Материалы по тегу: mosaicml
|
04.07.2023 [17:20], Владимир Мироненко
Обойдёмся без NVIDIA: MosaicML перенесла обучение ИИ на ускорители AMD Instinct MI250 без модификации кодаРазработчик решений в области генеративного ИИ MosaicML, недавно перешедший в собственность Databricks, сообщил о хороших результатах в обучении больших языковых моделей (LLM) с использованием ускорителей AMD Instinct MI250 и собственной платформы. Компания рассказала, что подыскивает от имени своих клиентов новое «железо» для машинного обучения, поскольку NVIDIA в настоящее время не в состоянии обеспечить своими ускорителями всех желающих. MosaicML пояснила, что требования к таким чипам просты:

Источник изображений: MosaicML Как отметила компания, ни один из чипов до настоящего времени смог полностью удовлетворить все требования MosaicML. Однако с выходом обновлённых версий фреймворка PyTorch 2.0 и платформы ROCm 5.4+ ситуация изменилась — обучение LLM стало возможным на ускорителях AMD Instinct MI250 без изменений кода при использовании её стека LLM Foundry. 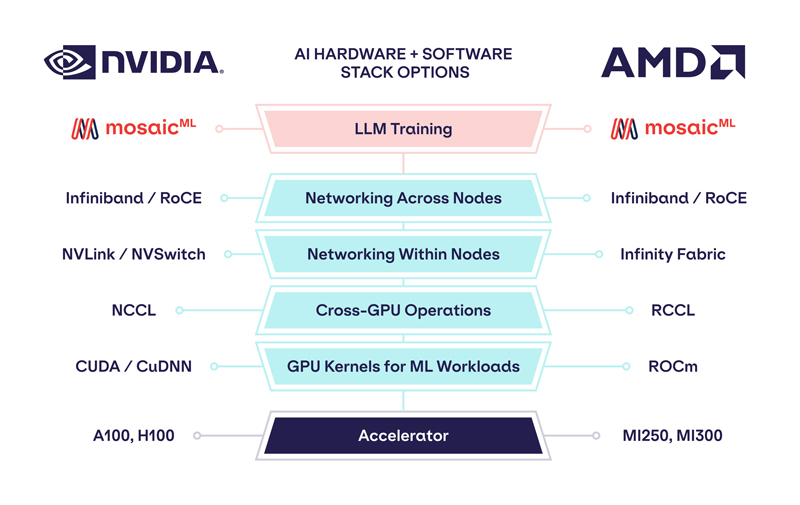 Некоторые основные моменты:
При этом никаких изменений в коде не потребовалось. 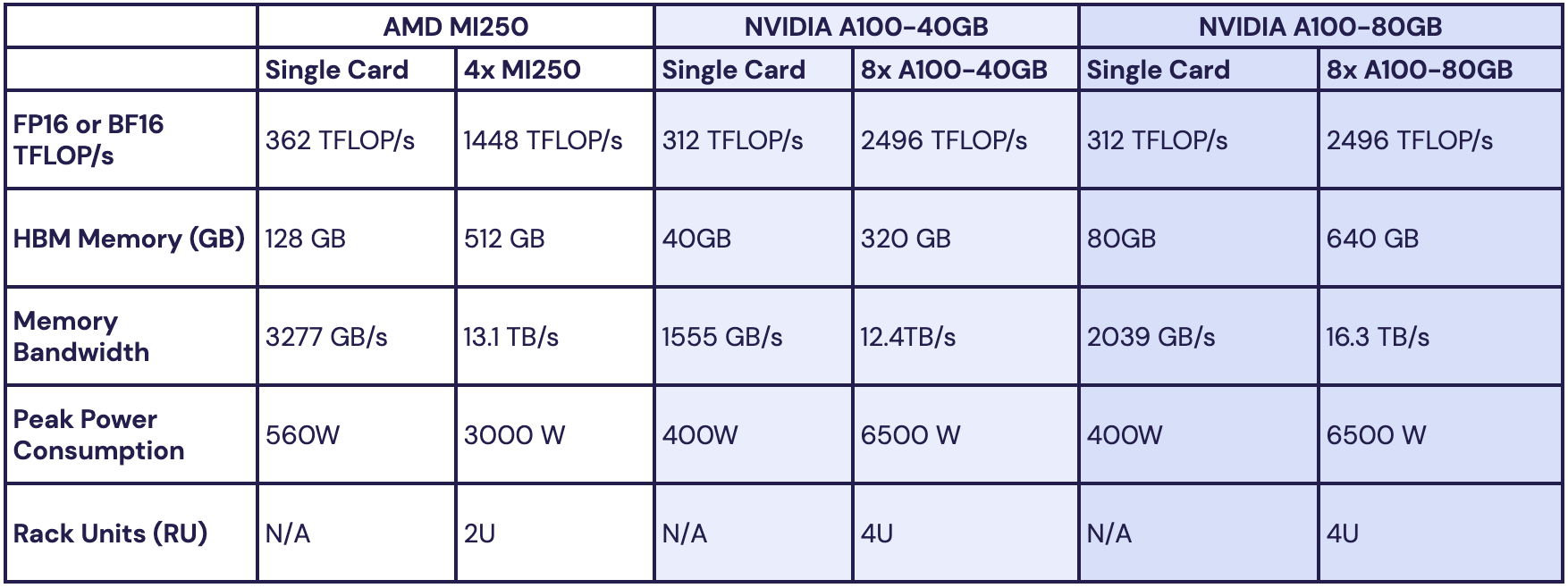 Все результаты получены на одном узле из четырёх MI250, но компания работает с гиперскейлерами для проверки возможностей обучения на более крупных кластерах AMD Instinct. «В целом наши первоначальные тесты показали, что AMD создала эффективный и простой в использовании программно-аппаратный стек, который может конкурировать с NVIDIA», — сообщила MosaicML. Это важный шаг в борьбе с доминирующим положением NVIDIA на рынке ИИ.
27.06.2023 [16:56], Владимир Мироненко
Databricks купила разработчика генеративного ИИ MosaicML за $1,3 млрдСтартап Databricks, разработчик платформы машинного обучения, анализа и обработки данных, объявил о приобретении компании-разработчика решений в области генеративного ИИ MosaicML Inc. С помощью разработанных MosaicML языковых моделей компании смогут обучать и выполнять точную настройку генеративных ИИ-моделей на основе собственных данных с высоким качеством и низкой стоимостью, а технологии оптимизации обучения моделей MosaicML помогут снизить затраты. MosaicML наиболее известна своим собственным семейством больших языковых моделей (LLM) MPT, с более чем 3,3 млрд загрузок модели MPT-7B. Семейство LLM компании с открытым исходным кодом основано на архитектуре MPT-7B, построенной с 7 млрд параметров и контекстным окном на 64 тыс. токенов. На днях MosaicML выпустила модель MPT-30B с 30 млрд параметров, которая гораздо мощнее MPT-7B и превосходит по качеству модель OpenAI GPT-3 (175 млрд параметров). 
Источник изображения: MosaicML MosaicML сообщила, что размер MPT-30B был специально подобран для развёртывания всего на одном ускорителе — либо NVIDIA A100 80 Гбайт (16-бит точность), либо A100 40 Гбайт (8-бит точность). По словам MosaicML, другие сопоставимые LLM, такие как Falcon-40B, имеют большее количество параметров и не могут обслуживаться на одном ускорителе, что увеличивает минимальную стоимость системы инференса. Платформа Databricks Lakehouse в сочетании с технологиями MosaicML предложит клиентам простой, быстрый и экономичный способ сохранить контроль над данными, а также обеспечить их безопасность и защитить правf собственности. Размещая модели в Databricks Lakehouse, компании смогут адаптировать их к конкретным корпоративным данным и безопасно развёртывать их. Использование обслуживаемых моделей, таких как от OpenAI, может привести к утечке данных и другим рискам. Это особенно важно для строго регулируемых отраслей — модель и данные должны оставаться вместе в изолированном окружении. 
Источник изображения: Databricks Кроме того, решения MosaicML обеспечивают в 2–7 раз более быстрое обучение моделей по сравнению со стандартными подходами, предлагая при этом линейное масштабирование. Компания утверждает, что модели с несколькими миллиардами параметров теперь можно обучить за часы, а не за дни. Согласно пресс-релизу, при применении интегрированной платформы Databricks и MosaicML обучение и использование LLM будет стоить тысячи долларов, а не миллионы. «Теперь Databricks может расширить свою платформу для создания, обучения и размещения традиционных моделей машинного обучения на большие языковые модели, — заявил Джастин ДеБрабант (Justin DeBrabant), старший вице-президент ActionIQ Inc. — Это означает, что Databricks предлагает продукты и услуги на платформе Lakehouse. которые простираются от ETL до аналитики SQL, пользовательского машинного обучения, а теперь и до размещённых LLM».
