Материалы по тегу: архитектура
|
16.11.2020 [20:44], Алексей Степин
Подробности об архитектуре AMD CDNA ускорителей Instinct MI100Лидером в области использования графических архитектур для вычислений долгое время была NVIDIA, однако давний соперник в лице AMD вовсе не собирается сдавать свои позиции. В ответ на анонс архитектуры Ampere и ускорителей нового поколения A100 на её основе компания AMD сегодня ответила своим анонсом первого в мире ускорителя на основе архитектуры CDNA — сверхмощного процессора Instinct MI100. Достаточно долго подход к проектированию графических чипов оставался унифицированным, однако быстро выяснилось, что то, что хорошо для игр, далеко не всегда хорошо для вычислений, а некоторые возможности для областей применения, не связанных с рендерингом 3D-графики, попросту избыточны. Примером могут служить модули растровых операций (RBE/ROP) или наложения текстур. Произошло то, что должно было произойти: слившиеся на какое-то время воедино ветви эволюции «графических» и «вычислительных» процессоров вновь начали расходиться. И новый процессор AMD Instinct MI100 относится к чисто вычислительной ветви развития подобного рода чипов.  Теперь AMD имеет в своём распоряжении две основных архитектуры, RDNA и CDNA, которые и представляют собой вышеупомянутые ветви развития GPU. Естественно, новый процессор Instinct MI100 унаследовал у своих собратьев по эволюции многое — в частности, блоки исполнения скалярных и векторных инструкций: в конце концов, всё равно, работают ли они для расчёта графики или для вычисления чего-либо иного. Однако новинка содержит и ряд отличий, позволяющих ей претендовать на звание самого мощного и универсального в мире ускорителя на базе GPU. 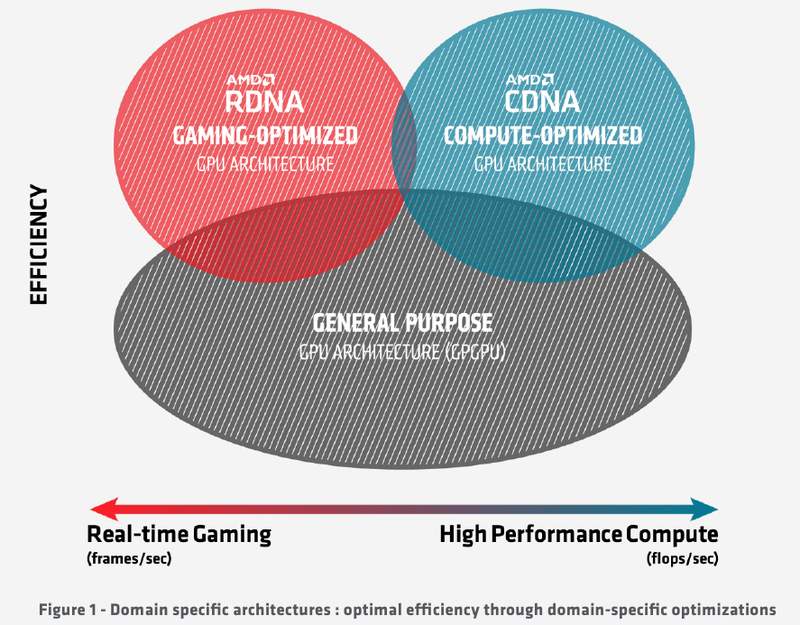
Схема эволюции графических процессоров: налицо дивергенция признаков AMD в последние годы существенно укрепила свои позиции, и это отражается в создании собственной единой IP-инфраструктуры: новый чип выполнен с использованием 7-нм техпроцесса и все системы интерконнекта, как внутренние, так и внешние, в MI100 базируются на шине AMD Infinity второго поколения. Внешние каналы имеют ширину 16 бит и оперируют на скорости 23 Гт/с, однако если в предыдущих моделях Instinct их было максимум два, то теперь количество каналов Infinity Fabric увеличено до трёх. Это позволяет легко организовывать системы на базе четырёх MI100 с организацией межпроцессорного общения по схеме «все со всеми», что минимизирует задержки. 
