Материалы по тегу: pci express 5.0
|
17.10.2025 [10:47], Сергей Карасёв
SK hynix показала 245-Тбайт SSD серии PS1101 для дата-центровКомпания SK hynix в ходе мероприятия Dell Technologies Forum 2025 в Сеуле (Южная Корея) продемонстрировала свои новейшие SSD, оптимизированные для высокопроизводительных серверов и дата-центров для ИИ. В частности, показаны устройства PEB110, PS1010, PS1012 и PS1101. 
Источник изображения: SK hynix Особого внимания заслуживает накопитель PS1101. Это решение, выполненное в форм-факторе E3.L, вмещает 245 Тбайт информации. Новинка ориентирована на крупномасштабные ИИ ЦОД и облачные среды, где критически важны высокая плотность хранения данных и энергоэффективность. В основу SSD положены чипы флеш-памяти QLC NAND, а для подключения служит интерфейс PCIe 5.0 х4. Скоростные показатели и величина IOPS пока не раскрываются. 
Источник изображения: SK hynix Устройству PS1101 предстоит конкурировать с другими SSD аналогичной ёмкости, о подготовке которых уже сообщили некоторые игроки рынка. В частности, Kioxia в июле нынешнего года анонсировала накопитель серии LC9 типоразмера EDSFF E3.L, рассчитанный на хранение 245,76 Тбайт данных. Кроме того, Sandisk представила NVMe SSD UltraQLC SN670 объёмом 256 Тбайт, предназначенный для ИИ-систем и НРС-платформ. А компания Samsung проектирует SSD с интерфейсом PCIe 6.0, вместимость которых будет достигать 512 Тбайт. 
Источник изображения: SK hynix Возвращаясь к новинкам SK hynix, можно выделить изделие PS1012 в форм-факторе U.2, которое вмещает до 61,44 Тбайт данных. Устройство выполнено на чипах флеш-памяти QLC NAND и оснащено интерфейсом PCIe 5.0 х4. В свою очередь, модель PEB110 типоразмера E1.S имеет вместимость до 8 Тбайт: этот продукт базируется на чипах TLC NAND с подключением посредством PCIe 5.0 х4. Наконец, изделие PS1010 получило исполнение E3.S, чипы TLC NAND, интерфейс PCIe 5.0 х4 и ёмкость до 15 Тбайт.
14.10.2025 [16:15], Сергей Карасёв
Intel подготовила 200GbE-адаптеры серии E835 для дата-центровВ начале текущего года корпорация Intel анонсировала сетевые контроллеры и адаптеры семейства Ethernet E830 с поддержкой стандарта 200GbE для корпоративных, облачных и периферийных развёртываний. А теперь появилась информация об изделиях серии Ethernet E835 с улучшенными характеристиками. 
Источник изображений: Intel Новые адаптеры ориентированы на дата-центры и телекоммуникационные инфраструктуры. Заявлена поддержка хост-интерфейсов PCIe 5.0 х8 и PCIe 4.0 х16. Intel предложит варианты в конфигурациях с портами 1 × 200GbE, 2 × 100GbE, 2 × 25GbE, 4 × 25GbE и 8 × 25GbE.  Реализована поддержка протоколов управления OS2BMC и OCP NIC 3.0, средств безопасности Secure Boot, SPDM (Security Protocol and Data Model), MCTP Type 6 и Root of Trust (на аппаратном уровне), а также стандартов FIPS 140-3 Level 1 и NIST SP800-193. Как и в случае с решениями Ethernet E830, имеется поддержка PTM (Precision Time Measurement), 1588 PTP и SyncE.  Судя по представленному изображению, устройства серии Ethernet E835 оборудованы пассивным охлаждением на основе крупного радиатора. Среди прочего говорится о совместимости с RDMA iWARP и RoCE v2. Сетевые адаптеры оптимизированы для использования в системах с процессорами Xeon 6. От решений Ethernet E830 унаследованы такие технологии, как Virtual Machine Device Queues (VMDq), Flexible Port Partitioning (FPP), Intel Data Direct I/O и др.
