Материалы по тегу: hpc
|
22.06.2020 [18:20], Игорь Осколков
ARM-суперкомпьютер Fugaku поднялся на вершину рейтингов TOP500, HPCG и HPL-AIКонечно же, речь идёт о японском суперкомпьютере Fugaku на базе ARM-процессоров A64FX, который досрочно начал трудиться весной этого года. Эта машина стала самым мощным суперкомпьютером в мире сразу в трёх рейтингах: классическом TOP500, современном HPCG и специализированном HPL-AI.  Суперкомпьютер состоит из 158976 узлов, которые имеют почти 7,3 млн процессорных ядер, обеспечивающих реальную производительность на уровне 415,5 Пфлопс, то есть Fugaku почти в два с половиной раза быстрее лидера предыдущего рейтинга, машины Summit. Правда, оказалось, что с точки зрения энергоэффективности новая ARM-система мало чем отличается от связки обычного процессора и GPU, которой пользуется большая часть суперкомпьютеров. Так что на первое место в Green500 она не попала.   Однако на стороне Fugaku универсальность — понижение точности вычислений вдвое приводит к удвоение производительности. Так что машина имеет впечатляющую теоретическую пиковую скорость вычислений 4,3 Эопс на INT8 и не менее впечатляющие 537 Пфлопс на FP64. Это помогло занять её первое место в бенчмарке HPL-AI, которые использует вычисления разной точности. А общая архитектура процессора, включающего набортную память HBM2, и системы, использующей интерконнект Tofu, способствовали лидерству в бенчмарке HPCG, который оценивает эффективность машины в целом. 
09.06.2020 [19:49], Юрий Поздеев
Суперкомпьютер Neocortex: 800 тыс. ядер Cerebras для ИИПиттсбургский суперкомпьютерный центр (PSC) получит $5 млн от Национального научного фонда на создание суперкомпьютера нового типа Neocortex, который объединяет ИИ-серверы Cerebras CS-1 и HPE SuperDome Flex в единую систему с общей памятью. Планируется, что решение будет введено в эксплуатацию до конца 2020 года.  Каждый сервер Cerebras CS-1 имеет процессор Cerebras Wafer Scale Engine (WSE), который содержит 400 000 ядер, оптимизированных для работы с ИИ (46 225 мм2, 1,2 трлн транзисторов). В паре с ними работает HPE SuperDome Flex, который используется для предварительной обработки информации и постобработки после Cerebras. SuperDome Flex представлен в максимальной комплектации, то есть с 32 процессорами Intel Xeon, 24 Тбайт оперативной памяти, 205 Тбайт флеш-памяти и 24 интерфейсными картами.  Каждый сервер Cerebras CS-1 подключается к SuperDome Flex через 12 каналов со скоростью 100 Гбит/с каждый. Процессор WSE способен обрабатывать 9 Пбайт данных в секунду, что, по подсчетам Nystrom, эквивалентно примерно миллиону фильмов в HD-качестве. Характеристики решения действительно впечатляют! 
Neocortex назван в честь области мозга, отвечающей за функции высокого порядка, включая когнитивные способности, сновидения и формирование речи Архитектура решения строилась таким образом, чтобы не пришлось разбивать вычислительные блоки на множество узлов — это позволило снизить задержки в обработке информации и ускорить обучение моделей ИИ. Cerebras CS-1 разрабатывался специально для ИИ, поэтому он имеет преимущества перед серверами с графическими ускорителями, которые хорошо справляются с матричными операциями, но имеют многие конструктивные ограничения.  По заявлениям Neocortex, сервер CS-1 будет на несколько порядков мощнее системы PSC Bridges-AI. Один сервер Neocortex CS-1 будет эквивалентен примерно 800-1500 серверов с традиционной архитектурой с использованием графических ускорителей. Задачи, в которых Neocortex покажет себя максимально эффективно относятся к классу нейронных сетей DCIGN (deep convolutional inverse graphics networks) и RNN (recurrent neural networks). Если говорить простыми словами, то это более точное прогнозирование погоды, анализ геномов, поиск новых материалов и разработка новых лекарств. 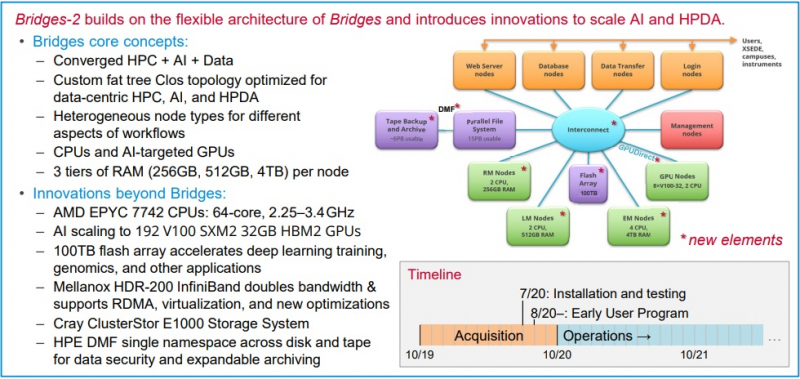 PSC, помимо Neocortex, запускает еще и новое поколение системы Bridges-2, которое будет развернуто осенью 2020 года. Таким образом, до конца этого года будут введены в эксплуатацию два мощных суперкомпьютера для ИИ. Neocortex и Bridges-2 будут поддерживать самые популярные фреймворки машинного обучения, что позволит создать гибкую и мощную экосистему для ИИ, анализа данных, моделирования и симуляции. До 90% машинного времени Neocortex будет выделяться через XSEDE (Extreme Science and Engineering Discovery Environment), финансируемую NSF организацию, которая координирует совместное использование передовых цифровых услуг, включая суперкомпьютеры и ресурсы для визуализации и анализа данных, с исследователями на национальном уровне.
23.02.2019 [20:20], Геннадий Детинич
Анонс серверных платформ ARM Neoverse E1 и N1: шах и мат, IntelУж извините за столь кричащий заголовок, но ARM давно мечтает сказать нечто подобное в отношении серверных платформ Intel. Пока получается не очень. Как говорят в самой ARM, не вышло с первого раза, попробуем во второй. Не получится во второй раз, на третий точно всё будет как надо. А сейчас и повод-то отличный! Разработчики оригинальных ядер ARM из одноимённой компании ударили сразу с двух направлений: по масштабируемым сетевым платформам (Neoverse E1) и по масштабируемым серверным (Neoverse N1). Очевидно, что пока «мата» в этой партии явно не будет. Intel крепко держится за серверные платформы и одновременно тянет руки к периферийным как в виде распределённых вычислительных ресурсов в составе базовых станций, так и в виде обычных периферийных ЦОД. Тем не менее, шансы объявить Intel «шах» у ARM определённо есть.  Рассчитанную на несколько лет вперёд стратегию Neoverse компания ARM представила в середине октября прошлого года. Она предполагает три крупных этапа, в ходе которых будут выходить доступные для широкого лицензирования 64-битные ядра ARM Ares (7 нм), Zeus (7 и 5 нм) и Poseidon (5 нм). Планируется, что каждый год производительность решений будет возрастать на 30 %. Сама компания ARM, напомним, не выпускает процессоры и SoC, а лишь продаёт лицензии на ядра и архитектуру, которые клиенты компании обустраивают нужными им контроллерами и интерфейсами. У ARM настолько многочисленная армия клиентов, что она ожидает буквально цунами из сотен и тысяч миллиардов ядер в год уже в недалёком будущем. Когда-нибудь в этот водоворот ядер будут вовлечены и серверные платформы, а затем количество перейдёт в качество.  Разработка и анонс ядер Neoverse N1 ― это явление народу 7-нм ядер Ares. Процессоры могут нести от 4 до 128 ядер, объединённых согласованной ячеистой сетью. Платформа N1 может служить периферийным компьютером с 8-ядерным процессором с потреблением менее 20 Вт, а может стать сервером в ЦОД на 128-ядерных процессорах с потреблением до 200 Вт. Степень масштабируемости должна впечатлять. Кроме этого, как сообщают в ARM, производительность ядер N1 на облачных нагрузках в 2,5 раза выше, чем у 16-нм ядер предыдущего поколения Cosmos (Cortex-A72, A75 и A53). Кстати, прошлой осенью на платформе Cosmos компания Amazon представила фирменный процессор Graviton. 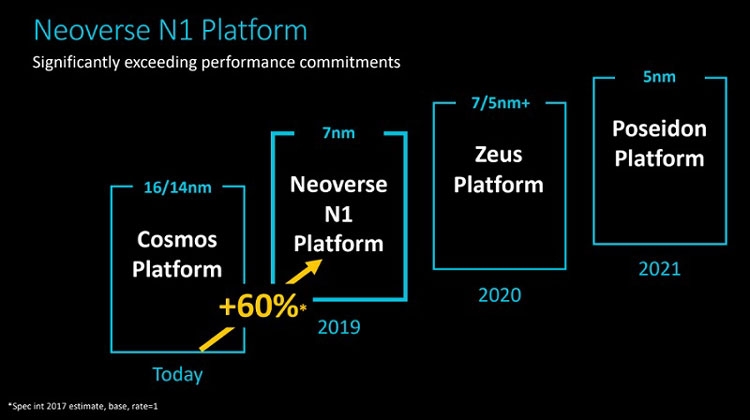 Производительность N1 при обработке целочисленных значений оказывается на 60 % больше, чем на ядрах Cortex-A72 Cosmos. При этом энергоэффективность ядер N1 также на 30 % выше, чем у ядер Cortex-A72. Как поясняют разработчики, платформа Neoverse N1 построена на «таких инфраструктурных расширениях, как виртуализация серверного класса, современная поддержка сервисов удалённого доступа, управление питанием и производительностью и профилями системного уровня». 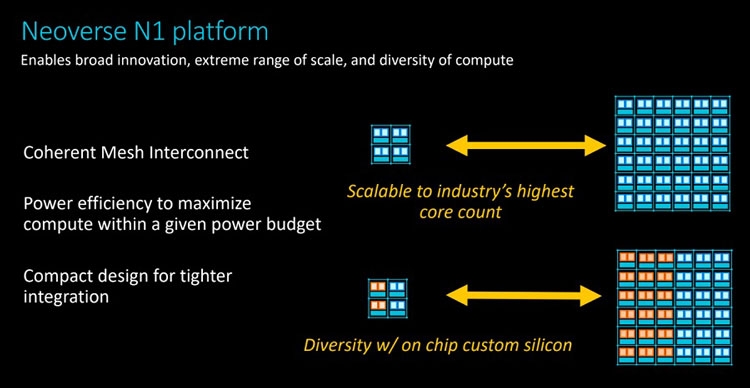 Когерентная ячеистая сеть (Coherent Mesh Network, CMN), о которой выше уже говорилось, разработана с учётом высокого соответствия вычислительным возможностям ядер. По словам ARM, сеть обменивается с ядрами такой служебной информацией, которая позволяет устанавливать объём загрузки в память данных для упреждающей выборки, распределяет кеш между ядрами и определяет, как он может быть использован, а также делает много других вещей, которые способствуют оптимизации вычислений. Интересно отметить, что в составе процессоров на платформе Neoverse N1 может быть существенно больше 128 ядер, но с оптимальной работой возникнут проблемы. Точнее, вычислительная производительность упрётся в пропускную способность памяти. Так, ARM рекомендует для CPU с числом ядер от 64 до 96 использовать 8-канальный контроллер DDR4, а для 96–128 ядерных версий ― контроллер памяти DDR5. Платформа Neoverse E1 ― это решение для сетевых шлюзов, коммутаторов и сетевых узлов, которое, например, облегчит переход от сетей 4G к сетям 5G с их возросшей требовательностью к каналам передачи данных. Так, Neoverse E1 обещает рост пропускной способности в 2,7 раза, увеличение эффективности при передаче данных в 2,4 раза, а также более чем 2-кратный рост вычислительной мощности по сравнению с предыдущими платформами (ядрами). С масштабируемостью ядер E1 тоже всё в порядке, они позволят создать решение как для базовых станций начального уровня с потреблением менее 35 Вт, так и маршрутизатор с пропускной способностью в сотни гигабайт в секунду. Что же, ARM расставила на доске новые фигуры. Будет интересно узнать, кто же начнёт игру?
22.08.2018 [13:00], Геннадий Детинич
Раскрыты спецификации ARM-процессоров Fujitsu A64FX для суперкомпьютера Post-KПримерно через три года начнётся коммерческая эксплуатация суперкомпьютера Post-K, который компании Fujitsu и RIKEN разрабатывают на смену предыдущей совместной системы суперкомпьютера K (начал работать в 2011 году). Новая система Post-K обещает 100-кратно поднять производительность на уровне приложений. И сделано это будет благодаря переходу Fujitsu на ARM-совместимые ядра и новую архитектуру с масштабируемыми векторными инструкциями (Scalable Vector Extensions).  На прошедшей на днях конференции Hot Chips 30 (2018) компания Fujitsu впервые обнародовала спецификации новых процессоров, которые получили обозначение A64FX. Ни «A», ни «64», ни «FX» не имеют отношение к компании AMD, хотя в названии новых суперпроцессоров Fujitsu что-то немного согревает душу. Это процессоры с поддержкой 64-разрядных команд ARM и векторных инструкций длиной до 512 бит. Каждый процессор Fujitsu A64FX будет нести 48 вычислительных ядер и 4 вспомогательных ядра, разделённые на четыре блока, соединённых внутренней кольцевой шиной. Для связи с другими процессорами Fujitsu использует две линии внешнего интерфейса Tofu с пропускной способностью 28 Гбит/с. Строение процессора и внешний скоростной интерфейс обещают значительное наращивание параллелизма в вычислениях. 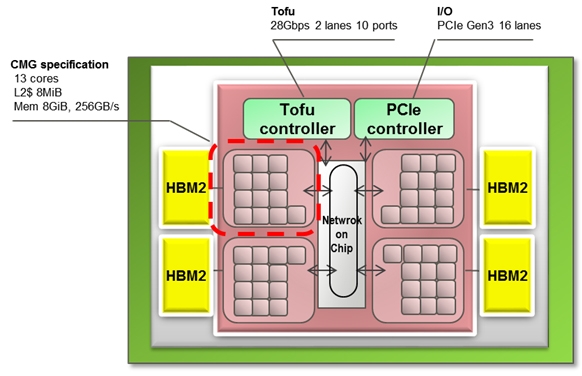
Fujitsu Каждый из 13-ядерных блоков поддержан кеш-памятью L2 объёмом 8 Мбайт. Кроме этого каждый из блоков напрямую обращается к модулю стековой памяти HBM2 объёмом 8 Гбайт. Суммарный объём памяти HBM2 у каждого процессора насчитывает 32 Гбайт, а общая скорость доступа достигает 1024 Гбайт/с. Поскольку память HBM2 можно рассматривать в качестве кеш-памяти третьего уровня, все или большинство операций выполняются в процессоре, что обещает отличный прирост производительности.  Процессор Fujitsu A64FX выпускается с использованием 7-нм техпроцесса, очевидно, что на линиях компании TSMC. Он насчитывает 8,7 млрд транзисторов. Пиковая производительность процессора для операций с двойной точностью достигает 2,7 терафлопс. Процессор без потерь на переход может вычислять операции с одинарной точностью и половинной, соответственно, в два и четыре раза быстрее. Также, за что надо благодарить тему машинного обучения, процессор A64FX оптимизирован для обработки 16- и 8-битных целочисленных значений. 
29.07.2018 [13:00], Геннадий Детинич
Американские ВВС получили самый большой в мире нейроморфный суперкомпьютерЗвучит громко, но это именно так. Лаборатория Air Force Research Laboratory (AFRL) в городе Ром, штат Нью-Йорк, получила в своё распоряжение самый большой в мире компьютер по числу задействованных в системе нейроморфных процессоров IBM TrueNorth. Система представлена полочными компьютерами высотой 4U (7 дюймов) для стандартной серверной стойки. Каждый компьютер располагает 64 процессорами IBM TrueNorth. В пересчёте на человеческие в буквальном смысле единицы измерения мозга — это 64 млн нейронов и 16 млрд синапсов. Всего в стойке может разместиться 512 млн цифровых нейронов. Примерно столько нейронов в коре головного мозга собаки. 
AFRL Система под именем «Blue Raven» на базе IBM TrueNorth для Лаборатории ВВС США представлена пока 64-процессорным решением с общим потреблением 40 Вт. Это, кстати, в 4 раза больше ожидаемого. Аналогичный 16-процессорный компьютер, переданный в 2016 году Ливерморской национальной лаборатории им. Лоуренса, потреблял всего 2,5 Вт или 156 мВт на один процессор. Возможно таким образом была повышена производительность системы, которая при потреблении 70 мВт способна работать с производительностью 46 млрд синаптических операций в секунду. 
IBM По оценкам IBM, работа процессоров TrueNorth с необозначенным датасетом на CIFAR-100 по распознаванию наборов изображений характеризуется производительностью свыше 1500 кадров в секунду с потреблением 200 мВт или свыше 7000 кадров в секунду на ватт. Ускоритель NVIDIA Tesla P4 (Pascal GP104), например, обрабатывает датасет Resnet-50 с производительностью 27 кадров в секунду на ватт. 
Структура процессора IBM TrueNorth Вообще, в Лаборатории AFRL, похоже, работают увлечённые люди. Новым проектом «Blue Raven» руководит тот же человек (Mark Barnell), который несколько лет назад отметился запуском суперкомпьютера Condor Cluster на базе сотен игровых консолей Sony PlayStation 3. Какими расчётами в AFRL будет заниматься суперкомпьютер с «мозгами» не уточняется. Пока учёные будут изучать круг задач, решаемый подобными системами. Ожидается, что принятая на «вооружение» научным отделом ВВС США вычислительная система обеспечит дальнейшее приоритетное развитие технологий в этой стране.
29.06.2018 [13:00], Геннадий Детинич
Опубликованы финальные спецификации CCIX 1.0: разделяемый кеш и PCIe 4.0Чуть больше двух лет назад в мае 2016 года семёрка ведущих компаний компьютерного сектора объявила о создании консорциума Cache Coherent Interconnect for Accelerators (CCIX, произносится как «see six»). В число организаторов консорциума вошли AMD, ARM, Huawei, IBM, Mellanox, Qualcomm и Xilinx, хотя платформа CCIX объявлена и развивается в рамках открытых решений Open Compute Project и вход свободен для всех. В основе платформы CCIX лежит дальнейшее развитие идеи согласованных (когерентных) вычислений вне зависимости от аппаратной реализации процессоров и ускорителей, будь то архитектура x86, ARM, IBM Power или нечто уникальное. Скрестить ежа и ужа — вот едва ли не буквальный смысл CCIX. 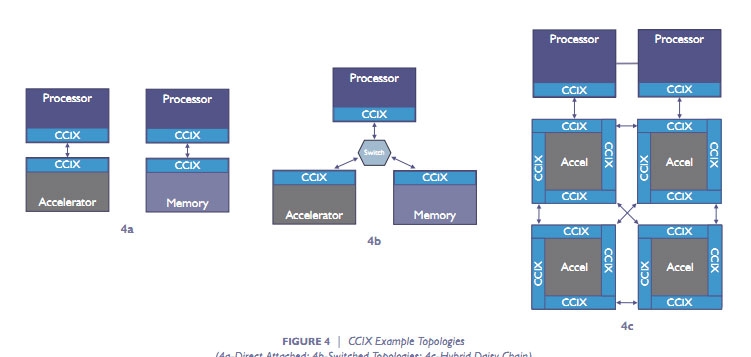
Варианты топологии CCIX На днях консорциум сообщил, что подготовлены и представлены финальные спецификации CCIX первой версии. Это означает, что вскоре с поддержкой данной платформы на рынок может выйти первая совместимая продукция. По словам разработчиков, CCIX позволит организовать новый класс подсистем обмена данными с согласованием кеша с низкими задержками для следующих поколений облачных систем, искусственного интеллекта, больших данных, баз данных и других применений в инфраструктуре ЦОД. Следующая ступенька в производительности невозможна без эффективных гетерогенных (разнородных) вычислений, которые смешают в одном котле исполнение кода общего назначения и спецкода для ускорителей на базе GPU, FPGA, «умных» сетевых карт и энергонезависимой памяти. 
Решение CCIX IP компании Synopsys Базовые спецификации CCIX Base Specification 1.0 описывают межчиповый и «бесшовный» обмен данными между вычислительными ресурсами (процессорными ядрами), ускорителями и памятью во всём её многообразии. Все эти подсистемы объединены разделяемой виртуальной памятью с согласованием кеша. В основе спецификаций CCIX 1.0, добавим, лежит архитектура PCI Express 4.0 и собственные наработки в области быстрой коррекции ошибок, что позволит по каждой линии обмениваться данными со скоростью до 25 Гбайт/с. 
Тестовая платформа с поддержкой CCIX Synopsys на FPGA матрице Но главное, конечно, не скорость обмена, хотя это важная составляющая CCIX. Главное — в создании программируемых и полностью автономных процессов по обмену данными в кешах процессоров и ускорителей, что реализуется с помощью новой парадигмы разделяемой виртуальной памяти для когерентного кеша. Это радикально упростит создание программ для платформ CCIX и обеспечит значительный прирост в ускорении работы гетерогенных платформ. Вместо механизма прямого доступа к памяти (DMA), со всеми его тонкостями для обмена данными, на платформе CCIX достаточно будет одного указателя. Причём обмен данными в кешах будет происходить без использования драйвера на уровне базового протокола CCIX. Ждём в готовой продукции. Кто первый, AMD, ARM или IBM? 
Тестовый набор CCIX 
Рабочая демо-система с неназванным CPU и FPGA, соединённых шиной CCIX
30.09.2017 [00:15], Алексей Степин
Терафлопс в космосе: на МКС тестируется компьютер HPE SpaceborneБытует мнение, что в космической отрасли используется всё самое лучшее, включая компьютерные компоненты. Это не совсем так: вы не встретите в космических аппаратах 18-ядерных Xeon и ускорителей Tesla. Во-первых, энергетические резервы за пределами Земли строго ограничены, и даже на МКС никто не будет тратить несколько киловатт на питание «космического суперкомпьютера». Во-вторых, практически вся электроника, работающая за пределами атмосферы, выпускается в специальном радиационно-стойком исполнении. Чаще всего за счёт техпроцессов «кремний на диэлектрике» (SOI) и «сапфировая подложка» (SOS), используется также биполярная логика вместо менее стойкой к внешним излучениям CMOS. 
Мини-кластер в космическом исполнении. Охлаждение жидкостное Мощными в космосе считаются такие решения, как BAE Systems серии RAD, особенно новая RAD5500 (от 1 до 4 ядер, 45-нм SOI, PowerPC, 64 бита). Четырёхъядерный вариант RAD5545 развивает производительность более 3,7 гигафлопс при потреблении около 20 ватт. Иными словами, вычислительные мощности в космосе тоже растут, но совсем иными темпами, нежели на Земле. Тому подтверждением служит недавно вступивший в строй на борту Международной космической станции компьютер HPE Spaceborne. Если на Земле мощность суперкомпьютеров измеряется десятками и сотнями петафлопс, то Spaceborne куда скромнее — судя по проведённым тестам, его вычислительная мощность достигает 1 терафлопса. Достигнута она путём сочетания современных процессоров Intel с ускорителями NVIDIA Tesla P100 (NVLink-версия). 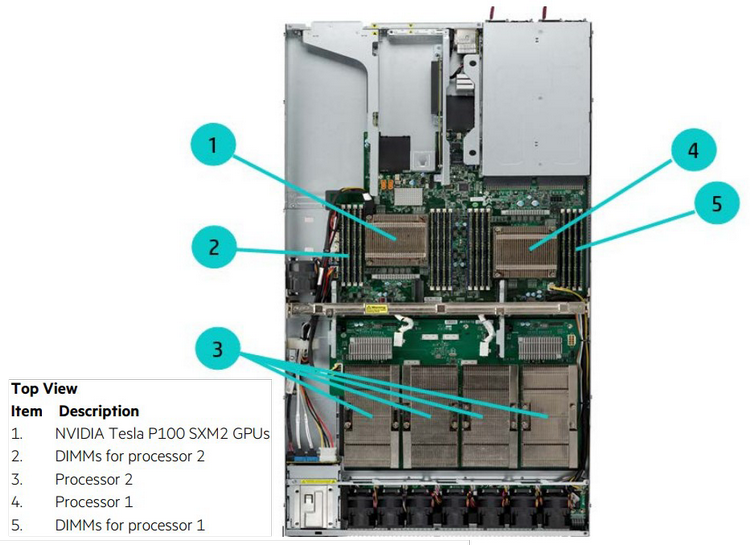
Конфигурация каждого из узлов Spaceborne Для космических систем это большое достижение, и не стоит иронизировать над этим показателем производительности. Интересно, что сама по себе система Spaceborne, доставленная на борт станции миссией SpaceX CRS-12, является своего рода экспериментом на тему «как чувствуют себя в космосе обычные компьютерные комплектующие». Это связка из двух серверов HPE Apollo 40 на базе Intel Xeon, объединённая сетью со скоростью 56 Гбит/с. 14 сентября на систему было подано питание (48 и 110 вольт), а недавно проведены первые тесты High Performance LINPACK. 
Системы охлаждения и электропитания Spaceborne Пока Spaceborne не будет использоваться для анализа научных данных или управления какими-либо системами станции. Его миссия — продемонстрировать то, насколько живучи обычные серверы в космосе. Результаты постоянных тестов будут сравниваться с аналогичной системой, оставшейся на Земле. Тем не менее, достижение первого терафлопса в космосе является своеобразным мировым рекордом. Это маленький шаг для супервычислений, но большой для всей космической индустрии, поскольку за Spaceborne явно последуют его более совершенные и мощные потомки. |
|