Строго говоря, речь пойдёт не только о самих процессорах Xeon, которые теперь непременно снабжаются приставкой Scalable Processor, но и о платформе Intel Purley — она включает текущие CPU Skylake-SP и грядущие Cascade Lake, чипсеты Lweisburg, а также некоторые ускорители, которые, впрочем, по большей части уже были представлены ранее. Префикс Scalable неслучаен, потому что на этот раз Intel постаралась угодить чуть ли не всем. Это касается и архитектуры платформы, и того разнообразия SKU, которое было представлено. Вот с этого, пожалуй, и начнём.

Наименования и серии
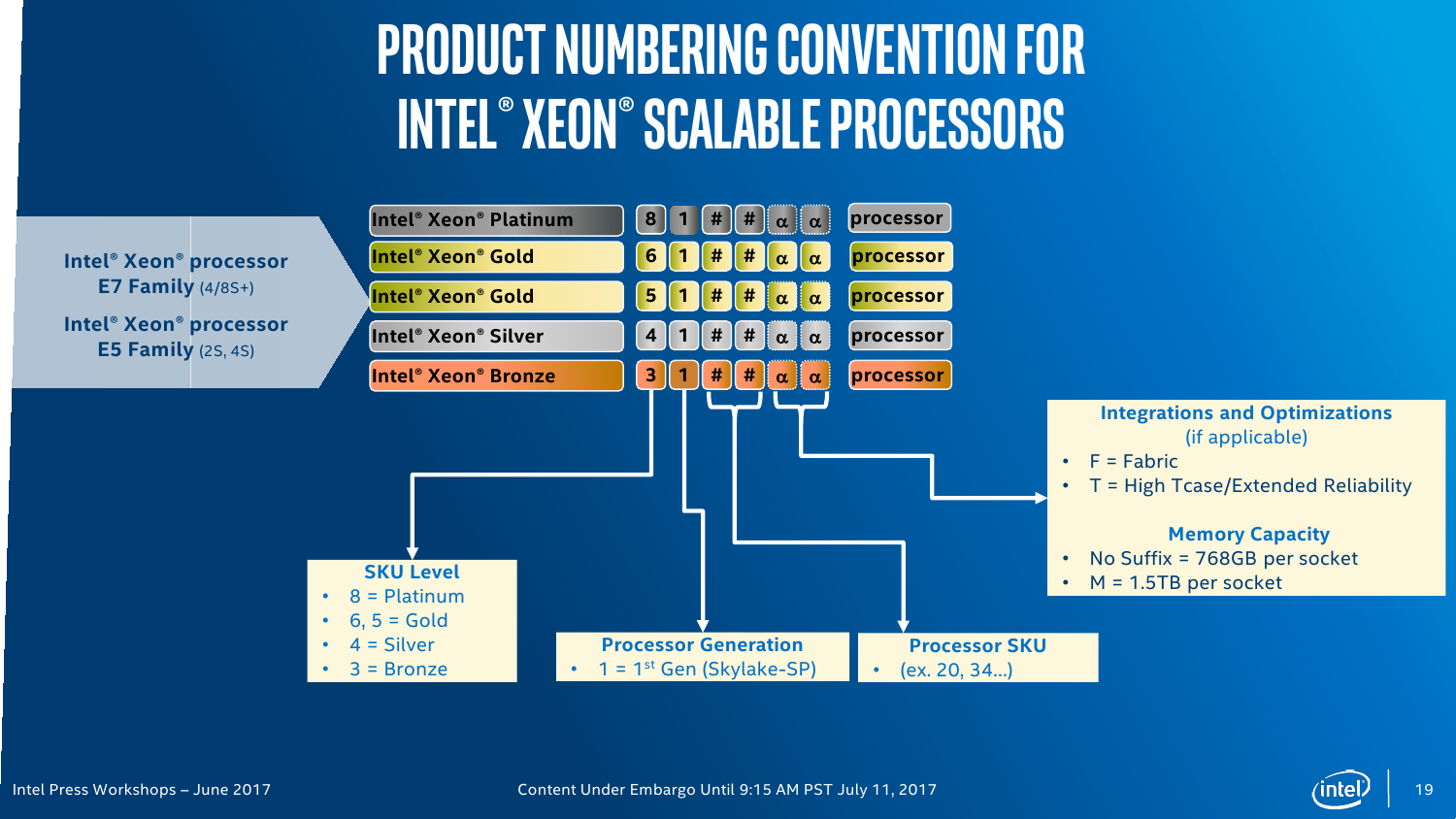
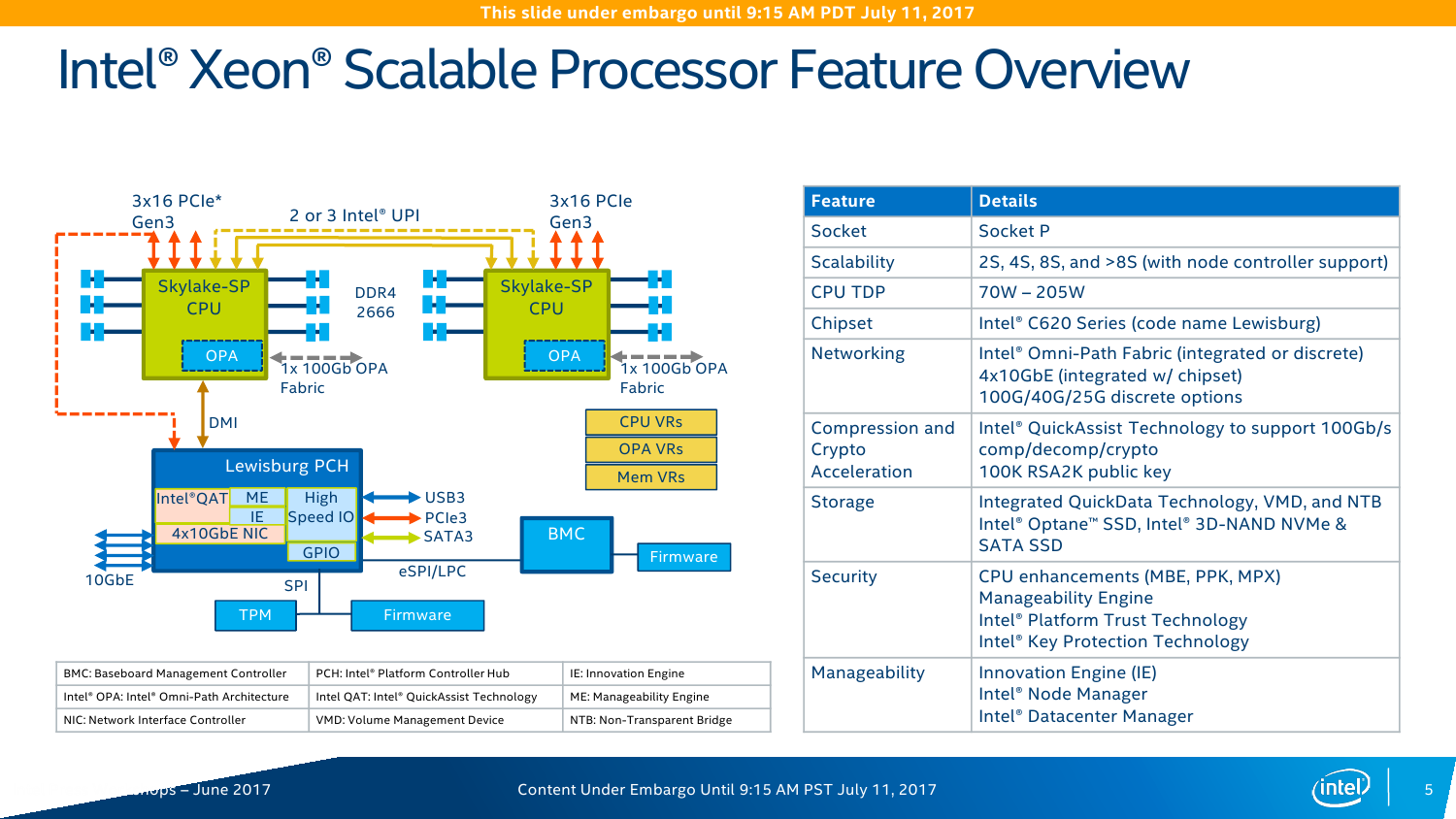
Кодовые имена для новых серий Xeon были известны уже давно: Platinum, Gold, Silver и Bronze. Можно было бы подумать, что современных серий Intel Xeon всего четыре, но фактически их шесть, если считать ещё и E3v6, которые являются лишь модификацией настольных моделей Intel Core Kaby Lake. А ведь есть ещё и E3v5 на базе Skylake. Серия Gold разделена на две неравные половинки. Все новинки различаются не только числом ядер и набором технологий. Стоит сразу отметь, что есть модели с новыми индексами: F означает наличие встроенного контроллера Intel Omni-Path, M указывает на поддержку большего объёма RAM (до 1,5 Тбайт на сокет вместо стандартных 768 Гбайт), а литерой T помечаются специальные версии CPU, которые «дружественны» стандарту NEBS для работы в экстремальных условиях — они более устойчивы к температурным нагрузкам и имеют более долгую гарантию работоспособности (до 10 лет).


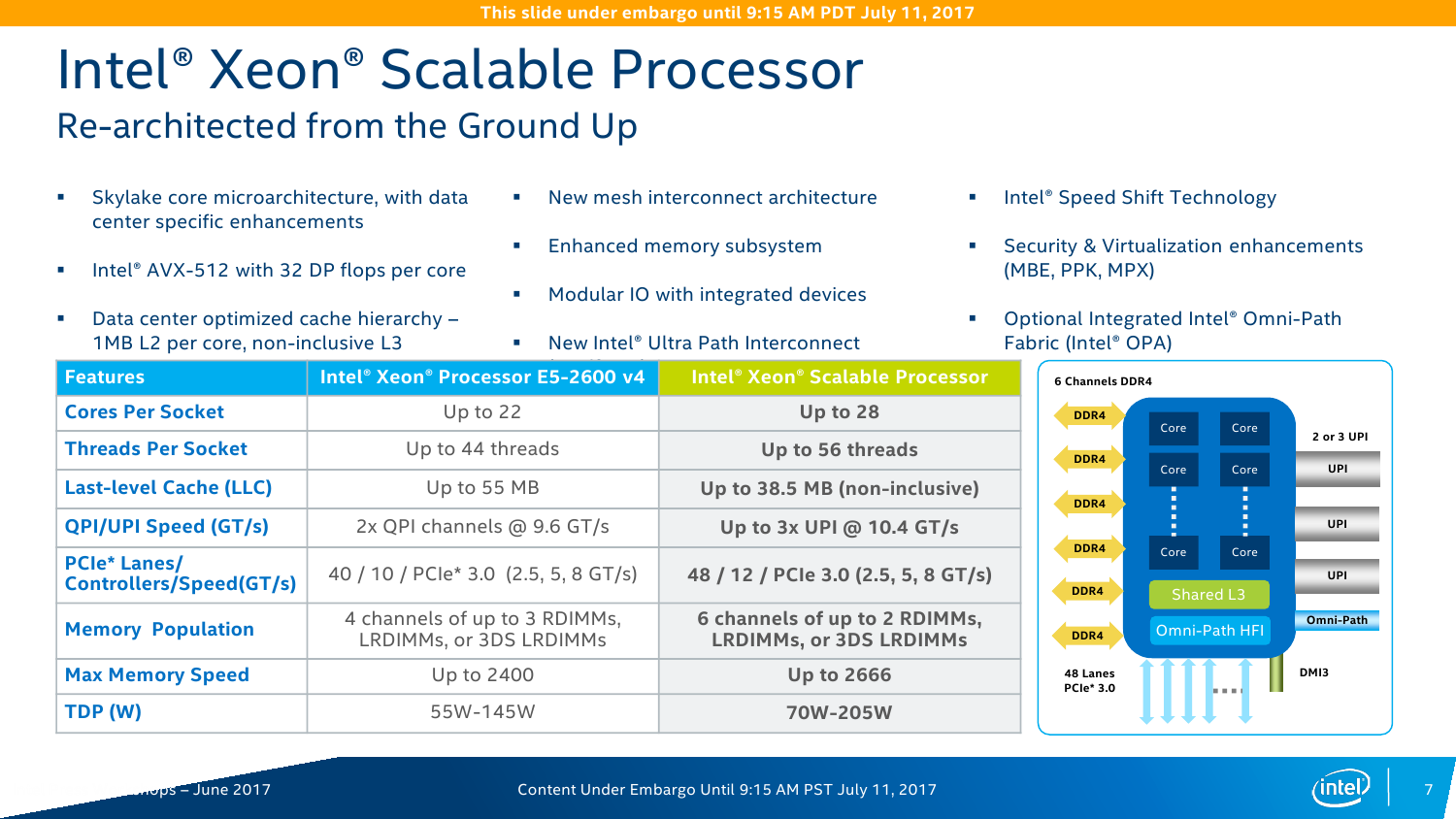
Процессоры Platinum ориентированы на высоконагруженные и критически важные системы. Они обладают максимально возможными числом ядер (до 28C/56T) и набором подсистем обмена данными (это касается внутренних и внешних шин). Вместе с большей частью серии Gold 6xxx эти процессоры можно в каком-то смысле назвать аналогами прошлых E7, хотя представитель Intel заявил, что только Platinum являются аналогами E7. Больше всего новых CPU можно условно соотнести с самой популярной серией E5 — сюда входят несколько моделей Platinum, Gold 5xxx, Silver и Bronze (этих вообще пока всего две штуки). Все Xeon Gold имеют до 22 ядер (22С/44Т), а Silver — до 12C/24T. Процессоры Bronze вовсе не поддерживают Hyper-Threading и могут иметь до 8 ядер, то есть фактически уже заходят на территорию Xeon E3. Ах да, 32-ядерных моделей не будет.


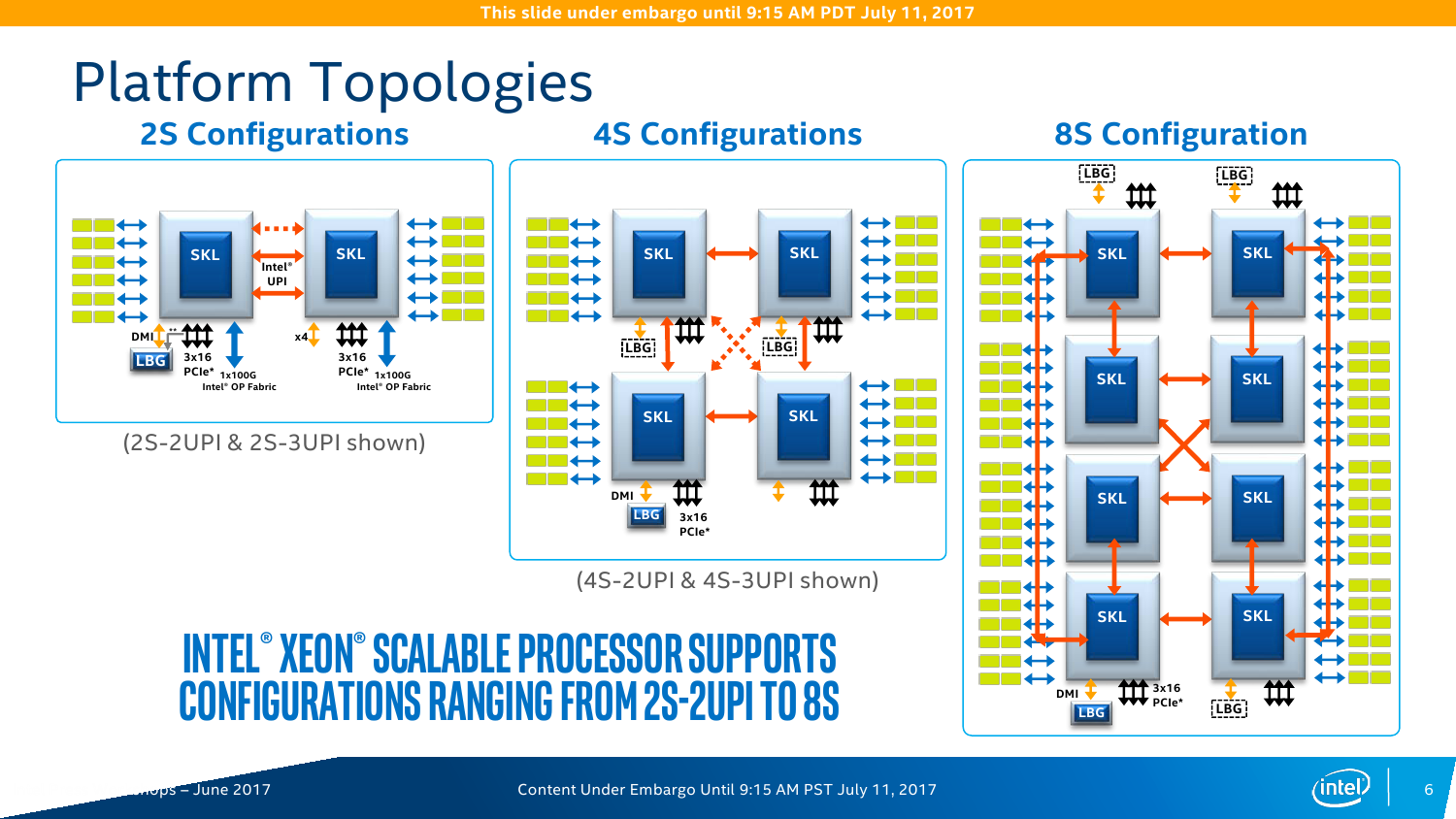
На этом отличия не заканчиваются. Intel Xeon Platinum позволяют объединить до 8 процессоров и имеют три линии шины UPI (о ней чуть позже), поддерживают память DDR4-2666, AVX-512 и возможность одновременного исполнения двух 512-бит FMA-инструкций. Xeon Gold 6xxx имеют всё то же самое, но позволяют объединить до 4 процессоров. Процессоры Xeon Gold 5xxx, Silver и Bronze имеют уже 2 линии UPI и выполняют лишь по одной 512-бит FMA за раз. Intel Xeon Silver и Bronze можно использовать лишь в двухсокетных конфигурациях, а Bronze к тому же официально умеет работать только с памятью DDR4-2133. Две последних серии предназначены для малых и умеренных нагрузок. Впрочем, сама Intel разделяет новинки на две большие части: с максимальной мощностью (во всех смыслах) и с оптимизированной производительностью на ватт.