Ускорители Instinct MI100 получили третий канал Infinity Fabric Общую организацию внутренней архитектуры процессор MI100 унаследовал ещё от архитектуры GCN; его основу составляют 120 вычислительных блоков (compute units, CU). При принятой AMD схеме «64 шейдерных блока на 1 CU» это позволяет говорить о 7680 процессорах. Однако на уровне вычислительного блока архитектура существенно переработана, чтобы лучше отвечать требованиям, предъявляемым современному вычислительному ускорителю. В дополнение к стандартным блокам исполнения скалярных и векторных инструкций добавился новый модуль матричной математики, так называемый Matrix Core Engine, но из кремния MI100 удалены все блоки фиксированных функций: растеризации, тесселяции, графических кешей и, конечно, дисплейного вывода. Универсальный движок кодирования-декодирования видеоформатов, однако, сохранён — он достаточно часто используется в вычислительных нагрузках, связанных с обработкой мультимедийных данных. 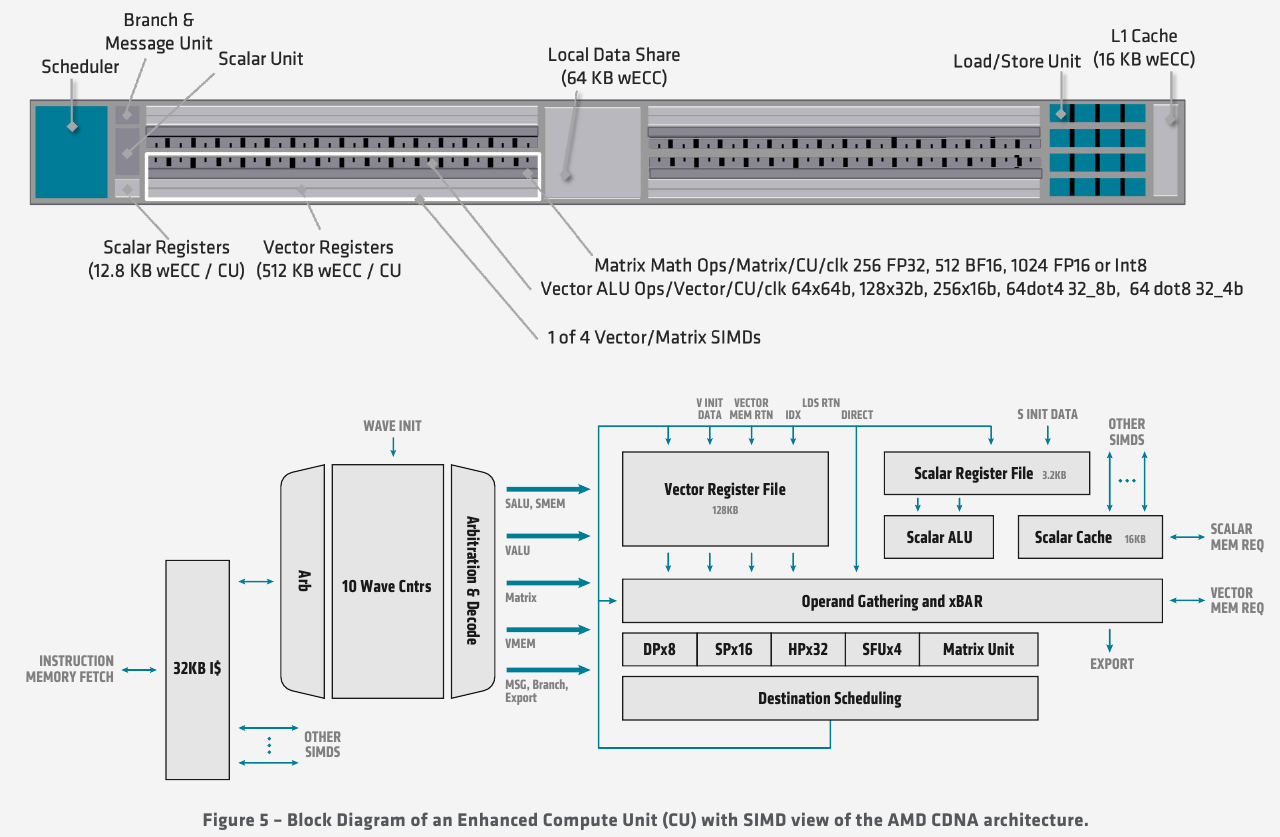
Структурная схема вычислительных модулей в MI100 Каждый CU содержит в себе по одному блоку скалярных инструкций со своим регистровым файлом и кешем данных, и по четыре блока векторных инструкций, оптимизированных для вычислений в формате FP32 саналогичными блоками. Векторные модули имеют ширину 16 потоков и обрабатывают 64 потока (т.