SC 15 фактически является крупнейшим специализированным мероприятием в области HPC – по сравнению с европейской версией ISC 2015 здесь людской поток был раза в четыре интенсивнее, а площадь павильона и количество участников значительно больше. Однако в итоге получилось нечто странное. Во-первых, многие вещи были анонсированы ещё летом, а здесь компании показывали уже готовые образцы или же делились некоторыми дополнительными сведениями, а действительно крупных новинок было не так чтоб много – к примеру, из российских компаний на SC 15 приехала только РСК, но и она публично представила готовые платформы Tornado и PetaStream. Во-вторых, ряд действительно свежих анонсов был сделан ещё до начала выставки. Взять тот же консорциум OpenHPC или новенькие Tesla M40 и M4, которые, кстати говоря, на стенде NVIDIA так и не появились. В-третьих, на выставке была масса стендов, связанных с HPC весьма опосредованно.
 |
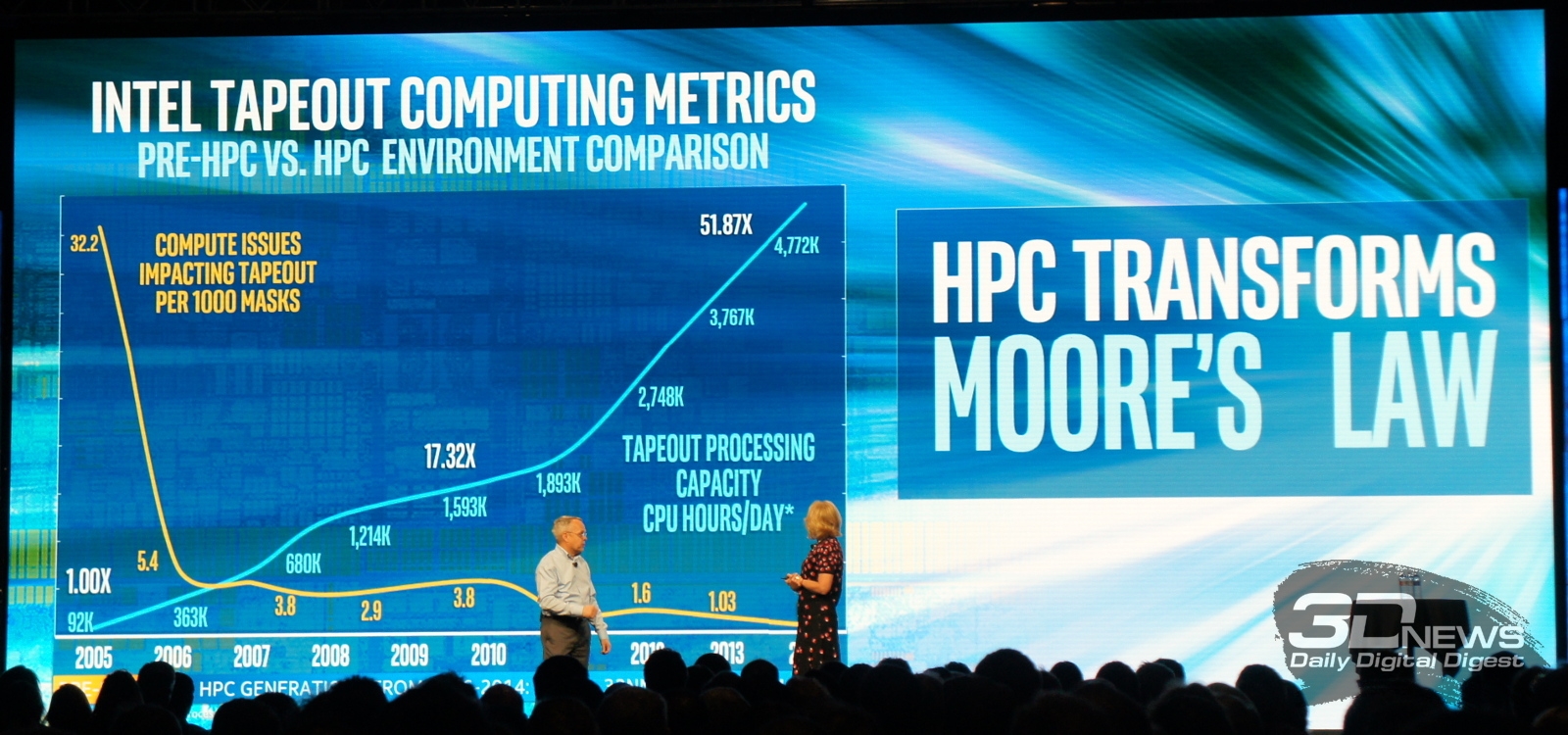 |
С другой стороны, если следовать заветам главного игрока в этом сегменте, то есть компании Intel, то всё не так уж плохо – закон Мура пока ещё работает, что бы там ни говорили злые языки, а впереди нас ждёт покорение экзафлопных вычислений. При этом HPC становятся менее дорогими. «Мы открываем новую эру, когда суперкомпьютерные вычисления перестают быть инструментом для решения какой-либо определенной проблемы и становятся доступными многим», – сказал Чарли Вуишпард (Charlie Wuischpard), вице-президент и генеральный директор подразделения HPC Platform Group корпорации Intel. Сложные вычисления нужны уже не только крупным корпорациям, но и компаниям поменьше для решения насущных задач в области финансов, Big Data, здравоохранения, инженерии, биологии и так далее. Очередная модная тема в этом сезоне, в английском это еще называют словом buzzword, – машинное обучение (machine learning), о котором говорят чуть ли не все компании.