Микроархитектура Intel Xeon Skylake-SP
Базовая структура каждого ядра Xeon Skylake-SP осталась ровной той же, что и у обычных Skylake. Однако сама Intel в презентации отмечает пару изменений. Во-первых, объём L2-кеша достигает 1 Мбайт путём прибавки 768 Кбайт, которые фактически находятся не в самом ядре, а рядом. L3-кеш имеет «некруглый» объём 1,375 Мбайт на ядро. Кеш неинклюзивный – L2 заполняется напрямую из RAM, и лишь затем ненужные линии вытесняются в L3. Общие для нескольких ядер данные хранятся в L3. При этом есть один неявный нюанс — объём L3 зависит не только от числа ядер. У некоторых моделей есть отдельное упоминание о его размере. Например, L3-кешем на 24,75 Мбайт могут оснащаться модели с 8 и 12 ядрами. Ещё более существенный разрыв виден у вариантов на 6 и 12 ядер, которые, тем не менее, имеют кеш на 19,25 Мбайт. Но в общем и целом основной упор сделан именно на работу с кешем L2. А набортная eDRAM и вовсе исчезла. Такая организация выгоднее во всех смыслах: и в плане простоты реализации, и в плане снижения частоты промахов L2 примерно при том же уровне промахов L3, как утверждает сама Intel. В целом же структура Skylake-SP аналогична таковой в настольных Skylake-X.
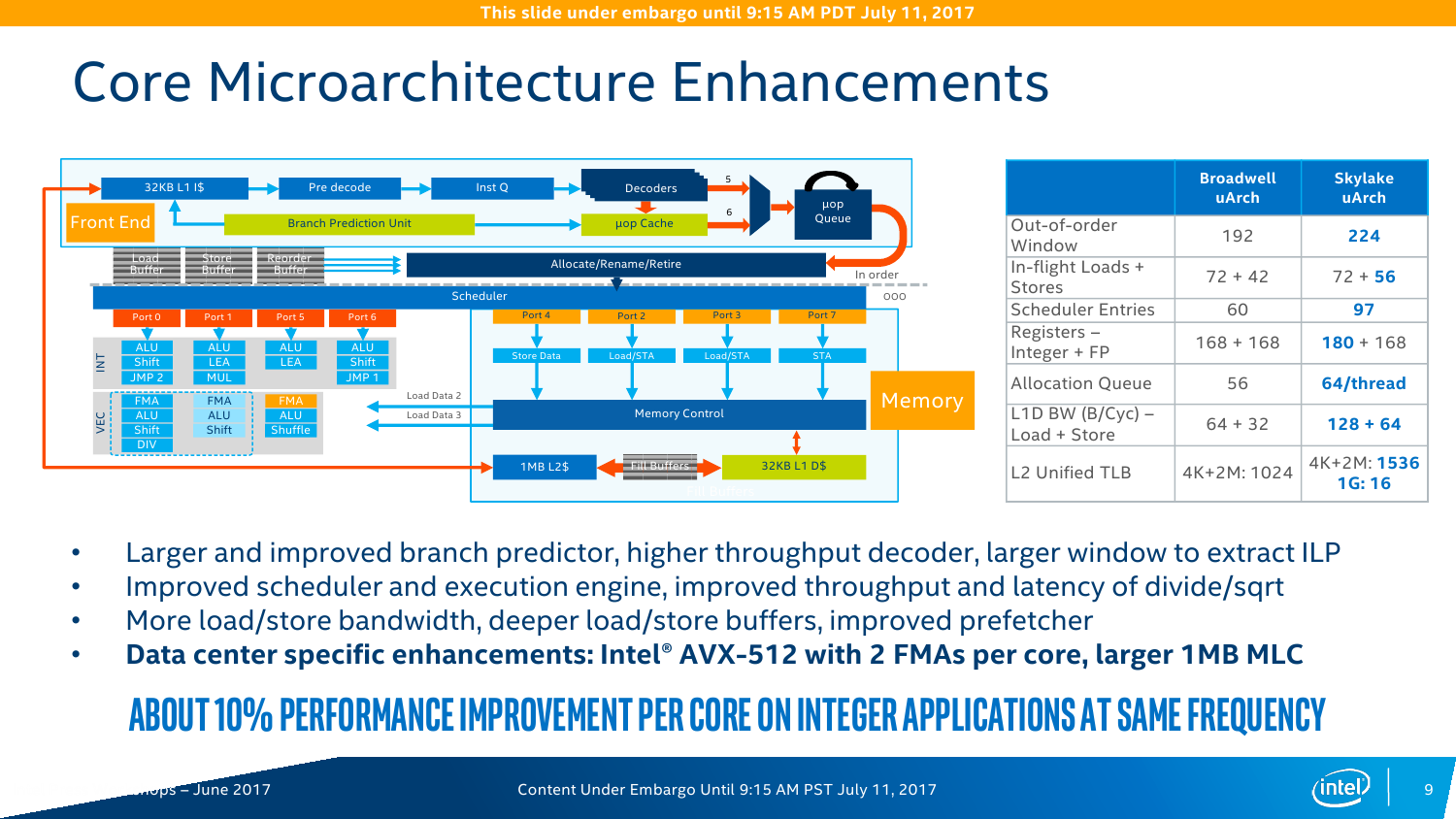
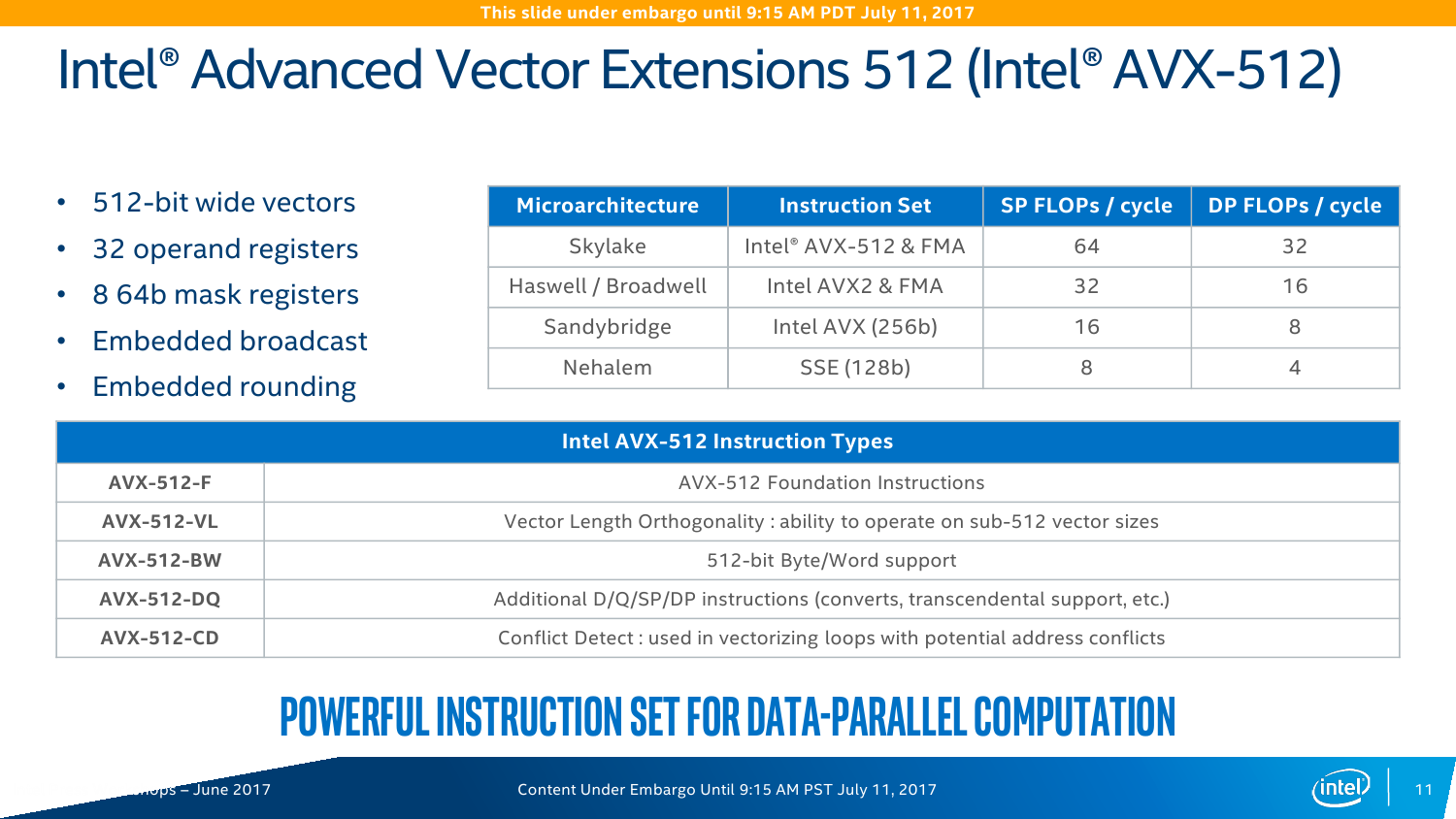
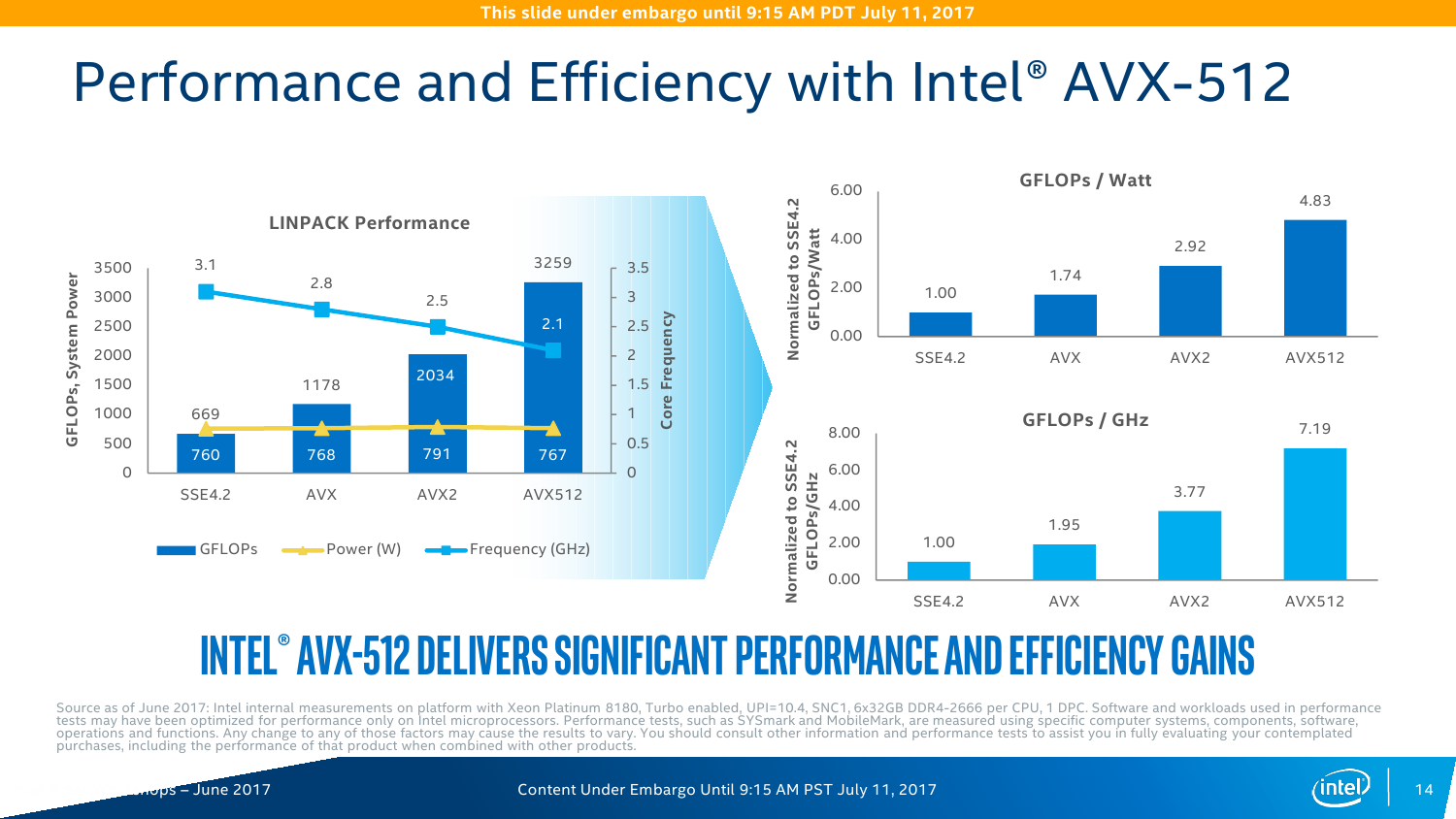
Во-вторых, к ядру дополнительно «прилеплен» блок AVX-512. Собственно, Port0 и 1 на пару могут выполнять одну такую инструкцию, плюс Port5 сам по себе умеет работать с одной AVX-512/FMA. ВМ тоже могут использовать их. И да, видимо, упомянутая выше возможность исполнения одной или двух FMA-инструкций имеет исключительно маркетинговый характер. Кроме того, базовая и турбочастота каждого ядра разнится и зависит от того, какой тип инструкций сейчас исполняется — с тяжёлыми AVX2/AVX-512 или без оных. Формально с приходом 512-битных инструкций производительность увеличивается в два раза по сравнению с прошлым поколением, то есть до 32 flops на такт при двойной точности. Это в сравнении с прошлым поколением, но по факту средний цикл жизни CPU в дата-центрах составляет минимум 3-4 года, так что на фоне старых процессоров прирост ещё значительнее. Правда, тут есть некоторое лукавство — AVX-512 нужны далеко не всем приложениям. А ПО, оптимизированное для Broadwell, без перекомпиляции в среднем получит +10% скорости на ядрах Skylake-SP. Как тут не вспомнить заветные +5% на поколение, которыми не первый год попрекают настольные CPU Intel.