10.10.2025 [12:00], Сергей Карасёв
AMD представила Ethernet-адаптеры Solarflare X4 со сверхнизкой задержкойКомпания AMD анонсировала Ethernet-адаптеры Solarflare X4 для систем, в которых критическое значение имеет минимальная задержка. Это могут быть платформы для трейдинга, анализа финансовых данных в реальном времени и других задач, где, как подчеркивается, важна каждая наносекунда. В семейство Solarflare X4 вошли две модели — X4542 и X4522. По сравнению с изделиями Solarflare предыдущего поколения новинки, по заявлениям AMD, обеспечивают уменьшение задержки до 40 %. Производительность на системном уровне увеличилась на 200 % по отношению к адаптерам Solarflare X2. Обе новинки выполнены в виде низкопрофильных карт расширения половинной длины с интерфейсом PCIe 5.0 x8. В основу положена кастомизированная ASIC, обеспечивающая сверхнизкие задержки. AMD уверяет, что при использовании адаптеров в связке с процессорами EPYC 4005 Grado достигается снижение задержки до 12 % по сравнению с аналогичными по классу решениями конкурентов. 
Источник изображения: AMD Версия Solarflare X4542 оснащена двумя разъёмами QSFP с поддержкой двух портов 40/50/100GbE или четырёх портов 1/10/25GbE. Модификация Solarflare X4522, в свою очередь, получила два разъёма SFP с поддержкой пары портов 1/10/25/50GbE. Карты оснащены пассивным охлаждением. Энергопотребление составляет менее 25 Вт. Для адаптеров доступно фирменное ПО AMD Solarflare Onload, которое отвечает за повышение производительности при работе с ресурсоёмкими сетевыми приложениями, такими как резидентные базы данных, программные балансировщики нагрузки и веб-серверы. Solarflare Onload помогает поднять эффективность обработки огромных объёмов небольших пакетов данных — даже в периоды пиковой нагрузки. AMD отмечает, что 9 из 10 крупнейших мировых фондовых бирж используют решения Solarflare для обеспечения работы своих торговых платформ.
22.09.2025 [13:02], Сергей Карасёв
ASRock представила видеокарты Intel Arc Pro B60 для рабочих станций с ИИКомпания ASRock анонсировала видеокарты Intel Arc Pro B60 Passive 24GB и Intel Arc Pro B60 Creator 24GB для профессиональных рабочих станций, ориентированных на задачи ИИ, большие языковые модели (LLM), дизайн, 3D-моделирование и пр. Новинки выполнены на архитектуре Intel Xe2-HPG и оснащены 24 Гбайт памяти GDDR6 со 192-битной шиной (19 Гбит/с). Модель Intel Arc Pro B60 Passive 24GB, наделённая пассивным охлаждением, имеет однослотовое исполнение. Карта будет доступна исключительно бизнес-заказчикам. В свою очередь, Intel Arc Pro B60 Creator 24GB получила активный кулер (с бесшумным режимом 0dB Silent Cooling) и двухслотовое исполнение. Обе новинки могут использоваться в конфигурациях с несколькими GPU в Linux-средах, что делает их подходящими для серверных развёртываний в рамках масштабных ИИ-платформ. 
Источник изображений: ASRock Видеокарты располагают 20 ядрами Xe2-HPG и 160 матричными движками (XMX). Частота ядра составляет 2400 МГц. Задействован интерфейс PCIe 5.0. Дополнительное питание подаётся через 8-контактный коннектор. Говорится о поддержке Microsoft DirectX 12 Ultimate. Доступны четыре интерфейса DisplayPort 2.1 — основной с поддержкой UHBR13.5 и три дополнительных с поддержкой UHBR10. Видеокарта Intel Arc Pro B60 Passive 24GB имеет размеры 190 × 112 × 19 мм и весит 566 г. Габариты Intel Arc Pro B60 Creator 24GB составляют 271 × 112 × 39 мм, масса — 1118 г.  Некоторые ретейлеры уже начали приём предварительных заказов на эти решения. Так, на сайте американского магазина Central Computers версия Intel Arc Pro B60 Creator 24GB предлагается по ориентировочной цене $600.
