Генеральная линия
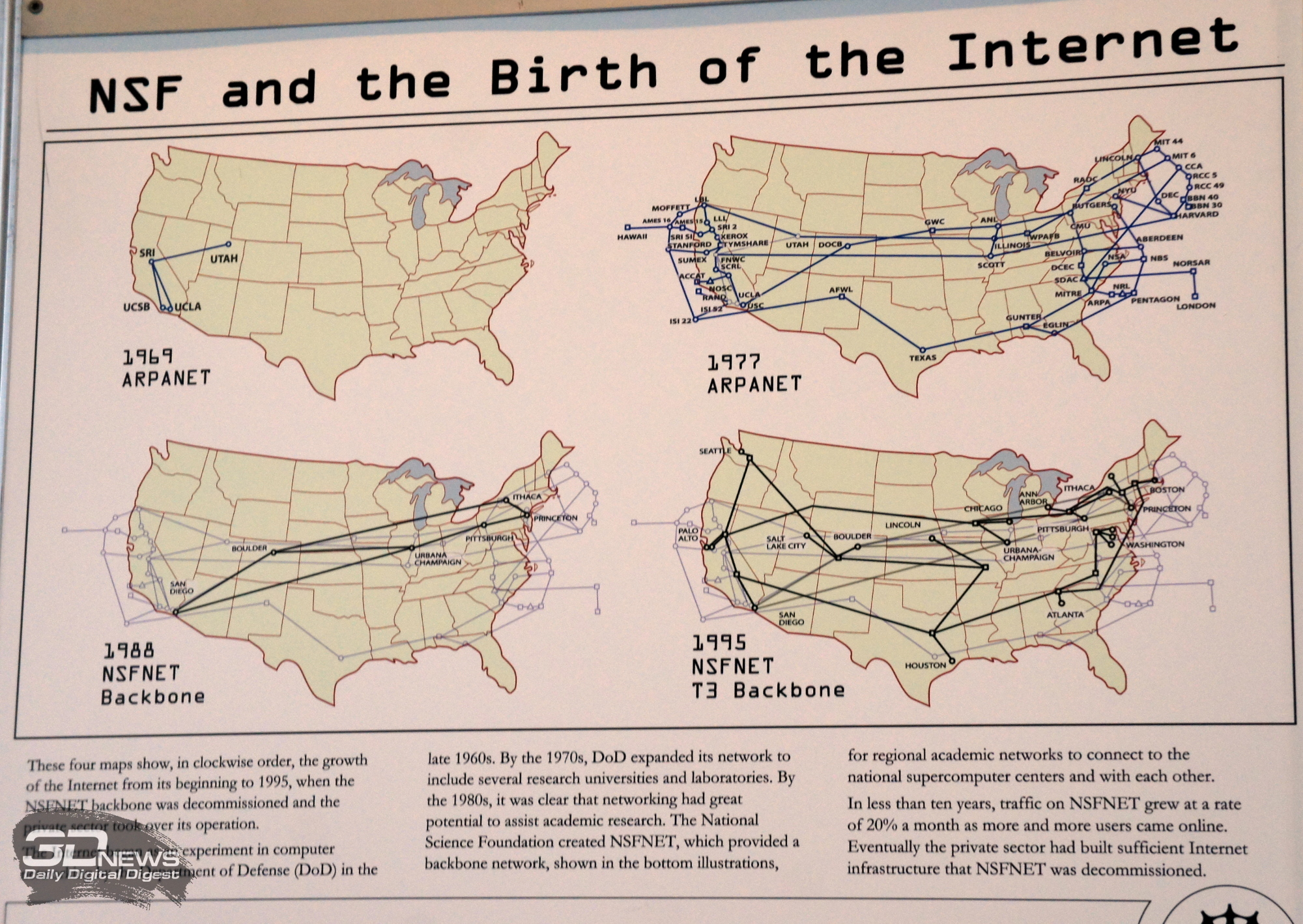
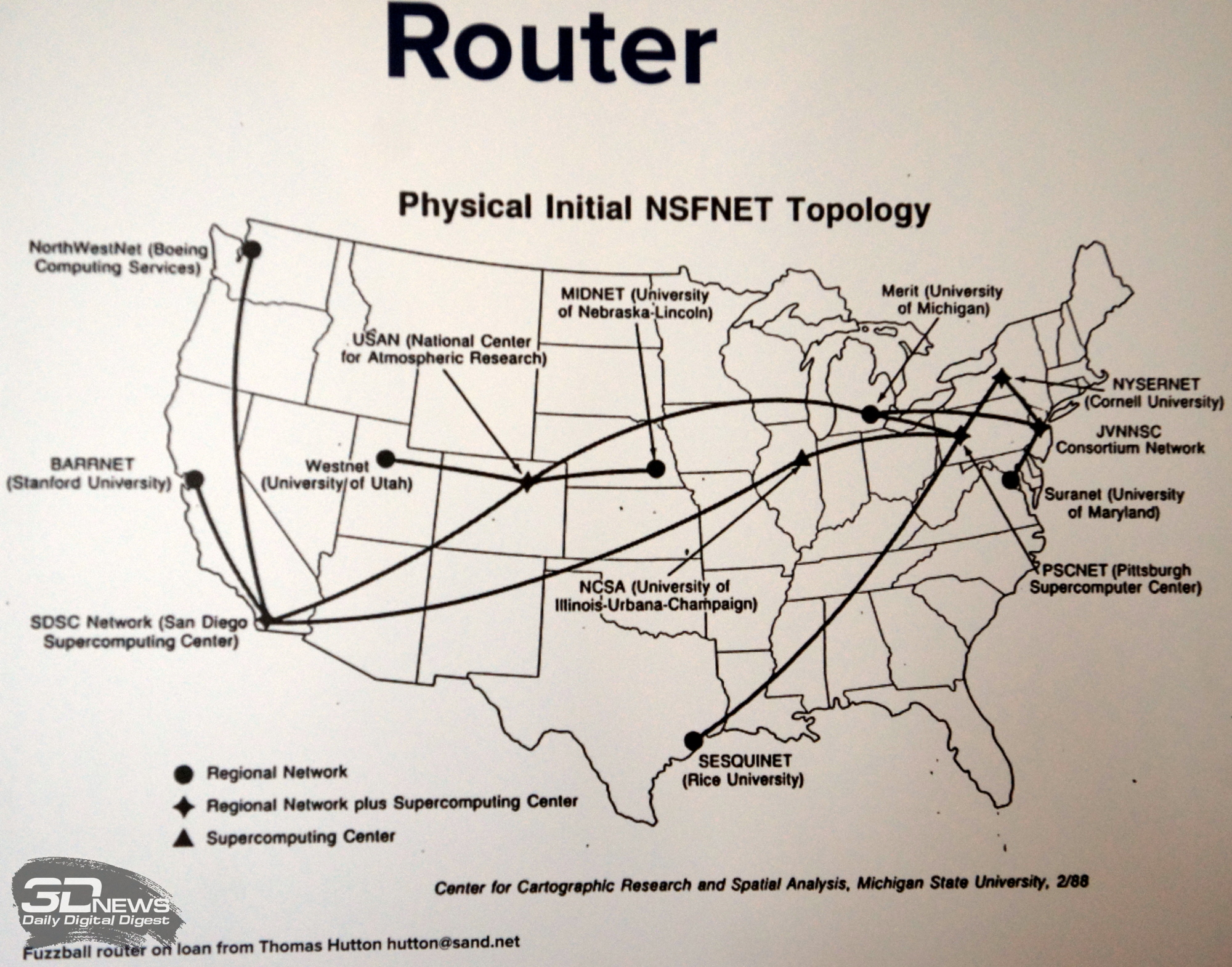
В 2018 году мероприятию SC исполнилось 30 лет. В связи с юбилеем организаторы устроили небольшую выставку исторических достижений суперкомпьютерного хозяйства. Главным экспонатом стал, конечно, легендарный Cray-1, созданный в 1976 году. Часть имён уже и мало кто вспомнит, ведь когда-то легендарные компании или умерли, или были поглощены и успешно переварены конкурентами. Взять, например, машины Convex на базе электроники из арсенида галлия. Или одни из первых, так и не ставших коммерчески успешными многопоточных решений Tera — компании, которая в итоге преобразовалась в нынешнюю Cray. А в отдельном уголке находились также первый интернет-роутер для модемных соединений Fuzzball и один из первых маршрутизаторов Cisco.