03.05.2023 [21:12], Владимир Мироненко
MosaicML представила инференс-платформу Mosaic ML Inference и серию моделей MosaicML Foundation SeriesMosaicML, провайдер инфраструктуры генеративного искусственного интеллекта, основанный бывшими сотрудниками Intel и учёными-исследователями, анонсировал инференс-платформу Mosaic ML Inference и серию моделей MosaicML Foundation Series, которые компании могут задействовать в качестве основы при создании собственных моделей ИИ. Как сообщается в пресс-релизе, это решение позволит разработчикам быстро, легко и по доступной цене развёртывать генеративные модели ИИ. «Благодаря добавлению возможностей инференса MosaicML теперь предлагает комплексное решение для обучения и развёртывания генеративного ИИ по наиболее эффективной цене, доступной на сегодняшний день», — отмечено в документе. Клиенты MosaicML отметили, что малые модели, обученные на собственных предметно-ориентированных данных, работают лучше, чем большие универсальные модели вроде GPT 3.5. 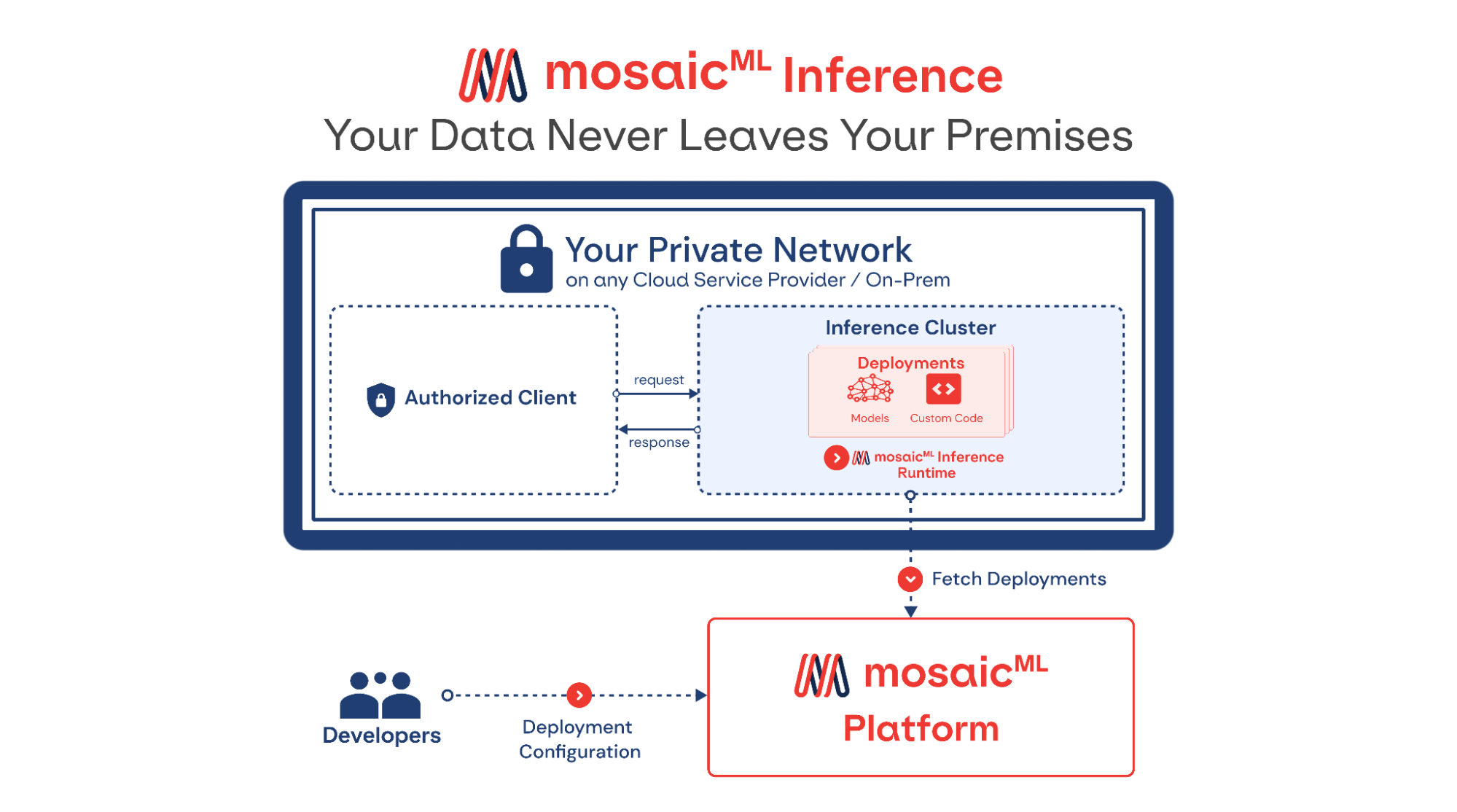
Источник изображений: MosaicML Гендиректор Навин Рао (Naveen Rao) сообщил ресурсу SiliconANGLE, что ценность решения компании для корпоративных клиентов включает два компонента: сохранение конфиденциальности и снижение затрат. Используя решение Inference от MosaicML, клиенты смогут развёртывать ИИ-модели с затратами в четыре раза меньше, чем при использовании большой языковой модели (LLM) от OpenAI, и в 15 раз дешевле при создании изображений, чем при использовании DALL-E 2 этой же компании. «Мы