09.09.2025 [15:46], Сергей Карасёв
d-Matrix представила 400GbE-адаптер JetStream для объединения своих ИИ-ускорителейСтартап d-Matrix анонсировал специализированную IO-карту JetStream, предназначенную для распределения нагрузок ИИ-инференса между серверами в дата-центре. Устройство ориентировано на использование в связке с ускорителями d-Matrix Corsair, архитектура которых основана на модифицированных ячейках SRAM для вычислений в памяти (DIMC). JetStream использует стандарт Ethernet, благодаря чему обладает совместимостью с уже существующими коммутаторами. Новинка выполнена в виде платы расширения с интерфейсом PCIe 5.0 х16. Используются корзины QSFP-DD. Могут быть задействованы два 200GbE-порта со скоростью 200 Гбит/с или один 400GbE-порт. Архитектура серверов d-Matrix для ИИ-инференса предполагает установку ускорителей Corsair с DMX-мостом между каждыми двумя такими картами для обеспечения высокой пропускной способности без использования PCIe. Затем пары ускорителей объединяются посредством коммутатора PCIe. В эталонном дизайне один NIC JetStream обслуживает до четырёх экземпляров Corsair. d-Matrix утверждает, что сетевую задержку в такой конфигурации удалось сократить до 2 мкс. 
Источник изображений: d-Matrix По заявлениям d-Matrix, карты JetStream могут применяться в существующих ЦОД без необходимости замены дорогостоящих инфраструктурных компонентов. В связке с ИИ-ускорителями Corsair и ПО d-Matrix Aviator решения JetStream способны справляться с ИИ-моделями, насчитывающими более 100 млрд параметров. При этом, как утверждает разработчик, обеспечивается в 10 раз более высокая производительность, в три раза лучшая экономическая эффективность и втрое большая энергоэффективность по сравнению с решениями на базе GPU. 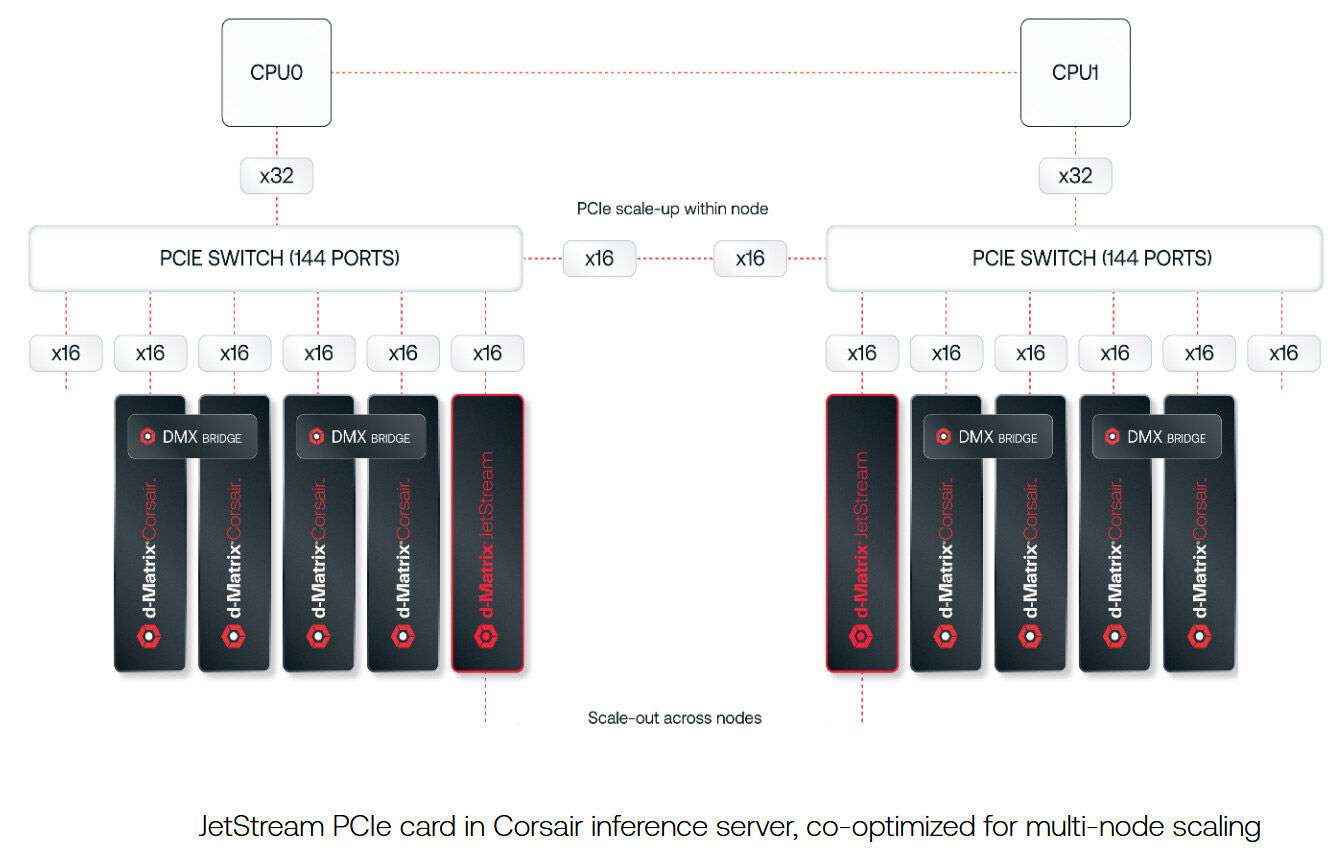 Энергопотребление JetStream составляет около 150 Вт. Адаптер оснащён системой охлаждения с радиатором и тепловыми трубками, которые охватывают зону QSFP-DD. Пробные поставки новинки уже начались, а массовое производство запланировано на конец текущего года.
20.08.2025 [11:13], Сергей Карасёв
SSSTC представила SSD серии CA8 — первые на рынке индустриальные M.2-накопители с памятью Kioxia BiCS Flash восьмого поколенияКомпания Solid State Storage Technology Corporation (SSSTC) анонсировала SSD семейства CA8, предназначенные для применения в интеллектуальных устройствах интернета вещей, платформах промышленной автоматизации, периферийных компьютерах, автомобильных системах и пр. По заявлениям