Материалы по тегу: коммутатор
|
29.05.2024 [12:08], Сергей Карасёв
Edge-оборудование Alibaba Cloud построено на Intel TofinoОблачная платформа Alibaba Cloud, по сообщению ресурса The Register, раскрыла аппаратную конфигурацию сетевого оборудования, которое используется на периферии. Речь идёт об устройствах под названием LuoShen, которые рассматриваются в качестве «серверов-коммутаторов». 
Источник изображения: Alibaba Отмечается, что изделия LuoShen находятся в производстве приблизительно два года. На сегодняшний день они эксплуатируются на «сотнях периферийных площадок» в составе облачной инфраструктуры Alibaba Cloud. LuoShen имеет форм-фактор 2U. Конструкция включает два CPU общего назначения, FPGA, а также чип Intel Tofino — интегральную схему специального назначения (ASIC) с возможностью программирования. Tofino представляет собой сетевой Ethernet-процессор, ориентированный на дата-центры. Утверждается, что LuoShen обеспечивает пропускную способность до 1,2 Тбит/с. Чип Tofino отвечает за перераспределение 64 портов 100G под различные цели. Это, в частности, обработка трафика виртуальных машин, интернет-трафика и пр. В зависимости от выполняемых задач данные направляются к CPU и FPGA, а после обработки отправляются в конечную точку. Отмечается, что устройствам LuoShen приходится обрабатывать трафик разных типов, а поэтому возможность программирования Tofino имела для Alibaba Cloud ключевое значение — облачная платформа смогла оптимизировать работу оборудования под собственные нужды. Благодаря переходу на LuoShen компания смогла сократить первоначальные затраты, занимаемое место и энергопотребление на 75 %, 87 % и 60 % соответственно по сравнению с ранее использовавшейся сетевой архитектурой.
27.03.2024 [23:40], Сергей Карасёв
Coherent представила оптические коммутаторы для дата-центров, ориентированных на задачи ИИCoherent анонсировала специализированные оптические коммутаторы для ИИ-кластеров высокой плотности. В основу устройств Optical Circuit Switch (OCS) положена фирменная платформа кросс-коммутации Lightwave Cross-Connect (DLX). В изделиях, в отличие от традиционных коммутаторов, не применяются приемопередатчики для преобразования фотонов в электроны и обратно. Вместо этого все операции осуществляются в оптическом тракте: импульсы поступают в один порт и выходят из другого (конечно, с небольшим ослаблением). Coherent выделяет несколько ключевых преимуществ своей технологии. Прежде всего значительно возрастает производительность, что важно при решении ресурсоёмких задач, связанных с приложениями ИИ. Кроме того, благодаря отказу от преобразования среды сокращаются энерозатраты. Наконец, отпадает необходимость в обновлении собственно коммутаторов при установке в ЦОД оборудования следующего поколения. Это значительно повышает окупаемость капитальных затрат. 
Источник изображения: Coherent Представленное решение насчитывает 300 входных и 300 выходных оптических портов. Коммутаторы OCS помогают решить проблемы масштабируемости и надёжности дата-центров, ориентированных на приложения ИИ. Аналитики Dell'Oro Group отмечают, что для ИИ-задач требуется более высокий уровень отказоустойчивости, нежели для традиционных приложений. Крайне важно, чтобы коммутаторы, используемые в составе ИИ-платформ, не провоцировали никаких перебоев во время обучения или эксплуатации больших языковых моделей. Устройства Coherent, как сообщается, обеспечивают необходимый уровень надёжности. Массовые поставки новых коммутаторов планируется организовать в 2025 году. При этом Google уже использует в своих дата-центрах оптические коммутаторы (OCS) собственной разработки на базе MEMS-переключателей для формирования ИИ-кластеров, а Meta✴ совместно с MIT разработала систему TopoOpt, представляющую собой оптическую патч-панель с манипулятором, который позволяет менять топологию сети.