предоставляем инструменты, работающие в любом облаке, которые позволяют клиентам предварительно обучать, настраивать и обслуживать модели, — сказал Рао. — Если клиент обучает модель, он может быть уверен, что эта модель принадлежит ему». С запуском нового сервиса клиенты MosaicML получают доступ к ряду LLM с открытым исходным кодом, включая Instructor-XL, Dolly и GPTNeoX, которые они могут точно настроить в соответствии со своими потребностями. Все модели получат одинаковую оптимизацию и доступность, что позволит им функционировать с меньшими затратами при развёртывании с помощью MosaicML Inference. 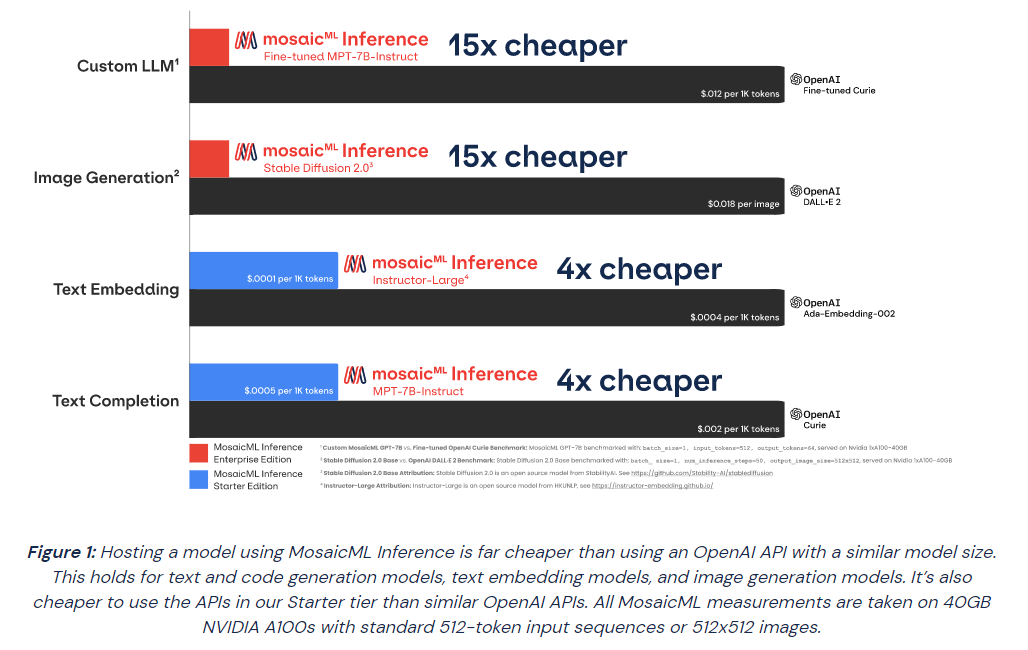 «Это модели с открытым исходным кодом, поэтому клиенты по определению могут настраивать и настраивать и обслуживать их с помощью наших инструментов, — сказал Рао. Компания готова помочь клиентам в работе с их ИИ-моделям. Разработчики смогут выполнять развёртывание в безопасном кластере локально или в облачной инфраструктуре AWS, CoreWeave, Lambda, OCI и GCP. Данные никогда не покидают защищённую среду. Также MosaicML Inference предлагает непрерывный мониторинг метрик кластера. Кроме того, компания предлагает модель MosaicML Foundational Model, одним из преимуществ которой является очень большое «контекстное окно» — более 64 тыс. токенов или около 50 тыс. слов. Для сравнения, максимальное количество токенов GPT-4 составляет 32 768 или около 25 тыс. слов. Чтобы продемонстрировать работу модели, Рао предоставил ей содержание «Великого Гэтсби» Ф. Скотта Фицджеральда и попросил написать эпилог. |
|