Cray-1


















Увы, всё это многообразие архитектур давно закончило свой век. Но стало ли от этого всем лучше? Сейчас в TOP500 доминирует Intel, да несколько лет назад начался взлёт ускорителей NVIDIA. Практично, но скучно, хотя ситуация может поменяться. А пока на носу выход AMD EPYC Rome, который уж точно должен засветиться в рейтинге, и Intel поколения Cascade Lake в двух ипостасях: AP и SP. Что характерно, обе новинки будут обновлениями текущих архитектур, нарастят число ядер (хотя и путём мультичиповой сборки) и получат ещё больше каналов памяти: до 8 и до 12 соответственно. Отдельный вопрос, появятся ли Cascade Lake-AP именно в HPC-сегменте, хотя при таком числе ядер они уже ближе к почившим Phi. Всё-таки 2S-конфигурацию этих чипов можно рассматривать как более плотную упаковку 4S-решений из обычных SP. Как раз уйдёт по 3 UPI-линка к соседям — если предположить, что Cascade от Skylake не слишком сильно отличается, а это похоже на правду. Ну и наверняка AP получат всё-таки BGA-упаковку, а их TDP легко может дотянуть до 300 Вт.


Памяти видимо-NVDIMM`о
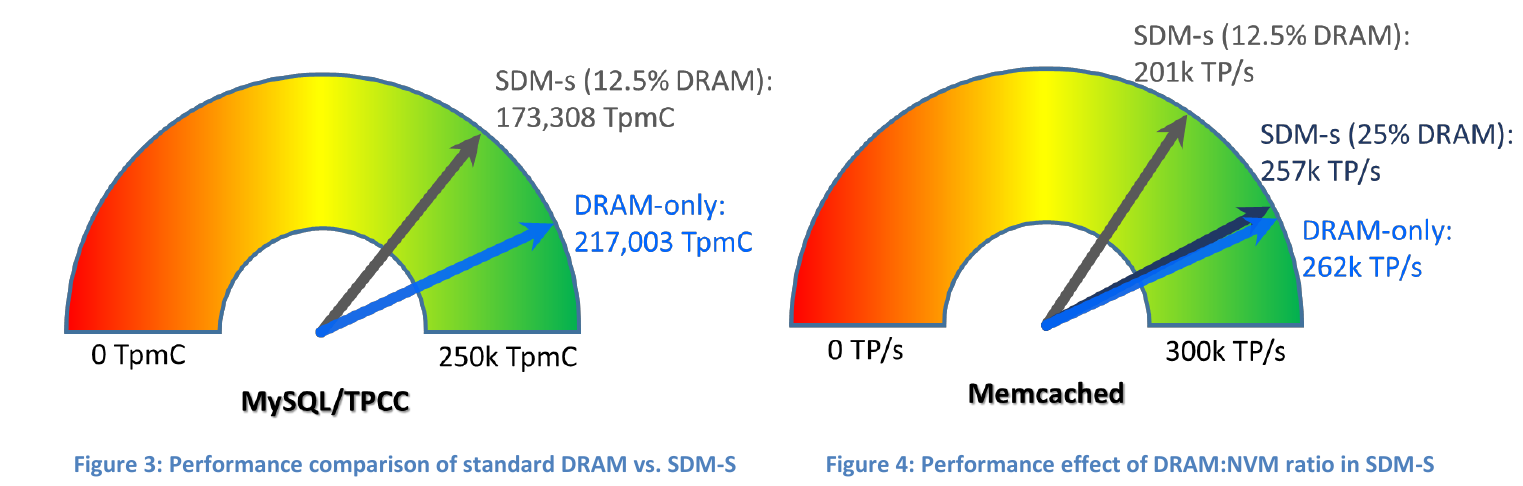
Но самое главное и долгожданное для целого ряда пользователей нововведение (помимо аппаратных патчей от Spectre-подобных дыр) — это поддержка Apache Pass (DC Persitent Memory), то есть нативное совместное использование Optane и DRAM. В данном случае DDR будет выступать в качестве кеша перед массивом Optane. И это даёт повод утверждать, что контроллер памяти в Cascade Lake гарантированно получит поддержку большего суммарного объёма памяти — вплоть до тех же 3-4 Тбайт на сокет в старших версиях. Для чего всё это нужно? Идея довольно проста — целый ряд реальных приложений крайне требователен к объёму доступной памяти, а не только к её скорости. При этом обычная DRAM нынче ох как дорога, так что конфигурация вроде 25 % DDR + 75 % Optane в итоге и выходит существенно дешевле, и даёт достаточный прирост производительности.

Intel Optane NVDIMM

Вообще о проблемах соотношения «байт — флопс» уже упомянуто в отдельном материале с ПаВТ-2018, так что отдельно на этом останавливаться не стоит, но нельзя не отметить, что различных подходов к решению этого вопроса на разных уровнях стало больше. Собственно модули Optane в форм-факторе DIMM уже давно не являются чем-то секретным. Формально их поддержка должна была появиться ещё в Skylake-SP, но по целому ряду причин этого не произошло. В качестве временной меры остаётся доступной технология IMDT (Intel Memory Drive Technology), которая точно так же позволяет расширить объём RAM, но за счёт накопителей PCI-E. В том числе и для таких задач Intel наконец выпустила серверные модули Optane формата M.2 на чипах нового поколения.