н. wavefront в терминологии AMD) за четыре такта. Но самое главное в архитектуре нового процессора — это новые блоки матричных операций. Наличие Matrix Core Engines позволяет MI100 работать с новым типом инструкций — MFMA (Matrix Fused Multiply-Add). Операции над матрицами размера KxN могут содержать смешанные типы входных данных: поддерживаются режимы INT4, INT8, FP16, FP32, а также новый тип Bfloat16 (bf16); результат, однако, выводится только в форматах INT32 или FP32. Поддержка столь многих типов данных введена для универсальности и MI100 сможет показать высокую эффективность в вычислительных сценариях разного рода. 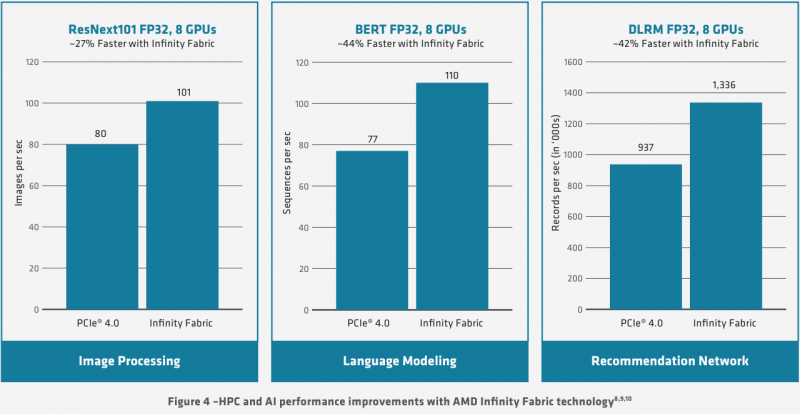
Использование Infinity Fabric 2.0 позволило ещё более увеличить производительность MI100 Каждый блок CU имеет свой планировщик, блок ветвления, 16 модулей load-store, а также кеши L1 и Data Share объёмами 16 и 64 Кбайт соответственно. А вот кеш второго уровня общий для всего чипа, он имеет ассоциативность 16 и объём 8 Мбайт. Совокупная пропускная способность L2-кеша достигает 6 Тбайт/с. Более серьёзные объёмы данных уже ложатся на подсистему внешней памяти. В MI100 это HBM2 — новый процессор поддерживает установку четырёх или восьми сборок HBM2, работающих на скорости 2,4 Гт/с. Общая пропускная способность подсистемы памяти может достигать 1,23 Тбайт/с, что на 20% быстрее, нежели у предыдущих вычислительных ускорителей AMD. Память имеет объём 32 Гбайт и поддерживает коррекцию ошибок. 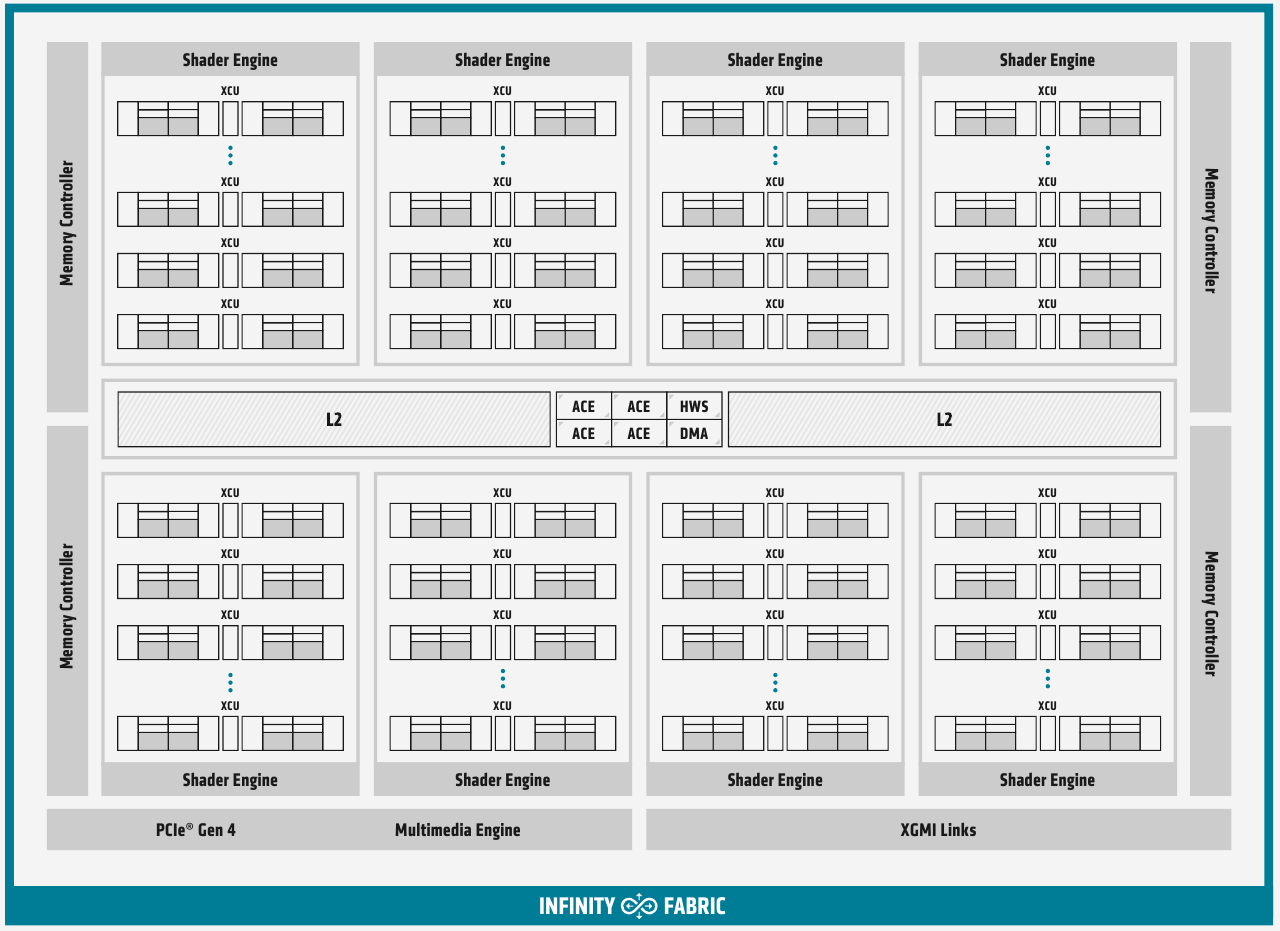