22.03.2024 [09:09], Алексей Степин
NVIDIA представила 800G-платформы Quantum-X800 и Spectrum-X800 для InfiniBand- и Ethernet-фабрик нового поколенияДополнением к только что представленным ИИ-ускорителям NVIDIA Blackwell станут новые сетевые 800G-платформы Quantum-X800 и Spectrum-X800, а также сетевые адаптеры ConnectX-8. Именно они позволят вывести масштабирование ИИ-кластеров на новый уровень и позволят «прокормить» гигантские массивы ускорителей в дата-центрах гиперскейлеров. Платформа NVIDIA Quantum-X800 ориентирована на наиболее производительные ИИ- и HPC-кластеры. Она использует новое поколение технологии InfiniBand, всё ещё обладающей рядом преимуществ в сравнении с Ethernet, и включает в себя обновлённые SHARP-движки. Технология SHARPv4 реализует «вычисления в сети» (In-Network Computing), что позволяет не только существенно разгрузить вычислительные узлы и серверы, но и обеспечить более высокую пропускную способность интерконнекта вкупе с более серьёзными возможностями его масштабирования. 
NVIDIA Q3400-RA 4U (справа) и SN5600. Источник изображений здесь и далее: NVIDIA Основой платформы Quantum-X800 стал 4U-коммутатор Q3400-RA, впервые в индустрии, как говорит компания, использующий 200G-блоки SerDes для каждой линии InfiniBand. Коммутатор располагает 144 портами 800G в 72 OSFP-модулях и выделенным портом для Unified Fabric Manager. Новинка имеет стандартное 19″ исполнение с воздушным охлаждением, но есть и вариант Q3400-LD с жидкостным охлаждением, предназначенный для 21″ OCP-стоек. В двухуровневом варианте fat tree коммутаторы позволят объединить 10 368 NIC.  Основным адаптером для новой платформы InfiniBand является ConnectX-8 SuperNIC с интерфейсом PCIe 6.0. Он является частью SHARPv4 и предлагается в однопортовом (OSFP224) и двухпортовом (QSFP112) вариантах и в нескольких форм-факторах, включая OCP 3.0. На платах также имеется разъём SocketDirect на 16 линий PCIe. Также компания представила компоненты NVIDIA LinkX: оптические трансиверы 2xDR4/2xFR4 и активные медные кабели (LACC).  Не забыла NVIDIA и про Ethernet: здесь вывести производительность сети на новый уровень должна платформа Spectrum-X800. Её основой служит новейший коммутатор SN5600 — это, по словам NVIDIA, первый в мире Ethernet-коммутатор класса 800GbE, специально разработанный для применения гиперскейлерами в крупных облачных ИИ-комплексах. Применяемая архитектура позволяет гарантировать каждому клиенту оптимальный и постоянный уровень производительности, а потоковая телеметрия позволит находить и ликвидировать возможные «бутылочные горлышки» в сети буквально на лету.  Общая пропускная способность SN5600 составляет 51,2 Тбит/с. Коммутатор располагает 64 портами 800GbE в формате OSFP. В нём используется ASIC пятого поколения на базе архитектуры Spectrum-4. В качестве основного адаптера предлагается SuperNIC на базе DPU BlueField-3 с двумя 400GbE-портами. 
Фото: Twitter/NVIDIANetworkng Spectrum-X800 сопровождает полноценный спектр инфраструктурных компонентов, включая кабели DAC и LACC. С оптическими трансиверами длина соединения 800GbE может достигать двух километров. Начиная со следующего года, решения на базе новых сетевых платформ NVIDIA будут доступны от широкого круга поставщиков оборудования, включая Aivres, DDN, Dell Technologies, Eviden, Hitachi Vantara, HPE, Lenovo, Supermicro и VAST Data.
11.03.2024 [22:30], Сергей Карасёв
Keenetic представила компактные 1GbE-коммутаторы с поддержкой PoE+Производитель сетевого оборудования Keenetic анонсировал неуправляемые коммутаторы PoE+ Switch 5 и PoE+ Switch 9, которые подойдут, например, для построения mesh-сетей Wi-Fi, систем видеонаблюдения и телефонии. Устройства получили прочный металлический корпус для настольного или настенного размещения. Модель PoE+ Switch 5 (KN-4610) оснащена одним портом 1GbE RJ-45 и четырьмя портами 1GbE RJ-45 с поддержкой стандарта PoE+ (802.3af/at), каждый из которых имеет выходную мощность в 30 Вт. При этом общий бюджет мощности ограничен 60 Вт. Габариты составляют 100 × 100 × 26 мм, масса — 205 г. 
