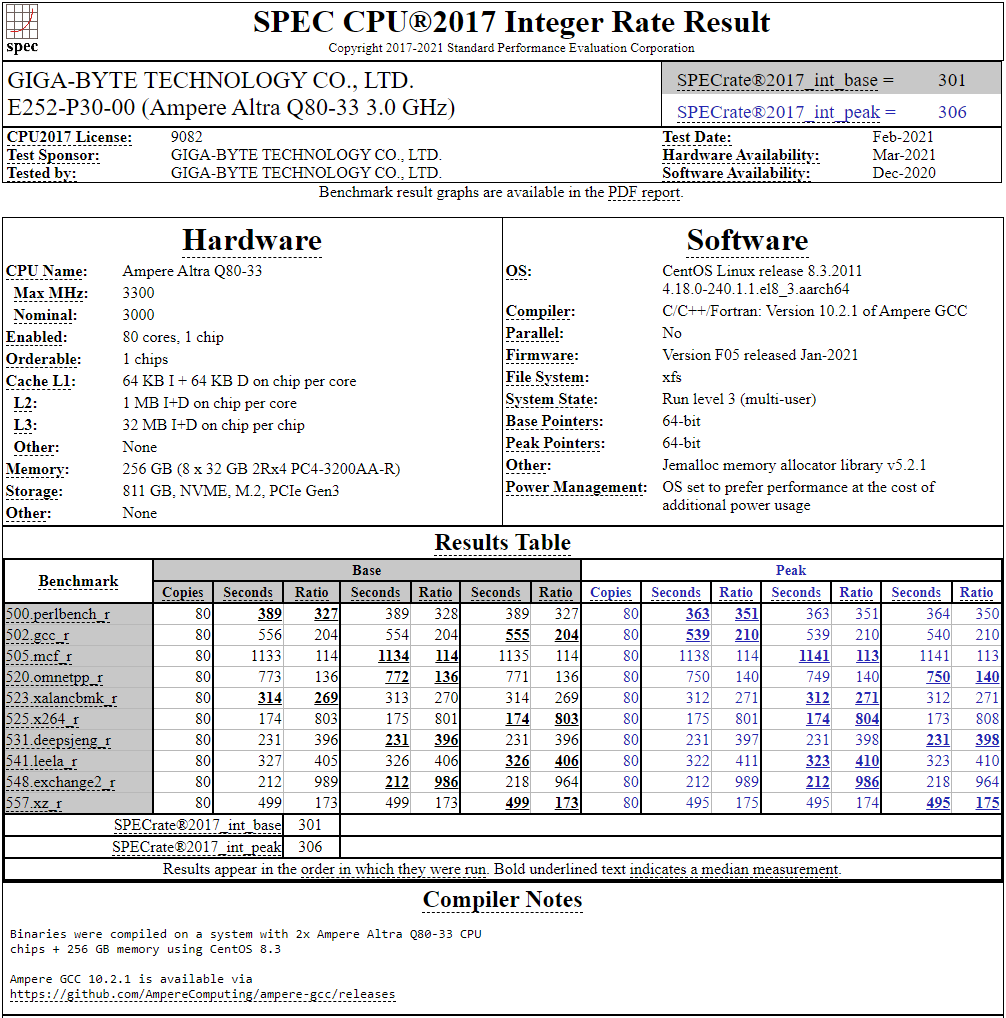 Результаты оказались существенно более высокими, нежели у Ampere Altra Q80-33; правда, стоит сделать скидку на то, что у Ampere использовалась 80-ядерная версия, а не более новая 128-ядерая Altra Max. Но в аутсайдерах оказался также и AMD EPYC 7773X (64 ядер/128 потоков, 2,2-3,5 ГГц, 768 Мбайт L3), показавший 440 очков против 510 у Yitian 710. Увеличенный объём кеша не слишком помог детищу «красных». 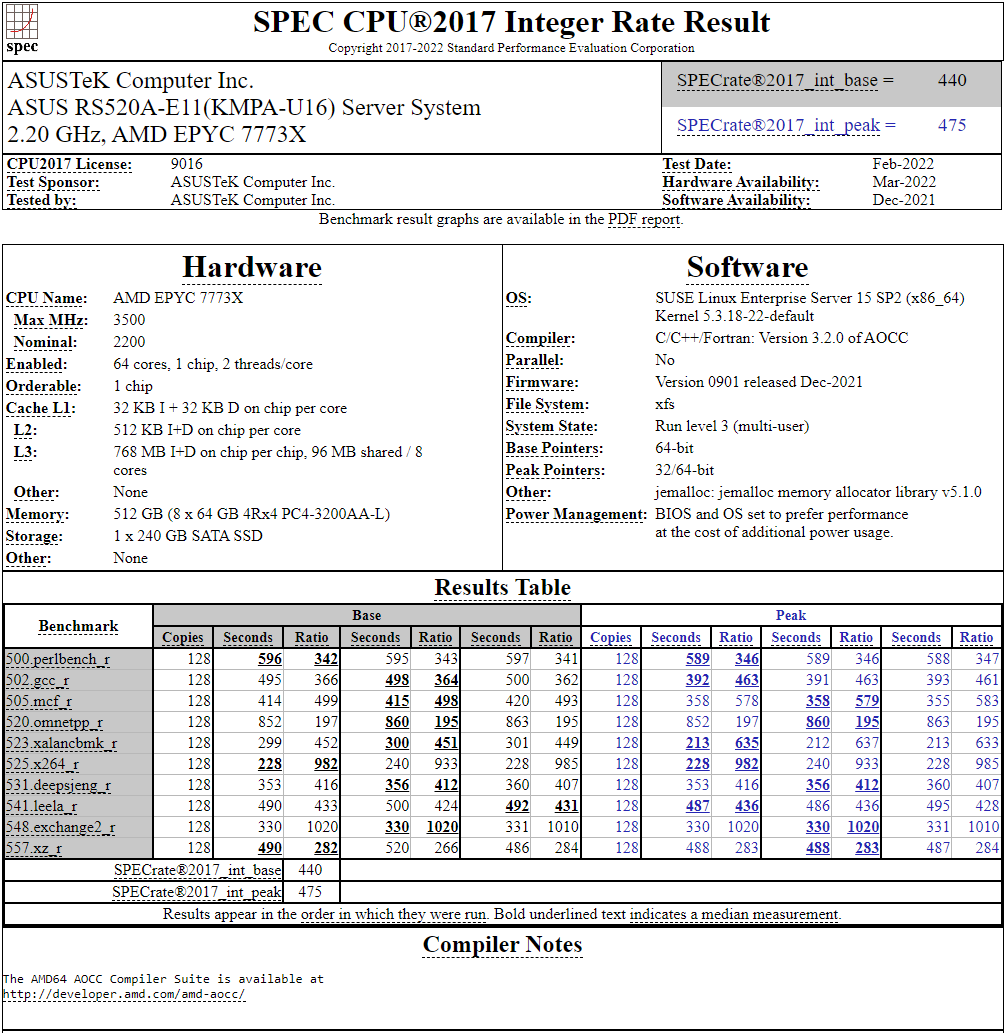 Таким образом, процессор на базе архитектуры Armv9 занял первое место там, где традиционно господствовали решения с архитектурой x86 — достаточно взглянуть на Топ-20 в рейтинге CPU2017 Integer. Можно сказать, что 128-ядерный процессор не вполне корректно сравнивать с 64-ядерным с поддержкой SMT, однако если технологии и архитектура позволяют разместить вдвое больше полноценных ядер в сопоставимом по размеру с AMD EPYC корпусе, так ли это важно? 
Текущий Tоп-20 целочисленной производительности в SPEC CPU2017 К сожалению, пока речь идёт только о целочисленных вычислениях. По неизвестной причине, Alibaba Cloud не опубликовала результаты CPU2017 Floating Point, где сравнение вышло бы существенно интереснее. В любом случае, монополия AMD на первые места пошатнулась; что же касается Intel, то в классе однопроцессорных систем самым мощным вариантом является 36-ядерный Xeon Platinum 8351N, который заведомо проиграет 64-128 ядерным монстрам AMD, Ampere, а теперь уже и Alibaba Cloud. |
|