Общая блок-схема Instinct MI100 «Мозг» чипа Instinct MI100 составляют четыре командных процессора (ACE на блок-схеме). Их задача — принять поток команд от API и распределить рабочие задания по отдельным вычислительным модулям. Для подключения к хост-процессору системы в составе MI100 имеется контроллер PCI Express 4.0, что даёт пропускную способность на уровне 32 Гбайт/с в каждом направлении. Таким образом, «уютнее всего» ускоритель Instinct MI100 будет чувствовать себя совместно с ЦП AMD EPYC второго поколения, либо в системах на базе IBM POWER9/10. Избавление от лишних архитектурных блоков и оптимизация архитектуры под вычисления в как можно более широком числе форматов позволяют Instinct MI100 претендовать на универсальность. Ускорители с подобными возможностями, как справедливо считает AMD, станут важным строительным блоком в экосистеме HPC-машин нового поколения, относящихся к экзафлопсному классу. AMD заявляет о том, что это первый ускоритель, способный развить более 10 Тфлопс в режиме двойной точности FP64 — пиковый показатель составляет 11,5 Тфлопс. 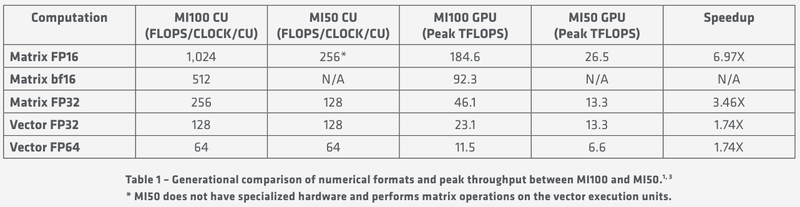
Удельные и пиковые показатели производительности MI100 В менее точных форматах новинка пропорционально быстрее, и особенно хорошо ей даются именно матричные вычисления: для FP32 производительность достигает 46,1 Тфлопс, а в новом, оптимизированном под задачи машинного обучения bf16 — и вовсе 92,3 Тфлопс, причём, ускорители Instinct предыдущего поколения таких вычислений выполнять вообще не могут. В зависимости от типов данных, превосходство MI100 перед MI50 варьируется от 1,74х до 6,97x. Впрочем, NVIDIA A100 в этих задача всё равно заметно быстрее, а вот в FP64/FP32 проигрывают. |
|