 |
 |
 |
|
|
Чарльз Вуишпард (Charles Wuischpard), вице-президент Intel и руководитель направления высокопроизводительных вычислительных систем, держит в руках пластину с новыми Intel Xeon Phi Knights Landing |
|
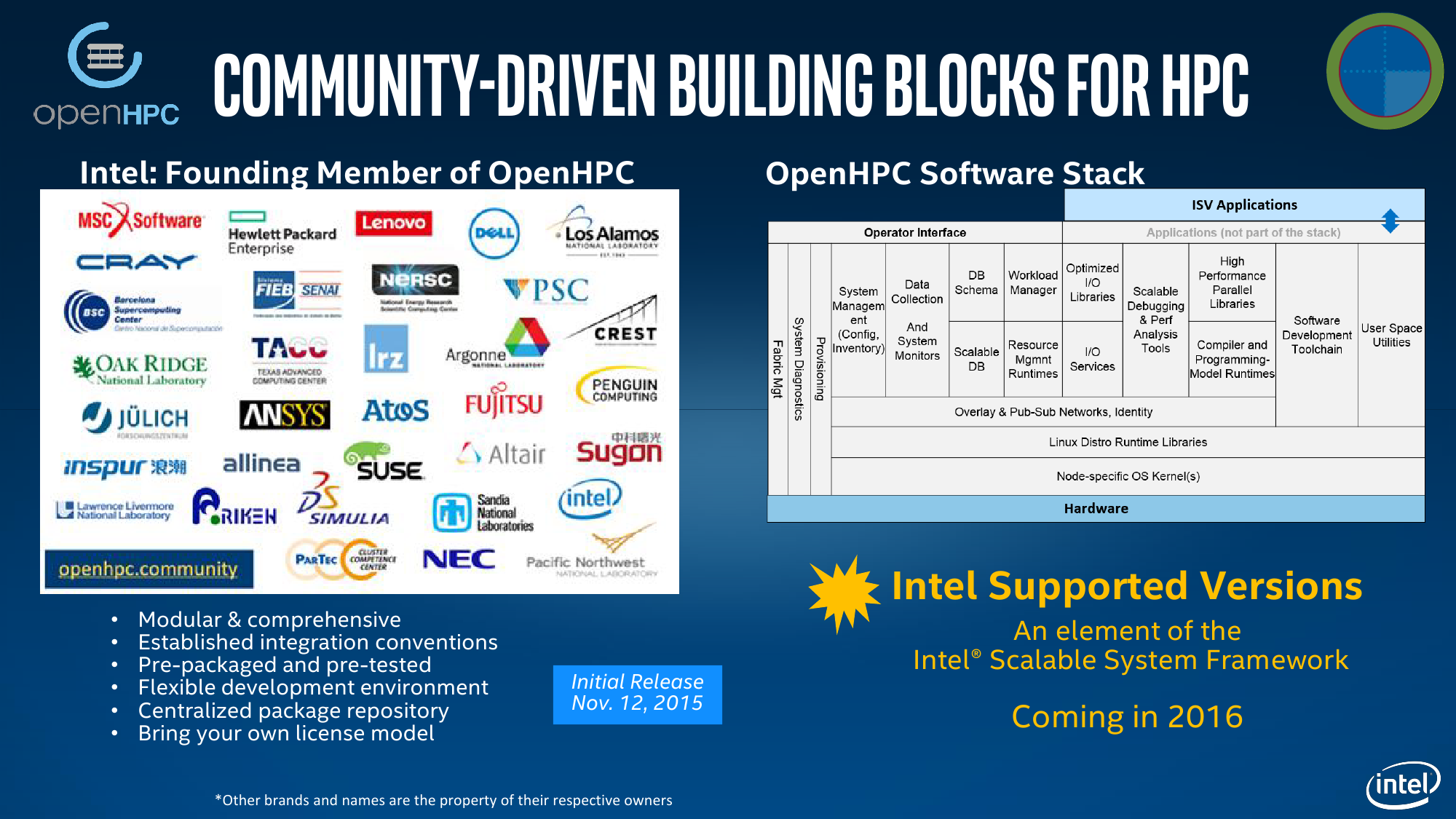
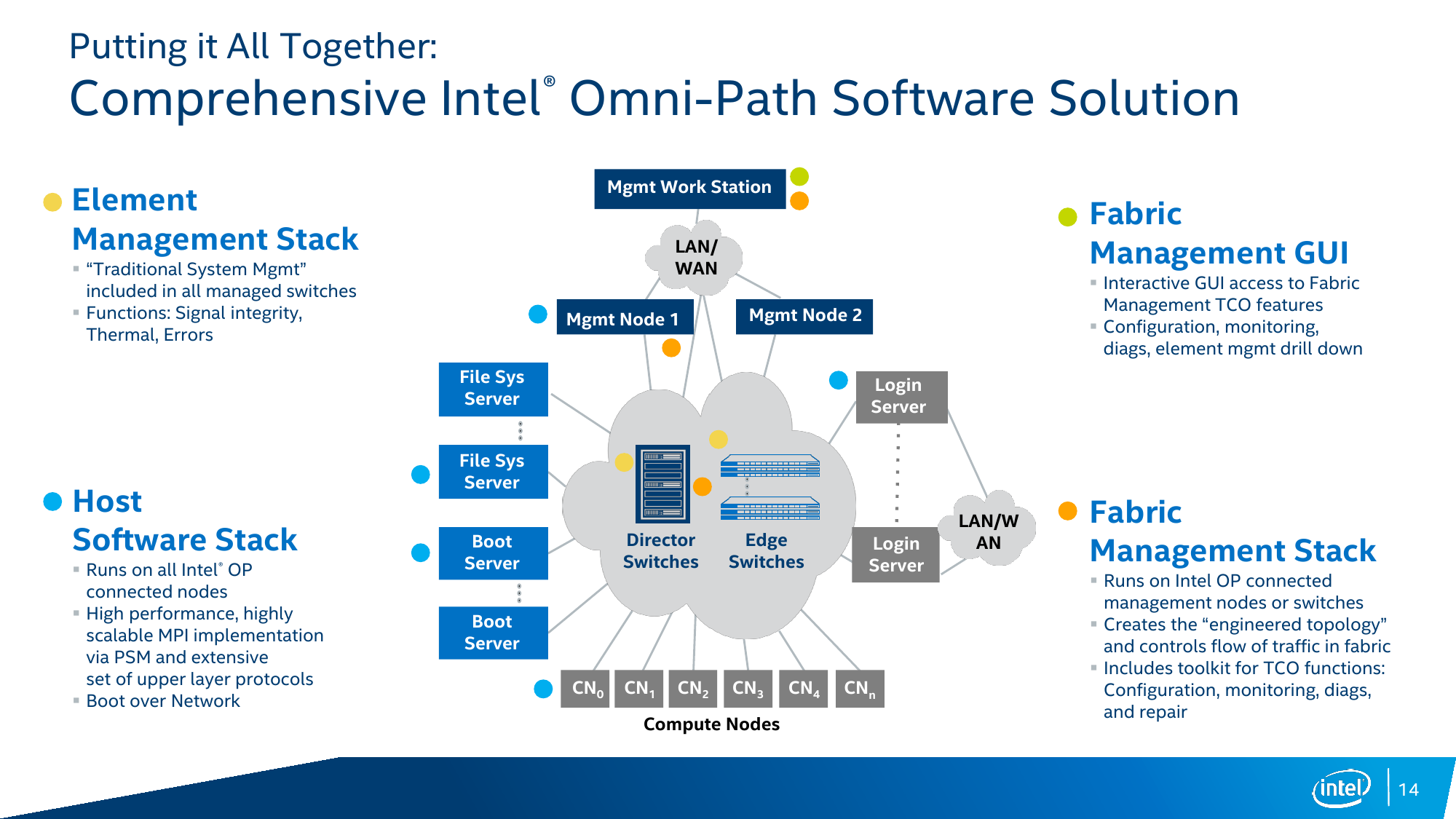
Основой для более широкого распространения HPC послужит Intel’s Scalable System Framework (SSF), о котором мы опять же писали ещё летом. Ну а на SC15 было объявлено о скорой готовности референсных решений на базе SSF и партнёрстве с рядом компаний в этой области. Кроме того, Intel инвестирует средства в создание пяти новых центров параллельных вычислений Intel Parallel Computing Centers для дальнейшей разработки одного из компонентов SSF – ФС Lustre. Также в рамках выставки было объявлено о создании сообщества OpenHPC Collaborative Project по разработке программного стека для HPC-проектов. Унификация позволит быстрее развёртывать новые кластеры и увеличить уровень совместимости между решениями различных производителей программного и аппаратного обеспечения. Компания Intel стала одним из учредителей, а в 2016 году в составе SSF появятся первые продукты для OpenHPC.