SSSTC, изделия CA8 — это первые на рынке индустриальные устройства M.2 2280 с памятью Kioxia BiCS Flash восьмого поколения. Применены 218-слойные флеш-чипы 3D TLC NAND с технологией CBA (CMOS direct Bonded to Array), которая, как утверждается, существенно повышает энергоэффективность, производительность и плотность хранения данных по сравнению с решениями предыдущего поколения. 
Источник изображения: SSSTC В серию CA8 вошли модели вместимостью 512 Гбайт, а также 1, 2 и 4 Тбайт. Для подключения служит интерфейс PCIe 5.0 х4 (NVMe 2.0). Заявленная скорость последовательного чтения информации достигает 14 000 Мбайт/с, скорость последовательной записи — 12 000 Мбайт/с. Величина IOPS (операций ввода/вывода в секунду) составляет до 2 млн при произвольном чтении и 1,6 млн при произвольной записи: это, как подчеркивается, одни из самых высоких значений для индустриальных SSD, доступных на рынке. Диапазон рабочих температур простирается от 0 до +85 °C. Значение MTBF (средняя наработка на отказ) превышает 3 млн часов. Упомянута поддержка AES-256 и TCG Opal. Функция Power Loss Notification (PLN) предотвращает повреждение данных при неожиданных отключениях питания. Накопители способны выдерживать более одной полной перезаписи в сутки (1 DWPD) на протяжении пяти лет.
12.08.2025 [14:51], Владимир Мироненко
NVIDIA анонсировала компактные ускорители RTX PRO 4000 Blackwell SFF Edition и RTX PRO 2000 BlackwellNVIDIA объявила о предстоящем выходе GPU NVIDIA RTX PRO 4000 Blackwell SFF Edition и NVIDIA RTX PRO 2000 Blackwell, «воплощающих мощь архитектуры NVIDIA Blackwell в компактном и энергоэффективном форм-факторе», которые «обеспечат ИИ-ускорение для профессиональных рабочих процессов в различных отраслях». Новинки отличаются вдвое меньшими размерами по сравнению с традиционными GPU, и при этом оснащены RT-ядрами четвёртого поколения и тензорными ядрами пятого поколения с пониженным энергопотреблением. Как сообщает NVIDIA, новые ускорители разработаны для обеспечения производительности нового поколения для различных профессиональных рабочих процессов, обеспечивая «невероятное» ускорение процессов проектирования, дизайна, создания контента, ИИ и 3D-визуализации. По сравнению с ускорителем предыдущего поколения RTX A4000 SFF, модель RTX PRO 4000 SFF обеспечивает до 2,5 раза более высокую производительность в обработке ИИ-нагрузок и в 1,5 раза более высокую пропускную способность памяти, обеспечивая большую эффективность при том же максимальном энергопотреблении 70 Вт. 