Источник изображений: Keenetic В свою очередь, вариант PoE+ Switch 9 (KN-4710) снабжён одним портом 1GbE RJ-45 и восемью портами 1GbE RJ-45 с поддержкой стандарта PoE+ с выходной мощностью 30 Вт. Общий бюджет мощности — 120 Вт. Устройство имеет габариты 177 × 105 × 26 мм и весит 427 г. Диапазон рабочих температур обоих коммутаторов — от 0 до +40 °C.  Отмечается, что новинки ориентированы прежде всего на подключение нескольких точек доступа Orbiter Pro KN-2810 и Voyager Pro KN-3510. Кабельное соединение между узлами системы Mesh Wi-Fi Keenetic, главным интернет-центром и ретрансляторами обеспечивает максимальные производительность и зону покрытия сигнала, а технология PoE устраняет необходимость в наличии рядом с ТД электрических розеток. На коммутаторы предоставляется трёхлетняя гарантия. Стоимость Keenetic PoE+ Switch 5 и PoE+ Switch 9 на сайте производителя составляет соответственно 4490 и 8990 руб. Кроме того, компания предлагает 30-Вт PoE-инжектор (802.3af/at, PoE+) KN-4510 за 1990 руб.
25.02.2024 [19:38], Сергей Карасёв
Энтузиаст превратил коммутаторы Ubiquiti UniFi Professional Max в простейшую «игровую консоль»Сотрудник Ubiquiti Адам Джезек (Adam Jezek) на досуге превратил коммутаторы UniFi Professional Max в матричный индикатор для простейших игр. Разработчик, в частности, показал возможность запуска «Змейки» и T-Rex Dinosaur — как в браузере Google Chrome. Устройства серии UniFi Professional Max оснащены технологией Etherlighting, которая предусматривает наличие многоцветной RGB-подсветки разъёмов для сетевых кабелей. Благодаря этому достигается наглядная визуальная индикация состояния и предназначения портов. В частности, определённым цветом могут быть обозначены разъёмы с разной скоростью подключения, поддержкой PoE и пр. 
Источник изображения: Адам Джезек Подсветку можно настраивать через мобильное приложение. А Джезек написал код, который напрямую управляет индикацией портов, позволяя использовать их в качестве матричного индикатора — например, формата 24 × 4 пикселя в случае двух коммутаторов. На такой «панели» может отображаться «змейка», которая управляется джойстиком. Код опубликован на GitHub. Джезек признаёт, что его программа не оптимизирована, а её использование осуществляется «на свой страх и риск». 
Источник изображения: Ubiquiti Нужно отметить, что в семейство UniFi Professional Max входят L3-модели Pro Max 24 PoE и Pro Max 48 PoE. Первая располагает 24 портами RJ-45 в конфигурации 8 × 2.5GbE PoE++, 8 × 1GbE PoE+ и 8 × 1GbE PoE++. Кроме того, есть два разъёма 10GbE SFP+. Вторая модификация получила 48 портов RJ-45: 8 × 2.5GbE PoE+, 8 × 2.5GbE PoE++, 24 × 1GbE PoE+ и 8 × 1GbE PoE++. Плюс к этому доступны четыре разъёма 10GbE SFP+. Общая доступная мощность PoE составляет соответственно 400 и 720 Вт. Кроме того, предлагаются варианты без поддержки PoE.