Причём официально Intel запускала их совместно с отечественной компанией РСК, которая ещё летом показала прототипы узлов с 12 накопителями M.2 с жидкостным охлаждением. Обновлённые узлы РСК "Торнадо" поддерживают до 4 Тбайт памяти в режиме IMDT (официально-то Cascade Lake ещё не вышел), но можно Optane сконфигурировать и в качестве обычных накопителей для гиперконвергентности или создания NVMe-over-fabric. Вообще говоря, «эксклюзивность» IMDT для Intel, похоже, подошла к концу: Western Digital предлагает точно так же расширять оперативную память, но уже более привычными SSD Ultrastar DC ME200 Memory Extension Drive объёмом до 4 Тбайт. Технически это ровно то же, что IMDT, так как истинным разработчиком технологии является компания ScaleMP: vSMP MemoryONE позволяет создать массив памяти, где DRAM будет занимать не менее 1/8 общего объёма. Так что можно ожидать анонса такой функции и от других производителей «железа».

WD Memory Extension Drive
Конечно, выглядит всё это как некое временное решение, но DDR5 ещё надо дождаться, да и на снижение стоимости оперативной памяти рассчитывать не стоит. Зато, по предварительным данным, для серверов она будет хороша: базовые частоты будут в районе 4-5 ГГц, а задержки при этом как минимум не ухудшатся. И такая память, вероятно, изначально будет регистровой и с коррекцией ошибок, так что домашние пользователи наверняка ещё долго будут довольствоваться DDR4. А может статься, что SCM (Storage Class Memory), к которой относятся Optane и Z-SSD от Samsung, и есть наше будущее. Во всяком случае, уж Optane-то с нами надолго — слишком много вложено в эту технологию. В современной иерархии памяти Intel он занимает сразу две позиции в пирамиде, на вершине которой неожиданно появилась HBM. Вообще, с HBM у Intel были продукты: усопший Xeon Phi имел MCDRAM, то есть одну из вариаций HMC от Micron. Хотя, может, она нужна для грядущих GPU? Или скорее ускорителей — не верится, что это будет именно потребительская графика, а не новый вычислитель.


Гетерогенные аномалии как девиантное поведение
А ещё HBM хорошо сочетается с FPGA (хотя Micron предлагает и GDDR6), которые, в свою очередь, можно скрестить с SSD и получить SmartSSD. Они дороже обычных накопителей, но утверждается, что прирост производительности окупает все затраты. Про этот совместный проект Xilinx и Samsung есть отдельная заметка. Стоит отметить, что это подход к проблеме с памятью с другой стороны — обработка части данных идёт непосредственно на накопителе, без лишнего перегона к процессору и обратно через RAM. Это такая лайт-версия in-memory computing, о котором давно говорят. Да и в целом на SC18 как-то неожиданно много было представлено решений Xilinx, да и Altera тоже. Вон даже Cray делает свою платформу Shasta с прицелом на гетерогенные вычисления. Правда, вопрос с таким подходом вообще и с FPGA в частности касается в большей степени поддержки со стороны ПО — как готовых программ, так и средств разработки.

Google TPU

NVIDIA Tesla T4
Ведь формально можно получить дикие петафлопсы «голой» производительности, которые некому будет эффективно использовать. Такие жалобы были, к примеру, на Tiahne прошлого поколения — китайский суперкомпьютер, который долго был на верхних строчках TOP500. Той же NVIDIA потребовались годы на адаптацию ПО и взращивание армии разработчиков. Результат: за 10 лет GPU-ускорение получили почти 600 HPC-приложений. А для тех же нейронных сетей появились совсем уж узкоспециализированные вычислители — от TensorCore до массы отдельных разработок, включая какой-нибудь Google TPU. И то и другое компании на SC18 привезли. И даже показали, что нейронки могут помочь с обычными HPC-задачами — отсеивая на предварительном этапе ненужные расчёты и анализируя результаты нужных. Кроме того, есть совсем уж узконаправленные разработки вроде нейроморфных процессоров, которые пытаются воссоздать в кремнии работу живого мозга, — на SC18 Intel привезла сразу несколько версий Loihi. В теории FPGA может потягаться со всеми ними за счёт большей универсальности. Но путь этот долог и труден.