Источник изображений: NVIDIA Ускоритель включает 8960 ядер NVIDIA CUDA, 24 Гбайт памяти GDDR7 ECC со 192-бит шиной и пропускной способностью 432 Гбайт/с. Используется интерфейс PCIe 5.0 x8. ИИ-производительность составляет 770 TOPS, RT-ядер — 73 TOPS, в формате FP32 — 24 TOPS. Доступно 2 движка NVENC девятого поколения и 2 движка NVDEC шестого поколения. Есть 4 разъёма DisplayPort 2.1b. Оптимизированная для массового проектирования и рабочих ИИ-процессов, RTX PRO 2000 обеспечивает до 1,6 раза более быстрое 3D-моделирование, в 1,4 раза более высокую производительность систем автоматизированного проектирования (САПР) и в 1,6 раза более высокую скорость рендеринга по сравнению с предыдущим поколением. Компания отметила, что инженеры САПР, продуктовые инженеры и специалисты творческих профессий по достоинству оценят 1,4-кратный прирост производительности RTX PRO 2000 при генерации изображений и 2,3-кратный прирост производительности при генерации текста, что обеспечивает более быструю итерацию, быстрое прототипирование и бесперебойную совместную работу.  RTX PRO 2000 оснащена 4352 ядрами NVIDIA CUDA, 16 Гбайт памяти GDDR7 ECC со 128-бит шиной и пропускной способностью 288 Гбайт/с. Используется интерфейс PCIe 5.0 x8. ИИ-производительность составляет 545 TOPS, RT-ядер — 54 TOPS, в формате FP32 — 17 TOPS. Доступно по одному движку NVENC девятого поколения и NVDEC шестого поколения. Есть 4 разъёма DisplayPort 2.1b. NVIDIA сообщила, что ускорители NVIDIA RTX PRO 2000 Blackwell и NVIDIA RTX PRO 4000 Blackwell SFF Edition поступят в продажу позже в этом году, не указав конкретные сроки.
12.08.2025 [11:39], Сергей Карасёв
InnoGrit выпустила SSD N3X со сверхнизкой задержкой для ИИ-системКомпания InnoGrit официально представила SSD семейства N3X для ИИ-платформ и периферийных вычислений. Устройства, обладающие повышенной надёжностью, доступны в вариантах вместимостью 800 Гбайт, а также 1,6 и 3,2 Тбайт. О подготовке накопителей InnoGrit-N3X сообщалось в конце мая текущего года. Тогда говорилось, что устройства оснащены контроллером InnoGrit Tacoma IG5669 и чипами памяти Kioxia XL-Flash второго поколения, функционирующими в режиме SLC. Применяется интерфейс PCIe 5.0 x4 (NVMe 2.0). По новой информации, задействован контроллер InnoGrit IG5668. Изделия обладают сверхнизкой задержкой: 13 мкс при чтении и 4 мкс при записи. Показатель при чтении, как утверждается, на 75 % ниже по сравнению со стандартными твердотельными накопителями с интерфейсом PCIe 5.0. Заявленная скорость последовательного чтения достигает 14 Гбайт/с, скорость последовательной записи — 12 Гбайт/с. Показатель IOPS (операций ввода/вывода в секунду) составляет до 1,6 млн при произвольной записи блоков данных по 4 Кбайт — это примерно в четыре раза выше, чем у типичных решений PCIe 5.0 для ЦОД. 
Источник изображения: InnoGrit SSD серии InnoGrit-N3X способны выдерживать до 100 полных перезаписей в сутки (100 DWPD): благодаря этому они подходят для использования в составе систем с высокой интенсивностью обмена данными. Реализованы средства сквозной защиты информации и шифрование по алгоритму AES-256. Функция Power Loss Protection (PLP) отвечает за сохранность данных при внезапном отключении питания. Устройства выпускаются в двух форм-факторах — U.2 и E1.S.