17.01.2024 [13:19], Сергей Карасёв
Fortinet представила точку доступа FortiAP 441K: Wi-Fi 7 с ZigBee и BluetoothКомпания Fortinet анонсировала точку доступа FortiAP 441K стандарта Wi-Fi 7, ориентированную на корпоративных пользователей. В комплексе с этим устройством может применяться новый высокопроизводительный PoE-коммутатор FortiSwitch T1024 с поддержкой 10GbE. Точка доступа FortiAP 441K предназначена для установки внутри помещений. Она построена на платформе Qualcomm Networking Pro 1220 Wi-Fi 7 и оснащена внутренними антеннами. Говорится о поддержке MIMO 4x4, модуляции вплоть до 4096-QAM, а также каналов шириной до 320 МГц. Также есть модификация FortiAP 443K с внешними антеннами. Устройство способно функционировать в частотных диапазонах 2,4; 5 и 6 ГГц: максимальная канальная способность составляет соответственно 1,148; 8,648 и 11,530 Гбит/с. Кроме того, реализована поддержка технологий ZigBee и Bluetooth (BLE), а также GPS/ГЛОНАСС/Galileo. Возможно одновременное обслуживание до 512 клиентов. 
Источник изображений: Fortinet Новинка располагает двумя 10GbE-портами с разъёмами RJ-45, коннектором USB 3.0 и последовательным портом RS-232 (RJ-45). Габариты составляют 250 × 250 × 57,5 мм, вес — 1,98 кг. Диапазон рабочих температур — от 0 до +50 °C. Допускается монтаж на потолок, стену или рейку T-Rail.  В свою очередь, коммутатор FortiSwitch T1024 наделён 24 портами 10GbE на основе разъёмов RJ-45. Мощность PoE достигает 90 Вт. Данная модель спроектирована специально для работы с точками доступа стандарта Wi-Fi 7.
14.12.2023 [12:42], Сергей Карасёв
Netgear представила L2-коммутаторы серии S3600 стандарта 10GbE с облачным управлениемКомпания Netgear анонсировала интеллектуальные L2-коммутаторы семейства S3600 для бизнес-сферы. Устройства поддерживают фирменную платформу облачного управления Insight, которая обеспечивает комплексную удалённую настройку и устранение неполадок сетевого оборудования. Дебютировали модели XS508TM и XS516TM, оснащённые соответственно 8 и 16 портами 10GbE на основе разъёмов RJ-45. Возможна работа в режимах 1GbE, 2,5GbE и 5GbE. Оба устройства также располагают двумя портами 10GbE SFP+. 
Источник изображений: Netgear Среди возможностей коммутаторов названы конфигурируемые сетевые функции L2/L2+, включая VLAN и Rapid Spanning Tree, защита от DoS-атак, дистанционный мониторинг (SNMP v1, v2c, v3 и RMON), зеркалирование портов, интеллектуальный интерфейс командной строки (CLI). Новинки оснащены активным охлаждением: младшая версия получила два вентилятора, старшая — три. Скорость вращения крыльчатки регулируется в зависимости от температуры, благодаря чему уровень шума не превышает соответственно 28,63 дБА и 27,35 дБА (при 25 °C). Общий диапазон рабочих температур — от 0 до +50 °C.  Коммутаторы оборудованы встроенным блоком питания. Заявленное максимальное энергопотребление составляет 32,7 Вт у XS508TM и 63,9 Вт у XS516TM. Габариты устройств — 330 × 206 × 43 мм, вес — 2,20 и 2,45 кг соответственно. Новинки могут монтироваться в стойку, на стену или использоваться в «настольном» режиме. Цена — около $1000 и $1600.
