В итоговом материале мы постарались чуть более подробно рассказать о наиболее важных событиях и анонсах мероприятия, о тенденциях и инновациях в мире суперкомпьютеров и HPC. Все новости с SC19 помечены соответствующим тегом на ServerNews и 3DNews, а ссылки на наиболее любопытные из них собраны в отдельной записи.

Чтобы не потеряться в тексте, добавим краткое меню со ссылкой на разделы:
Рынок HPC
По данным Hyperion Research рынок HPC чувствует себя прекрасно. В 2018 году он показал рост в 15%, достиг объёма $13,7 млрд, и только за первую половину 2019-го успел дорасти до $6,7 млрд. Много новых заказчиков пришло из корпоративного сектора. Причём сегмент аналитики данных с ИИ растёт быстрее всего. Оно и неудивительно, так как корпорациям интересны именно решения их сиюминутных бизнес-задач в отличие от традиционных HPC-инсталляций, ориентированных на фундаментальные и практические научные исследования. Кроме того, растёт интерес к облачным HPC-решениям, хотя далеко не все готовы отдать свои данные третьим лицам.

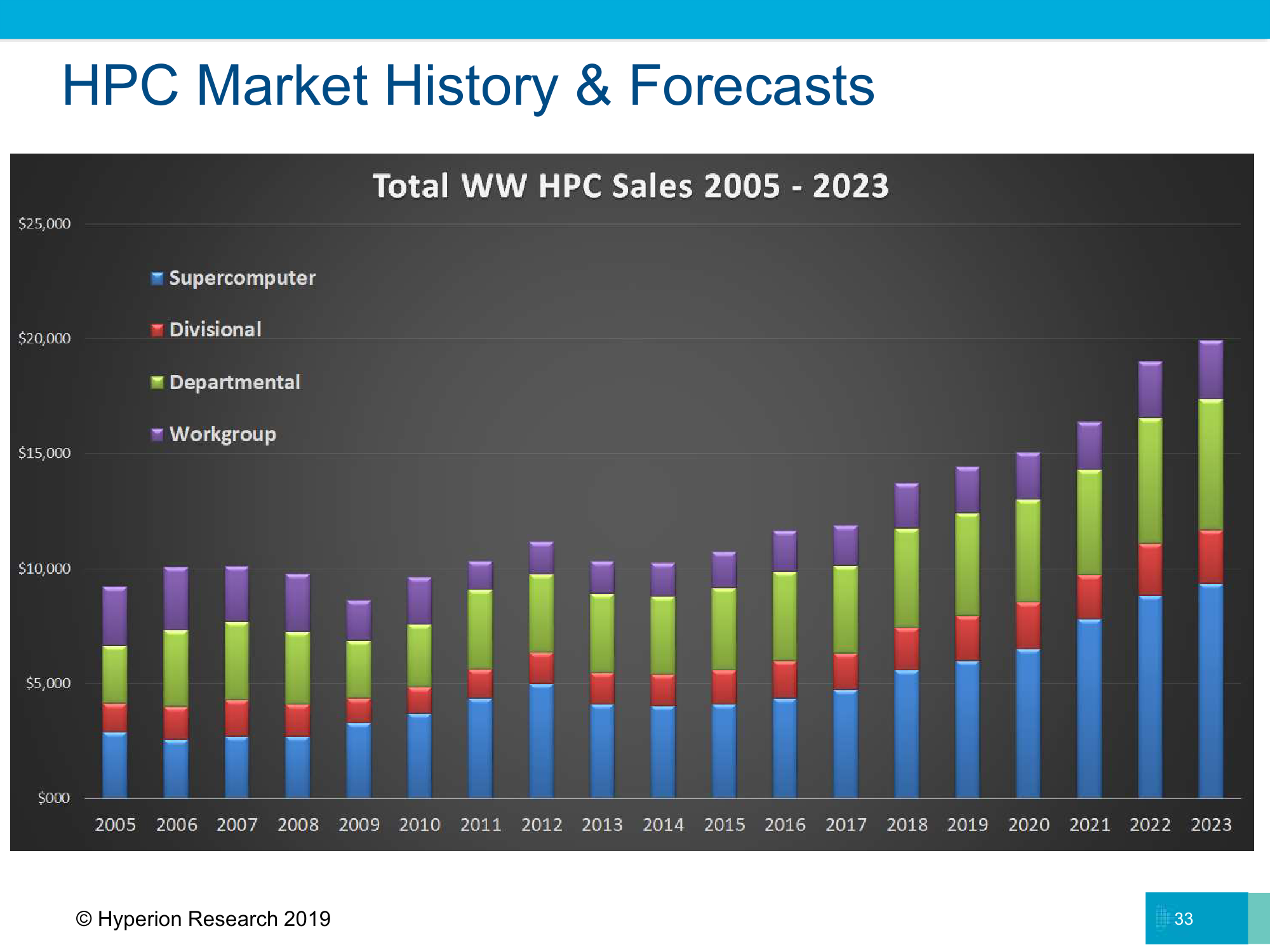
При этом аналитики отмечают, что ИИ-системы всё ещё находятся на начальном этапе развития. Эту область начинают активно осваивать многочисленные стартапы, занимающиеся и ПО, и специализированными чипами. Они наверняка образуют собственный сегмент, как и квантовые компьютеры, которые тоже никак нельзя назвать массовыми. Но если ИИ будет плотно интегрироваться с HPC, то вот квантовые системы, похоже, так и останутся лишь дополнением к старому доброму «кремнию» в форме облачного доступа.
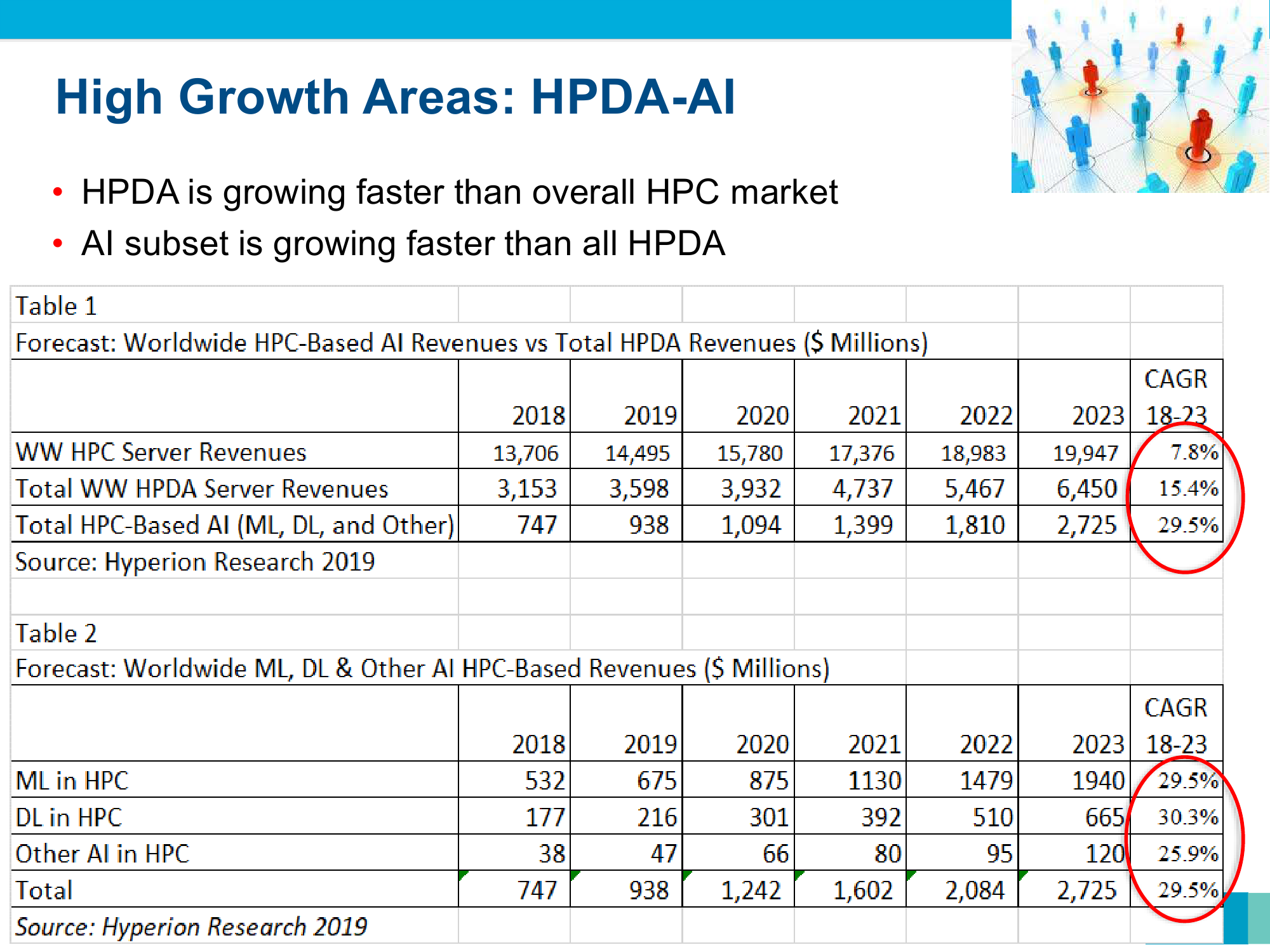
Кроме того, они очень дороги. А индустрия и так тратит немалые суммы на создание суперкомпьютеров экзафлопсного класса. В период 2020-2025 годов прогнозируется появление 26 подобных систем или близких к ним, которые обойдутся примерно в $9 млрд. Из них порядка $2 млрд уйдёт на 4-5 машин, которые появятся в 2021 году в Китае, США, Европе и Японии, и это станет историческим рекордом затрат в HPC. В перспективе добавится ещё один игрок — Великобритания.
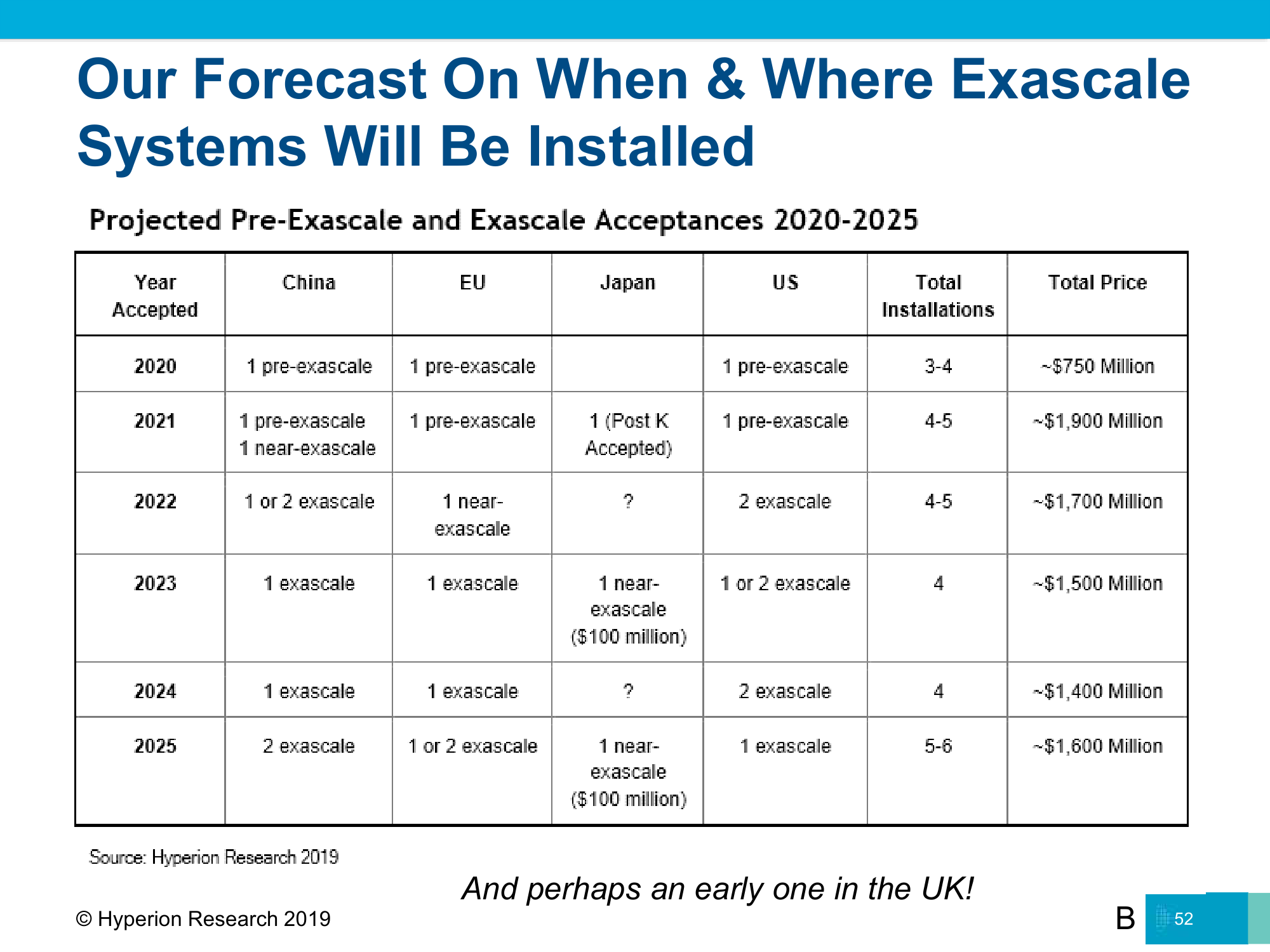
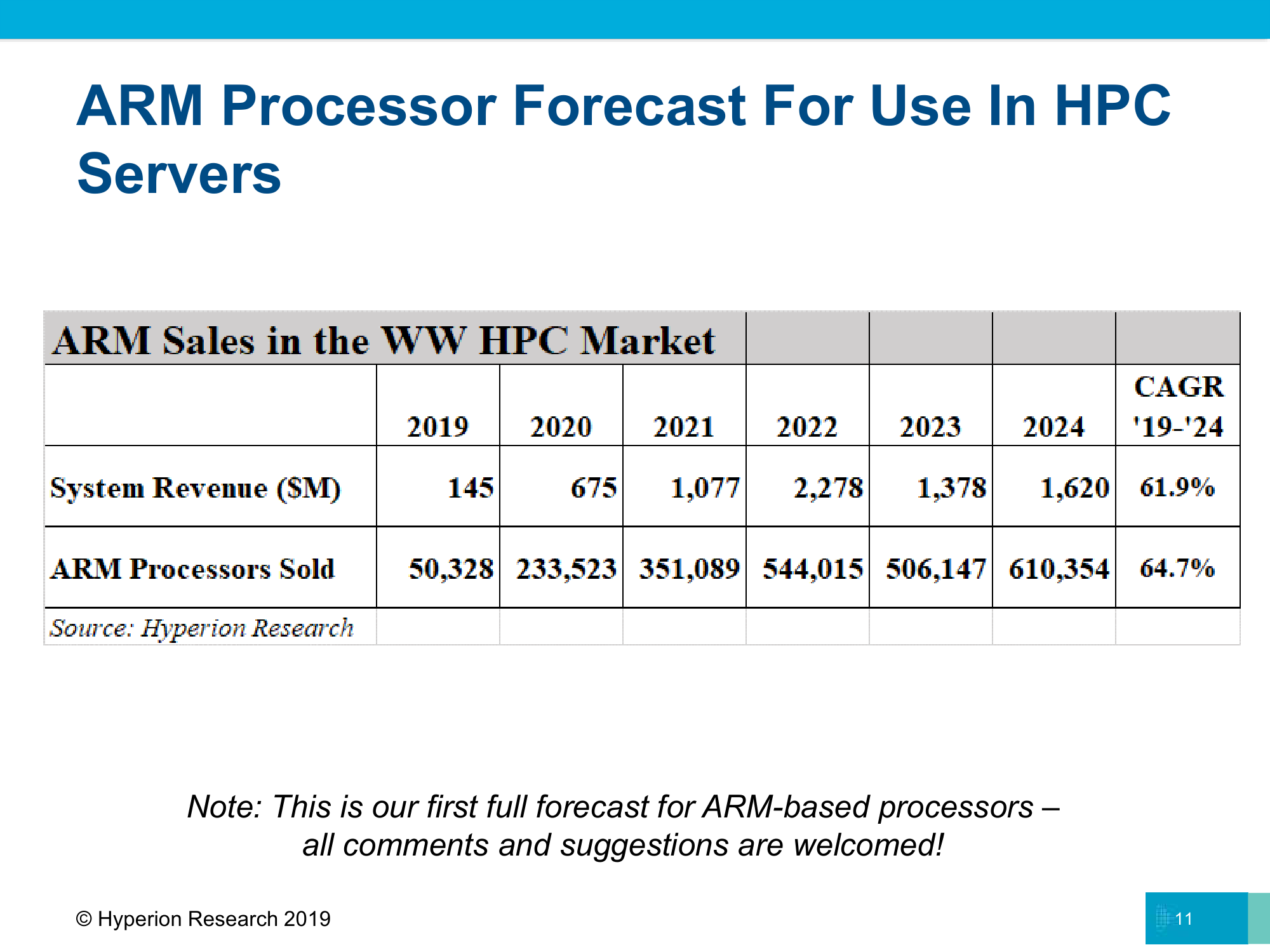
Ну а победителем в экзафлопсной гонке станет Япония. В первой половине следующего года должна окончательно завершиться установка суперкомпьютера Fugaku (Post-K) с более чем 150 тыс. узлов на базе ARM-процессоров. И начнётся новая гонка архитектур. С этого момента ARM досрочно признана достойной HPC-олимпа, и ей прочат светлое, но не лишённое трудностей будущее.
ARM
В ARM поверили — это и есть главная новость, а вовсе не попадание в свежий TOP500 Fugaku на базе Fujitsu A64FX и даже не его первое место в Green500 с обязательным упоминанием, что это единственная машина на базе только CPU (без «зелёных» ускорителей). Если посмотреть на спецификации A64FX, которые давно известны, то назвать его просто ARM-процессором язык не поворачивается. Дело в том, что концептуально он очень похож на почивший Xeon Phi: стандартные ядра + пачка широких векторных инструкций (тут это SVE), которые и дают основную производительность. А ещё набортная HBM2, внутренняя шина-фабрика и встроенный интерконнект.

Так что грядущие Marvell ThunderX3 и X4, которые тоже получат SVE, выглядят гораздо интереснее. Вице-президент Marvell Ларри Викелиус (Larry Wikelius) подробностями о новинках не поделился, но отметил, что экосистема ARM в серверном и HPC-сегментах за последние два года очень сильно выросла. Речь не о «железе», конечно, а ПО и средствах для его разработки и портирования — немало этому поспособствовало сотрудничество с Cray. Вторит ему и представитель Fujitsu, отмечая, что не надо путать миры мобильного и серверного ARM. Если вокруг первого годами выстраивалось сообщество, то у второго оно только зарождается.

То же, но в меньшей степени касается и Ampere, AWS, Huawei — немногочисленных, но крупных участников рынка серверных ARM, которые прямо на HPC не нацелены. Впрочем, конкретно у Fujitsu всё и так сложнее, чем у других игроков, так как её продукция ориентирована на японский рынок, где долгое время доминировали «домашние» SPARC-инсталляции, что процесс портирования ПО нисколько не облегчает.

Intel
Самый интересный, но и самый далёкий от реального продукта «железный» анонс — это серверные ускорители Intel Xe HPC. Он, правда, оказался слегка смазан утечкой в день проведения предварительного брифинга. Так что полным сюрпризом выступление Кодури не стало. Итак, кратко о том, что нас ждёт в Ponte Vecchio: несколько микроархитектур под разные вычислительные задачи, поддержка форматов от INT8 до FP64, HBM2-память, когерентная шина-фабрика XEMF для общего доступа к памяти со стороны GPU/CPU, сверхбыстрый и ёмкий кеш Rambo Cache, шина CXL для объединения множества GPU и CPU, упаковка Foveros с EMIB. Итоговый прирост производительности на узел в сравнении (не совсем честном, конечно) с текущими решениями Intel составит 500 раз. Появления новинки стоит ждать в 2021 году, и открытым остаётся вопрос, где же именно будут выпускаться эти 7-нм изделия.

О процессорах речь на выставке толком не шла, так как пока Intel чего-то нового предложить не может. Стало лишь известно, что новые Xeon получат технологию Data Streaming Accelerator (наследница QuickData) для ускорения обмена данными между локальными и удалёнными DRAM, SSD, Optane и разгрузки CPU. Да, кое-где можно было заметить первые системы на базе Xeon Scalable второго поколения Platinum 9200, но их было не слишком много, да и те больше похожи на референсные системы самой Intel с лёгкой доработкой. Похоже, AMD со своими Rome нарушила привычный ход событий. Из уникальных решений отметим отечественные узлы РСК с СЖО, которые органично дополняли и новую СХД на базе SSD формата EDSFF — 1 Пбайт в корпусе 1U даётся не каждому.

Cascade Lake AP с TDP 400 Вт нужно серьёзное охлаждение
Через упоминание о попадании в лидеры рейтинга IO500 параллельной файловой системы Intel DAOS, которая основывается на библиотеках PMDK и SPDK, перейдём к действительно самому важному анонсу Intel на SC19. Речь, конечно, идёт о oneAPI — открытом и бесплатном аналоге NVIDIA CUDA для разных платформ. oneAPI включает собственно API, язык программирования DPC++ (расширение Khronos SYCL), набор средств разработки (компиляторы, отладчики, профилироващики), библиотеки, утилиты портирования кода (с CUDA, в первую очередь).
Основная цель – упростить портирование и разработку ПО под разные архитектуры (CPU, GPU, FPGA, ускорители), сведя к минимуму работу над оптимизацией для каждой из них. Руководитель проекта, Билл Сэвэдж (Bill Savage), отдельно подчёркивает, что это «не попытка сделать новую Java с её слоганом “написал один раз, запустил везде”, нет. Какие-то доработки в коде для каждой платформы надо будет делать, но писать каждый раз с нуля уже не придётся».
AMD
На фоне oneAPI анонс ROCm 3.0 смотрится несколько блекло. Других крупных объявлений от AMD на SC19 не было, да и стенд на выставке был скромный. Однако это не значит, что AMD ничего не делала после выхода EPYC Rome в августе. Десяток-другой контрактов на грядущие суперкомпьютеры с CPU AMD “выстрелят” через полгода-год, вот тогда и посмотрим на расклад сил в TOP500. В текущем рейтинге есть только две машины на базе AMD EPYC Rome, ещё две на базе Naples и одна с китайским клоном Hygon Dyana.
Тем не менее, практически все крупные игроки так или иначе осваивают AMD. Кто-то теперь просто предлагает два варианта одной и той же платформы: с Intel и с AMD. Кто-то создаёт новые. Однако зачастую больший интерес вызывает не «ядерная» составляющая новинок, а обилие линий PCIe 4.0, что позволяет упаковать в шасси побольше ускорителей и накопителей без использования свитчей. Из интересных решений стоит отметить СХД Viking, которая вполне может оказаться самой быстрой на рынке. Правда, выйдет она наверняка под каким-нибудь более известным брендом.

А вот связка из процессоров и ускорителей AMD популярностью не пользуется, хотя сама компания представила на стенде и референсную платформу, и различные продукты с поддержкой PCIe 4.0. Увы, в TOP500 есть единственная машина с ускорителями AMD с некими Vega 20, хотя уже есть контракты на суперкомпьютеры с Instinct Mi 60, ситуация с которым не совсем ясна. Будет забавно, если oneAPI в итоге даст толчок к массовому использованию Instinct. Последние в будущем должны получить поддержку новых форматов чисел.
NVIDIA
Карта NVDIA Tesla V100s не удостоилась отдельного большого анонса. То тут, то там на стендах попадались таблички с упоминанием поддержки этого ускорителя, но без детального описания. Все отличия от обычной V100 заключаются в увеличении ПСП памяти и подросшей производительности при сохранении того же уровня TDP. Кроме того, на SC19 была замечена загадочная модификация GeForce RTX 2080 Ti — в серверном исполнении с пассивным охлаждением.

Анонс стека Magnum IO, который обещает в 20 раз ускорить обработку данных в кластерах за счёт устранения узких мест при работе с СХД и операциями ввода-вывода, пожалуй, наиболее важен для компании. Решение опирается, по большому счёту, на (R)DMA, но имеет далеко идущие последствия в свете покупки Mellanox. Компания явно не против избавиться от CPU, которые сейчас нужны больше для управления, а не собственно расчётов, и которые дают линии PCIe для связи с внешним миром.

В пределе должно получиться что-то вроде конструктора из СХД и массивов GPU, напрямую связанных быстрым интерконнектом InfiniBand/Ethernet, что позволит довольно легко масштабироваться. В этом свете рефересная платформа NVIDIA и ARM смотрится даже забавно: два отдельных шасси, соединённых внешним интерконнектом. Причём в верхней половинке с ускорителями остаётся полно свободного места, а нижняя — с CPU, дисковой корзиной и сетевыми адаптерами — упакована гораздо более плотно. Впрочем, тут тоже важнее перенос программной составляющей CUDA-X на ARM, что опять-таки указывает на взросление последней.
Облака
Amazon, Google и Microsoft уже не в первый раз приезжают на SC, да IBM с Oracle постоянно напоминают о своих облачных решениях. Им, кажется, пора уже устраивать собственный ежегодный «междусобойчик» на тему HPC, где они будут рассказывать всем желающим о возможности за относительно небольшие суммы арендовать почти настоящий суперкомпьютер. Собственно, программные решения для управления большим кластером виртуальных машин в облаке существуют уже давно. В последние год-два провайдеры стали активно добавлять к ВМ различные варианты ускорителей и, наконец, озаботились быстрым интерконнектом, наличие которого и отличает нормальную HPC-систему. Насколько при этом остаются «облачными» с технической точки зрения решения вроде Azure NDv2 с NVIDIA Tesla и выделенной InfiniBand-сетью, вопрос открытый.
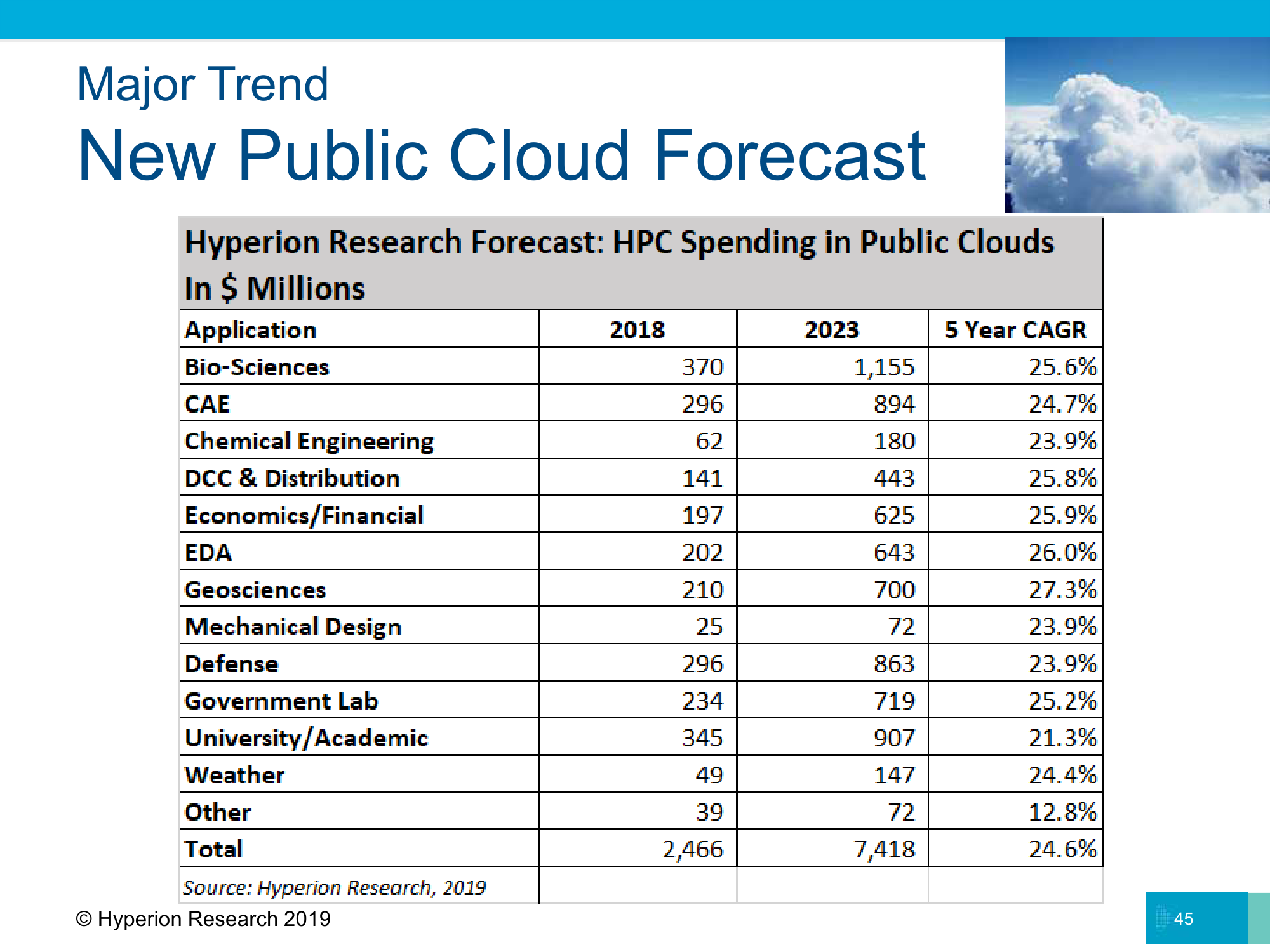
Альтернативные решения
Открытым остаётся и вопрос, считать ли FPGA, а также специализированные ИИ-ускорители, альтернативными решениями в области HPC или уже нет. Пока их всё же массовыми не назовёшь. Первые долгое время страдали от сложности разработки, но Xilinx ещё раз напомнила о платформе Vitis, да и oneAPI охватывает Arria. Так что теперь с FPGA можно работать с использованием «человеческих» языков программирования. Что касается вторых, то количество компаний, делающих специализированные чипы, растёт как на дрожжах. Из новичков отметим Graphcore, которые прописались в Microsoft Azure, и Cerebras, удивительно быстро умудрившиеся продать себя Аргоннской национальной лаборатории. Интересующимся темой также можно взглянуть на результаты рейтинга MLPerf среди чипов для запуска нейронных сетей (inference).
Из других «узких» решений от крупных игроков на SC19 присутствовали анонсированные в августе ИИ-ускорители Intel Nervana — как для обучения (NNP-T), так и для запуска нейронных сетей (NNP-I). Причём NNP-T представлен не только в виде PCIe-карт (AIC), но и в формате OAM (аналог SXM2), что явно понравится облакам и гиперскейлерам. Из интересного отметим, что AIC-версии могут попарно объединяться «мостиками» PCIe и имеют внешний интерфейс для сквозной связки карт как в пределах шасси, так и для объединения ускорителей в пределах стойки целиком.

На «голые» NNP-I пока посмотреть не удастся — на стенде Intel эти ускорители были спрятаны внутрь «рулеров» EDSFF. Вообще, такая своеобразная конверсия не единична — WD предлагает FPGA-акселераторы для тех же задач в форм-факторе U.2. В конце концов, в обоих случаях выходным интерфейсом является PCIe. Что касается предварительных бенчмарков Nervana, то Intel грозится с изрядным перевесом одолеть NVIDIA T4. Правда, тут есть нюанс — к моменту выхода NNP-I на рынок «зелёные» вполне могут выкатить новый инферентный ускоритель. Так что на их стороне пока что есть только хорошая масштабируемость — Nervana будет и в серверах, и в ультрабуках.

Нейроморфные системы Intel тоже не забросила и привезла на SC19 Pohoiki Spings с 768 чипами Loihi, эквивалентными 100 млн нейронов. Система набрана из 24 плат Nahuku, каждая из которых содержит 32 базовых чипа. Избранным партнёрам такие системы достанутся к концу года. Во время SC19 состоялось официальное объявление о входе в сообщество Intel Neuromorphic Research Community (INRC) крупных компаний, таких как Accenture, Airbus, General Electric и Hitachi. Ранее в нём участвовали лишь стартапы и разного рода научно-исследовательские организации. Впрочем, вся эта инициатива всё ещё носит сугубо экспериментальный характер.
К альтернативным в каком-то смысле можно отнести и платформу IBM POWER. Да, машины на этой архитектуре лидируют в TOP500, но их число очень невелико. Экосистема почти не развивается, несмотря на интересные разработки вроде нового формата оперативной памяти DDIMM, который на SC19 вообще оказался связан с интерконнектом Gen-Z. Родственный консорциум OpenCAPI продолжается бороться с PCIe, но не слишком успешно. Кажется, POWER окончательно превращается во «второй источник» для Министерства энергетики, которое и оплачивает все эти развлечения.
View this post on Instagram✴Редкий гость – #CPU #IBM #POWER9 на #SC19 #процессор #openpower #3dnews #3dnewsru
Так что IBM очень вовремя склонилась к другой стратегии. Она, конечно, всегда готова продать машину побольше, но теперь клиентам предлагается купить хоть какую-нибудь POWER-систему (да хоть один узел) для сбора данных, которые будут отправлены на обработку в ИИ-сервис IBM. Его же можно использовать и с уже имеющимися суперкомпьютерами. В конце концов, IBM продаёт не «железо», а помогает другим компаниям вести бизнес.

Mentor Veloce 2 — аппаратный эмулятор SoC, используется в проекте EPI Mont-Blanc 2020
Ту же идею иметь дополнительного, независимого поставщика процессоров для суперкомпьютеров худо-бедно реализует Евросоюз, который спонсирует сразу несколько проектов на базе RISC-V, OpenPOWER и MIPS вкупе с FPGA в рамках консорциума European Processor Initiative (EPI). Но массового производства «кремния» пока не видать. Япония успешно заполучила ARM, но и запасные варианты вроде NEC SX-Aurora тоже имеются.
Заключение
В целом выставка прошла на удивление… спокойно? Да, наверное, так. Стенды компаний не старались удивить какими-нибудь безумными и дорогими инсталляциями, перформансами и конкурсами. Всё скромненько, с упором на демонстрации, доклады и личные разговоры. Посетителей, если не считать вечеринку в день открытия, тоже субъективно было меньше, чем в прошлые годы. Ну и фокус выставки тоже несколько сместился, так как многие ключевые анонсы были уже сделаны на специализированных выставках вроде HotChips, Flash Memory Summit, AI Summit или отдельных мероприятиях самих вендоров.

Atos BullSequana Edge — типичная edge-платформа
Помимо прочего, не все были довольны появлением новых лиц, имеющих опосредованное отношение к HPC. Например, стало больше бывших майнеров, которые успешно заработали на скачках курсов криптовалют и теперь пытаются продать свои наработки кому-нибудь ещё. Речь, в частности, об иммерсионных СЖО. Для массового внедрения они, наверное, пока не слишком подходят, зато могут стать актуальными в микро-ЦОД для периферийных (edge) вычислений. Для последних крупные игроки тоже представили свои решения.
View this post on Instagram✴
По самой выставке нельзя было сказать, что число участников SC в этом году превысило 13 тыс. человек. И это при цене билета в несколько сотен долларов. Большая часть выбрала участие в конференции, а не осмотр стендов. Всего к SC19 было подготовлено 339 научных публикаций, из которых 87 было отобранодля проведения докладов. Это не рекордный результат за 31 год истории SC, но очень неплохой. Так что не исключено, что со временем мероприятие вернётся к своим истокам и станет именно научным.