10.08.2025 [15:24], Сергей Карасёв
Silicon Motion продемонстрировала решения с SSD на основе контроллера MonTitan SM8366Компания Silicon Motion показала ряд продуктов, оснащённых высокопроизводительными SSD на базе контроллера MonTitan SM8366. Решение MonTitan SM8366 ориентировано на накопители для дата-центров и инфраструктур гиперскейлеров. Обеспечивается поддержка PCIe 5.0 x4, NVMe 2.0a и OCP 2.0. Доступны 16 независимых каналов NAND Flash, а заявленная производительность достигает 2400 MT/s. Скорость последовательной передачи данных может превышать 14,2 Гбайт/с, величина IOPS — 3,5 млн при работе с блоками данных по 4 Кбайт. Возможно создание накопителей в форматах E1.S, E1.L, U.2/3. Поддерживается память DDR4-3200 и DDR5-4800 в одно- и двухканальном режимах. Контроллер выполнен в корпусе FCBGA с размерами 21 × 21 мм.  В рамках FMS 2025 продемонстрирована система VAST Data Ceres V2 Dbox, оснащённая накопителями Unigen семейства Cheetah с контроллером MonTitan SM8366. Это, в частности, SSD формата E1.L вместимостью 128 Тбайт на чипах QLC NAND, а также изделия стандарта U.2 ёмкостью 3,2 Тбайт с чипами SLC NAND. Система VAST Data Ceres V2 Dbox выполнена в форм-факторе 1U и наделена DPU NVIDIA BlueField-3. 
Источник изображения: Silicon Motion Кроме того, показан сервер небольшой глубины Aetina AEX-2UA1 для периферийных вычислений, в состав которого включены накопители Innodisk 5TS-P на основе MonTitan SM8366. Система построена на модульной платформе NVIDIA MGX. Отмечается, что сервер Aetina AEX-2UA1 предоставляет ИИ-возможности в средах с ограниченным пространством для установки оборудования.
09.08.2025 [13:19], Сергей Карасёв
Беспортовый контроллер: Microchip представила RAID-ускорители Adaptec SmartRAID 4300 для NVMe-хранилищКомпания Microchip Technology анонсировала ускорители Adaptec SmartRAID 4300 для дата-центров, поддерживающих ресурсоёмкие нагрузки, в том числе связанные с ИИ. Решения предназначены для работы с массивами NVMe RAID в составе программно-определяемых хранилищ (SDS). Концепция Adaptec SmartRAID 4300 предполагает разделение платформы Microchip Smart Storage на программные и аппаратные компоненты. В данном случае CPU отвечает за непосредственную запись данных на твердотельные накопители, полноценно используя скоростные возможности интерфейса PCIe. Вместе с тем дополнительные расчёты (в том числе XOR-операции) переносятся с хост-процессора на RAID-ускоритель. Такой подход, как утверждается, устраняет узкие места, присущие традиционным решениям с последовательным подключением. В результате, достигается высокий уровень гибкости и масштабируемости. Возможно подключение до 32 устройств NVMe SSD с интерфейсом PCIe 4.0 х4 или PCIe 5.0 х4. По оценкам Microchip, изделия Adaptec SmartRAID 4300 обеспечивают семикратное увеличение производительности ввода-вывода (I/O) по сравнению с решениями предыдущего поколения. 