09.12.2023 [23:32], Сергей Карасёв
Продажи Ethernet-коммутаторов корпоративного класса растут, а маршрутизаторов — падаютКомпания International Data Corporation (IDC) подвела квартальные итоги исследования мирового рынка сетевого оборудования корпоративного класса — коммутаторов Ethernet и маршрутизаторов. Отрасль показала смешанные результаты, несмотря на смягчение проблем с цепочками поставок, которые начались во время пандемии COVID-19. Продажи Ethernet-коммутаторов в III четверти 2023 года составили $11,7 млрд, что на 15,8 % больше год к году. В сегменте устройств для дата-центров выручка поднялась на 7,2 %, в сегменте решений для прочих корпоративных заказчиков — на 22,2 %. В рейтинг ведущих поставщиков коммутаторов Ethernet входят Cisco, Arista Networks, Huawei, HPE и H3C с долями соответственно 45,1 %, 10,6 %, 9,6 %, 7,7 % и 4,1 %. 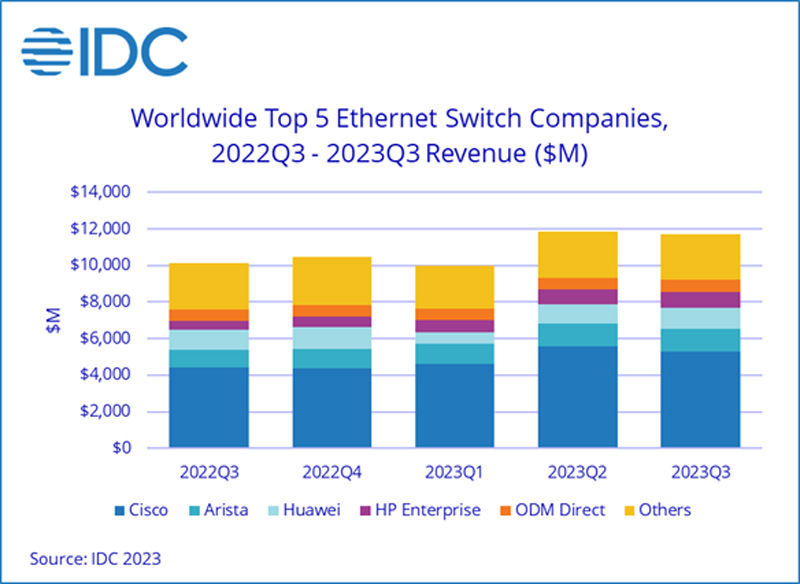
Источник изображения: IDC Поставки коммутаторов стандартов 200/400GbE для ЦОД выросли на 44,0 % по сравнению с прошлым годом, а количество реализованных портов поднялось на 63,9 %. Спрос на решения 100GbE увеличился на 6,0 % год к году, на модели 25/50GbE — на 26,3 %. По направлению коммутаторов для сегментов, не связанных с ЦОД, поставки устройств 1GbE прибавили 18,3 %, моделей 10GbE — 5,8 %. Выручка от оборудования 2,5/5GbE показала рост на 92,0 %. С географической точки зрения спрос на коммутаторы Ethernet увеличился в большинстве регионов мира. В США продажи в годовом исчислении поднялись на 26,7 %, в Канаде — на 28,6 %. В Латинской Америке зафиксирована прибавка на уровне 25,9 %, в Западной Европе — на 12,0 %, в Центральной и Восточной Европе — на 17,8%. В Азиатско-Тихоокеанском регионе (за исключением Японии и Китая) показан рост на 14,1 %. При этом в КНР продажи упали на 12,4 %, а в Японии — поднялись на 2,9 %. Что касается маршрутизаторов, то их отгрузки в III квартале 2023 года уменьшились на 9,4 %, составив $3,7 млрд. С региональной точки зрения продажи в Америке сократились на 7,3 %, в Азиатско-Тихоокеанском регионе — на 11,1 %, в Европе, на Ближнем Востоке и в Африке — на 10,4 %.
09.12.2023 [23:13], Сергей Карасёв
Cisco выпустила L3-коммутаторы Catalyst 1200/1300 с PoE для малого и среднего бизнесаКомпания Cisco анонсировала коммутаторы серий Catalyst 1200 и Catalyst 1300: в семейства вошло большое количество моделей с разным набором портов 1GbE и 10GbE. Новинки предназначены для использования в сфере малого и среднего бизнеса. Все устройства укомплектованы двухъядерным процессором Arm с тактовой частотой до 1,4 ГГц, который функционирует в тандеме с 1 Гбайт оперативной памяти DDR4. Предусмотрено 512 Мбайт флеш-памяти. В зависимости от модификации применяется пассивное или активное (с одним вентилятором) охлаждение. В оснащение входят от 8 до 52 сетевых портов (с разъёмами RJ-45 и коннекторами SFP/SFP+). Поддерживается технология PoE: в случае Catalyst 1200 суммарный бюджет мощности таких портов достигает 375 Вт, в случае Catalyst 1300 — 740 Вт. 