 |
 |
|
 |
 |
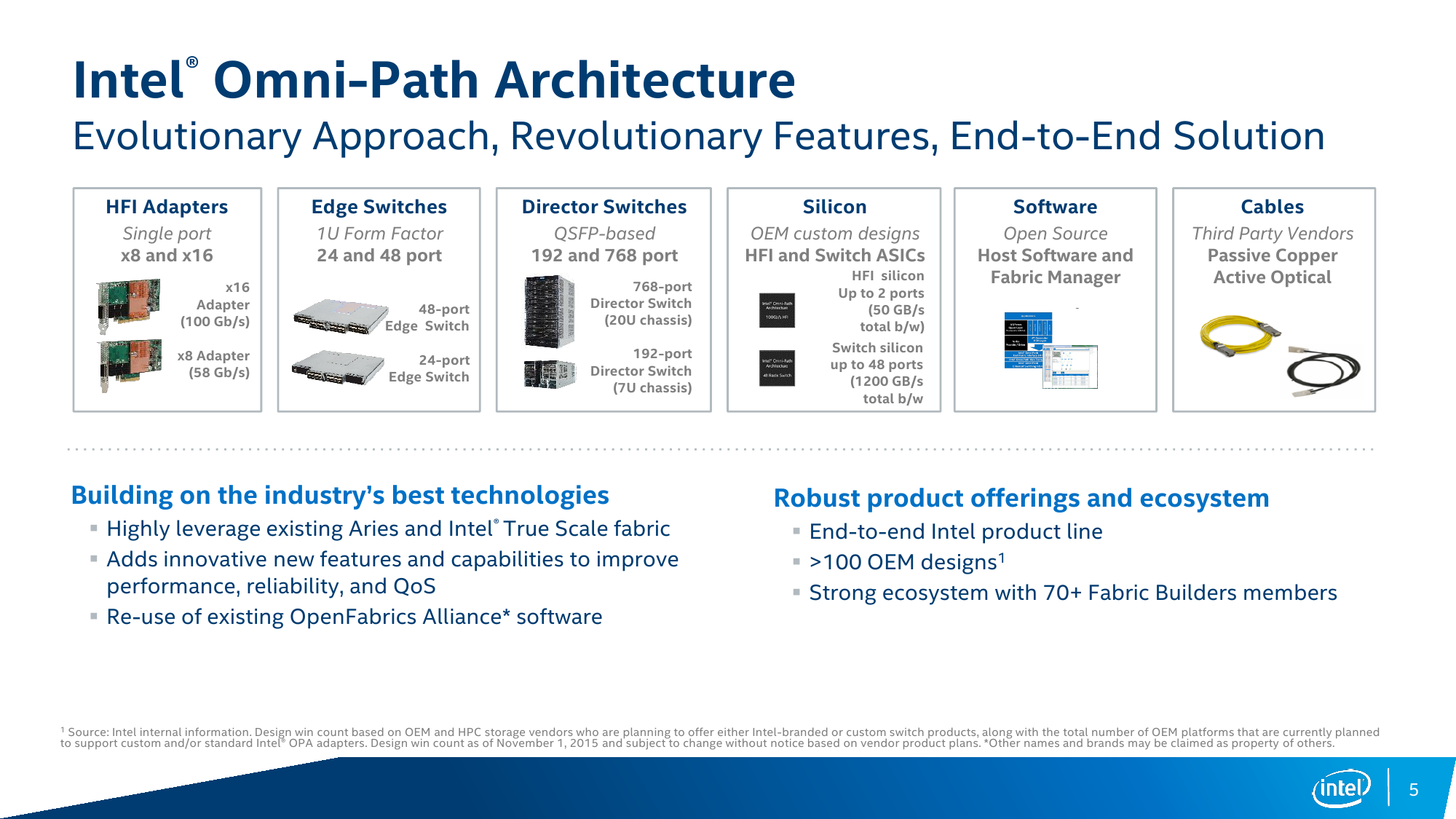
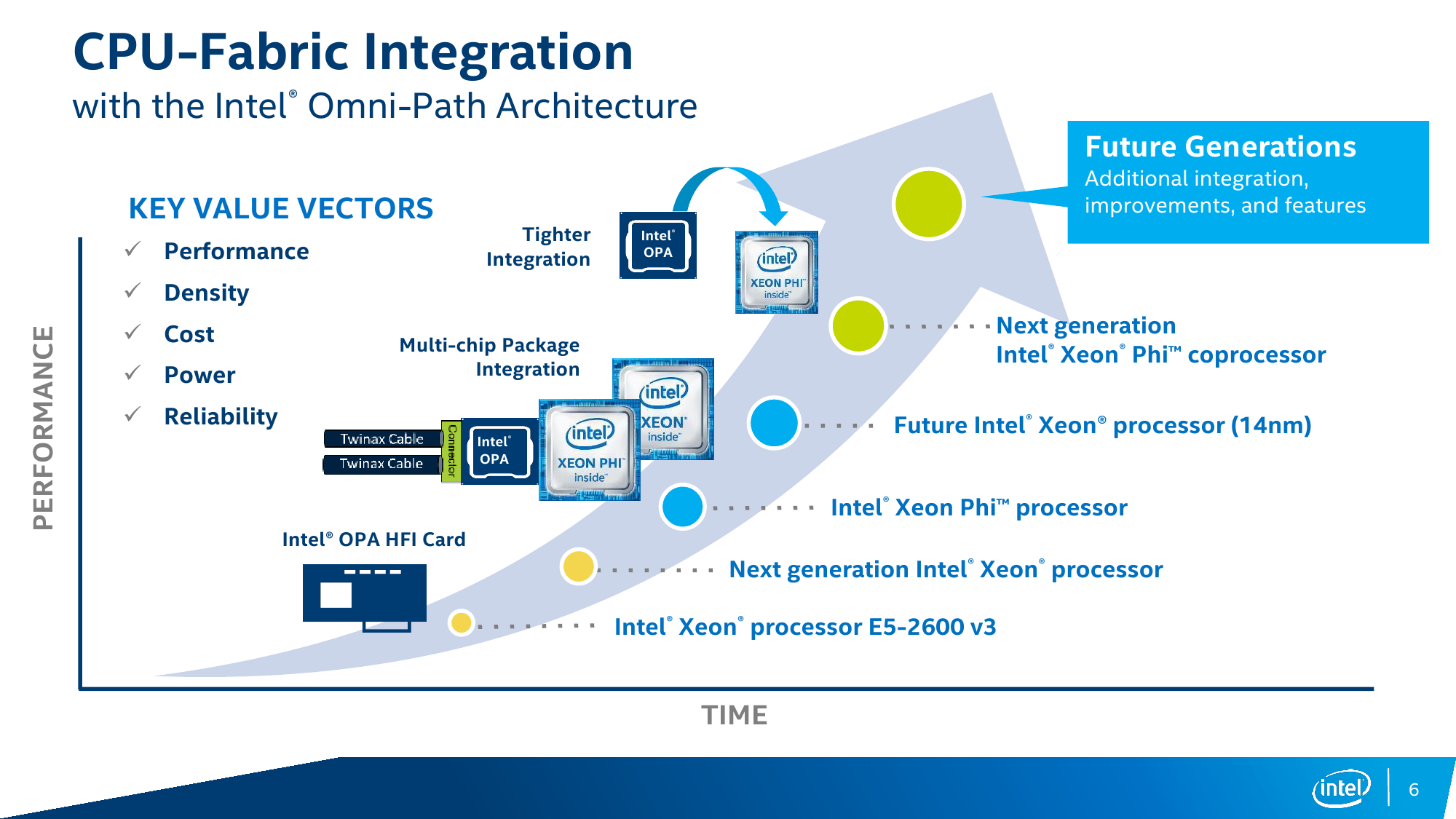
Главный же анонс Intel на SC15 – технология высокоскоростных коммуникационных каналов Intel Omni-Path Architecture (OPA)! Новая архитектура будет программно совместимой с нынешним вариантом Intel TrueScale Fabric, но при этом будет намного совершеннее с технической точки зрения. Intel OPA почему-то нередко сравнивают с Infiniband EDR из-за типа соединения – собственно говоря, та же пассивная «медь» (до 3 м) и активная «оптика» (до 30 м) – и из-за скорости подключения 100 Гбит/с (для 4X-портов). Однако у этих двух технологий есть масса различий. Что касается непосредственно кабельного хозяйства, то Intel оставляет это на плечах соответствующих производителей. Программное обеспечение для OPA с открытым исходным кодом, а вот контроль над остальными элементами более жёсткий. Сама Intel производит ASIC’и, которые используются и в её собственных продуктах, и будут доступны OEM-партнёрам, коих уже набралось больше сотни. Доступны ASIC в двух вариантах: для хост-адаптеров и для свитчей.
 |
 |
 |
|
|
Образцы адаптера и 48-портового свитча Intel Omni-Path на стенде РСК |
|
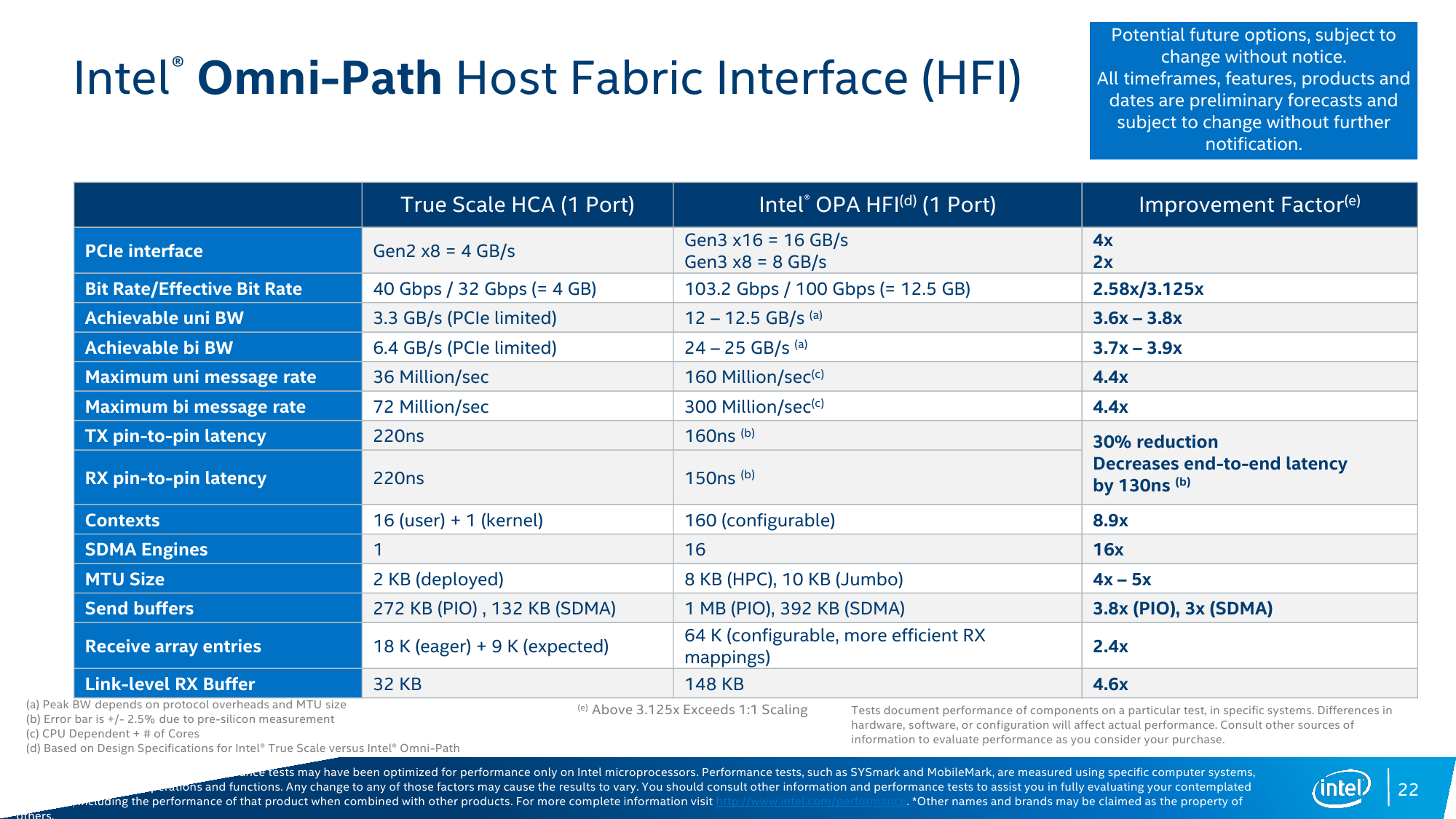
Для систем текущего поколения Intel предлагает два варианта однопортовых адаптеров с QSFP-коннекторами, различающихся лишь числом задействованных линий PCIe – младшая версия из-за использования лишь восьми линий предлагает меньшую скорость обмена данными. Оба предназначены для систем текущего и следующего поколений на базе CPU Intel Xeon. Текущее поколение Intel Xeon Phi Knights Landing (KNL) оснащено в некоторых вариантах подключением Omni-Path. Впрочем, с ними ситуация интересная – Intel обещает их публичную доступность в 2016 году, но фактически они уже используются в будущих суперкомпьютерах Cray, Atos и Penguin Computing, а первая партия этих чипов распродана. Для всех этих систем предлагаются коммутаторы на 24/48/192/768 портов. В будущих Intel Xeon под крышкой процессора будет находиться и чип Omni-Path, а у следующего поколения Xeon Phi, видимо, всё будет размещено уже на одной подложке.
 |
 |
|
 |
 |
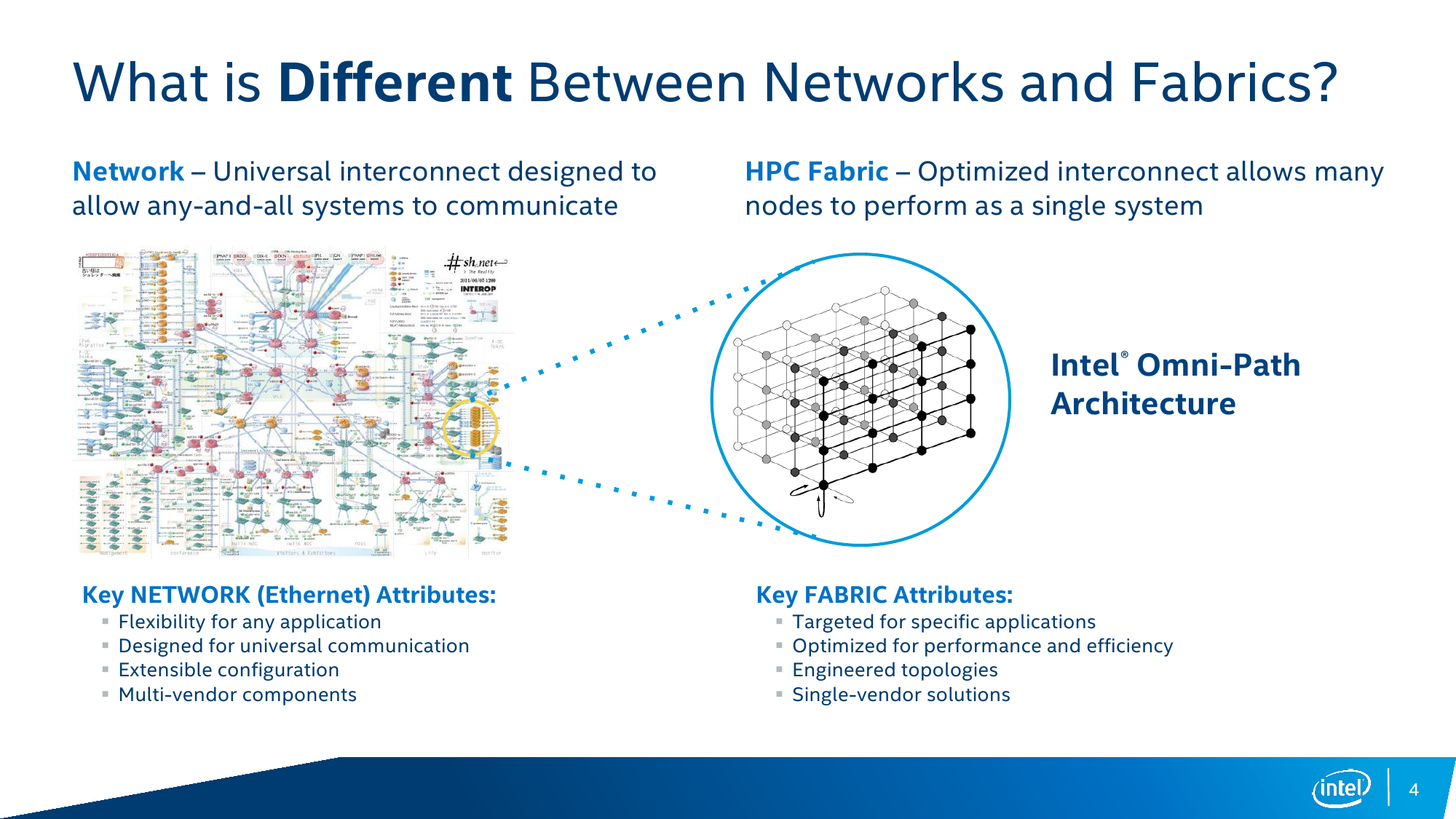
Что же такого интересного предлагает Intel в своей Omni-Path Architecture? Первое и самое основное, о чём уже говорилось раньше, – это фабрика. Фабрика представляет собой такой тип соединения между узлами, который по возможности позволяет сигналу пойти кратчайшим путём, а не как обычно — стекаясь в какой-то централизованный коммутатор и уже от него уходя к пункту назначения, что обычно необходимо для взаимодействия разнородных систем разных вендоров. Таким образом, оптимизация соединений в фабрике позволяет большому числу узлов работать как единой системе, выполняя одну и ту же задачу, что как раз и является характерным для HPC-вычислений. То есть фабрика изначально оптимизирована под конкретный класс приложений и нередко разрабатывается в рамках экосистемы одного производителя.
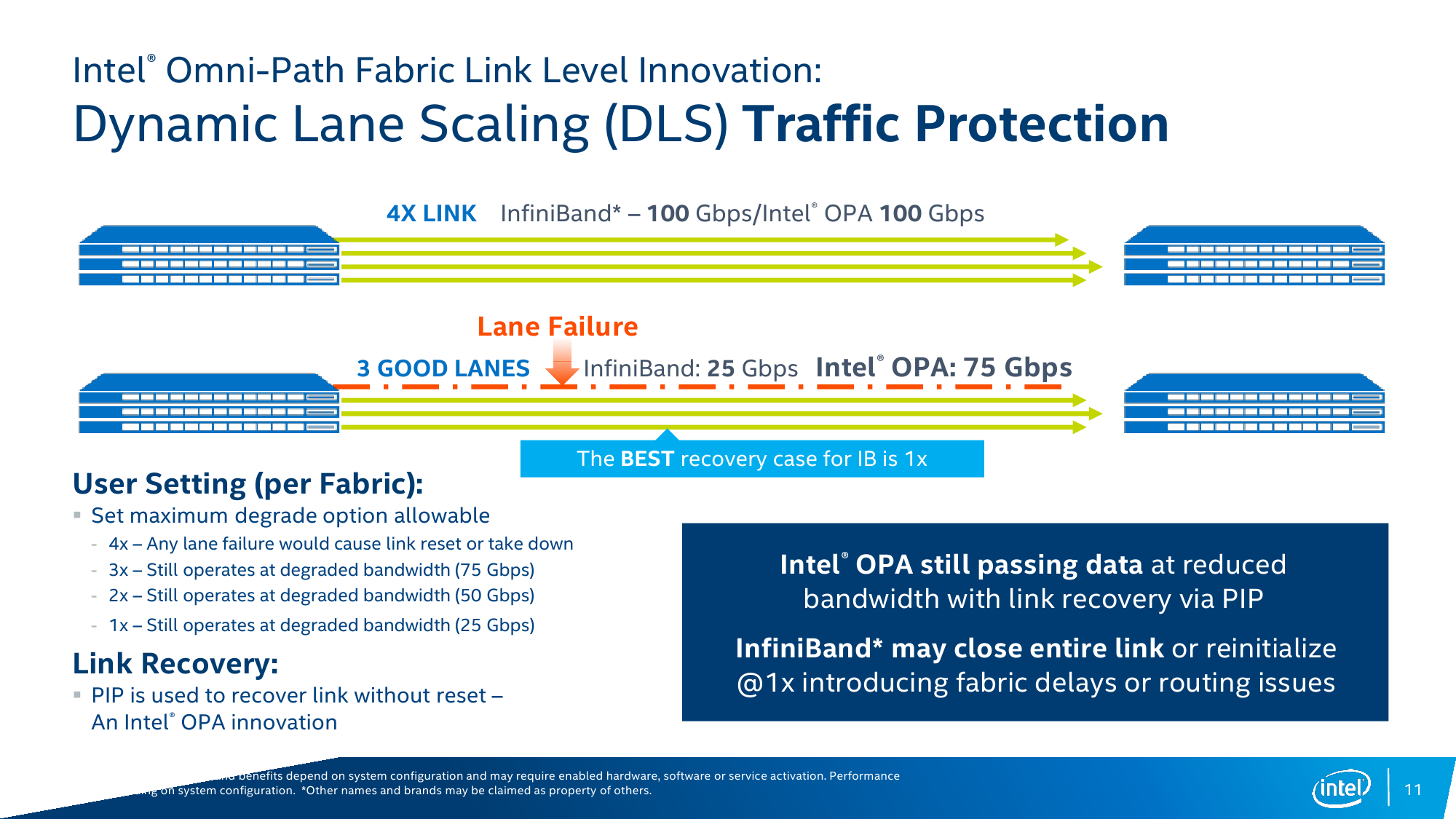
Сама по себе концепция не так уж нова – фабрики создаются и на базе Infinband, и с помощью других технологий, но в тех же Xeon Phi KNL наличие Intel OPA рядышком с основным кристаллом должно дать преимущество в виде снижения задержек. Второе важное отличие OPA – способность сохранять связь при повреждении физических линий в кабеле, тогда как Infiniband в лучшем случае потратит время на реинициализацию соединения на минимальной скорости 1X (25 Гбит/с), а в худшем — вовсе прекратит работу. Intel OPA же пропорционально снизит скорость, но подключение не потеряет – в случае обнаружения ошибки сначала отключится одна из линий и скорость упадёт до 3X (75 Гбит/с), а если ошибки всё равно будут появляться, то подключение последовательно опустится до уровней 2X и 1X (25 Гбит/с). Такой подход очень важен при долгих расчётах (от часов до недель) сложных задач, когда потеря связности даже на короткое время вынуждает заново запускать обработку данных.
 |
 |
|
 |
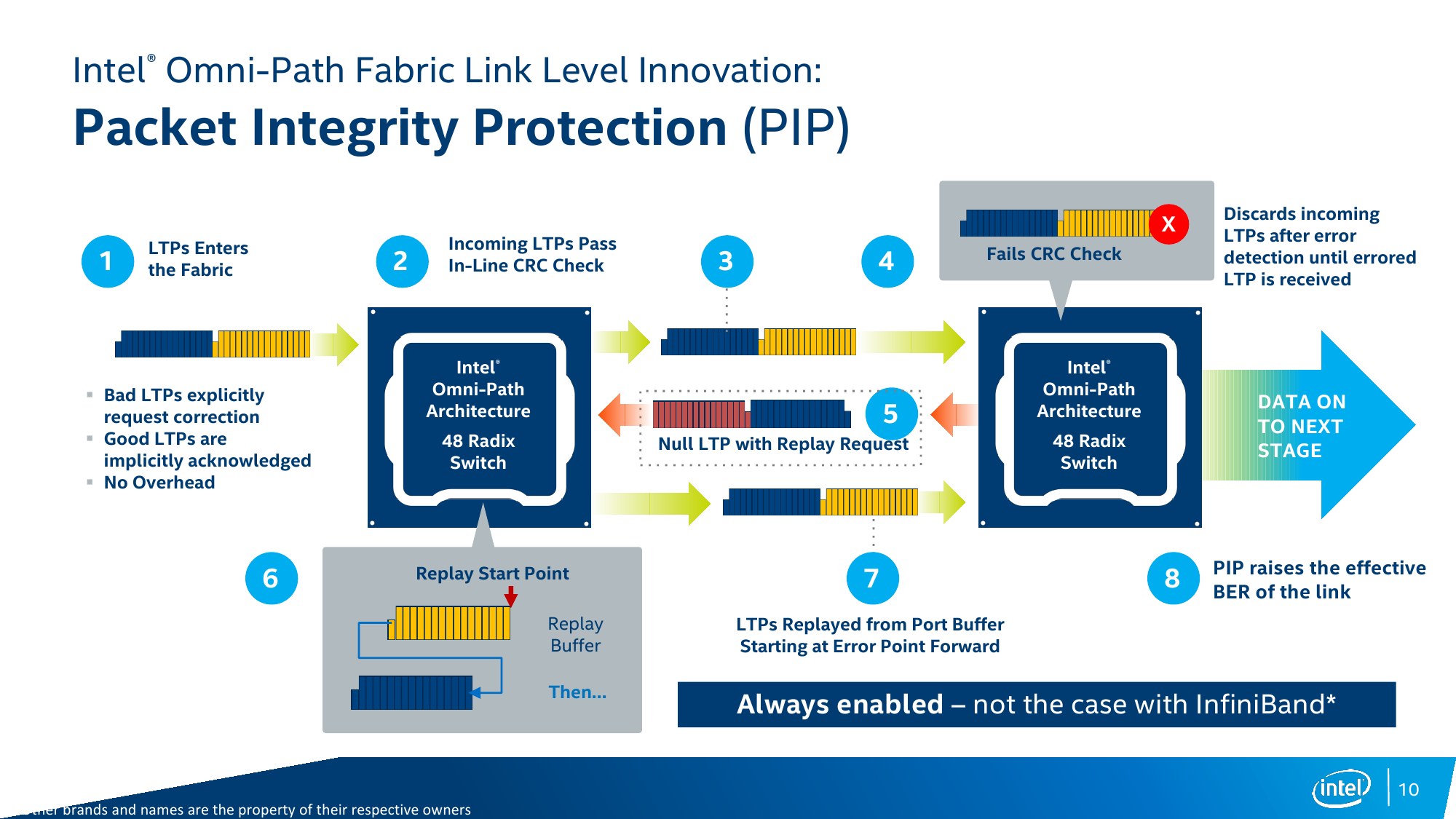 |
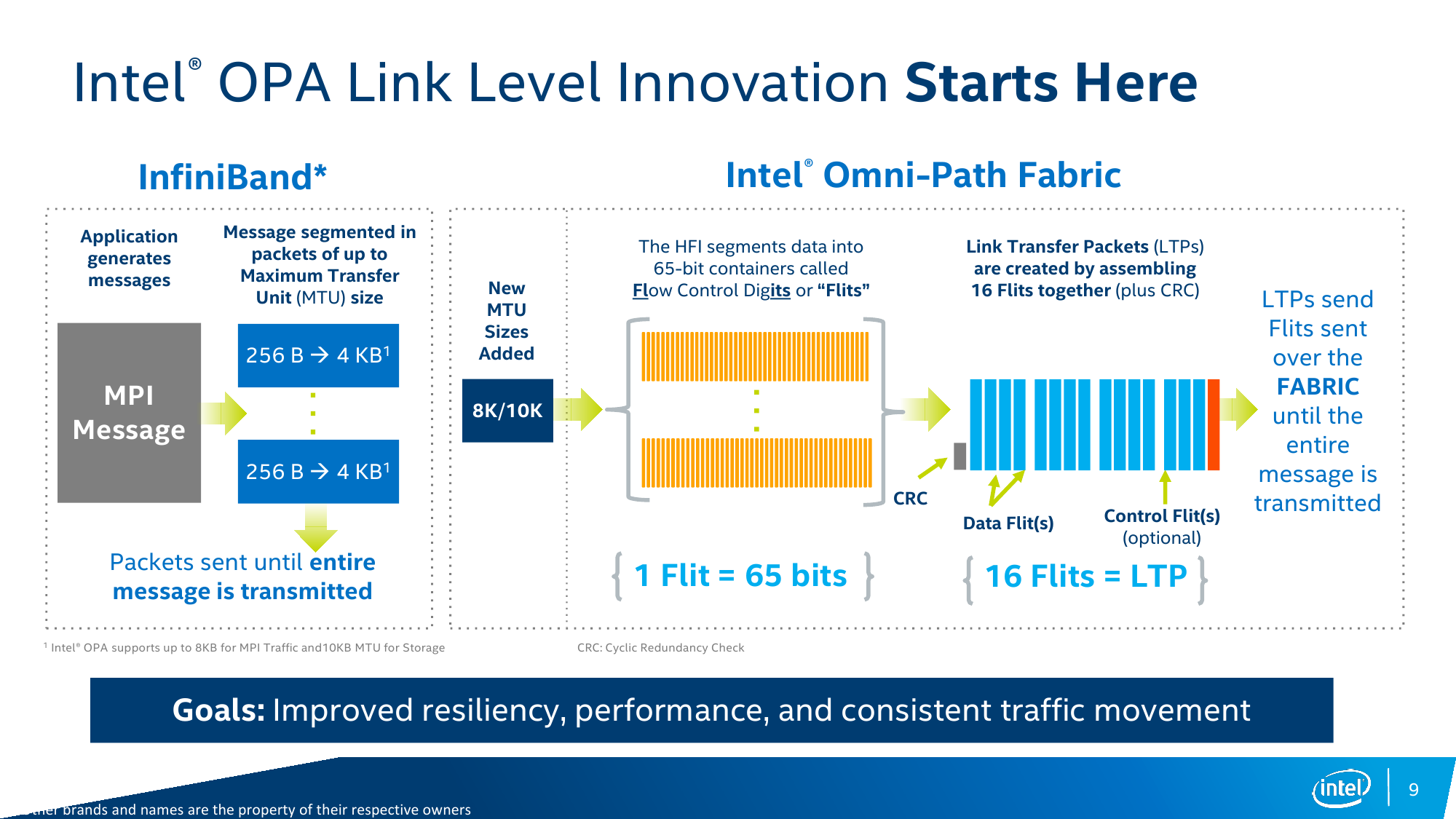
На более глубоком уровне есть и другие изменения, способствующие эффективности и надёжности передачи данных. С одной стороны, были увеличены MTU (максимальный размер передаваемого блока) пакетов фабрики до 8 Кбайт для MPI-сообщений и до 10 Кбайт для пакетов, предназначенных для взаимодействия с хранилищем. С другой стороны, механизм передачи данных подразумевает разбивку каждого пакета на контейнеры (флиты, flits) длиной 65 бит (+1 бит типа флита), которые затем объединяются в кортеж (LTP) из 16 флитов суммарным размером до 1056 бит. Итоговая эффективность передачи равна 64/66b. Далее LTP отправляется в путешествие по фабрике. При этом LTP с данными сохраняются в буфере отправителя для минимизации задержки, чтобы в случае выявления ошибки передачи данных (не сошлась контрольная сумма) тут же заново отправится в путь с того места, где произошла ошибка. Столь непростая на первый взгляд схема обработки данных нужна не только для надёжности передачи, но и для более гибкого управления трафиком внутри фабрики.
 |
 |
|
 |
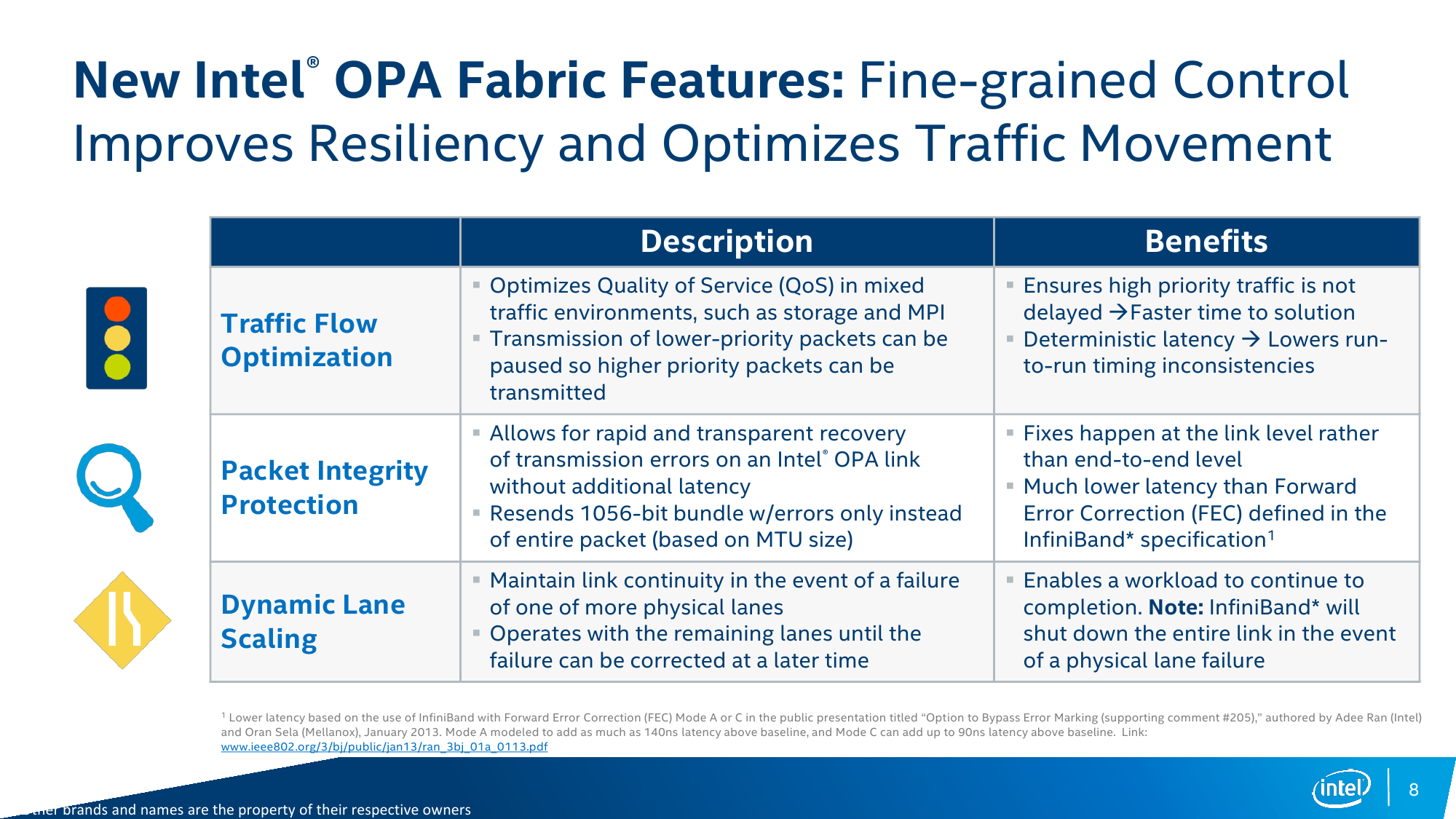 |
Для простоты скажем, что теоретически Intel Omni-Path Architecture поддерживает создание до 32 классов трафика (на практике их, скорее всего, будет от 4 до 8) с заранее заданным приоритетом. Практически же там всё устроено несколько сложнее и приоритизация доступна на разных уровнях — от виртуальных фабрик (vFabric, группа портов и протоколов) до виртуальных линий (Virtual Lane, конкретный канал связи). В конечном итоге каждый узел фабрики, приняв определённую порцию пакетов, самостоятельно переопределяет очередь передачи данных в соответствии с их приоритетом. Таким образом, например, при получении пачки высокоприоритетных MPI-сообщений после принятия низкоприоритетных обращений к хранилищу первые в итоге всё равно будут доставлены быстрее, чем вторые. Впрочем, использование такого механизма QoS предлагает решение множества проблем: разделение задач, распределение ресурсов, учёт особенностей работы конкретных протоколов приложений и так далее.
 |
 |
|
|
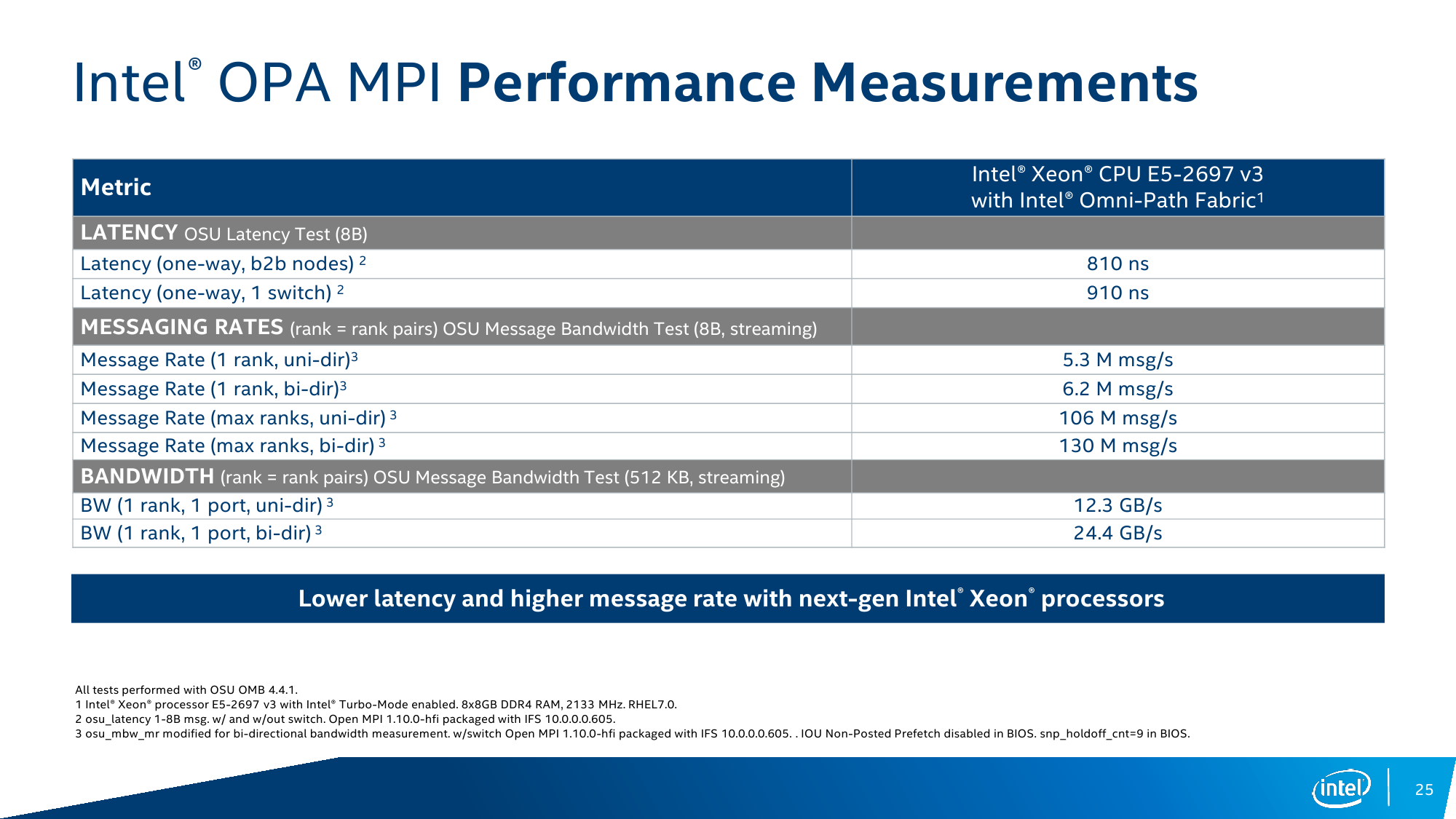
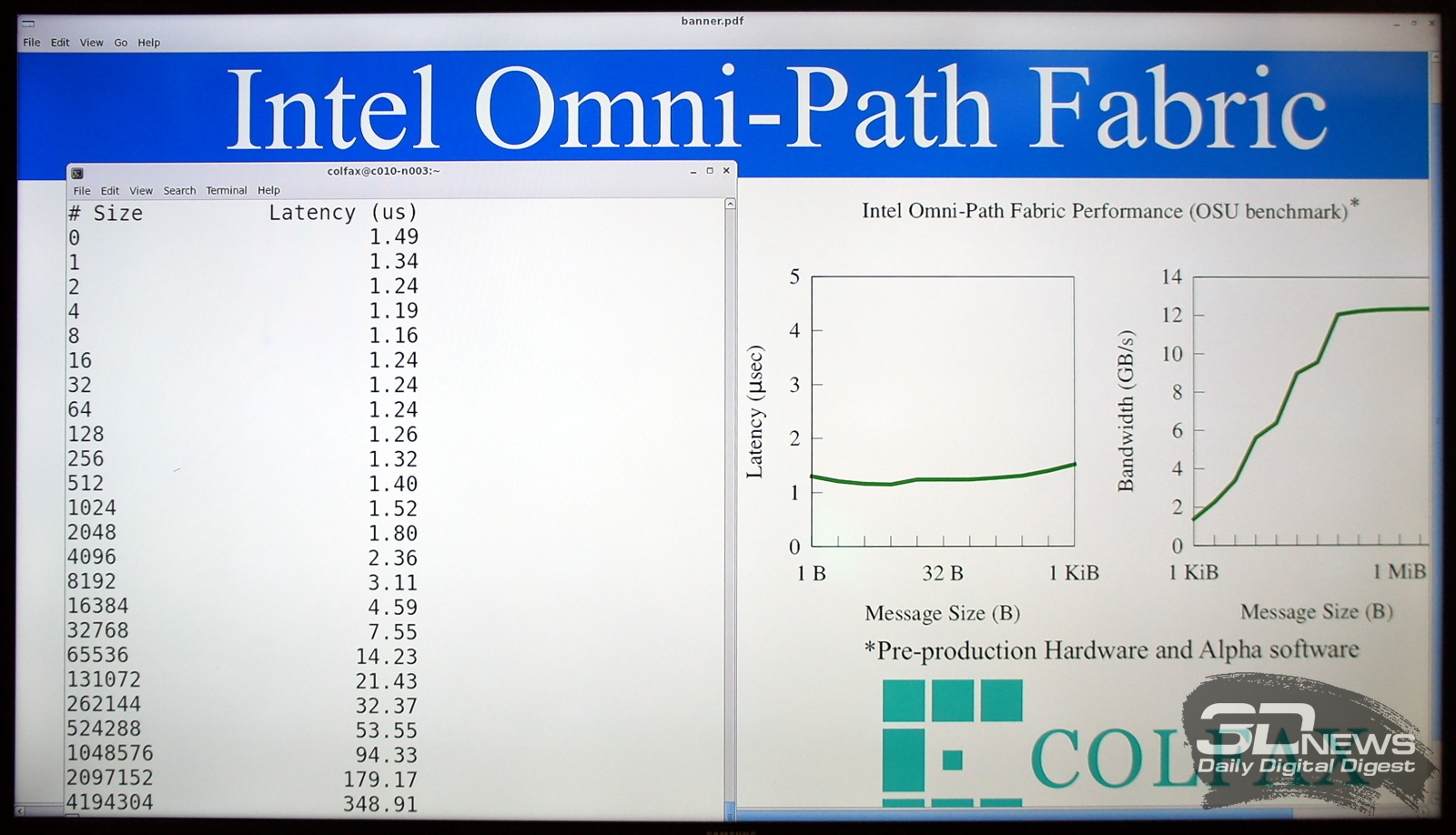
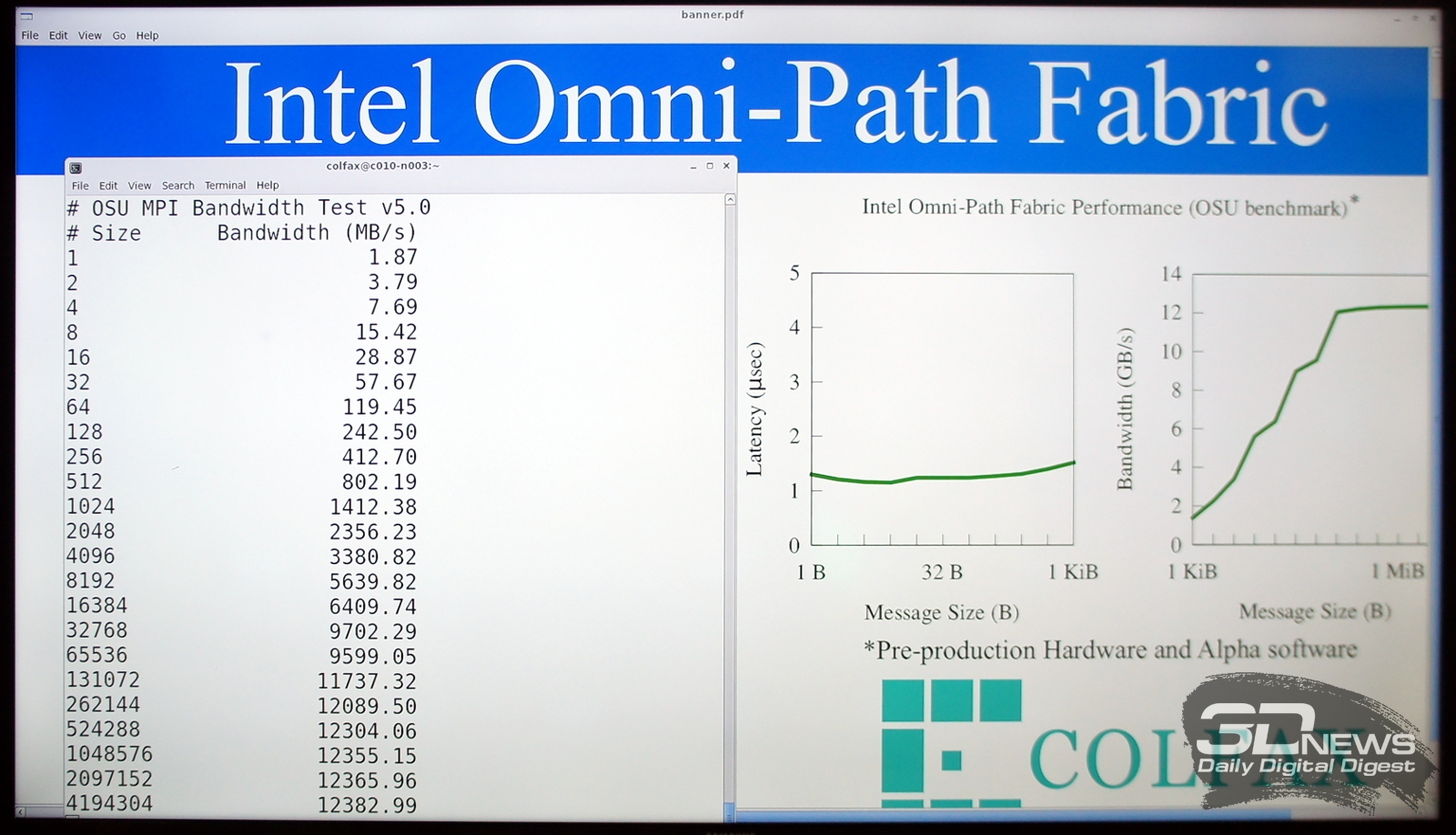
Предварительные тесты Intel Omni-Path на реальном железе |
||
Помимо очевидных преимуществ в скорости и величине задержек, Intel OPA также предлагает более высокие — по сравнению с Infinband EDR — энергоэффективность и показатель «цена/производительность». В общем, у Intel OPA есть все шансы стать новым стандартом связи в области HPC. В конце концов, когда-то Infiniband родился в результате слияния внутренних наработок Intel и других компаний — и очень быстро завоевал рынок. Посмотрим, удастся ли Intel повторить тот успех, но на этот раз уже в лице единоличного разработчика стандарта.