Разнообразие ускорителей на базе FPGA Xilinx

FPGA-карты Xilinx Alveo U200, U250 и U280
А вообще, вырисовывается интересный альянс: AMD готова дружить с Xilinx и другими компаниями. В принципе, никто не мешает собрать HPC-платформу без использования продукции Intel и NVIDIA. А если уж говорить об ускорителях вообще, то всё равно сейчас все производители предлагают более-менее универсальные платформы с кучей PCI-E. Шасси на шесть карточек уже как-то и неприлично иметь — надо на восемь, а лучше сразу на двенадцать. Рекордсмены Gigabyte и SuperMicro предлагают уже по 20 слотов (через свитчи, конечно), но это всё же решения под мелкие ускорители вроде NVIDIA Tesla T4 или накопители. Хотя для NVMe всё же гораздо интереснее «линеечные» диски, которые делают Intel и Samsung, — в этом форм-факторе можно уместить до 1 Пбайт в 1U-корпусе.

Inspur AGX-5 на платформе NVIDIA HGX-2: 16 ускорителей Tesla V100 с NVSwitch

Cisco UCS C480 ML M5: 8 NVIDIA Tesla V100 с NVLink
Но всё это не ново на уровне подхода. Мы уже лет двадцать видим одно и то же: куча одинаковых «ящиков», пусть и плотно упакованных во всех смыслах, каждый из которых выполняет одну и ту же программу. Это стандартный путь, и сами «ящики» давно стандартны — глобально от обычных ПК они ничем не отличаются. Ну да, и сами процессоры побольше, и число их тут увеличено, а памяти относительно много, но практически всегда не хватает. На PCI-E мы всё так же вешаем ускорители, а CCIX и NVLink/(Open) CAPI хоть и быстрее, но тоже принципиально ничего не меняют. Смена x86/POWER на ARM/RISC-V или GPU на FPGA либо любой другой ускоритель не влияет на общий подход. Остается интерконнект, который и делает во многом суперкомпьютер суперкомпьютером. Ну вот, в этом плане к 200 Гбит/с подобрались — а надо пятьсот хотя бы при текущем векторе развития.

Mellanox ConnectX-5 и ConnectX-6

Lenovo Neptune
Ах да, теперь ведь везде СЖО — просто потому, что с таким тепловыделением чипов и при такой плотности компонентов жить на "воздухе" просто невозможно. И спор Asetek с CoolIT по поводу того, правильно ли ставить помпы непосредственно в точках большого теплосъёма внутри узлов, или лучше использовать централизованную прокачку, тут совершенно непринципиален. Игроки покрупнее и вовсе делают всё сами, а те же иммерсионные СЖО окончательно стали маргинальными: некоторые компании уже годами возят одну и ту же экспозицию для своих стендов, а мелкие стартапы и вовсе, похоже, не выжили. Все эти огромные ванны попросту неудобны в эксплуатации, хотя в некоторых сферах до сих пор актуальны. В любом случае ничего принципиального СЖО не вносят.
View this post on Instagram✴Буль-буль! Иммерсионная #СЖО #alliedcontrol на #SC18 via #3dnews #3dnewsru
View this post on Instagram✴
Тем временем DoE и DARPA вкладывают миллиарды долларов в надежде обойти закон Мура, но на выходе мы наверняка получим очередную вариацию GPU. Конечная цель — универсальная машина экзафлопсного класса. Вот только некоторые области уже давно уходят к узкоспециализированным решениям. И речь не только про нейронные сети и нейроморфные штуки. Например, Anton — специальный суперкомпьютер для молекулярной динамики — уже упоминался в материалах сайта. А на SC18 японская RIKEN показывала платы MDGRAPE-4, ещё одного такого же решения со схожей архитектурой. Предыдущее поколение (2006 года выпуска) по флопсам формально обгоняло тогдашнего лидера TOP500 в три раза. Правда, что тогда, что сейчас это сравнение не совсем корректно, хотя вынужденное использование уже оптических линий связи между чипами MDGRAPE-4 наводит на размышления.
View this post on Instagram✴Экспериментальные квантовые чипы #Intel #tanglelake #quantumcomputing #SC18 #3dnewsru #3dnews
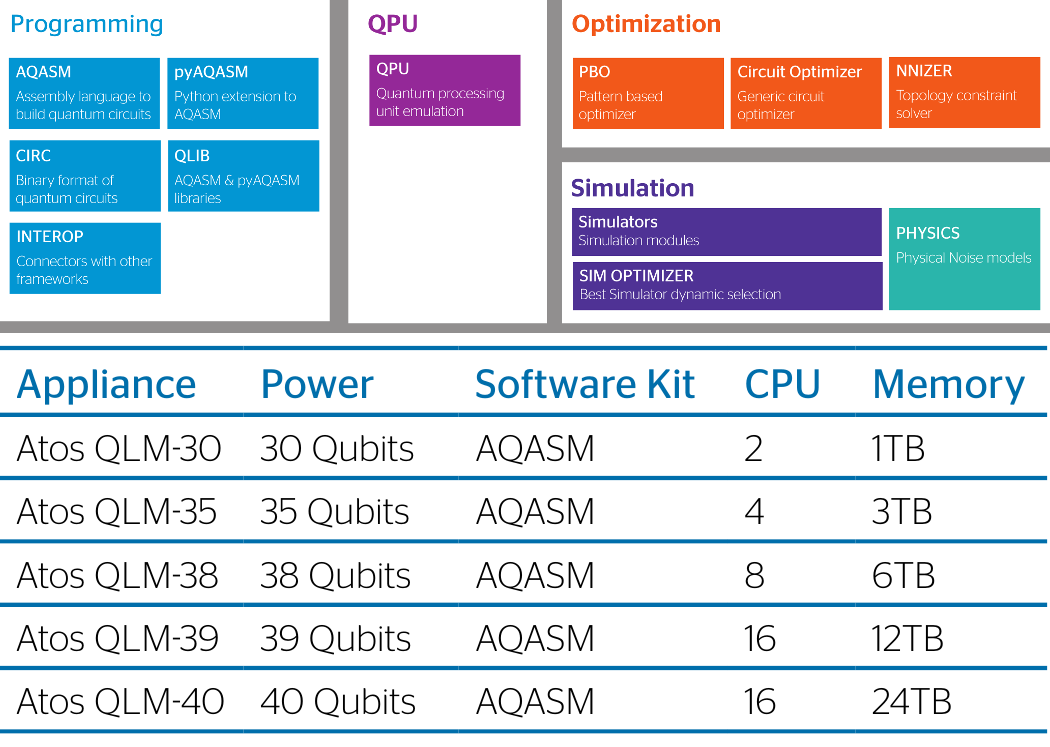
Квантовые компьютеры? Дорого, сложно и не сказать, что универсально. Хотя в последние два года вышло сразу несколько разработок. Это обновлённый D-Wave, а также Rigetti 19Q, IBM Q и Intel Tangle Lake. Последние два были представлены на SC18. IBM привезла сразу холодильную установку, а Intel обошлась только собственно вычислителями. Основная проблема со всеми ними проста — мало кто умеет правильно создавать программы для квантовых компьютеров. На расчёт задачи может уйти несколько минут, а на адаптацию алгоритма — недели и месяцы. Для подготовки специалистов и ПО Atos ещё в прошлом году представила Quantum Learning Machine. Нет, это не квантовый компьютер, а специальная аппаратно-программная платформа на обычном «железе», которая может корректно симулировать поведение 30-40 кубитов. На ней можно производить отладку будущего софта. Atos даже создала особый язык программирования: aQasm (Atos Quantum Assembly Language).

Atos Quantum Learning Machine
Gen-Z: общий интерконнект для всех — и пусть никто не уйдёт обиженный
Наверное, единственное интересное движение в сторону переработки архитектуры, пусть и не столь глубокое и всеобъемлющее, — это первые реальные продукты на базе Gen-Z. Технология эта разрабатывается с 2016 года с почина HPE, хотя сейчас в консорциуме много видных игроков, а возглавляет его представитель Dell. Зимой была утверждена первая версия спецификации. Если коротко, то Gen-Z предлагает универсальную шину/интерконнект для объединения всего и вся. Буквально всего: CPU, памяти, хранилища, устройств ввода-вывода, (GP)GPU, FPGA, DSP и так далее. Gen-Z использует достаточно высокоуровневый протокол для общения между всеми ними и скрывает от пользователя всю низкоуровневую «магию». Естественно, адаптировать аппаратные компоненты должны сами производители. Зато в итоге можно будет с лёгкостью менять компоненты, не задумываясь о проблемах совместимости. В идеале, конечно.
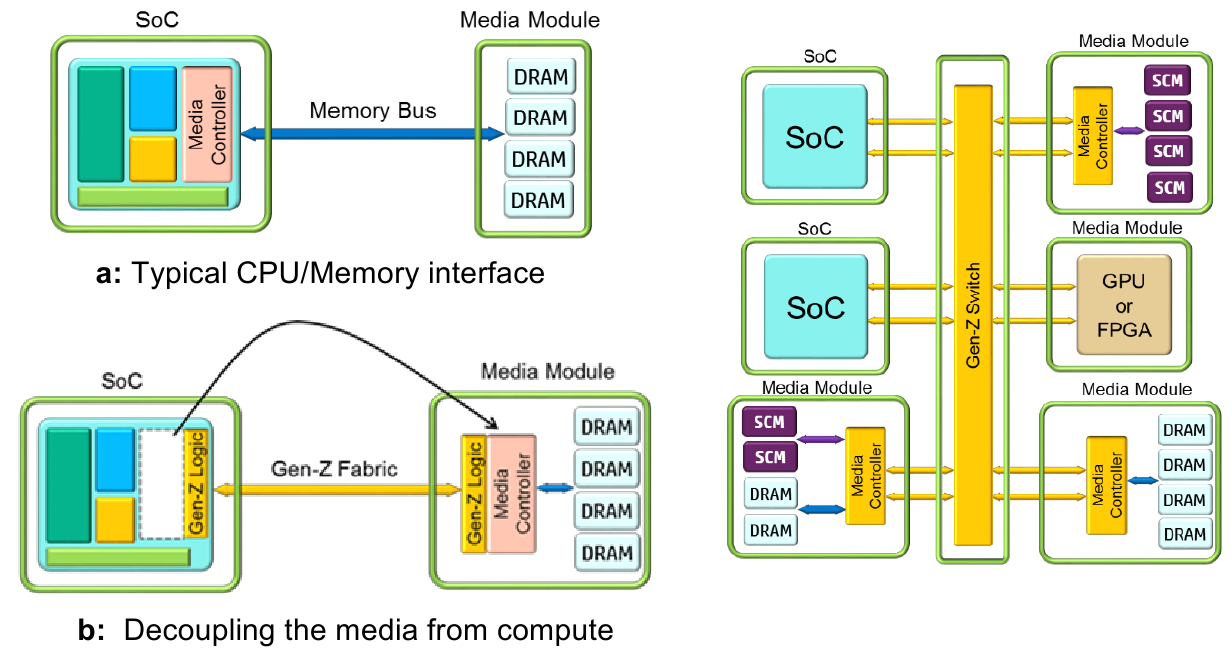
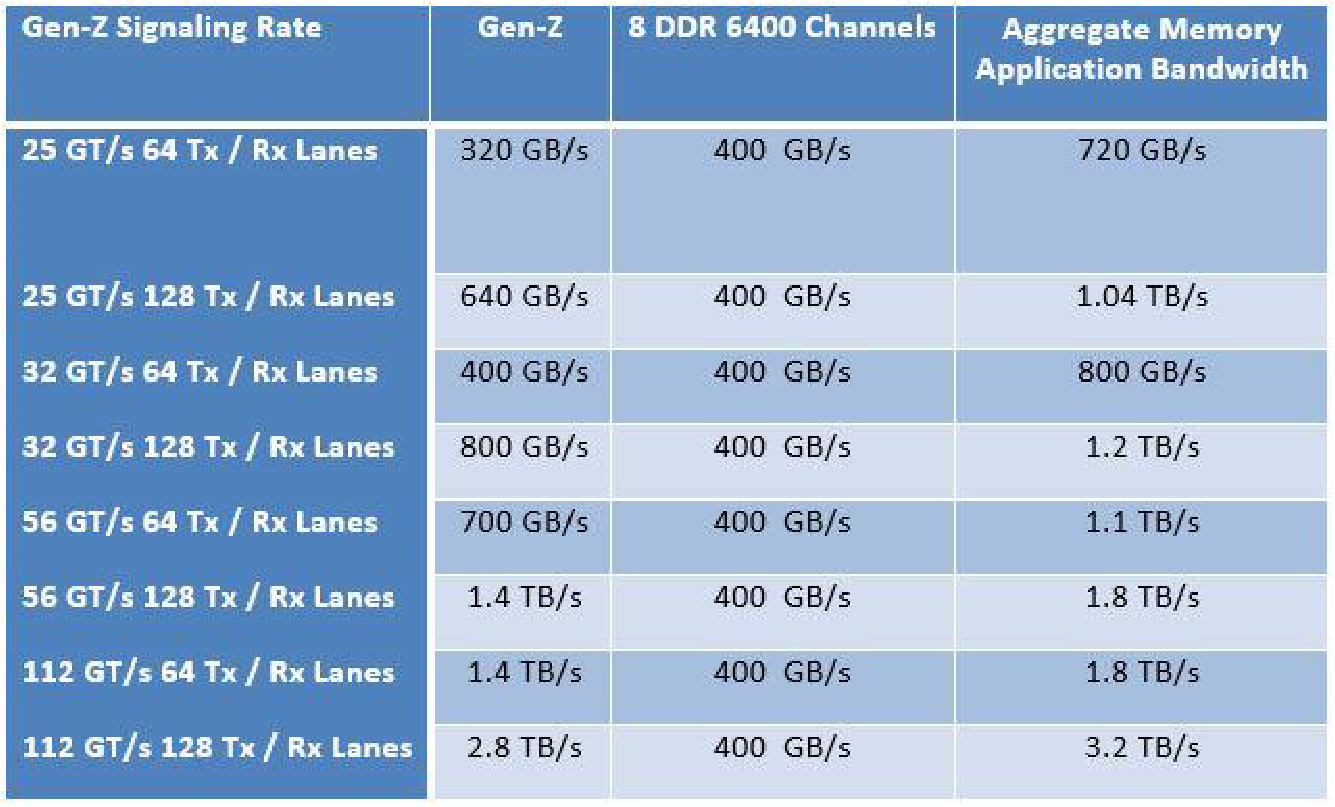
Впрочем, в двух словах описать все возможности Gen-Z не представляется возможным. Но, кажется, в спецификации учтены чуть ли не все возможные сценарии и заранее продумана защита от типичных проблем. Список участников консорциума включает многих крупных игроков, но в нём нет Intel и NVIDIA, у которых свой взгляд на то, как лучше делать шины и платформу в целом. Впрочем, Gen-Z пока в начале своего пути и ещё неизвестно, что из всего этого получится. Но в целом идея действительно интересная. На SC18 консорциум привёз первые реальные образцы оборудования с поддержкой Gen-Z, а также целую россыпь различных версий физической инфраструктуры — всевозможных вариаций кабелей, разъёмов, контактных площадок и так далее. Несколько удивляет, что до сих пор не доминируют оптические варианты исполнения, так как «медь» смотрится несколько громоздко.

Gen-Z: общий модуль RAM для двух серверов

Gen-Z DRAM Media Controller Card
Наиболее наглядная демонстрация Gen-Z — это два сервера, подключённых к общему внешнему пулу оперативной памяти. В самих серверах обычных модулей RAM действительно нет, хотя, по идее, для загрузки машины хоть какой-то локальный объём всё равно нужен. Всё это работает на современном «железе» с небольшой модификацией ПО. Ещё одна демка хоть и не кажется чем-то необычным, но на самом деле тоже важна — она показывает работу общей памяти для нескольких узлов на примере простого графического редактора. Правда, сейчас у Gen-Z классическая проблема курицы и яйца: готовых платформ нет, потому что нет «экосистемы», которую, в свою очередь, не из чего формировать.


Модули Gen-Z
Пока что консорциум активно трудится над программным эмулятором аппаратной части, чтобы разработчики ПО всех уровней могли адаптировать ОС, драйверы и программы для Gen-Z. Если всё сложится удачно, то мы увидим любопытные системы, которые можно на лету формировать из различных блоков, совместимых с Gen-Z. То есть на уровне шасси, стойки, а потенциально и целой машины легко конфигурировать память, хранилище, вычислители, ускорители и внешние интерфейсы путём добавки или изъятия готовых блоков в зависимости от текущих потребностей.









Послесловие
Общее настроение хорошо передаёт комментарий к прошлой заметке с SC18: «Скучно всё это... 2021 год, и где же нейроморфные компьютеры на квантовых кубитах с троичной логикой?» Пусть и не в такой конкретно формулировке, но ничего этого на практике действительно нет. Беглый осмотр стендов выставки показывает, что да, мы всё выше, быстрее, сильнее. Но это экстенсивный путь развития. И грядущие экзафлопсные машины наверняка будут очень дорогими, горячими — в случае развёртывания действительно гетерогенных вычислений, а ещё и непростыми в освоении, если всё останется так, как есть. Причём не так важно, будут ли это отдельные чипы, либо сразу N чипов под одной крышкой, либо же просто новые инструкции. О да, мы уже видим эволюцию в памяти, а это хоть какой-то сдвиг подхода к построению машин. Мы видим зачатки квантовых и нейроморфных систем, но нужны ли они нам на самом деле? Кто создаст новую универсальную архитектуру? Кто сделает HPC great again? Или хотя бы не таким привычным и… стабильным.