Источник изображения: Cisco Управляемые L3-коммутаторы Catalyst 1300 допускают объединение в стек до восьми устройств, что позволяет довести количество портов до 200. При этом полученная группа идентифицируется остальными сетевыми устройствами как один логический коммутатор (с одним IP-адресом). Решения Catalyst 1200, в свою очередь, поддерживают только статическую L3-маршрутизацию. Взаимодействовать с коммутаторами можно через мобильное приложение на смартфоне. Допускается также подключение внешнего Bluetooth-адаптера через порт USB для последующей работы посредством ноутбука или планшета. Заодно Cisco выпустила Meraki MX — устройство обеспечения безопасности с облачным управлением и SD-WAN. Решение предоставляет такие возможности, как брандмауэр, фильтрация контента, защита от угроз, VPN, управление работоспособностью VoIP и пр.
01.12.2023 [23:19], Алексей Степин
Broadcom представила первый сетевой коммутатор со встроенным ИИ-движкомКомпания Broadcom представила Trident 5-X12 — первый сетевой коммутатор, снабжённый ИИ-движком, который поможет избавиться от сетевых заторов и ускорить обучение ИИ. Новый сетевой процессор относится к семейству StrataXGS и имеет маркировку BCM78800. Он предназначен в первую очередь для компактных ToR-коммутаторов нового поколения. Это первый сетевой ASIC, дополненный инференс-движком NetGNT (Networking General-purpose Neural-network Traffic-analyzer). NetGNT может быть «натаскан» на распознавание ситуации, потенциально ведущей к сетевому затору. К примеру, в сценариях, характерных для обучения нейросетей, часто встречается ситуация, когда множество потоков пакетов прибывает одновременно на один порт, что и вызывает затор. Но движок Broadcom способен предсказать и заранее предотвратить такое развитие событий. 
Источник изображений здесь и далее: Broadcom Trident 5-X12 также имеет расширенную систему телеметрии и располагает объёмными FIB с гибким распределением. Реализованы множественные механизмы распределения нагрузки и предотвращения заторов. Новинка относится к программируемым решениям (NPL), причём готовые сценарии предлагает и сама Broadcom. В рамках API сохранена совместимость с предыдущими решениями компании. Возможно использование SONiC. 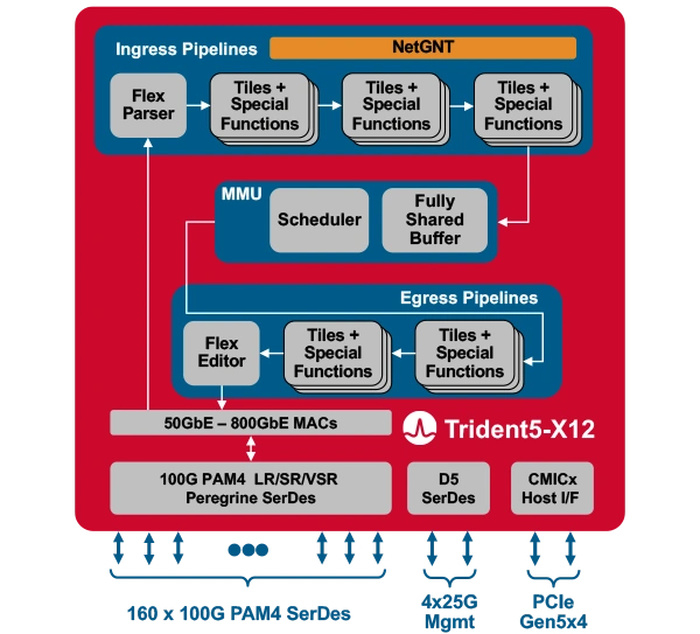 Чип оснащён 160 100G-блоками SerDes (PAM-4) и позволяет среди прочего реализовывать смешанные конфигурации — например, с 24 портами 400G и 8 портами 800G в 1U-шасси. При этом совокупная пропускная способность составляет 16 Тбит/с, однако благодаря 5-нм техпроцессу энергопотребление у новинки в пересчёте на порт на четверть ниже, нежели у Trident 4-X9. |
|