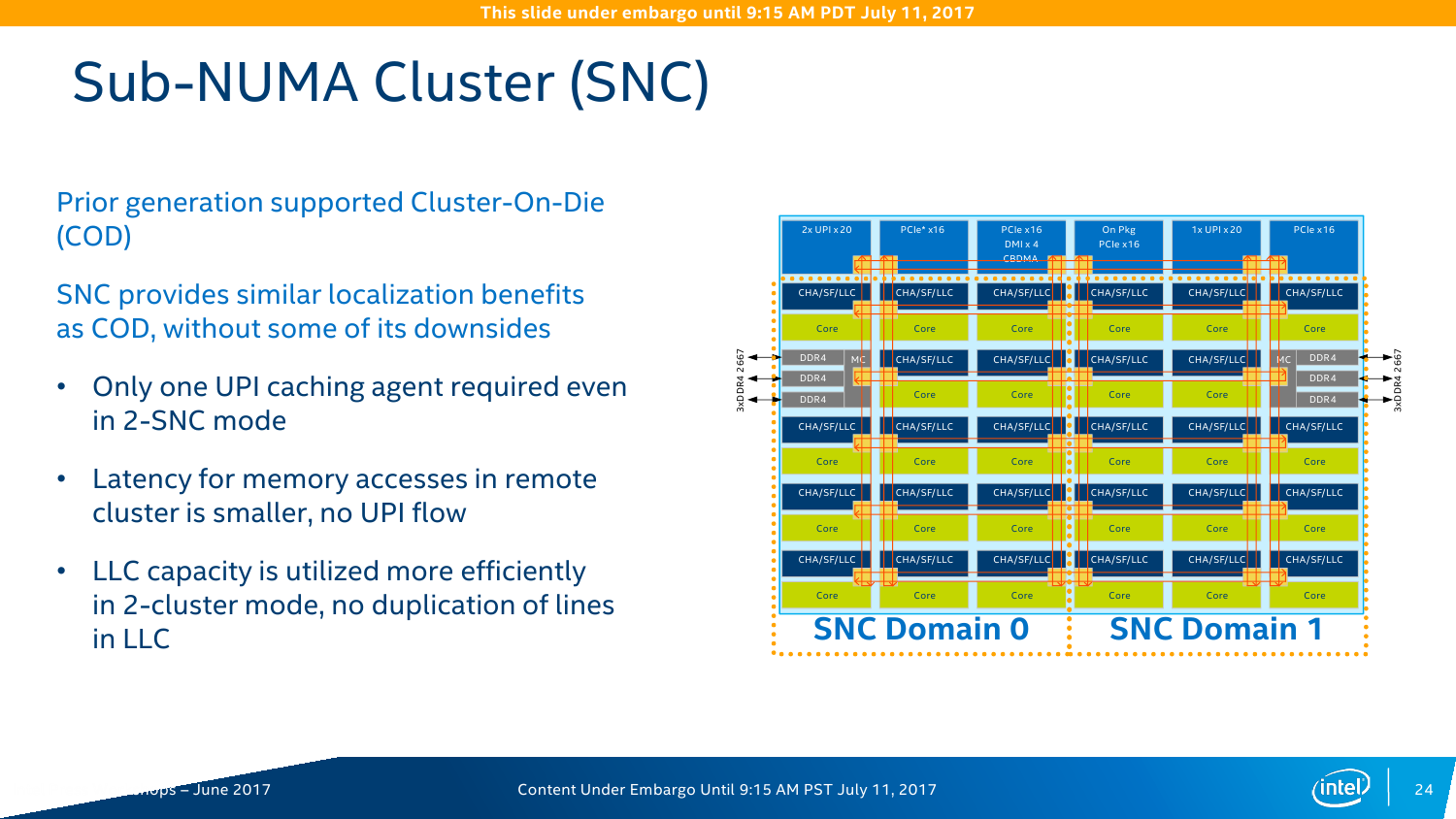
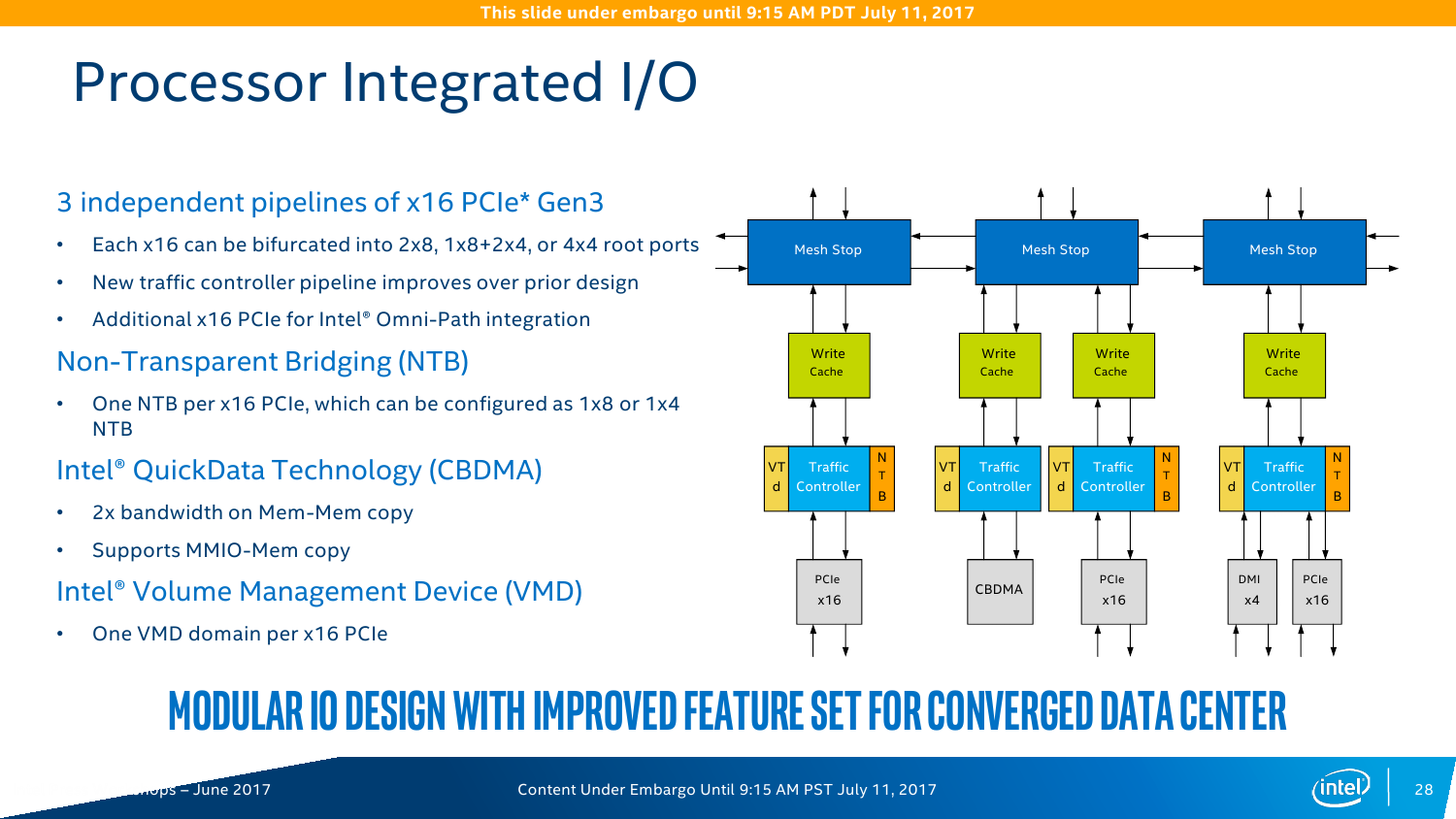
На практике заявленный средний прирост чистой производительности при оптимизации под Skylake-SP ещё выше — в среднем в 2,2-2,3 раза. Дополнительные проценты обеспечивает смена топологии и строения шин. Главное, конечно, — это смена внутренней шины с кольцевого типа на mesh-сетку. Теперь у каждого ядра есть собственный блок, который включает системный агент, L3-кеш и фильтр снупинга (конкретный алгоритм реализации когерентности не уточняется). При обращении к другим узлам сети запрос идёт сначала по, условно говоря, оси ординат, а потом по оси абсцисс. Аналогичная схема используется в Xeon Phi KNL. Потенциально такая топология вкупе с новыми кешами позволяет заметно увеличить эффективность межъядерного взаимодействия и работы с памятью, особенно для ВМ и тяжёлых расчётов. Кроме того, при такой схеме из одного CPU легко получаются два NUMA-узла (КП тоже два), которые нужны для ряда HPC-задач. В этом случае и трафик внутри mesh-сети снижается, и задержка растёт чуть медленнее.
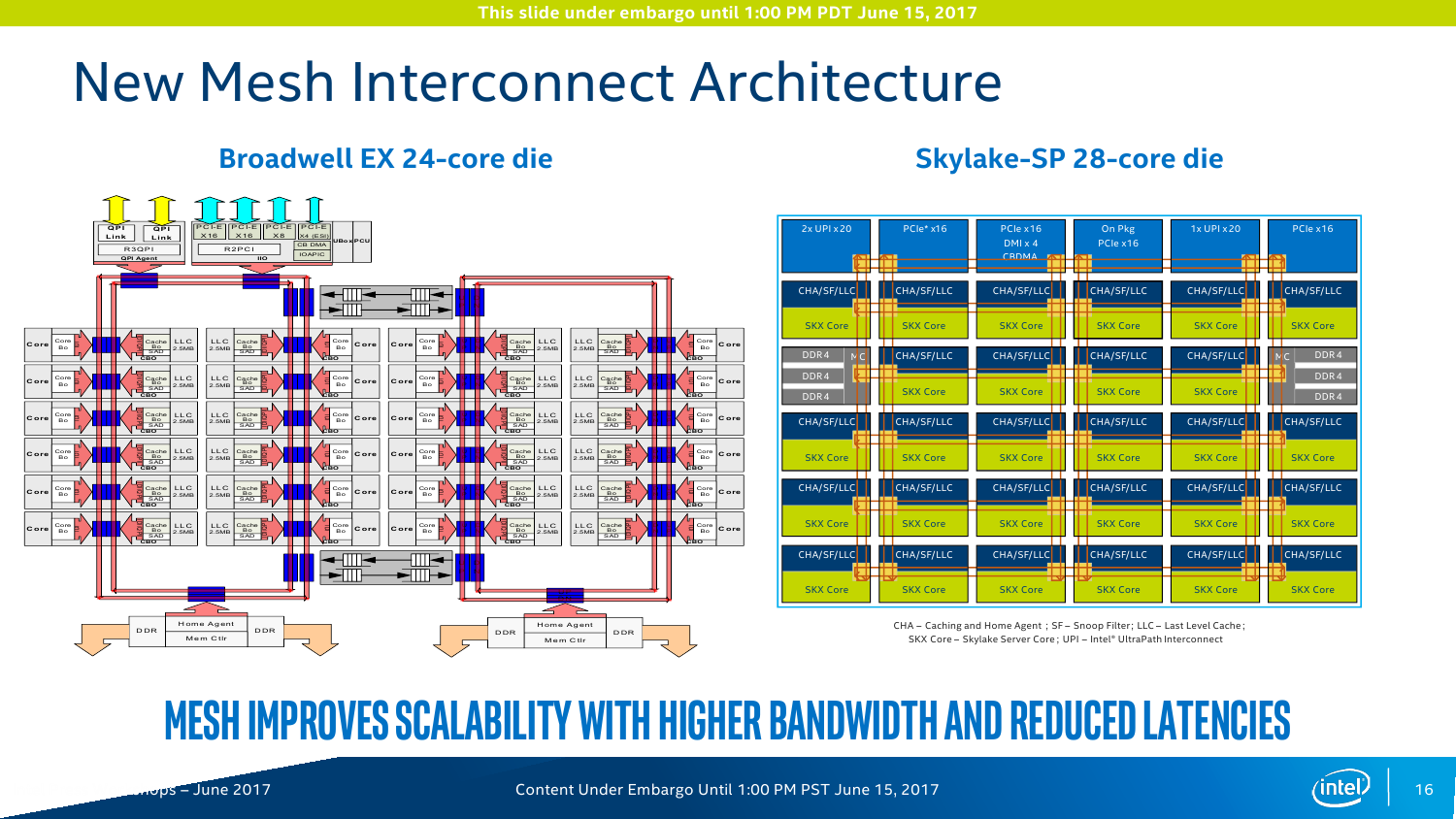
В кремнии, как обычно, будет три варианта кристаллов: XCC, HCC и LCC, то есть eXtreme, High и Low Core Count. Однако разделение есть смысл делать не только по числу ядер, но и по возможностям uncore-части. Так, например, среди CPU серии Platinum есть 4-ядерные модели с полным набором возможностей платформы. С частотами и TDP всё сложно и всё просто одновременно. С одной стороны, привычно наблюдается баланс между числом ядер и базовой частотой. С другой стороны, с ходу разобраться в этом обилии SKU затруднительно. В любом случае максимальная базовая частота не превышает 3,6 ГГц, а TDP достигает 205 Вт. Да, Intel недвусмысленно намекает, что эра воздушного охлаждения заканчивается. Про турбочастоты детальной информации пока нет, но если уж говорить про энергопотребление в целом, то технология SpeedShift никуда не делась.
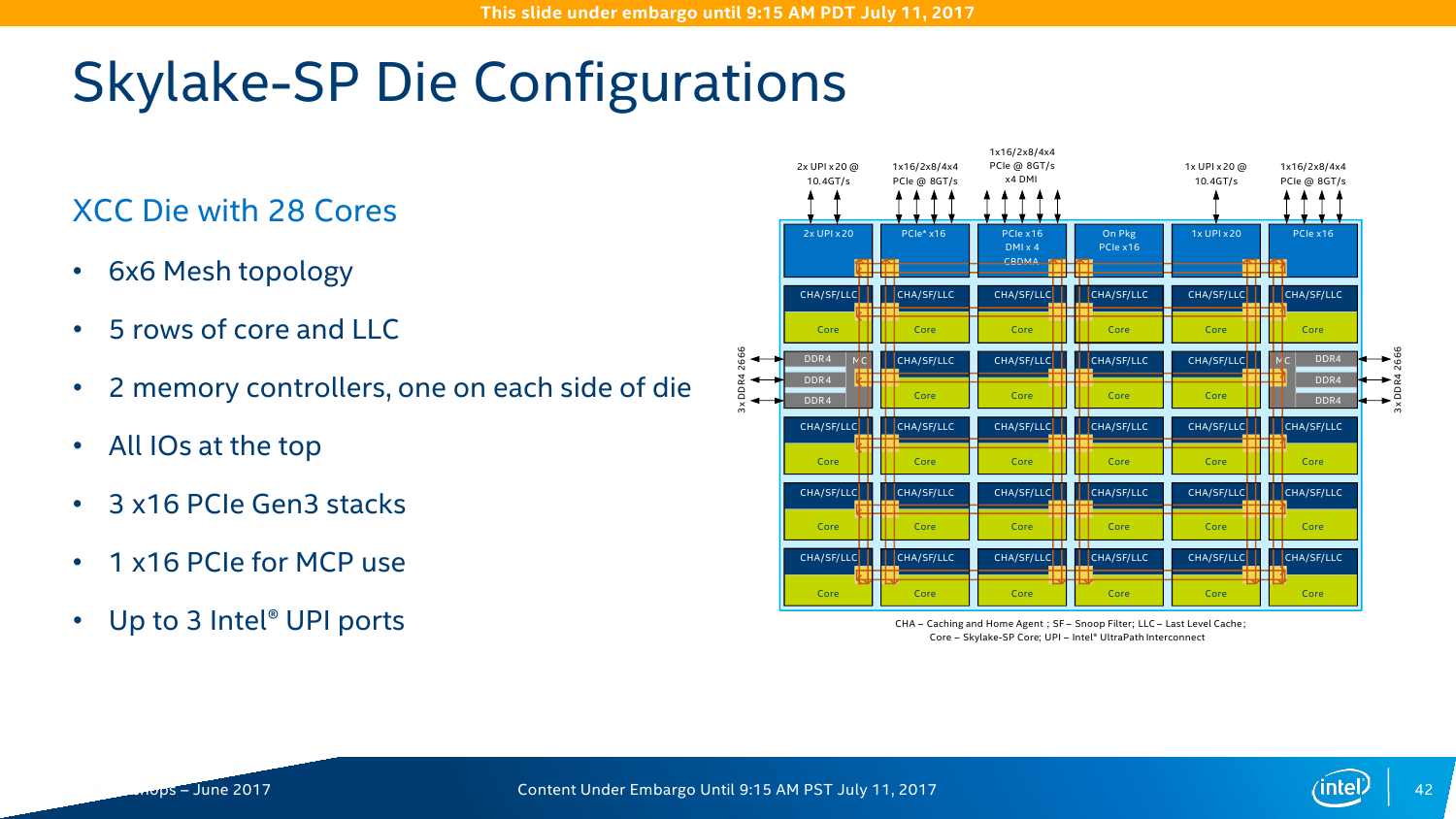
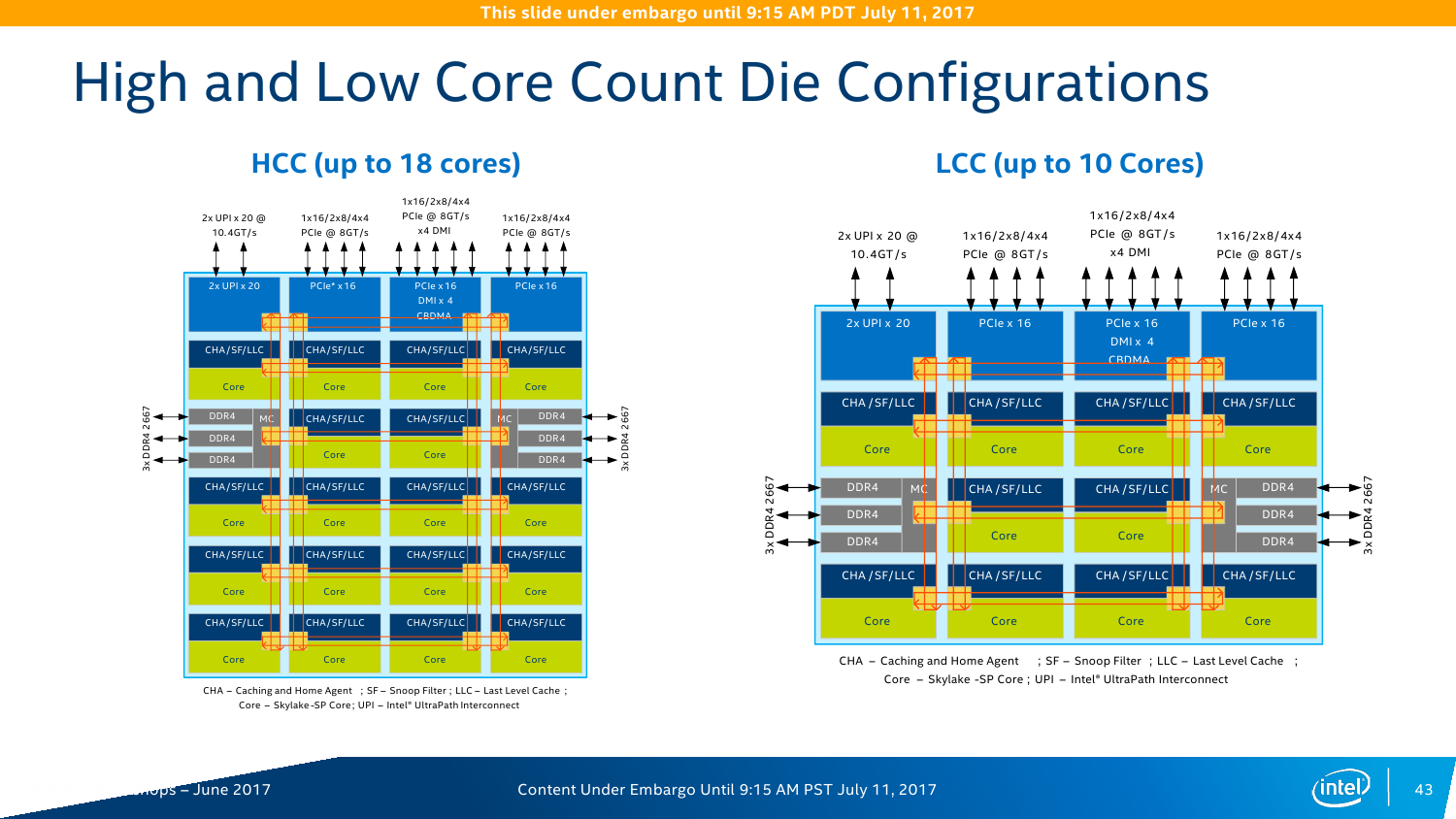
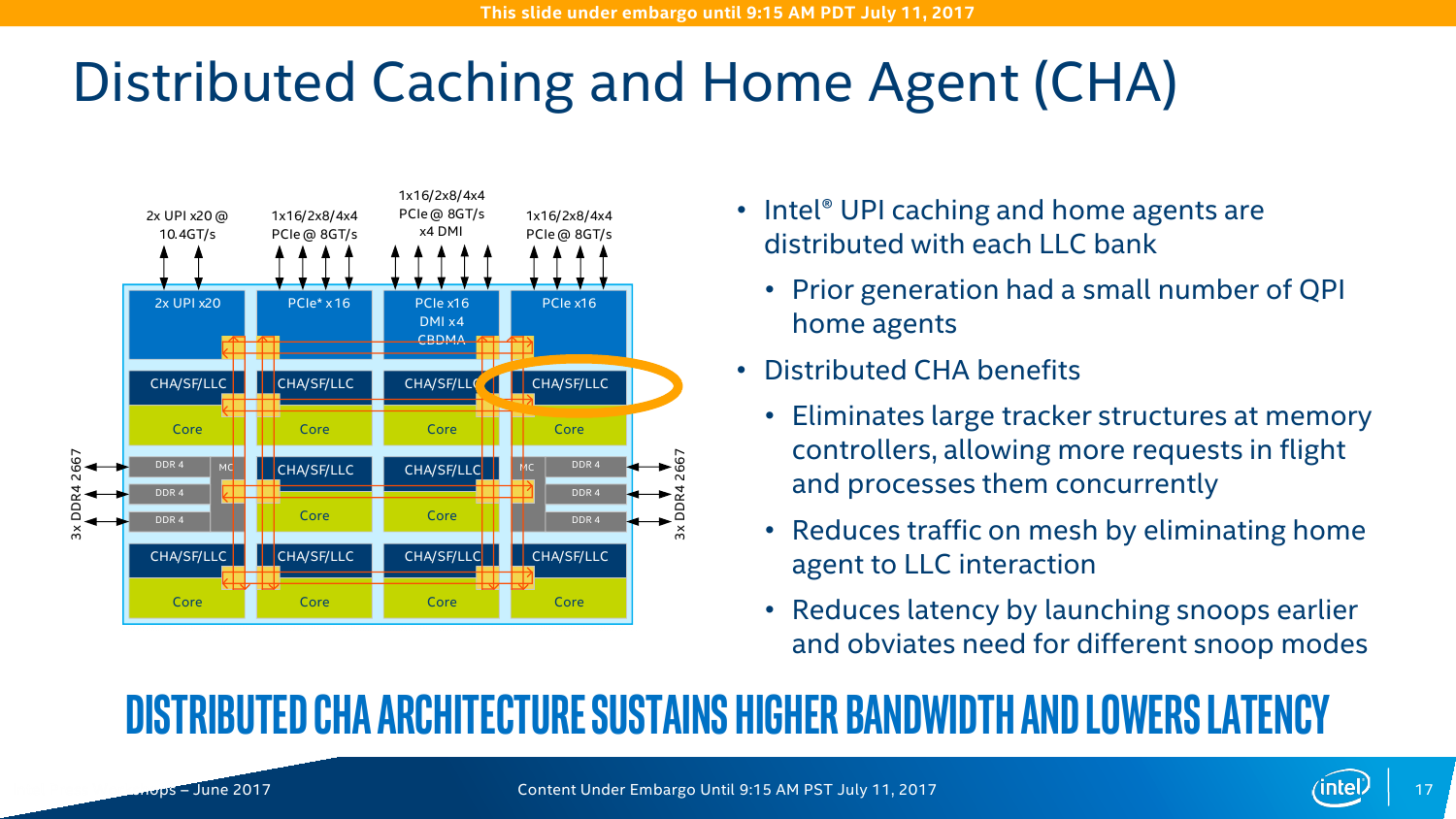
Контроллеров памяти (КП) тут два, это трёхканальные DDR-2133/2400/2666 с поддержкой некоего нового алгоритма выявления и коррекции ошибок (adaptive double device data correction, ADDDC), который умеет устранять сбои ECC-памяти. Расположены они по краям сетки, напротив друг друга. При промахе L2 параллельно инициализируется обращение к памяти и L3-кешу. Кроме того, КП на основе истории обращений пытается заранее предсказать, какие блоки памяти будут востребованы в дальнейшем. Увы, никаких деталей про маршрутизацию и работу системных агентов не приводится. КП, как и раньше, поддерживает работу с модулями памяти RDIMM, LRDIMM, 3DSLRDIMM — до двух модулей на канал, объёмом до 128 Гбайт каждый. То есть максимальный доступный объём составляет 1,5 Тбайт на сокет, однако, как говорилось в самом начале, большинство SKU поддерживает только 768 Гбайт.
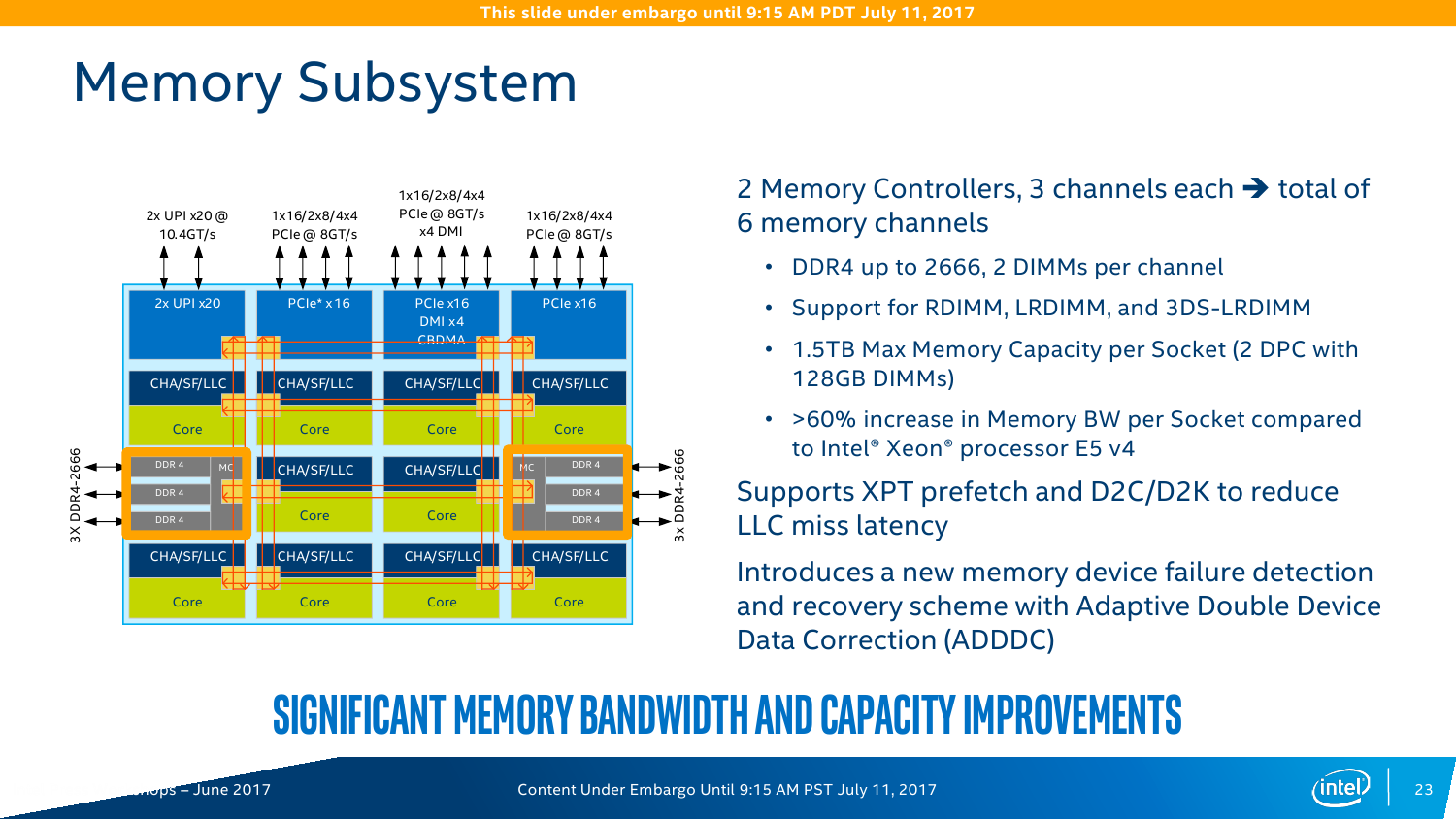
Uncore-часть
Все контроллеры внешних по отношению к самому CPU шин сведены в одну линию вверху сетки. Их тут немного: один или два блока UPI (x2 есть всегда, ещё один x1 есть у некоторых моделей CPU), два блока PCI-E x16 (в виде x16, 2x8, 1x8 + 2x4 или 4x4) и ещё один комбинированный блок с таким же набором интерфейсов PCI-E x16 + DMI x4. В процессорах с интегрированным контроллером Omni-Path есть ещё один «скрытый» PCI-E x16 для подключения самого интерконнекта. Кроме того, для связи с чипсетом помимо шины DMI можно задействовать дополнительно линию PCI-E x16, сократив таким образом и так не то чтобы совсем уж многочисленные линии PCI-E 3.0 до двух x16. На смену шине Quick Path Interconnect пришла шина UPI — Ultra Path Interconnect. Скорость передачи данных возросла незначительно, с 9,6 до 10,4 GT/s. Однако в моделях Silver и Bronze она осталась прежней. Основной упор сделан не на рост скорости, а на увеличение эффективности коррекции ошибок передачи данных и кеширования и энергоэффективность.

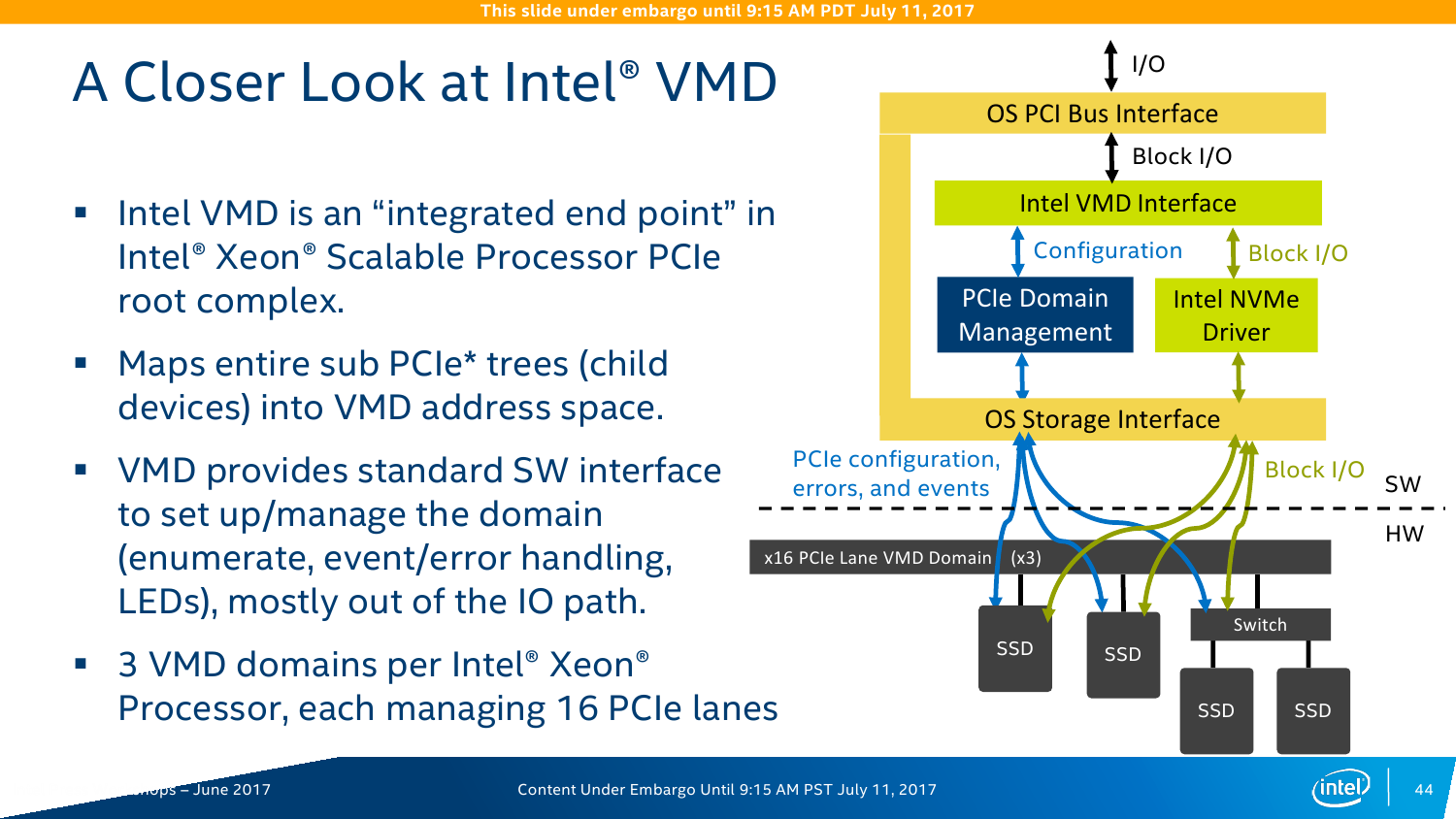
Намного более интересное и полезное нововведение — это Intel Volume Management Device (VMD). VMD является подконтроллером PCI-E, который объединяет и абстрагирует NVMe-накопители от CPU и ОС, служа своего рода мостом или прокси. То есть можно установить большее число накопителей. Кроме того, он же осуществляет мониторинг состояния SSD и управляет горячей заменой дисков. В VMD для платформы Purley доступно до 72 SSD на каждый процессор с использованием свитчей PCI-E, а вот без них число накопителей не может быть больше 12 (на каждый CPU, конечно). Сама Intel справедливо отмечает, что VMD является основой для создания программно-определяемых хранилищ (SDS, Software Defined Storage).

В сочетании с интегрированным в CPU интерконнектом Omni-Path появляется возможность, «не отходя от кассы», задействовать технологию NVMe-over-fabric для большей гибкости при работе с накопителями: «Фактически на каждом узле можно отказаться от локального хранилища и работать только с удалёнными накопителями». Ну, точнее говоря, NVMe-over-OPA, потому что в чипсете-то тоже есть сетевой контроллер. С другой стороны, CPU стал настоящей SoC — теоретически Skylake-SP может работать и без PCH. Да, интеграция всё большего числа компонентов под крышку CPU стала нормой.
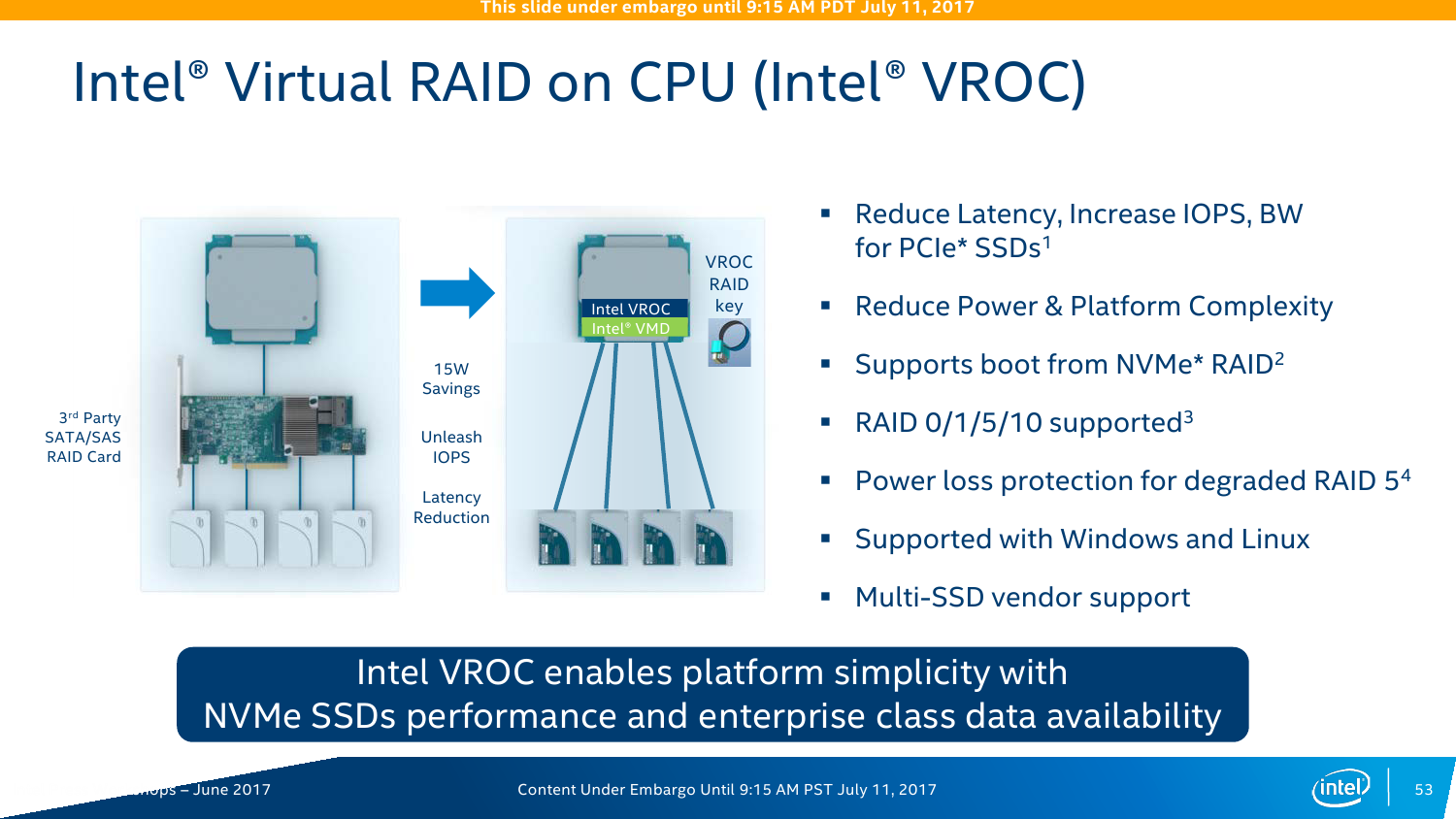
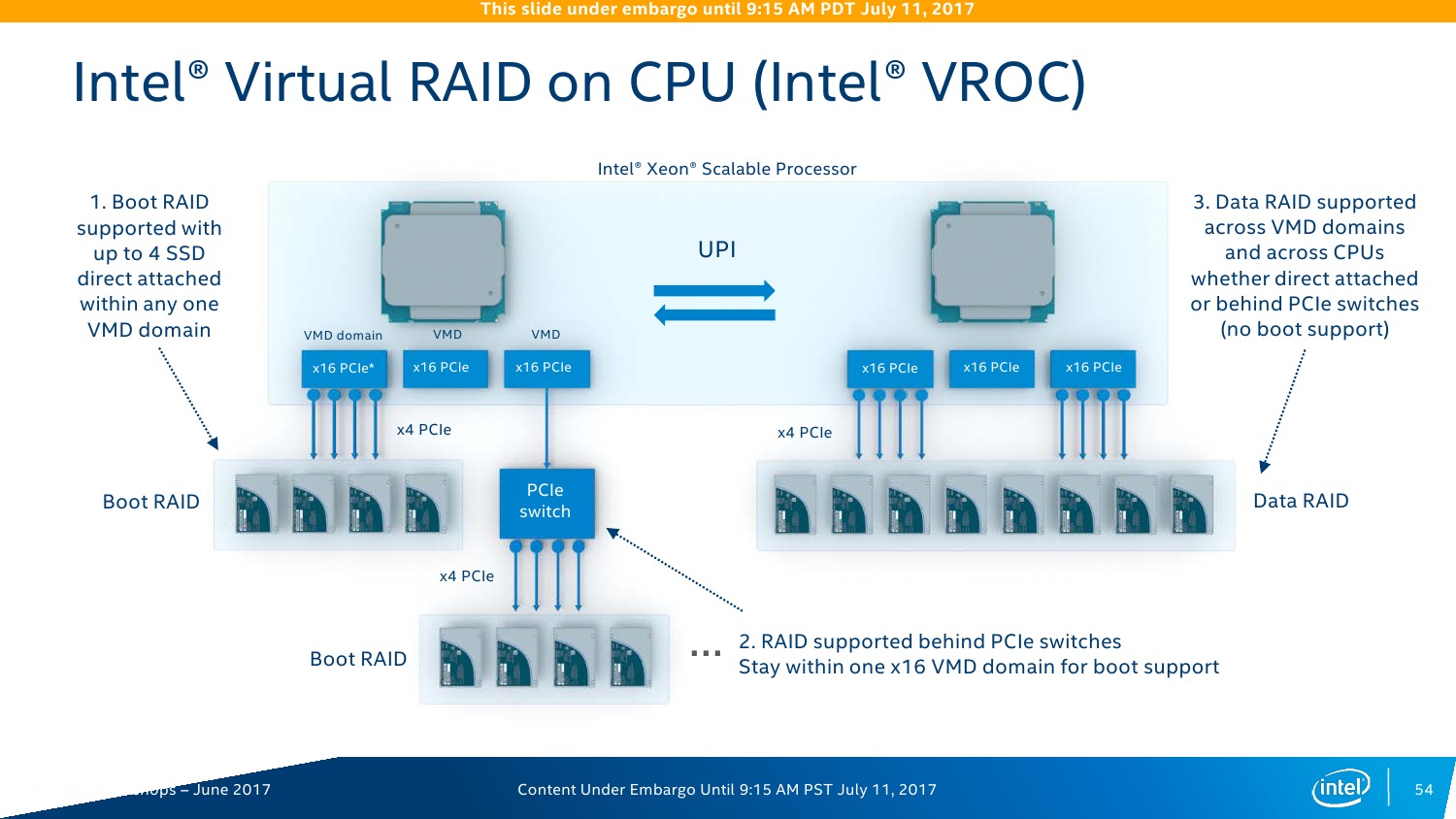
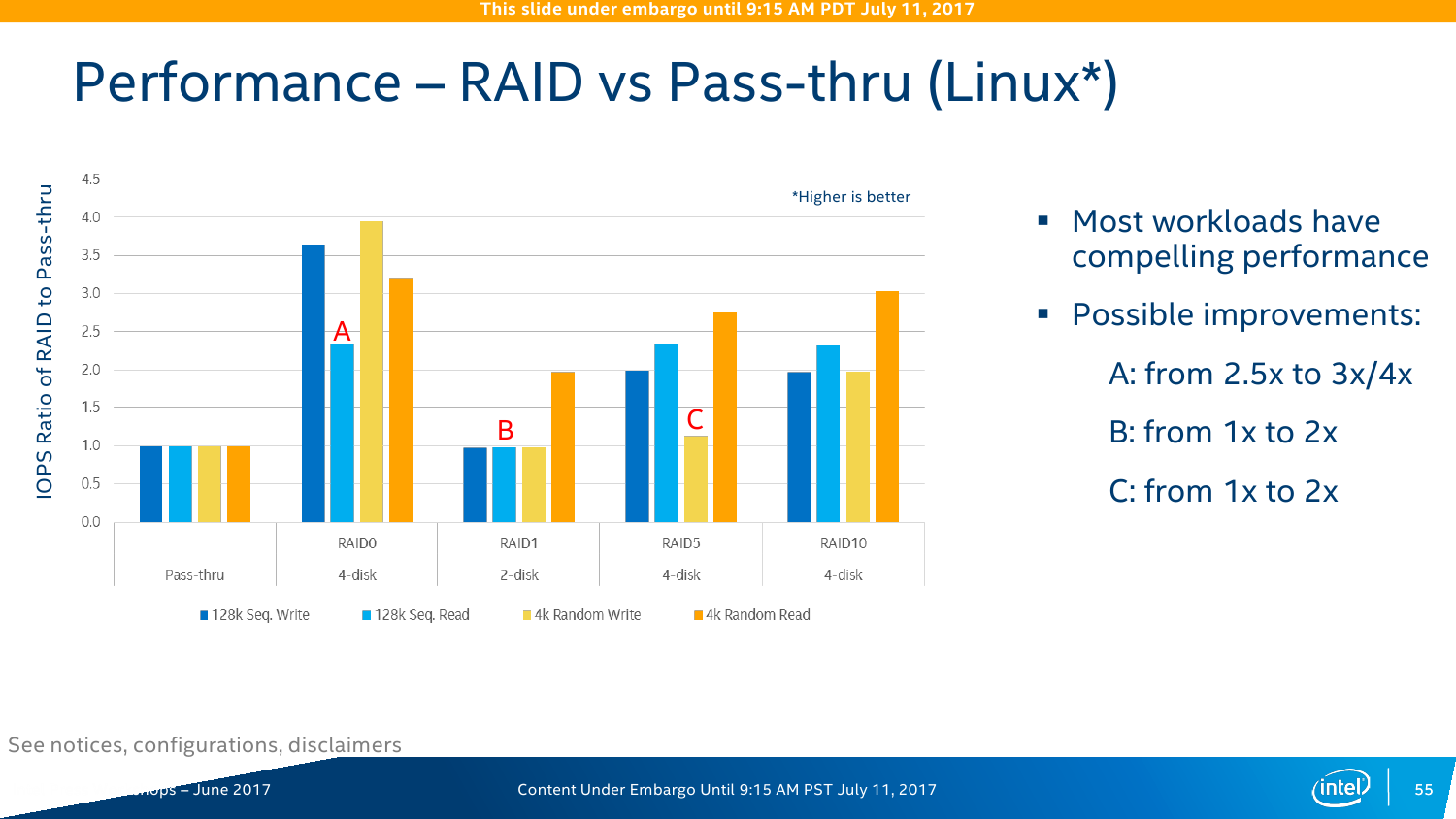
Ещё один компонент в Skylake-SP называется Virtual RAID on CPU (Intel VROC). Да, это встроенный RAID-контроллер, который поддерживает уровни 0/1/5/10 и возможность загрузки с массива (не во всех комбинациях, правда). Основная задача — увеличение скорости доступа и снижение задержки при обращении к NVMe-накопителям (посредством VMD тоже), плюс экономия электроэнергии путём отказа от внешнего контроллера. Детали строения опять-таки не приводятся, но говорится, что для работы VROC можно «отрезать» одно-два ядра CPU, которые и будут обслуживать массив. Явного ограничения на тип SSD (в том числе на марку) нет. Эта опция, скорее всего, будет необязательной и за неё придётся доплачивать.
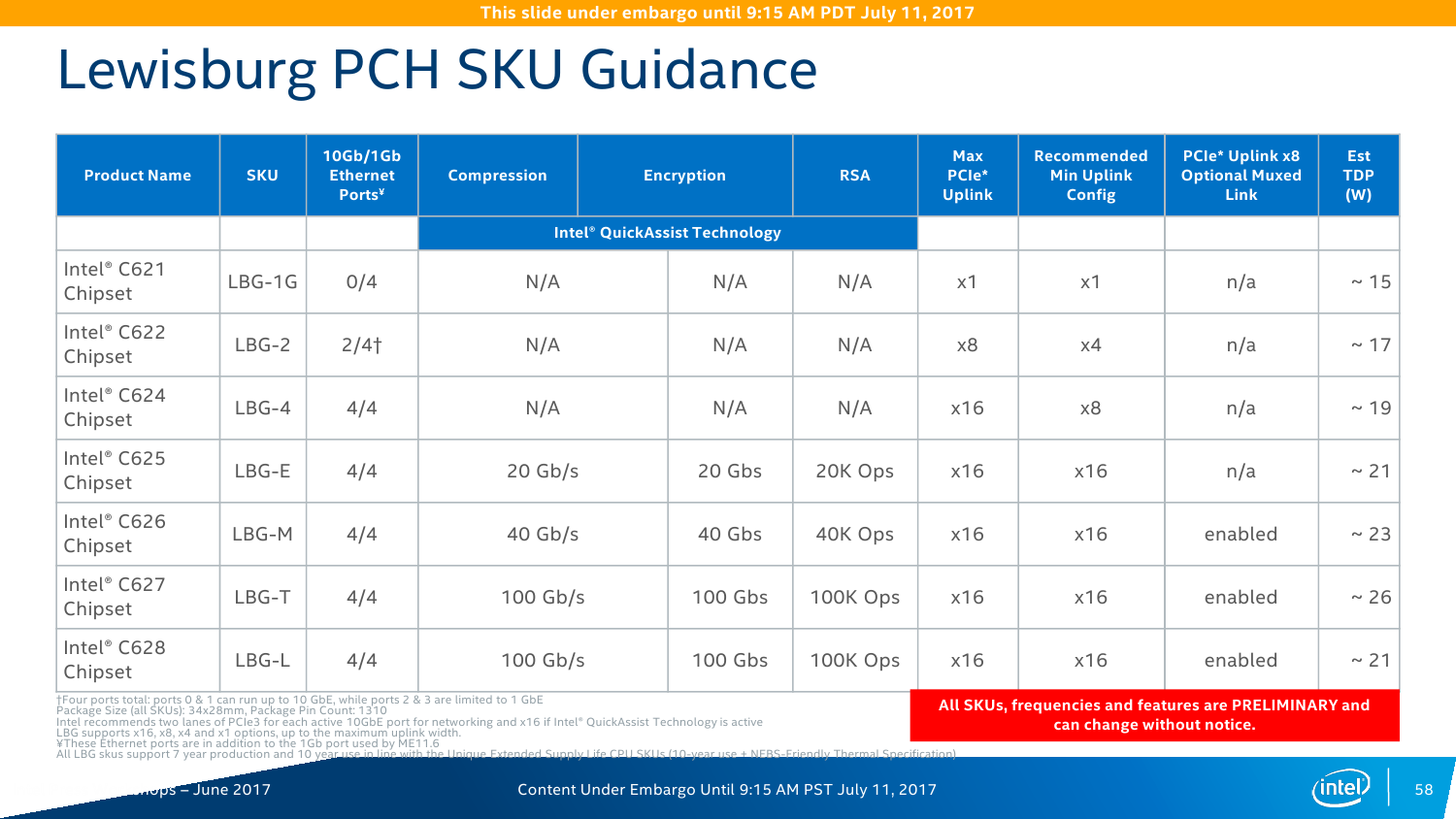
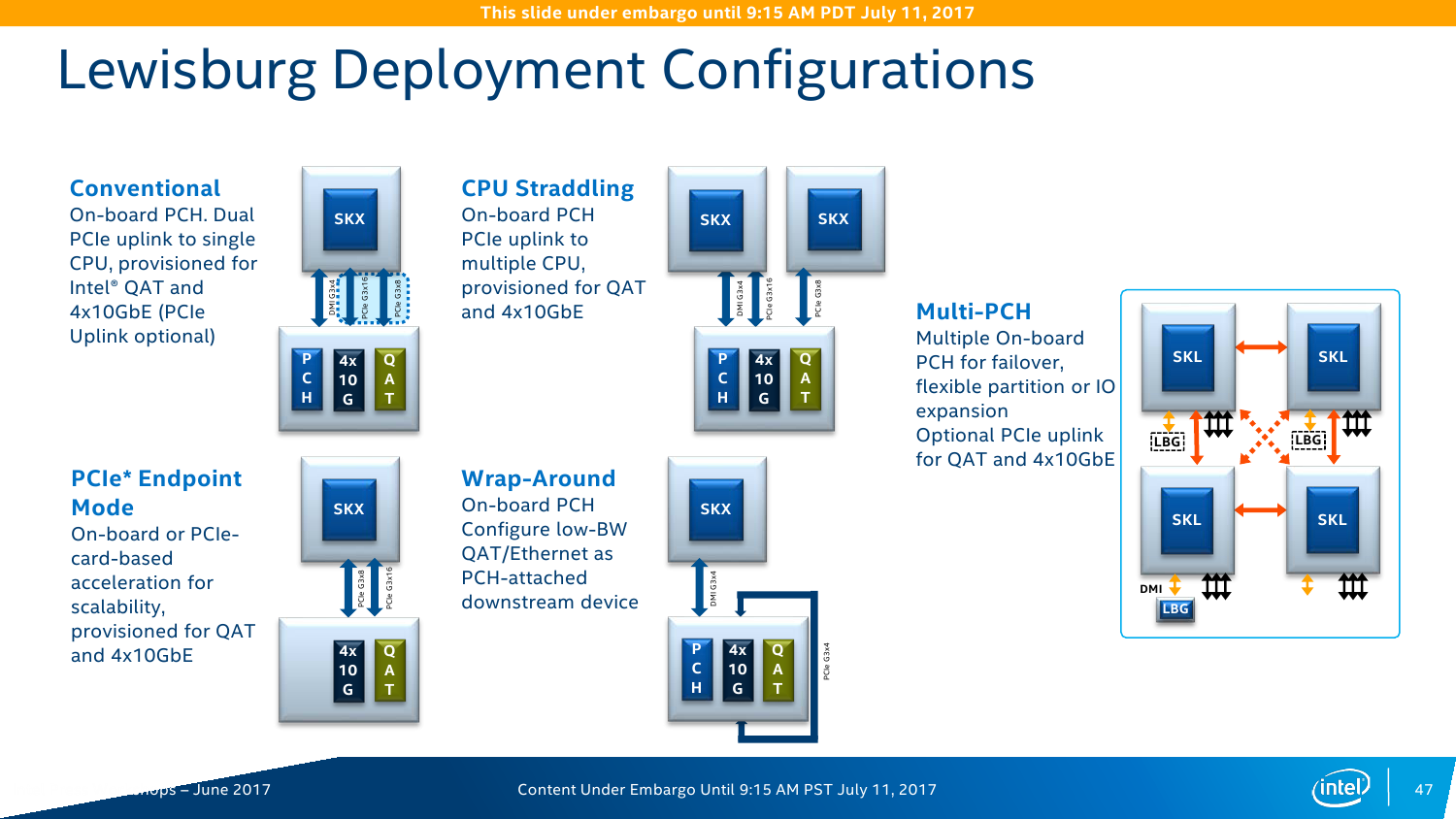
Серия чипсетов C620 включает 7 моделей, которые различаются в первую очередь сетевыми возможностями — набором Ethernet-портов и функций Intel QuickAssist Technology (QAT). Все они имеют поддержку до 14 портов SATA3 и USB 2.0, до 10 портов USB 3.0 и до 20 PCI-E x8 и/или x16 (конкретная разбивка не уточняется). Поддержки SATA Express нет, но есть NVMe и Intel Rapid Storage Technology enterprise (RSTe). Также чипсет теперь умеет работать с модулями TPM 2.0. Среди других нововведений – новая низкоскоростная шина eSPI и более высокая энергоэффективность чипсета в целом. Кроме того, есть поддержка Node Manager 4.0, который занимается мониторингом и управляет питанием, энергопотреблением и производительностью платформы в целом. Все чипсеты Lewisburg будут производиться в течение семи лет.
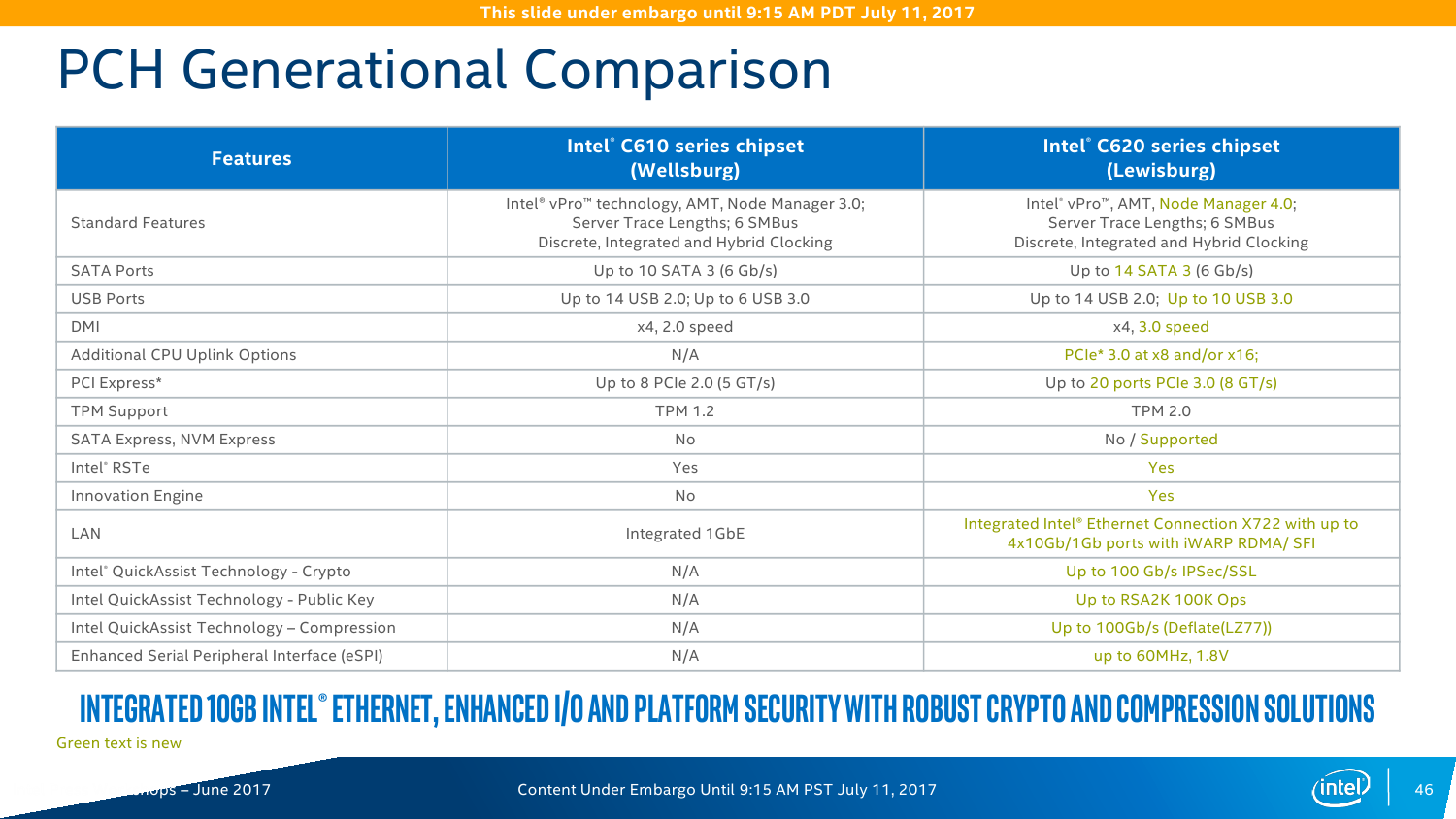
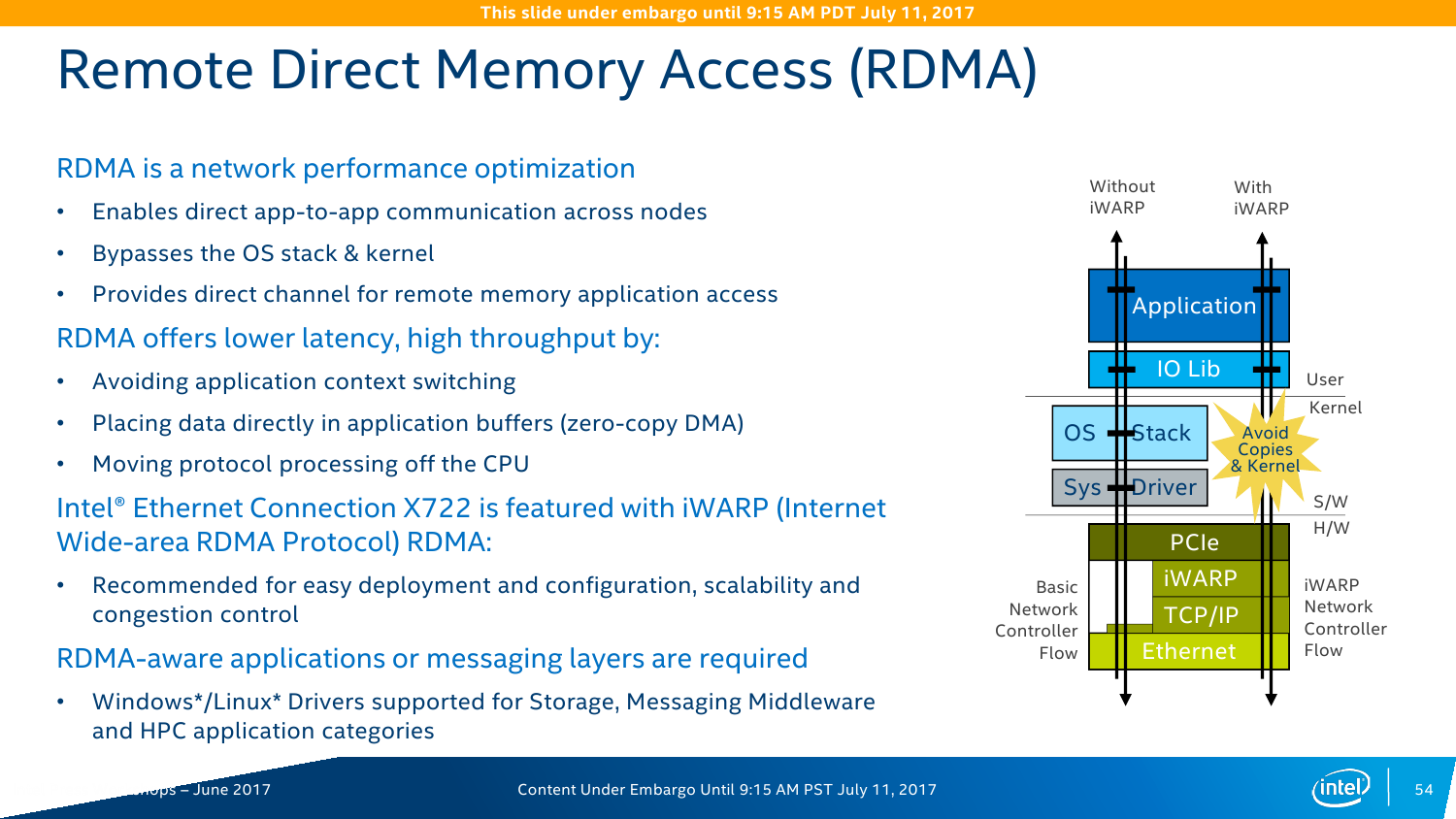
Конечно, самое важное изменение касается работы с Сетью. В C620 появился новый сетевой контроллер Intel X722, который предлагает до четырёх 10-гигабитных подключений. В чипсете находится только MAC-уровень, а конкретные физические порты выбираются уже производителем платы (пока есть только медь). X722 поддерживает различные варианты разгрузки (offload) для систем виртуализации, а также RDMA-протокол iWARP. Выбор последнего обусловлен, по словам Intel, тем, что для его использования не требуется дополнительных вложений в текущую сетевую инфраструктуру.

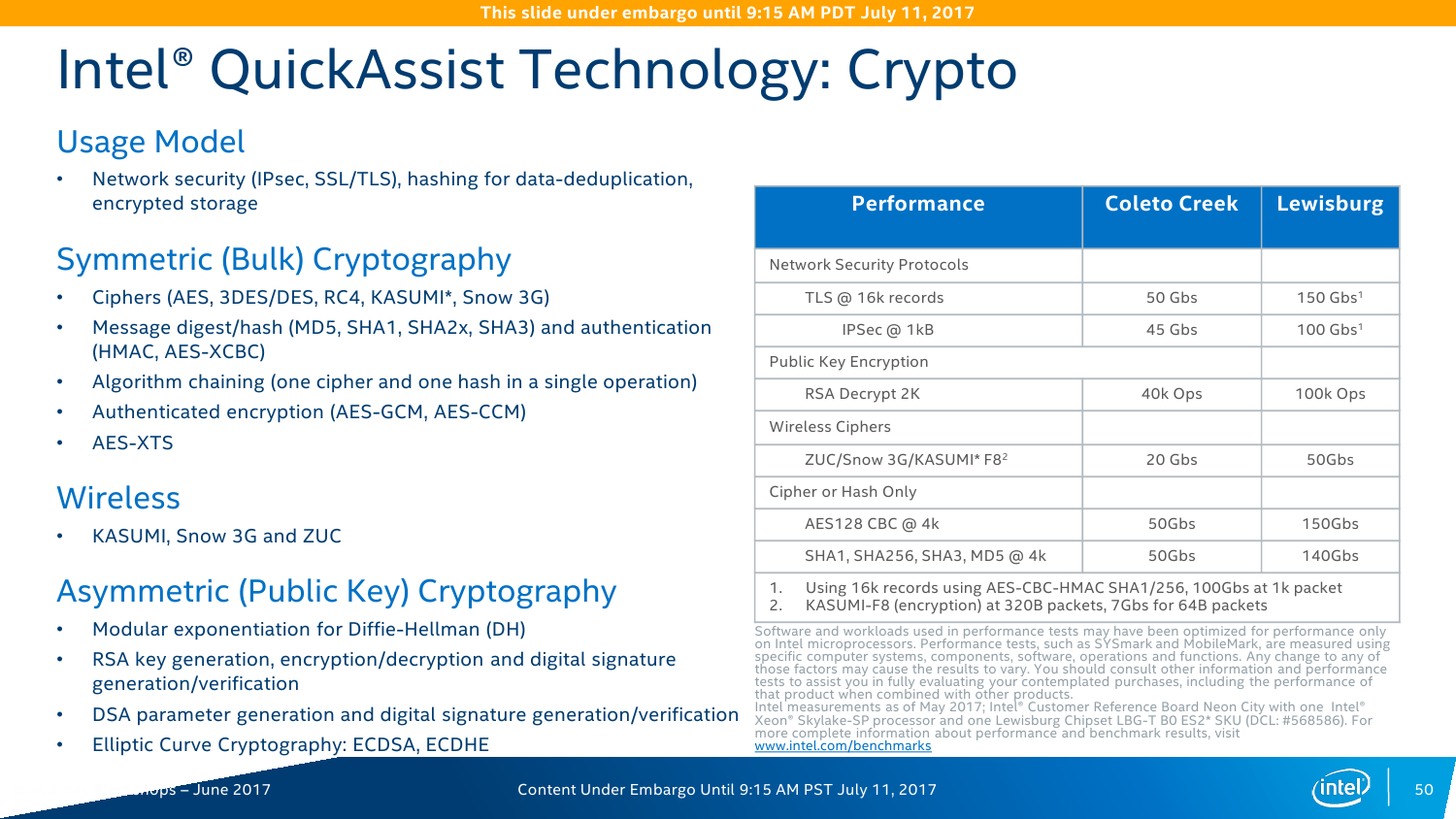
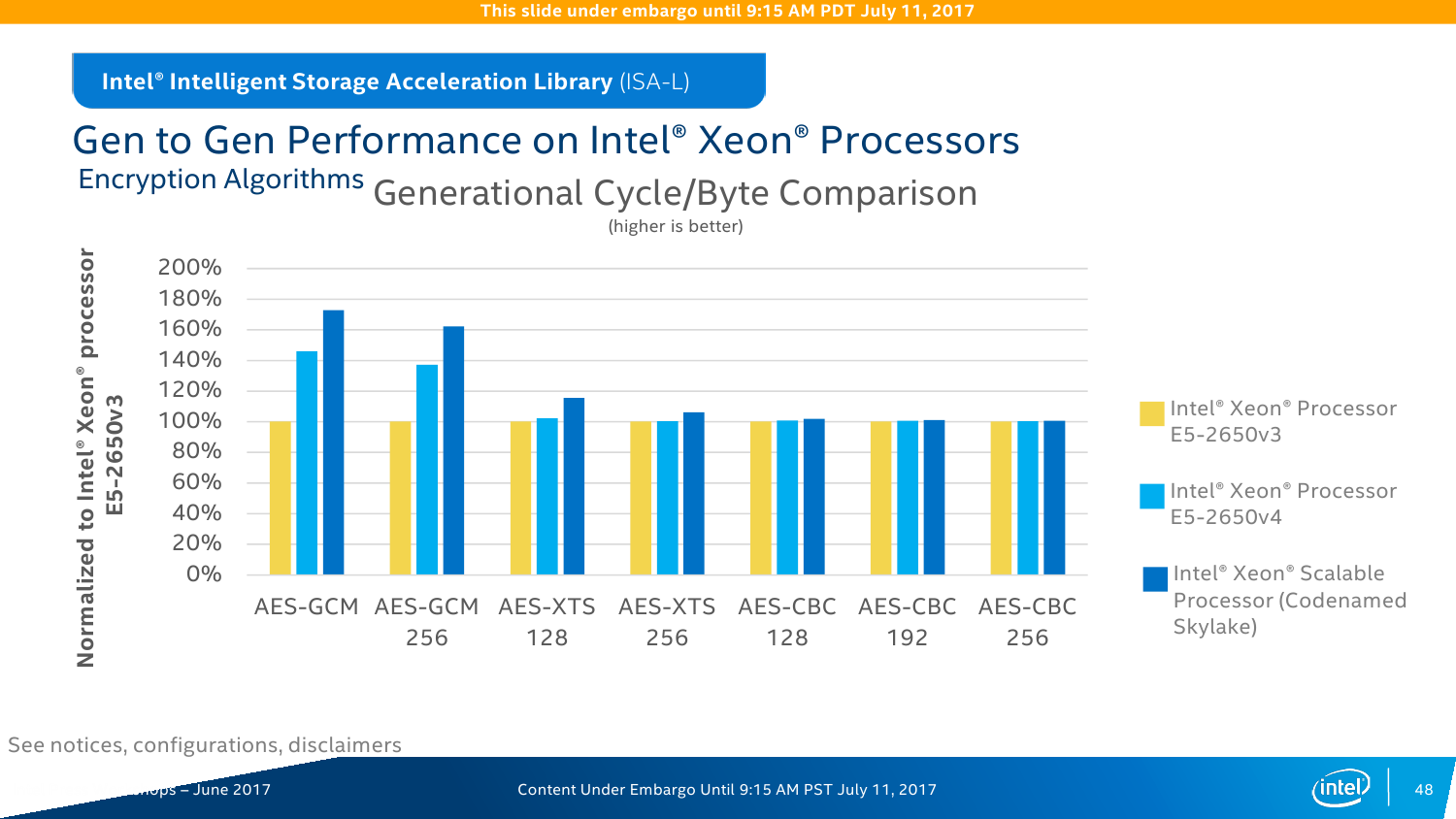
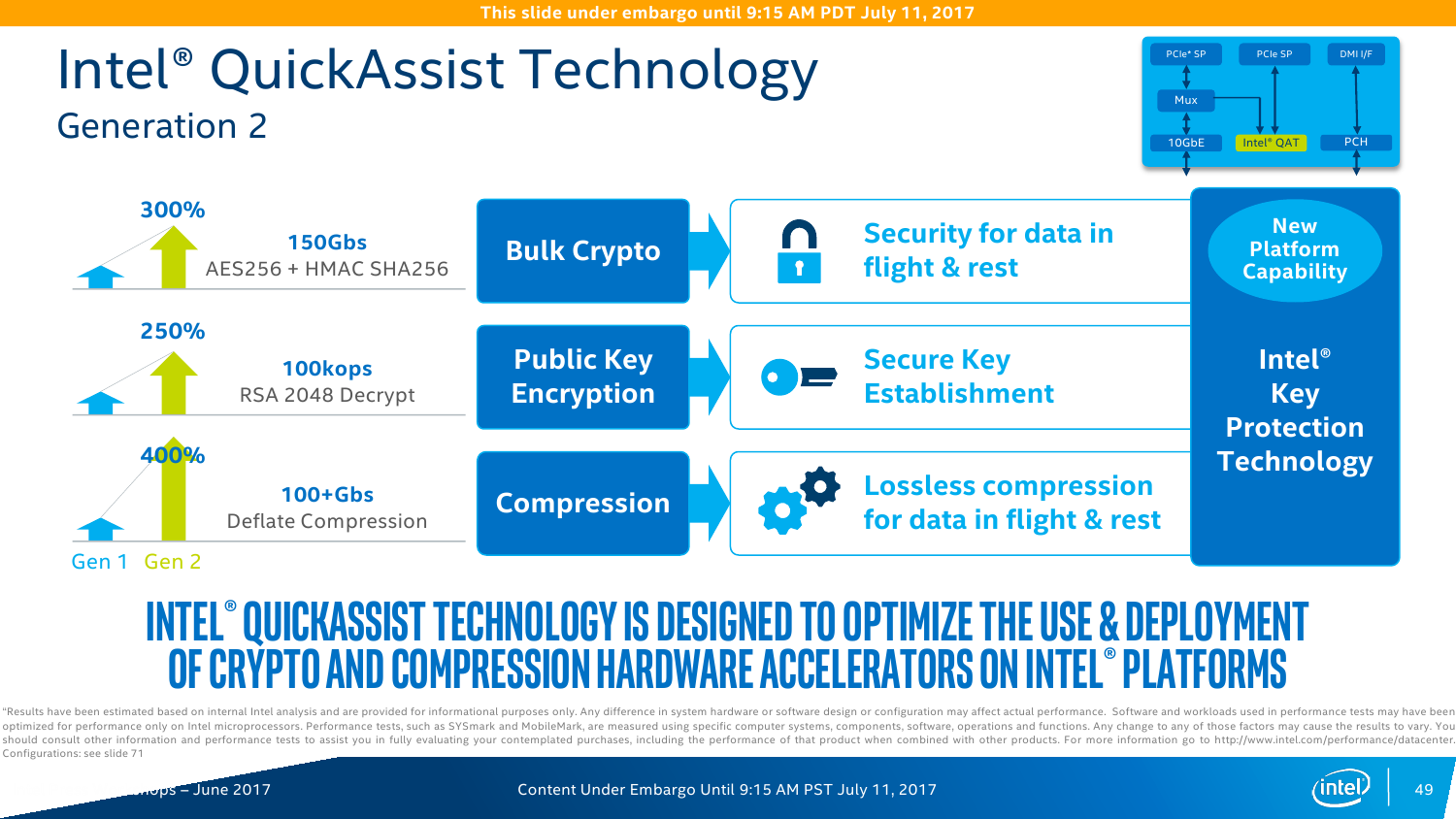
Intel QuickAssist Technology (QAT) — это ускоритель для работы с компрессией и криптографией. Аппаратно поддерживается целый набор алгоритмов шифрования и хеширования. Ранее он был доступен в виде отдельных чипов и плат, а теперь перебрался в чипсет. Разработчики обещают следующий уровень производительности: шифрование на лету AES-256 — до 150 Гбит/с; расшифровка ключами RSA-2048 – до 100 тысяч операций в секунду; одновременные сжатие и распаковка LZ77 — до 100 Гбит/с; обработка TLS и IPSec — до 150 и 100 Гбит/с соответственно. Но вообще говоря, QAT нужен не только и не столько для обработки сетевого трафика, потому что его возможности можно утилизировать и при работе с защищёнными приложениями, и с системами хранения данных, которые также получат прирост производительности за счёт разгрузки некоторых функций.
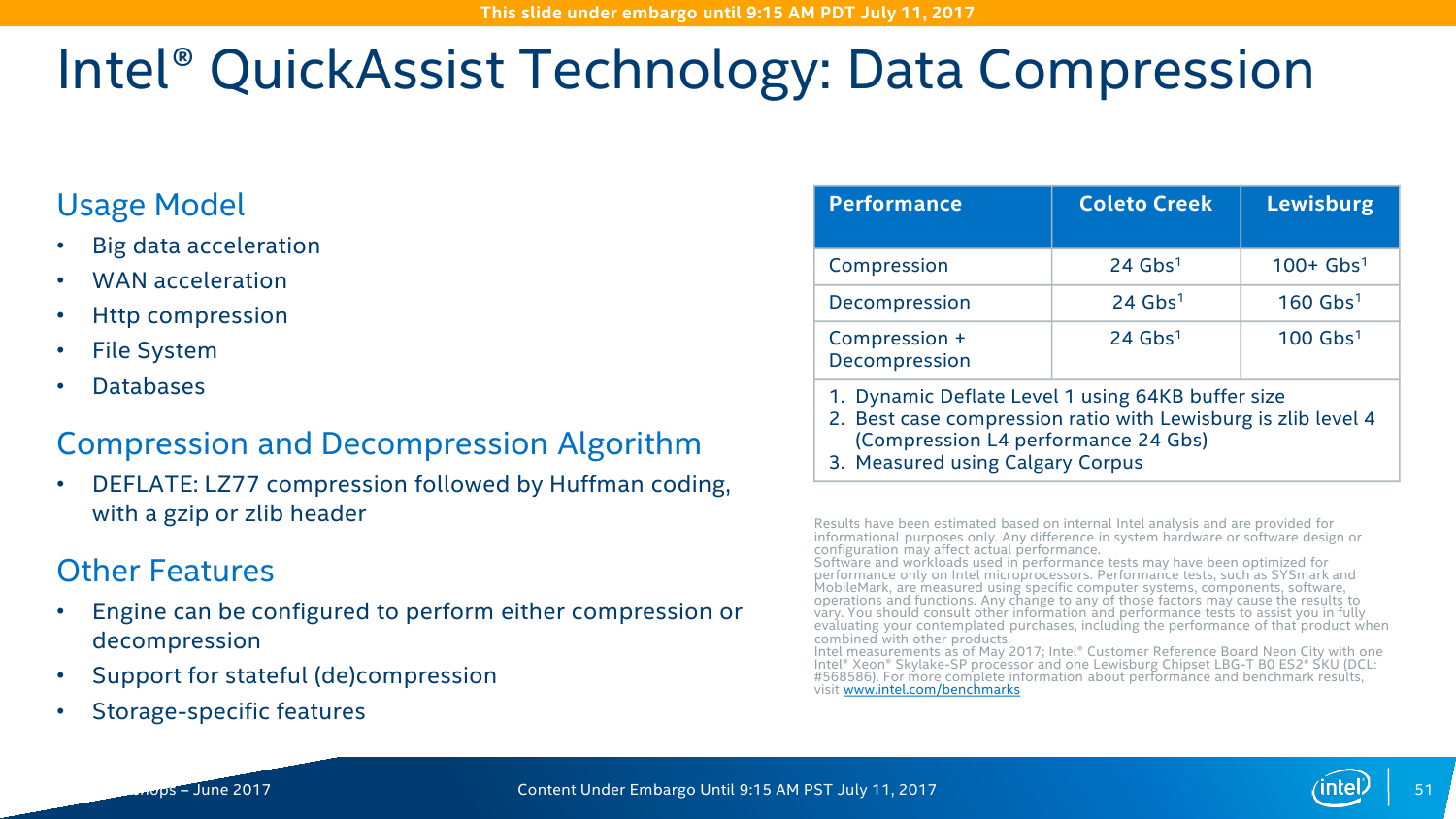
Для разработчиков Intel предоставляет набор Data Plane Development Kit (DPDK), который позволяет наиболее полно задействовать все возможности по работе с данными на новой платформе. Дополняет его Intelligent Storage Acceleration Library (ISA-L). Как бы это странно ни звучало для обывателя, но для РФ именно они весьма и весьма актуальны из-за необходимости прохождения различных процедур в ФСБ в связи с использованием стойкого шифрования. То есть в некоторых структурах использование Intel QAT может быть запрещено. Строго говоря, российские разработчики и так массово перешли на DPDK при создании различных security-продуктов.
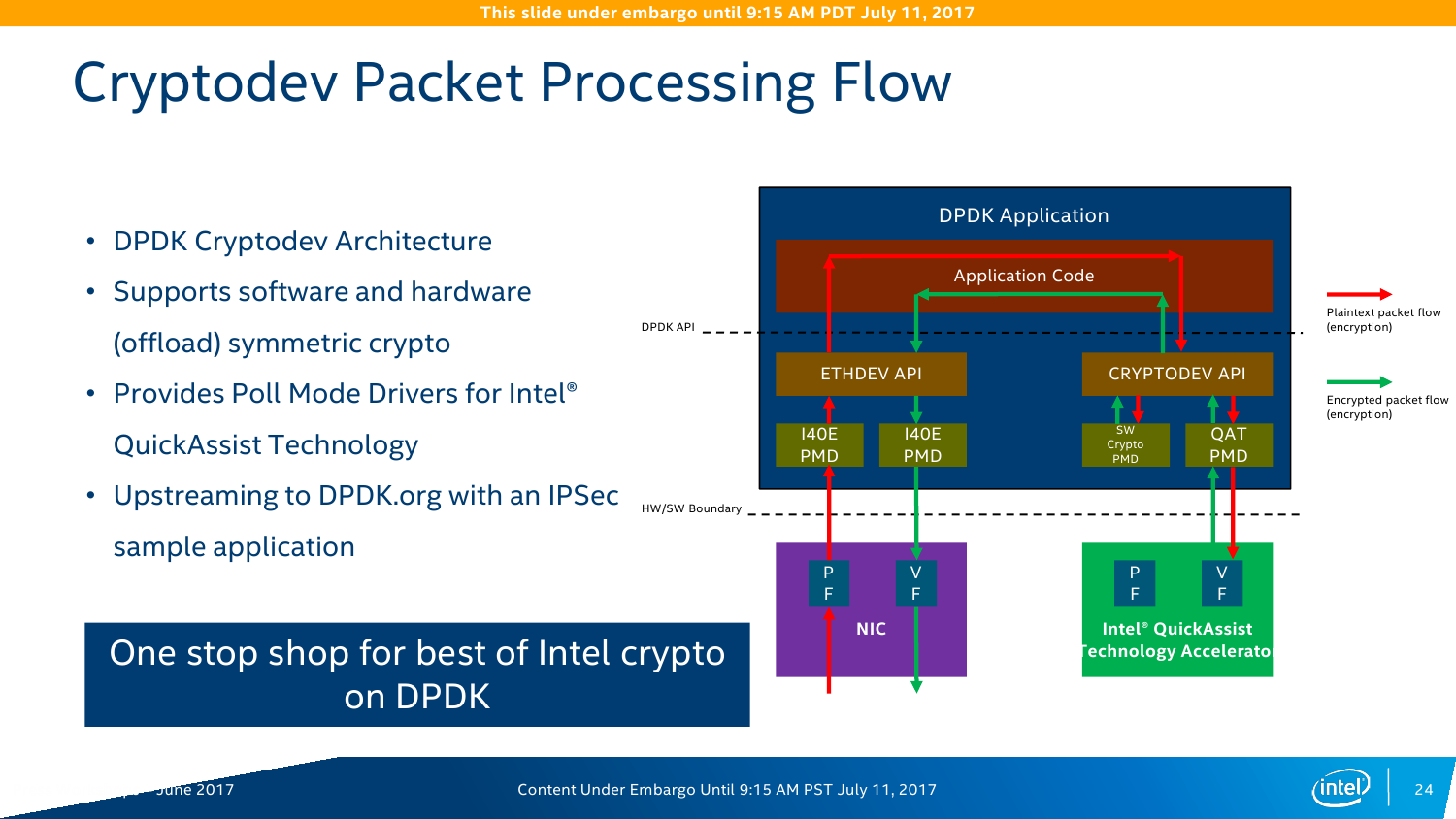
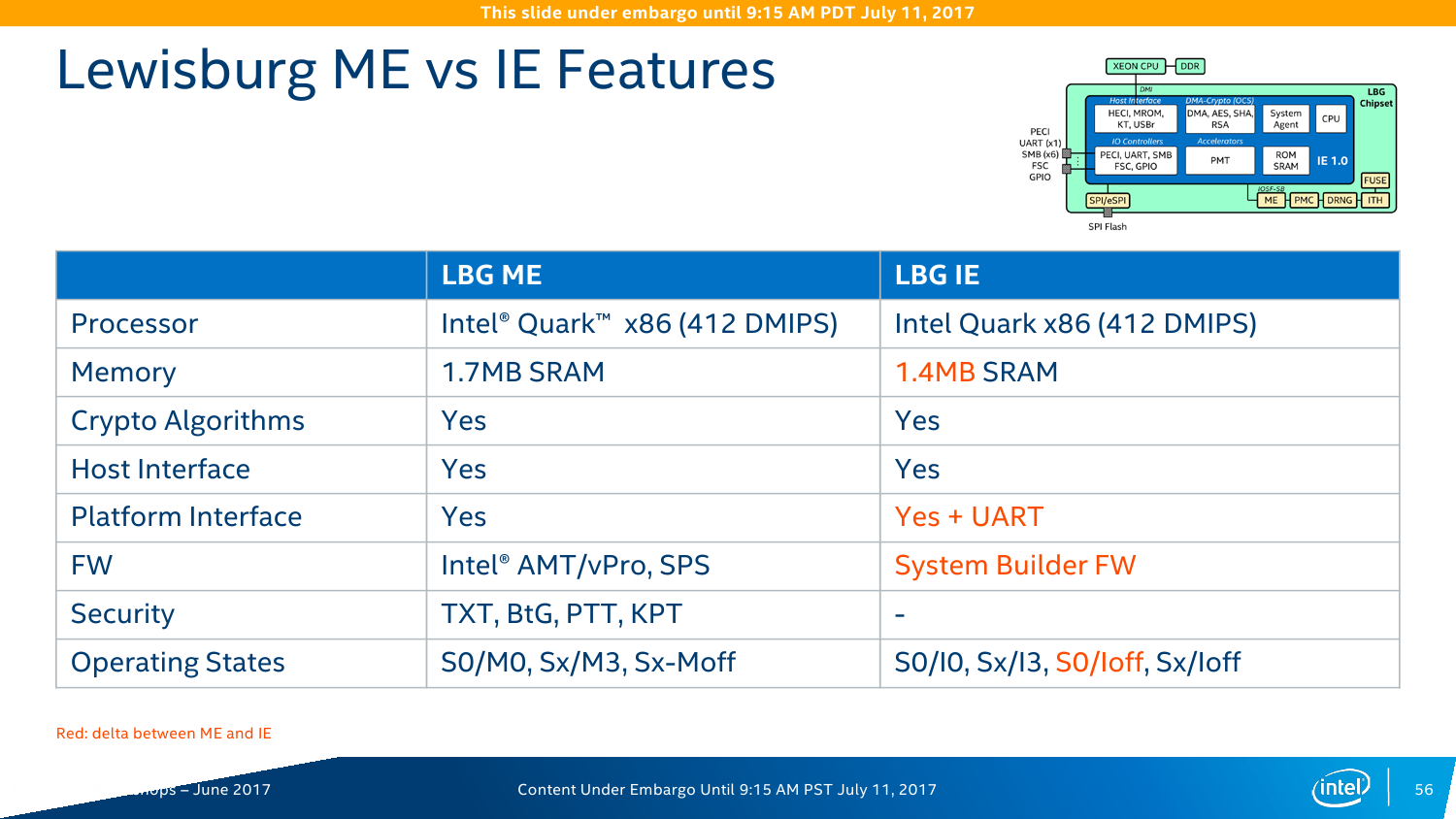
Впрочем, обновление серверной платформы повлекло за собой и значительное обновление программных компонентов, про которые и отдельно-то можно написать ещё два-три материала, так что останавливаться мы на них в этом тексте не будем. Лучше вернёмся к чипсету и упомянем ещё одну технологию — Innovation Engine (IE). Модуль Intel IE по своим задачам и возможностями аналогичен давно используемому Management Engine (ME), но только для разработчиков платформ. IE не нова, пока из интересного стоит отметить постепенный переход от IPMI к протоколу Redfish. Аппаратная основа для всех ME/IE одна: отдельный процессор Intel Quark + немного SRAM.

Новые технологии и расширения
В этой части коротко пробежимся по некоторым ключевым технологиям, которые впервые появились в Intel Xeon Scalable Processor или которые уже имелись ранее, но были дополнены новыми функциями. Примером последней является Intel TXT (Trusted Execution) — она обзавелась функцией One Touch Activation (TXT-OTA), которая, по сути, позволяет удалённо включить и сконфигурировать TXT. Это важно при администрировании и переконфигурировании большого числа узлов. Системы Intel Platform Trust Technology (PTT) и BootGuard никуда не делись, как привычные TSX или блочки для AES/SHA. Технологии Intel QAT вкупе с PTT в случае платформы Purley предлагают дополнительную опцию Intel Key Protection Technology (KTP). Суть её сводится к защищённым хранению и передаче внутри платформы ключей шифрования. Доступ к ключам и управление ими осуществляется только владельцем, что необходимо, например, при размещении серверов в стороннем дата-центре.

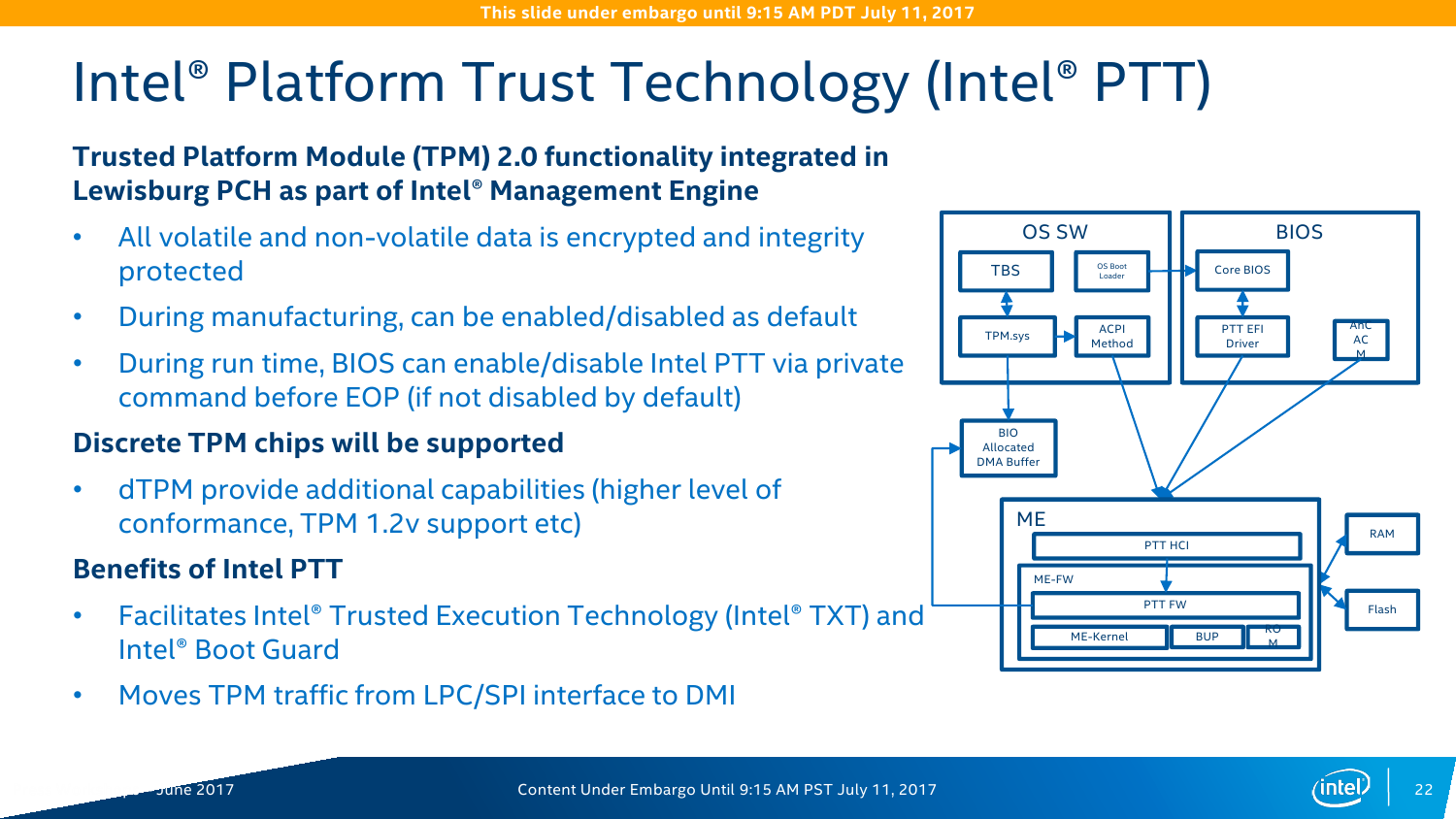
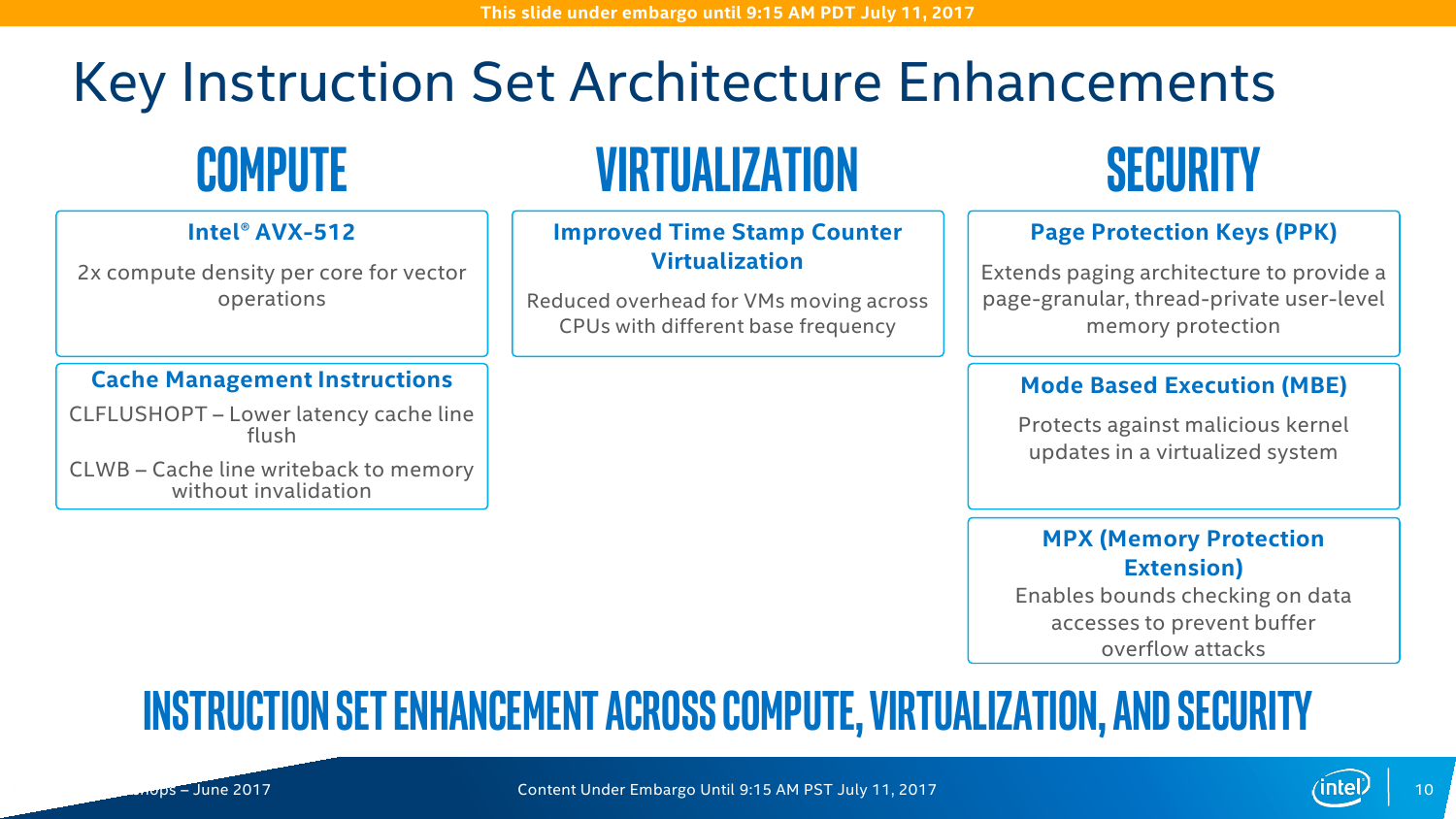
У системы виртуализации VT-x появилось несколько расширений. Mode-Based Execution Control (MBE) отвечает за проверку исполняемого кода ядра ОС. Timestamp Counter Scaling (TSC) помогает при живой миграции виртуальных машин с одного CPU на другой при разных базовых частотах процессора. MPX (Memory Protection Extension) предотвращает стандартные атаки на переполнение буфера при работе с памятью. Page Protection Keys (PPK) повышает изоляцию страниц памяти друг от друга. Наконец, в серверных Skylake появилась функция LMCE (Local machine check exception) — при сбое уведомление придёт для конкретного потока (vCPU), а не для всех. Часть упомянутых выше технологий это относится и к RAS-платформе Intel Run Sure, которая ранее была доступна только для процессоров Intel Xeon E7. Теперь же Intel решила «исправиться» и предлагает функции RAS в том или ином виде почти для всех CPU. Естественно, разделение по классам осталось — только серия Platinum как преемник Xeon E7 получит максимум функций.
Как это всё выглядит
В московском офисе предварительно показали пару вариантов машин на новой платформе, плюс фото серверных «тушек» можно найти в новостях с ISC 2017. CPU теперь имеют сокет LGA3647 (Socket P). Физически точно такой же разъем используется в Xeon Phi Knights Landing, но электрически они между собой несовместимы.

Intel Xeon Scalable Processor

Сверху — CPU с двумя портами Intel Omni-Path (это Xeon Phi), снизу — с одним
Модели с индексом F, то есть со встроенным стогигабитным адаптером Intel Omni-Path имеют на узкой стороне «отросток» с выводами. К нему подключается кабель, который идёт в конвертер, а уже из него выходят коннекторы для одного из стандартных разъёмов (будет и «медь», и «оптика»). Варианты с одним и двумя портами Omni-Path чуть-чуть различаются.

SpreadCore — Intel S2600WF (WolfPass)

ShadowCore — Intel S2600BP (Buchannan Pass)
Два представленных типа двухсокетных плат имеют кодовые имена SpreadCore и ShadowCore. Первая – это обычная плата на всю ширину стойки, Intel S2600WF (WolfPass). Из интересного, пожалуй, можно отметить разве что OCuLink — подключение дисковой корзины с SSD. Вторая плата — Intel S2600BP (Buchannan Pass) — больше подходит для «лезвийного» исполнения. В случае последней чуть отличается материал радиаторов: ближний к кулерам сделан из алюминия, а дальний из меди.

На фото виден кабель OCuLink, идущий к дисковой корзине
Конкуренты
Строго говоря, судить о производительности и конкуренции между AMD EPYC и Intel Xeon Scalable Processor, а тем более в отрыве от конечной цены различных решений, пока рано. Да, Intel в презентациях показывает различные примеры её роста — все они сведены в отдельную галерею ниже. Но кое-какие моменты рассмотреть всё же можно. Понятно, что многое зависит от конкретных задач и приложений. Те же инструкции AVX-512 нужны не всем, а в EPYC как раз есть только AVX2. То же самое касается и структуры кристаллов. Если есть много независимых потоков, то для обоих процессоров нет особой разницы. Но если дело касается, например, виртуализации, то уже не всё так однозначно. Из-за особенностей строения EPYC возникают задержки при задействовании более четырёх ядер, то есть при выходе за пределы CCX-комплекса внутри отдельного кристалла или за пределы кристалла вообще. Ещё у EPYC есть одна интересная опция — сквозное шифрование памяти. Однако, о чём уже говорилось выше, её, увы, не всегда можно задействовать из-за необходимости сертификации для некоторых секторов рынка.
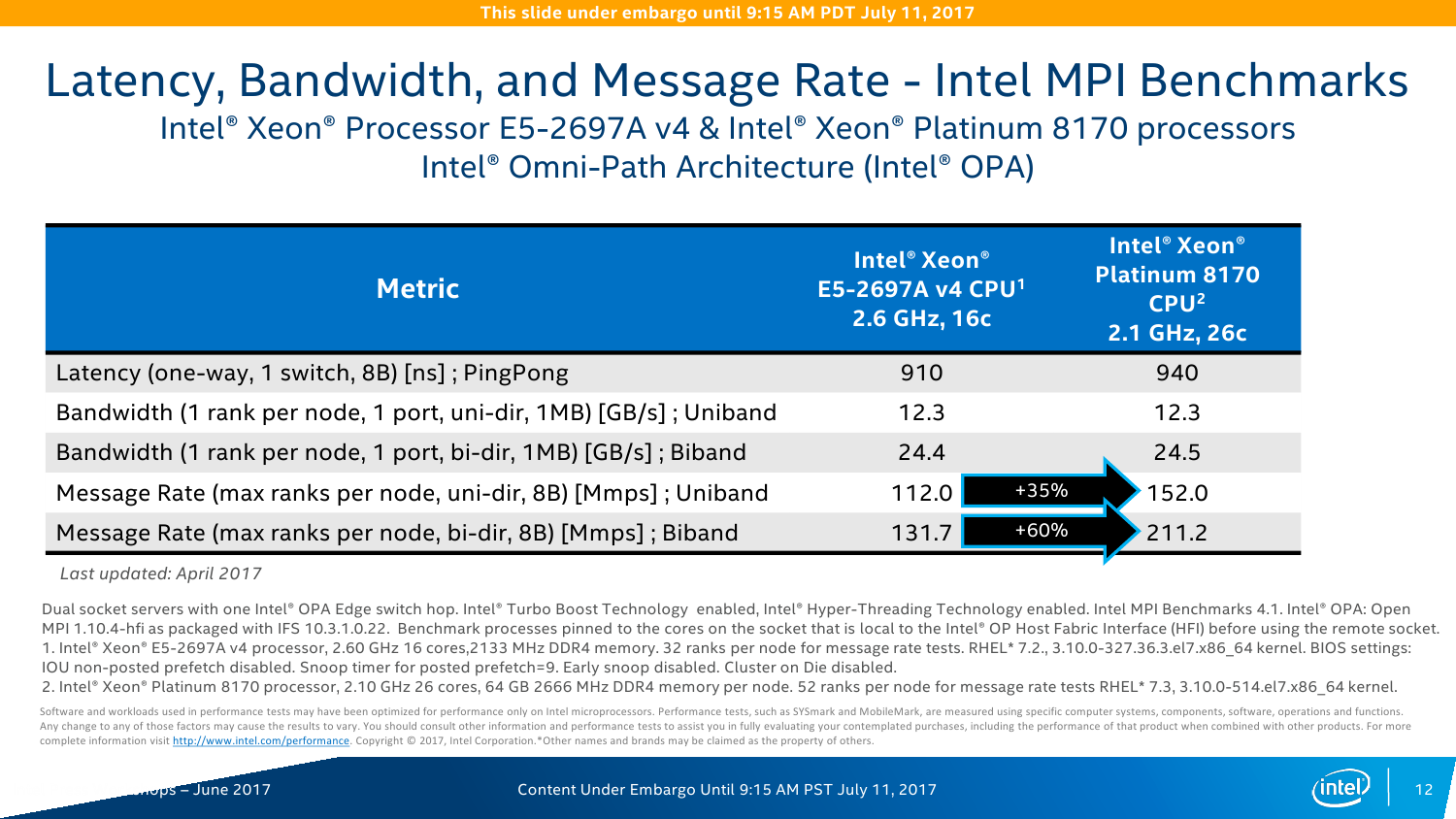
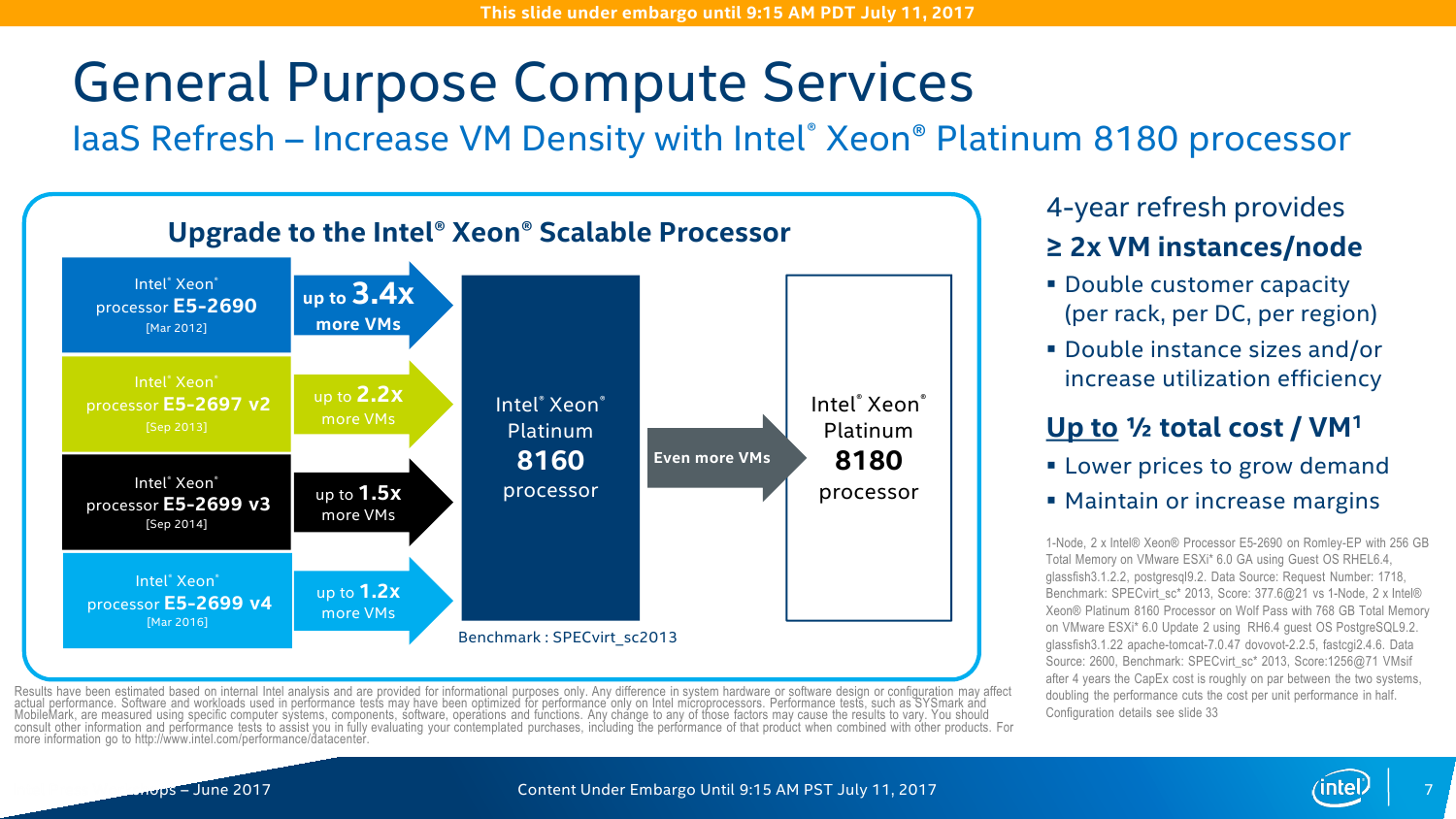
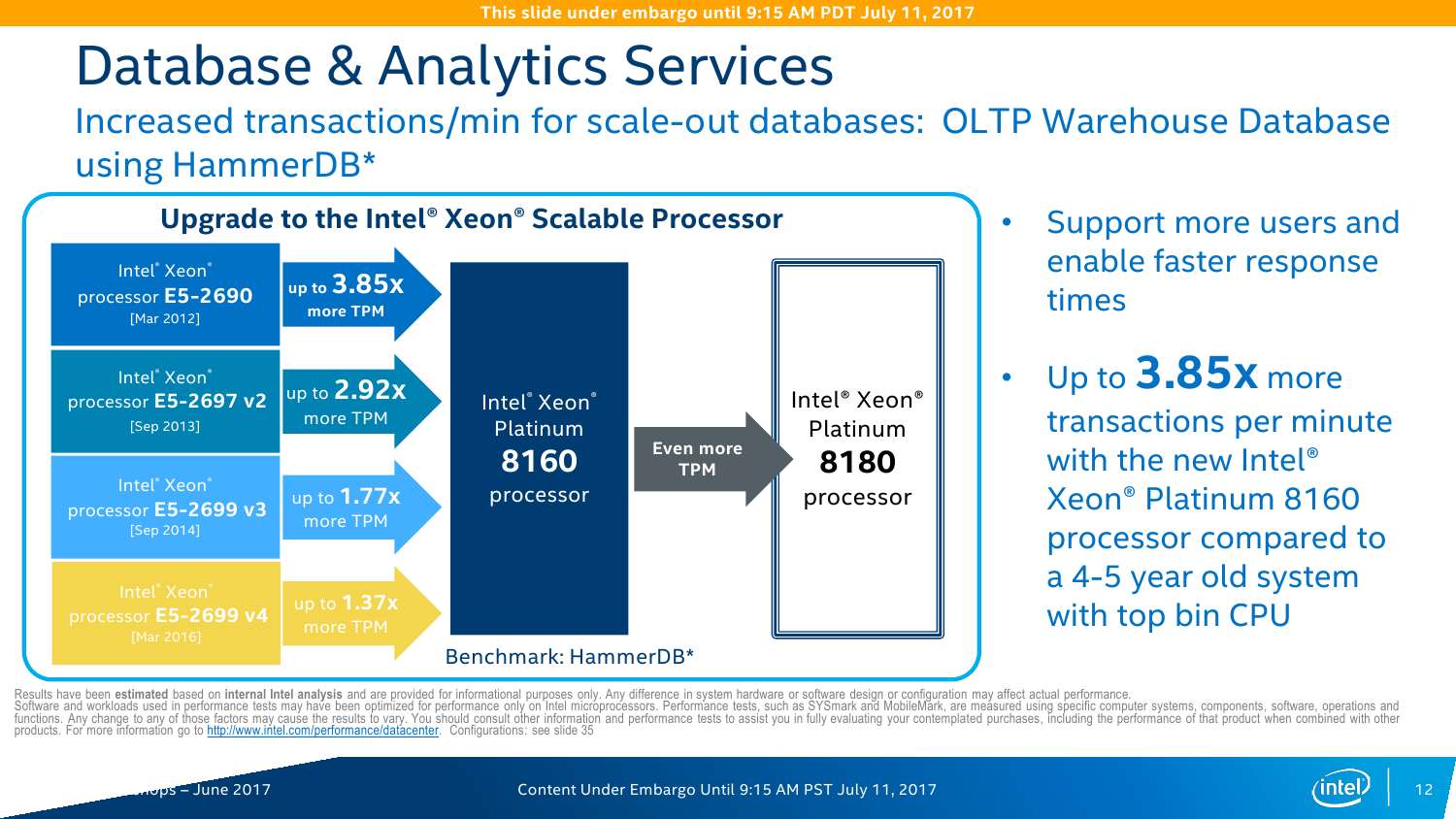
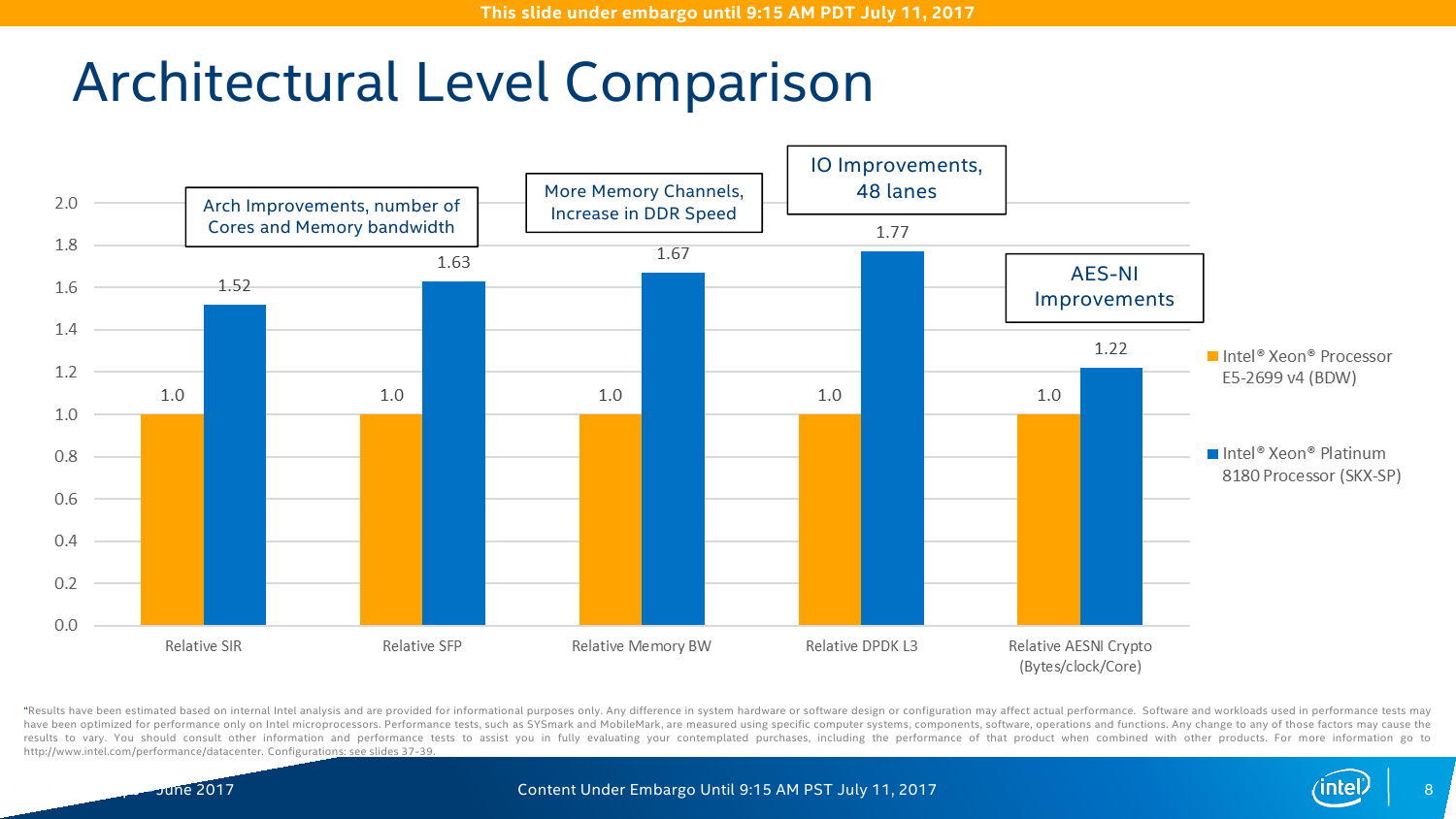
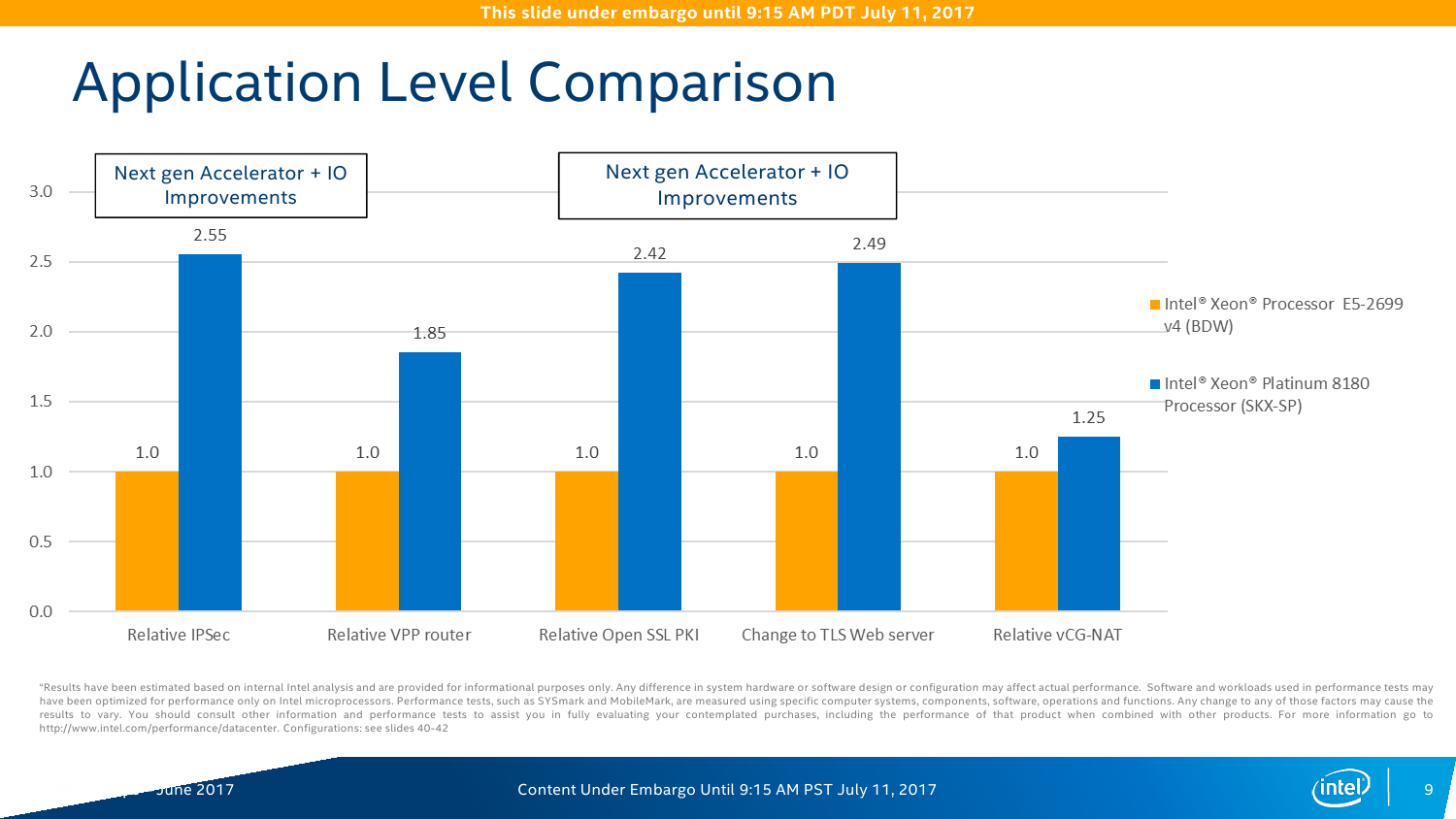
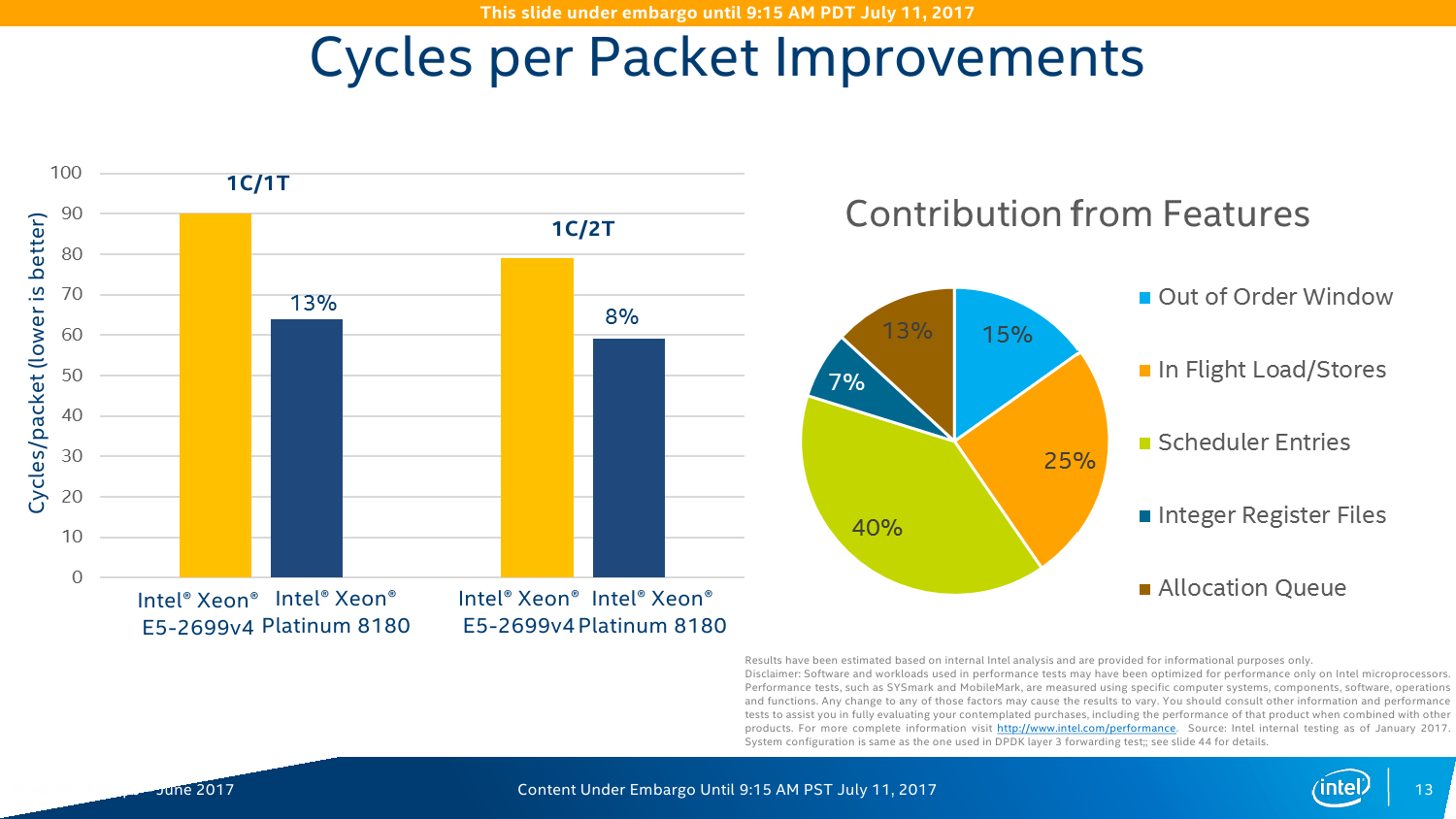



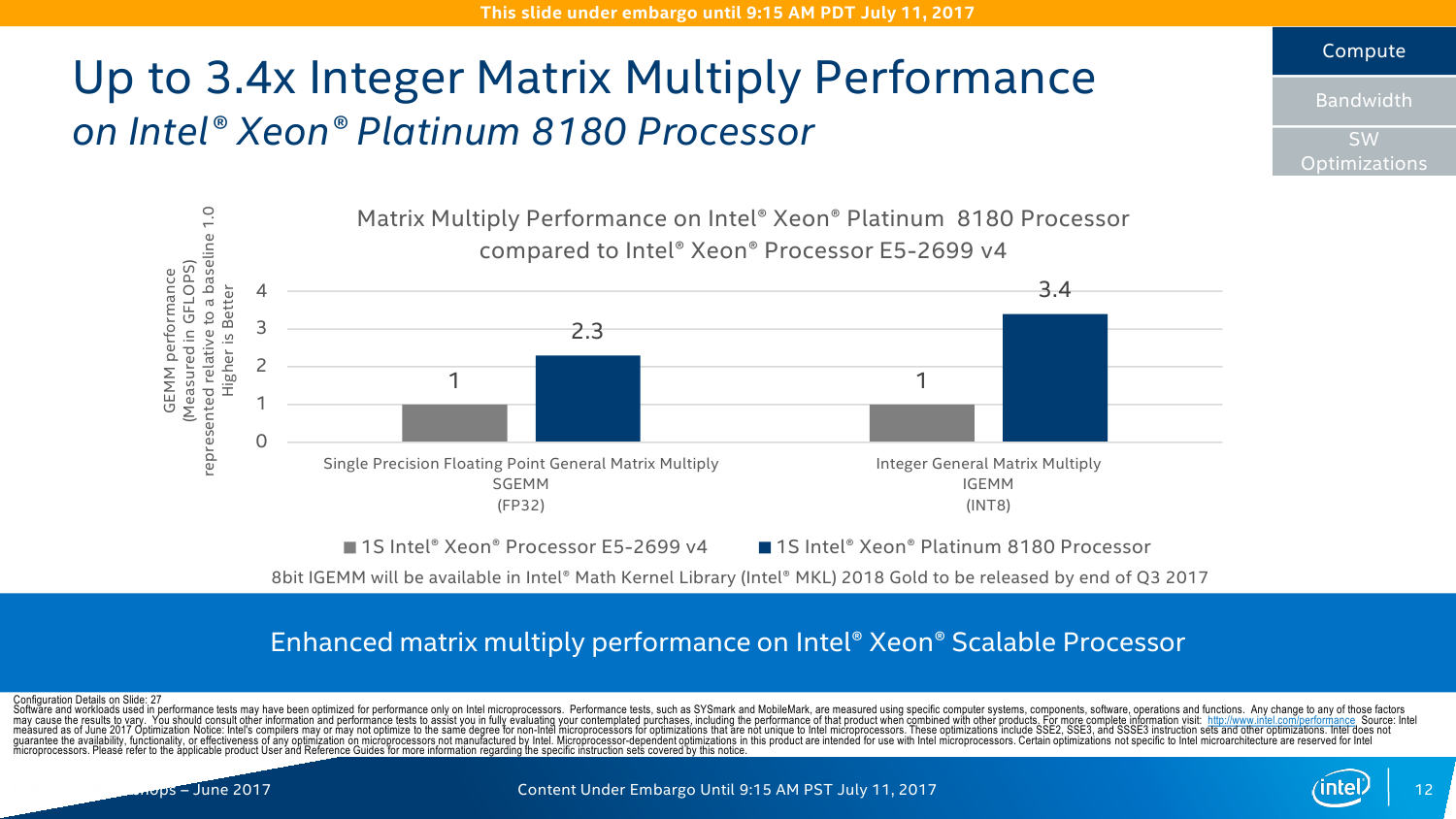
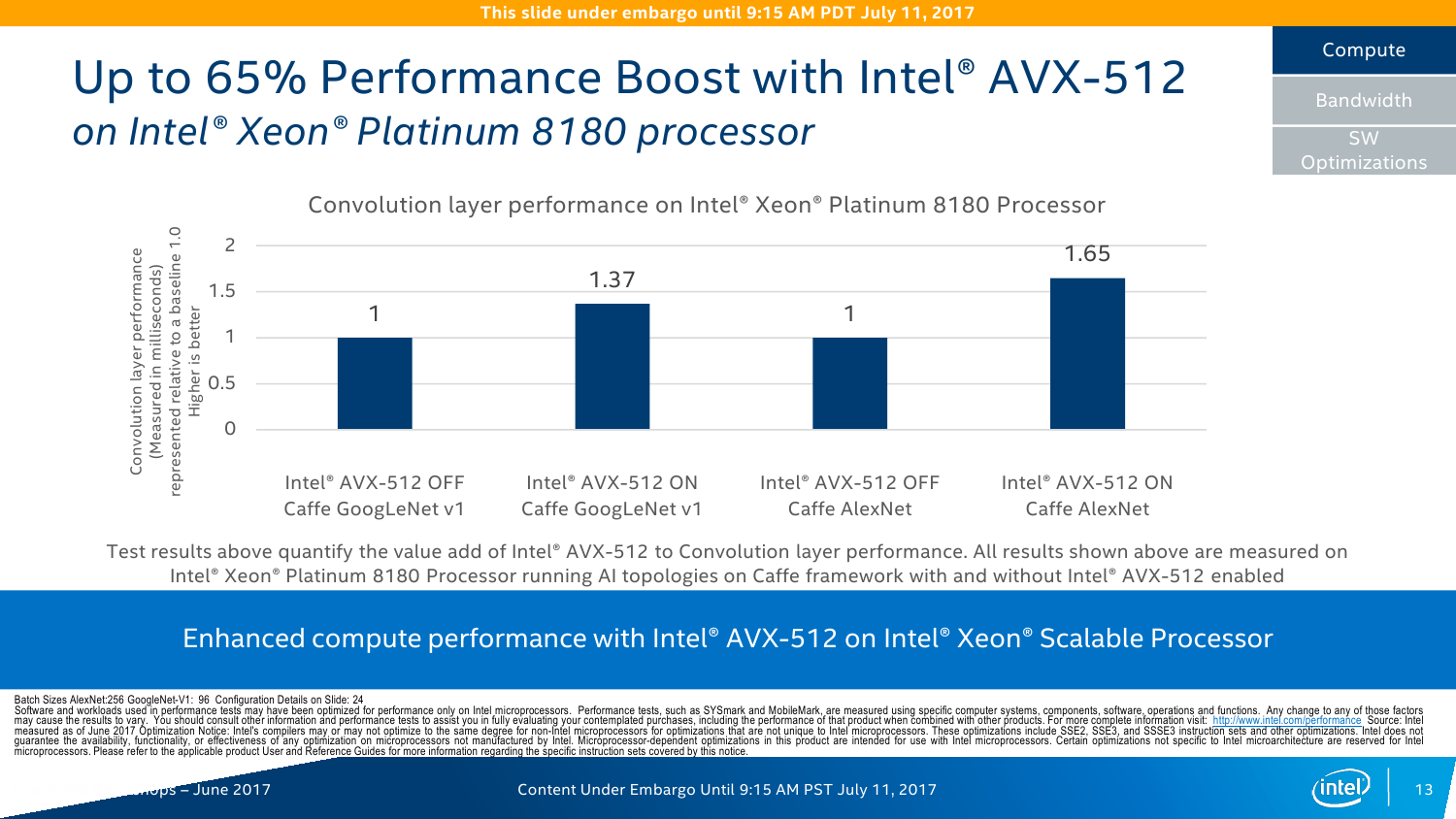
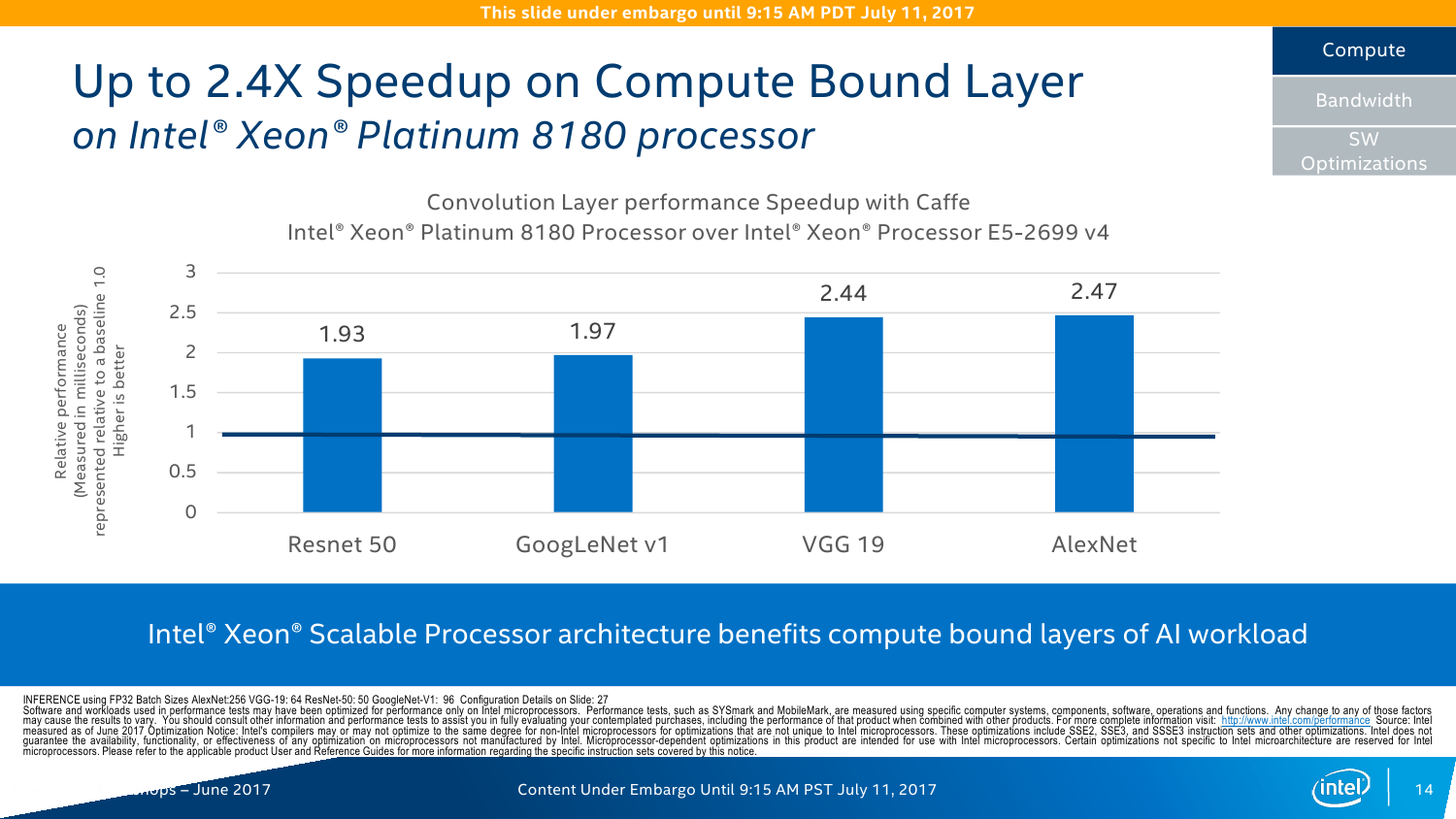
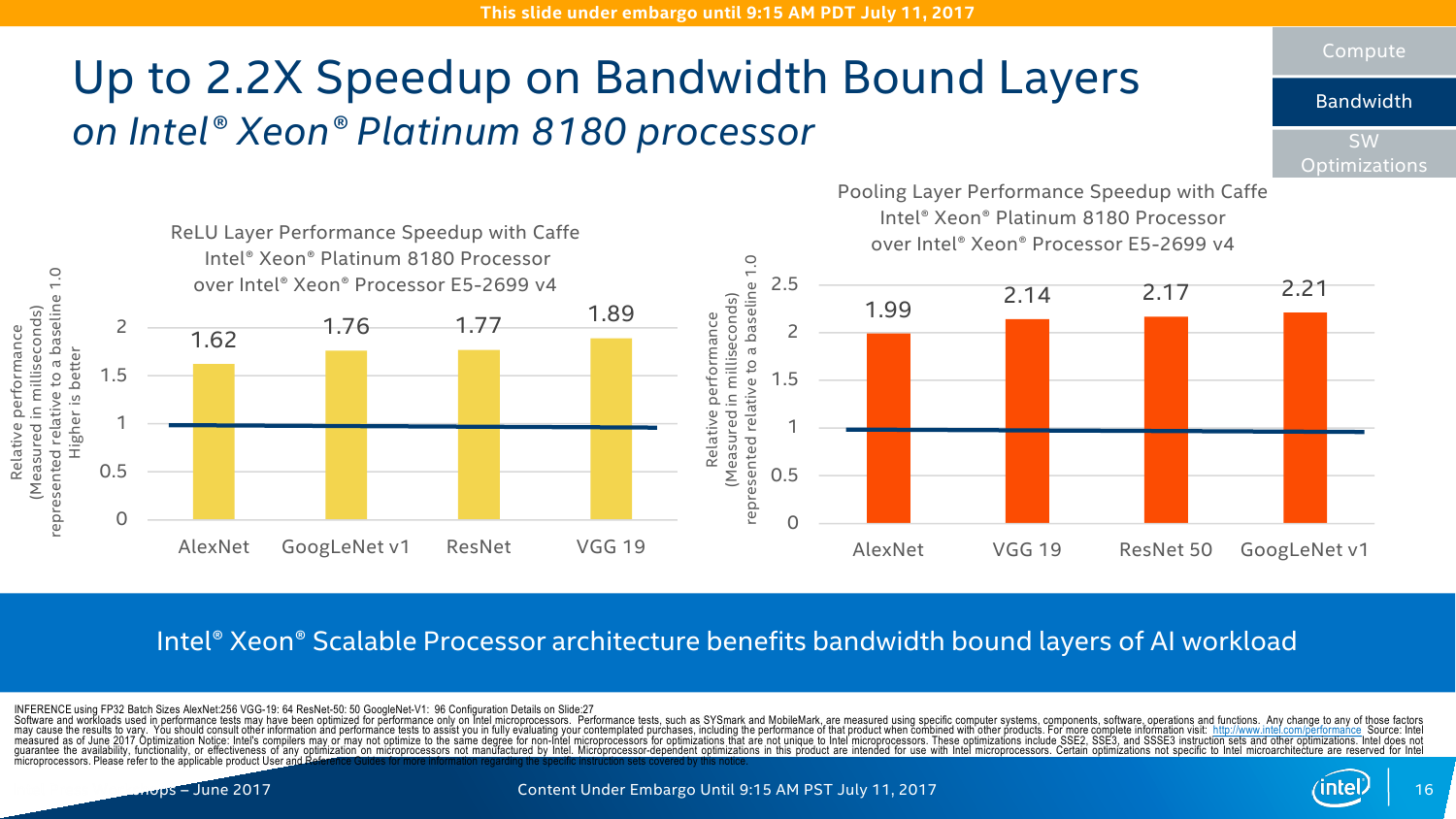
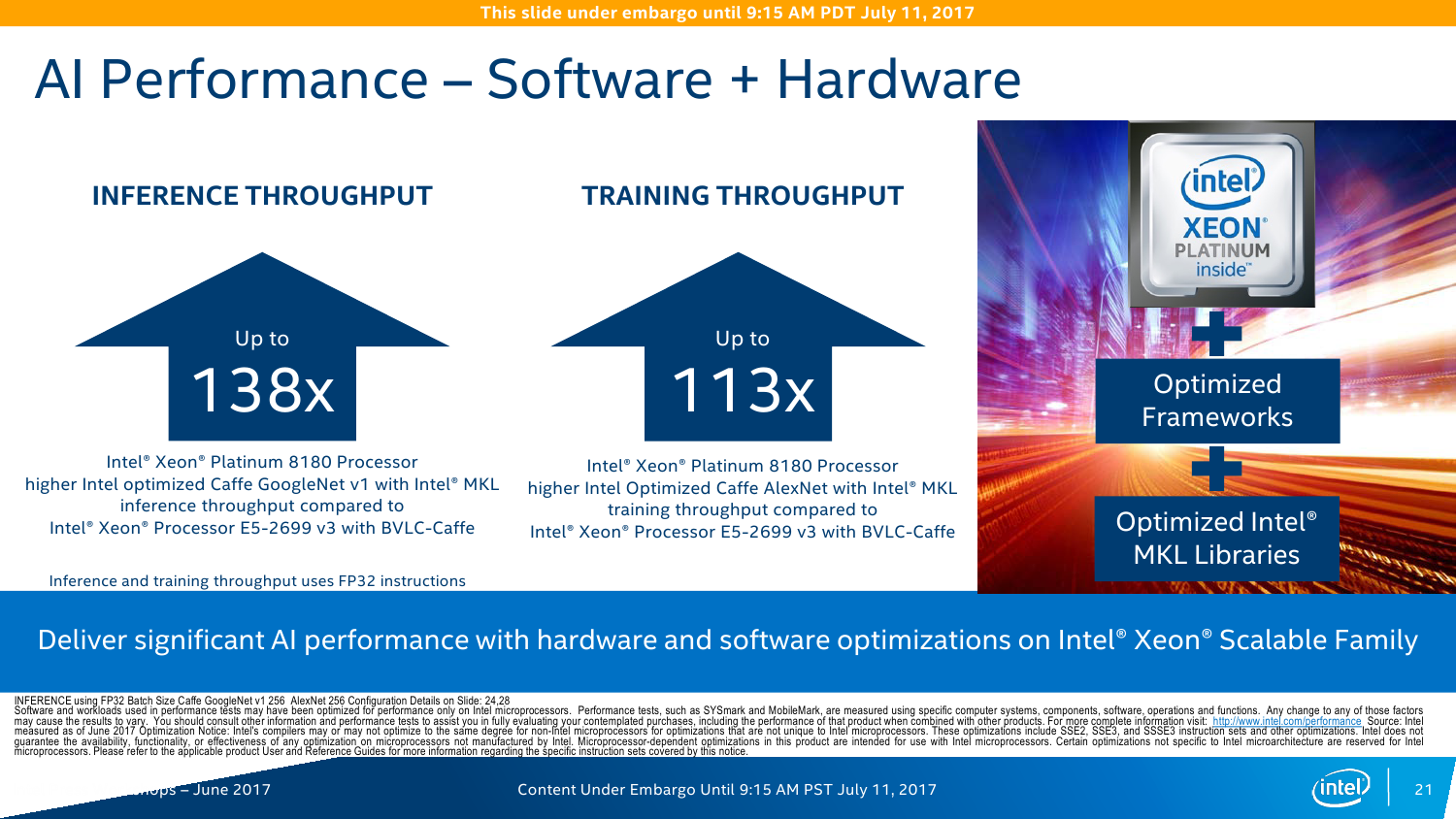




С IO ситуация тоже неоднозначная. AMD делает упор на то, что в EPYC есть 128 линий PCI-E x16. Это так, и в односокетном варианте можно получить очень и очень интересные решения, что и было отмечено в обзоре этой платформы. Однако в двухсокетном варианте, который как раз чаще всего используется, уже не всё так гладко (про 4P EPYC пока не особо слышно). Линков всё так же 128 (по 64 с каждой стороны уходит на связь между CPU). То есть на каждом сокете у EPYC всего на одну PCI-E x16 больше в сравнении с новыми Xeon, но не стоит забывать, что и на интерконнект их придётся потратить, и, возможно, на связь с внешними чипсетами. Так что в этом плане здесь наблюдается паритет, но у Intel, правда, есть варианты CPU c встроенным Omni-Path. Естественно, всё это тоже нужно не для всех, а, к примеру, для HPC, где неплохо было бы подключать ускорители и интерконнект напрямую к CPU, но не через мосты.
Заключение
Для платформы Purley сама Intel считает основными четыре отрасли: HPC (суперкомпьютинг), корпорации, телекоммуникации и облака. Сюда же можно смело добавить машинное обучение (ИИ), которое фактически и так растёт во всех этих областях. Естественно, только ими дело не ограничивается – изначально анонсированный набор решений и сам по себе достаточно велик и разнообразен, и дальше будет только расти. Кроме того, Intel, в отличие от конкурента, имеет в портфолио и другие технологии: ускорители, накопители, FPGA, интерконнект. Осталось добавить разве что RAM и… нет, будет не монополия, а скорее высокий риск vendor-lock’а. Хотя посмотрим ещё, что там будет с NVDIMM на Optane. И вот весь этот набор, а не только новые Xeon Scalable Processor, поможет Intel «расширить и углубить» присутствие на рынке серверов и дата-центров. А рынок этот меняется, и меняется очень быстро. Всё чаще говорят о гиперконвергенции (про неё немного рассказано здесь) не как о чём-то абстрактном. Всё больше систем глубже погружаются в виртуализацию и контейнеризацию. Всё меньше остаётся «железных» продуктов, которые нельзя было бы перевести на программно-определяемые (software-defined) платформы. Но об этом мы поговорим в следующий раз.