В этот раз выставка ISC не была особенно впечатляющей. Важные анонсы в этом году компании сделали или на Computex, или на собственных мероприятиях вроде GTC. Так что крупные игроки просто почивали на лаврах, старательно интерпретируя результаты свежего списка TOP500 в свою пользу. По числу суперкомпьютеров лидирует Lenovo (23 с хвостиком процента от всех инсталляций), по суммарной мощности впереди опять IBM (почти 20 %). Самыми эффективными вообще признаны узлы Penguin Computing (разработчик куплен SMART Global Holdings), а по энергоэффективности в частности — решения PEZY.
Из 500 машин 475 базируются на процессорах Intel: 19 позиций занято Xeon Phi, а больше всего представлено поколение Broadwell. Процессоры AMD используют всего две машины, и это до сих пор не EPYC, как можно было бы подумать, а Opteron, что несколько настораживает. Систем с Radeon не оказалось вовсе. Это, впрочем, не мешало AMD не слишком изящно и не совсем легально (догадаетесь по фото почему?) подтрунивать над Intel.

Азиаты в лице китайских ShenWei и PEZY имеют соответственно две и четыре позиции в TOP500. SPARC-машины производства Fujitsu за год потеряли одного бойца, теперь их в списке шесть. Да и POWER-систем за год тоже стало меньше — в сумме 15 инсталляций, из которых только три с POWER9, причём две из них занимают в рейтинге первое и третье место, попав в него впервые. Но это вовсе не показатель того, насколько хороши новые CPU IBM. Секрет прост — основная вычислительная мощь приходится на ускорители NVIDIA. Из 132 новичков в свежем списке 26 снабжены именно ими, причём более половины дополнительных флопсов приходится на Tesla. Заодно обратите внимание на уровень энергопотребления, особенно в сравнении с китайскими машинами. В лидере рейтинга, Summit, по данным NVIDIA, 95% пиковой производительности приходится именно на GPU, которых в нём аж 27648 штук. На графике хорошо видно, насколько далеко отрываются от всех первые четыре машины в списке. И даже пятая — ABCI — снабжена Tesla.
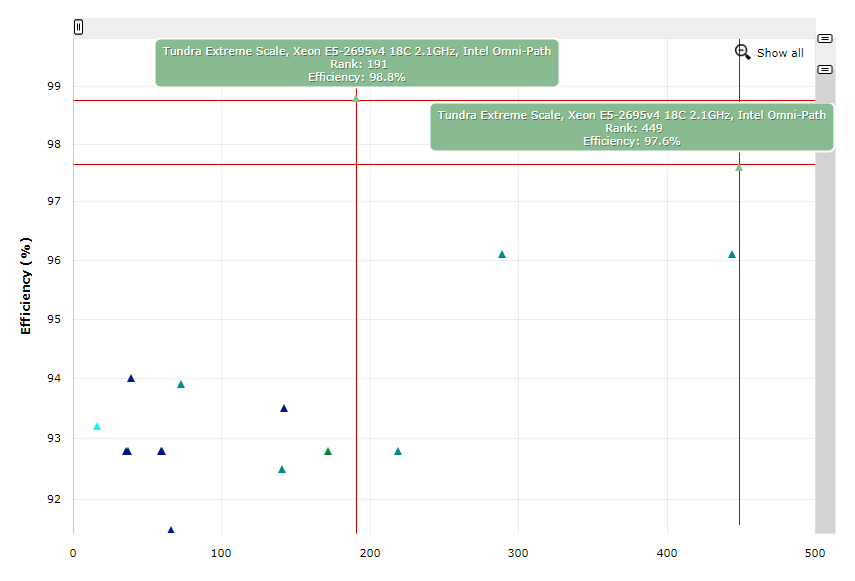
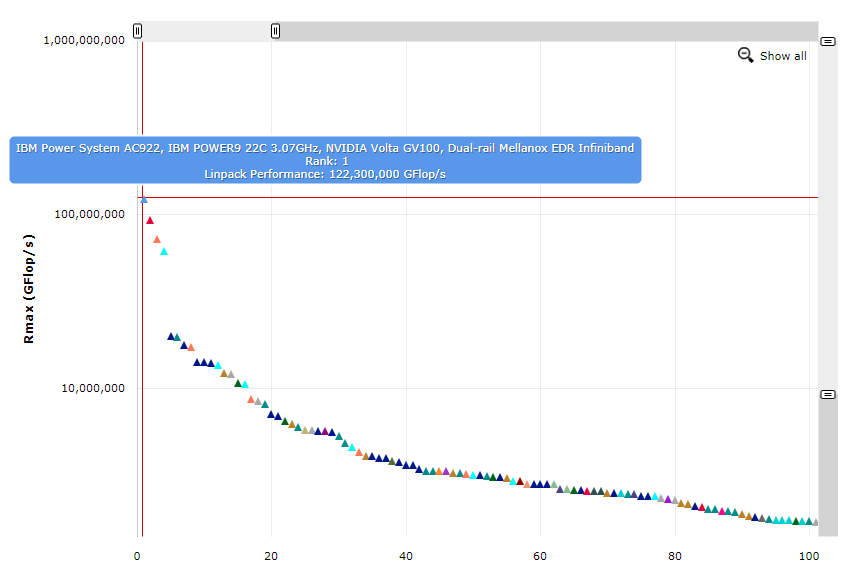
Все три новинки с Tesla отличает наличие ядер Tensor Core, и в результате суммарно они имеют большую производительность в области машинного обучения, чем все оставшиеся сотни машин, вместе взятые. Получается, не даром NVIDIA гордится, что её продукты подходят для всех трёх «горячих» областей — обычных расчётов, ИИ и визуализации, попутно напоминая об их энергоэффективности: значительная часть инсталляций в Green500 использует Tesla. Ну и в целом очевиден сдвиг в сторону слияния традиционного HPC с AI, о чём отдельно поговорим ниже. Ещё интереснее то, что более половины ускорителей Tesla для этих задач продаётся компаниям, которые сознательно не участвуют в TOP500. Интересно, как обстоят с этим дела у AMD?

NVIDIA DGX-2

Однако одной новинки в нынешнем рейтинге TOP500 так и не оказалось. Речь идёт о суперкомпьютере с ARM-процессорами. Формально такие узлы показывали на прошлых выставках и крупные игроки вроде Atos и Cray, и компании поменьше. В итоге до массового производства дожили только Cavium ThunderX 2 с непростой судьбой: первое поколение так и не вышло, а в итоге были взяты ядра Vulcan, доставшиеся от Broadcom после поглощения и потрошения. Сама же Cavium в прошлом году была поглощена Marvell. Все остальные ARM-процессоры для серверов действительно массово не производились. Applied Micro X-Gene 3 оказались в руках Ampere, судьба Phytium и HiSilicon не известна уже года три как, Qualcomm пока притормозила разработку Centriq и ничего не говорит про Firetrail, а Samsung, похоже, решила вернуться в игру, но подробности не сообщает. Про проекты (или прожекты) не для HPC или на ядрах младше ARMv8 вспоминать не будем.


Так вот, лёд-то на самом деле тронулся. HPE за неделю до начала ISC 2018 официально объявила о создании суперкомпьютера Astra на базе ThunderX 2 (надо полагать, семейства ThunderX_CP). ARM-первенец будет состоять из 2592 двухсокетных узлов Apollo 70 с 28-ядерными 2-ГГц CPU: 145152 ядра в сумме и до 2,3 Пфлопс в сумме. Проект спонсируется DoE, которому через пару лет надо подобраться к экзафлопсу, поэтому основная цель Astra — выяснить, насколько ARM подходит для HPC. Ну и в целом DoE явно не помешает третья архитектура в копилке. Важный нюанс — вычисления будут производиться именно на CPU, так как для GPGPU в общем случае не так важно, кто «кормит» ускорители данными. ThunderX 2 поддерживают SMT4, имеют 16 Мбайт L2-кеша, 56 линий PCI-E 3.0 и 8 каналов памяти DDR4-2666 (в исполнении HPE до 256 Гбайт на CPU). Однако не до конца ясно, как у них дела с TDP и что там с расширениями — по первому пункту никто ничего не пишет, а по второму пока заявлены 128-бит SIMD NEON, но не SVE.
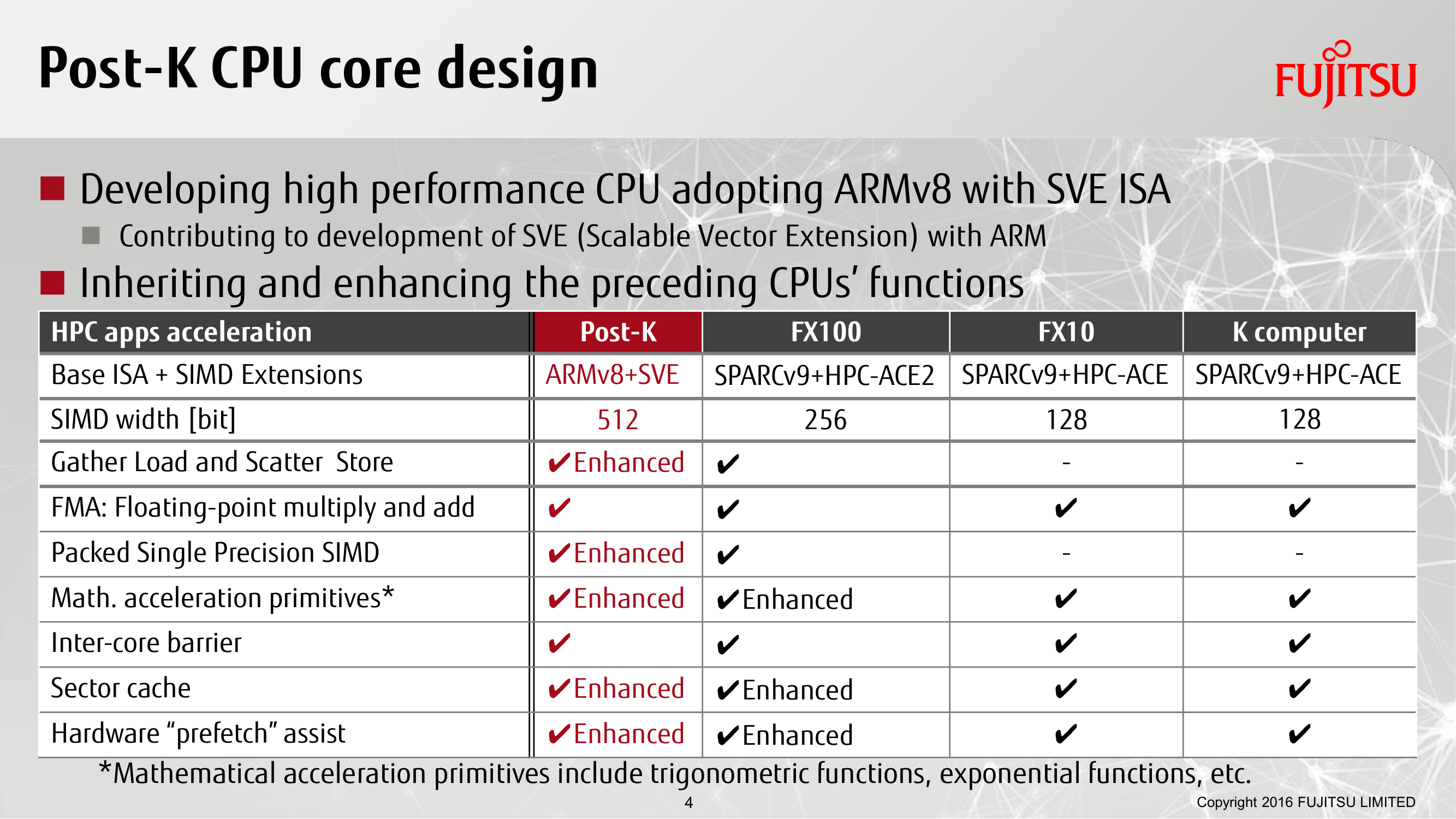

А вот ARM-процессоры для Fujitsu Post-K будут поддерживать 512-битные векторные инструкции SVE, что в теории позволит им приблизиться к современным Intel Xeon с AVX-512. Ранее SIMD-инструкции были вынесены в отдельный сопроцессор и не были обязательными. На ISC 2018 компания наконец немного поделилась информацией о будущих CPU. Да, в основе всё так же ARMv8, но в слегка необычной конфигурации: 48 вычислительных ядер FP16/32/64 и с поддержкой SVE-512 + 2/4 вспомогательных ядра для работы самой ОС. Вряд ли это окончательный вариант чипа, но уже ясно, что Fujitsu хочет покрыть все области, включая традиционный HPC и ИИ. Новая машина будет полагаться на стековую память и следующее поколение интерконнекта Tofu (125 Гбит/с в каждую сторону). Похоже, Fujitsu, как и HPE, делает ставку на смену парадигмы и переход к решениям in-memory, то есть в буквальном смысле к вычислениям непосредственно внутри модулей памяти, чем занимаются сейчас IBM и, по слухам, Micron.


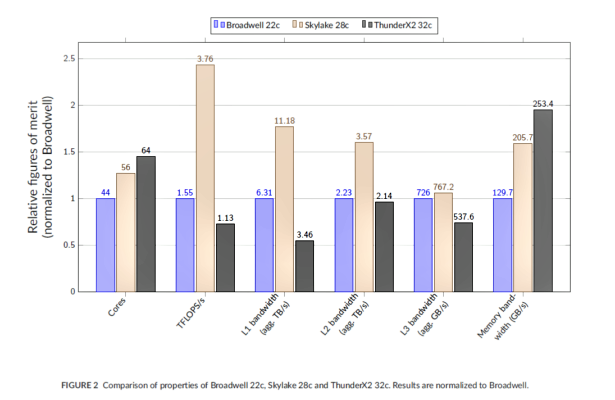
Собственно говоря, первые тесты узлов будущего суперкомпьютера Isambarad — младшего брата Astra на 10000 ядер ThunderX 2 от Cray — показывают, что FP-вычисления нельзя назвать сильной стороной этих ARM-процессоров: до Broadwell они не дотягивают, а от Skylake отстают уже существенно. Это, понятное дело, заслуга AVX, и тем более интересно будет увидеть в работе SVE, которые вообще могут быть длиной до 2048 бит. Производительность кешей тоже отстаёт, зато по скорости работы с RAM новые CPU в два раза лучше Broadwell и заметно обгоняют Skylake. Хотелось бы, конечно, узнать конкретную конфигурацию памяти, но и так ясно, что не всякие нагрузки для ThunderX 2 одинаково полезны. С другой стороны, системы на этих процессорах, по отзывам, в итоге оказываются дешевле в 2-3 раза при одинаковом числе чипов (речь именно о штуках, а не о производительности). Isambarad строится всё с той же целью — оценка применимости ARM в HPC и сравнение с традиционными архитектурами.
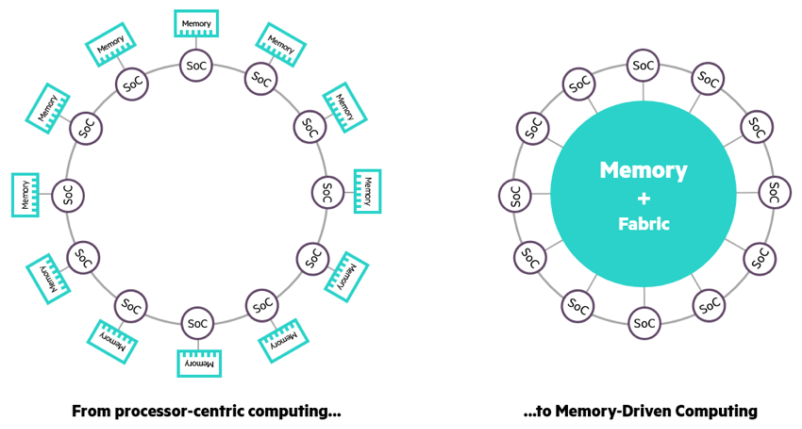
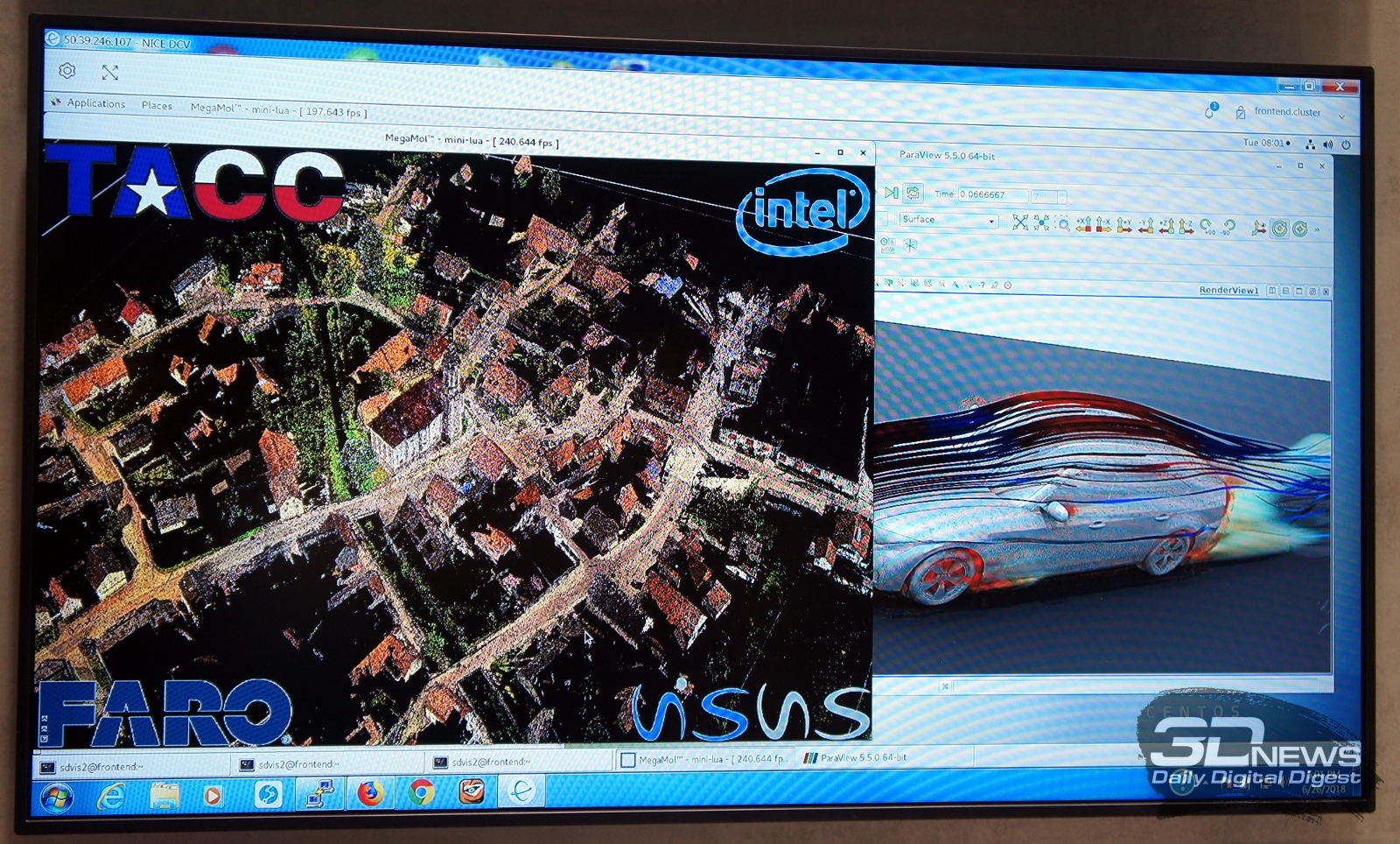
Пока что полный отказ от архитектуры фон Неймана, которая требует постоянной пересылки данных и инструкций между вычислителем и памятью, далёк. Все продолжают наращивать объём и скорость доступной памяти, а также производительность шин, потому что проблем с собственно вычислениями особо-то и нет. Обычным задачам от этого только лучше, а некоторые без таких нововведений просто невозможны — как, например, та же визуализация данных, которая в общем случае требует, чтобы все эти данные были в RAM. На ISC 2018 NVIDIA и Intel как раз показывали свои решения, оптимизированные под собственные архитектуры. Intel демонстрировала визуализацию в реальном времени модели объёмом полтерабайта, полученной путём съёмки с воздуха хорошим лидаром немецкой деревушки. Впрочем, это просто красивый пример, тогда как на практике эта система полезна для быстрой оценки промежуточных результатов долгих, очень долгих расчётов, длящихся днями и неделями.

Но это так, лирическое отступление. А вообще мы уже неоднократно писали о проблемах PCI Express, об альтернативах в виде OpenCAPI или NVLink, а теперь и NVSwitch. Похоже, что почти все пропустят PCI-E 4.0 и будут ждать 5.0. На ISC 2018 наконец были показаны рабочие прототипы новой когерентной шины CCIX, которая за два года доросла до первой стабильной версии. Цель простая и понятная — упростить и улучшить взаимодействие между собой CPU, GPU, FPGA, ускорителей и прочих устройств внутри узлов. Любопытно, что консорциум Gen-Z, который ставит перед собой ещё более амбициозные задачи по объединению всего и вся, на ISC 2018 не приехал, хотя базовый вариант стандарта был представлен в этом году. Intel с NVIDIA не участвуют в подобных инициативах, но если у второй уже есть своё решение, то вот первой в связи с многочисленными покупками последних лет (Altera, Nervana, Mobileye, Movidius), пожалуй, не помешает единый интерфейс для этих разнородных вычислительных модулей.


Что касается второй части — собственно памяти, то мы уже писали про анонс модулей Intel Optane DC P4801X в формате M.2 (для них скоро будет конкурент в лице Z-SSD Samsung), более ёмких 64-слойных Intel SSD DC P4511, а также о грядущем расширении серии рулеров форм-фактора EDSFF. Первой из HPC-игроков новые Optane на выставке продемонстрировала отечественная компания РСК, показавшая обновлённые узлы «Торнадо» для построения гиперконвергентных систем. Сейчас они вмещают до 12 M.2-накопителей (с водяным охлаждением, конечно), но конструкция шасси рассчитана на установку рулеров в будущем. А вот про что не упоминали, так это про участие свежего суперкомпьютера производства РСК, установленного в ОИЯИ, в новом, пока что очень и очень скромном списке IO500, где он занимает 12-е место из 16. Это рейтинг для нового одноименного бенчмарка, который, как ясно из названия, оценивает в первую очередь производительность систем ввода-вывода и распределённых ФС, от которых во многом зависит утилизация имеющихся флопсов. Бенчмарк учитывает операции не только чтения/записи файлов, но и создания/удаления, поиска/фильтрации, а также работу с метаданными.
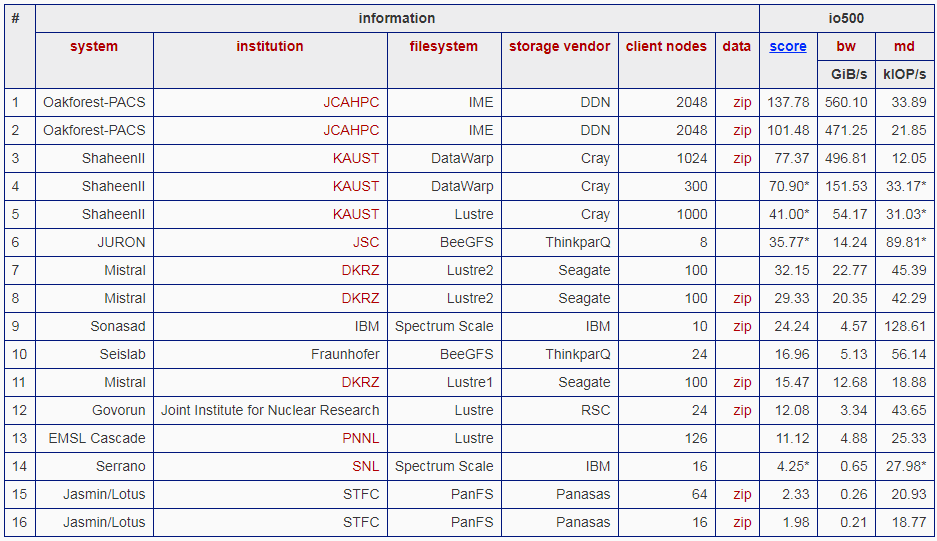

Треть участников IO500 использует ФС Lustre, которую DDN только что выкупила у Intel. Сама Intel, видимо, так и не смогла толком развить это направление, хотя с софтом у неё, как правило, проблем нет. Кстати, именно софт должен стать основным полем HPC-битвы для ARM. Ну и в целом это особая боль любой новой аппаратной платформы, а тех же SVE-инструкций как раз и не было ранее — для них надо все адаптировать. Тут интересно вот что — заставит ли ARM своих партнёров унифицировать набор инструкций и будет ли заниматься портированием утилит и библиотек? Первый шаг ARM уже сделала, объявив год назад о выходе бета-версии компилятора Fortran. Однако этого явно мало, так как для той же Fujitsu, ранее использовавшей CPU SPARC, вопрос переноса и, самое главное, оптимизации всего имеющегося софта будет стоять очень остро. Это же, к слову, относится и к NEC, которая наконец представила свои новые векторные ускорители Aurora и платформу TSUBASA.


Хороший пример важности работы над ПО показала Intel, продемонстрировав оптимизированную для Xeon модификацию фреймворка для нейронных сетей TensorFlow, которая оказалась в десять раз быстрее оригинальной версии Google. NVIDIA в очередной раз показывала готовые контейнеры с предустановленными и правильно настроенными наборами ПО для HPC-задач, которые позволяют очень быстро начать обработку данных, не занимаясь лишними телодвижениями. А AMD посвятила себя продвижению платформы ROCm, хотя никаких существенных докладов не сделала. А вот ключевой доклад Intel на этот раз оказался удивительно пространным, загадочным и даже философским. Начать можно с того, что Intel — это теперь data company (вот и как это переводить?). А закончить — очередным громким заявлением о том, что программисты больше не нужны.


В общем, Intel снова объявила данные главной ценностью человечества и сказала, что их можно использовать в HPC ещё лучше. Как? Надо перейти к новой концепции их обработки. Сейчас для решения задач путь простой: делаем математическую модель какого-либо процесса, запускаем её расчёт на суперкомпьютере, на основе расчётов делаем выводы и предсказания о том, как это всё будет в реальной жизни. Если не получилось, повторяем заново и заново. Что нужно сделать? Пойти от обратного, конечно, — огромные массивы данных буквально отовсюду у нас и так уже есть. Так не лучше ли каким-то образом (вот каким?) научить машину находить в них зависимости, строить и корректировать модели на лету, а затем использовать для корректировки происходящих процессов. В будущем — несомненно, светлом и прекрасном — можно будет отказаться и от программистов с алгоритмистами, так как машина будет сама всё делать. Ну или почти всё. Идея вообще-то не нова — это развитие уже знакомых нам «столпов» BigData, HPDA, AI. Без конкретики звучит это всё пока что немного фантастично, хотя, впрочем, вполне реализуемо. И да, всё это потребует много-много памяти, то есть — смотри выше абзац про ARM и HPE.

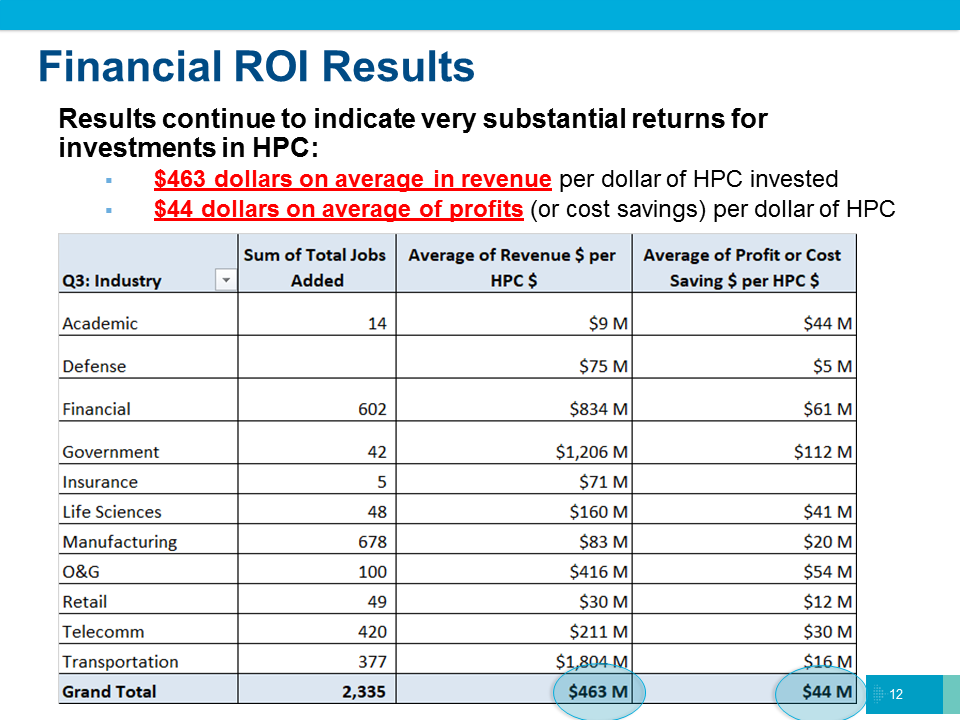
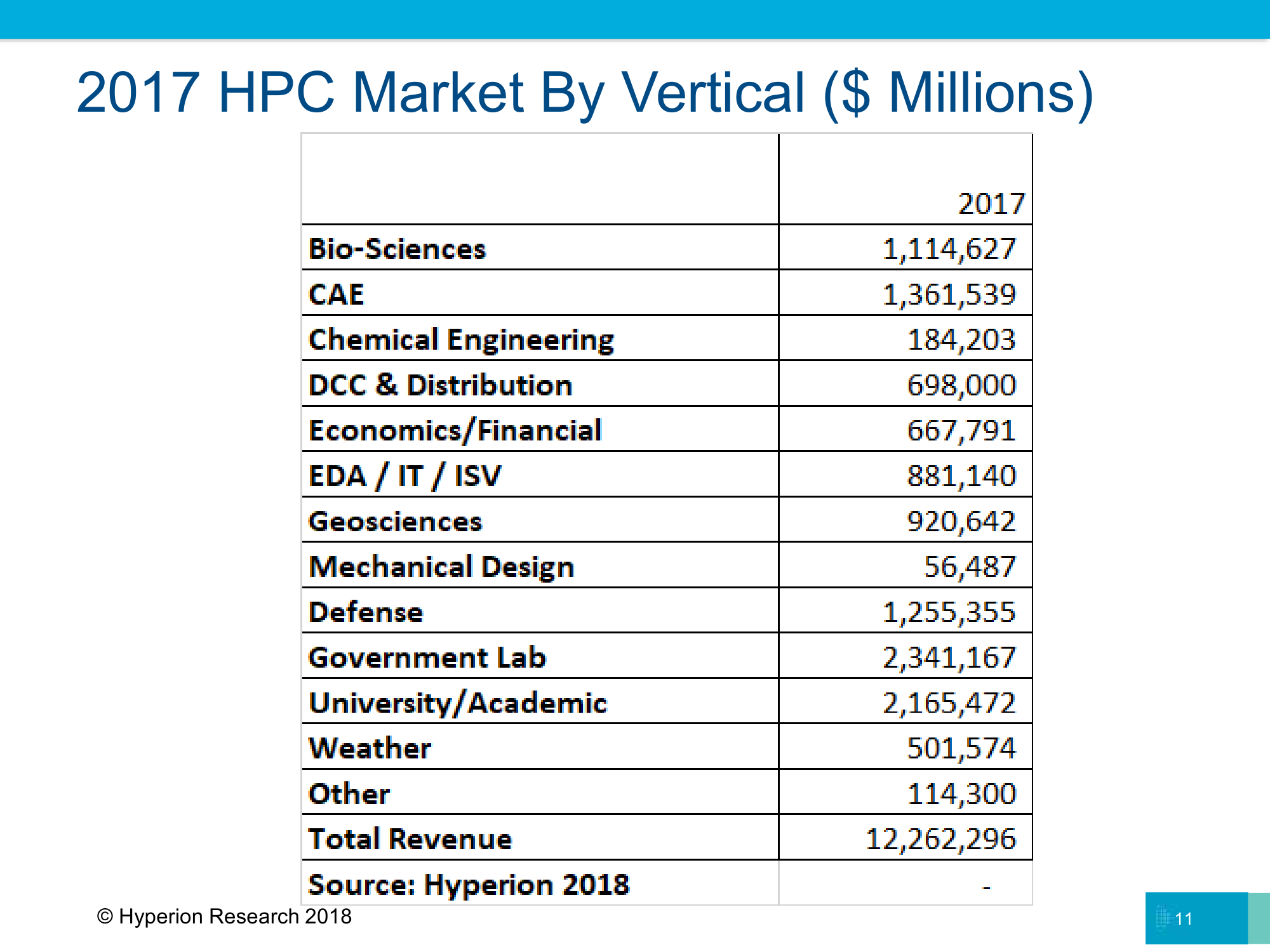
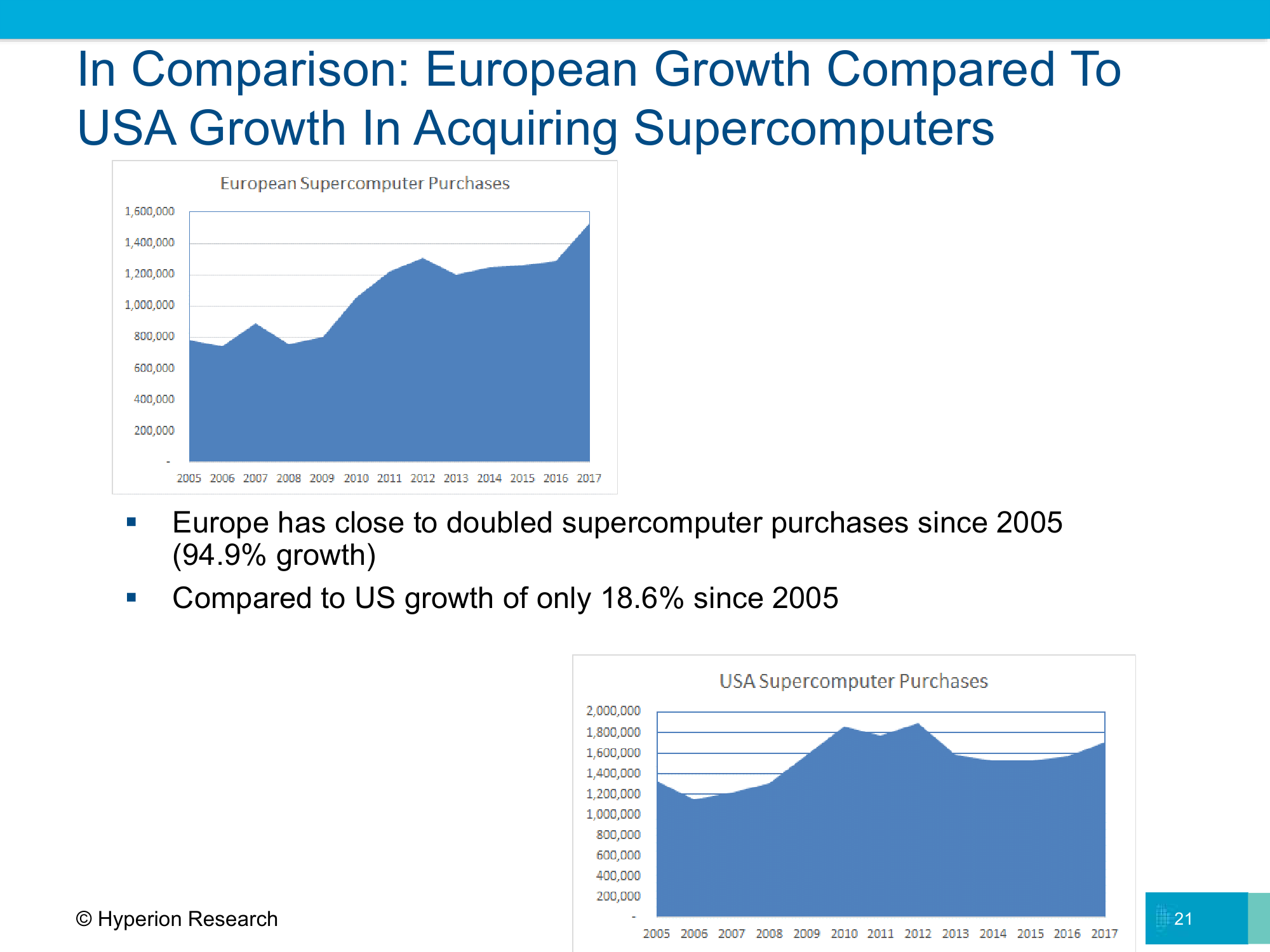
Возможно, всё это — суть желание найти новые пути развития, так как в последние годы рост «голой» производительности слегка замедлился и сейчас подстёгивается значительными вливаниями со стороны государств, которые очень хотят побыстрее достичь важной отметки в один экзафлопс. Тут лидируют США, Евросоюз, Китай и Япония (обратите внимание на предсказываемые архитектуры CPU). HPC остаётся областью с достаточно высоким уровнем возврата инвестиций — по данным Hyperion Research, каждый вложенный в высокопроизводительные вычисления доллар генерирует $436 выручки и $44 прибыли или экономии. Высокий уровень первоначальных затрат, впрочем, всё равно делает эту область во многом государственной, за редкими исключениями.


А вообще, в отчёте Hyperion Research можно выделить три интересных момента. Во-первых, аналитики считают ИИ, машинное/глубинное обучение и прочие связанные технологии всё ещё незрелым и перспективным направлением развития в HPC, которому только предстоит столкнуться с множеством проблем. Это подтверждается и другими исследователями. Одна из особенностей, на которую, видимо, и намекала Intel в своём докладе, — это высокий уровень специализации ИИ-решений: на каждую гайку приходится почти вручную искать свой болт.
Во-вторых, растёт интерес к HPC в облачных окружениях — к созданию частных и гибридных облаков. Эта тенденция видна и на рынке обычных ЦОД, хотя для HPC особенность в том, что почти 2/3 пользователей работают с облаками, но выносят туда менее десятой доли своих задач. Основные страхи неизменны: боязнь за сохранность данных и за надёжность доступа к ним. А облака тем временем, как машины в TOP500, становятся более гетерогенными, добавляя к CPU различные ускорители: FPGA, GPU, специализированные акселераторы для нейронных сетей и так далее. Наконец, в-третьих: далее в отчётах будут учитываться квантовые компьютеры, то есть это косвенное признание их важности и готовности развития. Благо в последние годы появились проекты по созданию таковых на базе привычного «кремния», что потенциально сильно упрощает и удешевляет их массовое производство.








Заключение
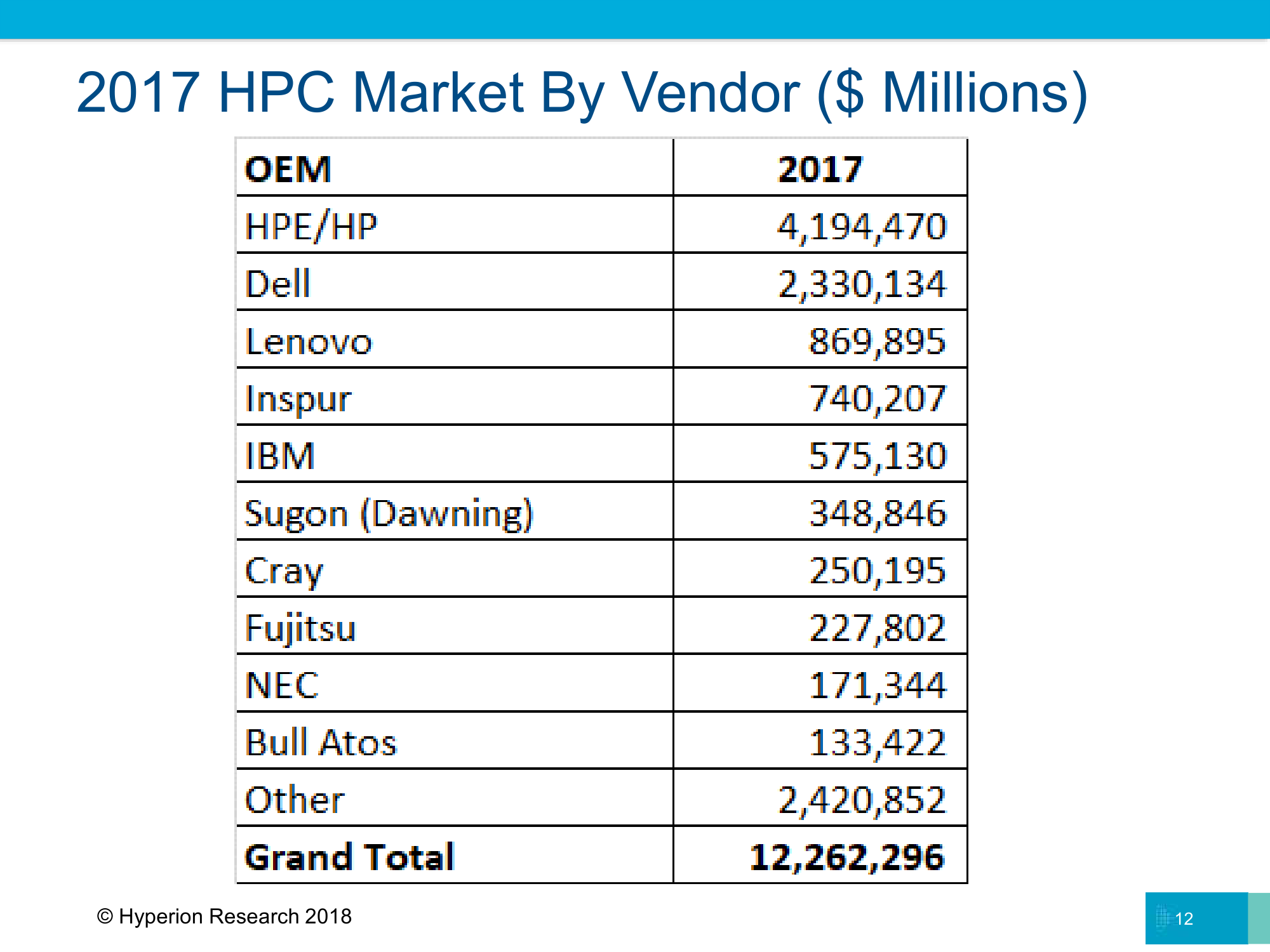
Если уж совсем коротко говорить о самом главном, то можно выделить несколько важных веяний. Первое: США наконец вернули себе лидерство в публичном рейтинге. Произошло это за счёт NVIDIA, которая активно наращивает присутствие в TOP500, где всё больше вычислительных мощностей приходится именно на Tesla. Все прочие ускорители, за исключением решений из ЮВА, у которых всегда свой особый путь, в публичном поле не особо заметны. По CPU лидерство всё так же за Intel, а AMD, можно считать, из рейтинга совсем пропала. IBM со своими POWER9 тоже пока не блещет числом инсталляций.
В следующем рейтинге наверняка будет новый игрок. И это второе — ARM наконец должна выйти на HPC-рынок. Интереснее всего будет посмотреть на работу грядущих CPU с SVE-512 производства Fujitsu, но на текущий момент у ARM в активе только ThunderX 2, первые тесты которых показывают слабость в вычислениях по сравнению с Xeon, но хорошую производительность при работе с памятью, на что и делается ставка.
Это приводит нас к третьему пункту — потенциальному росту технологий in-memory, а в перспективе и к частичному отказу от классической архитектуры фон Неймана. Пока что идёт наращивание объёмов всех видов памяти и повышается интерес к (гипер)конвергенции. Под это дело очень удачно вышло новое мерило производительности и инструмент пиара — рейтинг IO500. В реальности же складывается ощущение, что сейчас есть смысл не гнаться за «железом», а развивать программное окружение. Из прочих тенденций отметим взаимопроникновение HPC и облаков, усиление разработок альтернативных аппаратных платформ для вычислений и ускорителей, а также возрождение интереса к квантовым вычислениям. В целом пока вроде бы никаких революций на горизонте не видно, но мы же все знаем, что они имеют свойство случаться внезапно.