Источник изображений: Microchip В частности, в средах Windows показатель IOPS в режимах RAID 0 и RAID 5 достигает 5 млн при произвольном чтении данных блоками по 4 Кбайт и соответственно 4,8 млн и 2,3 млн при произвольной записи. Скорость последовательного чтения составляет до 317 Гбайт/с (RAID 0) и 291 Гбайт/с (RAID 5), скорость последовательной записи — до 120 Гбайт/с (RAID 0) и 26 Гбайт/с (RAID 5). При работе с Linux скорости значительно выше. Так, величина IOPS в режимах RAID 0 и RAID 5 при произвольном чтении достигает 27,2 млн и 27,3 млн соответственно, при произвольной записи — 22,4 млн и 5,1 млн. Скорость последовательного чтения — до 300 и 291 Гбайт/с, последовательной записи — до 196 и 155 Гбайт/с. 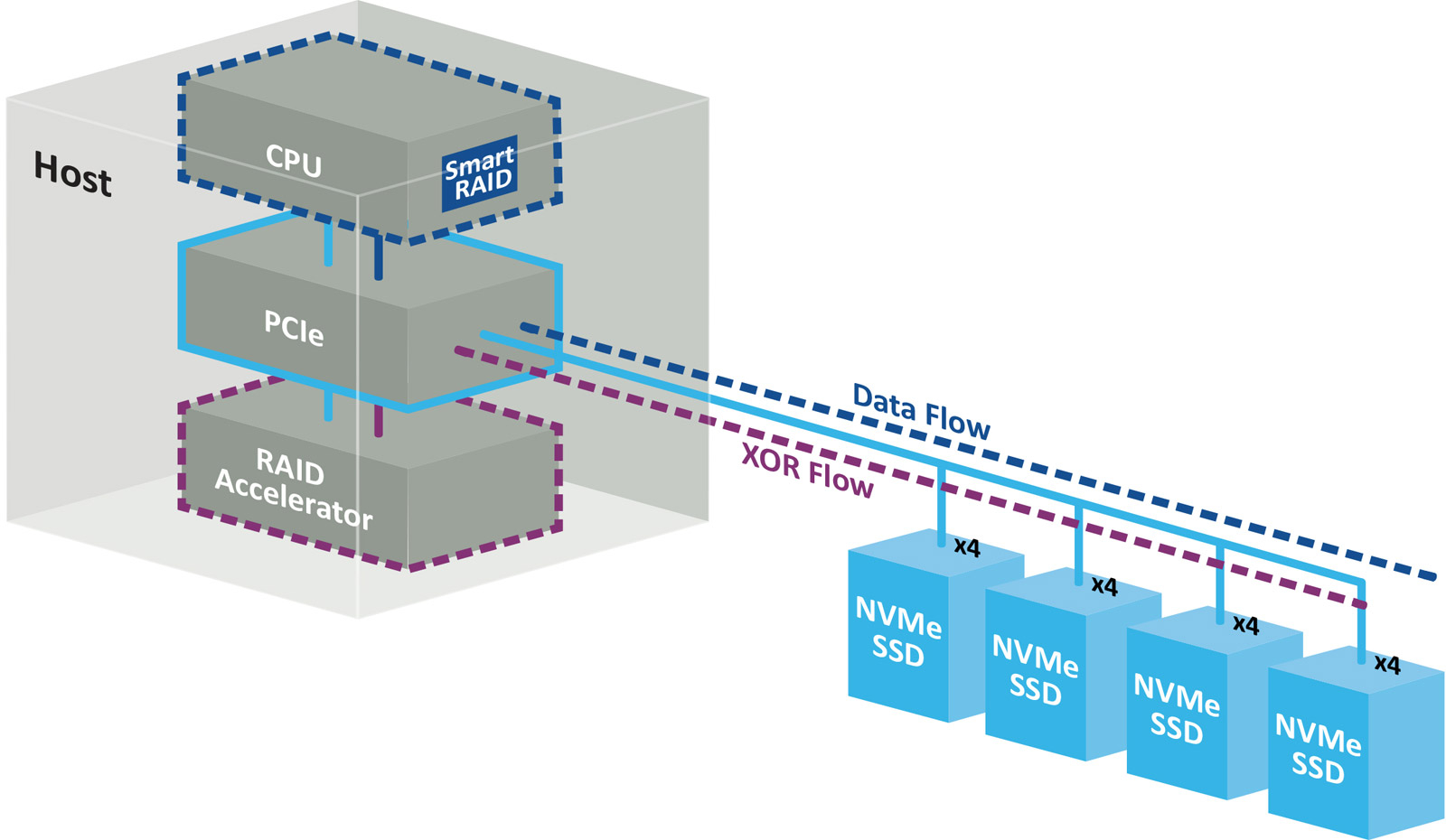 Ускорители выполнены в виде низкопрофильной (HHHL) карты расширения с интерфейсом PCIe 4.0 х16. Поддерживаются массивы RAID 0/1/5/10/50. Габариты составляют 68,9 × 167,65 мм. Значение MTBF (средняя наработка на отказ) — до 3 млн часов при температуре до +40 °C. Гарантирована совместимость с Windows Server, Red Hat Enterprise Linux, SuSE Linux Enterprise Server, Oracle Linux. |
|