Упаковка
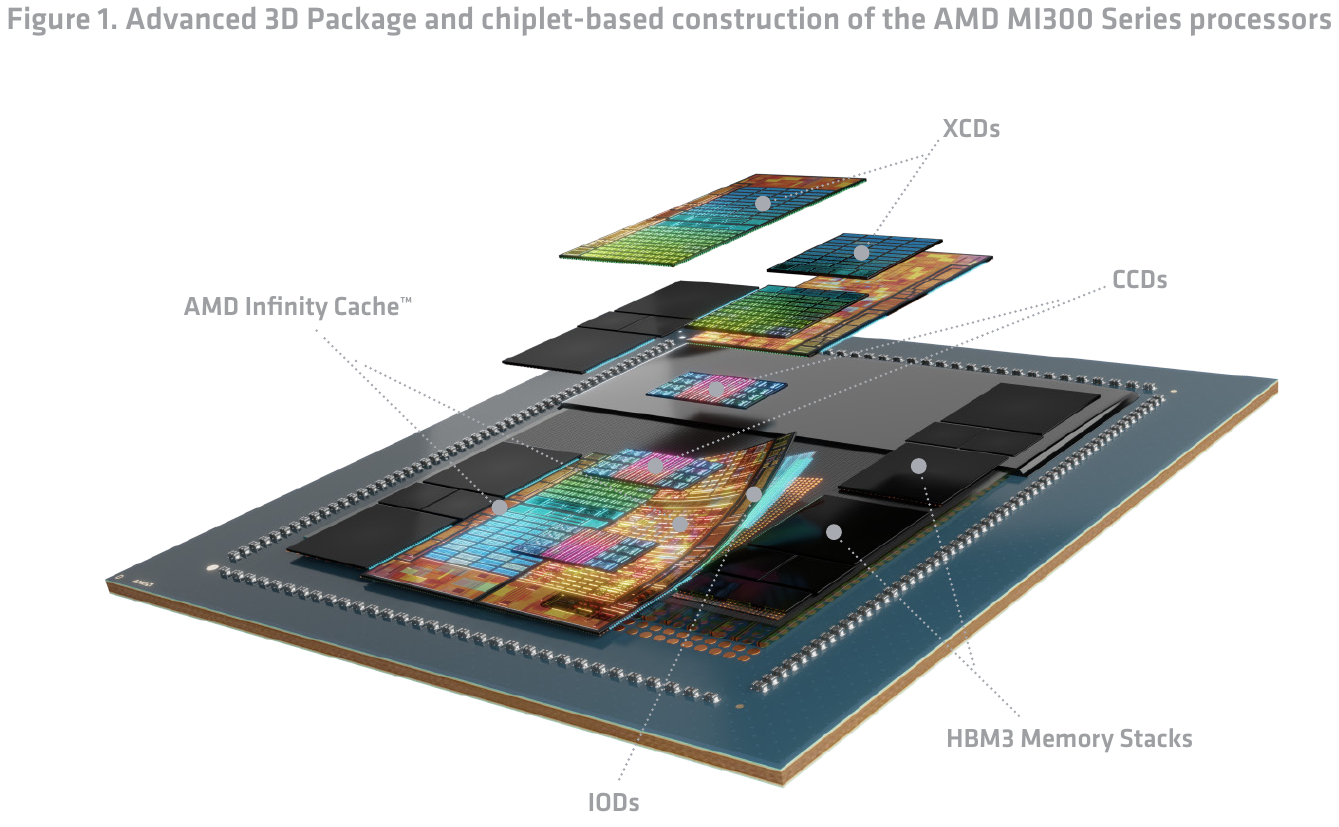
С инженерно-технической точки зрения MI300 развивает идеи, заложенные ещё в серии MI200. Но упаковка и конструкция продуктов в поколении CDNA3 стала значительно более сложной и продвинутой. С появлением MI300, наконец, можно говорить о по-настоящему гетерогенной архитектуре, активно использующей как горизонтальную, так и вертикальную интеграцию модулей. Достигнуто это благодаря применению технологий упаковки, использующих продвинутую подложку-интерпозер CoWoS.
Чип может содержать до восьми модулей ускорителей (XCD) и четыре модуля ввода-вывода (IOD), включающих системную инфраструктуру и объединяющих чиплеты в единое целое посредством интерконнекта Infinity Fabric. Модули IOD отвечают и за взаимодействие с восемью сборками высокопроизводительной памяти HBM3. Все 12 модулей работают как единое целое с программной точки зрения и насчитывают совокупно до 153 млрд транзисторов. Итоговая сборка сравнима по сложности с Ponte Vecchio.
Источник: AMD
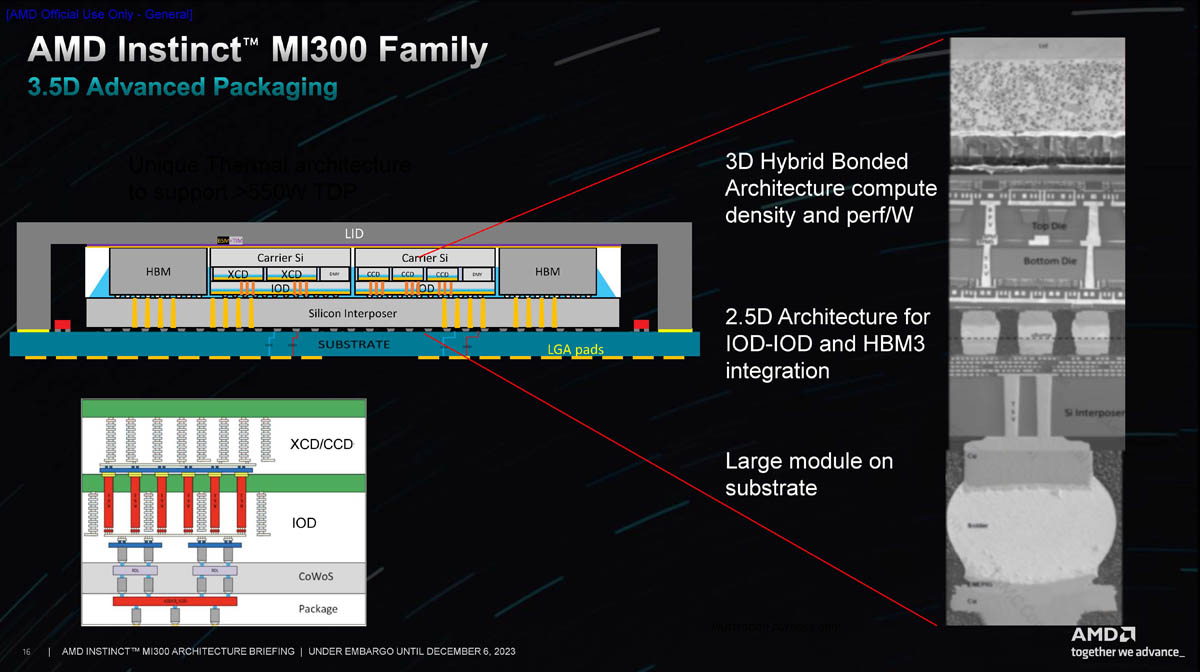
Непосредственно на интерпозере размещаются модули IOD и сборки HBM3, а уже поверх IOD устанавливаются вычислительные чиплеты. Они соединяются с нижележащими чиплетами посредством технологии, отработанной AMD в решениях с 3D V-Cache. Площадки Bond Pad Via (BPV) в нижней части XCD точно совмещаются с посадочными местами на вершине IOD, куда выведены пронизывающие кристалл по вертикали TSV-соединения. Любопытно, что верхние чиплеты могут устанавливаться в двух положениях: обычном и развёрнутыми на 180°.
Источник: AMD via ServeTheHome
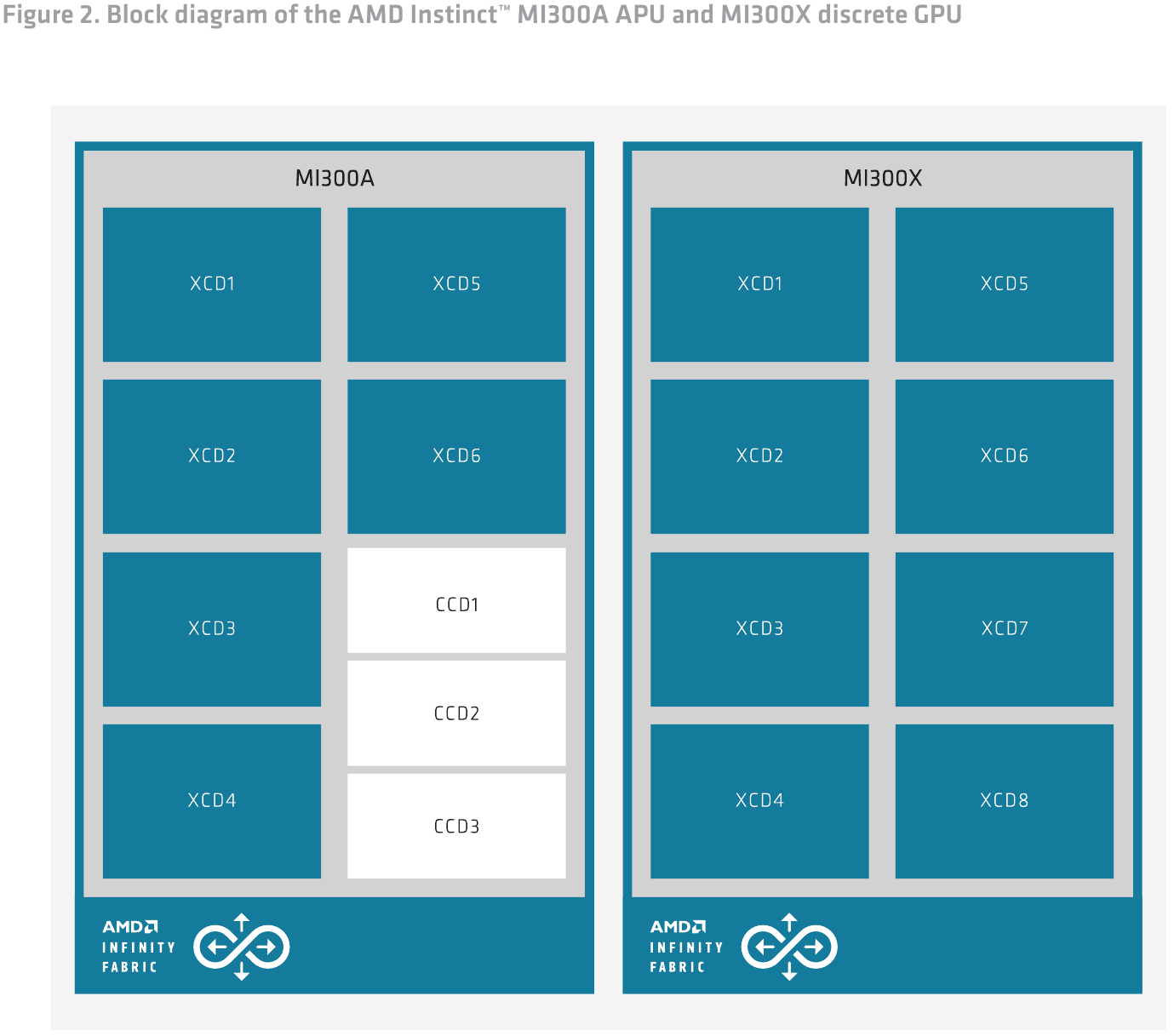
MI300 существует в двух ипостасях: «чистый» ускоритель MI300X, который включает восемь XCD, и гибрид MI300A, где есть шесть модулей XCD, дополненных тремя модулями CCD, которые в сумме дают 24 x86-ядра Zen 4. Чиплетов во втором случае уже 13, но транзисторов несколько меньше (146 млрд), поскольку ядра Zen проще XCD.
Вместимость кеша Infinity Cache в обоих случаях составляет 256 Мбайт. Не меняется и конфигурация сборок HBM3, лишь их объём, составляющий либо 16, либо 24 Гбайт на блок. Теплопакет у новинок AMD примерно одинаков: 750 Вт у MI300X в конструктиве OAM и 760 Вт у гибридного MI300A, больше похожего на обычный EPYC Genoa.
Источник: AMD
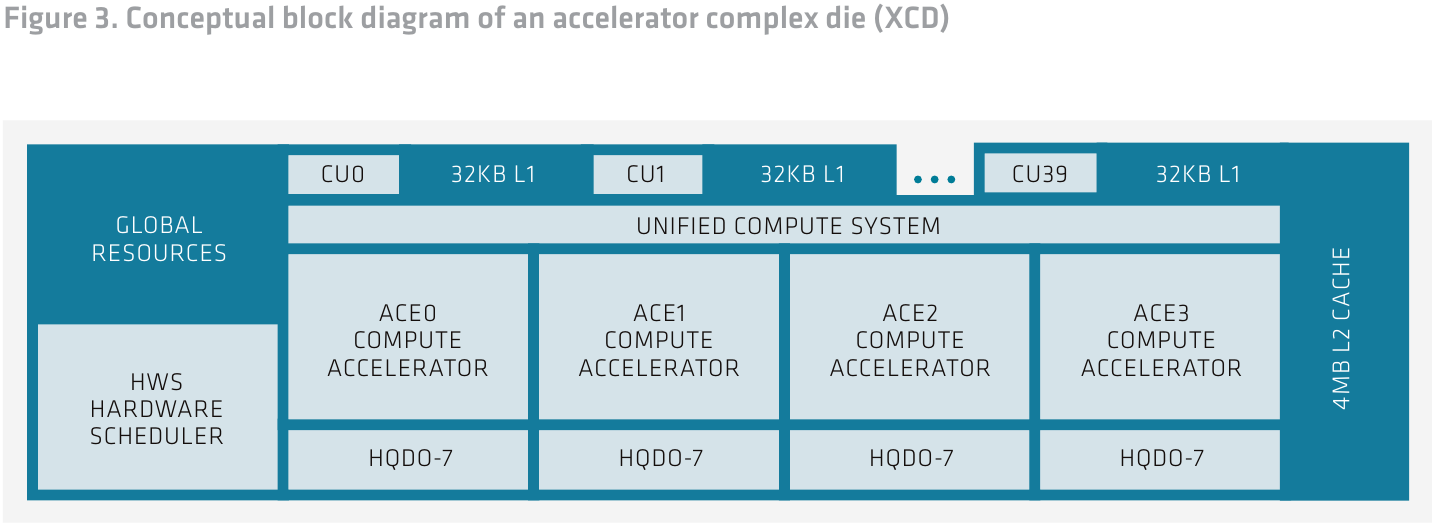
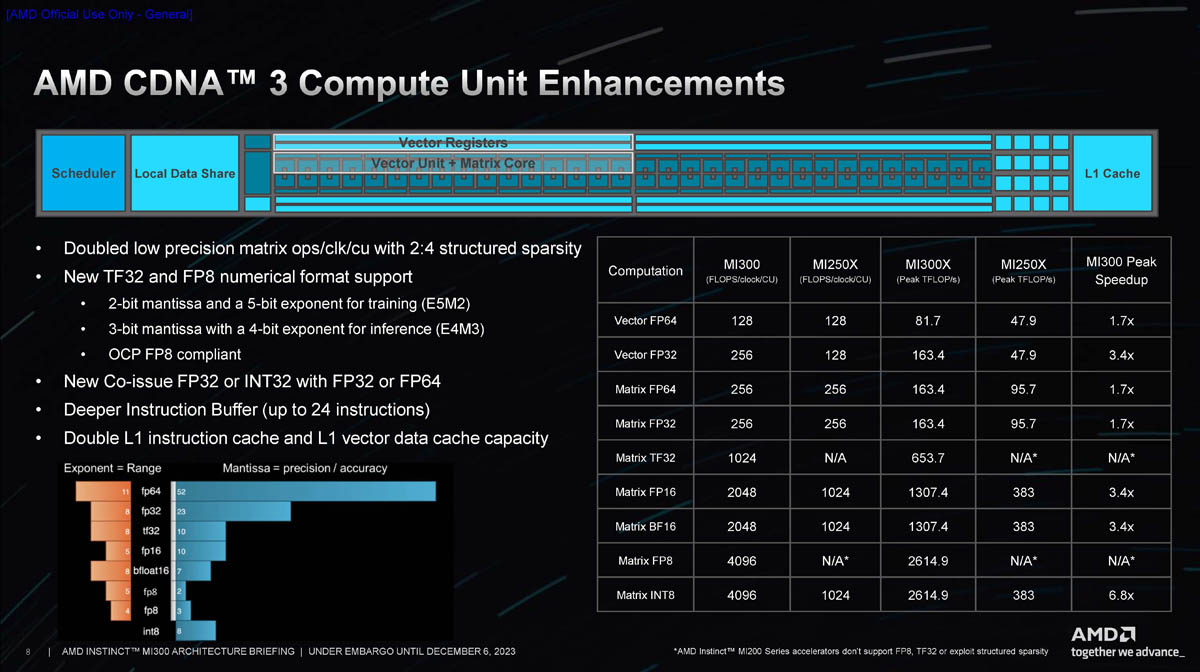
Модули XCD в архитектуре CDNA 3 меньше аналогичных «строительных блоков» CDNA 2. Они содержат меньше исполнительных блоков (CU), но это позволяет компоновать решения MI300 более гибко, так что в итоге общее количество CU может достигать 304, что на 40 % больше аналогичного показателя MI250X. Часть ресурсов в XCD общая для всех CU: планировщик, аппаратный организатор очередей, 4 Мбайт кеша L2. Также здесь имеется четыре движка Asynchronous Compute Engines (ACE), обслуживающих 40 CU. По умолчанию активно только 38 CU. Два отключены для увеличения выхода годных кристаллов, но вполне вероятно, что для особо требовательных заказчиков будут отобраны 40-блочные кристаллы.
Источник: AMD
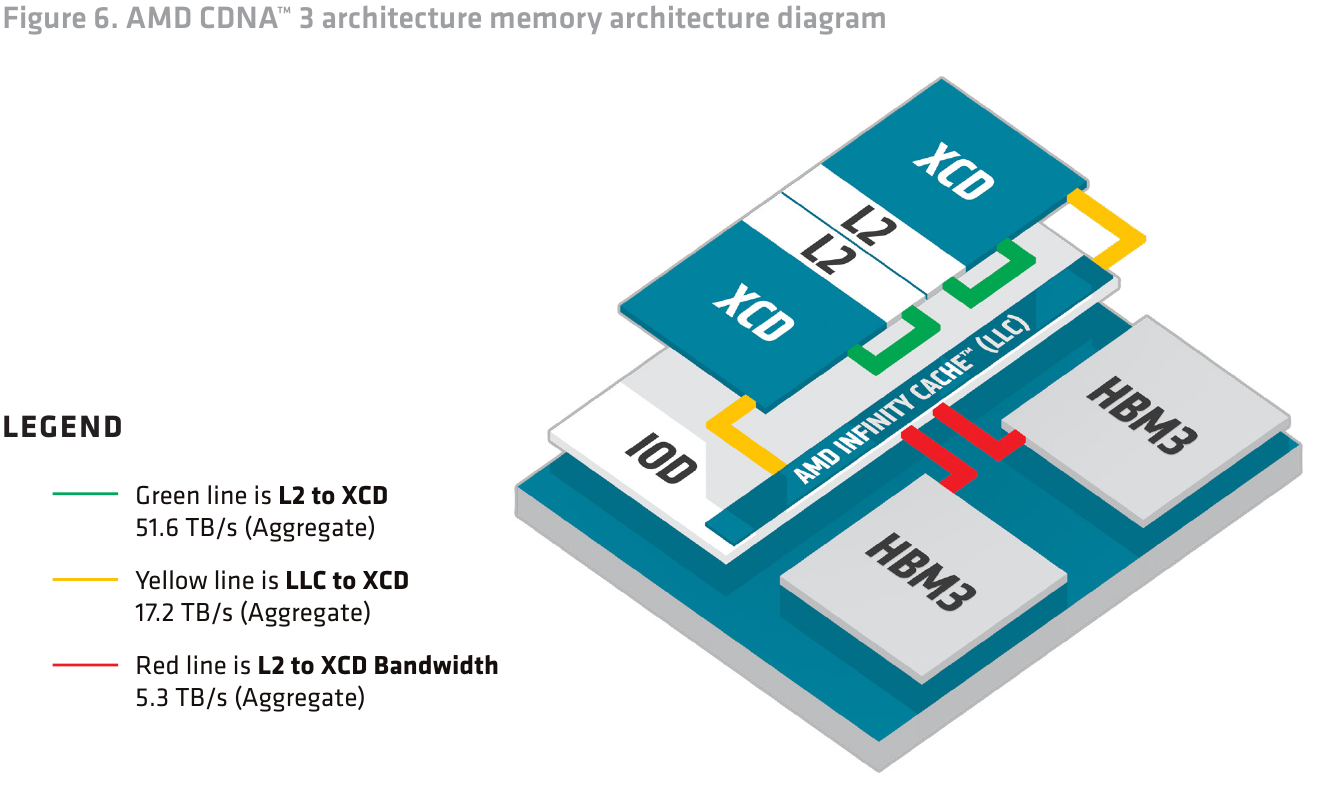
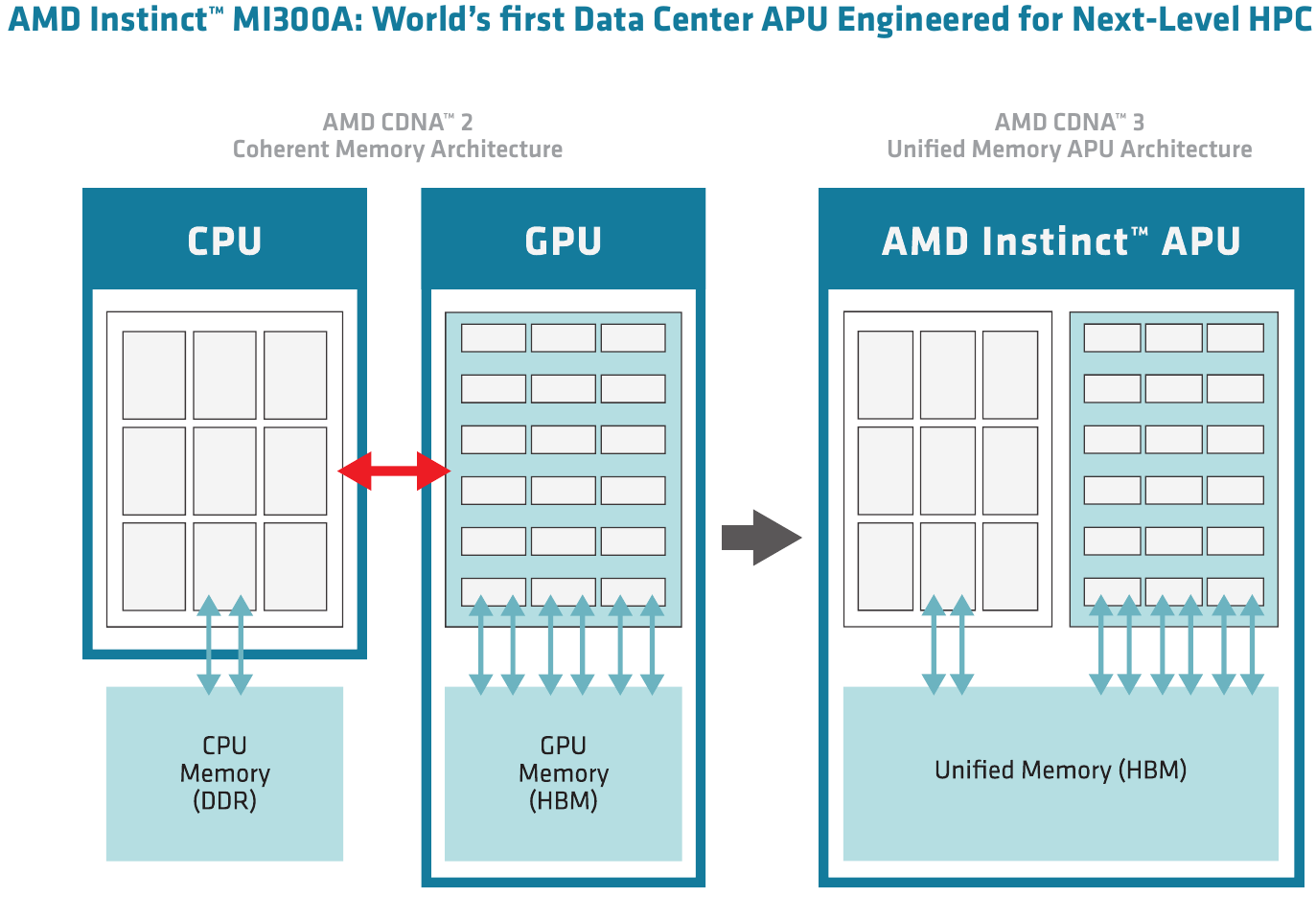
В CDNA3 AMD полностью переработало архитектуру памяти, начиная с кешей L2 и заканчивая переходом на HBM3. Это позволило избежать потенциально узких мест: так, пропускная способность L2 в XCD достигает 51,6 Тбайт/с, Infinity Cache может передавать данные на скорости 17,2 Тбайт/с, и он же общается со сборками HBM3 на скорости до 5,3 Тбайт/с. В случае с MI300A унифицированная архитектура памяти позволяет избежать «длинных путей» при обмене данными между CPU и GPU — HBM-пул у APU единый, к нему равноправно может обращаться любой из компонентов ускорителя, будь то XCD или CCD. Это существенно отличается от более гетерогенного подхода NVIDIA в GH200.
Спецификации
Спецификации MI300A и MI300X достаточно близки: как уже было сказано, обе новинки основаны на архитектуре CDNA3 и, по сути, отличаются только заменой двух вычислительных модулей XCD у MI300A на три модуля с процессорными ядрами x86 общего назначения да менее ёмкими сборками HBM3.
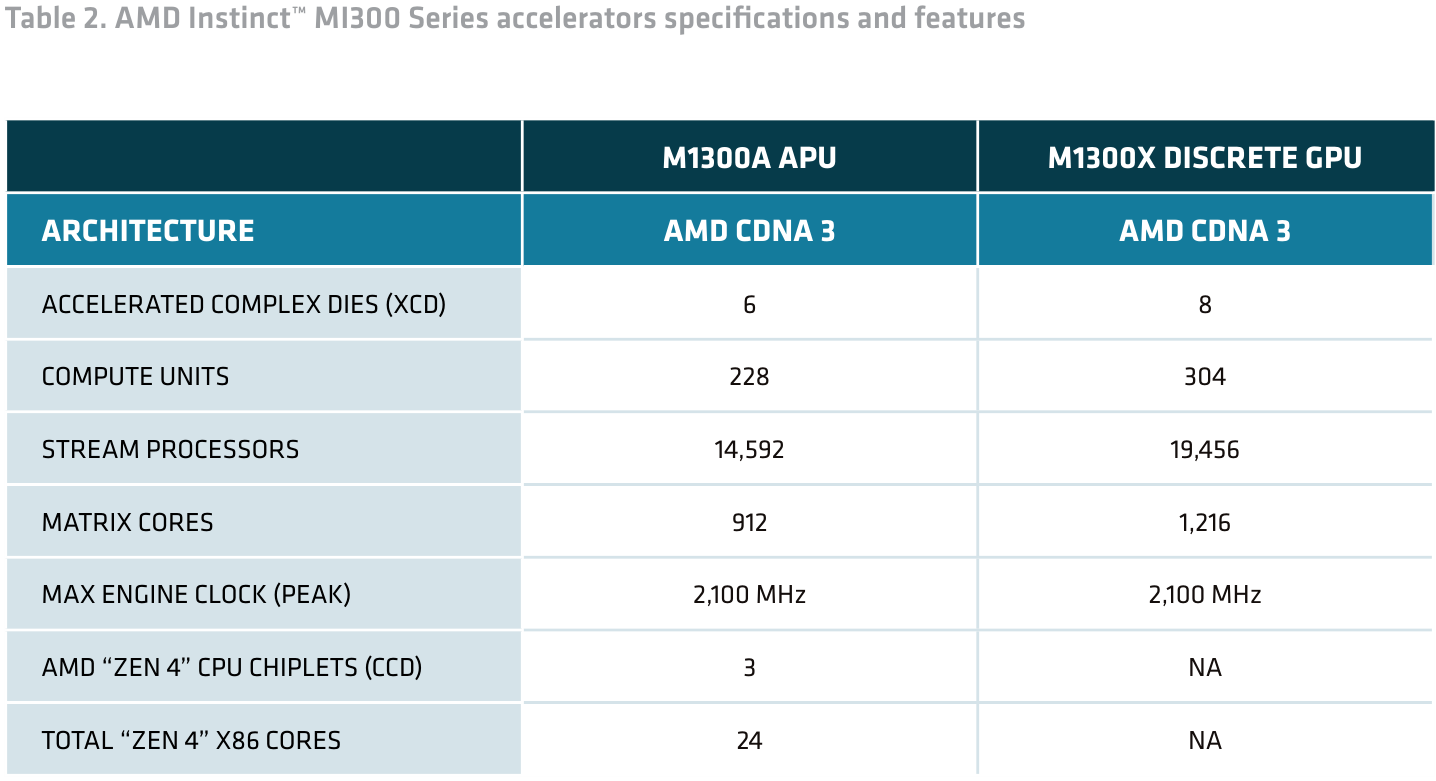
Источник здесь и далее: AMD
Оба чипа производятся на мощностях TSMC с использованием 5-нм техпроцесса (6-нм для модулей IOD), оба имеют по восемь сборок HBM3 с одинаковой пропускной способностью в районе 5,3 Тбайт/с, но сами сборки неодинаковы — у стандартного ускорителя объём набортной памяти составляет 192 Гбайт, в то время как у APU лишь 128 Гбайт.
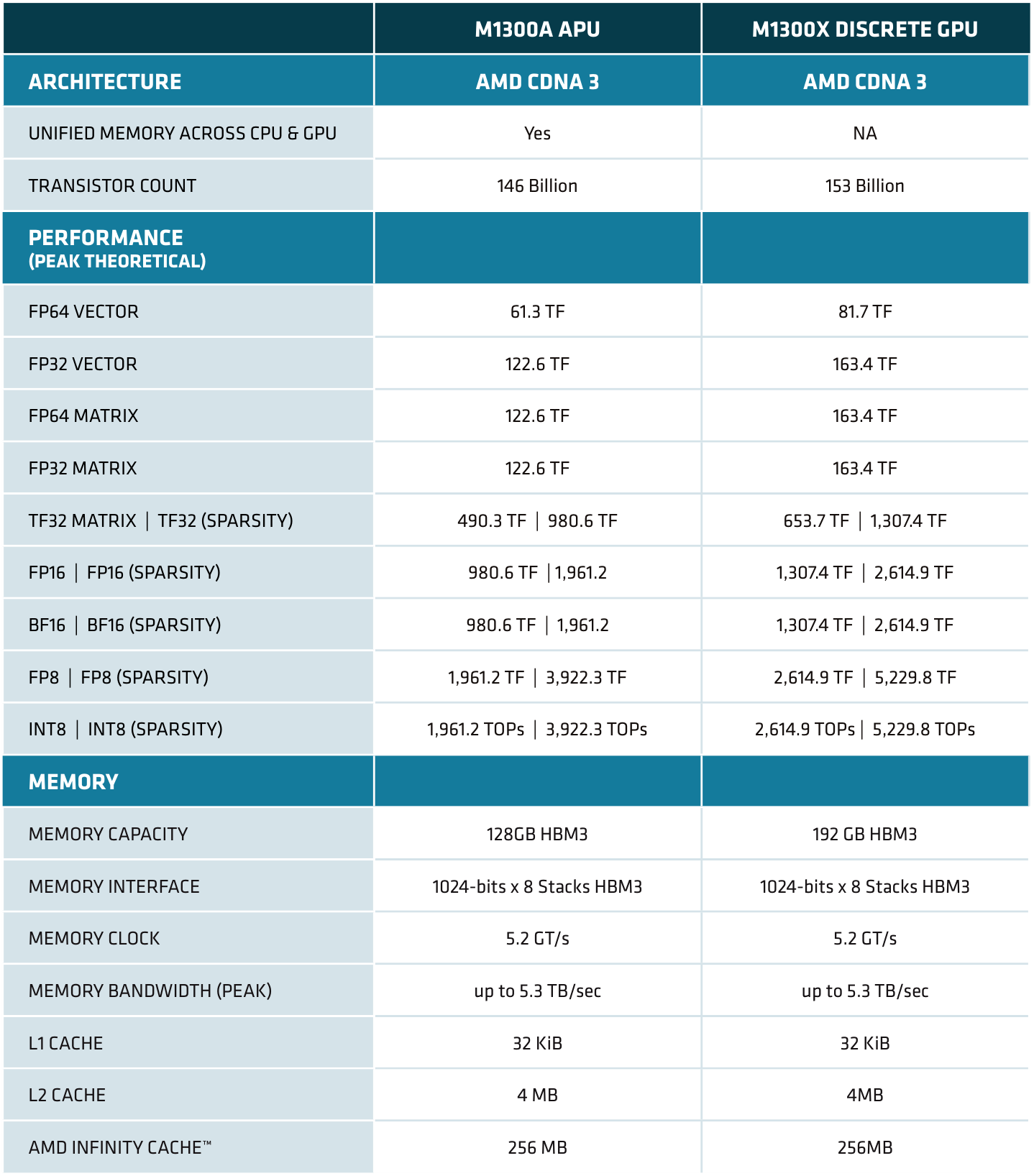
Коммуникационные возможности модулей IOD сконфигурированы по-разному. У MI300X каждый из них «смотрит в мир» семью линиями Infinity Fabric, что в числе прочего делает легко реализуемой топологию с восемью ускорителями без применения дополнительных средств коммутации. Оставшиеся линии сконфигурированы как порты PCI Express 5.0 x16. И это важное отличие от NVIDIA H100, где требуются чипы NVSwitch, которые вообще-то холодными не назовёшь.
Источник: AMD
Более универсальный MI300A имеет лишь четыре линии Infinity Fabric на IOD, остальные линии сконфигурированы в виде четырёх портов PCIe 5.0. Это вполне логично, поскольку APU предстоит общаться с большим числом периферийных устройств, как у MI300X PCIe служит лишь для связи с хост-процессором. С другой стороны, для MI300X идеальная конфигурация, когда на каждый ускоритель приходится один сетевой интерфейс, не оставляет возможностей для подключения накопителей без использования PCIe-коммутатора.
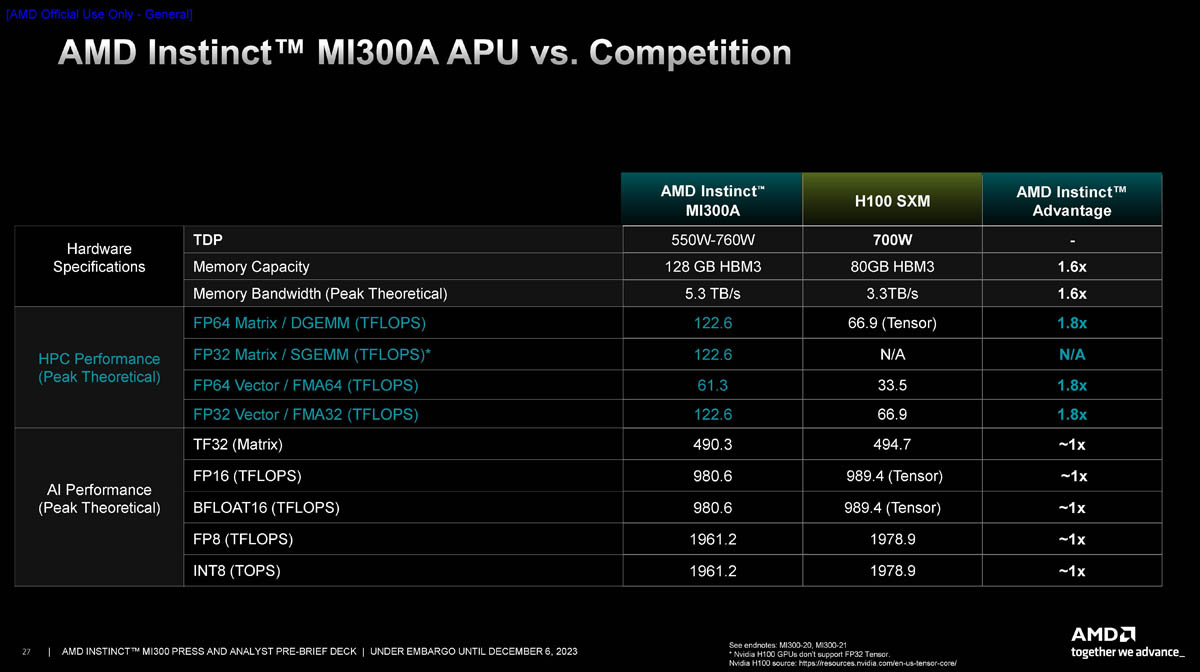
Максимальная тактовая частота XCD у обоих вариантов составляет 2,35 ГГц. Но в силу того, что общее количество потоковых процессоров и матричных ядер у чипов разное — 19456/126 и 14592/912 соответственно — отличается и производительность. Но даже MI300A в векторном и матричном режимах FP32/64, по словам AMD, примерно вдвое быстрее NVIDIA H100 SXM, а в ИИ-режимах пониженной точности не уступает последнему. MI300X, имеющий на 2 модуля XCD больше, пропорционально быстрее. В целом, складывается ощущение, что MI300 в отличие от H100 изначально проектировался для FP64-нагрузок.
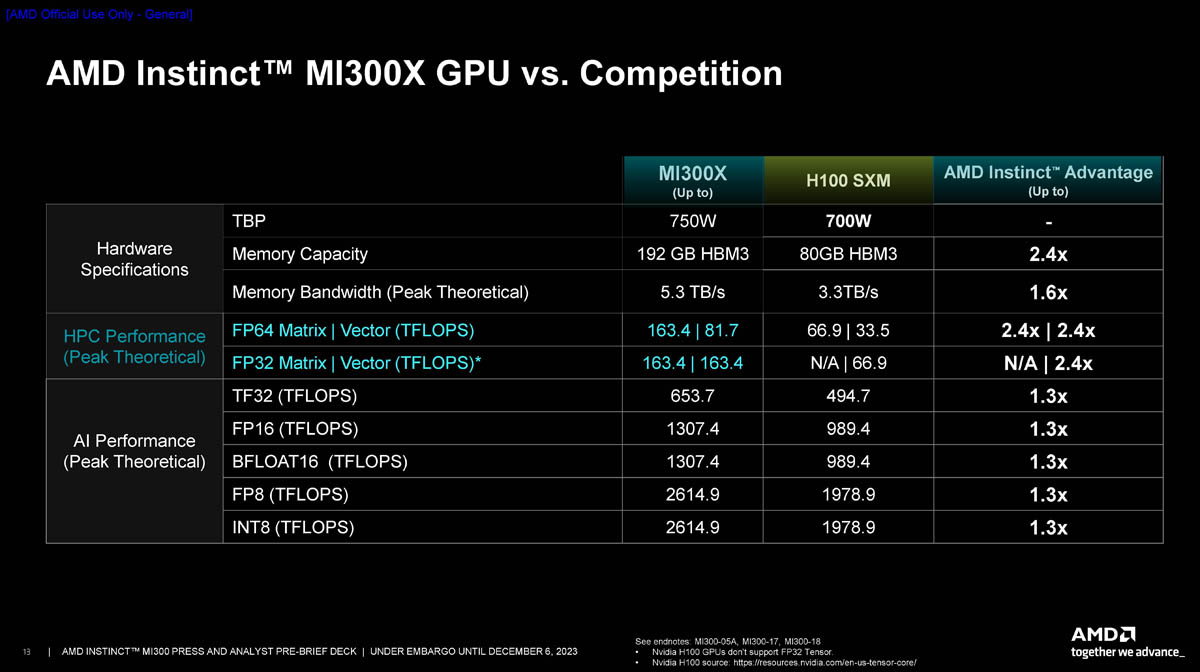
Источник: AMD via ServeTheHome
Как видно из сравнения характеристик MI300X и NVIDIA H100 SXM, первенство AMD вполне закономерно: здесь и больший объём более быстрой памяти, и серьёзный выигрыш во всех вычислительных режимах, от INT8 до FP64. Небезынтересно и сравнение на уровне платформ, ведь в распоряжении NVIDIA есть платформа HGX H100, также использующая восемь ускорителей на узел.

Источник: AMD
В первую очередь, бросается в глаза серьёзный выигрыш в объёме локальной памяти, почти в 2,5 раза — и здесь преимущество AMD очевидно, поскольку объёмы используемых в обучении ИИ-моделей растут день ото дня и 1,5 Тбайт памяти HBM3 лишними явно не окажутся. Именно за счёт объёма памяти выигрыш AMD может оказаться существеннее, особенно в задачах инференса.

Источник: AMD
Также стоит отметить, что по параметрам систем интерконнекта обе платформы весьма близки и явного лидерства не прослеживается. Тем не менее, нельзя не отметить, что, во-первых, это собственные тесты AMD, к которым у NVIDIA уже появились претензии, а во-вторых, NVIDIA в скором времени выпустит ускорители H200 (141 Гбайт HBM3e с ПСП 4,8 Тбайт/с) и GH200 (624 Гбайт HBM3e + LPDDR5x, ПСП 4,9 Тбайт/с). AMD ответила на претензии NVIDIA — MI300X всё равно быстрее H100 в инференсе.
Источник: AMD via ServeTheHome
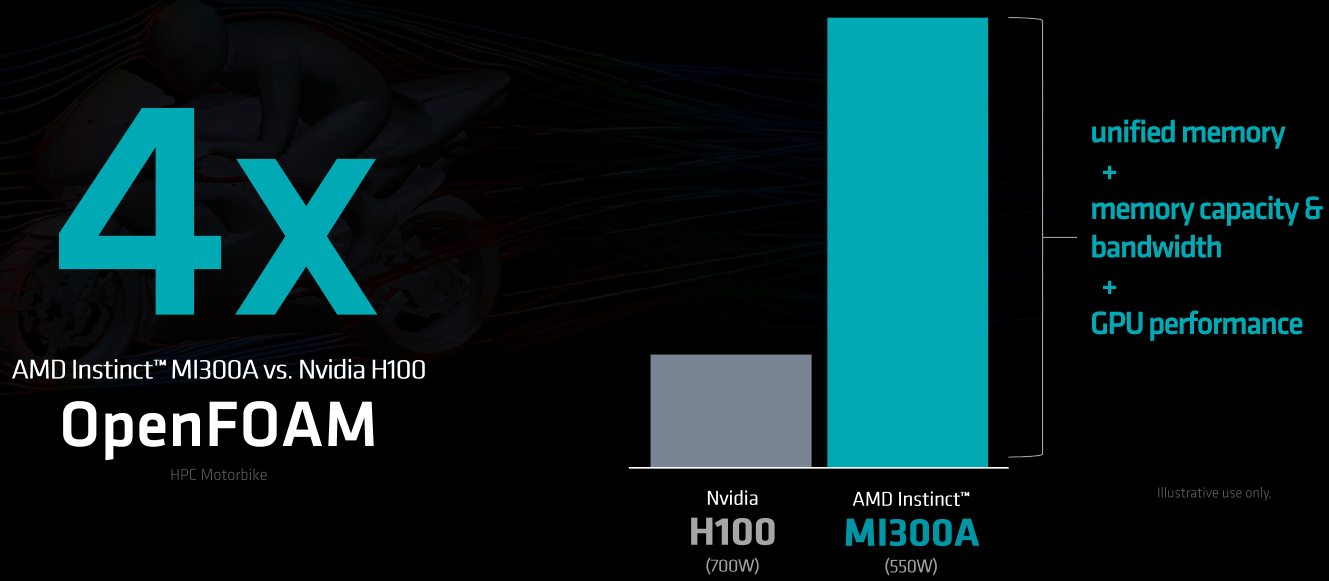
У MI300A ситуация не менее интересная, если сравнивать эту новинку с H100. Новый APU позиционируется AMD в качестве «строительного блока» для HPC-систем нового поколения. В нагрузках, характерных для мира HPC, важна как подсистема памяти, где у AMD вновь первенство, так и производительность в режимах FP32 и FP64. И здесь даже чисто теоретически у MI300A имеется двукратное преимущество перед H100, который, к тому же не умеет работать в режиме матричных вычислений FP32. В реальных задачах выигрыш может быть выше именно за счёт новой архитектуры памяти.
Источник: AMD
В стандартном примере OpenFOAM motorbike новый APU опередил H100 в четыре раза, работая при этом с теплопакетом 550 Вт против 700 Вт у NVIDIA. И даже при сравнении MI300A в режиме TDP 760 Вт энергоэффективность демонстрируется вдвое более высокая, нежели может показать ускоритель NVIDIA. Поэтому можно смело сказать, что новые суперкомпьютеры на базе AMD MI300A будут не только быстрыми, но и экономичными.
Архитектура CDNA3
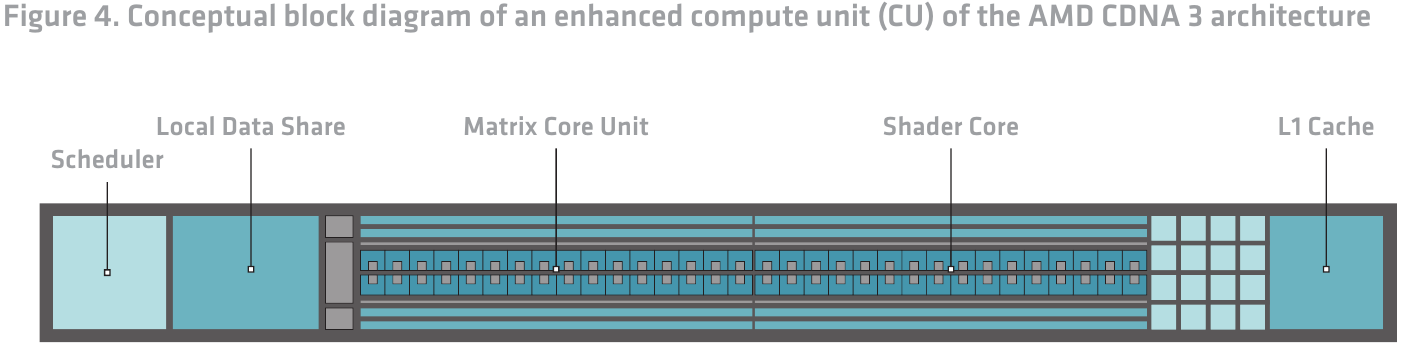
Общая структура кристаллов XCD уже описана выше, пора «нырнуть» глубже. Каждое исполнительное устройство (CU) в составе XCD представляет собой законченный многопоточный процессор с планировщиком, L1-кешем 32 Кбайт и областью Local Data Share (LDS). Последняя служит для более эффективного обмена данными между вычислительными ядрами в пределах XCD и лучшей загруженности этих ядер.
Источник: AMD
Каждые два блока CU имеют общий восьмиканальный множественно-ассоциативный кеш инструкций объёмом 64 Кбайт, что вдвое выше, нежели в CDNA2. Таков же объём LDS. Размер линии кеша вырос вдвое, с 64 до 128 байт. Соответственно была расширена и шина запроса из кеша данных L2, а значит, вдвое выросла пропускная способность в этой точке.
Источник: AMD
Сами ядра архитектурно похожи на ядра CDNA2, однако конструкция была существенно переработана в целях обеспечения более эффективного параллелизма на всех уровнях. В ряде случаев производительность при выполнении векторных или матричных операций удалось поднять вдвое или даже вчетверо. Но самым главным нововведением в CDNA3, пожалуй, следует считать обновление матричных ядер, призванных максимально эффективно работать с типами данных, характерных для ИИ-нагрузок.
Источник: AMD
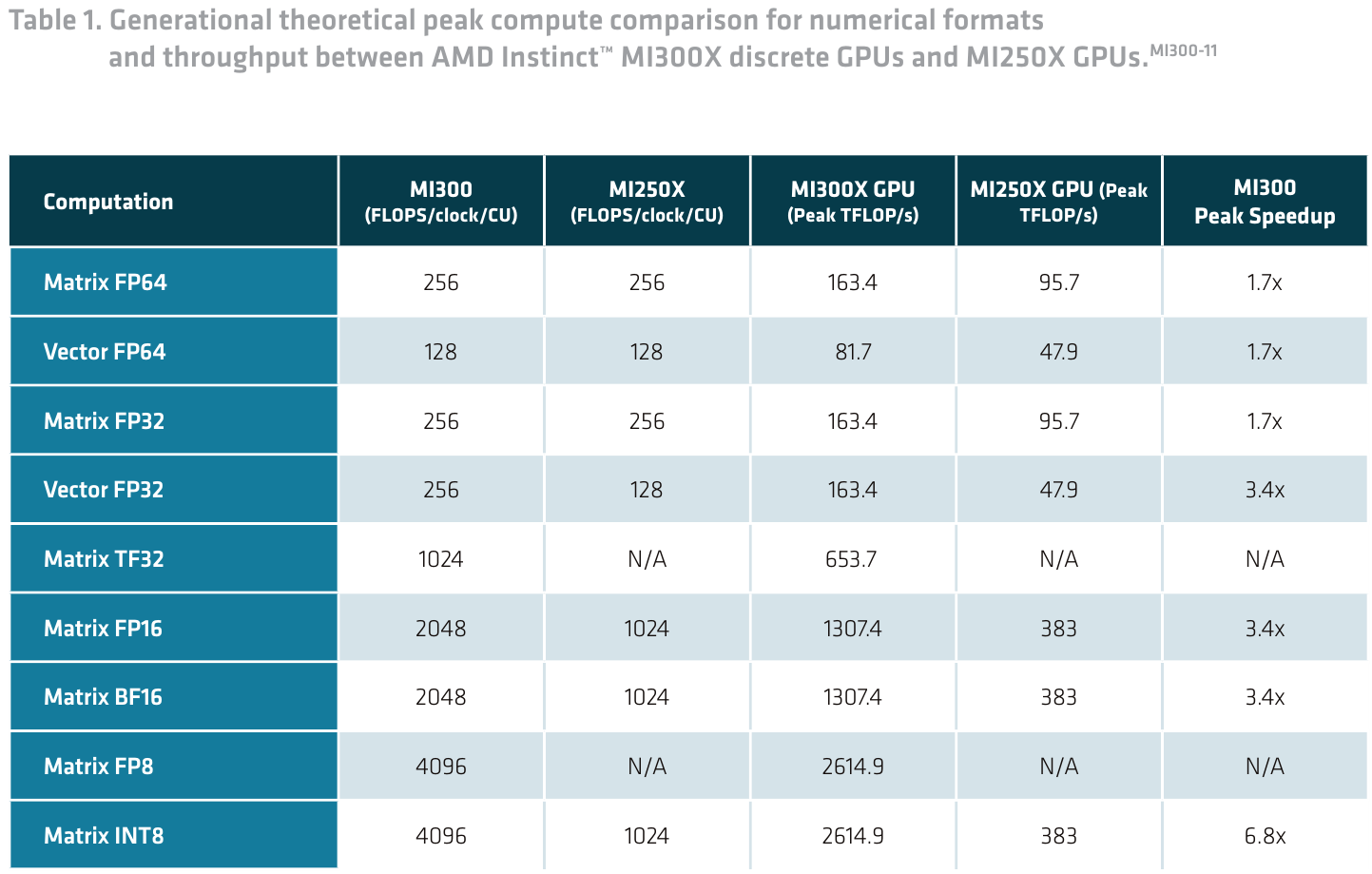
Они поддерживают как FP16 и BF16, характерные для режима обучения, так и INT8, активно использующийся в инференс-режиме. В сравнении с MI250X новые матричные ядра MI300 почти в 3,5 раза быстрее в первом случае и в 6,8 — во втором. В режимах FP32 и FP64 выигрыш меньше, но всё равно составляет до 1,7 раз.
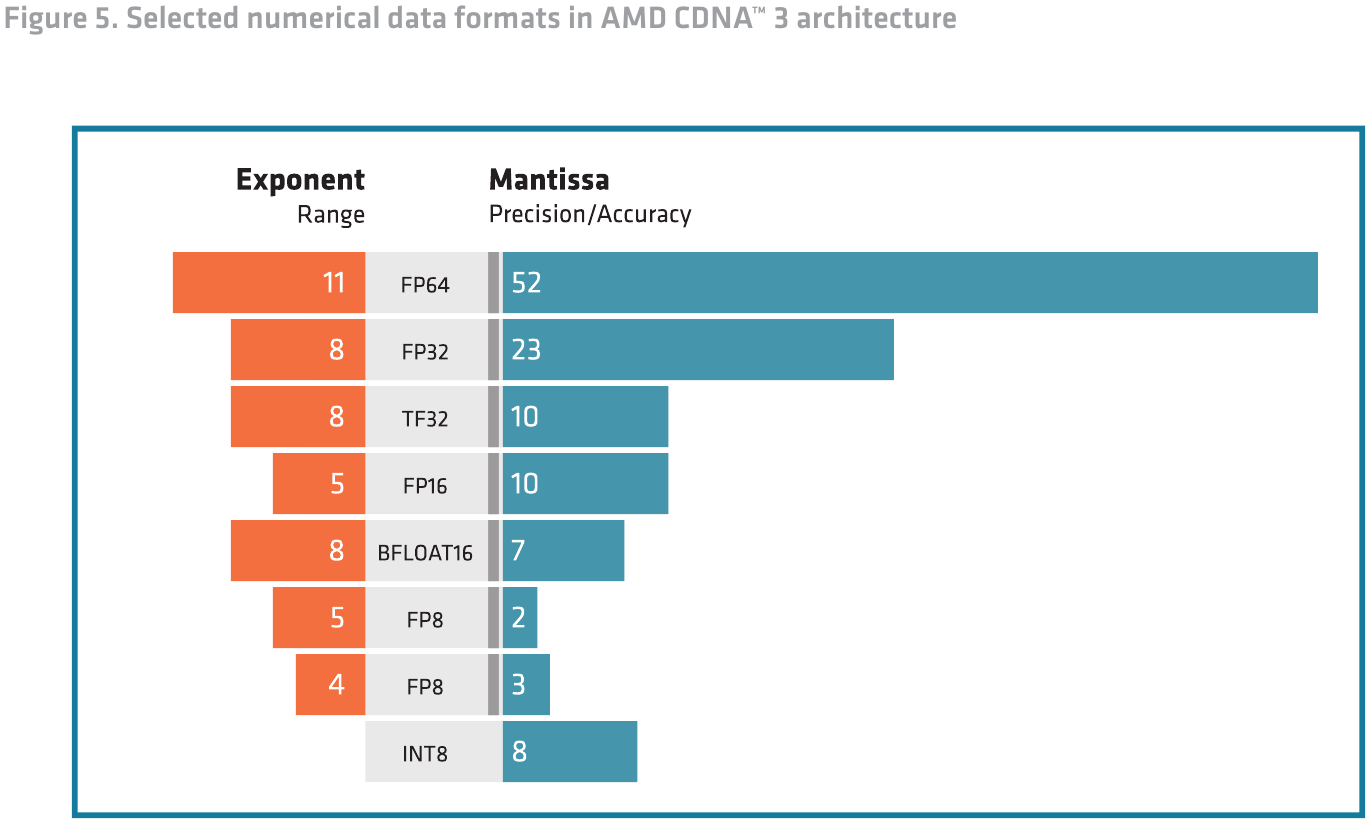
Кроме того, MI300 получил поддержку новых типов данных: FP8 и TF32. Последний представляет собой нечто средние между FP16 и BF16, и позволяет заменить FP32 при обучении без потерь точности, обеспечив при этом более высокую производительность. Кроме того, такой режим лишён определённых недостатков FP16 и BF16: первый не очень хорош для больших языковых моделей (LLM), а у BF16 мантиссы может не хватить для некоторых систем машинного зрения.
Источник: AMD
Режим FP8 введён с целью достижения максимальной производительности при минимальной заполненности памяти. CDNA3 поддерживает два варианта этого режима, описанных в спецификациях OCP 8-bit Floating Point: E5M2 для обучения и E4M3 для инференса. В таком режиме может быть достигнута производительность в 16 раз выше, нежели в режиме FP32.
Источник: AMD via ServeTheHome
Наконец, в матричных ядрах появилась эффективная поддержка разреженных данных (sparse data), что позволяет вдвое поднять формальную производительность на реальных данных. При этом появление поддержки разреженных вычислений вносит некоторую сумятицу при сравнении с другими чипами, чем уже воспользовались некоторые вендоры.
Представляет интерес и новая иерархия подсистем памяти. В CDNA3 она была полностью переработана в сравнении CDNA2, дабы более полно раскрыть потенциал гетерогенной чиплетной архитектуры MI300 и обеспечить автоматическую когерентность кешей, начиная с уровня L2.
Источник: AMD via ServeTheHome
Роль последнего из-за внедрения Infinity Cache в качестве кеша последнего уровня изменилась. Ряд функций работы с памятью был перенесён из L2 в Infinity Cache, а сам кеш L2 переработан, чтобы лучше справляться с наплывом разнообразных потоков данных, поддерживая при этом их изоляцию от трафика поддержания когерентности. По сути, L2 является «точкой обмена» — именно через L2-кеш идёт всё общение XCD с остальными блоками.
L2-кеш работает в режиме write-back и имеет объём 4 Мбайт. При этом он 16-канальный и множественно-ассоциативный, а каждый из каналов может независимо обращаться к 256-Кбайт блоку, что важно, поскольку кеш делится между всеми 38 CU, входящими в состав XCD. Возможно одновременное чтение из кеша по четырём запросам от разных CU за такт линиями по 128 байт. При записи объём на линию вдвое меньше, то есть 64 байта на канал на такт, но также поддерживается один запрос к Infinity Cache.

Источник: AMD via ServeTheHome
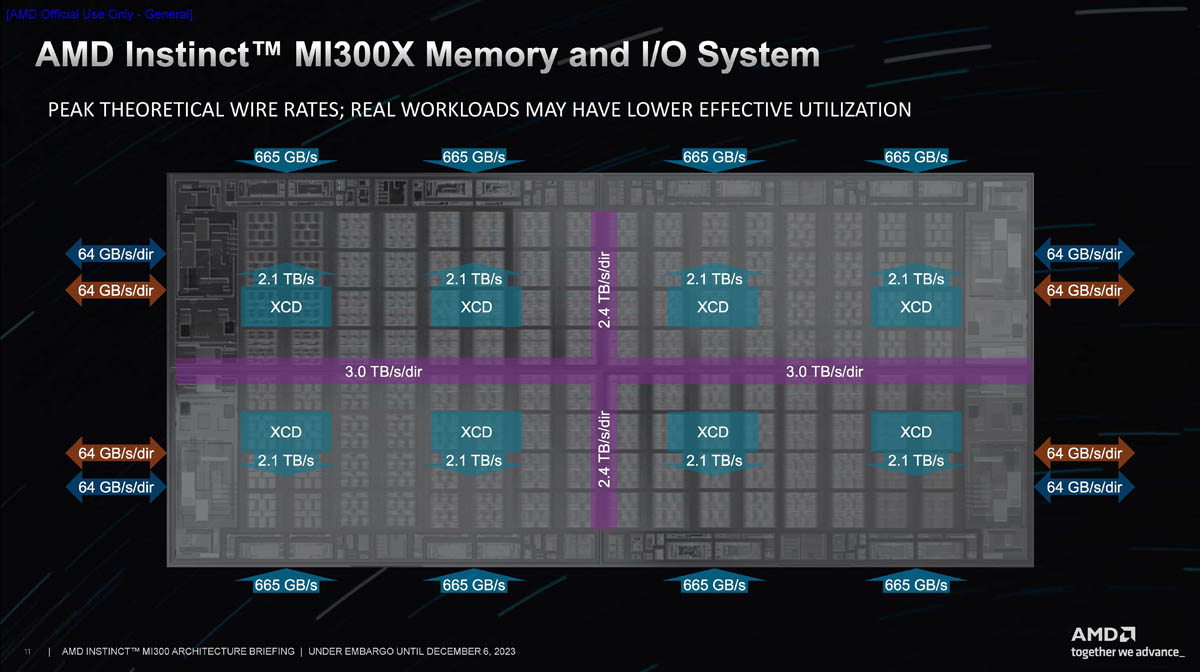
Когерентность L2 поддерживается в пределах XCD, а Infinity Cache использует snoop-фильтр таким образом, чтобы все запросы на когерентность от соседних XCD не перегружали и без того активно используемые разделы L2. Infinity Cache в MI300 может содержать обычно не кешируемые структуры данных, такие, например, как IO-буфера. Производительность при этом достигает 17,2 Тбайт/с, то есть находится на уровне, характерном для L2-кешей решений предыдущего поколения.
Этот кеш также 16-канальный множественно-ассоциативный. Он связан со сборками HBM сразу 16 параллельными каналами шириной 64 байта каждый. На четыре кристалла IOD приходится восемь сборок HBM3, то есть суммарно 128 каналов. Как уже упоминалось, сборки HBM3 могут иметь ёмкость 16 или 24 Гбайт, а формируемый ими пул памяти является унифицированным для XCD и CCD в случае MI300A.
Источник: AMD
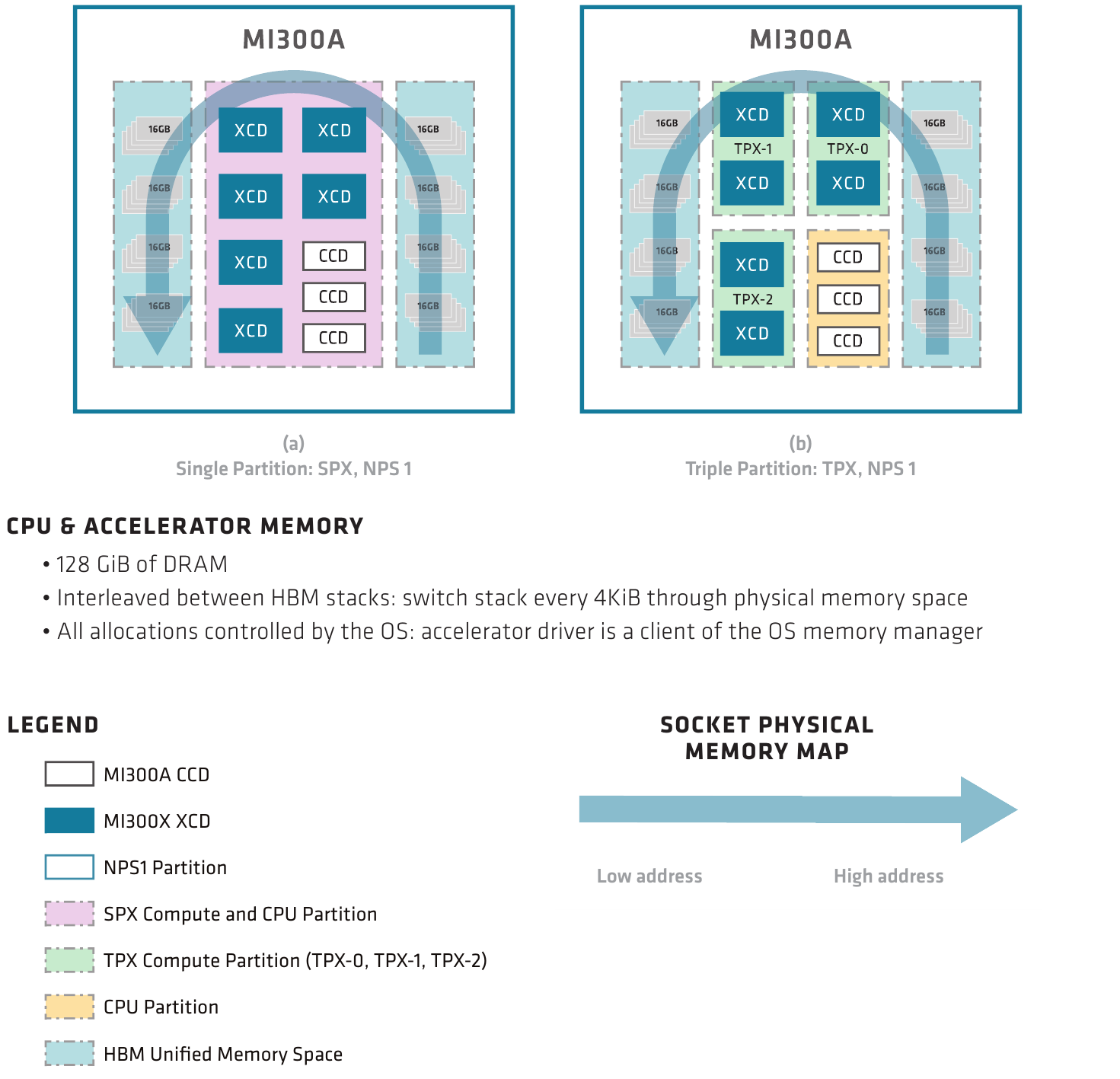
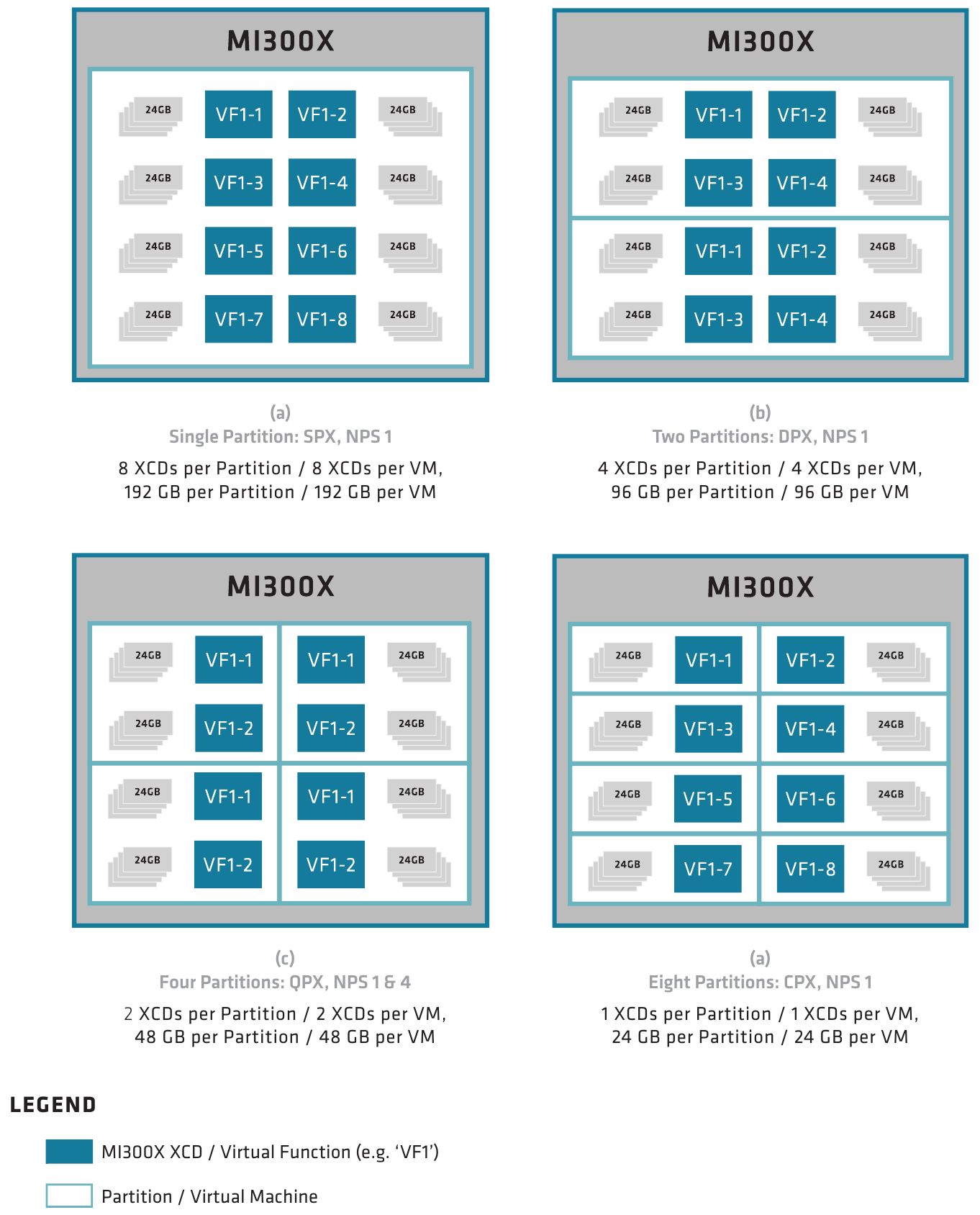
Технически массив XCD может быть разделён на виртуальные GPU, что немаловажно для облачных сценариев, но может выступать и как единый большой GPU. Гранулярность разбиения, впрочем, разная: восемь разделов для MI300X, но лишь три для MI300A, то есть по два XCD на каждый из трёх CCD.
Источник: AMD
Разделяемым может быть и ресурс сборок HBM, но только при условии, что количество разделов памяти не превышает количество собственно разделов GPU. Новые решения AMD полностью поддерживают изоляцию разделов и предоставляют SR-IOV. Разделение работает на уровне ОС, драйвер ускорителя служит клиентом для менеджера памяти операционной системы.
Источник: AMD
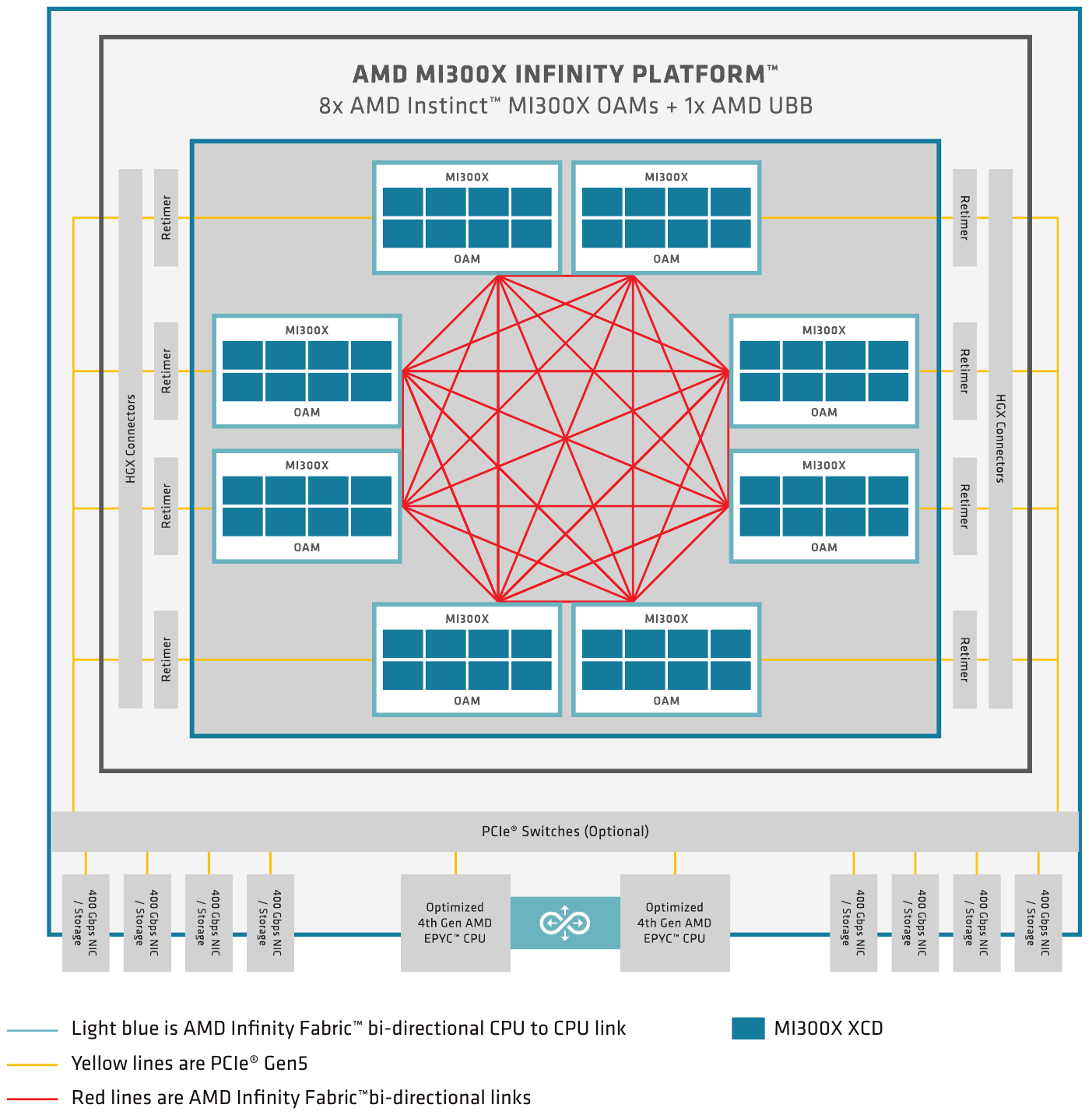
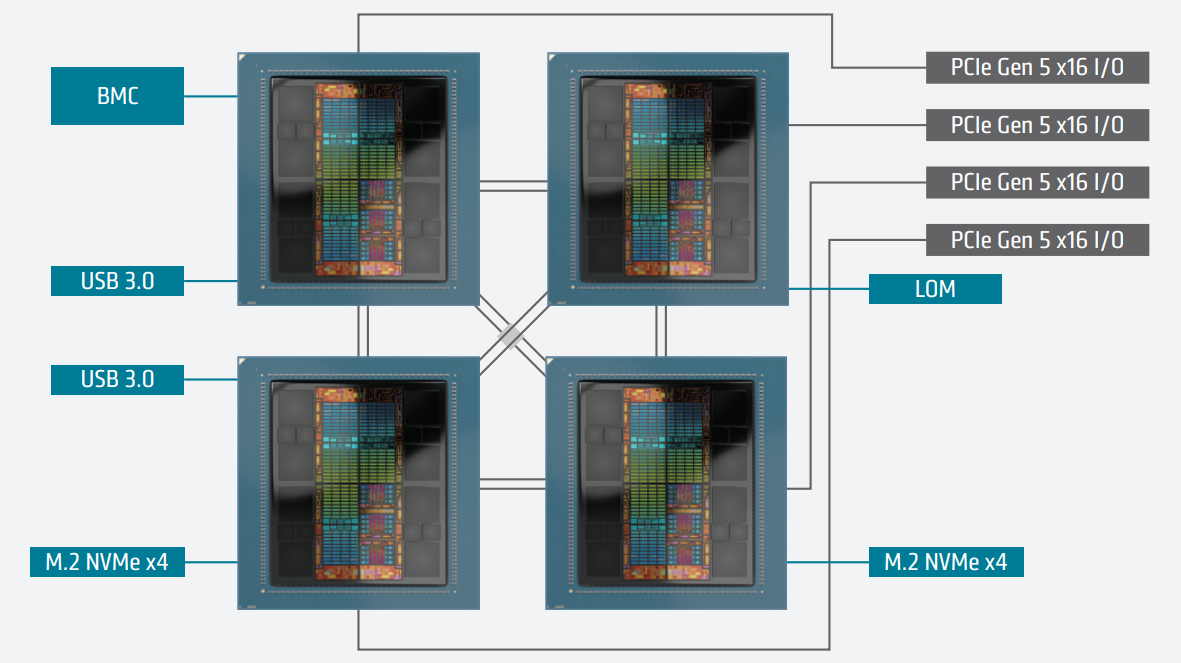
Что касается общения с внешним миром, то каждый кристалл IOD содержит два линка Infinity Fabric по 16 линий в каждом: всего в составе MI300X доступно восемь каналов по 16 линий, из них семь предназначены для связи с другими чипами в составе OAM-шасси на восемь чипов, а восьмой конфигурируется в качестве PCI Express 5.0 и служит для общения с периферией. Такая конструкция идеально вписывается в стандарт OCP Universal Base Board (UBB).
Источник: AMD
У APU MI300A топология несколько иная. В рамках четырёхпроцессорной системы каждый чип связан с соседями посредством двух линков Infinity Fabric с пропускной способностью 256 Гбайт/с, а часть ресурсов IF используется для организации портов PCIe 5.0 x16, разъёмов M.2 и прочей периферии. Такой вариант предпочтителен для организации универсальных процессорных узлов для задач HPC, ведь он будет включать в себя не только 912 CU с архитектурой CDNA3, но и 96 процессорных ядер Zen 4.
XGMI как ответ на NVLink
Несмотря на то, что архитектура и конструкция MI300X позволяет создавать вычислительные узлы с восемью OAM-модулями ускорителей, встаёт вопрос: насколько новая архитектура AMD готова к масштабированию на более высоких уровнях? В основном AMD возлагает надежды на Ethernet/Slingshot или иной интерконнект с интерфейсом PCIe 5.0. Но теперь у неё есть ответ и на NVIDIA NVLink 4. Последний NVIDIA уже приспособила для GH200 NVL32 — наборного ускорителя размером с целую стойку.
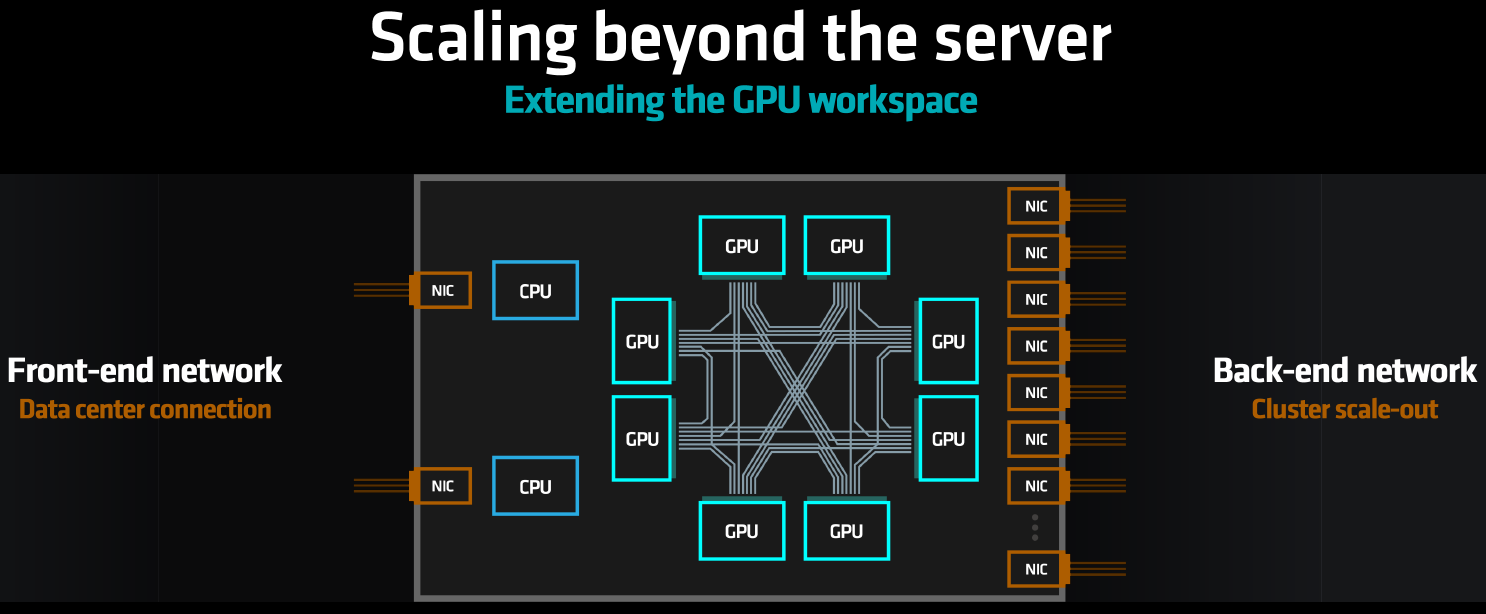
Источник: AMD
Infinity Fabric базируется на PCI Express, но при этом может работать практически на любом уровне, от соединения чиплетов в составе процессоров и ускорителей AMD до межсокетного интерконнекта. При необходимости шина легко конфигурируется в PCIe 5.0 и CXL. Это упрощает создание коммутаторов более высокого уровня, чем и займётся Broadcom, объявившая о поддержке XGMI и Infinity Fabric в следующем поколении своих PCIe-свитчей. Ожидается, что будут созданы и сетевые адаптеры с поддержкой XGMI.
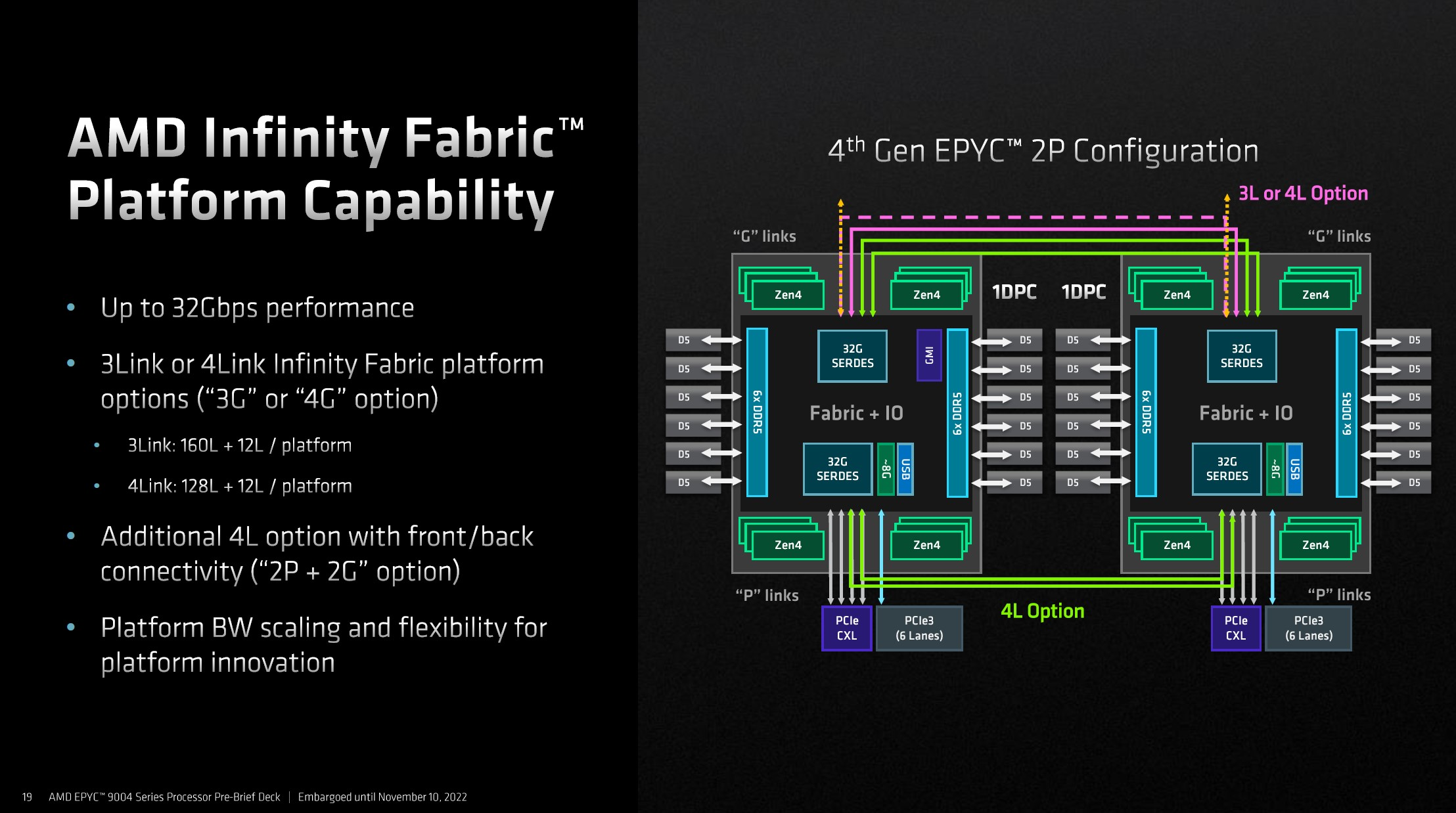
Источник: AMD
Таким образом, при построении ИИ-кластера на базе MI300 появится возможность избежать потерь эффективности при передаче данных в достаточно длинной цепочке «CPU-GPU/PCIe/RDMA-Ethernet». Связка «XGMI-XGMI» в таком случае весьма интересна, особенно в масштабных задачах обучения ИИ. Так что XGMI-интерконнект на уровне стойки и кластера выглядит многообещающе. GigaIO уже готова создавать облака из тысяч MI300X.
ROCm 6 и экосистема ПО
В деле использования ускорителей, особенно в больших масштабах, вопрос наличия удобного и популярного ПО для работы является критическим и в значительной мере определяет успех платформы. Ранее AMD пыталась опираться на открытые стандарты и решения, а также модульность, что, по замыслу компании, должно было привлечь новых разработчиков и сформировать полноценную экосистему.
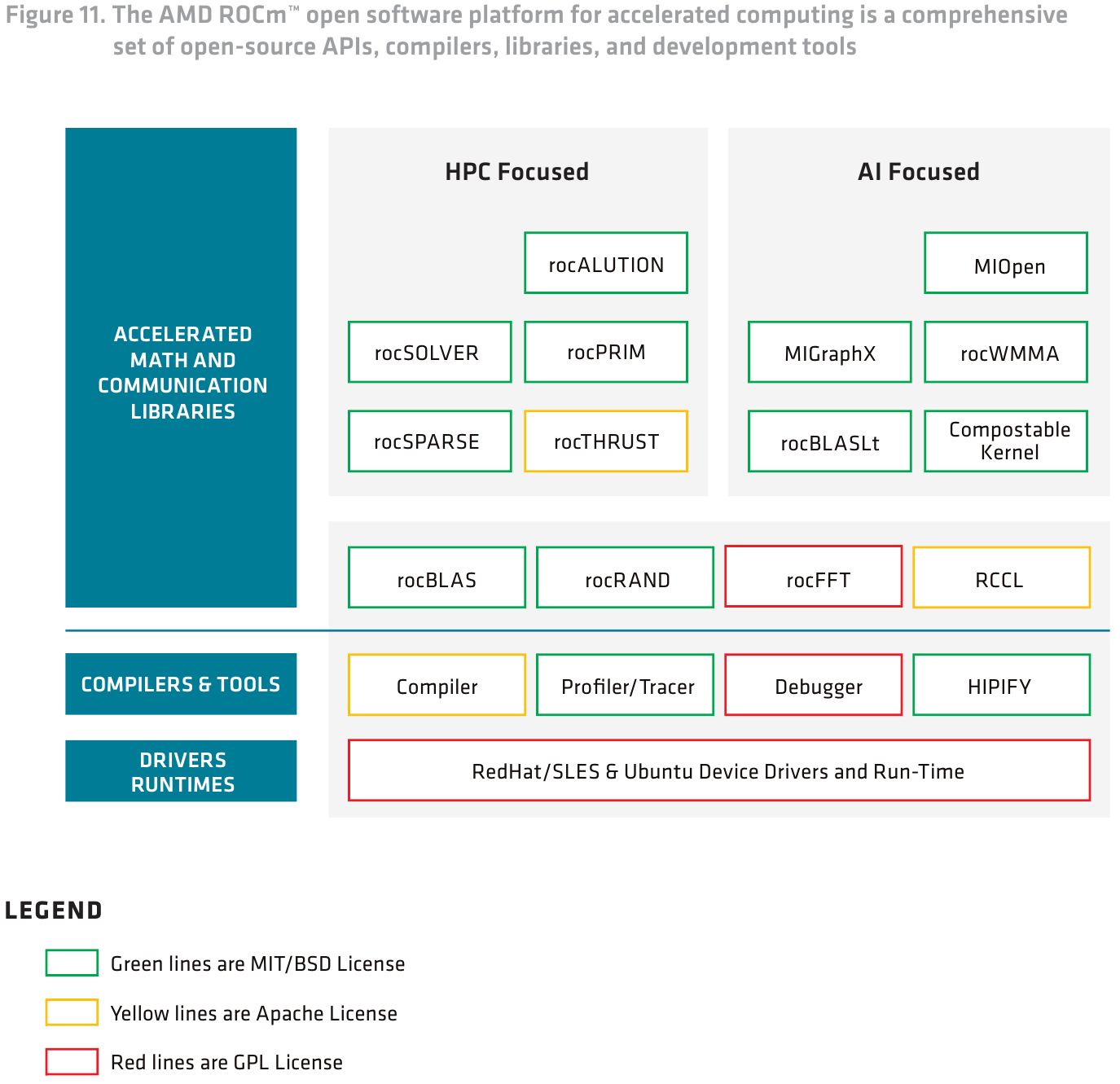
Источник: AMD
Политику компания не поменяла — практически все компоненты грядущей платформы ROCm 6 используют открытые лицензии, от драйверов до компиляторов и комплекта HPC- и ИИ-библиотек. Необходимая документация к ROCm доступна на сайте AMD, а для компонентов доступны и соответствующие репозитории с открытым кодом.
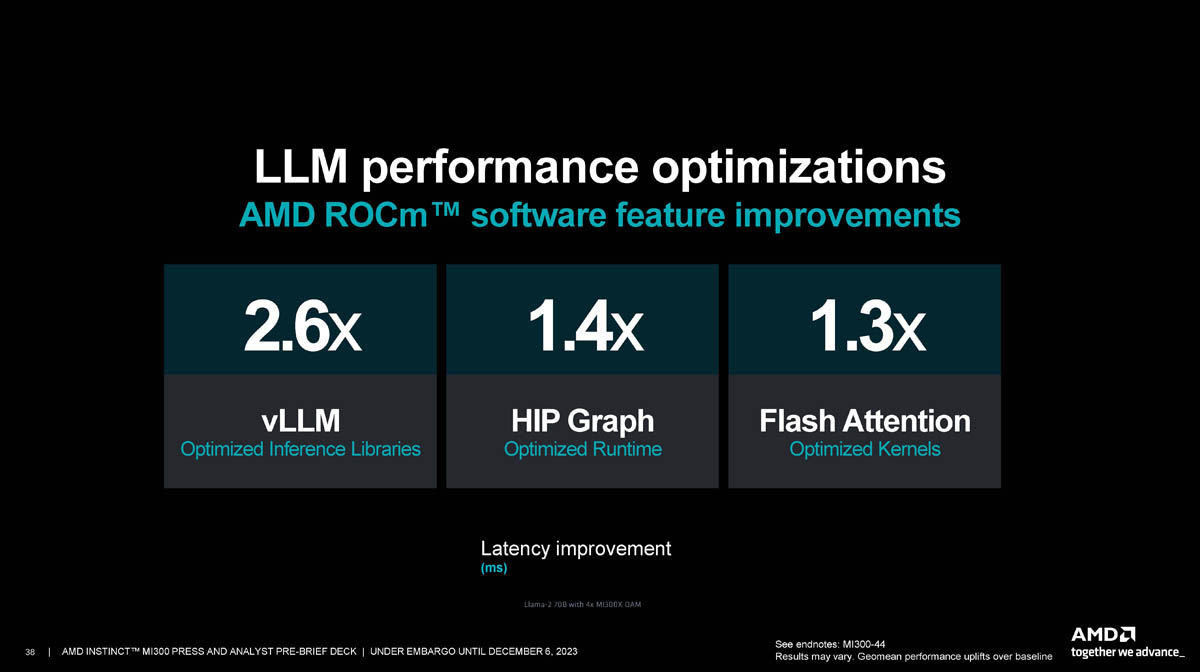
Источник: AMD via ServeTheHome
А вот общий подход AMD, наконец, изменила, вложившись в развитие ПО и заключив за последний год массу новых партнёрств. Первой ласточкой стала интеграция с PyTorch, а затем с Lamini и MosaicML. Во время анонса MI300 было объявлено о поддержке OpenAI Triton, а вчера компания сообщила о совместной работе с ONNX.
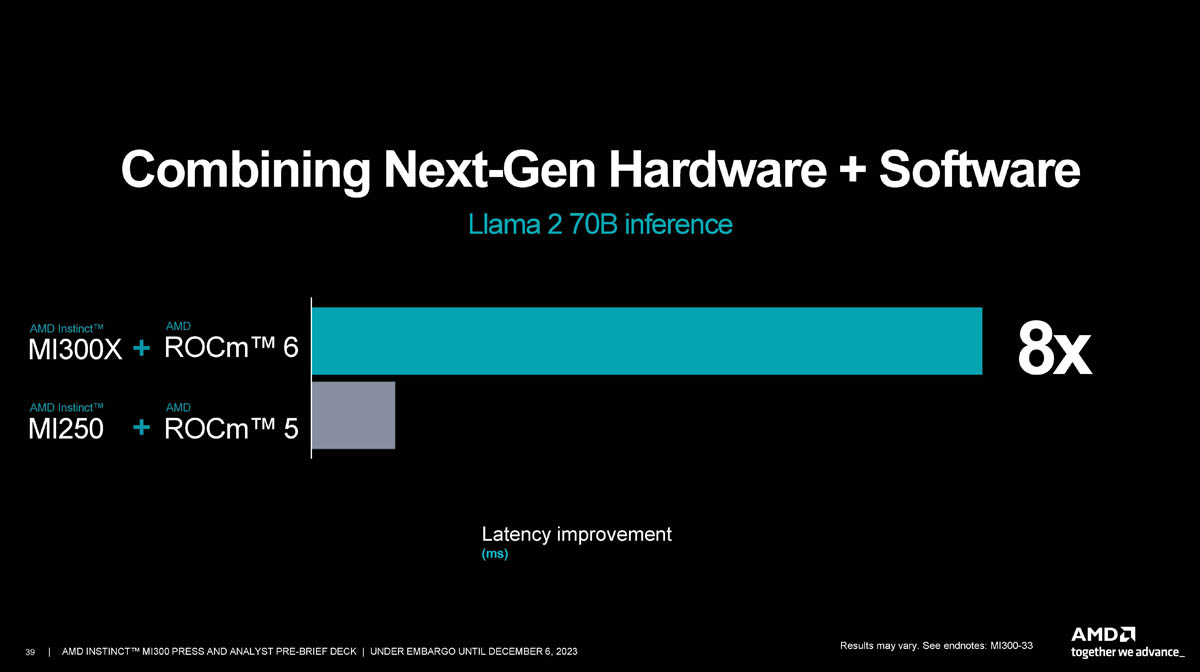
Источник: AMD via ServeTheHome
В шестой версии ROCm были серьёзно оптимизированы все компоненты, от ядра системы до библиотек инференса. В сочетании с новыми ускорителями MI300X это позволяет AMD говорить о восьмикратном преимуществе над платформой MI250 с ROCm 5. Экосистема, совместимая с новыми решениями AMD, уже довольно внушительна и продолжает расти, хотя до программной платформы NVIDIA ей пока далеко.

Источник: AMD
Внимание к MI300 и CDNA3 в целом у рынка достаточно высоко, в список заинтересованных компаний входят как ведущие производители серверного и сетевого оборудования, так и крупные софтверные гиганты, включая Microsoft или Oracle, а также провайдеры ЦОД и облачных услуг.

Источник: AMD
Ускорители Instinct MI300X поставляются заказчикам уже сейчас, массово производятся и гибридные процессоры MI300A, уже успевшие прописаться в суперкомпьютере El Capitan. Судя по всему, MI300 ждёт удачная судьба — у новинок AMD есть все необходимые качества, чтобы завоевать достойное место под солнцем на рынке ИИ и HPC. Компания рассчитывает поставить 400 тыс. ускорителей в следующем году. Впрочем, рынок, остро нуждающийся в ускорителях NVIDIA, похоже, готов поглотить любые объёмы альтернативных ускорителей, лишь бы сроки поставок не были столь пугающими. Кто-то вообще вынужден обходиться CPU.
Источники: