Израильский стартап UnifabriX показал, что разработанный его силами пул Smart Memory Node с поддержкой CXL 3.0 может не только расширять объём доступной системам оперативной памяти, но и повышать эффективность её использования, а также общую производительность серверных платформ. На конференции SC22, прошедшей в конце прошлого года, компания продемонстрировала работу Smart Memory Node в комплексе с несколькими серверами на базе Sapphire Rapids.

UnifabriX Smart Memory Node. Использование E-EDSFF E3 позволяет легко наращивать объём пула (Источник здесь и далее: Blocks & Files)
UnifabriX делает основной упор не на непосредственном увеличении доступного объёма оперативной памяти с помощью CXL, а на том, что эта технология повышает общую пропускную способность подсистемы памяти, что позволяет процессорным ядрам использовать её более эффективно. Как показывает приведённый график, со временем число ядер в современных процессорах активно росло, но доступная каждому ядру ПСП снижалась.
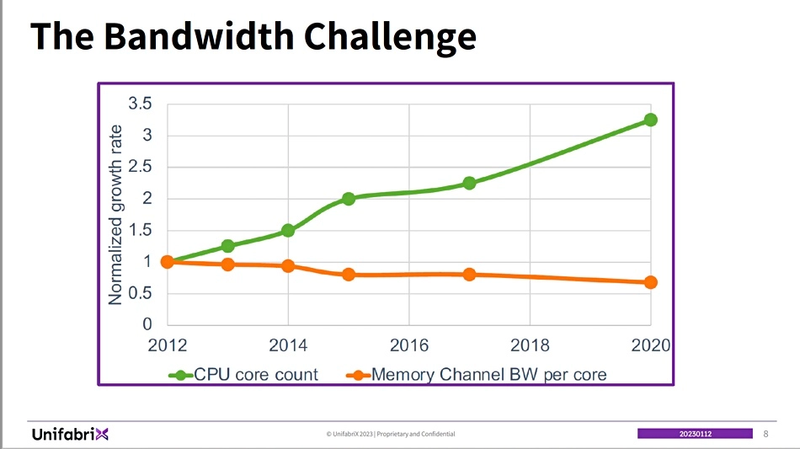
По мере увеличения количества ядер, каждому ядру достаётся всё меньше памяти.
На SC22 компания провела тестирование с помощью HPC-бенчмарка HPCG (High Performance Conjugate Gradient), который оценивает не только «голую» производительность вычислений, но и работу с памятью, что не менее важно в современных нагрузках. Без использования пула Smart Memory Node максимальная производительность была достигнута при загрузке процессорных ядер не более 50 %, то есть вычислительные ресурсы у системы ещё были, но для их использования катастрофически не хватало пропускной способности памяти!
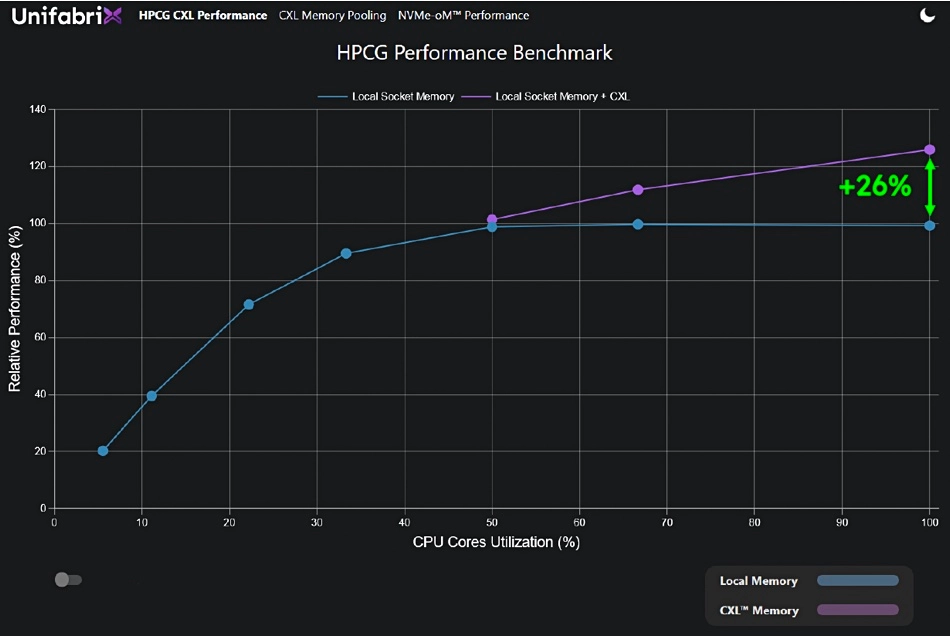
Подключение пулов CXL позволило поднять производительность на 26 %. В реальных сценариях выигрыш может оказаться ещё больше
Компания считает, что в случае с такими процессорами, как AMD EPYC Genoa, использование только локальной DRAM выведет систему «на плато» уже при 20 % загрузке. Подключение же пулов Smart Memory Node позволило, как минимум, на 26 % повысить загрузку процессорных ядер, поскольку предоставило в их распоряжение дополнительную пропускную способность. К локальным 300 Гбайт/с, обеспечиваемым DDR5, добавилось ещё 256 Гбайт/с, «прокачиваемых» через PCIe 5.0/CXL.
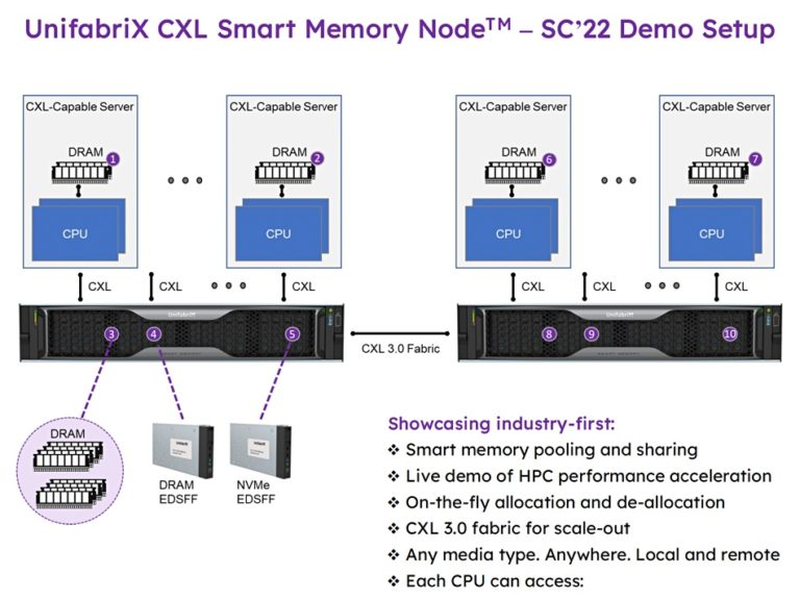
Схема тестовой платформы, показанной на SC22
В тестовом сценарии на SC22 были использованы системы на базе Xeon Max. UnifabriX Smart Memory Node имеет в своём составе сопроцессор RPU (Resource Processing Unit), дополненный фирменным ПО. Устройство использует модули EDSFF E3 (такие есть у Samsung и SK hynix), максимальная совокупная ёмкость памяти может достигать 128 Тбайт. UnifabriX умеет отслеживать загрузку каналов памяти каждого процессора из подключённых к нему систем, и в случае обнаружения нехватки ПСП перенаправляет дополнительные ресурсы туда, где они востребованы. Каждое такое устройство оснащено 10 портами CXL/PCIe 5.0.

Smart Memory Node имеет 10 портов CXL, совместимых с PCI Express 5.0/6.0
Таким образом, UnifabriX наглядно указала на основное узкое место современных NUMA-систем и показала, что использование CXL позволяет обойти накладываемые ограничения и использовать многоядерные комплексы более эффективно. Речь идёт как об обеспечении каждого ядра в системе дополнительной ПСП, так и о повышении эффективности подсистем хранения данных, ведь один пул Smart Memory Node может содержать 128 Тбайт данных.
Источник: